调查研究-202 SGLang 深度解析:为什么大模型推理框架不只是“把模型跑起来“
TL;DR
- 场景:RAG、多轮对话、Agent 工具调用、JSON 强约束、长 system prompt、高并发生产环境
- 结论:SGLang 的价值不在于"比 vLLM 更快",而在于把 LLM 应用视为结构化程序,让 runtime 理解请求之间的结构关系
- 产出:6 类最值得测试 SGLang 的场景 + 12 项真实压测指标 + 与 vLLM / TensorRT-LLM 的选型对比
版本矩阵
| 功能 | 状态 | 说明 |
|---|---|---|
| RadixAttention 跨请求前缀缓存 | ✅ 已验证 | 2024/01 发布,v0.3+ 稳定支持 |
| Compressed FSM 结构化输出 | ✅ 已验证 | 2024/02 发布,JSON 解码 3x 加速 |
| v0.4 零开销批处理 + 缓存感知负载均衡 | ✅ 已验证 | 2024/12 发布 |
| v0.5.6 稳定版 | ✅ 已验证 | 2026 年当前推荐生产版本 |
| DeepSeek V3/R1 Day 0 支持 | ✅ 已验证 | 2025/01 发布 |
| DeepSeek-V4 Day 0 支持 | ✅ 已验证 | 2026/04 发布 |
| DFlash / Spec V2 投机解码 | ✅ 已验证 | 2026/06 新一代 |
| NVIDIA GB300 NVL72 25x 加速 | ✅ 已验证 | 2026/02 发布 |
| SGLang Diffusion 多模态 | ✅ 已验证 | 2026/01 推出 |
| XGrammar 结构化输出集成 | ⚠️ 待验证 | 持续优化方向,文档未明确版本号 |
| 与 vLLM PagedAttention 通用基准对比 | ⚠️ 待验证 | 公开 benchmark 不能代表真实业务负载 |
TL;DR
SGLang 不是一个简单的"模型启动器"。
它更像一个面向复杂 LLM 应用的推理执行系统:既提供服务端 runtime,也提供用于表达结构化 LLM 程序的 frontend language。
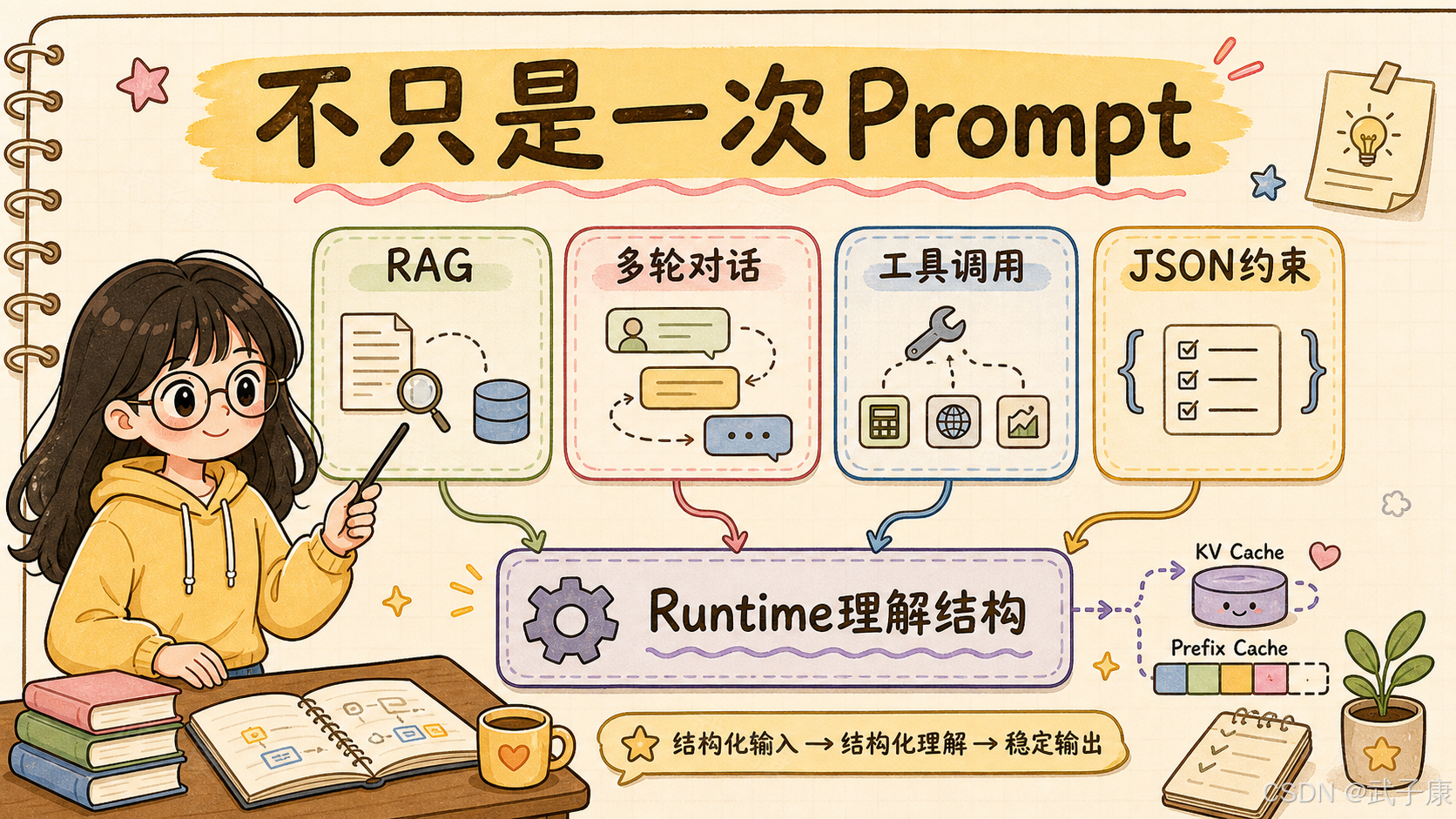
如果你的场景只是启动一个聊天模型、提供 OpenAI-compatible API、支持流式输出,很多框架都能做。但当业务进入 RAG、多轮对话、Agent、工具调用、JSON schema、长上下文、并发服务之后,问题就不只是"模型能不能跑起来"。
真正的瓶颈会变成:
重复 prefill 有没有被浪费?
KV Cache 能不能跨请求复用?
长 system prompt 是否每轮都重新算?
结构化输出是否稳定且足够快?
Agent 的分支和并行能否被 runtime 理解?
高并发下 TTFT、吞吐和 GPU 利用率能否同时稳定?
SGLang 的价值就在这里:它把 LLM 应用看成一种有结构的程序,而不是一串孤立 prompt。
1. 为什么现在需要重新理解推理框架?
早期部署大模型,很多团队的目标很直接:
把模型加载到 GPU
提供 HTTP 接口
兼容 OpenAI API
支持流式输出
尽量提高吞吐
尽量降低延迟
这当然重要。
但 LLM 应用已经从"单轮聊天"进入更复杂的形态。
一个 RAG 应用可能会先改写问题,再召回文档,再对文档分块摘要,再做交叉验证,最后生成回答。
一个 Agent 应用可能会先判断任务类型,再选择工具,调用工具,读取结果,决定是否继续调用,最后总结。
一个企业助手可能每轮都携带很长的 system prompt、权限规则、输出规范、历史对话和用户上下文。
一个结构化输出系统则可能要求模型必须生成合法 JSON、函数参数、枚举字段或控制指令。
这些场景下,最贵的不一定是 decode。
很多时候,最浪费的是 repeated prefill:大量相同或相似的上下文被一遍遍送进模型重新计算。
SGLang 的切入点就是:复杂 LLM 工作流里存在大量可复用结构。
这些结构包括:
共同 system prompt
共享 few-shot 示例
固定 RAG 模板
多轮对话历史
工具调用格式
JSON schema
Agent 分支控制流
并行子任务
如果 runtime 能看见这些结构,就有机会缓存、复用、调度和约束。
2. SGLang 的两层:Frontend + Runtime
理解 SGLang,先不要把它只看成一个推理 server。
它有两层。
第一层是 frontend language。
它是一个 Python 内嵌式 DSL,用来表达更复杂的 LLM 程序。开发者可以描述生成、选择、分支、并行、多轮状态、结构化输出等逻辑。
第二层是 backend runtime。
它负责真正的高性能推理:KV Cache 管理、请求调度、批处理、前缀复用、结构化 decoding、量化、并行和分布式服务。
这就是 SGLang 和很多通用 serving 框架的关键差异。
普通推理服务更关心:
这个 prompt 怎么推理?
这个 batch 怎么拼?
这个模型怎么加载?
这个接口怎么兼容?
SGLang 进一步关心:
多个 prompt 是否共享前缀?
多轮调用能不能复用上下文?
JSON / function call 的约束能否高效执行?
Agent 程序里的分支能否被调度?
重复 prefill 能否避免?
它不是只把请求丢给模型,而是试图理解请求之间的结构关系。
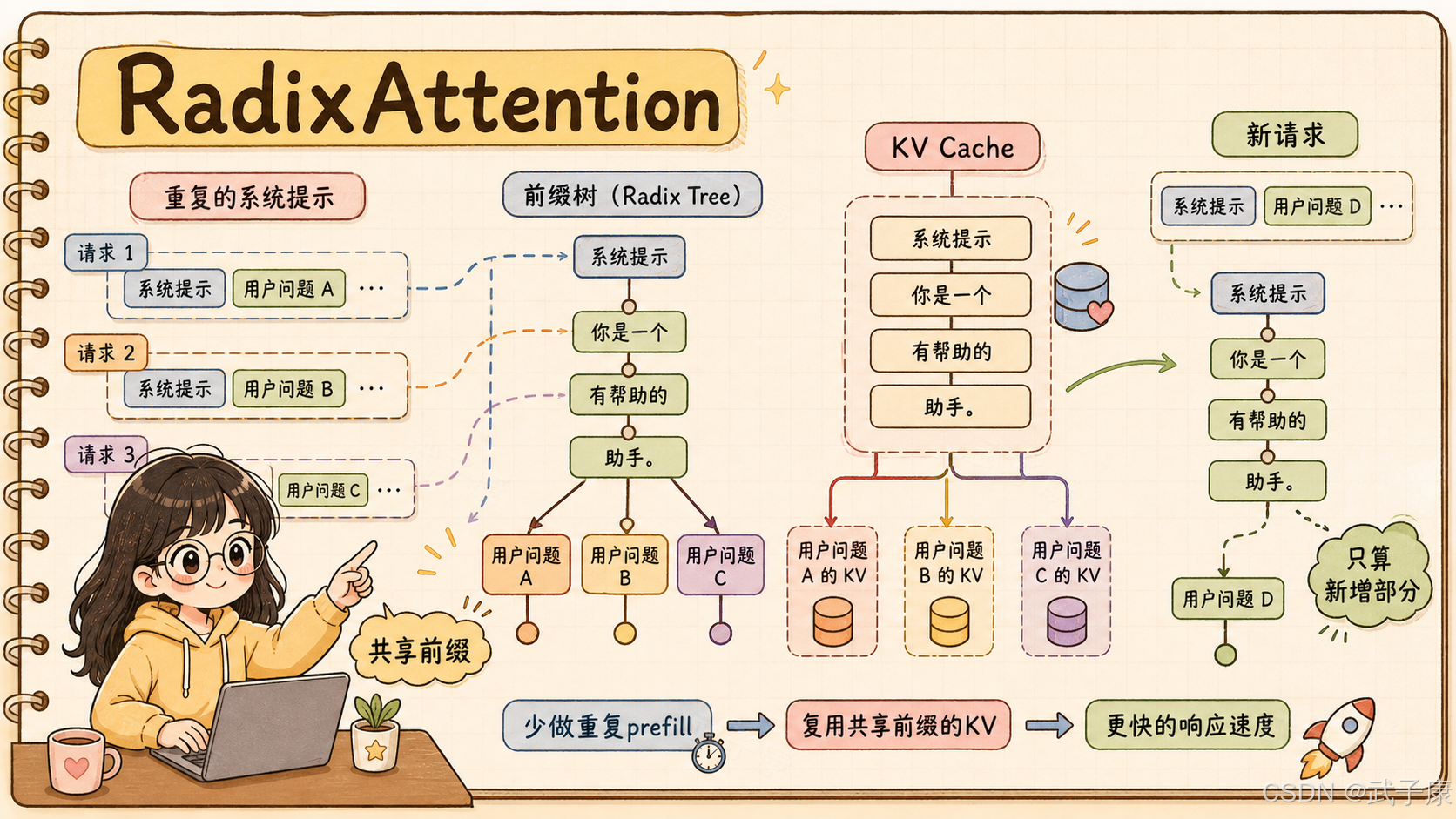
3. RadixAttention:把重复前缀变成可复用 KV Cache
SGLang 最有代表性的设计是 RadixAttention。
要理解它,先理解 KV Cache。
Transformer 生成文本时,每个 token 都会产生 Key / Value 状态。后续生成新 token 时,不需要重新计算前面所有 token,而是复用已有 KV Cache。
单个请求内部复用 KV Cache,是常规操作。
真正的问题是:多个请求之间,能不能复用?
比如企业客服场景里,大量请求可能共享同一个 system prompt:
你是一个专业客服助手。
必须遵守以下规则……
回答格式如下……
工具说明如下……
如果每个请求都重新 prefill 这一大段固定内容,GPU 会反复做重复计算。
再比如 RAG:
固定模板相同
引用格式相同
few-shot 示例相同
只在最后替换用户问题和召回文档
这类请求之间也存在大量公共前缀。
RadixAttention 的思路是把请求前缀组织成 radix tree,也就是压缩前缀树。相同前缀对应的 KV Cache 可以保留下来,并被后续请求复用。
直观理解:
普通做法:每个请求都从头读一遍教材
RadixAttention:已经读过的章节做成缓存
下次遇到相同章节,直接复用状态
只处理新增部分
这对固定 system prompt、few-shot、长上下文、多轮对话、RAG 模板和 Agent 共享上下文都很有价值。
注意,它不是简单的字符串缓存。
它缓存的是模型执行后的 KV 状态,节省的是 GPU prefill 计算。
4. 为什么 JSON 生成也是推理系统问题?
很多业务接入 LLM 后,第一反应是让模型输出 JSON:
{
"intent": "order_query",
"order_id": "12345",
"need_human": false
}
但生产环境里,只靠 prompt 说"请输出 JSON"通常不够。
模型可能多输出解释文本,可能漏字段,可能字段类型错误,可能枚举值不合法,也可能生成一个看起来像 JSON、实际上解析失败的字符串。
工程上更可靠的方式是 constrained decoding。
它在每一步 token 生成时,根据 schema、grammar 或状态机限制模型只能选择合法 token。
这能显著提高格式可靠性,但也会带来额外开销。
因为每生成一步,都要判断哪些 token 合法、哪些 token 不合法。
SGLang 从设计上把结构化输出视为 runtime 的一等能力,而不是 prompt 后处理插件。论文和官方资料中都强调了有限状态机、压缩状态机,以及后续与 XGrammar 等结构化输出能力相关的优化方向。
对 Agent 来说,这尤其关键。
Agent 不只是聊天,它经常要输出:
工具名称
工具参数
函数调用
数据库查询条件
机器人控制指令
多步骤计划
严格 JSON schema
如果结构化输出不稳定,后端系统就会塞满修补逻辑。
如果结构化输出太慢,实时交互体验又会下降。
所以 JSON 不是"小格式问题",而是推理 runtime 的稳定性和性能问题。
5. SGLang 和 vLLM:不是谁取代谁
很多人第一次听到 SGLang,会直接问:它和 vLLM 有什么区别?
可以粗略理解:
vLLM 更像通用高性能 LLM serving 基座。
SGLang 更像面向结构化 LLM 程序的推理执行引擎。
vLLM 的优势是成熟、通用、生态广、部署体验好,OpenAI API 兼容也很完善。对很多普通聊天、文本生成、统一模型服务场景来说,vLLM 仍然是非常稳妥的默认选择。
SGLang 的优势更容易出现在复杂 workflow:
长 system prompt
共享前缀
多轮上下文
RAG 模板
Agent 多步调用
工具调用 JSON
结构化输出
多分支并行
如果你的服务主要瓶颈是普通 decode 吞吐,迁移前要用真实 workload 压测,不能只看公开 benchmark。
如果你的瓶颈是重复 prefill、长上下文复用、结构化 decoding、Agent 多步调用,SGLang 的设计更贴近问题本身。
一句话:
不要问"SGLang 和 vLLM 谁更强"。
应该问"我的 workload 到底复杂在哪里"。
6. SGLang 和 TensorRT-LLM:层次不一样
TensorRT-LLM 更偏 NVIDIA 体系下的底层高性能优化框架。
它强调算子优化、图优化、量化、编译、硬件深度适配,适合追求极限性能并且有较强底层部署能力的团队。
SGLang 更偏生产推理服务框架和 runtime 系统。
它关注 OpenAI API 兼容、服务编排、前缀缓存、结构化输出、批处理、并行、量化和复杂 workflow。
可以粗略理解:
| 框架 | 更像什么 | 适合场景 |
|---|---|---|
| vLLM | 通用高性能 serving 基座 | 普通聊天、通用模型服务、快速自建 API |
| SGLang | 结构化 LLM 程序执行 runtime | RAG、Agent、多轮、JSON、前缀复用 |
| TensorRT-LLM | 底层硬件优化引擎 | NVIDIA 体系内极致性能、强工程团队 |
当然,现代推理框架的边界正在收敛。
continuous batching、paged attention、chunked prefill、speculative decoding、prefill-decode disaggregation、量化、并行推理,这些能力正在被不同框架不断吸收。
所以选型不能只看功能表。
要看你的模型、GPU、prompt 长度、并发、输出约束、部署团队和真实请求分布。

7. 什么场景最适合测试 SGLang?
我会优先在六类场景里测试 SGLang。
第一,RAG 问答系统。
RAG 通常有固定模板、固定引用格式、重复 prompt 结构。只要请求之间有共享前缀,RadixAttention 就可能带来 prefill 收益。
第二,多轮对话系统。
客服、企业助手、语音机器人都会带历史对话。上下文越长,重复计算越值得优化。
第三,Agent 工具调用。
Agent 需要多步决策、工具选择、参数生成、结果读取和继续推理。SGLang 的结构化程序表达和结构化输出更贴近这类任务。
第四,JSON / schema 强约束输出。
如果业务依赖稳定 JSON、函数参数、枚举字段和控制指令,SGLang 值得测。
第五,长 system prompt。
企业知识库助手、合规助手、代码审查助手、数据分析助手,常常带很长的角色说明、规则说明和输出规范。这些固定内容是前缀缓存的天然候选。
第六,高并发生产推理。
SGLang 支持连续批处理、分页注意力、并行策略、量化和分布式服务,已经不是只用于论文实验的工具。
但这并不意味着所有项目都应该迁移。
如果只是低频内部工具,部署复杂度比性能更重要,简单方案可能更合适。
如果只是普通聊天,没有长 prompt,没有 RAG,没有 Agent,没有结构化输出,SGLang 的优势未必明显。
8. 怎么评估 SGLang 是否适合你?
不要只看公开 benchmark。
公开 benchmark 往往不能代表你的业务。模型、GPU、驱动、batch、prompt 长度、并发、采样参数、输出长度都会影响结果。
更可靠的做法是构造自己的测试集。
至少关注这些指标:
TTFT
总响应时间
tokens/s
吞吐量
p50 / p95 / p99
GPU 显存占用
GPU 利用率
长 prompt prefill 延迟
多轮历史复用收益
JSON 输出合法率
结构化输出延迟
失败率
流式输出稳定性
测试集最好分三类:
普通聊天:验证基础 serving
长 system prompt + 多轮上下文:验证前缀复用
RAG / Agent / JSON schema:验证结构化 workflow
如果 SGLang 在普通聊天测试里没有明显优势,不代表它不行。
它的优势往往出现在复杂结构场景。
反过来,如果你的真实业务没有复杂结构,也没必要为了框架热度迁移。
9. 对 AI 语音机器人有什么意义?
对实时语音机器人来说,SGLang 尤其值得关注。
典型链路是:
VAD -> ASR -> LLM / Agent -> TTS -> 播放
LLM 不是孤立模块。
它还要处理角色设定、多轮历史、工具调用、设备控制、知识库查询、意图识别、结构化动作输出、打断后的状态恢复。
这类场景往往有大量固定内容:
机器人 persona
安全规则
输出规范
工具说明
动作 schema
对话历史模板
这些都是前缀缓存的候选。
而机器人控制指令又需要稳定结构化输出:
{
"action": "move_forward",
"speed": 0.3,
"duration": 2
}
这里不能只靠自然语言提示。
否则后端控制链路会很脆。
如果要在语音机器人里测试 SGLang,我会重点看:
固定 persona 是否降低 TTFT
工具调用 JSON 是否更稳定
多轮上下文是否减少重复 prefill
高并发语音请求下吞吐是否更稳
本地模型服务是否能替代部分云端调用
对实时语音链路来说,首 token 延迟通常比总吞吐更敏感。
所以必须用真实语音业务请求测试,而不是只看普通文本 benchmark。
10. 一句话结论
SGLang 的意义不是一句"比 vLLM 更快"。
更准确地说,它抓住了 LLM 应用工程化后的核心变化:
大模型推理不再只是单次 prompt 的推理。
它越来越像结构化语言模型程序的执行。
谁能理解结构,谁就能更好地缓存、调度、约束和加速。
这就是 SGLang 值得认真研究的原因。

错误速查卡
| 症状 | 根因 | 定位 | 修复 |
|---|---|---|---|
| 公开 benchmark 显示 SGLang 优势不明显 | 测试 workload 与生产 workload 不匹配(无共享前缀) | 用业务真实 prompt 复测,重点看 prefill 占比 | 重新设计压测集,加入长 system prompt / 多轮 / RAG 模板 |
| 迁移后 JSON 输出解析失败率高 | 仅靠 prompt 约束,未启用 constrained decoding | 检查是否启用 FSM / XGrammar | 改为结构化 decoding 模式,按 schema 生成 |
| 镜像拉取慢或超时 | GHCR 在国内无 CDN,跨海拉取瓶颈 | docker pull ghcr.io/lmsys/sglang:0.5.6 卡顿 |
改用国内镜像源,或先下载模型权重再本地构建 |
| 多轮对话首 token 越来越慢 | 历史上下文持续累积,命中前缀缓存但调度低效 | 监控 RadixAttention 命中率与 TTFT p95 | 启用 prefix cache + 限制最大历史长度 + 周期性压缩 |
| 高并发下 Python GIL 成为瓶颈 | SGLang router 为 Python 实现 | 在 L4/g2-standard-32 等中等规模机器上做 150 并发压测 | 启用 sgl-router Rust 版本(sgl-model-gateway)或调整部署规模 |
| Agent 工具调用格式不稳定 | 模型自由生成 tool call 字段 | 解析日志查看 function name / 参数错误率 | 引入 JSON schema constrained decoding |
| v0.5.x 升级到新版 DeepSeek V4 出现 garbled text | 单 token decode 在 B200 上异常 | 复现 v0.5.12 之前版本 + DSV4-Pro | 升级到 v0.5.13+ 稳定性补丁(已 cherry-pick 12 个修复) |
| 浮点输出与原始模型不一致(如 GSM8K 准确率下降) | HiSparse + SGLANG_OPT_USE_COMPRESSOR_V2=1 引入 | 关闭 V2 压测 | 升级修复版本(已恢复 GSM8K 准确率 0.825→0.960) |
作者:武子康的个人博客

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐



 9
9 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)