模型初始化常用参数设置
·
模型初始化参数
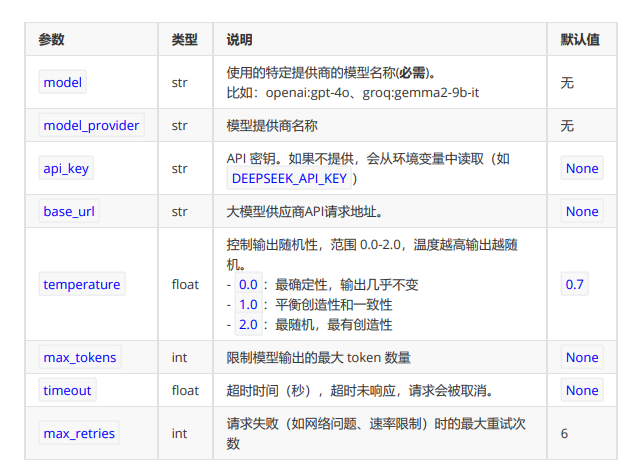
在LangChain中,Model Class 和init_chat_model初始化模型共同的参数及解释。
API参考文档:
https://docs.langchain.org.cn/oss/python/langchain/models#parameters
temperature 参数使用场景选择:
0.0-0.3:需要一致性、准确性的任务(数学计算、数据提取、分类、代码生成)
0.5-0.7:平衡创造性和一致性(聊天、问答)
0.8-1.5:创造性任务(写作、头脑风暴)
1.5-2.0:高度创造性(诗歌、故事创作)

.env文件
#从DeepSeek官网获取的配置信息
DEEPSEEK_API_KEY =sk-31c9440dxxxxxfb91eeec513XXXXX
DEEPSEEK_BASE_URL=https://api.deepseek.com
temperature 参数练习
代码如下
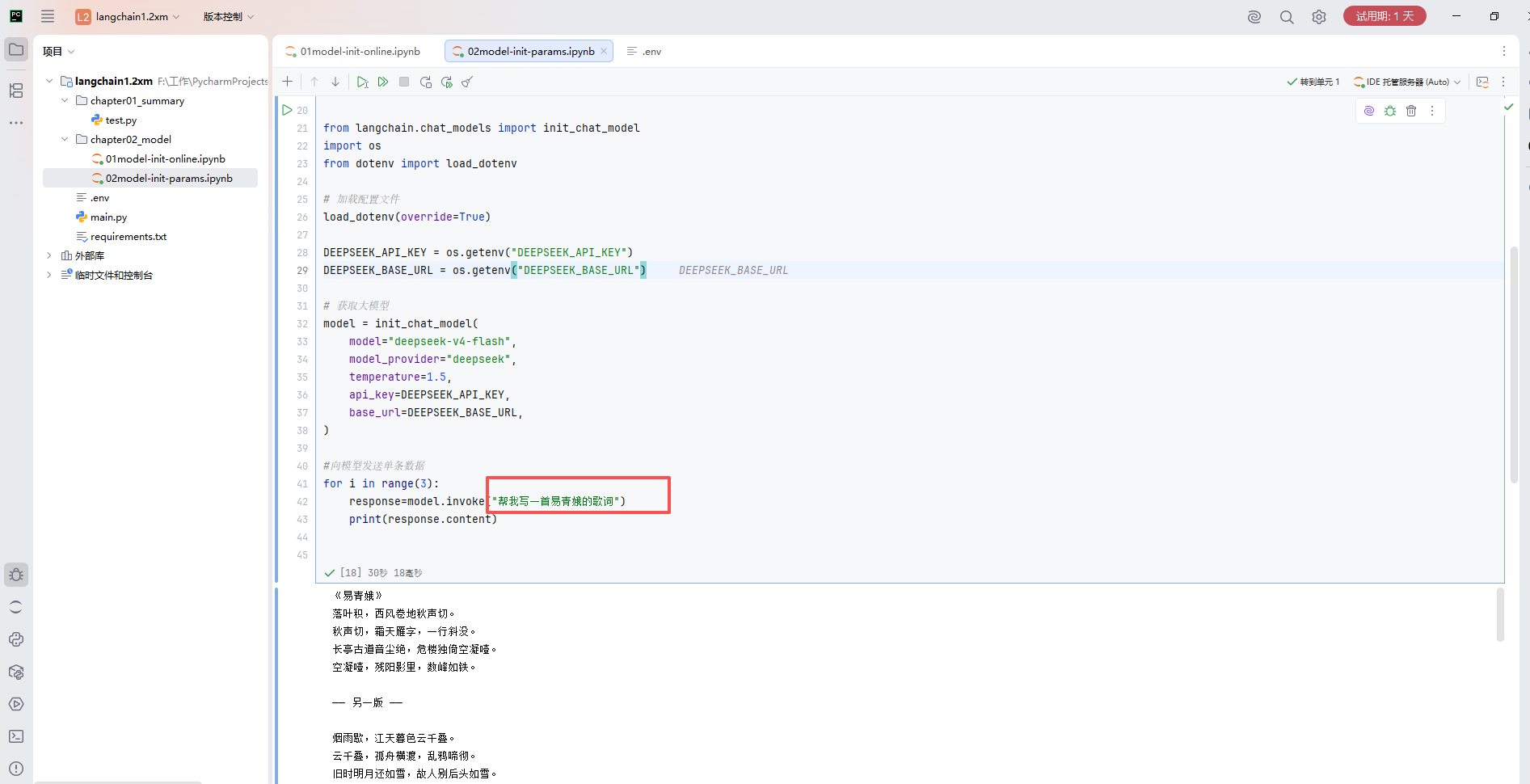
# 模型初始化的参数使用情况
# temperature
# 在langChain中, Model Class和init_chat_model初始化模型共同的参数和解释
# API文档:https://docs.langchain.org.cn/oss/python/langchain/models#parameters
# model :使用的特定提供商的模型名称(必需)。比如:openai:gpt-4o、groq:gemma2-9b-it
# model_provider:模型提供商名称
# api_key :API 密钥。如果不提供,会从环境变量中读取(如DEEPSEEK_API_KEY )
# base_url :大模型供应商API请求地址。
# temperature : 控制输出随机性,范围 0.0-2.0,温度越高输出越随机。- 0.0 :最确定性,输出几乎不 - 1.0 :平衡创造性和一致性- 2.0 :最随机,最有创造性
# max_tokens: 限制模型输出的最大 token 数量
# timeout :float 超时时间(秒),超时未响应,请求会被取消。
# max_retries:请求失败(如网络问题、速率限制)时的最大重试次数
# temperature 参数根据使用场景选择:
# 0.0-0.3:需要一致性、准确性的任务(数学计算、数据提取、分类、代码生成)
# 0.5-0.7:平衡创造性和一致性(聊天、问答)
# 0.8-1.5:创造性任务(写作、头脑风暴)
# 1.5-2.0:高度创造性(诗歌、故事创作)
from langchain.chat_models import init_chat_model
import os
from dotenv import load_dotenv
# 加载配置文件
load_dotenv(override=True)
DEEPSEEK_API_KEY = os.getenv("DEEPSEEK_API_KEY")
DEEPSEEK_BASE_URL = os.getenv("DEEPSEEK_BASE_URL")
# 获取大模型
model = init_chat_model(
model="deepseek-v4-flash",
model_provider="deepseek",
temperature=1.5,
api_key=DEEPSEEK_API_KEY,
base_url=DEEPSEEK_BASE_URL,
)
#向模型发送单条数据
for i in range(3):
response=model.invoke("帮我写一首易青娥的歌词")
print(response.content)
max_tokens 参数练习
Token是什么?
基本单位 : 大模型通过分词器(Tokenizer)将文本拆分后的最小语义单元是token(相当于自然语言中
的词或字)。不同的模型采用不同的 分词算法 (如BPE、WordPiece),因此同一段文本在不同模型中
的Token数量可能不同。
收费依据 :大语言模型通常也是以token的数量作为其计量(或收费)的依据。
1个中文Token≈1-1.8个汉字,1个英文Token≈3-4个字符
Token与字符转化的可视化工具:
OpenAI提供:https://platform.openai.com/tokenizer
百度智能云提供:https://console.bce.baidu.com/support/#/tokenizer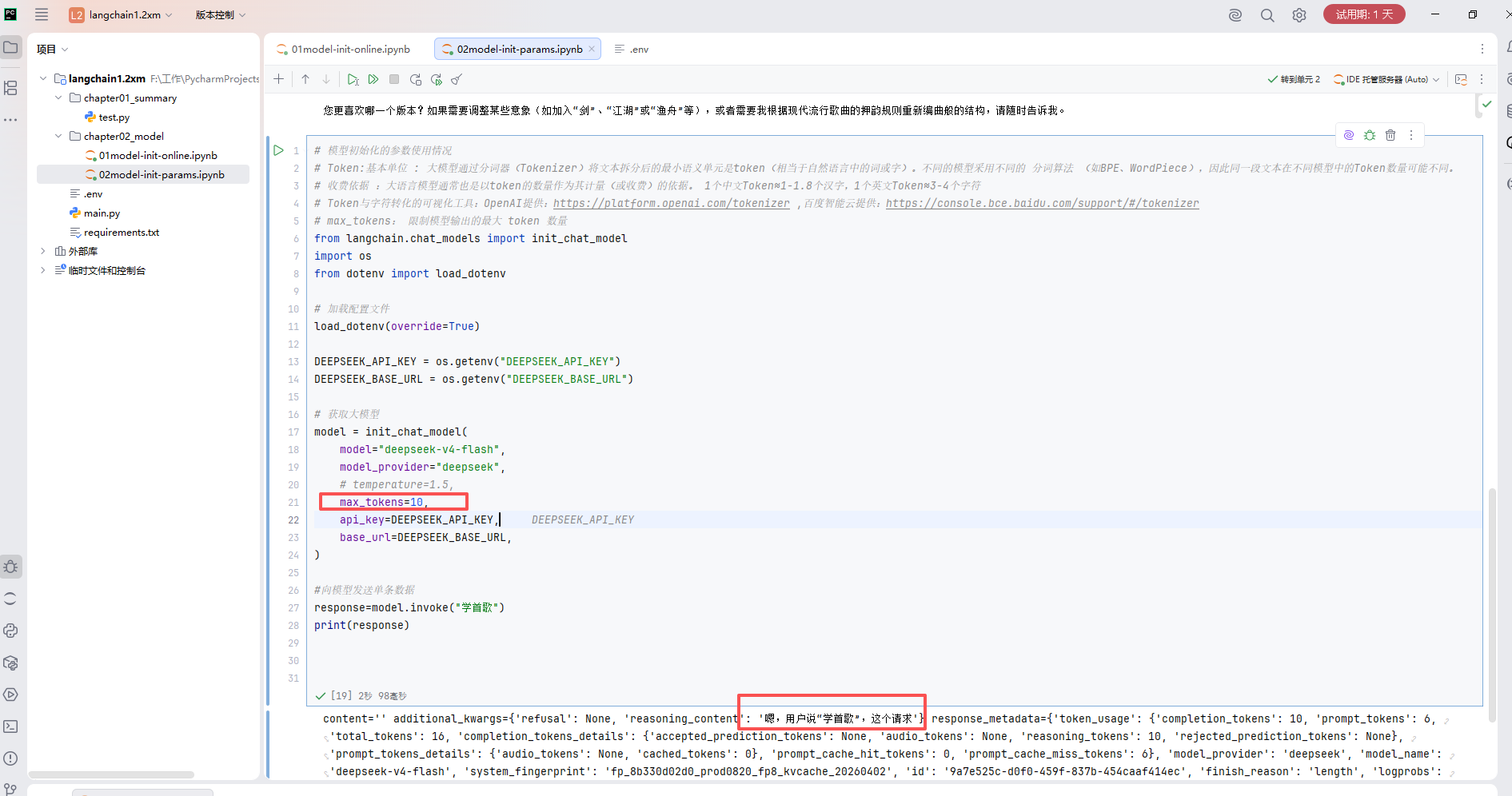
代码如下
# 模型初始化的参数使用情况
# Token:基本单位 : 大模型通过分词器(Tokenizer)将文本拆分后的最小语义单元是token(相当于自然语言中的词或字)。不同的模型采用不同的 分词算法 (如BPE、WordPiece),因此同一段文本在不同模型中的Token数量可能不同。
# 收费依据 :大语言模型通常也是以token的数量作为其计量(或收费)的依据。 1个中文Token≈1-1.8个汉字,1个英文Token≈3-4个字符
# Token与字符转化的可视化工具:OpenAI提供:https://platform.openai.com/tokenizer ,百度智能云提供:https://console.bce.baidu.com/support/#/tokenizer
# max_tokens: 限制模型输出的最大 token 数量
from langchain.chat_models import init_chat_model
import os
from dotenv import load_dotenv
# 加载配置文件
load_dotenv(override=True)
DEEPSEEK_API_KEY = os.getenv("DEEPSEEK_API_KEY")
DEEPSEEK_BASE_URL = os.getenv("DEEPSEEK_BASE_URL")
# 获取大模型
model = init_chat_model(
model="deepseek-v4-flash",
model_provider="deepseek",
# temperature=1.5,
max_tokens=10,
api_key=DEEPSEEK_API_KEY,
base_url=DEEPSEEK_BASE_URL,
)
#向模型发送单条数据
response=model.invoke("学首歌")
print(response)

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐

 2
2 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)