基于 Trae + DeepSeek 的 Vibe Coding 实践指南(四):SpringBoot + 阿里云视觉的视频字幕提取系统全栈落地
目录


前言
大家好啊,我是云泽Q,欢迎阅读我的文章,一名热爱计算机技术的在校大学生,喜欢在课余时间做一些计算机技术的总结性文章,希望我的文章能为你解答困惑~
该篇主要是做整个项目重构和前端制作~
一、搞懂开发根基:前端、后端到底怎么分工?
接下来就要搭建前端并连接前后端了,在开始之前要先知道前端和后端都是干什么的,不然连基础分工都搞不懂,自然写不出精准AI指令
1.1 前端:只管“好看、展示”
我们肉眼能看到的一切,全部属于前端:网页页面、HTML界面、手机APP画面、按钮样式、字体排版。
它的核心工作只有一件事:把内容展示给用户,不负责数据校验、不负责逻辑运算。
举个最简单的登录例子:我们在APP输入账号密码、点击登录按钮,这个页面、输入框、按钮全是前端;前端只负责收集我们输入的信息,本身不会校验账号密码对错。
1.2 后端:负责“干活、算数”
后端也叫服务器开发,所有业务代码全部存放在云端服务器,肉眼看不见、摸不着,我们之前所写的代码都属于后端。
承接全部核心工作:账号密码校验、数据计算、业务规则判定、接口调度。依旧拿登录举例:前端把账号密码传给后端,后端比对数据库信息,判定对错,再把「登录成功/失败」结果传回前端,最后由前端弹窗展示结果。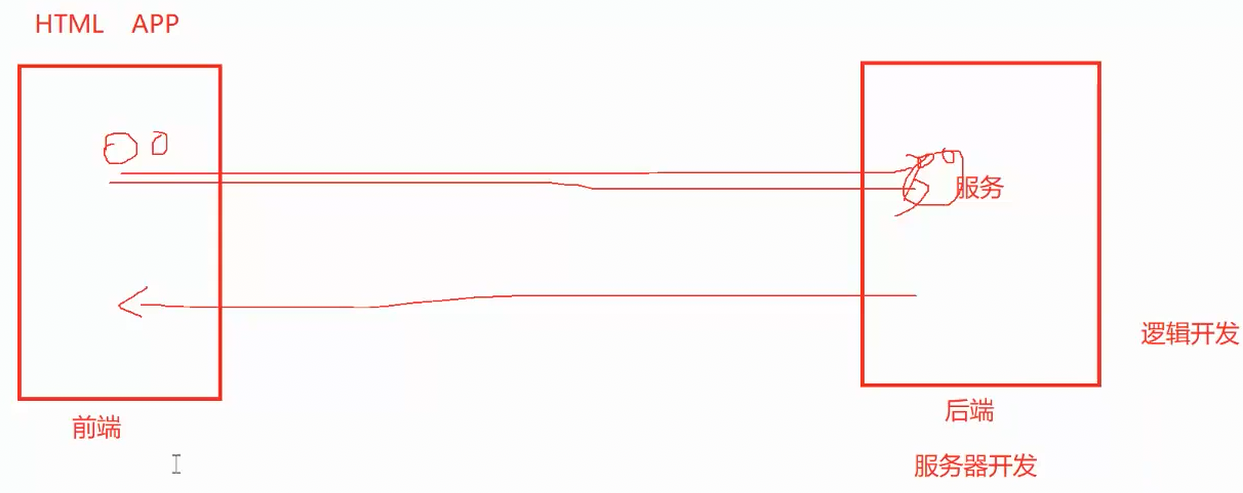
前端要把用户输入的账号密码传给后端是要通过调用后端上的某一个服务来实现
1.3 为什么前端更容易被AI替代?
行业现状直白来说:前端入门门槛低、业务逻辑简单,核心工作只是美化页面、适配样式,没有复杂业务逻辑,也是目前AI适配度最高、最先被替代的开发岗位。
而后端牵扯业务规则、数据安全、服务联动,逻辑错综复杂,AI很难独立吃透,也是目前开发行业更吃香、更保值的方向。
我们搭建Spring Boot后端项目,本质目的不是炫技术,而是统一前后端对接规则,我们现在的项目相当于服务器都没有搭好,就是因为在这个Spring Boot架构底下,前端会在指定的文件夹底下,按照指定的方式去找对应的服务,让前端能精准找到后端服务,避免对接错乱,所以我们的难点就在后端服务怎么改
二、后端代码编写
现在都说用AI辅助编码,但绝大多数人效率极低,问题从来不在AI,而是在使用者自身,比如说我们现在就利用AI改后端服务
2.1 不懂技术的人问问题
把这个代码看怎么样整理一下?(😂)
看到这类指令AI也会懵逼,它再聪明,都接受不了含糊不清的指令
这类指令完全是无效指令,AI无法判定代码适配Spring Boot还是Python架构、代码存放路径、编码规范、输出格式。再强大的AI,面对模糊需求也只能胡乱输出代码,最后返工整改,白白浪费时间。
2.2 稍微知道一点的
这个文件当中的代码是阿里云官方的示例代码,认真读取当前代码的含义。理解完成后把当前代码进行合理的归类和整理为springboot的后端项目。
归类按照springboot项目的结构划分,比如应该在service文件夹下的放到service下,应该在controller下的放到controller,应该是常量的代码,按照常量的方式进行划分,后端也增加slf4j作为日志的部分。日志路径保存在当前项目的根目录:logs/app.log可以抽离为配置的放在config的文件目录下。遵循REST API接口的约定
总体目标是:方便后续工程化管理。
所有代码注释使用中文,方便维护。
但是这个看起来很专业的话术也不一定能做好,因为你也不懂controller这些东西到底是什么,可能需要来回沟通好多次才会成功
2.3 有成熟经验的开发者
# 阿里云示例代码重构为 Spring Boot 项目
## 任务目标
将提供的阿里云官方示例代码,在 test 包下的 RecognizeVideoCastCrewList 类和 GetAsyncJobResult 类进行整合,转换为一个结构清晰、便于工程化管理的 Spring Boot 后端项目。
目前 RecognizeVideoCastCrewList 类中的执行结果:
System.out.println (com.aliyun.teautil.Common.toJSONString (TeaModel.buildMap (response)));
中,包含一个 RequestId。
因为是异步调用,这个 RequestId 的值,将会在 GetAsyncJobResult 类中使用到。会传给 setJobId 方法,作为参数。GetAsyncJobResult 类的调用结果打印出来之后为:
System.out.println (com.aliyun.teautil.Common.toJSONString (TeaModel.buildMap (getAsyncJobResu
ltResponse))); 需要把最终这个打印结果以 Json 形式返回给前端,前端会解析这个数据。
## 具体要求
### 1. 代码结构划分
按照 Spring Boot 标准项目结构进行组织:
- **Controller 层**:处理 HTTP 请求的代码放入 `controller` 包下
- **Service 层**:业务逻辑代码放入 `service` 包下(如有必要,可进一步分为 `service.impl`)
- **常量类**:常量定义集中放入 `constant` 包下
- **配置类**:可抽离的配置(如 Bean 定义、属性加载等)放入 `config` 包下
- **其他**:根据实际情况可能需要 `model`(实体/DTO)、`utils`(工具类)等,按 Spring Boot 惯例放置
### 2. 日志记录
- 使用 **SLF4J** 作为日志门面,具体实现推荐 **Logback**
- 日志配置文件(如 `logback-spring.xml`)放置在 `src/main/resources` 下
- 日志输出路径:项目根目录下的 `logs/app.log`
- 建议按日期或大小滚动,保留适当历史
- 控制台输出可保留用于开发环境
### 3. 注释规范
- 所有代码注释使用**中文**,便于团队维护
- 关键类、方法、字段一定要添加清晰的功能说明及必要的参数/返回值注释
### 4. 工程化管理目标
- 代码层次分明,职责单一
- 配置外部化(使用 `application.properties`)
- 遵循 Spring Boot 约定,便于后续集成测试、部署与扩展
- 遵循 REST API接口的约定
## 交付成果
请输出完整的项目代码结构,包含:
- 按上述包结构组织的 Java 文件
- 配置文件(日志配置、应用配置等)
- 如有必要,提供 `pom.xml` 依赖说明
- 不要修改RecognizeVideoCastCrewList 类和 GetAsyncJobResult 类,只需重新生成其他类即可
- 先不着急写代码,先分析和理解我的问题。
> 注意:请先认真阅读并理解原始阿里云示例代码的功能与逻辑,再进行重构。
这是一个有经验的大佬写的提示词,但是其是可以复用的,就算在座的你写不出来也没有关系,可以让AI来帮助写这个提示词
前提就是这已经是一个完整的springboot项目了,你找一个这样的专业人员完成的完整springboot项目,然后让AI倒推根据当前完整的项目写一个提示词,然后把提示词拿出来只改任务目标部分,看清楚有哪些类,哪些ID,把这些内容进行改动就可以了,下面的部分完全不用动
这样vibeCoding的模式就出来了,我们可以先用没那么精准的沟通方式让AI做项目,经过一些时间之后项目做出来了,可以回过头来让它把整个项目精炼出专业的提示词。以便下次复用,只要是springboot项目,都可以引用我上面的提示词
所以归根结底Vibe Coding本质是自然语言没有问题,但并不是真的大白话,不存在不懂技术就可以靠大白话做项目的说法,这是一定要有一定技术基础才可以玩起来的东西,就像图示代码必须要理解每一个代码文件最终返回了什么,又需要什么
接下来我就把这段提示词复制,进入Trae点击新建任务,把提示词放入输入框扔给AI让它先做
等代码写好之后,就会生成一份配置文件,每次配置一些信息的时候直接在配置文件配置即可,不需要去每一份代码里都做改动了,我依旧一键进行代码审查,代码就不看了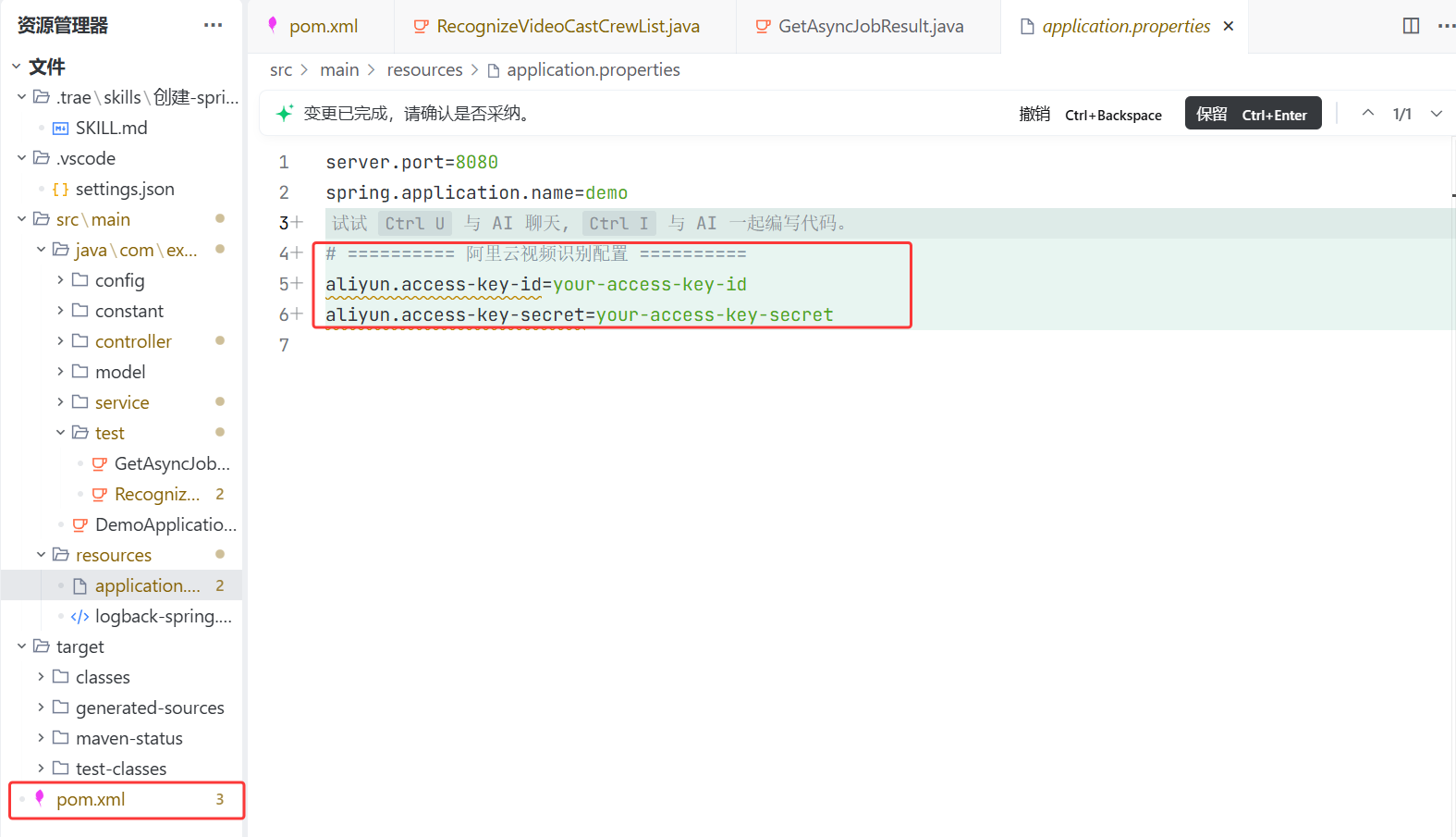
接下来把要填的信息填入这个配置文件,接下来我们把前端界面写出来再运行项目
三、前端代码编写
3.1 提示词编写
## 目标要求
1.上传本地的单个视频的功能
2.上传之后点击按钮进行视频解析
3.解析完成后,后端会把阿里云生成的异步调用后的响应结果以 JSON 的形式返回。
4.前端必须先熟悉后端返回的 JSON 结构,然后才能更正确的解析这个 JSON 文件
5.字段 subtitlesChineseResultsUrl 和 subtitlesEnglishResultsUrl 在返回 JSON 的 body.Data.Result 中,这是一个 JSON 字符串,需要先解析它。解析后的结构是 {subtitlesResults: [ {subtitlesChineseResultsUrl, subtitlesEnglishResultsUrl} ] },具体路径是 body.Data.Result.subtitlesResults [0].subtitlesChineseResultsUrl 和 body.Data.Result.subtitlesResults [0].subtitlesEnglishResultsUrl,对应的分别是中文字幕识别对应的标准 SRT 格式文件下载地址和英文字幕识别对应的标准 SRT 格式文件下载地址。这 2 个都是链接,这 2 个链接可以显示在页面上,用户点击下载按钮就可以下载对应的字幕文件,文件格式为 SRT 格式。
其它情况
1.为了更好的打通前后端的交互,必要情况下可以修改后端的代码
2.前后端做好统一响应,可以利用ResponseEntity处理。
3.前端采用 HTML+CSS+JavaScript 的技术栈,页面一定要美观,因为你是专业的前端
4.需要在控制台输出的同时,前端页面也要展示后端返回给前端的响应数据。方便用户校验。
有兄弟看到这就懵逼了,因为写前端还需要前面第二篇文章所提到的该界面的各种参数的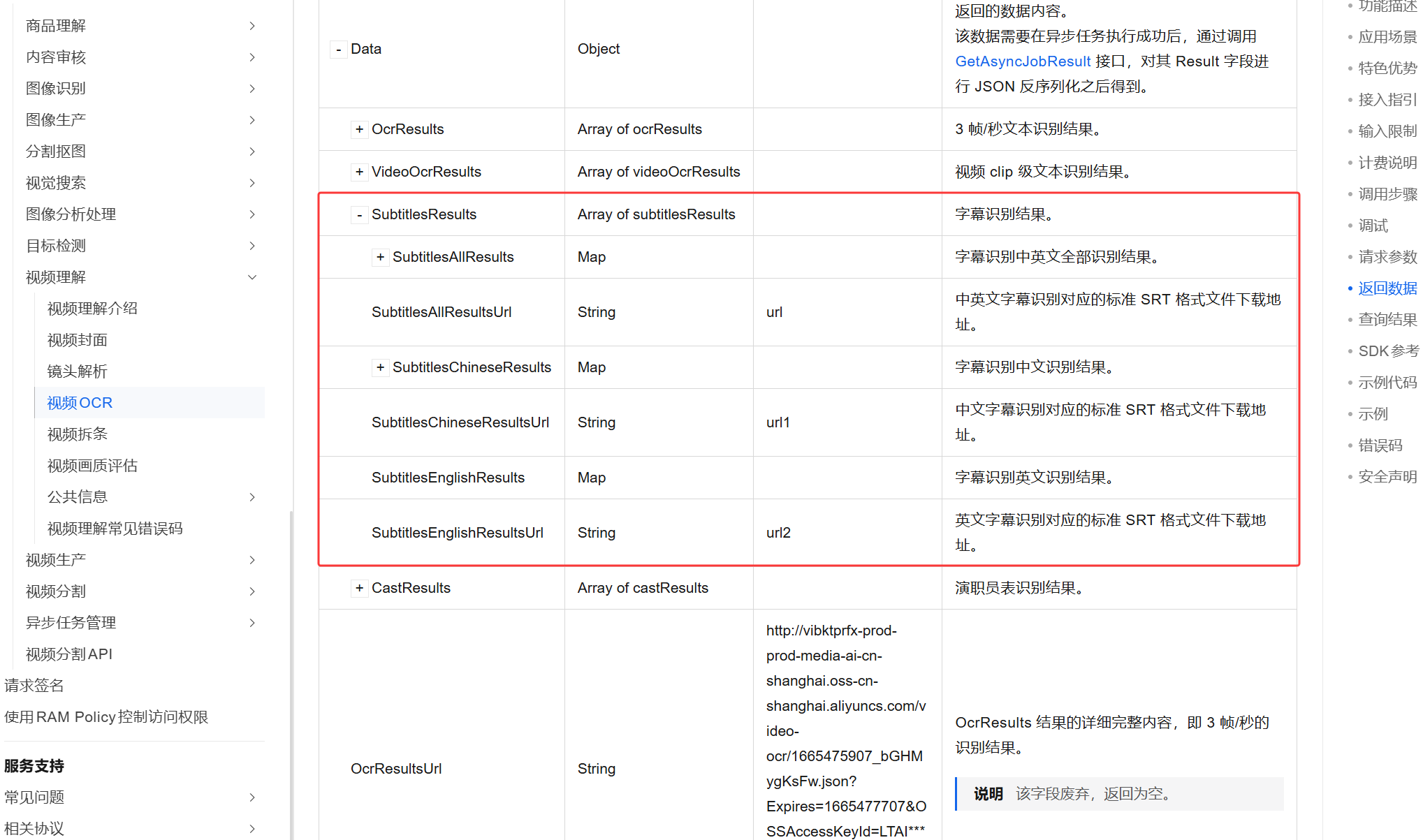
我们最终要解析的数据就是这些返回数据,有兄弟说这个解析后的结构后面一大堆东西我不会描述,没有关系。根据我的实测,你甚至不需要说字段,因为AI很擅长写前端,你只需要告诉他你的目标要求,然后告诉他你要解析的数据是subtitlesChineseResultsUrl和subtitlesEnglishResultsUrl里面的数据就可,它也是可以完成的,我这里之所以写的很详细是因为第二篇文章的最后Java Run在终端输出结果了,我们也可以把那个结果复制出来,然后告诉AI我想描述一下我要哪两个字段,让它帮准确你描述一下,此时它就会告诉你怎么描述,然后把它描述的东西拿出来就可以放到提示词里面了
但是这一步始终都要看清楚返回结果的包含结构,甚至于我们可以把图片中的所有内容都展开,截一个图发给AI,告诉它前端要哪两个字段(subtitlesChineseResultsUrl和subtitlesEnglishResultsUrl,中文字幕和英文字幕),让它帮你用大白话描述一下也是可以的,这也就是这部分写前端的唯一的难点了
然后接着把提示词复制,新建一个任务发给AI,让它去写前端就好了,同样的中间出现什么问题都可以把报错信息发给他,让它自己解决
现在AI做完了,我们可以看到文件现在最大允许上传的大小是500MB,这个是可以自己改的
打开它所给的网址可以看出这个前端页面做的也还可以,我们从浏览器打开把示例视频拖拽进去给它,让它解析一下看看具体效果如何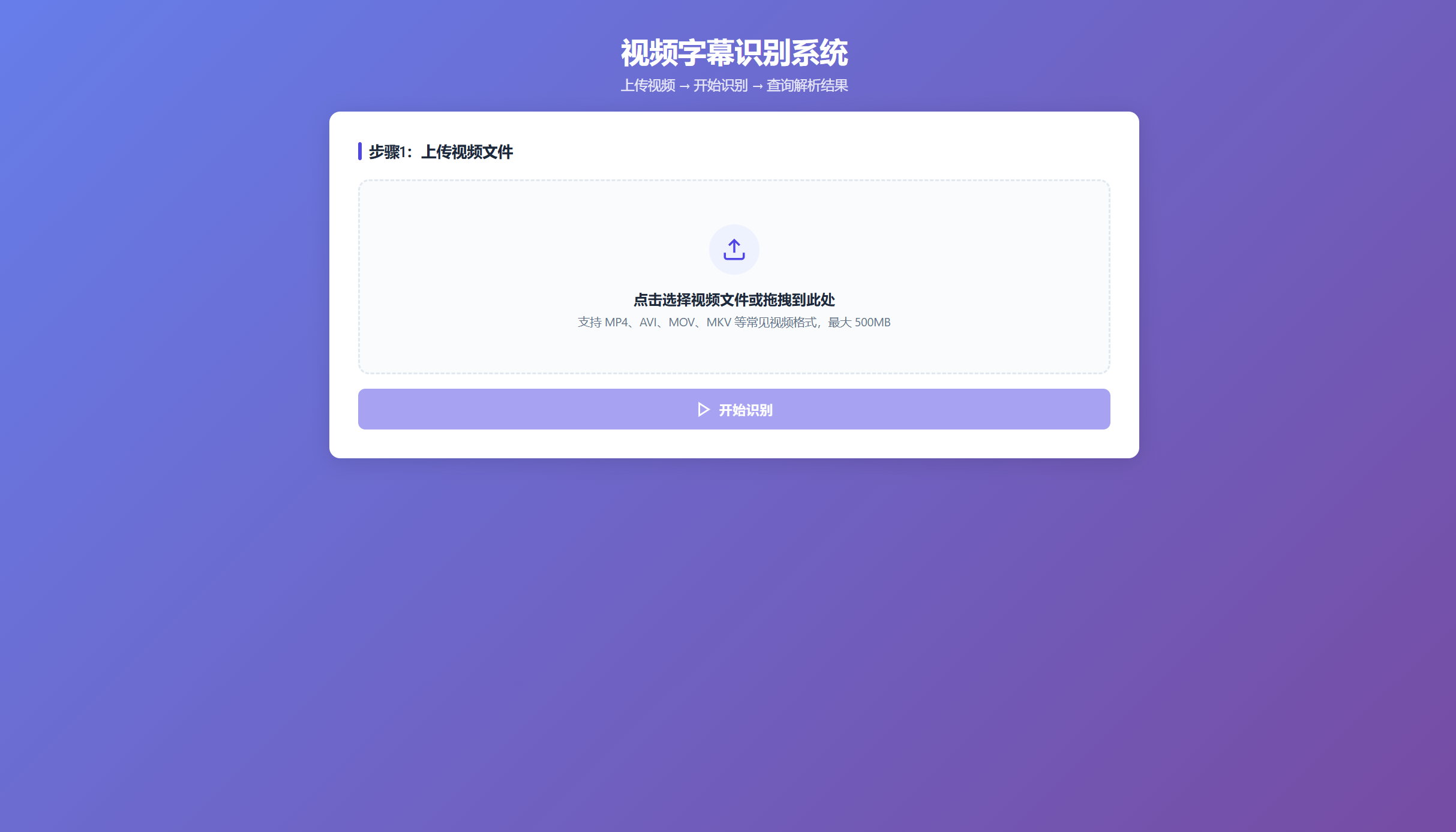
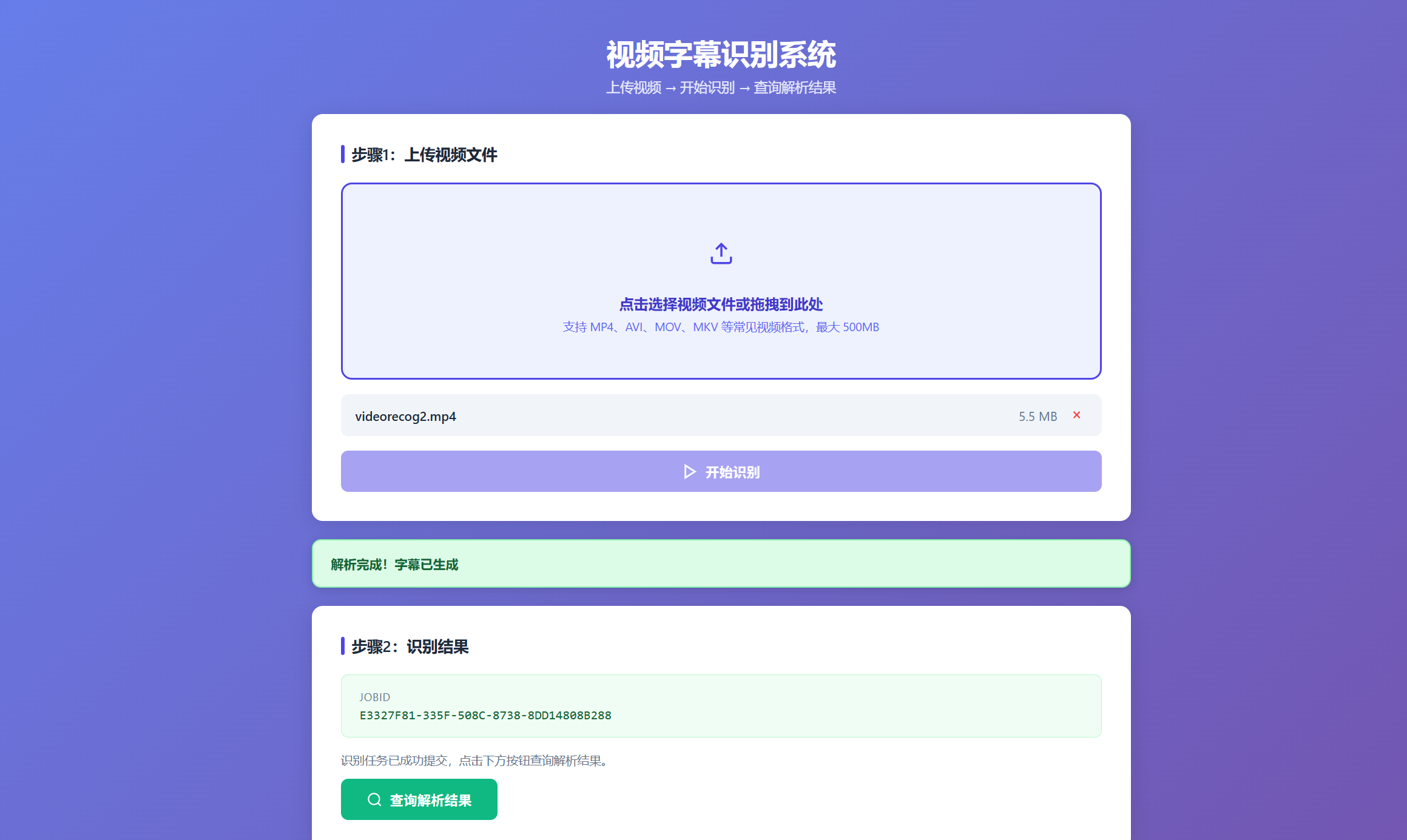
下面的**后端响应数据 (JSON)**就是后端返回给前端的所有内容,这个折叠显示组件是我自己让AI做的,大家都一样,有好的想法都可以让AI实现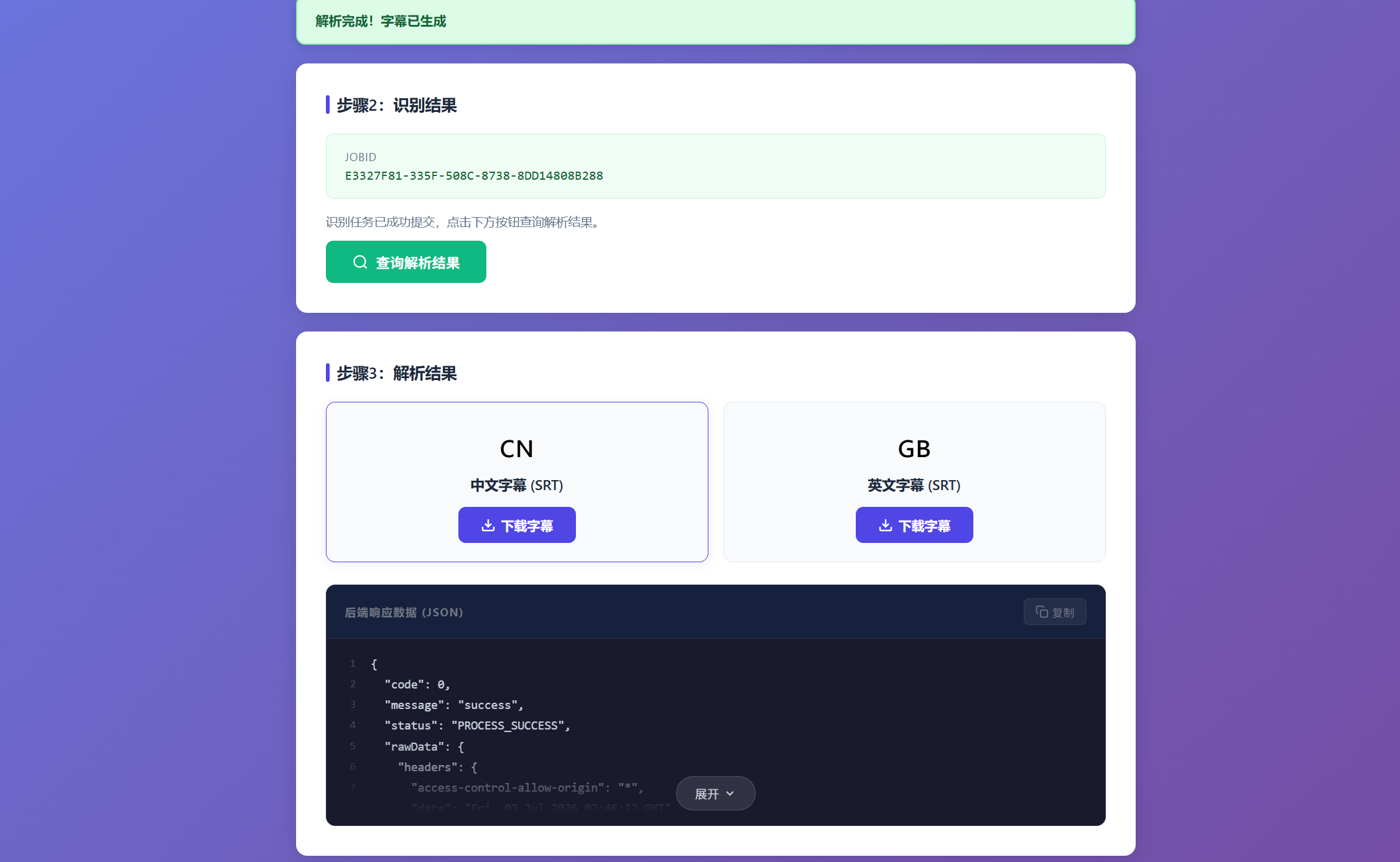
也可以反过头来把这些内容全部复制扔给AI,为AI解析图中所框选的字段怎么解析,用大白话描述,这些内容在第二篇文章搭建后端的时候也打印过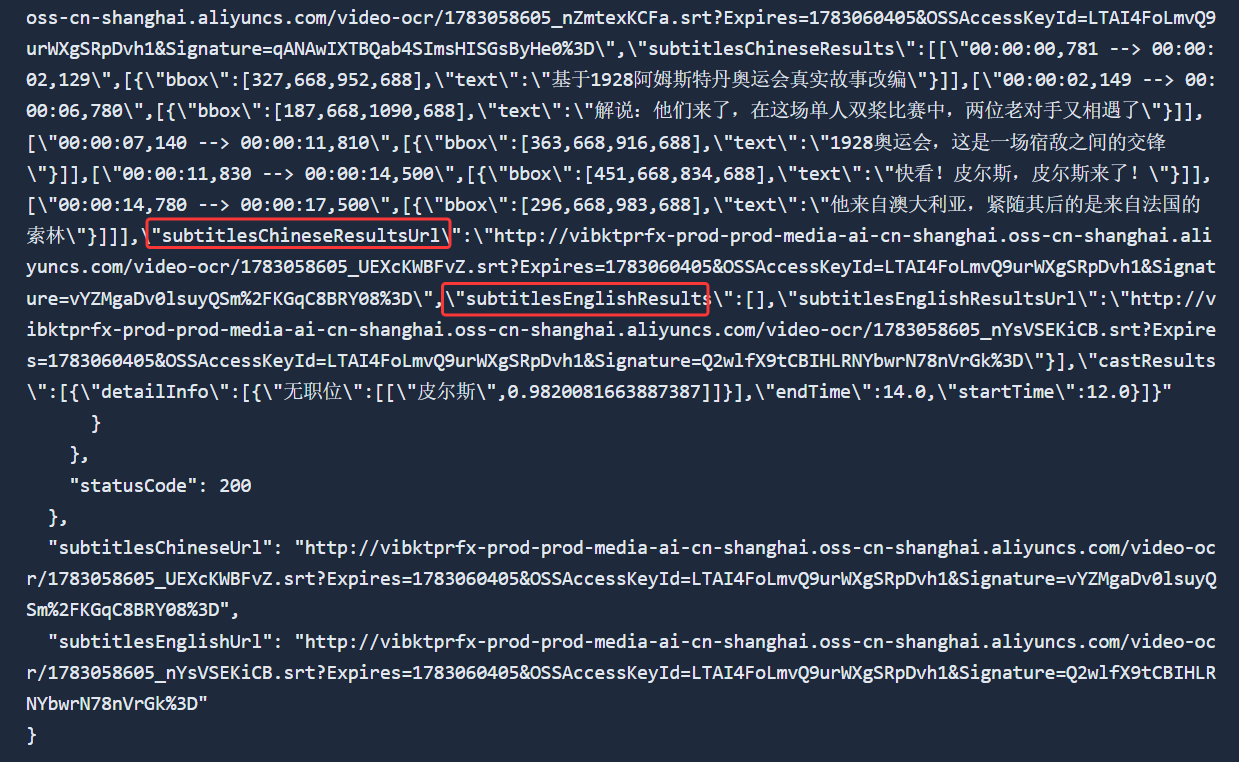
补充一个点:如果你的项目做的有问题,而AI只修改了前端,修改之后项目是不需要重新启动的,刷新一下网页就可以了
这样整个视频字幕提取的项目就全部OK了,如果你觉得这个界面不好看,也可以把自己的想法告诉它来改,但是!想必都听说过AI幻觉这个词,也就是如果你的描述模糊不清,它就会擅作主张改你的代码,这其中就会有改错的可能,所以如果你后续想和AI交互的时候,就可以这样说
当前项目没有任何问题,按当前界面的功能也没问题,现在不改变当前前端的任何功能的情况下,只修改页面的美观性。前提:你是一个专业的前端工程师,美学师
四、前后端测试
netstat -ano | findstr ":8080"
taskkill /F /PID 50164
这里补充一个端口被占用问题的解决办法,不过这一块是需要懂技术的,所以我把办法摆在这里,可以看懂的就懂了,看不懂也没关系,还是那句话,出问题了把报错信息扔给AI,让它自己解决
结语


中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐


 18
18 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)