从 0 吃透 Transformer:大模型背后的核心结构,一篇讲清
如果你这两年学 AI,一定绕不开一个词:Transformer。
ChatGPT、Claude、Gemini、BERT、T5、机器翻译、代码助手、文档摘要、图文理解,背后都能看到 Transformer 的影子。
很多人第一次学 Transformer,会被这些词劝退:
- • Self-Attention
- • Multi-Head Attention
- • Positional Encoding
- • Encoder / Decoder
- • Q、K、V
- • Mask
- • Feed Forward
- • LayerNorm
看起来像一锅术语汤。
但如果用一句话概括 Transformer,它其实很直观:
Transformer 的核心能力,是让每个词主动去“看”句子里的其他词,并判断谁对当前词最重要。
这篇文章不硬啃论文,而是从入门视角把 Transformer 的结构、逻辑、代码和应用场景讲清楚。看完你至少能回答三个问题:
-
- Transformer 为什么能理解上下文?
-
- Self-Attention 到底在算什么?
-
- 为什么现在的大模型基本都离不开 Transformer?
一、为什么 RNN 不够用了?
在 Transformer 出现前,自然语言处理常用 RNN、LSTM、GRU。
它们处理句子的方式像“从左到右读书”:
我 → 喜欢 → 机器 → 学习
这种方式有两个问题。
第一,慢。
因为它必须按顺序处理,前一个词算完,后一个词才能继续。句子越长,越难并行。
第二,长距离依赖难。
比如这句话:
那本我昨天在图书馆借到的人工智能教材,非常适合入门。
“那本”和“教材”隔得很远,但它们关系很强。传统序列模型要一层层传递信息,中间容易丢。
Transformer 换了一种思路:
不按顺序慢慢传,而是让每个词直接和所有词建立联系。
这就是 Self-Attention 的思想。
二、Transformer 总结构:先看全局图
原始 Transformer 是 Encoder-Decoder 结构,最早用于机器翻译。
可以简单理解为:
- • Encoder:负责理解输入;
- • Decoder:负责生成输出;
- • Attention:负责找重点、建立词与词之间的关系。
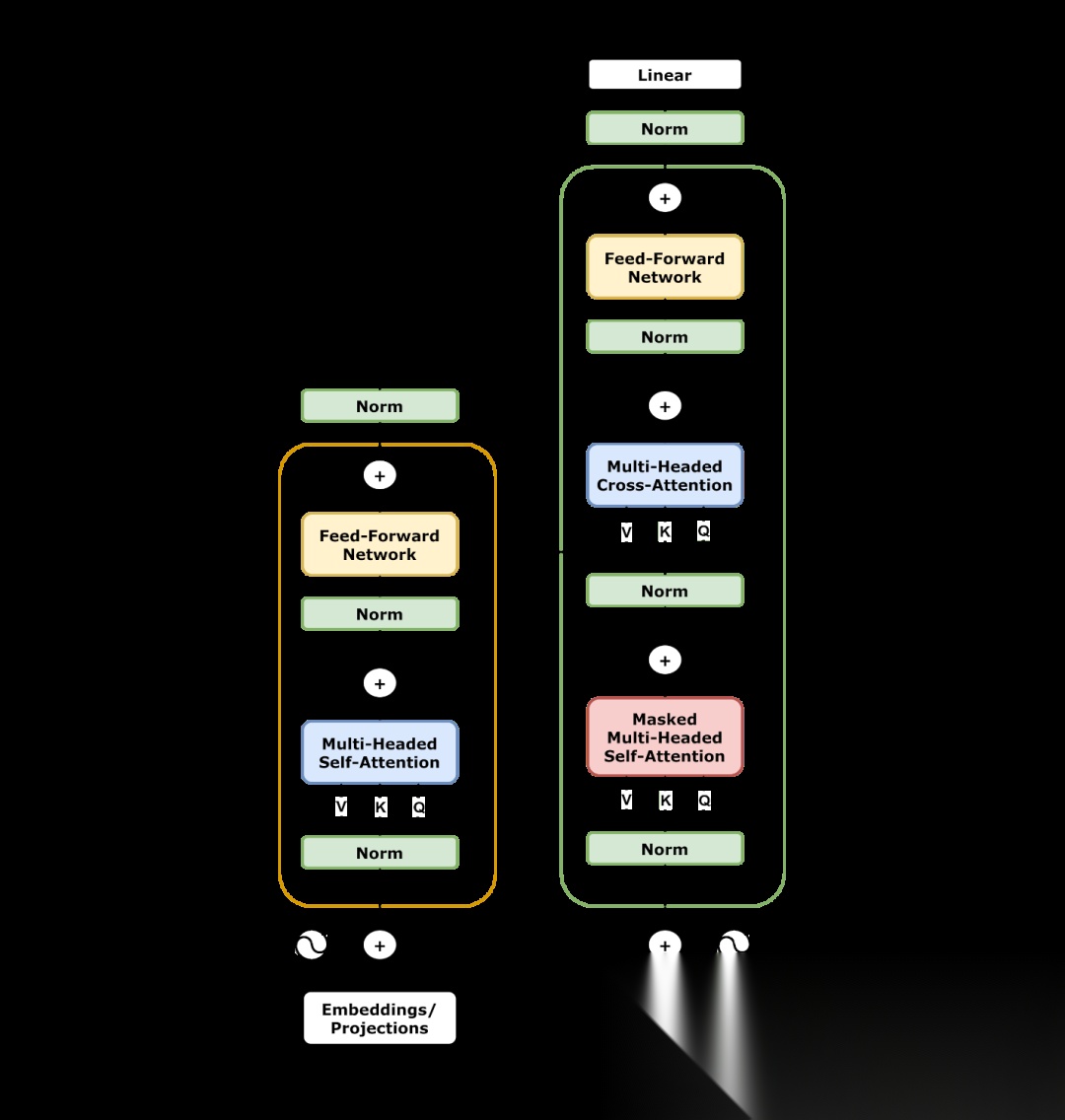
Transformer 完整结构图
上图来自 Wikimedia Commons,是 Transformer 全结构示意图。它比简化图更接近原始论文里的 Encoder-Decoder 思路:左边是 Encoder,右边是 Decoder,中间通过 Attention 连接。
完整结构看起来复杂,但主线并不难:
-
- 文本先被切成 token;
-
- token 转成向量;
-
- 加上位置编码;
-
- 经过多层 Attention 和前馈网络;
-
- 得到上下文表示;
-
- Decoder 根据上下文一步步生成输出。
如果是翻译任务:
输入:我喜欢机器学习输出:I like machine learning
Encoder 先理解中文句子,Decoder 再生成英文句子。
三、Token 是什么?模型不是直接读汉字
模型不能直接理解“我喜欢机器学习”这几个字。
它会先通过 Tokenizer 切分文本:
我 喜欢 机器 学习
或者在真实大模型里,可能切成更细的片段:
我 喜欢 机器 学 习
每个 token 会被映射成一个向量。
import torchimport torch.nn as nnvocab_size = 10000embed_dim = 128embedding = nn.Embedding(vocab_size, embed_dim)token_ids = torch.tensor([[12, 305, 88, 901]])x = embedding(token_ids)print(x.shape)
输出形状:
torch.Size([1, 4, 128])
含义是:
| 维度 | 含义 |
|---|---|
1 |
batch size |
4 |
token 数量 |
128 |
每个 token 的向量维度 |
这一步之后,文本就变成了模型能处理的数字矩阵。
四、为什么需要位置编码?
Self-Attention 本身不天然知道顺序。
对它来说:
我 喜欢 机器 学习
和
学习 机器 喜欢 我
如果没有位置信息,可能只是同一堆 token 的排列。
所以 Transformer 要加入位置编码,让模型知道每个词在句子里的位置。
直觉上,最终输入模型的是:
token 向量 + 位置向量
代码里可以这样理解:
import torchimport torch.nn as nnmax_len = 512embed_dim = 128token_embedding = nn.Embedding(10000, embed_dim)position_embedding = nn.Embedding(max_len, embed_dim)token_ids = torch.tensor([[12, 305, 88, 901]])positions = torch.arange(0, token_ids.size(1)).unsqueeze(0)x = token_embedding(token_ids) + position_embedding(positions)print(x.shape)
这样模型既知道“这个词是什么”,也知道“这个词在第几个位置”。
五、Self-Attention:Transformer 的灵魂
Self-Attention 的核心问题是:
当前这个词,应该重点关注句子里的哪些词?
比如:
我 喜欢 机器 学习
当模型处理“喜欢”时,它可能会关注:
- • “我”:谁喜欢?
- • “机器 学习”:喜欢什么?
这不是靠规则写死的,而是模型自己学出来的。
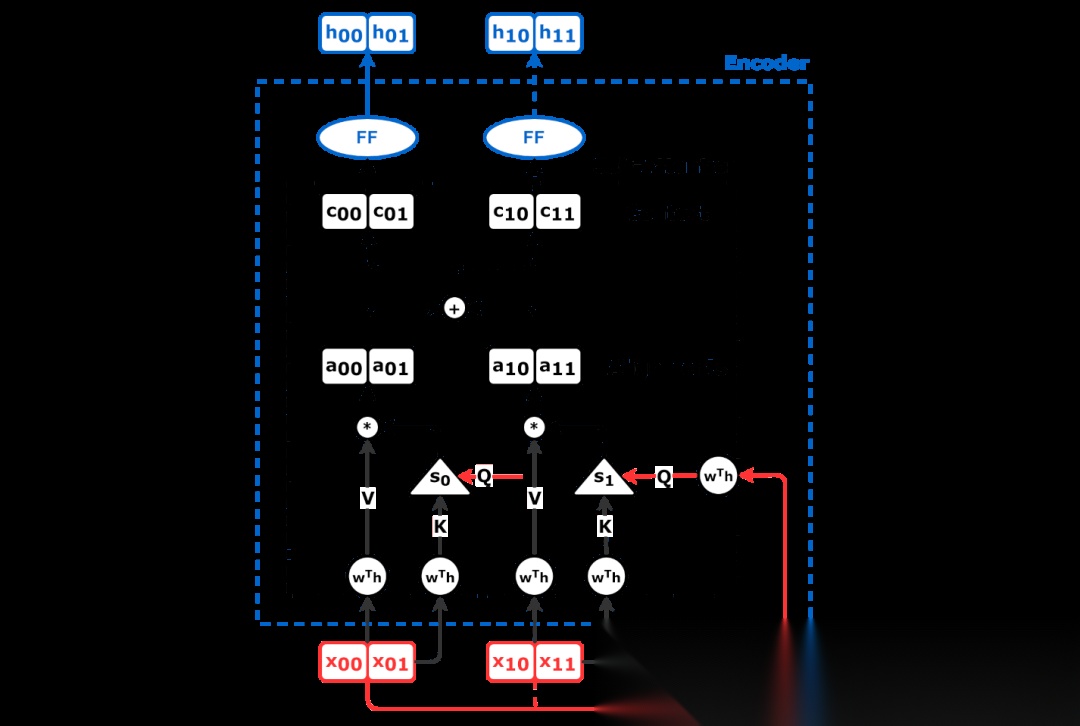
Self-Attention 详细机制图
这张图展示了 Encoder Self-Attention 的细节:输入 token 会被映射成 Query、Key、Value,然后通过注意力权重汇总上下文信息。
Self-Attention 会给每个词分配注意力权重。权重越高,说明当前词越应该关注它。
六、Q、K、V 到底是什么?
这是 Transformer 入门最容易卡住的地方。
可以用查资料来类比:
- • Q = Query,当前词想问什么;
- • K = Key,每个词能提供什么线索;
- • V = Value,每个词真正携带的信息。
计算逻辑:
-
- 当前词拿着 Q 去和所有词的 K 做匹配;
-
- 匹配分数越高,说明越相关;
-
- 对分数做 softmax,变成权重;
-
- 用权重加权求和所有 V;
-
- 得到当前词的新表示。
公式长这样:
Attention(Q, K, V) = softmax(QK^T / sqrt(d_k)) V
看着吓人,其实就是:
相关性打分 → 归一化成权重 → 加权求和
七、用 PyTorch 手写一个迷你 Self-Attention
先看最小版本,不考虑多头。
import torchimport torch.nn as nnimport torch.nn.functional as Fclass SelfAttention(nn.Module): def __init__(self, embed_dim): super().__init__() self.q_proj = nn.Linear(embed_dim, embed_dim) self.k_proj = nn.Linear(embed_dim, embed_dim) self.v_proj = nn.Linear(embed_dim, embed_dim) def forward(self, x): # x: [batch, seq_len, embed_dim] Q = self.q_proj(x) K = self.k_proj(x) V = self.v_proj(x) d_k = Q.size(-1) scores = torch.matmul(Q, K.transpose(-2, -1)) / (d_k ** 0.5) weights = F.softmax(scores, dim=-1) output = torch.matmul(weights, V) return output, weightsx = torch.randn(2, 4, 128)attn = SelfAttention(embed_dim=128)output, weights = attn(x)print("output:", output.shape)print("weights:", weights.shape)
输出:
output: torch.Size([2, 4, 128])weights: torch.Size([2, 4, 4])
weights 的形状是 [batch, seq_len, seq_len]。
如果句子有 4 个 token,每个 token 都会对 4 个 token 分配注意力权重。
八、Multi-Head Attention:为什么要多头?
单头 Attention 只从一个角度看句子。
但语言关系很复杂:
- • 有的头可能关注主语和谓语;
- • 有的头可能关注修饰关系;
- • 有的头可能关注指代关系;
- • 有的头可能关注句子边界。
Multi-Head Attention 就是让模型从多个角度同时看。
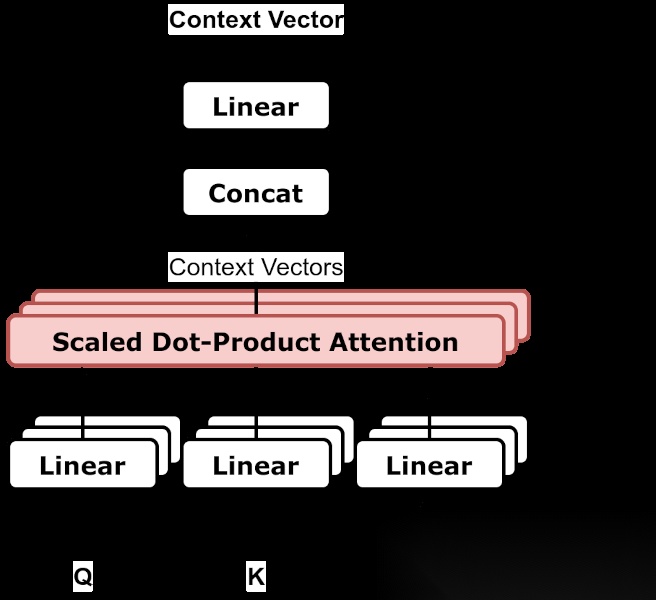
Multi-Head Attention 结构图
直觉上:
一个专家看语法一个专家看语义一个专家看位置一个专家看指代最后把多个专家的结果合并
PyTorch 里可以直接用:
import torchimport torch.nn as nnembed_dim = 128num_heads = 8mha = nn.MultiheadAttention( embed_dim=embed_dim, num_heads=num_heads, batch_first=True)x = torch.randn(2, 10, 128)out, attn_weights = mha(x, x, x)print(out.shape)print(attn_weights.shape)
这里 mha(x, x, x) 的三个 x 分别对应 Q、K、V。
在 Self-Attention 里,Q、K、V 都来自同一段输入。
九、Feed Forward:Attention 后还要再加工
Attention 负责让 token 之间交换信息。
但每个 token 自身的特征还需要进一步变换,这就靠 Feed Forward Network。
它通常是两层全连接网络:
class FeedForward(nn.Module): def __init__(self, embed_dim, hidden_dim): super().__init__() self.net = nn.Sequential( nn.Linear(embed_dim, hidden_dim), nn.GELU(), nn.Linear(hidden_dim, embed_dim) ) def forward(self, x): return self.net(x)
Transformer Block 可以简化成:
输入 → Multi-Head Attention → Add & Norm → Feed Forward → Add & Norm → 输出
十、Add & Norm 是干什么的?
Transformer 很深,如果每层都直接变换,训练容易不稳定。
所以它用了两个技巧:
-
- 残差连接:保留原始输入;
-
- LayerNorm:稳定每层输出分布。
简化代码:
class TransformerBlock(nn.Module): def __init__(self, embed_dim, num_heads, hidden_dim): super().__init__() self.attn = nn.MultiheadAttention( embed_dim=embed_dim, num_heads=num_heads, batch_first=True ) self.norm1 = nn.LayerNorm(embed_dim) self.ffn = FeedForward(embed_dim, hidden_dim) self.norm2 = nn.LayerNorm(embed_dim) def forward(self, x): attn_out, _ = self.attn(x, x, x) x = self.norm1(x + attn_out) ffn_out = self.ffn(x) x = self.norm2(x + ffn_out) return x
这就是一个非常简化的 Encoder Block。
十一、Encoder-only、Decoder-only、Encoder-Decoder 有什么区别?
Transformer 不一定都长成原始论文那样。
现在常见模型大概分三类:
Transformer 完整结构图:Encoder 与 Decoder 的关系
这张完整结构图也可以用来理解三类模型的差异:Encoder-only 主要保留左侧理解部分;Decoder-only 主要使用右侧自回归生成部分;Encoder-Decoder 则同时使用两边。
1. Encoder-only:适合理解
代表模型:BERT 类模型。
特点:
- • 能同时看上下文;
- • 适合做文本分类、信息抽取、句子匹配;
- • 不适合直接长文本生成。
典型任务:
输入:这条评论情绪是正面还是负面?输出:正面
2. Decoder-only:适合生成
代表模型:GPT 类模型。
特点:
- • 按从左到右的方式生成;
- • 每次预测下一个 token;
- • 非常适合聊天、写作、代码生成。
典型任务:
输入:帮我写一段 Python 数据清洗代码输出:import pandas as pd ...
3. Encoder-Decoder:适合理解后生成
代表模型:T5、原始 Transformer 翻译模型。
特点:
- • Encoder 理解输入;
- • Decoder 生成输出;
- • 适合翻译、摘要、问答生成。
典型任务:
输入:一篇长文章输出:一段摘要
十二、Mask:为什么生成模型不能偷看答案?
Decoder-only 模型训练时,会学习预测下一个 token。
比如:
我 喜欢 机器 学习
当模型预测“机器”时,它只能看到:
我 喜欢
不能提前看到:
学习
否则就是作弊。
所以 Decoder 里要用 Masked Self-Attention,把未来位置遮住。
简单理解:
第1个词:只能看第1个词第2个词:只能看第1、2个词第3个词:只能看第1、2、3个词
这也是 GPT 类模型能一个 token 一个 token 往后写的原因。
十三、训练和推理:模型到底怎么学会说话?
很多人以为模型是“背答案”,其实更准确地说:
大语言模型在训练时学的是:给定前文,预测下一个 token。
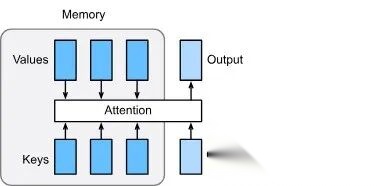
注意力机制总览
这张注意力机制图来自 Dive into Deep Learning 项目,它把“查询 Query 如何从键值对 Key-Value 中取信息”的过程画得更抽象,也更接近 Attention 的通用定义。
训练阶段:
输入:我 喜欢 机器目标:学习
模型预测一个概率分布:
学习:0.62视觉:0.08翻译:0.03...
如果正确答案是“学习”,模型就会被奖励;如果预测偏了,就通过反向传播调整参数。
推理阶段:
-
- 用户输入 prompt;
-
- 模型预测下一个 token;
-
- 把新 token 拼回输入;
-
- 再预测下一个;
-
- 一直循环,直到结束。
这就是“生成”的底层逻辑。
十四、Transformer 的应用场景
Transformer 最开始用于机器翻译,但现在已经扩展到很多领域。
下面这些图是从网上下载的真实应用素材,不再使用生成图。它们分别对应智能问答、机器翻译、代码生成和视觉 Transformer 场景。
Chatbot Arena 聊天机器人界面
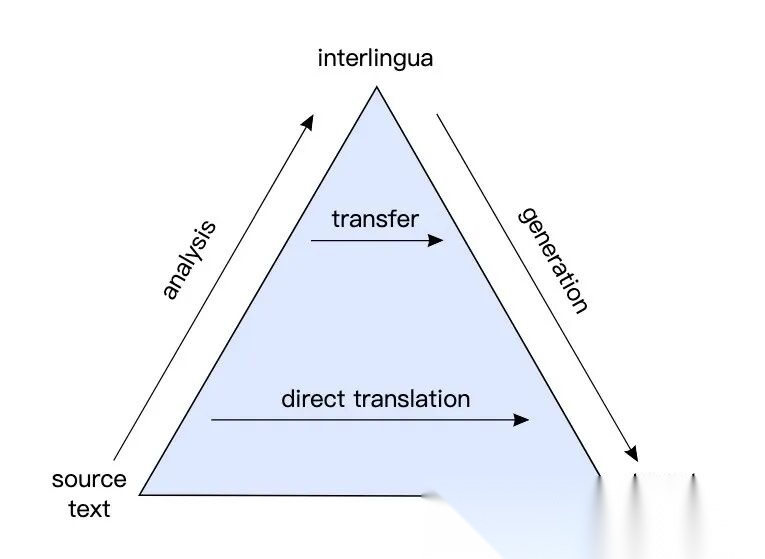
机器翻译中的 Vauquois Triangle 示意图

代码生成与编程辅助场景

Vision Transformer 图像理解示意
1. 智能问答
用户输入问题,模型理解上下文,生成回答。
比如:
请解释一下什么是过拟合,并举一个例子。
模型需要理解“过拟合”的概念,还要组织语言输出。
2. 机器翻译
Transformer 最早的爆发点就是翻译。
它能把源语言编码成语义表示,再生成目标语言。
中文:我正在学习机器学习英文:I am learning machine learning
3. 代码生成
代码助手本质上也是序列生成。
输入:写一个函数,统计列表中每个元素出现次数输出:def count_items(items): ...
模型不仅要懂自然语言,还要懂代码语法和常见 API。
4. 文档摘要
长文档输入模型后,模型提取重点,再生成短摘要。
这类任务常见于:
- • 会议纪要;
- • 法律文档;
- • 论文阅读;
- • 公众号长文总结;
- • 企业知识库。
5. 图文理解
现在很多多模态模型也大量借鉴 Transformer。
图片会被切成 patch,像文本 token 一样送入模型。
图片 patch → 向量序列 → Attention 建模关系
所以 Transformer 不只处理文字,也能处理图像、音频、视频等序列化数据。
6. 搜索和推荐
搜索推荐里也常用 Transformer 做语义匹配。
比如:
用户搜索:适合新手的 Python 数据分析教程
模型要理解这个 query 的语义,再匹配最相关的内容。
十五、一个迷你文本分类模型:Transformer 入门代码
下面用 PyTorch 写一个非常简化的文本分类模型。
它不是大模型,但能帮你理解 Transformer 如何接任务。
import torchimport torch.nn as nnclass MiniTransformerClassifier(nn.Module): def __init__(self, vocab_size, embed_dim, num_heads, hidden_dim, num_classes, max_len=128): super().__init__() self.token_emb = nn.Embedding(vocab_size, embed_dim) self.pos_emb = nn.Embedding(max_len, embed_dim) self.block = TransformerBlock( embed_dim=embed_dim, num_heads=num_heads, hidden_dim=hidden_dim ) self.classifier = nn.Linear(embed_dim, num_classes) def forward(self, token_ids): batch_size, seq_len = token_ids.shape positions = torch.arange(seq_len, device=token_ids.device).unsqueeze(0) x = self.token_emb(token_ids) + self.pos_emb(positions) x = self.block(x) cls_vector = x[:, 0, :] logits = self.classifier(cls_vector) return logitsmodel = MiniTransformerClassifier( vocab_size=10000, embed_dim=128, num_heads=8, hidden_dim=256, num_classes=2)token_ids = torch.randint(0, 10000, (4, 32))logits = model(token_ids)print(logits.shape)
输出:
torch.Size([4, 2])
这表示 batch 里有 4 条文本,每条输出 2 个类别的分数。
十六、Transformer 为什么这么强?
总结下来,有 4 个关键原因。
1. 能并行
RNN 要按顺序读,Transformer 可以同时处理所有 token。
这让它更适合大规模训练。
2. 能建模长距离关系
Self-Attention 让任意两个 token 可以直接建立联系。
远距离依赖不再需要一步步传递。
3. 可扩展性强
堆更多层、更多参数、更大数据,Transformer 往往还能继续变强。
这也是大模型能发展起来的重要原因。
4. 任务迁移能力强
同一套结构可以迁移到:
- • 文本;
- • 图像;
- • 音频;
- • 视频;
- • 代码;
- • 多模态任务。
这让 Transformer 成了 AI 里的通用架构。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐


 0
0 0
0- 0



 已为社区贡献434条内容
已为社区贡献434条内容

所有评论(0)