双非如何快速入职字节等大厂大模型?真实案例分析:推理优化和投机解码
一般学校如何快速入职字节等大厂?什么是推理优化和投机解码?

大厂招人的逻辑,其实并不是"你必须多优秀",而是需求导向——你正好做我急需的方向,简历筛选、面试流程都会显著加速。
我身边就有一位非 985/211 学校的同学,去年秋招拿到了字节的 SP offer。靠的不是项目堆量、不是发顶会,而是踩对了一个正在爆发的方向:LLM 推理优化。她毕业设计专门研究了一个叫 投机解码(Speculative Decoding) 的技术,面试时几乎所有的技术问题都在她的舒适区里。
这篇文章想讲清楚两件事:
- 这个方向现在为什么这么缺人?
- "投机解码"到底是什么?(本文不含公式,下一篇会展开原理与最新研究方向)
适合人群:想冲大厂、特别是有自研大模型公司(字节、阿里、腾讯、DeepSeek、Moonshot、智谱、百川等)的同学。
一、为什么 LLM 推理优化是 2025-2026 年的人才洼地?
简单一句话:大模型训出来了,但用起来太贵,大家都在抢能把成本打下来的人。
几个具体数据感受一下:
1. 推理成本是大厂的核心账单。 启明创投合伙人周志峰在公开采访中提到,大模型每百万 token 调用成本,从 2023 年的约 120 美元(人民币 800 元)降到 2024 年不到 1 元人民币,下降了 99.9%,未来还可能再降 99.9% [1]。这个"降下去的成本",正是推理优化工程师做出来的。

2. 字节豆包等团队公开发布的技术报告显示:UltraMem 架构相比 MoE 推理成本最高降低 83%,速度提升 2-6 倍 [2];COMET 训练优化让训练成本节省 40% [3]。这些都是"工程优化"性质的成果,不是算法突破——背后是大量推理团队的招聘需求。
3. 行业薪酬与人才缺口。 麦肯锡报告预测,到 2030 年中国 AI 人才需求 600 万,市场供给约 200 万,缺口 400 万 [4]。脉脉等求职平台数据显示,AI 岗位平均薪资显著高于普通后端岗位,资深大模型工程师年薪百万的案例并不少见 [4]。
4. 开源生态成熟。 vLLM 已经成为 LinkedIn、Amazon Rufus 等大型生产系统的核心推理引擎,支持投机解码作为默认特性 [5]。这意味着懂 vLLM 内部工作机制的人,是直接对接生产部署需求的。
更关键的是:这个方向不像"训练大模型"那样需要顶尖名校 + 大量算力 + 几年研究积累。它本质上偏工程——理解 GPU 内存层级、KV cache、推理框架的源码,再加上一两个有量化数据支撑的实操项目,就能进入面试官的雷达。
二、投机解码是什么?(人话版)
要理解投机解码,先理解大模型为什么那么慢——
大模型生成文字是一个 token 一个 token 蹦的。要写一句 100 字的回答,模型要被调用 100 次。每次调用,GPU 都要把模型的几百亿参数全部读一遍才能算(这是 GPU 硬件的内存层级决定的,下一篇会详细讲)。
这就引出了一个浪费:每次"读 140 GB 权重"的搬运成本是固定的,但只换回 1 个新 token。就好像每次开大卡车送货,只送 1 个包裹。
核心 idea:让小模型先猜,大模型批改
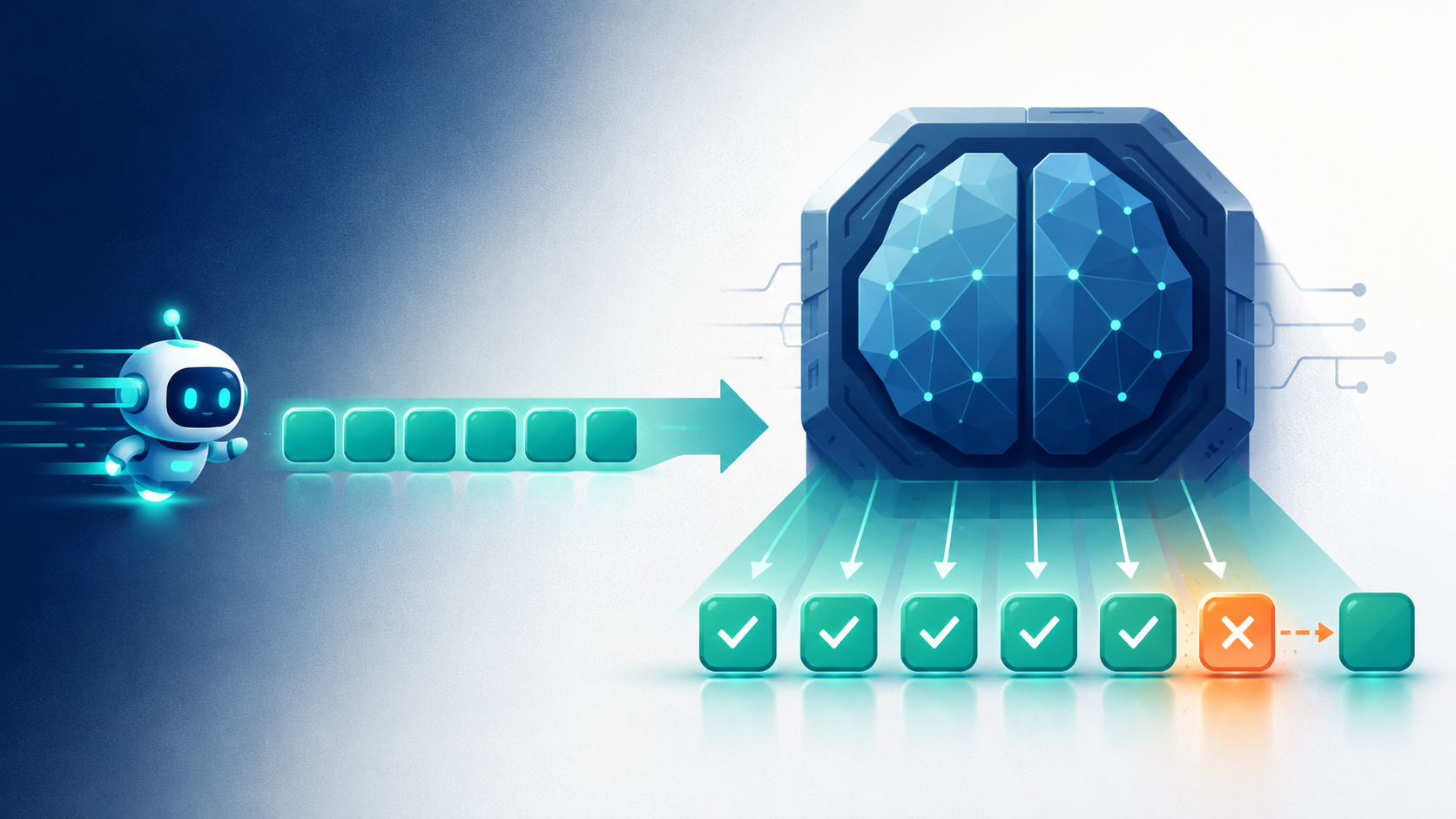
投机解码的思路非常聪明:
- 用一个便宜得多的小模型(比如 1B 参数的)先快速猜出未来 5-7 个 token
- 把这些猜测一次性塞给大模型,让大模型用一次前向并行验证
- 大模型同意的猜测直接采纳;第一个不同意的位置用大模型的正确答案替换
- 顺利的话,一次"搬运"换回 5-7 个 token,速度直接翻几倍
最神奇的是:输出质量一点不变。投机解码有严格的数学保证,最终输出和"直接用大模型生成"的概率分布完全相等——不是近似,是精确相等(下一篇会给出完整证明)。
一个直观的比喻

想象你是一位教授,要回 50 封学生邮件。
- 慢方式:你逐封写,串行
- 投机解码方式:让助教(小模型)先把每封邮件的回复草稿写好,你(大模型)扫一眼批一整批——对的通过,错的就地改正
助教工资便宜,你的时间很贵。总效率高得多。
这就是投机解码的本质:用便宜的预测换昂贵的并行验证机会。
三、大厂为什么离不开它?三大场景

场景 1:云端推理(万亿级 token / 天的成本压力)
豆包、Kimi、ChatGPT、Claude、Gemini 这种产品,每天处理几十亿到几百亿 token。每个 token 节省 1 毫秒,一年就是上百万美元的电费节约。
所以所有主流推理框架(vLLM、TensorRT-LLM、SGLang)都把投机解码作为默认特性。vLLM 官方报告 spec decoding 可以带来 最高 2.8× 的吞吐提升 [6]。
场景 2:端侧推理(手机、车机、AI 眼镜)
端侧设备算力和电池都受限。能不能让 7B 模型在手机上跑得像 1.5B 一样快? 投机解码是端侧最有希望的方向之一——大模型保证质量,小模型加速预测。这是字节、华为、小米、苹果都在重点投入的方向。
场景 3:实时交互(语音、代码补全)
GitHub Copilot、Cursor、各种语音助手,首 token 延迟(TTFT)和 token 间延迟(ITL)直接决定用户体验。spec decoding 是这类产品的核心加速手段。Cursor 这类公司的招聘,明确把推理优化列在核心技能里。
四、适合什么背景入手?

实话说,这个方向对纯算法/数学背景的要求并不算高,但对工程能力要求高。如果你:
- 熟悉一门系统编程语言(Python 是底线,C++/CUDA 加分)
- 看得懂 Transformer 的大致结构(不需要会手推 attention 公式)
- 愿意读开源代码(vLLM、HuggingFace transformers)
- 对 GPU 内存层级、缓存、并发等系统知识有兴趣
那么你比很多纯算法背景的同学更适合做这个方向。
入门成本非常低:花 1-2 周读核心论文 + 跑通 vLLM 的投机解码 demo + 实测自己环境下的加速比,就能在面试时拿出说得清楚、有数字的项目经历。
许多非顶尖学校的同学就是靠这个路径,成功进入字节、阿里、腾讯、DeepSeek、Moonshot 等公司的推理团队。它本质是一条信息差红利路径——大厂极度需要、人才供给却严重不足。
五、下期预告
如果这篇文章让你对这个方向产生了兴趣,下一篇会真正帮你上手:
- 大模型推理慢的双重瓶颈:自回归 + memory-bandwidth bound 到底是怎么回事
- 投机解码的完整算法:包含修正拒绝采样的数学证明(其实并不难)
- 5 个最新研究方向:Medusa、EAGLE、SpecInfer、MTP、Lookahead 各自解决什么问题
- 学习路径:5 篇必读论文(按顺序)+ 实操建议
- 面试题清单:从浅层到设计题,10+ 道高频原题
这是一个高 ROI 的方向——只要愿意花 2-3 周认真学,就能在面试中显得非常专业。
下期见。
参考资料
[1] 字节跳动豆包大模型团队 / 启明创投合伙人周志峰公开发言. (2025). 转引自证券时报:《字节跳动重大宣布!成本再降 40%!》. https://www.stcn.com/article/detail/1574071.html
[2] 量子位. (2025-02-12). 推理成本比 MoE 直降 83%!字节最新大模型架构 UltraMem 入围 ICLR 2025. https://www.qbitai.com/2025/02/253107.html
[3] 新浪科技 / IT之家. (2025-03-10). 字节跳动豆包大模型团队开源 MoE 架构优化技术 COMET,训练成本节省 40%. https://finance.sina.com.cn/tech/digi/2025-03-10/doc-inepeiii9608044.shtml
[4] 麦肯锡《2030 中国 AI 人才需求报告》及脉脉、智联招聘平台数据;转引自 CSDN 行业分析:《2025 AI 应用层风口:大模型开发人才缺口炸裂》. https://blog.csdn.net/EnjoyEDU/article/details/154948613
[5] vLLM Team. (2025-01). vLLM 2024 Retrospective and 2025 Vision. https://blog.vllm.ai/2025/01/10/vllm-2024-wrapped-2025-vision.html
[6] vLLM Team. (2024-10-17). How Speculative Decoding Boosts vLLM Performance by up to 2.8x. https://blog.vllm.ai/2024/10/17/spec-decode.html
如果觉得有帮助,欢迎点赞收藏,下一期深度解析见。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐


 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)