LLM 全解析:大语言模型原理、三种接入方案与 DeepSeek API 实战

引言:
前些天发现了一个巨牛的人工智能 学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。
1、什么是大语言模型
大语言模型(LLM,Large Language Model),简单来说,就是一个用海量文本数据训练出来的、能够理解和生成人类语言的巨型人工智能程序。
你可以把它想象成一个读过互联网上大部分公开文字(书籍、网页、论文、代码等)的“超级学霸”。它虽然没有真正的意识,但通过记住数万亿个文字之间的统计规律,学会了如何组合出听起来合理、通顺的句子。
为了帮你快速建立认知,我把它的核心拆解为以下四个维度:
1. 它“大”在哪里?(三大维度)
-
数据大:训练时“吃”的数据量极其惊人。例如 GPT-3 训练数据达到了 45TB(相当于几千万本书)。
-
参数大:参数就像人脑中的“神经元连接”。参数越多,模型越“聪明”。早期模型几亿参数,现在的顶级模型(如 GPT-4、Claude 3)参数规模达到了 数千亿甚至上万亿。
-
算力大:训练一次顶级大模型,需要数千张高性能显卡连续运行数月,耗电成本高达数千万美元。
2. 它的核心原理是什么?(下一个词预测)
虽然看起来很神奇,但 LLM 最底层的训练逻辑其实非常简单,就是 “完形填空” 或 “猜下一个词”。
-
训练时,研究人员会把一段话遮住后半部分,让它预测后面的内容,然后比对正确答案,不断调整参数。
-
例如,输入“床前明月______”,模型会根据海量学习经验,计算出“光”的概率最高(90%),其次是“色”(5%)。
-
通过这种无数次的猜词训练,模型自然而然地学会了语法、逻辑、推理,甚至一些世界常识。
3. 它和传统搜索引擎有什么区别?
这是新手最容易混淆的地方:
| 对比维度 | 传统搜索引擎 | 大语言模型(LLM) |
|---|---|---|
| 工作方式 | 检索:你去库里找已有的网页。 | 生成:它现场“创作”新内容给你。 |
| 返回结果 | 给出一大堆链接,让你自己看。 | 直接整合信息,生成一段连贯的答案。 |
| 是否能思考 | 不能,只做关键词匹配。 | 能进行简单的推理、总结、翻译和代码编写。 |
| 时效性 | 抓取最新信息(实时)。 | 知识截止于训练时,不知道训练后发生的事(除非开启联网搜索)。 |
4. 知名的 LLM 代表有哪些?
-
国外:OpenAI 的 GPT 系列(ChatGPT)、Google 的 Gemini、Anthropic 的 Claude。
-
国内:百度的 文心一言、阿里的 通义千问、字节的 豆包、深度求索的 DeepSeek。
5. 它的局限性和缺点
LLM 并非全知全能,使用时有几个常见“坑”需要留意:
-
幻觉问题:当它不懂时,它会一本正经地胡说八道,编造不存在的引用或事实(这叫“AI 幻觉”)。
-
缺乏真正推理:它不懂数学背后的意义,只是记住了数万亿种数学题解题模式的排列组合,所以复杂的多步逻辑推理容易出错。
-
过时知识:如果没有开启联网功能,它不知道 2026 年 6 月 28 日之后发生的新闻。并且缺乏私有知识,不包含我们的私人数据。
-
输入长度限制:所有LLM都有固定的输入长度(如4K、8K、128K、400KToken)。我们无法将一本几百页的PDF或整个公司知识库直接塞给模型。
-
复杂任务处理能力弱:原生API本质是一个“一问一答”的接口。对于需要多个步骤的复杂任务(如“分析这份财报,总结要点,并生成一份PPT大纲”),我们需要自己编写复杂的逻辑来拆解任务、多次调用API并管理中间状态。
-
输出格式不可控:虽然可以通过提示词要求模型输出JSON或特定格式,但它仍可能产生格式错误或不合规的内容,需要我们自己编写后处理代码来校验和清洗。像LangChain这样的框架,正是为了系统性地解决这些问题而诞生的。
2.接入大模型主流三种方式
1. API 调用(最常用、企业首选)
厂商提供在线接口,通过 HTTP/HTTPS 请求传参调用云端大模型,无需本地部署。
- 代表:OpenAI、文心一言、通义千问、DeepSeek、Llama 云服务
- 优点:开箱即用、算力不用自己承担、支持流式输出
- 缺点:依赖网络、有调用费用、数据走第三方服务器
2. 本地私有化部署(开源模型为主)
下载开源大模型权重(Llama、Qwen、GLM、Mistral),在自己服务器 / 显卡本地运行。细分两种:直接加载推理框架(Transformers)、封装成本地 API 服务(Ollama、vLLM)
- 优点:数据不出内网、无按量收费、完全可控
- 缺点:需要高性能 GPU、部署调优门槛高、硬件成本高
3. 嵌入 SDK / 组件集成(端侧 / 应用内置)
将轻量化大模型推理库封装成 SDK,嵌入客户端、APP、小程序、硬件设备(端侧大模型)。
- 代表:移动端 Qwen-7B、离线语音大模型、RISC-V 端侧小模型
- 优点:离线可用、低延迟、保护用户本地数据
- 缺点:只能跑小参数量轻量化模型,能力受限
下面我们主要讲解API接入方式
典型流程:
第1步:获取“入场券”(API Key 和 URL)
在调用之前,你需要在模型厂商的官网注册账号,创建一个应用(Project),然后生成一串独一无二的密钥(API Key)。
-
API Key:相当于你的“会员密码”,每次请求必须带上,用于鉴权和计费。
-
Base URL:服务器的入口地址(例如
https://api.openai.com/v1)。
⚠️ 极度重要:API Key 必须放在服务器端或环境变量里,绝对不能写在前端网页或上传到GitHub,否则别人能盗刷你的额度。
第2步:构造请求体(告诉服务员你要什么)
你需要向 API 发送一个 HTTP POST 请求,请求体通常是 JSON 格式。最核心的参数有三个:
| 参数 | 作用 | 示例值 |
|---|---|---|
model |
指定用哪个大模型 | "gpt-4" 或 "deepseek-chat" |
messages |
对话历史(必须包含角色) | [{"role": "user", "content": "你好"}] |
temperature |
控制随机性(0~2),越高越有创意 | 0.7 |
一个标准的请求体长这样:
{
"model": "gpt-3.5-turbo",
"messages": [
{"role": "system", "content": "你是一位资深程序员"}, // 设定AI的人设
{"role": "user", "content": "请用C语言写一个交换数组元素的函数"}
],
"temperature": 0.7
}第3步:发送请求并处理响应(Python 代码实战)
绝大多数现代大模型 API 都支持 流式(Stream) 输出(像ChatGPT那样逐字蹦出来)和非流式(一次性全部返回)。下面是最简洁的非流式调用代码(使用 requests 库):
import requests
import json
# 1. 配置你的密钥和地址
API_KEY = "sk-xxxxxxxx" # 替换成你的真实 Key
BASE_URL = "https://api.openai.com/v1" # 国内厂商会换成自己的域名
# 2. 构造请求头(鉴权)和请求体
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {API_KEY}"
}
data = {
"model": "gpt-3.5-turbo",
"messages": [{"role": "user", "content": "C语言中break只能跳出当前循环吗?"}]
}
# 3. 发送POST请求
response = requests.post(f"{BASE_URL}/chat/completions",
headers=headers,
json=data,
timeout=30)
# 4. 解析返回的JSON,提取出AI回复的内容
if response.status_code == 200:
result = response.json()
# 路径:choices[0] -> message -> content
ai_reply = result["choices"][0]["message"]["content"]
print(ai_reply)
else:
print(f"请求失败,状态码:{response.status_code},错误信息:{response.text}")第4步:进阶处理——流式输出(像真人对话)
如果你想让回复一个字一个字地显示出来(提升用户体验),需要将 data 里的 "stream": True 开启,然后用迭代器逐行读取:
data["stream"] = True
response = requests.post(f"{BASE_URL}/chat/completions",
headers=headers,
json=data,
stream=True) # 开启流式
for line in response.iter_lines():
if line:
line = line.decode('utf-8')
if line.startswith("data: "):
chunk = line[6:] # 去掉前缀 "data: "
if chunk == "[DONE]":
break
# 解析JSON片段并打印
chunk_json = json.loads(chunk)
content = chunk_json["choices"][0]["delta"].get("content", "")
print(content, end="", flush=True)典型流程全貌图(脑内构建)
[你的应用程序]
→ 带上 API Key
→ 发送 JSON(包含 model + messages)
→ 大模型服务器(GPU集群)进行推理计算
→ 返回 JSON(包含 AI 生成的文本)
→ 你的应用程序解析并展示给用户
新手最容易踩的 3 个“坑”
-
计费陷阱:每一次请求都是按输入+输出的总 Token 数扣费的,如果不小心把整本小说塞进
messages,一次调用可能花掉几十块钱。 -
上下文超长:每个模型都有最大 Token 限制(比如 8K、128K),如果历史对话太长,需要自己手动裁剪或使用“滑动窗口”策略。
-
网络超时:大模型推理需要时间(通常1~5秒),一定要给 HTTP 请求设置足够长的
timeout,否则容易中断。
3.下面是deepseek API接入实操:
首先打开deepseek官网

右上角有一个调用API文档,点击进入
接着在首页进行点击 API key,申请一个key。
接着点击创建 API key
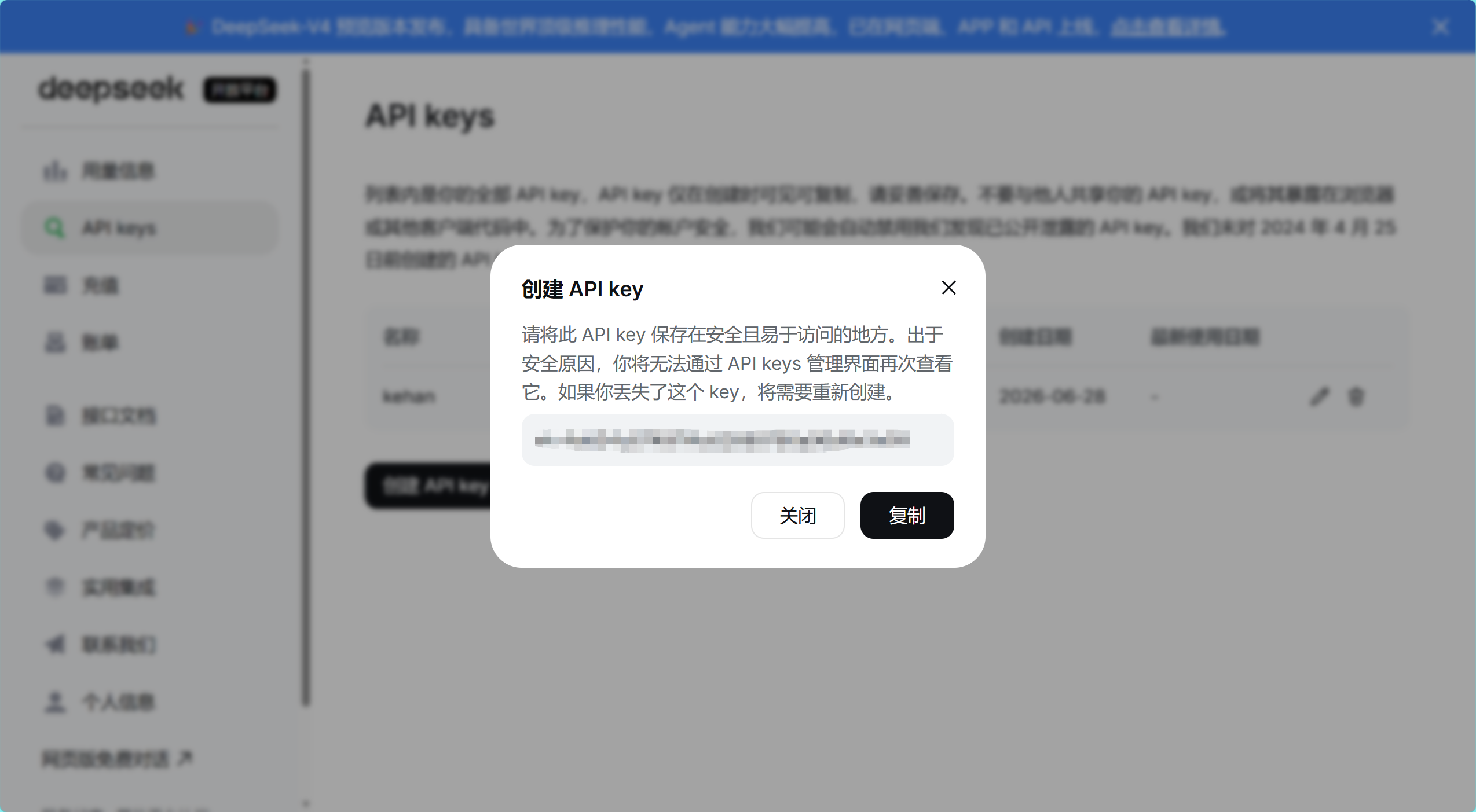
注意这里的密钥需要自己提前保存复制,不然退出之后你是没有办法再重新查看的!
下面我用APIfox进行一个验证(以deepseek为例)
并且使用的是DS官网的curl脚本用例
curl https://api.deepseek.com/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer ${DEEPSEEK_API_KEY}" \
-d '{
"model": "deepseek-v4-pro",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
],
"thinking": {"type": "enabled"},
"reasoning_effort": "high",
"stream": false
}'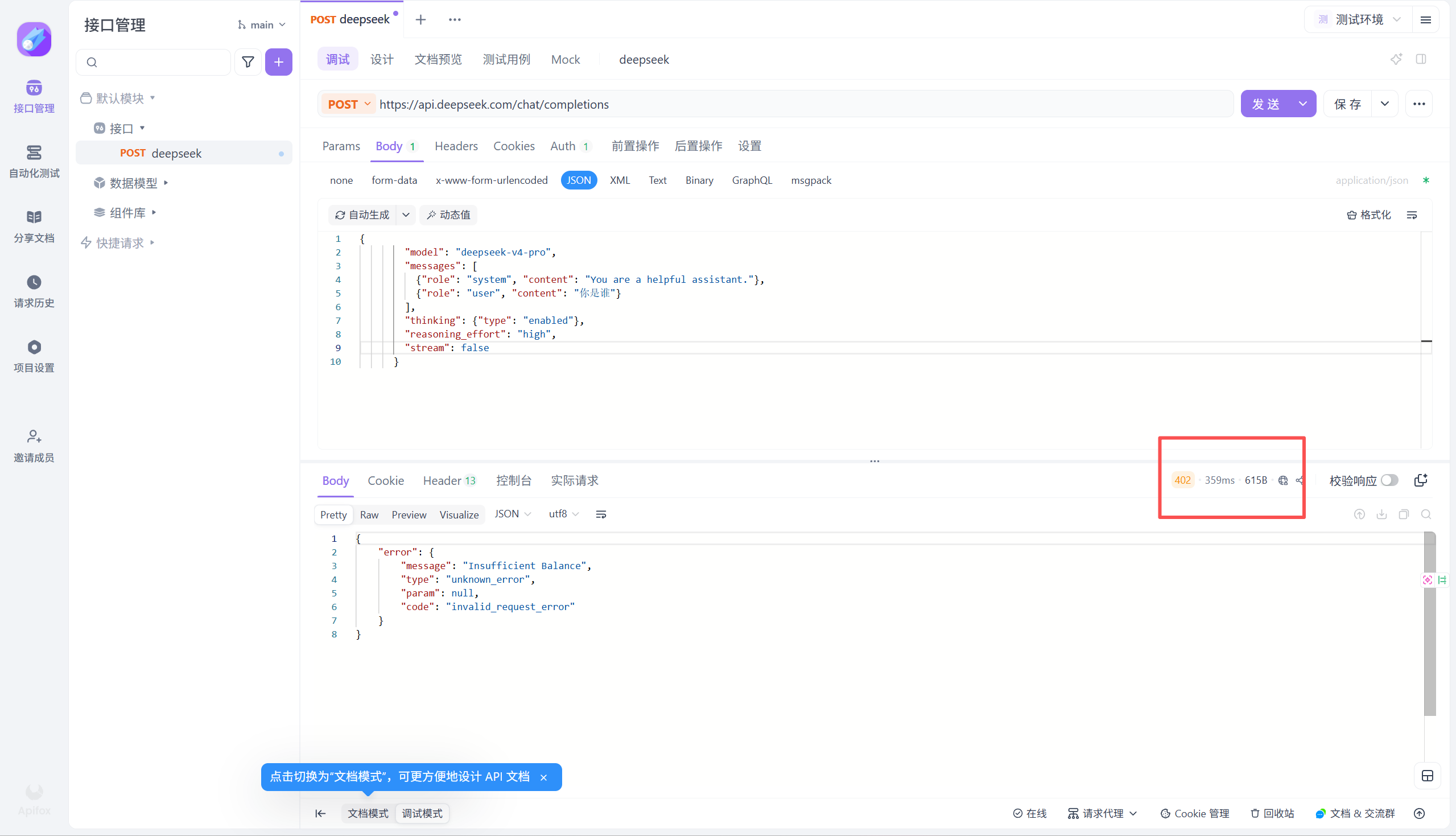
注意我这里显示的402报错表示需要付费,因为我们之前都没有充值
调用API常见错误码
在调用 DeepSeek API 时,可能会遇到以下错误。这里列出了相关错误的原因及其解决方法。
| 错误码 | 描述 |
|---|---|
| 400 - 格式错误 | 原因:请求体格式错误 解决方法:请根据错误信息提示修改请求体 |
| 401 - 认证失败 | 原因:API key 错误,认证失败 解决方法:请检查您的 API key 是否正确,如没有 API key,请先 创建 API key |
| 402 - 余额不足 | 原因:账号余额不足 解决方法:请确认账户余额,并前往 充值 页面进行充值 |
| 422 - 参数错误 | 原因:请求体参数错误 解决方法:请根据错误信息提示修改相关参数 |
| 429 - 请求速率达到上限 | 原因:请求速率(TPM 或 RPM)达到上限 解决方法:请合理规划您的请求速率。 |
| 500 - 服务器故障 | 原因:服务器内部故障 解决方法:请等待后重试。若问题一直存在,请联系我们解决 |
| 503 - 服务器繁忙 | 原因:服务器负载过高 解决方法:请稍后重试您的请求 |
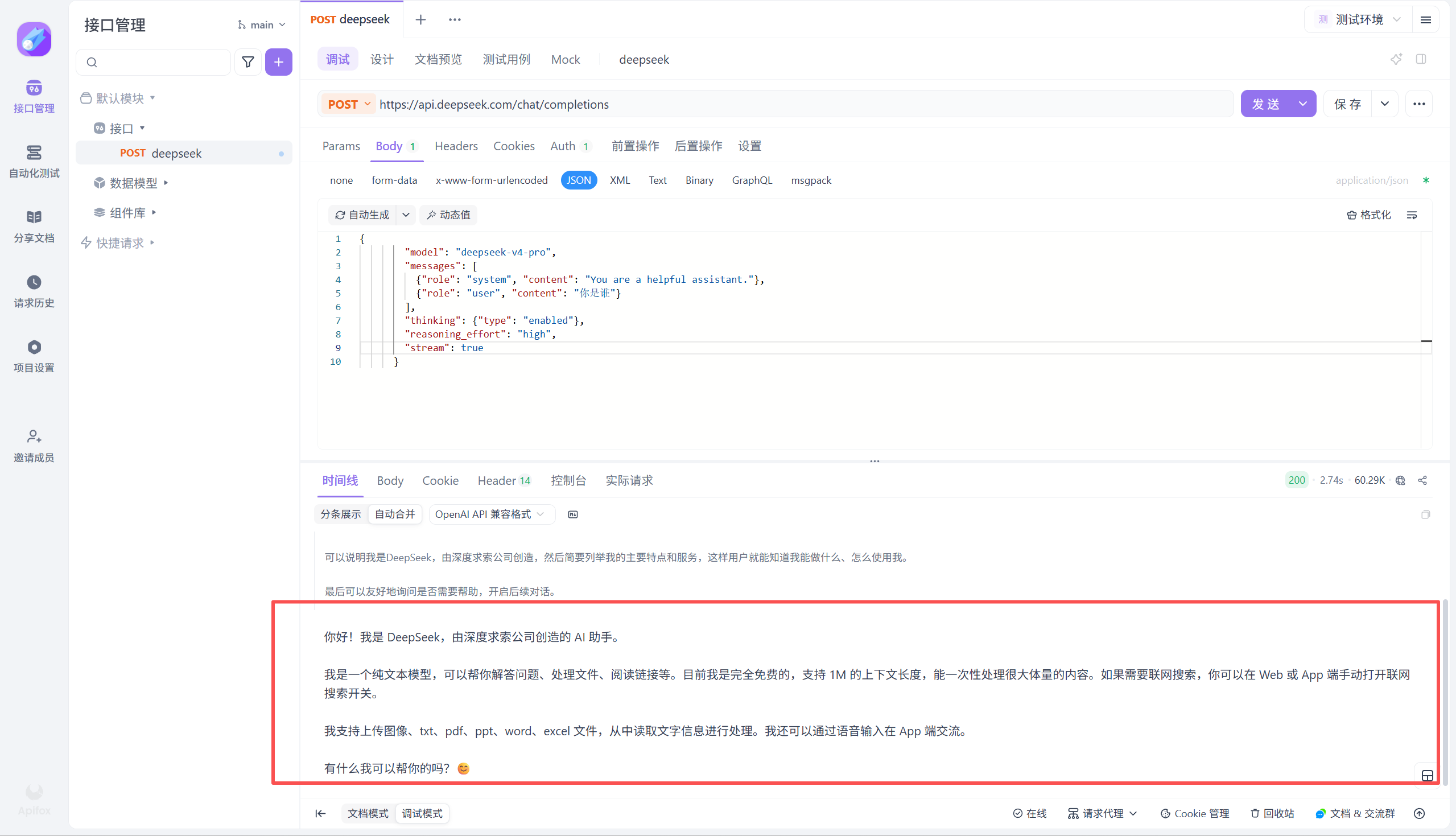
充值之后点击发送就可以了。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐

 14
14 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)