基于vue多维数据融合与混合推荐算法的智能旅行规划系统设计与实现
摘要
随着国内旅游市场的持续增长,用户面临信息过载、行程规划耗时、个性化推荐缺失等问题。本文设计并实现了 TripMaster Pro 智能旅行规划系统,以 Python Flask 为后端框架,Vue.js 3 + Element Plus 为前端技术栈,整合全国景点数据 6121 条、美食数据 6150 条、住宿数据 1364 条及非物质文化遗产数据,构建了涵盖数据展示、智能推荐、行程规划、可视化分析、AI 对话、多模态交互等功能的综合性旅游服务平台。
在智能行程优化方面,系统采用模拟退火算法和遗传算法实现行程编排,根据问题规模自动选择最优求解策略,并集成用户疲劳度模型约束行程强度,支持体弱、正常、运动员三种体能等级预设,确保生成的行程既丰富又可持续。系统接入 DeepSeek 大模型 API,通过精心设计的提示词工程实现 AI 智能行程生成和自然语言对话,当大模型服务不可用时自动降级到本地模板回复,保证服务可用性。
在数据处理方面,系统采用 SQLite 作为主数据库,通过连接池管理和 WAL 模式优化提升并发性能;针对携程采集数据中价格格式多样的问题,设计了专门的价格解析与类型推断函数。前端采用前后端分离架构,通过 Vite 代理实现跨域转发,使用 ECharts 实现可视化大屏,支持语音识别和图片识别等多模态交互能力。
关键词:智能旅行规划;模拟退火;遗传算法;DeepSeek 大模型;疲劳度模型;多模态交互
1.案例背景
近年来国内旅游市场持续增长,2024年国内旅游人次已超过60亿。然而用户面临信息过载、行程规划耗时、个性化推荐缺失、协作分享不便等问题。现有平台大多仅提供静态信息展示,缺乏智能化行程编排、实时数据感知和多人协作能力。
本文设计 TripMaster Pro 系统,以"数据驱动决策、智能赋能旅行"为理念,整合多源旅游数据,构建完整的后端服务基础设施(连接池、缓存、监控),采用模拟退火与遗传算法实现智能行程优化,集成开放时间、实时拥堵、疲劳度等多维约束,接入 DeepSeek 大模型提供 AI 能力,支持行程的版本管理、协作编辑与社交分享,以及语音交互、图片识别等多模态交互。
技术栈:后端 Python Flask + SQLite(连接池 + WAL + 读写分离),前端 Vue.js 3 + Element Plus + Vite,可视化 ECharts,地图百度地图 API,AI 服务 DeepSeek API。
2.数据提取
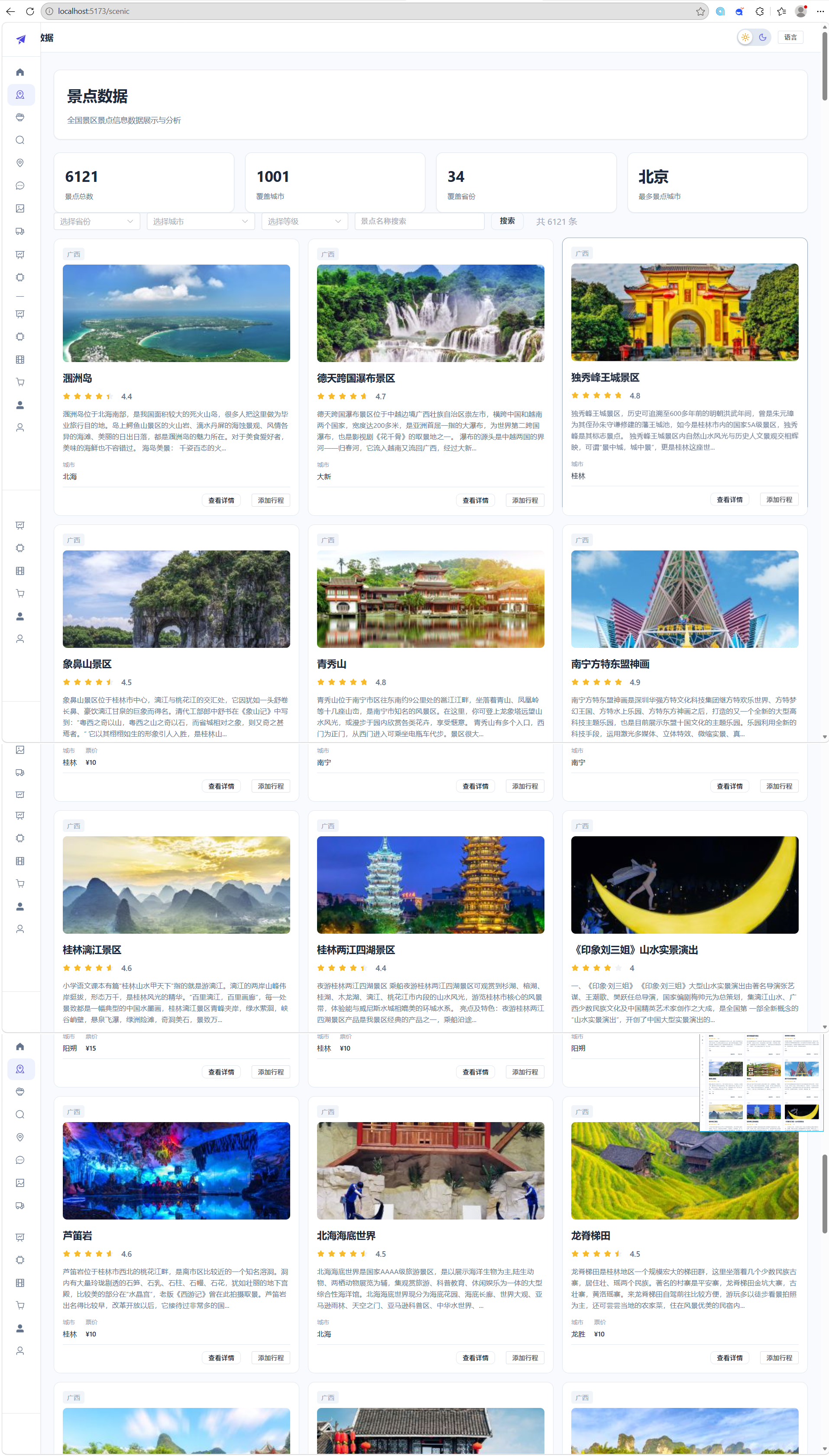
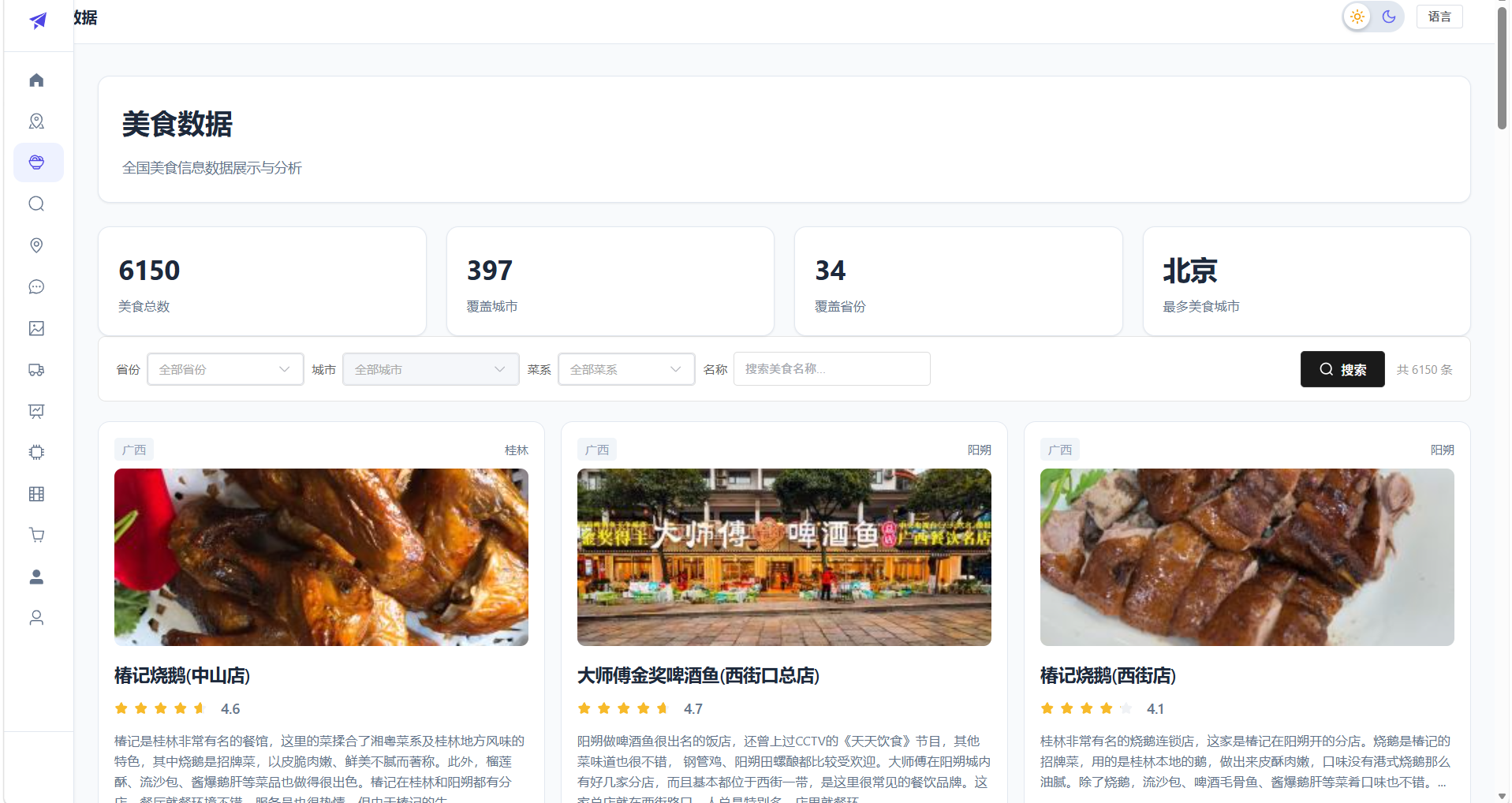
系统的数据来源主要包括四个部分:(1)景点数据:通过编写网络爬虫从携程网采集全国 A 级景区信息,共计 6121 条记录,包含景区名称、所在城市、景区类型、等级、评分、门票价格、经纬度坐标、景点介绍、图片 URL 等字段;(2)美食数据:通过爬虫从携程网采集全国各地特色美食信息,共计 6150 条记录,包含美食名称、所属城市、菜系分类、口味特点、推荐店铺、人均消费等字段;(3)住宿数据:通过爬虫从携程网采集酒店列表信息,共计 1364 条酒店记录,包含酒店名称、所在城市、星级、评分、价格、地址等字段。地理坐标数据通过调用百度地图 API 进行地理编码,确保所有位置信息的真实性和准确性。(4)非遗数据:国家级非物质文化遗产项目信息,采用多工作表 Excel 格式,包含项目信息、传承人信息和统计分析数据。
数据采集采用"公开数据集 + 网络采集 + 第三方API"的多源融合策略。对于地理坐标数据,系统调用百度地图 API 进行地理编码,将景区名称转换为经纬度坐标,确保所有位置信息的真实性和准确性,而非随机生成或估算。
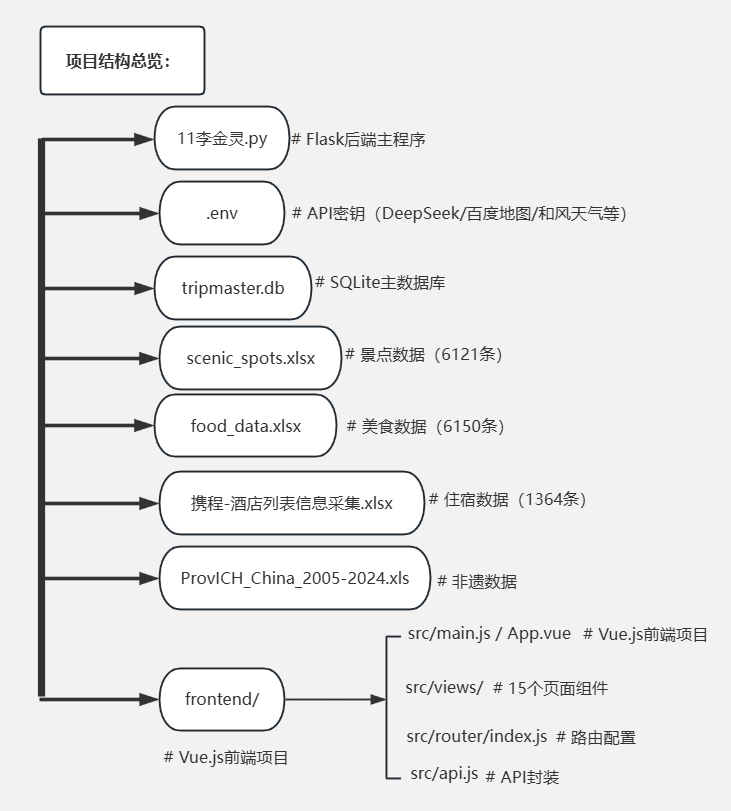
3.项目文件介绍
系统的后端主程序为 11李金灵.py,采用 Python Flask 框架编写,是整个系统的服务端核心,集成了数据加载、数据库操作、优化算法、AI接口调用及100余个 RESTful API 接口。前端项目位于 frontend/ 目录下,基于 Vue.js 3 + Vite + Element Plus 构建。
数据文件包括四个 Excel 文件:scenic_spots.xlsx(景点数据)、food_data.xlsx(美食数据)、携程-酒店列表信息采集.xlsx(住宿数据)、ProvICH_China_2005-2024.xls(非遗数据)。数据库文件 tripmaster.db 为 SQLite 主数据库,系统启动时自动创建。.env 文件存储百度地图、DeepSeek、和风天气等第三方服务的 API 密钥。
4.数据处理
4.1 数据加载与清洗
系统启动时自动读取所有 Excel 数据文件。景点和美食数据通过 pandas 批量读取,使用 astype(object).where(pd.notnull(df), None) 将 NaN 统一转为 Python None,避免数据库类型错误。住宿数据使用 openpyxl 逐行读取,因携程采集的价格格式复杂多样(如"¥120"、"100元/晚"、"起"),需要在读取过程中实时调用价格解析函数处理。加载完成后数据同时写入 SQLite 和保留在内存中,数据库支持复杂查询,内存数据用于前端高频筛选和地图渲染。
def load_scenic_spots():
df = pd.read_excel(os.path.join(APP_ROOT, 'scenic_spots.xlsx'))
df = df.astype(object).where(pd.notnull(df), None)
_SCENIC_SPOTS = df.to_dict('records')
print(f'[SCENIC] 景点数据加载完成:{len(_SCENIC_SPOTS)}条')
4.2 价格解析与类型推断
携程采集的住宿数据中价格字段格式多样,系统设计了分层解析策略:先去除"¥""元""起"等前后缀,再尝试浮点数转换,失败则返回 None。酒店类型根据星级和标签规则推断,如"五星"推断为五星级,"豪华"推断为豪华型,默认返回"舒适型"。
def _parse_price(val):
if val is None: return None
s = str(val).strip().replace('起','').replace('元','').replace('¥','')
try: return float(s.strip())
except ValueError: return None
def _infer_hotel_type(star, tags):
if '豪华' in str(star): return '豪华型'
if '五星' in str(star): return '五星级'
if '民宿' in str(tags).lower(): return '民宿'
return '舒适型'4.3 数据库表结构
系统采用 SQLite 作为主数据库,设计了完整的数据库架构。核心表包括:scenic_spots(景点信息,含人气热度、扩展字段)、users(用户账号)、favorites(收藏记录)、user_interactions(交互记录)、trips(行程计划,含分享码、公开状态)、trip_versions(行程版本历史)、trip_collaborators(行程协作者)、api_logs(API请求日志)、slow_queries(慢查询记录)、error_alerts(错误告警)等。系统通过 DBIndexManager 自动维护索引,通过 DBBackupManager 实现定时全量备份。
CREATE TABLE scenic_spots (
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT NOT NULL, city TEXT, type TEXT,
latitude REAL, longitude REAL, rating REAL,
price REAL, visit_time INTEGER, level TEXT,
description TEXT, tags TEXT, popularity REAL,
is_active INTEGER DEFAULT 1, extra TEXT DEFAULT '{}'
);
CREATE INDEX idx_city ON scenic_spots(city);
CREATE INDEX idx_type ON scenic_spots(type);
CREATE INDEX idx_rating ON scenic_spots(rating);
CREATE TABLE trips (
id INTEGER PRIMARY KEY AUTOINCREMENT,
user_id INTEGER, title TEXT, city TEXT, days INTEGER,
budget_level TEXT, content TEXT, share_code TEXT UNIQUE,
is_public INTEGER DEFAULT 0, like_count INTEGER DEFAULT 0,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
CREATE TABLE trip_versions (
id INTEGER PRIMARY KEY AUTOINCREMENT,
trip_id INTEGER, version INTEGER, content TEXT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
FOREIGN KEY (trip_id) REFERENCES trips(id) ON DELETE CASCADE
);
CREATE TABLE trip_collaborators (
id INTEGER PRIMARY KEY AUTOINCREMENT,
trip_id INTEGER, user_id INTEGER, role TEXT DEFAULT 'editor',
invited_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
FOREIGN KEY (trip_id) REFERENCES trips(id) ON DELETE CASCADE,
UNIQUE(trip_id, user_id)
);5.后端服务基础设施
5.1 数据库连接池
SQLite 默认单线程,高并发下易出现"数据库被锁定"错误。系统实现 DBConnectionPool 连接池,初始化时创建5个连接放入队列,通过上下文管理器实现借还管理,确保连接在任何情况下正确归还。同时开启 WAL 模式(写操作分离到独立日志文件,支持读写并发)、同步模式设为 NORMAL、缓存大小设为64MB,显著提升并发性能。
class DBConnectionPool:
def __init__(self, db_path, pool_size=5):
self._pool = queue.Queue(maxsize=pool_size)
for _ in range(pool_size):
conn = sqlite3.connect(db_path, check_same_thread=False)
conn.execute('PRAGMA journal_mode=WAL')
conn.execute('PRAGMA synchronous=NORMAL')
conn.execute('PRAGMA cache_size=-64000')
self._pool.put(conn)
@contextmanager
def get_connection(self):
conn = self._pool.get(timeout=10)
try: yield conn
finally: self._pool.put(conn)
5.2 读写分离
系统实现 DBReadWriteSplitter 读写分离管理器。写操作使用主库(WAL模式),读操作优先使用只读副本,副本通过 sqlite3 的 backup 方法从主库同步,同步间隔60秒。当副本不可用时自动回退到主库读,保证服务连续性。
class DBReadWriteSplitter:
def __init__(self, db_path):
self.db_path = db_path
self._read_replica_path = db_path + '.replica'
self._sync_interval = 60
def _sync_to_replica(self):
source = sqlite3.connect(self.db_path, timeout=30)
dest = sqlite3.connect(self._read_replica_path, timeout=30)
source.backup(dest)
dest.close(); source.close()
def get_read_connection(self):
if self.should_sync(): self._sync_to_replica()
try:
return sqlite3.connect(
f'file:{self._read_replica_path}?mode=ro', uri=True)
except:
return sqlite3.connect(self.db_path) # 回退主库5.3 缓存引擎
系统实现 CacheEngine 缓存引擎,采用多层缓存策略:第一层为内存 LRU 缓存(基于 OrderedDict,默认容量1000条),第二层为 SQLite 持久化缓存,第三层为 Redis 分布式缓存(可选)。缓存支持 TTL(生存时间)和版本号管理,当数据更新时自动使旧缓存失效。景点数据、地图 API 结果、DeepSeek 响应等高频数据均通过缓存加速。
class CacheEngine:
def __init__(self, backend='MemoryLRU', capacity=1000):
self.backend = backend
self._memory_cache = OrderedDict()
self._capacity = capacity
self._db_cache_table = 'cache_entries'
def get(self, key):
if key in self._memory_cache:
self._memory_cache.move_to_end(key)
return self._memory_cache[key]['value']
# 回退到数据库缓存
return self._get_from_db(key)
def set(self, key, value, ttl=300):
if len(self._memory_cache) >= self._capacity:
self._memory_cache.popitem(last=False)
self._memory_cache[key] = {'value': value, 'expires': time.time()+ttl}5.4 集中式日志与性能监控
系统构建 CentralizedLogStore 集中式日志存储,记录所有 API 请求(时间、方法、路径、用户ID、响应耗时、状态码),自动识别慢查询(超过500ms)并记入 slow_queries 表。ErrorAlertManager 捕获系统异常并生成告警,支持严重等级分级和确认标记。PerformanceMonitor 统计各接口的 QPS、P50/P95/P99 延迟、错误率等指标,为性能调优提供数据支撑。
class CentralizedLogStore:
def log_api(self, method, path, user_id, duration_ms, status_code):
conn = get_db(); c = conn.cursor()
c.execute('INSERT INTO api_logs (ts,method,path,user_id,duration_ms,status_code) VALUES (?,?,?,?,?,?)',
(datetime.now().isoformat(), method, path, user_id, duration_ms, status_code))
conn.commit(); conn.close()
class PerformanceMonitor:
def record(self, path, duration_ms):
self._stats[path]['count'] += 1
self._stats[path]['total_ms'] += duration_ms
if duration_ms > self._stats[path]['max_ms']:
self._stats[path]['max_ms'] = duration_ms6.模型原理
6.1 模拟退火行程优化
模拟退火算法(SA)灵感来源于金属退火过程,通过温度参数控制搜索行为。系统将景点坐标作为搜索空间,以行程总成本为目标函数,综合考虑交通距离(Haversine公式)、游览时间、门票费用、疲劳度累积、开放时间合规性和实时拥堵惩罚六个因素。增强版 SA 新增了开放时间过滤:若指定了开始日期,系统调用 ScenicOpenHours 过滤掉全程闭馆的景点;同时集成实时拥堵数据,从 TrafficCongestion 服务获取景点热度评分和人群密度等级,在成本函数中对高拥堵景点施加额外惩罚。参数设置:初始温度100度,冷却速率0.995,最大迭代2000次。
class SimulatedAnnealingOptimizer:
INITIAL_TEMP = 100.0; COOLING_RATE = 0.995; MAX_ITER = 2000
def _get_scenic_points(self, city, preferences, start_date=None, days=1):
points = [...]
# 开放时间过滤
if start_date:
available, unavailable = ScenicOpenHours.filter_available_scenics(
[p['name'] for p in points], start_date, days)
points = [p for p in points if p['name'] in available]
return points[:15]
def _calculate_route_cost(self, route, fatigue_model, start_date=None):
total_time = total_distance = total_cost = total_fatigue = 0
congestion_penalty = open_time_violations = 0
for i, point in enumerate(route):
total_time += point.get('visit_time', 3) * 60
total_cost += point.get('price', 0)
total_fatigue += fatigue_model.calculate_activity_fatigue(
point.get('visit_time', 2), point.get('type'))
# 实时拥堵惩罚
traffic = self._get_realtime_traffic(point['name'])
if traffic['crowd_level'] == 'high':
congestion_penalty += 30
if i < len(route) - 1:
total_distance += self._haversine(point, route[i+1])
return total_time + total_distance*10 + total_cost + total_fatigue*2 + congestion_penalty6.2 遗传算法行程优化
遗传算法(GA)通过选择、交叉、变异三种遗传操作在多代种群中搜索最优解。染色体编码由景点排列顺序和天分隔断点两部分组成。适应度函数采用"奖励高分景点、惩罚过度疲劳"策略,同时引入开放时间奖励(景点在游览日开放的给予加分)和拥堵惩罚(高拥堵景点扣分)。参数:种群50个个体,进化100代,交叉率0.8,变异率0.15。当景点数超过10个且天数不少于3天时自动选择 GA。
class GeneticAlgorithmOptimizer:
POPULATION_SIZE = 50; MAX_GENERATIONS = 100
CROSSOVER_RATE = 0.8; MUTATION_RATE = 0.15
def _fitness(self, chromosome, fatigue_model, start_date=None):
day_routes = self._decode(chromosome)
total_rating = open_time_bonus = total_penalty = 0
for route in day_routes:
for pt in route:
total_rating += pt['rating']
# 开放时间奖励
if start_date and ScenicOpenHours.is_open(pt['name'], start_date):
open_time_bonus += 5
fatigue = fatigue_model.calculate_activity_fatigue(
pt.get('visit_time',2), pt.get('type'))
if fatigue > fatigue_model.max_daily_fatigue * 0.5:
total_penalty += fatigue
return total_rating * 10 + open_time_bonus - total_penalty6.3 智能行程编排调度器
系统设计了 SmartItineraryPlanner 智能调度器,根据问题规模自动选择最优算法。小规模问题(景点少于10个、天数少于3天)采用模拟退火,收敛快、内存占用小;大规模问题采用遗传算法,搜索能力强、全局性好。用户也可手动指定算法覆盖自动判断。
class SmartItineraryPlanner:
def plan(self, city, days, budget, preferences, algorithm='auto'):
if algorithm == 'auto':
points_count = len(self._get_scenic_points(city, preferences))
if points_count > 10 and days >= 3:
algorithm = 'ga'
else:
algorithm = 'sa'
if algorithm == 'ga':
return self.ga.optimize(city, days, budget, preferences)
else:
return self.sa.optimize(city, days, budget, preferences)6.4 用户疲劳度模型
系统建立疲劳度约束模型,将体力消耗纳入行程优化核心考量。定义三种体能预设:体弱人士(上限60,6小时)、正常体能(上限100,10小时)、运动员级(上限150,12小时)。疲劳度计算考虑活动类型差异:登山类系数1.5,室内类系数0.8。模型与优化算法深度集成,SA中总疲劳度纳入成本函数,GA中超标疲劳产生惩罚。
class FatigueModel:
FITNESS_PRESETS = {
'weak': {'max_daily_fatigue': 60, 'max_daily_hours': 6,
'fatigue_factor': 1.6, 'prefer_flat': True},
'normal': {'max_daily_fatigue': 100, 'max_daily_hours': 10,
'fatigue_factor': 1.0, 'prefer_flat': False},
'athletic':{'max_daily_fatigue': 150, 'max_daily_hours': 12,
'fatigue_factor': 0.7, 'prefer_flat': False},
}
def calculate_activity_fatigue(self, hours, activity_type):
base = hours * 15
if activity_type in ('mountain', 'hiking'): base *= 1.5
elif activity_type in ('museum', 'indoor'): base *= 0.8
return base6.5 景点开放时间管理
ScenicOpenHours 模块维护各景点的开放时间表,支持常规营业时间、季节性调整和特殊闭馆日。在行程规划时,系统根据用户选择的开始日期和行程天数,过滤掉全程闭馆的景点,并在遗传算法的适应度函数中对开放景点给予奖励分,确保生成的行程中每个景点在游览日均可进入。
6.6 实时拥堵评估
TrafficCongestion 模块通过实时特征服务获取景点的热度评分(heat_score)和点击率(ctr),将人群密度划分为低、中、高三个等级。在模拟退火的成本函数中,高拥堵景点额外增加30点惩罚,引导算法优先选择人流较少的时段或景点,提升用户的实际游览体验。
7. 模型设计与实现
7.1 统一响应与错误处理
系统定义统一错误码(ERR_OK=0、ERR_PARAMS=400、ERR_UNAUTHORIZED=401、ERR_NOT_FOUND=404、ERR_INTERNAL=500、ERR_TIMEOUT=504)和响应格式(code、success、message、data、timestamp)。错误响应包含 trace_id,便于前后端联调时快速定位问题。
def ok(data=None, message='成功'):
return jsonify({'code': 0, 'success': True, 'message': message,
'data': data, 'timestamp': int(time.time())})
def err(message=None, code=500):
msg = message or ERROR_MESSAGES.get(code, '未知错误')
return jsonify({'code': code, 'message': msg,
'trace_id': hashlib.md5(f'{time.time()}{code}'.encode()).hexdigest()[:12],
'timestamp': int(time.time())}), 500
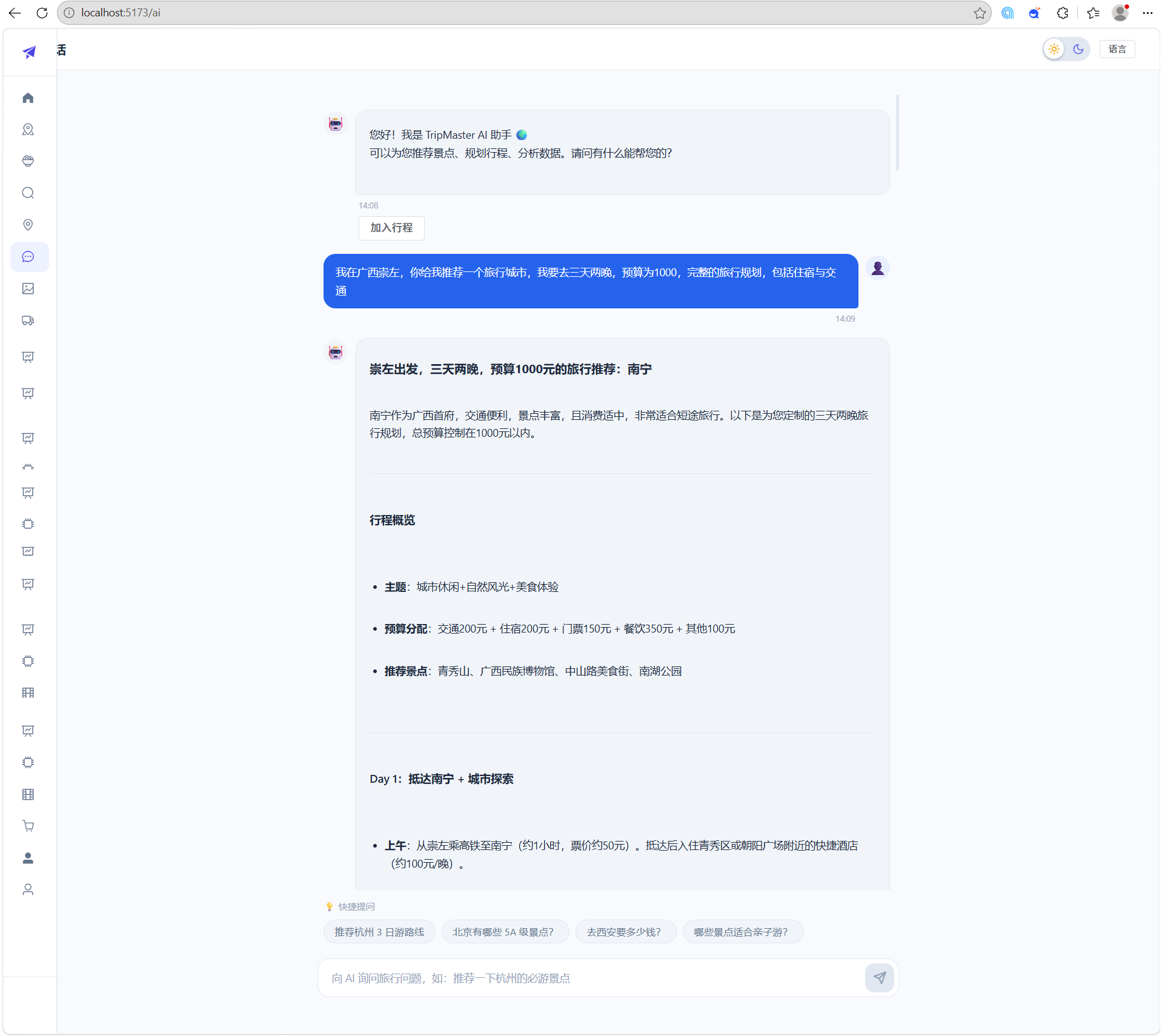
7.2 DeepSeek大模型集成
系统接入 DeepSeek API 实现 AI 行程生成和自然语言对话。行程生成通过 Prompt Engineering 设计结构化提示词,以"资深中国旅游规划师"角色指令引导输出 JSON 格式行程(含标题和每日主题及景点列表)。API 调用设置 120 秒超时,失败时自动降级到本地模板回复。对话接口取最近10轮消息作为上下文,避免超出模型上下文窗口限制。缓存引擎缓存 DeepSeek 响应,相同查询直接返回缓存结果,降低 API 调用成本。
# AI行程生成
prompt = [
{'role': 'system', 'content': '你是资深中国旅游规划师'},
{'role': 'user', 'content': f'请为游客定制【{destination}{days}日游】行程,'
f'偏好:{preferences},请按JSON格式输出'}
]
resp = requests.post('https://api.deepseek.com/chat/completions',
json={'model': 'deepseek-chat', 'messages': prompt},
headers={'Authorization': f'Bearer {api_key}'}, timeout=120)7.3 行程管理API
系统实现了完整的行程管理功能,包括保存、查看、导出、分享和协作编辑。行程保存时同时创建版本历史记录,支持回溯到任意历史版本。分享功能生成唯一分享码,支持设置公开/私密权限。协作编辑支持邀请其他用户作为协作者(editor 或 viewer 角色),协作者可实时修改行程内容。导出功能生成 HTML 格式的行程单,包含景点列表、地图占位和元信息。
@app.route('/api/trips', methods=['POST'])
def create_trip():
data = request.json or {}
conn = get_db(); c = conn.cursor()
c.execute("""INSERT INTO trips (user_id, title, city, days, budget_level, content, share_code, is_public)
VALUES (?, ?, ?, ?, ?, ?, ?, ?)""",
(user['id'], data['title'], data['city'], data['days'],
data['budget_level'], data['content'], generate_share_code(), 0))
trip_id = c.lastrowid
# 创建初始版本
c.execute('INSERT INTO trip_versions (trip_id, version, content) VALUES (?, 1, ?)',
(trip_id, data['content']))
conn.commit(); conn.close()
return ok({'trip_id': trip_id})
@app.route('/api/trips/<int:trip_id>/collaborators', methods=['POST'])
def trip_add_collaborator(trip_id):
# 只有行程所有者可以添加协作者
data = request.json or {}
target_email = data.get('email')
role = data.get('role', 'editor')
# 查找目标用户并添加到 trip_collaborators 表
7.4 社交功能
系统实现了基础的社交功能。用户可以关注其他用户,关注后可在社交动态页面查看被关注用户的公开行程。社交动态时间线按时间倒序排列,展示行程标题、城市、天数、点赞数和评论数。用户可以对公开行程点赞和评论,形成轻量级的旅行社区氛围。
@app.route('/api/social/feed')
def social_feed():
current = _check_auth()
conn = get_db(); c = conn.cursor()
c.execute("""SELECT t.*, u.username,
COALESCE(t.like_count,0) as like_count,
COALESCE(t.comment_count,0) as comment_count
FROM trips t JOIN users u ON t.user_id = u.id
WHERE t.user_id IN (SELECT following_id FROM friends WHERE user_id = ?)
AND t.is_public = 1
ORDER BY t.created_at DESC LIMIT 50""", (current['id'],))
feed = [dict(zip([d[0] for d in c.description], r)) for r in c.fetchall()]
conn.close()
return ok({'feed': feed, 'total': len(feed)})7.5 配置状态API
/api/config/status 接口返回系统配置全景,包括外部 API 状态(百度地图、DeepSeek、和风天气等是否已配置密钥)、内部 API 列表(路径、方法、描述)以及缓存后端类型。该接口帮助管理员快速了解系统依赖配置情况和可用功能。
8. 界面实现
8.1 前端架构
前端采用 Vue.js 3 Composition API + Vite + Element Plus,单页应用架构,15个路由全部懒加载。HTTP 请求通过 axios 统一封装,配置请求拦截器自动附加用户 ID。支持中/繁/英三语国际化,通过自定义 i18n 模块维护 UI 文本字典。
8.2 智能推荐页面
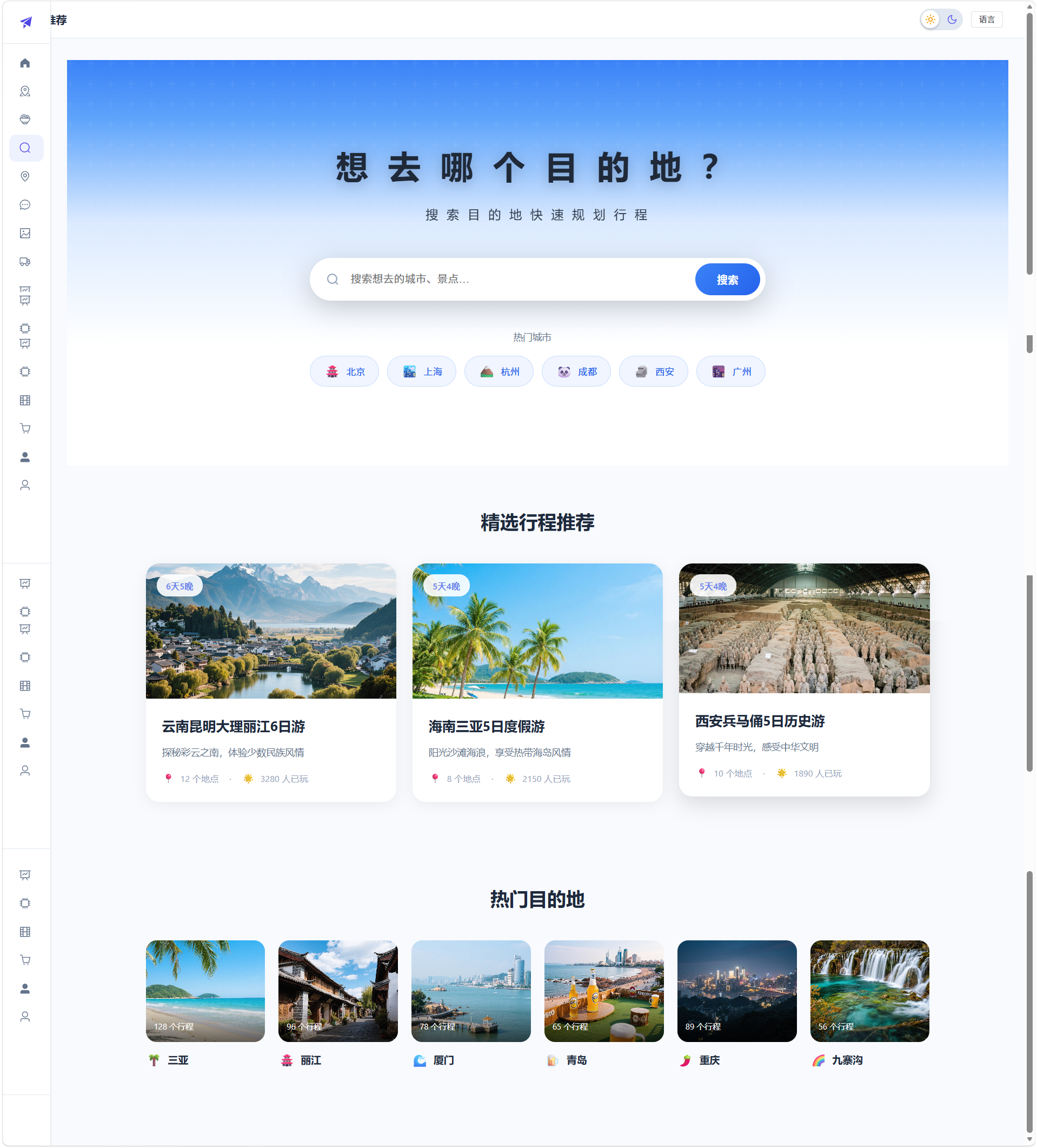
参考 pitravel.cn 风格,采用大标题搜索区域设计。顶部"想去哪个目的地?"引导文案,圆角搜索框支持回车触发,下方热门城市快捷按钮带 emoji 图标,底部精选行程卡片网格展示,点击跳转规划页。
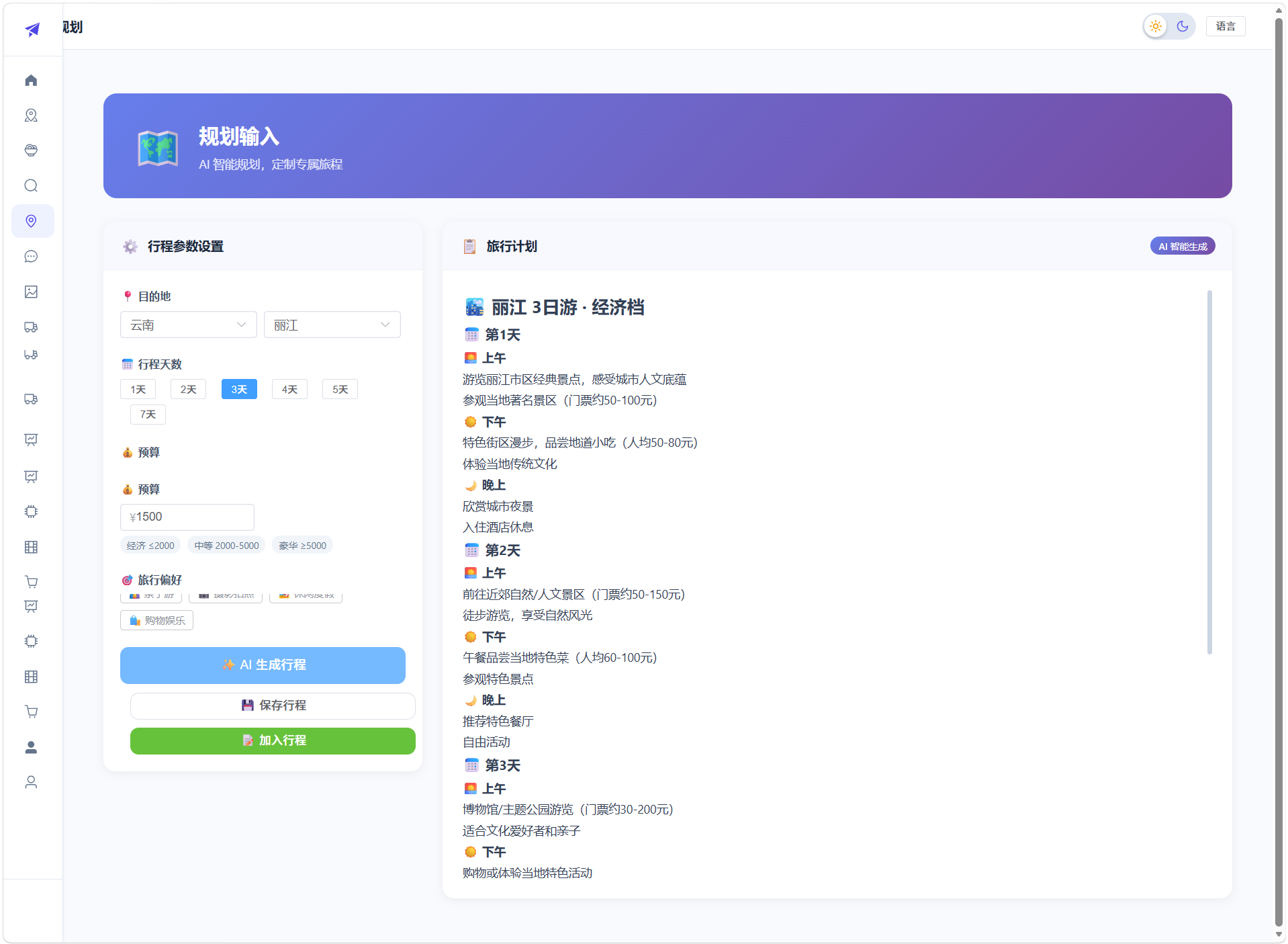
8.3 旅行规划页面
左右分栏布局。左侧配置面板:省份-城市级联选择器、行程天数快捷按钮(1/2/3/4/5/7天)、旅行偏好标签(自然风光/历史文化/美食探索等)。点击"AI生成行程"调用 DeepSeek API,右侧时间轴展示每日行程,含景点图片、名称、建议时长和地址。
8.4 我的行程页面
展示用户保存的所有行程,支持查看详情、导出为 HTML 行程单、生成分享链接、邀请协作者。行程详情页显示版本历史,可回溯到任意历史版本。
8.5 可视化大屏
深色主题,ECharts 渲染城市 TOP15 柱状图、省份分布条形图、评分分布饼图、美食菜系 TOP10、中国地图散点图(气泡大小表示景点密度),支持缩放和漫游。
8.6 系统界面展示
以下为各功能模块界面截图:
系统首页:
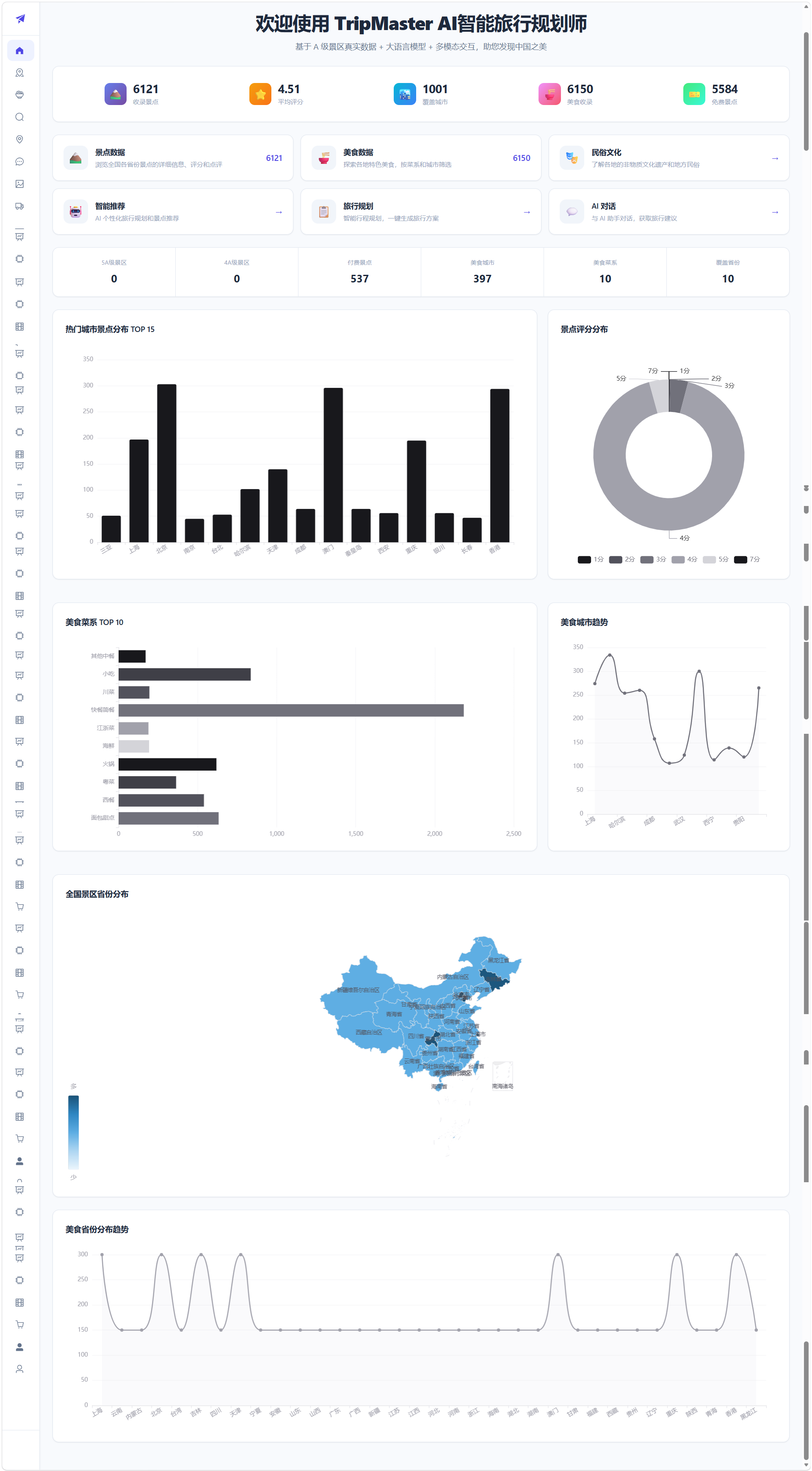
景点数据:
美食数据:
智能推荐:
旅行规划:
AI对话:
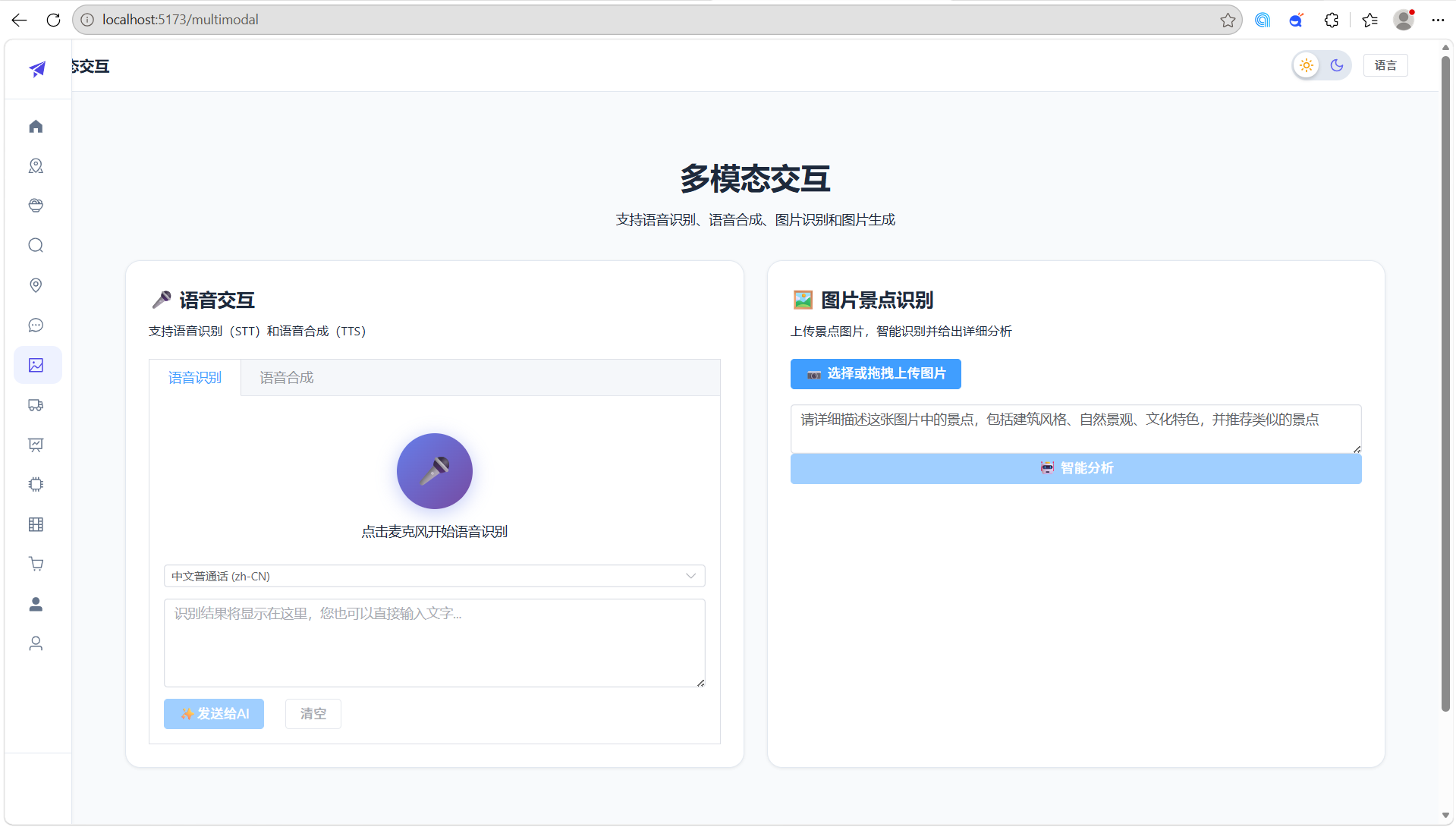
多模态交互:
出行服务:
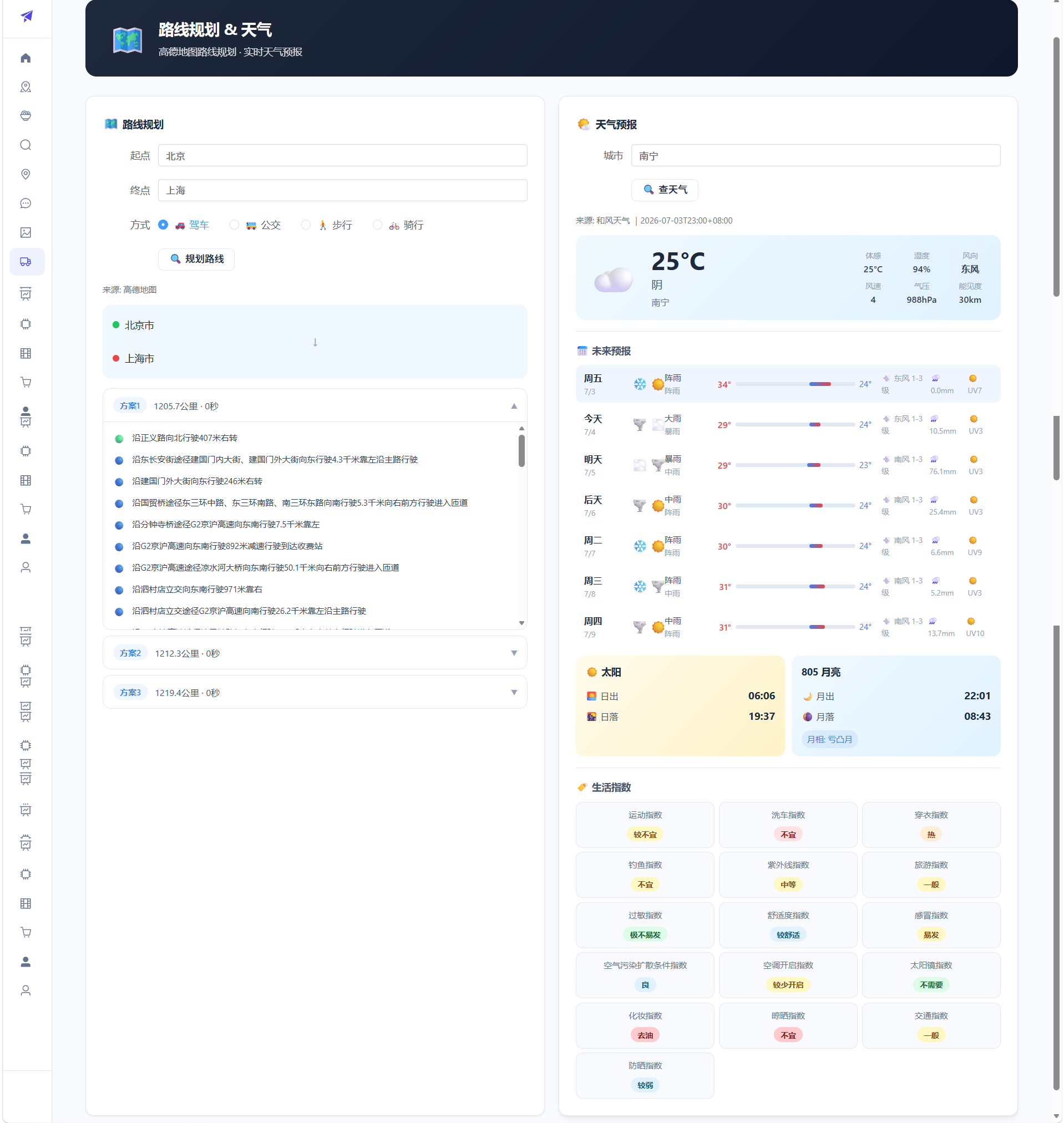
可视化大屏:
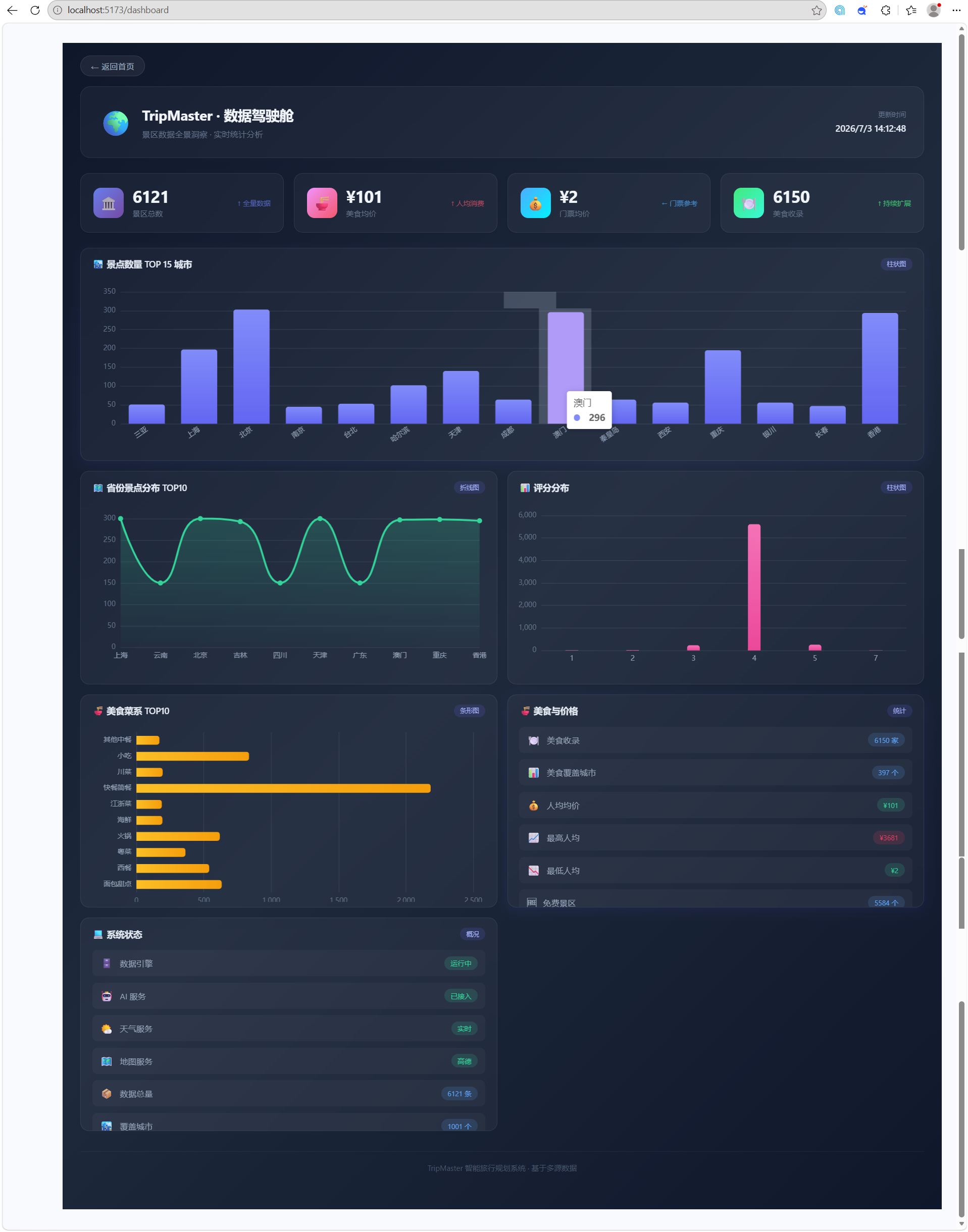
机器学习:
本地文化:
我的行程:
我的账户:
9. 系统部署与运行
系统需要 Python 3.9+ 和 Node.js 18+。后端依赖:pip install flask flask-cors pandas openpyxl requests。前端依赖:cd frontend && npm install。
# 终端1:启动后端
python "11李金灵.py"
# [SCENIC] 景点数据加载完成:6121条
# Running on http://127.0.0.1:5000
# 终端2:启动前端
cd frontend && npm run dev
# Local: http://localhost:5173/10. 视频展示
视频展示系统完整功能流程:首页浏览、景点筛选、智能推荐、行程生成、AI对话、多模态交互、可视化大屏、行程管理与协作。
系统演示视频:
旅游
11. AI使用说明
AI辅助范围:代码生成、算法设计咨询、UI设计参考、Bug调试。迭代过程:(1)引入DeepSeek实现AI行程生成;(2)参考pitravel.cn完善界面;(3)引入SA/GA优化行程编排;(4)增加疲劳度、开放时间、实时拥堵约束;(5)增加行程版本管理和协作编辑功能。
展示部分:

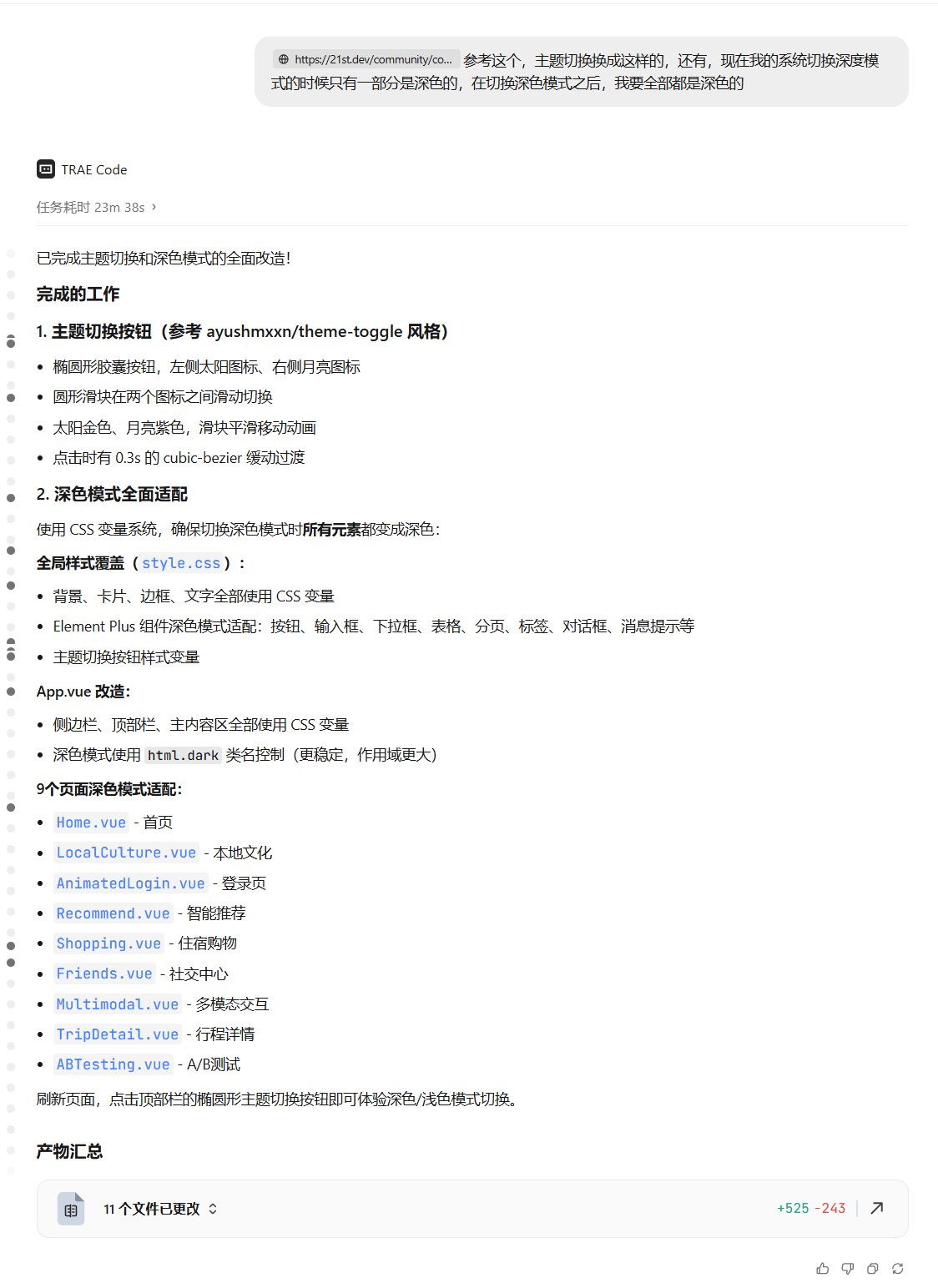
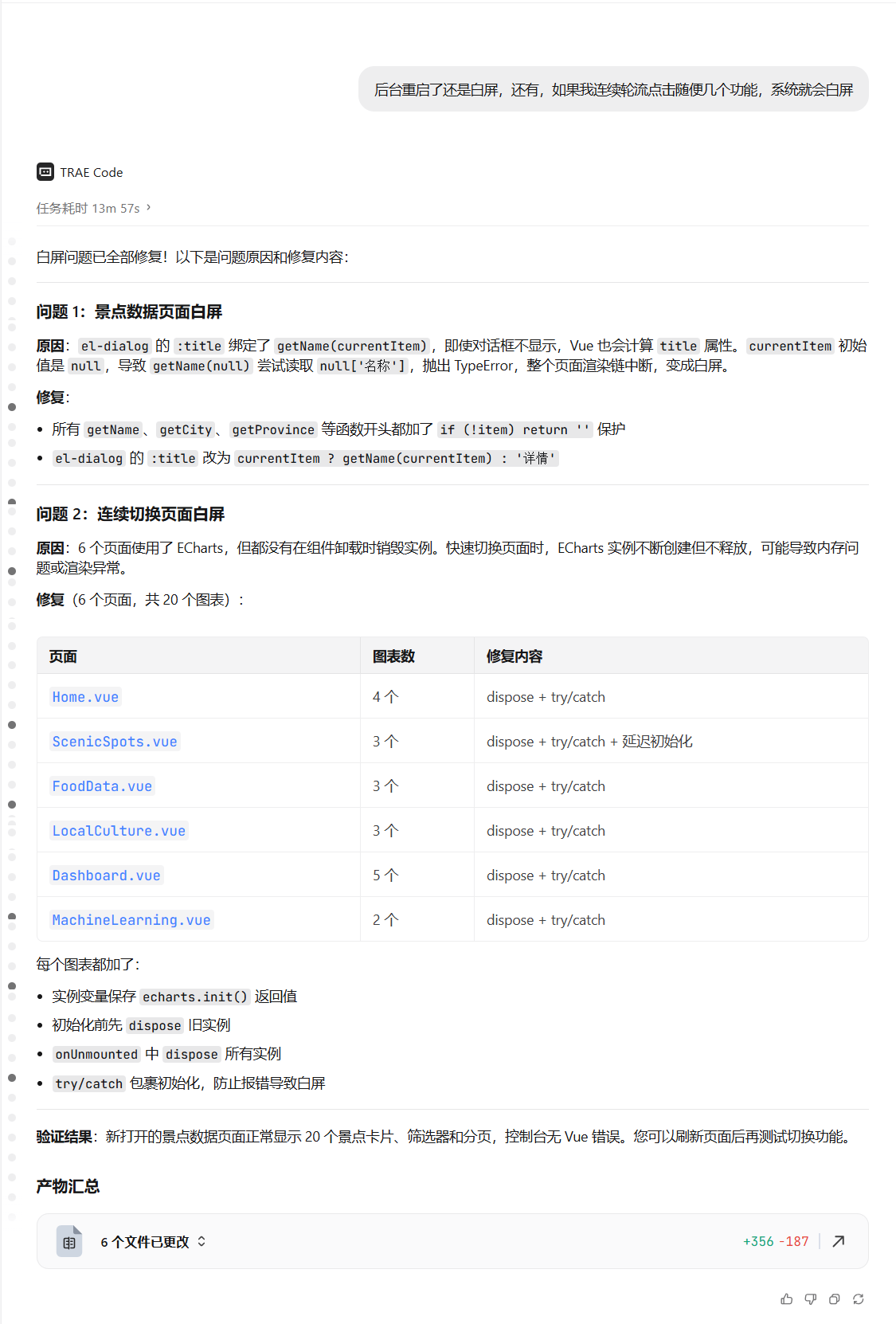
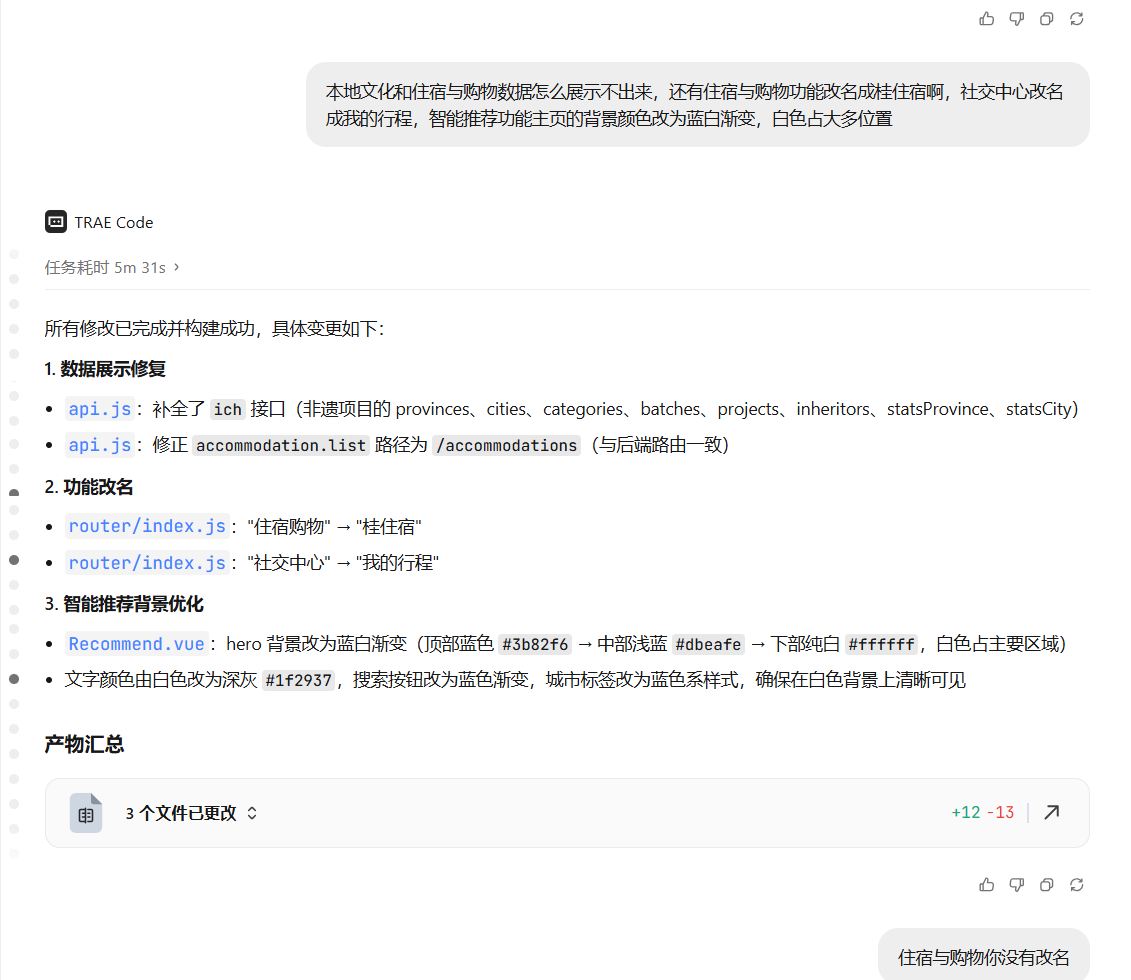
12. 总结
本文设计实现 TripMaster Pro 智能旅行规划系统,整合多源旅游数据,构建完整的后端服务基础设施(连接池、读写分离、缓存、监控),基于模拟退火与遗传算法实现智能行程优化,集成开放时间过滤、实时拥堵评估与疲劳度模型,接入DeepSeek大模型实现AI行程生成与智能对话,支持行程版本管理、协作编辑、社交分享与导出,以及语音交互、图片识别等多模态能力。系统采用前后端分离架构,界面简洁美观,功能丰富实用。未来方向:引入深度强化学习、接入实时交通数据、扩展多语言支持、精细化用户画像。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)