DeepSeek 发布新的推测解码方法 DSpark
DeepSeek 发布新的推测解码方法 DSpark
DeepSeek刚刚发布了DSpark for V4 Flash & Pro,这是一种新的推测解码方法,可将吞吐量提高51%至400%!DS还表明,DSpark对于Gemma和Qwen等其他模型也表现良好!
注意:DeepSeek-V4-Pro-DSpark并非新模型,而是在原有版本的基础上增加了一个推测性解码模块。文件夹中提供了一个最小推理示例inference。更多详情,请参阅:https://github.com/deepseek-ai/DeepSpec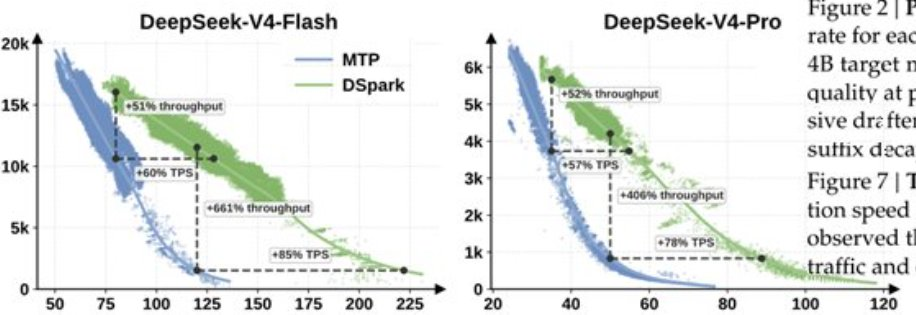
介绍
我们推出DeepSeek-V4系列的预览版,其中包括两个强大的混合专家 (MoE) 语言模型——DeepSeek -V4-Pro(1.6T 参数,已激活 49B)和DeepSeek-V4-Flash (284B 参数,已激活 13B)——两者均支持一百万个标记的上下文长度。
DeepSeek-V4系列在架构和优化方面进行了多项关键升级:
- 混合注意力架构:我们设计了一种混合注意力机制,结合了压缩稀疏注意力(CSA)和高度压缩注意力(HCA),以显著提高长上下文效率。在 100 万个词元的上下文设置下,与 DeepSeek-V3.2 相比,DeepSeek-V4-Pro 仅需27% 的单词元推理浮点运算次数和10% 的键值缓存。
- 流形约束超连接(mHC):我们引入 mHC 来加强传统的残差连接,增强跨层信号传播的稳定性,同时保持模型的表达能力。
- Muon优化器:我们采用Muon优化器以实现更快的收敛速度和更高的训练稳定性。
我们使用超过32T 个多样化且高质量的词元对两个模型进行预训练,随后进行全面的后训练流程。后训练流程采用两阶段范式:首先,通过 SFT 和 GRPO 强化学习独立培养领域特定专家;其次,通过策略内蒸馏进行统一模型整合,将不同领域的专家技能整合到一个模型中。
DeepSeek-V4-Pro-Max是 DeepSeek-V4-Pro 的最高推理模式,显著提升了开源模型的知识能力,稳居目前最佳开源模型之列。它在编码基准测试中取得了顶尖性能,并在推理和智能体任务方面显著缩小了与领先的闭源模型之间的差距。同时,DeepSeek-V4-Flash-Max在拥有更大的推理预算时,其推理性能与 Pro 版本相当,但由于其参数规模较小,在纯知识任务和最复杂的智能体工作流程方面自然略逊一筹。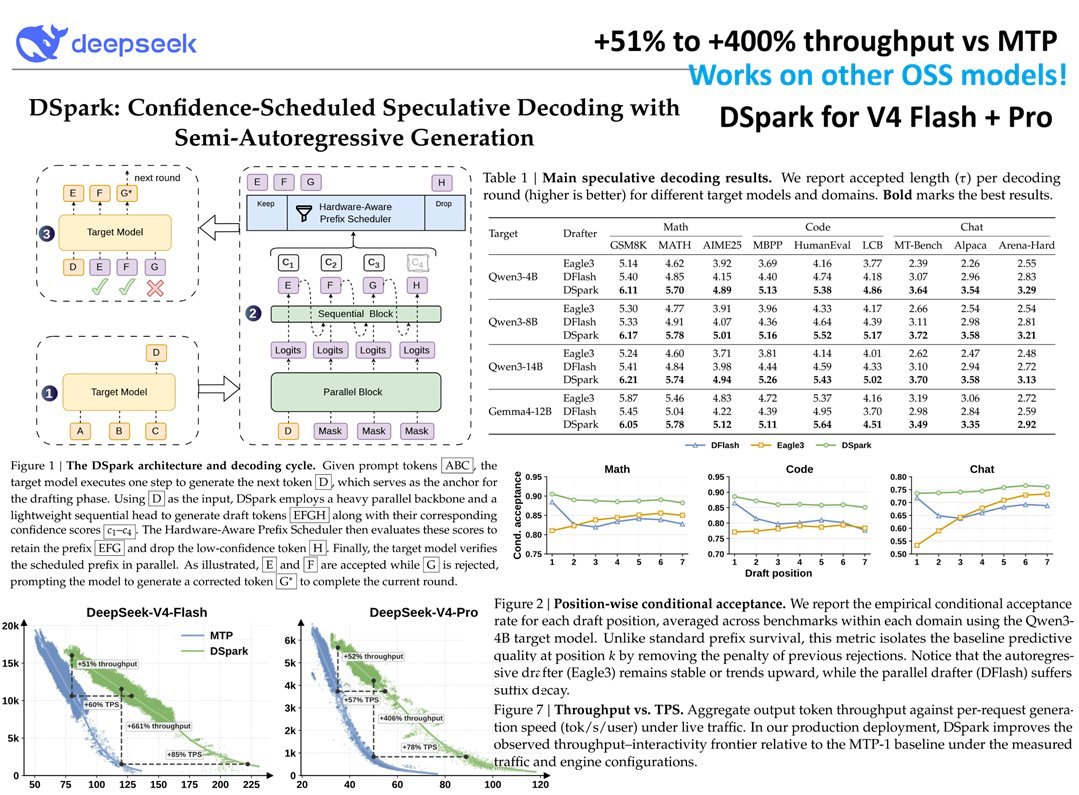
Model Downloads
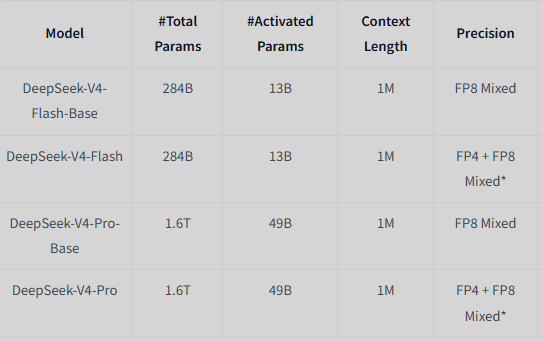
| Model | #Total Params | #Activated Params | Context Length | Precision | Download |
|---|---|---|---|---|---|
| DeepSeek-V4-Flash-Base | 284B | 13B | 1M | FP8 Mixed | HuggingFace | ModelScope |
| DeepSeek-V4-Flash | 284B | 13B | 1M | FP4 + FP8 Mixed* | HuggingFace | ModelScope |
| DeepSeek-V4-Pro-Base | 1.6T | 49B | 1M | FP8 Mixed | HuggingFace | ModelScope |
| DeepSeek-V4-Pro | 1.6T | 49B | 1M | FP4 + FP8 Mixed* | HuggingFace | ModelScope |
* FP4 + FP8 Mixed: MoE expert parameters use FP4 precision; most other parameters use FP8.
Evaluation Results — Base Model
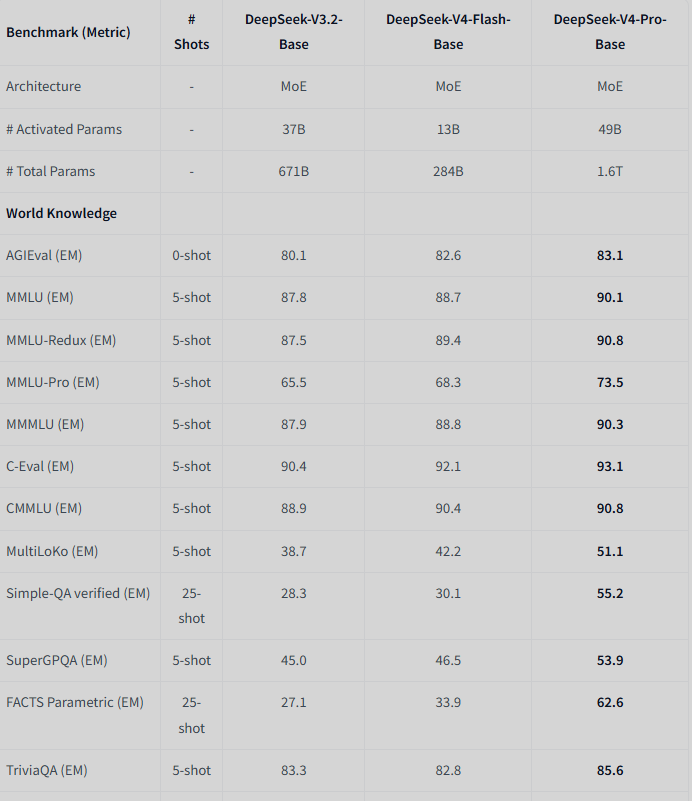
| Category | Benchmark (Metric) | # Shots | DeepSeek-V3.2-Base | DeepSeek-V4-Flash-Base | DeepSeek-V4-Pro-Base |
|---|---|---|---|---|---|
| Architecture | Architecture | - | MoE | MoE | MoE |
| Params | # Activated Params | - | 37B | 13B | 49B |
| Params | # Total Params | - | 671B | 284B | 1.6T |
| World Knowledge | AGIEval (EM) | 0-shot | 80.1 | 82.6 | 83.1 |
| World Knowledge | MMLU (EM) | 5-shot | 87.8 | 88.7 | 90.1 |
| World Knowledge | MMLU-Redux (EM) | 5-shot | 87.5 | 89.4 | 90.8 |
| World Knowledge | MMLU-Pro (EM) | 5-shot | 65.5 | 68.3 | 73.5 |
| World Knowledge | MMMLU (EM) | 5-shot | 87.9 | 88.8 | 90.3 |
| World Knowledge | C-Eval (EM) | 5-shot | 90.4 | 92.1 | 93.1 |
| World Knowledge | CMMLU (EM) | 5-shot | 88.9 | 90.4 | 90.8 |
| World Knowledge | MultiLoKo (EM) | 5-shot | 38.7 | 42.2 | 51.1 |
| World Knowledge | Simple-QA verified (EM) | 25-shot | 28.3 | 30.1 | 55.2 |
| World Knowledge | SuperGPQA (EM) | 5-shot | 45.0 | 46.5 | 53.9 |
| World Knowledge | FACTS Parametric (EM) | 25-shot | 27.1 | 33.9 | 62.6 |
| World Knowledge | TriviaQA (EM) | 5-shot | 83.3 | 82.8 | 85.6 |
| Language & Reasoning | BBH (EM) | 3-shot | 87.6 | 86.9 | 87.5 |
| Language & Reasoning | DROP (F1) | 1-shot | 88.2 | 88.6 | 88.7 |
| Language & Reasoning | HellaSwag (EM) | 0-shot | 86.4 | 85.7 | 88.0 |
| Language & Reasoning | WinoGrande (EM) | 0-shot | 78.9 | 79.5 | 81.5 |
| Language & Reasoning | CLUEWSC (EM) | 5-shot | 83.5 | 82.2 | 85.2 |
| Code & Math | BigCodeBench (Pass@1) | 3-shot | 63.9 | 56.8 | 59.2 |
| Code & Math | HumanEval (Pass@1) | 0-shot | 62.8 | 69.5 | 76.8 |
| Code & Math | GSM8K (EM) | 8-shot | 91.1 | 90.8 | 92.6 |
| Code & Math | MATH (EM) | 4-shot | 60.5 | 57.4 | 64.5 |
| Code & Math | MGSM (EM) | 8-shot | 81.3 | 85.7 | 84.4 |
| Code & Math | CMath (EM) | 3-shot | 92.6 | 93.6 | 90.9 |
| Long Context | LongBench-V2 (EM) | 1-shot | 40.2 | 44.7 | 51.5 |
Reasoning Mode
DeepSeek-V4-Pro 和 DeepSeek-V4-Flash 都支持三种推理强度模式:
| Reasoning Mode | Characteristics | Typical Use Cases | Response Format |
|---|---|---|---|
| Non-think | Fast, intuitive responses | Routine daily tasks, low-risk decisions | summary |
| Think High | Conscious logical analysis, slower but more accurate | Complex problem-solving, planning | <think> thinking summary |
| Think Max | Push reasoning to its fullest extent | Exploring the boundary of model reasoning capability | Special system prompt + <think> thinking summary |
DeepSeek-V4-Pro-Max vs Frontier Models
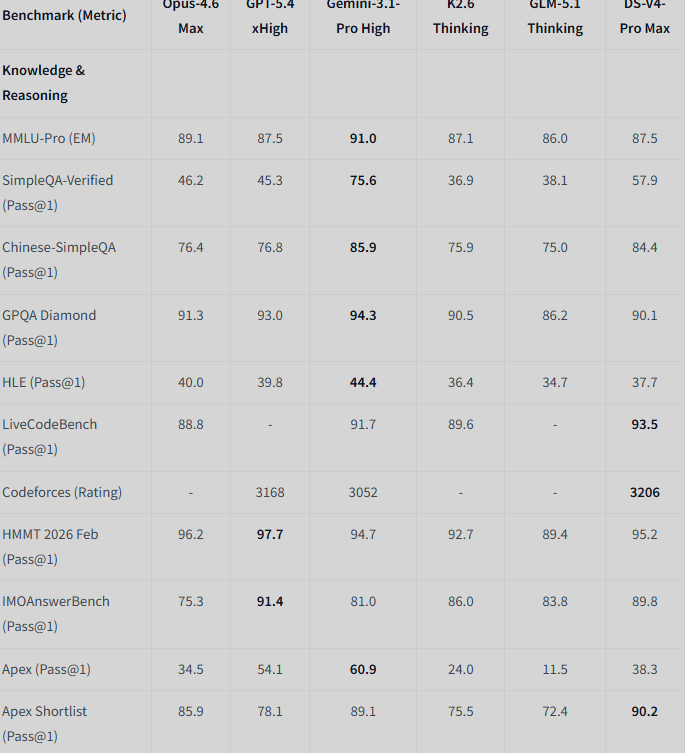
| Category | Benchmark (Metric) | Opus-4.6 Max | GPT-5.4 xHigh | Gemini-3.1-Pro High | K2.6 Thinking | GLM-5.1 Thinking | DS-V4-Pro Max |
|---|---|---|---|---|---|---|---|
| Knowledge & Reasoning | MMLU-Pro (EM) | 89.1 | 87.5 | 91.0 | 87.1 | 86.0 | 87.5 |
| Knowledge & Reasoning | SimpleQA-Verified (Pass@1) | 46.2 | 45.3 | 75.6 | 36.9 | 38.1 | 57.9 |
| Knowledge & Reasoning | Chinese-SimpleQA (Pass@1) | 76.4 | 76.8 | 85.9 | 75.9 | 75.0 | 84.4 |
| Knowledge & Reasoning | GPQA Diamond (Pass@1) | 91.3 | 93.0 | 94.3 | 90.5 | 86.2 | 90.1 |
| Knowledge & Reasoning | HLE (Pass@1) | 40.0 | 39.8 | 44.4 | 36.4 | 34.7 | 37.7 |
| Knowledge & Reasoning | LiveCodeBench (Pass@1) | 88.8 | - | 91.7 | 89.6 | - | 93.5 |
| Knowledge & Reasoning | Codeforces (Rating) | - | 3168 | 3052 | - | - | 3206 |
| Knowledge & Reasoning | HMMT 2026 Feb (Pass@1) | 96.2 | 97.7 | 94.7 | 92.7 | 89.4 | 95.2 |
| Knowledge & Reasoning | IMOAnswerBench (Pass@1) | 75.3 | 91.4 | 81.0 | 86.0 | 83.8 | 89.8 |
| Knowledge & Reasoning | Apex (Pass@1) | 34.5 | 54.1 | 60.9 | 24.0 | 11.5 | 38.3 |
| Knowledge & Reasoning | Apex Shortlist (Pass@1) | 85.9 | 78.1 | 89.1 | 75.5 | 72.4 | 90.2 |
| Long Context | MRCR 1M (MMR) | 92.9 | - | 76.3 | - | - | 83.5 |
| Long Context | CorpusQA 1M (ACC) | 71.7 | - | 53.8 | - | - | 62.0 |
| Agentic | Terminal Bench 2.0 (Acc) | 65.4 | 75.1 | 68.5 | 66.7 | 63.5 | 67.9 |
| Agentic | SWE Verified (Resolved) | 80.8 | - | 80.6 | 80.2 | - | 80.6 |
| Agentic | SWE Pro (Resolved) | 57.3 | 57.7 | 54.2 | 58.6 | 58.4 | 55.4 |
| Agentic | SWE Multilingual (Resolved) | 77.5 | - | - | 76.7 | 73.3 | 76.2 |
| Agentic | BrowseComp (Pass@1) | 83.7 | 82.7 | 85.9 | 83.2 | 79.3 | 83.4 |
| Agentic | HLE w/ tools (Pass@1) | 53.1 | 52.0 | 51.6 | 54.0 | 50.4 | 48.2 |
| Agentic | GDPval-AA (Elo) | 1619 | 1674 | 1314 | 1482 | 1535 | 1554 |
| Agentic | MCPAtlas Public (Pass@1) | 73.8 | 67.2 | 69.2 | 66.6 | 71.8 | 73.6 |
| Agentic | Toolathlon (Pass@1) | 47.2 | 54.6 | 48.8 | 50.0 | 40.7 | 51.8 |
Comparison across Modes
| Category | Benchmark (Metric) | V4-Flash Non-Think | V4-Flash High | V4-Flash Max | V4-Pro Non-Think | V4-Pro High | V4-Pro Max |
|---|---|---|---|---|---|---|---|
| Knowledge & Reasoning | MMLU-Pro (EM) | 83.0 | 86.4 | 86.2 | 82.9 | 87.1 | 87.5 |
| Knowledge & Reasoning | SimpleQA-Verified (Pass@1) | 23.1 | 28.9 | 34.1 | 45.0 | 46.2 | 57.9 |
| Knowledge & Reasoning | Chinese-SimpleQA (Pass@1) | 71.5 | 73.2 | 78.9 | 75.8 | 77.7 | 84.4 |
| Knowledge & Reasoning | GPQA Diamond (Pass@1) | 71.2 | 87.4 | 88.1 | 72.9 | 89.1 | 90.1 |
| Knowledge & Reasoning | HLE (Pass@1) | 8.1 | 29.4 | 34.8 | 7.7 | 34.5 | 37.7 |
| Knowledge & Reasoning | LiveCodeBench (Pass@1) | 55.2 | 88.4 | 91.6 | 56.8 | 89.8 | 93.5 |
| Knowledge & Reasoning | Codeforces (Rating) | - | 2816 | 3052 | - | 2919 | 3206 |
| Knowledge & Reasoning | HMMT 2026 Feb (Pass@1) | 40.8 | 91.9 | 94.8 | 31.7 | 94.0 | 95.2 |
| Knowledge & Reasoning | IMOAnswerBench (Pass@1) | 41.9 | 85.1 | 88.4 | 35.3 | 88.0 | 89.8 |
| Knowledge & Reasoning | Apex (Pass@1) | 1.0 | 19.1 | 33.0 | 0.4 | 27.4 | 38.3 |
| Knowledge & Reasoning | Apex Shortlist (Pass@1) | 9.3 | 72.1 | 85.7 | 9.2 | 85.5 | 90.2 |
| Long Context | MRCR 1M (MMR) | 37.5 | 76.9 | 78.7 | 44.7 | 83.3 | 83.5 |
| Long Context | CorpusQA 1M (ACC) | 15.5 | 59.3 | 60.5 | 35.6 | 56.5 | 62.0 |
| Agentic | Terminal Bench 2.0 (Acc) | 49.1 | 56.6 | 56.9 | 59.1 | 63.3 | 67.9 |
| Agentic | SWE Verified (Resolved) | 73.7 | 78.6 | 79.0 | 73.6 | 79.4 | 80.6 |
| Agentic | SWE Pro (Resolved) | 49.1 | 52.3 | 52.6 | 52.1 | 54.4 | 55.4 |
| Agentic | SWE Multilingual (Resolved) | 69.7 | 70.2 | 73.3 | 69.8 | 74.1 | 76.2 |
| Agentic | BrowseComp (Pass@1) | - | 53.5 | 73.2 | - | 80.4 | 83.4 |
| Agentic | HLE w/ tools (Pass@1) | - | 40.3 | 45.1 | - | 44.7 | 48.2 |
| Agentic | MCPAtlas (Pass@1) | 64.0 | 67.4 | 69.0 | 69.4 | 74.2 | 73.6 |
| Agentic | GDPval-AA (Elo) | - | - | 1395 | - | - | 1554 |
| Agentic | Toolathlon (Pass@1) | 40.7 | 43.5 | 47.8 | 46.3 | 49.0 | 51.8 |

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 1
1 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)