基于大模型的简历筛选与匹配系统,多版本简历管理模块、多维条件职位检索与收藏模块、基于DeepSeek大语言模型API的简历智能分析与优化
第1章 引 言
1.1 研究背景与意义
近年来,我国数字经济与平台经济深度融合,线上招聘已成为劳动力市场供需匹配的核心渠道。人社部统计数据显示,2024年全国人力资源服务机构通过网络发布的招聘求职信息总量突破6.8亿条,在线招聘市场用户规模达到2.3亿人,日均活跃简历投递量超过800万次。与此同时,单个求职者平均浏览岗位数从2019年的42个上升至2024年的137个,信息过载现象愈发严重。从结构层面审视,招聘市场长期存在“两难”困局:求职端面临岗位筛选低效、职业定位模糊、简历质量参差等问题;企业端则苦于简历筛选周期长、人岗匹配精准度不足。工业和信息化部人才交流中心发布的《人工智能产业人才发展报告》指出,当前招聘领域的技术应用仍以关键词匹配和规则过滤为主,语义理解层面的智能化程度不足,难以从海量非结构化文本中提取候选人的隐性能力特征。
学术界对智能招聘的研究大致沿两条路径展开:一是基于传统机器学习算法的简历解析与岗位分类,多采用TF-IDF特征结合朴素贝叶斯或支持向量机模型,受限于特征工程复杂度,泛化能力有限;二是协同过滤与矩阵分解驱动的推荐策略,在冷启动和数据稀疏场景下表现欠佳。梳理现有成果可发现三个突出短板:信息采集环节较少关注招聘平台结构化数据的系统性获取与更新,分析环节中简历评分的可解释性与交互实时性有待加强,决策辅助层面缺乏将岗位趋势、薪资预测与个人竞争力分析整合为闭环功能的设计。上述不足促使选择从“数据采集—智能分析—精准推荐—决策辅助”的全链路视角切入,在已有研究侧重单点技术优化的基础上,引入大语言模型的语义推理能力与梯度提升树回归算法,构建一个覆盖求职全流程的智能分析系统,重点解决简历结构化评估的模糊性问题和薪资区间预测的定量支撑问题。
本研究的实践意义体现在多个维度。从求职者角度看,系统提供的AI简历优化功能可将原本依赖人工经验的修改过程转化为可量化、可迭代的分析反馈,降低简历打磨门槛;薪资预测模块则利用历史岗位数据的统计规律为议价环节提供参考依据,减少信息不对称带来的薪资偏差。从招聘平台运营方角度看,后台数据分析看板整合了职位热度趋势、行业竞争度、地域机会分布等多维指标,为市场研判与资源配置提供了数据驱动手段。从学科交叉角度而言,本研究将大语言模型的自然语言理解能力嵌入传统招聘信息系统的业务逻辑,为自然语言处理技术在人力资源垂直领域的落地探索了可行路径;同时将XGBoost回归模型应用于薪资区间预测,丰富了梯度提升框架在结构化表格数据预测任务中的实践案例。研究还为高校就业指导部门、企业人力资源部门提供了可参考的技术选型方案与系统设计思路,具有较强的应用推广价值。
1.2 国内外研究现状
在智能招聘与简历分析领域,国内外学者围绕自然语言处理、推荐算法、系统架构设计等方向开展了持续探索,技术路线呈现从规则驱动向数据驱动、从单一功能向全流程覆盖的演进趋势。
杨木广针对简历筛选环节信息噪声多、初筛效率低的问题,提出基于数字人的简历筛选优化方案,通过构建虚拟人力资源专员角色介入筛选流程,将重复性人工判断转化为自动化流水线处理,降低了对招聘人员经验的依赖。该研究在流程自动化设计上取得了进展,但数字人的语义理解模块仍依赖预设规则库,对非结构化简历中开放域描述的提取能力有限。王先淏着眼于简历与岗位描述之间的深层语义关联,采用对比学习框架将简历文本和职位需求映射至同一向量空间,通过拉近正样本对、推远负样本对的训练策略提升匹配精度。该方法在公开数据集上取得了优于传统孪生网络的表现,但模型依赖高质量标注数据,在岗位类别覆盖不全的稀疏场景下泛化效果有所下降。
段振花将研究对象聚焦于招聘信息本身,设计了一套基于自然语言处理技术的招聘信息智能解析工具,从岗位描述中自动抽取职位名称、技能要求、学历门槛等结构化字段,并整合为就业指导软件提供给高校就业中心使用。该研究在信息抽取规则的可配置性上做出了尝试,但抽取流程对网页模板变动的自适应性有待提高。张翔洲则从系统工程角度出发,构建了集职位发布、简历投递、初筛匹配于一体的在线招聘管理系统,在业务功能完整性上形成了参考框架,但智能匹配模块仍采用关键词加权打分机制,语义覆盖深度受限。
在职位推荐领域,郝雅如基于人力资源大数据平台,提出结合岗位内容特征与求职者行为序列的智能匹配算法,利用历史投递行为数据构建偏好模型,在一定程度上缓解了冷启动阶段的推荐质量衰减问题。姜正泽进一步将简历分析结果与动态用户画像相结合,设计了混合推荐算法,使推荐结果能够随用户行为的累积逐步调整优化。李梦从用户行为日志出发,将点击、收藏、投递等隐式反馈信号纳入推荐模型训练,在真实业务场景中验证了行为信号对推荐准确率的正向作用。吴思渺则从文本分类入手,将技能集的提取与匹配作为推荐的核心依据,在计算机类岗位的匹配测试中取得了较高的准确率。
在组织管理与招聘伦理层面,付桃红从民营企业数字化转型的视角讨论了敏捷型组织中职位管理的重构路径,指出传统岗位说明书模式难以适应快速迭代的业务需求。楼湘萍通过实验方法研究了人工智能招聘系统对求职者公平感知的影响,发现算法透明度显著影响用户对筛选结果的接受程度。唐贵瑶和孙倩从管理学视角梳理了AI招聘面临的技术边界与治理困境,提出了“人机协同、分级决策”的应对策略框架。李怡霏从产业生态角度展望了人工智能重塑全场景招聘的潜在方向。
在国外研究中,Daryani等人较早探讨了自然语言处理与相似度计算在自动化简历筛选中的应用,将简历与岗位需求的匹配问题形式化为文本相似度度量任务。Gao等人面向医疗围术期场景,提出了一种部署友好的大语言模型微调策略LoRA,在保护隐私的前提下完成了并发症检测任务的模型适配,其低资源微调思路对大语言模型在招聘垂直领域的轻量化部署具有参考价值。
综合来看,现有研究在简历解析、匹配推荐、系统构建等方面为智能招聘领域奠定了扎实基础,技术重心正从传统机器学习向大语言模型迁移。但现有工作仍存在三个方面的拓展空间:一是数据采集环节对招聘平台原始数据的结构化复用关注不足,二是简历分析模块中AI评分的可解释性与交互实时性有待增强,三是较少将岗位趋势研判、薪资定量预测与个人竞争力评估整合为一体化决策辅助功能。本研究在上述成果基础上,着力构建涵盖数据采集、简历分析、薪资预测与多维数据看板的完整系统,探索大语言模型与梯度提升树回归在招聘垂直场景中的协同应用路径。
1.3 主要研究内容及章节安排
本研究围绕“数据采集—智能分析—精准推荐—决策辅助”的全链路目标,设计并实现一套基于大语言模型与机器学习算法的招聘信息采集与职业需求分析系统。具体研究内容包括四个方面:一是招聘数据的结构化采集与存储,设计网络爬虫程序完成对主流招聘平台职位列表页与详情页的多维字段提取,构建涵盖岗位名称、薪资范围、行业属性、技能标签等信息的标准化数据集,并基于SQLite关系型数据库完成持久化存储与查询优化。二是基于大语言模型的简历智能分析模块,设计内置提示词模板将简历内容结构化为自然语言对话输入,调用DeepSeek大语言模型API实现对简历完整性、技能匹配度和职业竞争力的三维评分,通过服务器推送事件机制将分析结果以流式响应实时输出至前端,同步支持AI简历生成与优化建议的交互式应用。三是XGBoost回归模型驱动的薪资预测模块,以岗位名称、行业类别、工作城市、公司性质和公司规模为特征变量,训练梯度提升树回归模型,输出月薪估计值及置信区间,并同步展示特征重要性排序与相似职位参考记录,为求职者的薪资议价环节提供定量参考依据。四是多维数据分析与可视化看板,面向管理员用户提供职位热度趋势、行业竞争度分析、地域机会分布等统计功能,集成ECharts图表库实现词云图、饼图、柱状图等多种可视化呈现方式,辅助进行就业市场宏观研判。系统采用Flask轻量级Web框架整合各功能模块,前端基于Bootstrap响应式布局实现多页面路由与模态框交互,通过JWT令牌机制保障接口访问安全,最终形成一个功能完整、交互流畅的智能招聘辅助平台。
本文围绕招聘信息采集与职业需求分析系统的设计与实现展开论述,全文共分为七章,各章内容安排如下。
第一章为绪论,阐述选题的研究背景与意义,分析当前招聘市场在信息过载、人才匹配效率方面的现实困境,在梳理国内外智能招聘、简历分析及推荐算法等领域研究现状的基础上,指出现有工作在数据采集系统性、分析可解释性及功能整合度方面的不足,进而明确本文的研究切入点与主要工作内容。
第二章为相关技术及理论,对系统开发所依赖的关键技术进行原理性说明,包括Flask轻量级Web框架与JWT认证机制、SQLAlchemy对象关系映射与SQLite数据持久化方案、DeepSeek大语言模型的流式调用与提示词工程、XGBoost梯度提升回归算法的数学基础与正则化策略,以及多策略融合推荐方法的权重模型,为后续章节的系统设计与实现提供理论支撑。
第三章为系统分析,从经济可行性、技术可行性和操作可行性三个维度论证系统开发的现实条件,通过业务流程图和用例图详细描述职位搜索与收藏、简历管理与AI分析、AI简历生成与优化、薪资预测及管理后台数据分析等核心业务流程,并依据角色权限对功能需求进行分类梳理,同时从性能、安全性、可用性和可维护性四个方面定义非功能性需求。
第四章为系统总体设计,采用分层架构思想描述数据从存储层到前端展示层的完整流动路径,绘制系统总体架构图与功能模块划分图,明确六大功能模块的边界与职责,在此基础上完成关系型数据库的实体关系建模,并以三线表形式逐一列出用户、简历、职位、收藏记录及分析记录五张核心数据表的结构定义。
第五章为系统开发与实现,首先以表格形式给出系统的软硬件开发环境配置,随后依次阐述数据采集模块的Selenium驱动策略与结构化提取方法、数据处理模块的CSV批量导入与首次启动初始化机制,以及六大功能模块的前后端协同实现过程,重点说明流式响应传输、提示词模板构建、评分动画渲染、模型推理调用和图表可视化等关键实现环节,并展示各模块的运行效果界面。
第六章为系统测试,明确黑盒测试的目的与方法,针对数据导入、职位搜索、简历管理、AI分析、薪资预测、职位推荐和管理后台七个模块编写四十二项测试用例,逐项验证功能逻辑与异常处理能力,对测试中发现的流式重连丢失、编码器未知标签异常和词云渲染超时三项问题进行修正,最终给出测试结论。
第七章为总结与展望,对系统在功能完整性、智能化水平和用户体验方面取得的成果进行归纳,客观分析在模型数据时效性、推荐算法鲁棒性、弱网环境稳定性及移动端适配方面存在的优化空间,并对后续研究方向进行展望。
第2章 相关技术及理论
2.1 Flask轻量级Web框架
Flask是用Python编写的微型Web框架,其核心设计理念是保持内核简洁而通过扩展机制按需引入功能。系统选用Flask作为后端服务基础,主要基于三点考量:框架内置的Jinja2模板引擎支持服务端渲染与前端SPA路由的结合,Werkzeug工具集提供了稳健的WSGI服务器接口,Blueprint蓝图机制便于将用户认证、简历管理、职位搜索、AI分析及管理后台等功能模块解耦为独立组件。系统定义了六个蓝图实例,分别挂载于“/api/auth”“/api/resume”“/api/job”“/api/ai”“/api/admin”“/api”等URL前缀下,每个蓝图内部通过装饰器将视图函数映射为RESTful风格的资源端点。前端与后端的数据交互统一采用JSON格式,跨域访问通过Flask-CORS扩展解决。
在身份认证环节,系统采用JSON Web Token(JWT)无状态方案。用户登录成功后,服务端使用HMAC-SHA256算法对包含用户标识、管理员标志和过期时间的载荷进行签名,生成形如“header.payload.signature”的令牌字符串。客户端后续请求在Authorization头中携带该令牌,服务端通过验证签名及过期时间完成鉴权。这种机制避免了服务端维护会话状态的存储开销,适合前后端分离架构。
2.2 数据持久化与对象关系映射
系统采用SQLite作为数据库引擎,其无需独立服务进程、零配置部署的特点契合轻量级Web应用的场景需求。数据访问层使用SQLAlchemy作为对象关系映射工具,将关系表结构映射为Python类,使开发者以面向对象方式操作数据。模型定义中通过db.Column()声明字段类型与约束,db.relationship()建立一对多关联,如User与Resume之间通过外键user_id形成级联删除关系。
数据查询方面,利用SQLAlchemy的链式过滤接口构建动态查询条件:当用户输入关键词时,通过or_()组合多个字段的contains()模糊匹配;分页功能借助paginate()方法完成总记录数统计与页面切片。在数据库初始化阶段,通过db.create_all()自动建表,并结合pandas读取CSV文件批量导入职位数据,减少手动配置工作量。
2.3 大语言模型与流式交互
系统接入DeepSeek大语言模型API实现简历智能分析、简历生成和简历优化三项核心功能。DeepSeek系列模型基于Transformer解码器架构,通过自回归方式逐词生成响应文本。模型在训练阶段使用海量语料学习语言模式与知识表示,使其具备语义理解、逻辑推理和结构化内容生成能力。在调用时,向API提交包含系统角色指令和用户提示词的消息列表,模型根据上文语境以概率最大化的方式生成后续字符序列。
提示词工程是实现可靠输出的关键。以简历分析为例,系统设计了一套包含角色设定、输出格式约束和评分解耦要求的模板化提示词,将简历的结构化字段逐项填充后形成完整请求。为改善长文本生成时的用户体验,调用采用流式传输模式:API以Server-Sent Events协议逐块返回增量内容,后端通过Python的requests库开启stream=True参数,对响应体按行解析data字段,再经由Flask的stream_with_context()生成器封装为SSE事件流推送至前端。前端EventSource接收到每个数据块后实时更新DOM,使得分析报告的呈现过程具有渐进加载的视觉效果,避免了长时间等待的焦虑感。
2.4 XGBoost梯度提升回归
薪资预测模块采用XGBoost回归模型,将离散的职位特征映射为连续月薪值。XGBoost本质上是梯度提升决策树算法的工程优化实现,其核心思想是通过迭代地训练多个CART回归树来逐步降低整体预测误差。每一轮迭代新增的树模型负责拟合上一轮预测结果与真实值之间的残差,最终将所有树的预测结果求和得到强学习器的输出。
特征工程阶段,系统将非数值型字段(职位名称、行业、城市、公司性质、公司规模)使用LabelEncoder编码为整型标识,薪资字段通过正则表达式解析后取上下限均值作为回归标签。模型训练完成后保存为pickle格式文件,预测时加载复用。此外,XGBoost提供了基于分裂次数或增益平均的特征重要性度量,该指标被用于薪资预测结果页面的可视化展示,帮助用户理解各因素对薪酬水平的影响程度。
2.5 多策略融合推荐算法
职位推荐模块采用加权融合策略,将内容匹配得分、协同过滤得分、热度得分、时间衰减得分和个性化得分按预设权重线性组合,形成最终推荐评分。权重配置分别为0.35、0.25、0.20、0.15、0.05,优先级向内容匹配倾斜。内容匹配得分通过职位名称是否包含求职意向词、技能标签与简历技能的共现数量等规则计算;协同过滤得分统计了收藏过相似职位的其他用户中同时收藏当前职位的人数比例;热度得分取浏览量与收藏量的归一化值;其中d为职位发布以来的天数。该机制使得新发布职位获得更高权重,避免了陈旧信息的持续霸榜。个性化得分依据用户历史收藏中行业与职位名称的重合度给予少量加分。多策略融合兼顾了文本相关性、群体行为信号与信息时效性,在一定程度上缓解了单一策略的片面性。
2.6 网络数据采集技术
职位数据来源于对主流招聘平台公开页面的自动化采集。使用Selenium驱动Chrome浏览器模拟用户行为,通过XPath和CSS选择器定位搜索框、翻页按钮与职位列表元素;页面渲染完成后,利用BeautifulSoup解析HTML文档树,提取目标字段并输出为CSV文件。为规避反爬检测,配置了窗口尺寸、User-Agent伪装和实验性选项排除自动化标记。采集分为列表采集与详情采集两个阶段,后者遍历已获取的职位链接逐一抓取详细描述、福利标签、公司简介等内容。最终经过清洗、去重、字段映射后导入系统数据库,为搜索、推荐与分析模块提供数据基础。
第3章 系统分析
3.1 可行性分析
经济可行性分析:本系统的开发成本主要几乎为0,开发工具方面,Python、Flask、SQLite等核心技术栈均为开源产品,无需支付许可费用。综上所述,系统从经济上是可行的。
技术可行性分析:后端采用Python语言与Flask轻量级Web框架,该技术组合在Web应用开发领域成熟度高,社区生态完善,文档资源丰富。数据层使用SQLite数据库配合SQLAlchemy对象关系映射工具,支持快速建表与查询优化,满足中小规模并发场景的存储需求。大语言模型方面,DeepSeek API提供了标准化的RESTful调用接口与流式响应支持,集成门槛较低。薪资预测模块基于XGBoost回归算法,该框架在结构化数据预测任务中经过广泛验证,模型训练与推理效率均可接受。前端采用Bootstrap响应式框架与ECharts可视化库,组件丰富且兼容主流浏览器。上述技术均属业界成熟方案,不存在未攻克的技术瓶颈。综上所述,系统从技术上是可行的。
操作可行性分析:系统前端界面采用Bootstrap导航栏与卡片式布局,页面切换通过哈希路由触发,各功能模块入口清晰可见,用户无需阅读操作手册即可凭直觉完成职位搜索、简历创建、AI分析触发等核心操作。职位搜索页面提供关键词、类型、地点、薪资四个维度的输入框,支持回车键快捷搜索;简历编辑采用模态框表单,字段标注明确,必填项带有校验提示。管理员后台集成了数据看板与分类表格,筛选条件以按钮与下拉框形式呈现,图表由ECharts自动渲染,无需手动配置。目标用户群体为具有基本计算机操作能力的求职者和人力资源从业者,操作习惯与常用网站保持一致。综上所述,系统从操作上是可行的。
3.2 需求分析
3.2.1 用户需求分析
本系统面向求职者和系统管理员两类用户。求职者的核心诉求可归纳为三点:高效地从海量岗位中定位匹配度较高的职位、获得对自身简历质量的客观评估与改进建议、在薪资议价环节获取市场参考数据。管理员的关注点则集中于就业市场的宏观态势把握,包括不同行业的冷热分布、各城市的岗位供给密度以及热门技能的需求强度变化。此外,未登录访客可浏览首页展示的系统功能介绍,了解平台核心价值后再决定是否注册,这一设计降低了用户接触门槛。
3.2.2 业务流程分析
本系统的核心业务涵盖六个流程:职位搜索与收藏、简历管理与AI分析、AI简历生成、AI简历优化、薪资预测以及管理后台数据分析,构成从求职准备到决策辅助的完整链路。
职位搜索与收藏流程中,用户进入搜索页面后输入关键词、职位类型、地点或薪资范围等条件,系统根据组合条件查询数据库并分页返回结果列表。用户浏览结果卡片上的岗位名称、公司信息、标签和薪资字段,对感兴趣的职位可通过按钮一键收藏,已收藏的职位在个人收藏页集中展示,支持取消收藏操作。该流程将分散的岗位信息聚合为可筛选、可标记的结构化列表,减少跨平台反复检索的时间消耗。
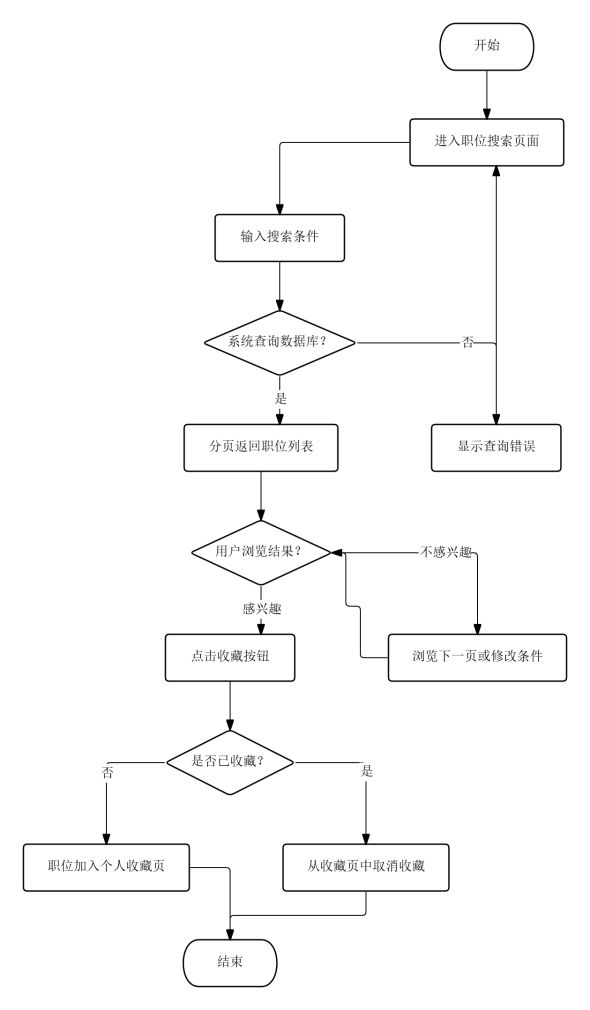
图3.1 职位搜索与收藏流程
简历管理与AI分析流程中,用户创建简历时填写标题、姓名、联系方式、求职意向、教育经历、工作经历、技能标签和自我评价等字段,提交后系统存入数据库。在分析页面选择一份已有简历并触发AI分析,后端将简历字段填充至提示词模板后调用DeepSeek API,分析结果以流式传输返回,实时渲染为包含完整性、技能匹配度和竞争力三项评分的分析报告。用户阅读报告后可据此手动修改简历,或直接使用AI优化功能获取润色后的版本。
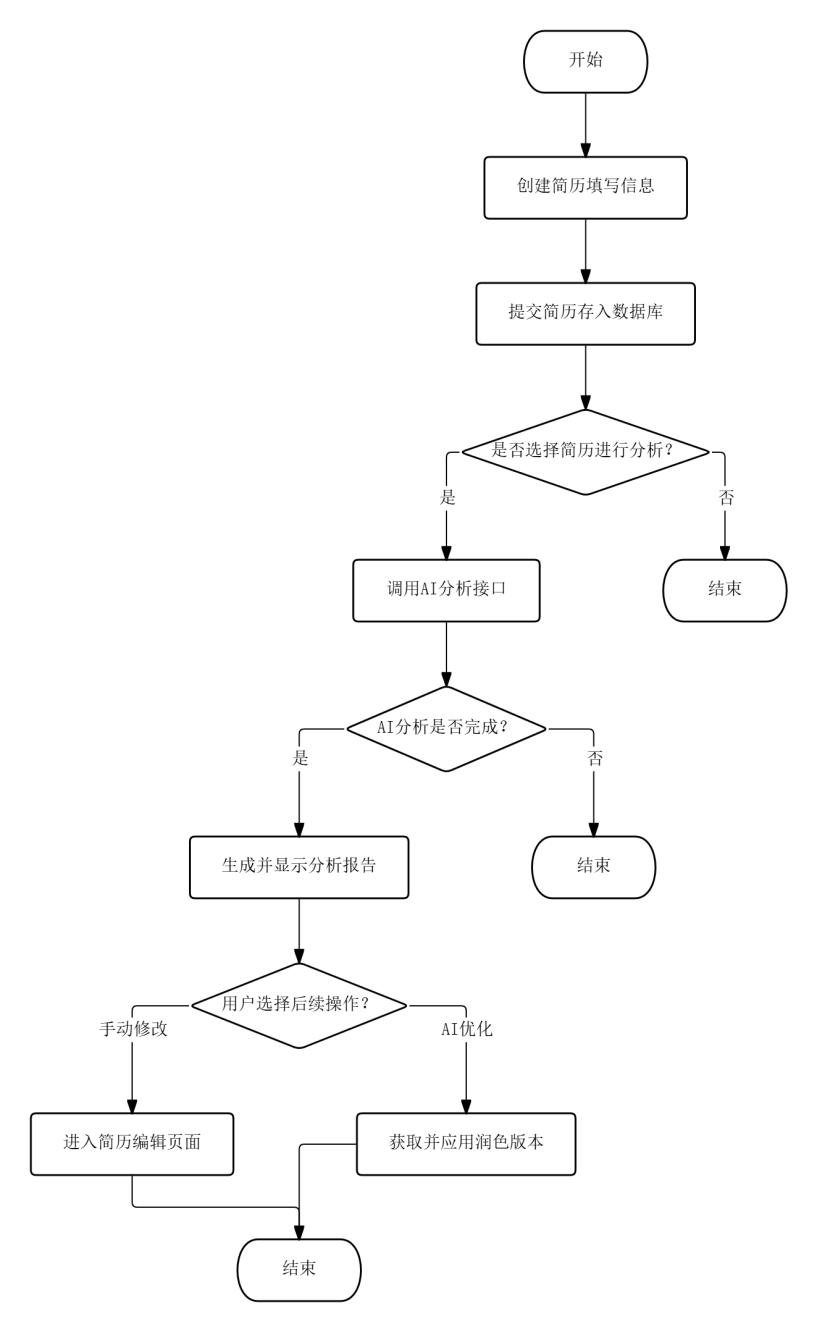
图3.2 简历管理与AI分析流程
AI简历生成流程中,用户输入姓名、学历、工作年限、关键技能、项目经历和求职意向等结构化信息,系统构建生成提示词后调用DeepSeek API,在对话窗口中以流式方式输出完整简历文本。生成内容按基本信息、教育背景、工作经历、项目经历、技能特长等章节组织,用户确认后可一键保存至个人简历库。
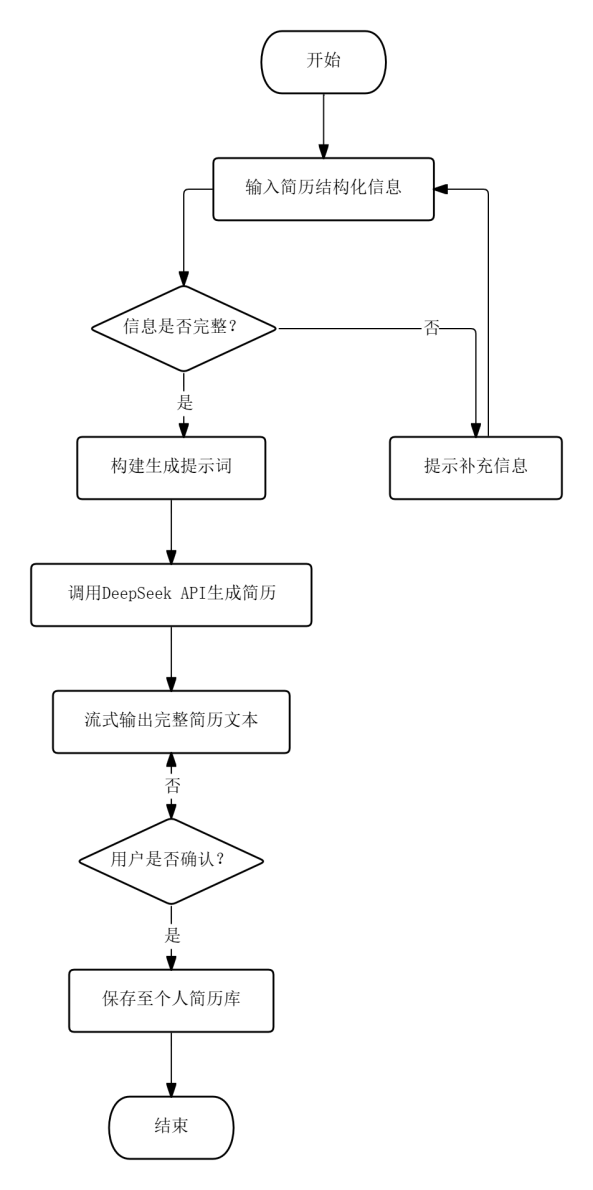
图3.3 AI简历生成流程
AI简历优化流程中,用户选择已有简历后点击优化分析按钮,系统先基于字段完整度和内容长度计算三项评分并回传前端渲染评分圈图,随后将简历内容和评分短板封装为优化提示词调用API,AI返回详细的改进建议、优化后的各模块内容以及结构化JSON数据。用户查看优化对比后点击应用按钮,系统自动将优化结果更新至原简历记录。该流程将传统上依赖职业顾问的主观建议转化为可量化、可回朔的迭代过程。
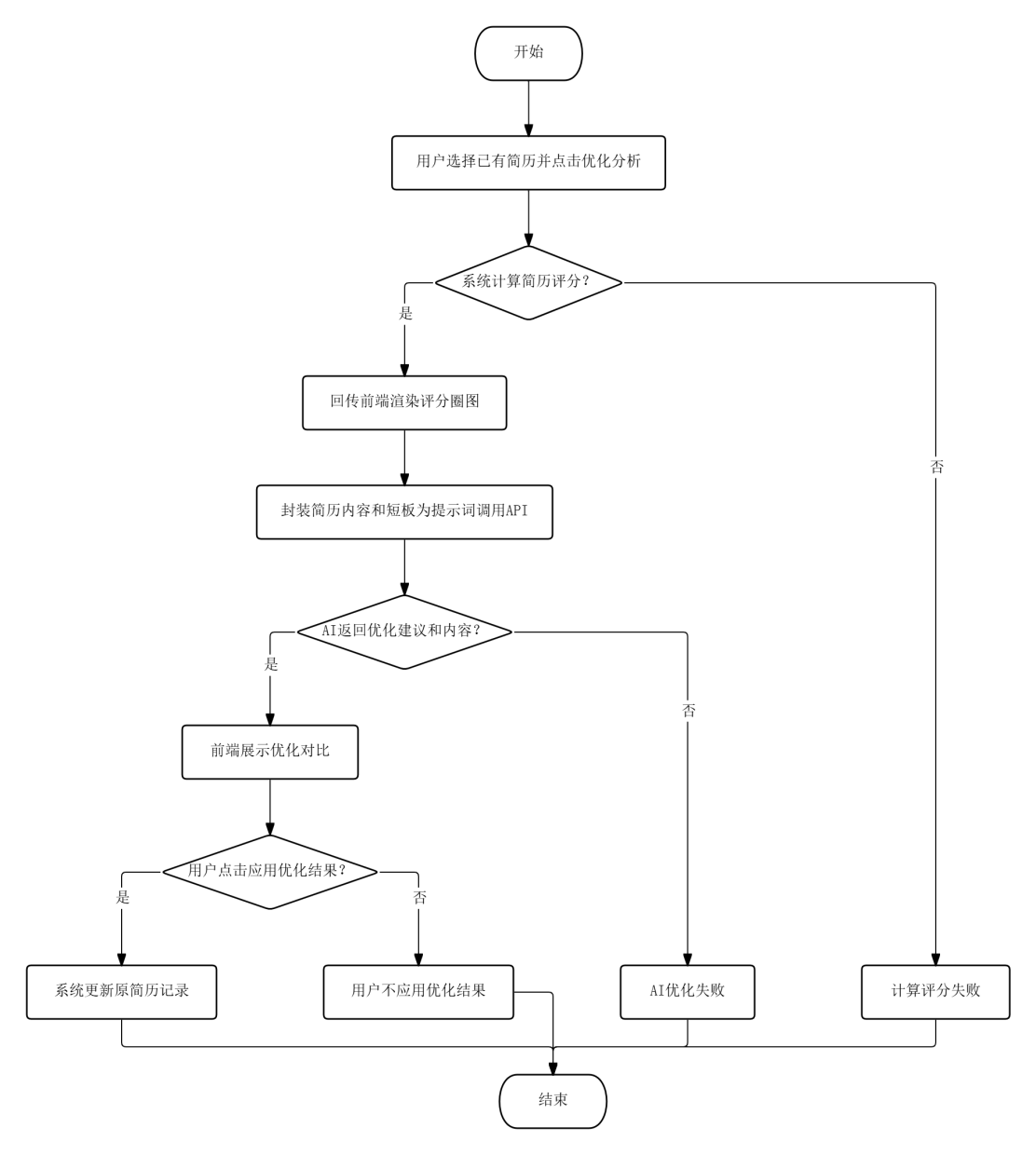
图3.4 AI简历优化流程
薪资预测流程中,用户在预测页面输入或选择职位名称、行业、城市、公司性质和公司规模五项参数,点击预测按钮后系统将参数编码后送入已训练的XGBoost模型,返回月薪估计值、置信区间、特征重要性排名以及相似职位的实际薪资参考。预测结果以醒目的数字和进度条展示,相似职位卡片附带查看外链,辅助用户在薪资议价时形成合理预期。
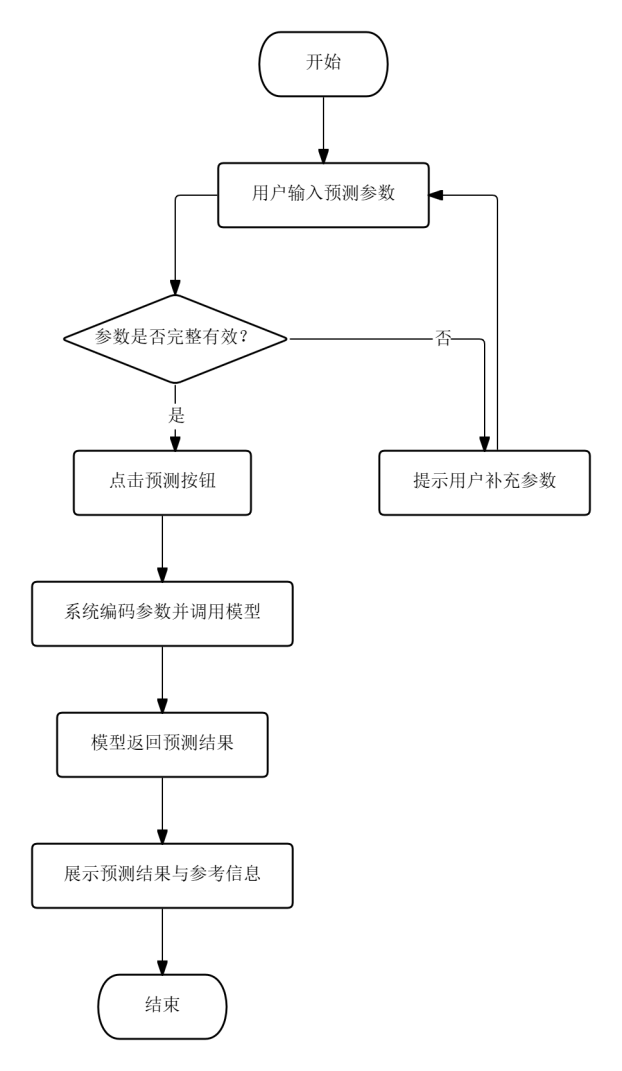
图3.5 薪资预测流程
管理后台数据分析流程中,管理员登录后进入数据看板,系统自动加载用户总数、职位总数、简历总数和收藏总数四项统计指标,并以柱状图、饼图和词云图分别呈现薪资分布、行业分布、城市分布和技能需求频率。管理员可设定起止日期对数据进行时间范围筛选,点击生成智能分析报告按钮后系统汇总趋势、竞争度和地域机会三项分析结果并渲染为折线图与组合图。该流程将分散的数据表中的原始记录转化为可视化决策信息,支持快速捕捉市场变化信号。
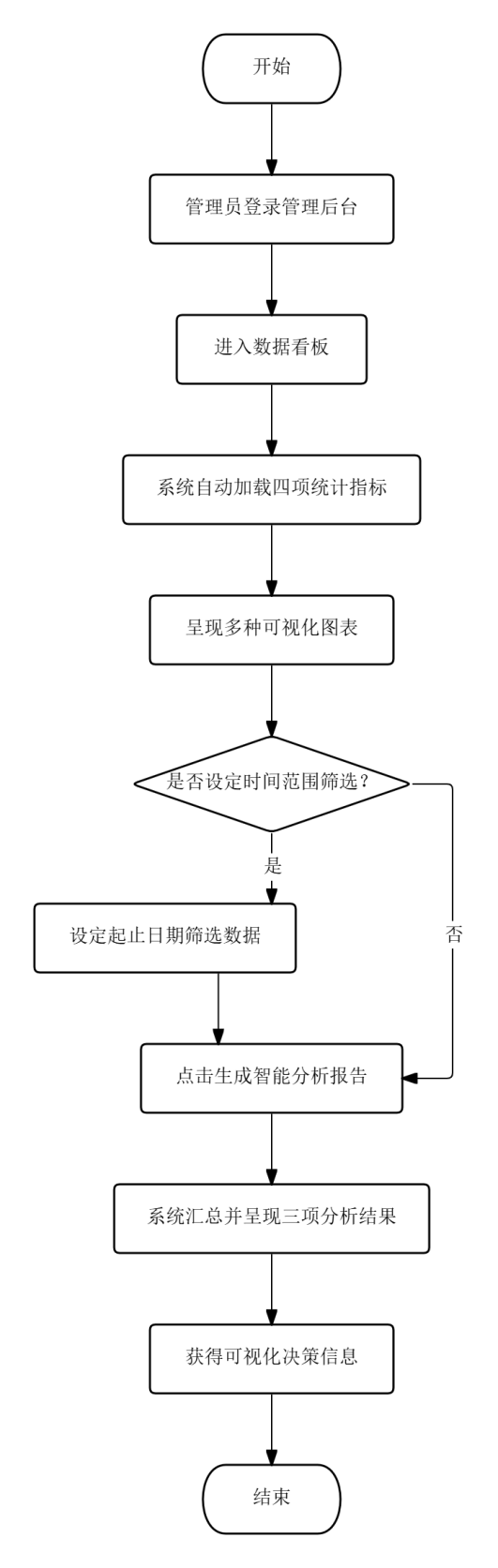
图3.6 管理后台数据分析流程
3.2.3 功能需求分析
从角色权限角度划分,系统包含三类使用者:未登录访客、已登录求职者和系统管理员。不同的角色对应不同的功能集合。
未登录访客仅可浏览首页展示的系统介绍卡片,查看职位搜索、AI推荐、简历分析等功能的宣传性描述,并通过导航栏的登录和注册按钮进入认证流程。该设计确保核心功能仅向注册用户开放,同时降低首次访问的决策成本。
已登录求职者的功能覆盖求职全流程。简历管理模块支持创建、编辑、删除和设为默认四种操作,简历字段涵盖个人基础信息、求职意向、教育经历、工作经历、项目经历、技能证书和自我评价。职位搜索模块提供关键词、类型、地点、薪资四维筛选和分页浏览,每条职位卡片显示岗位名称、公司、城市、薪资和标签信息,支持外部链接跳转至原始招聘页面和收藏按钮操作。收藏管理模块以列表形式汇总用户标记的职位,支持取消收藏。AI分析模块允许用户从下拉菜单选择简历后触发分析,系统实时展示评分和优化建议。AI生成模块接收用户填写的从业背景和求职偏好后调用模型生成完整简历。AI优化模块在分析基础上提供一键应用优化结果的功能。薪资预测模块接收五项岗位参数后返回模型预测值及相似职位参考。职位推荐模块基于多策略融合算法为用户生成个性化推荐列表,每条结果标注匹配度百分比。个人中心模块提供资料编辑和密码修改功能。求职者功能需求的用例结构如图3.7所示。
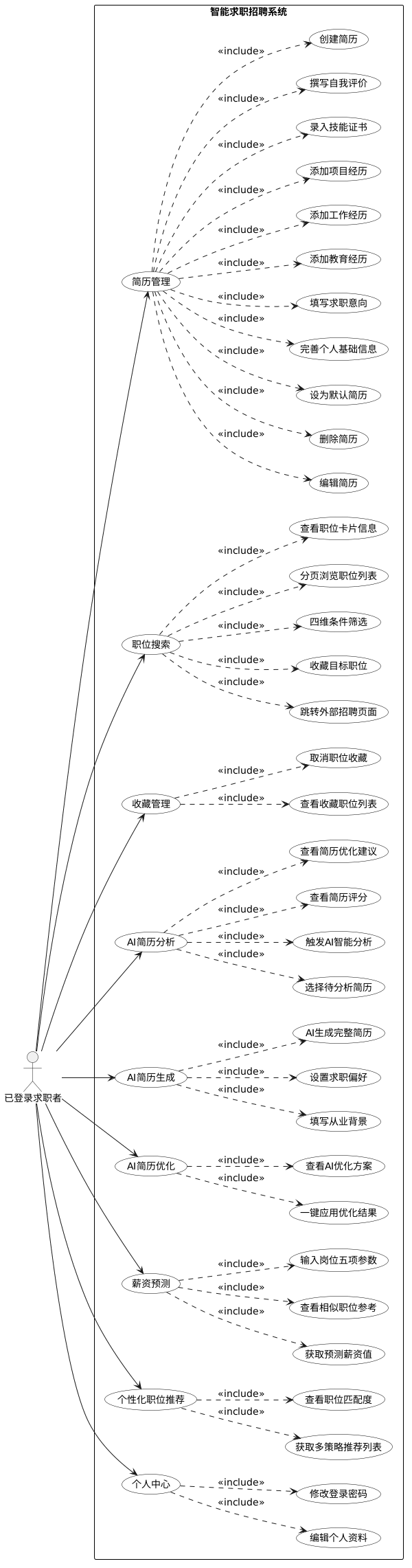
图3.7 求职者功能用例图
系统管理员的功能以数据管理和统计决策为主。用户管理模块支持按用户名、角色、状态进行筛选查询,提供查看详情、启用禁用、重置密码和删除四种操作。职位管理模块支持按职位名称或公司关键词搜索,提供查看外部链接和删除操作。收藏管理模块提供按城市和行业的筛选查询及删除功能。数据分析看板展示关键统计指标和图表,支持日期范围筛选。智能分析报告功能整合趋势分析、竞争度分析和地域机会分析三类结果,以组合图表形式呈现行业和城市维度的就业市场变化。
管理员功能需求的用例结构如图3.8所示。
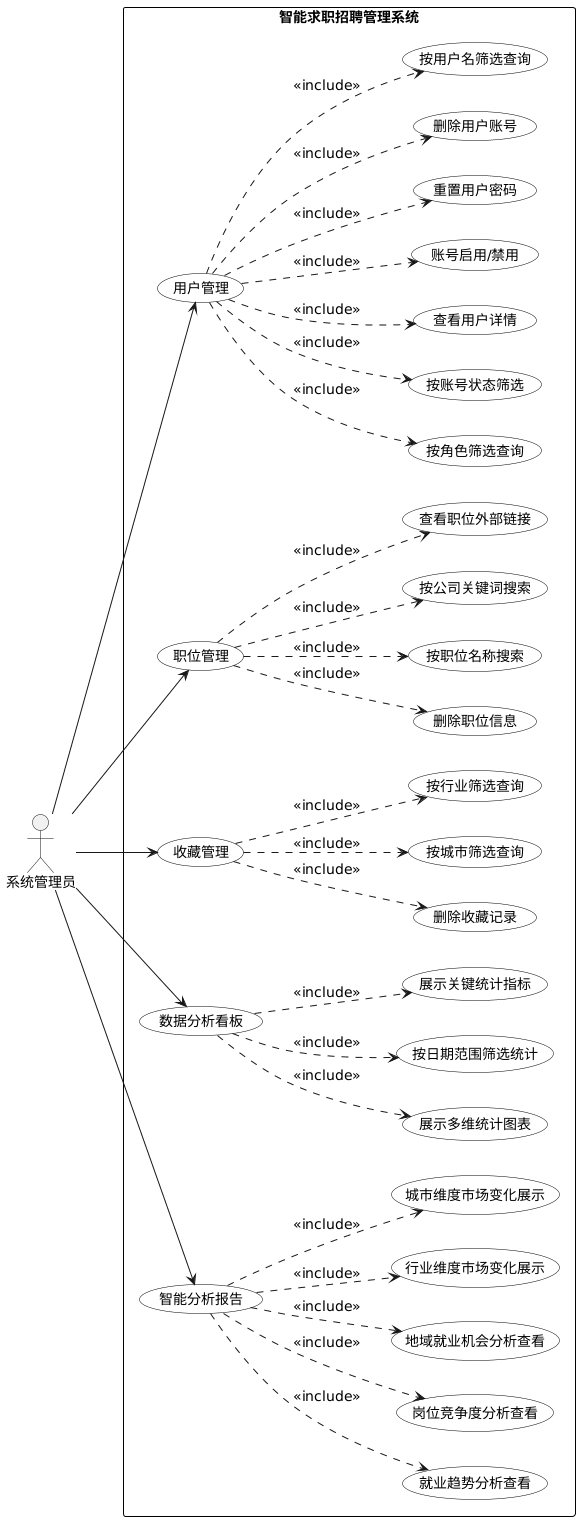
图3.8 管理员功能用例图
3.2.4 非功能性需求分析
性能需求方面,系统应保证在单服务器部署条件下,普通页面加载时间不超过两秒,涉及AI模型调用的分析类接口响应时间不超过十五秒,流式输出的首字节时间不超过三秒。数据库查询需对高频搜索字段建立索引,单次分页查询的返回数据量控制在二十条以内,避免前端渲染卡顿。
安全性需求方面,所有涉密接口均需验证JWT令牌有效性,令牌设置二十四小时过期时间以降低泄露风险。用户密码采用bcrypt哈希存储,禁止明文传输。管理员功能的访问需额外校验身份,普通用户请求管理接口时应返回403状态码。
可用性需求方面,前端界面需支持主流现代浏览器,页面采用响应式布局适配桌面端显示。表单输入框应提供即时校验提示,必填项未完成时阻止提交。AI分析等待期间需显示加载动画,避免用户误以为系统无响应。
可维护性需求方面,后端代码按蓝图组织功能模块,模型层、服务层与路由层分离,便于后续功能扩展和Bug定位。配置文件集中管理API密钥、模型参数和权重值,避免硬编码散布于业务逻辑中。前端JavaScript按页面功能拆分为独立文件,变量命名遵循驼峰规范,关键函数添加注释说明。
第4章 系统总体设计
4.1 系统架构设计
本系统采用前后端分离的B/S架构,按照数据流动方向自底向上划分为数据存储层、业务逻辑层、接口路由层、服务代理层和前端展示层五个层级。数据存储层以SQLite关系型数据库为核心,通过SQLAlchemy对象关系映射工具将Python模型类与数据表建立映射,负责职位信息、用户资料、简历内容和分析记录的持久化存储与查询优化。业务逻辑层封装了简历评分算法、多策略融合推荐引擎、薪资预测模型调用和提示词模板构建等核心处理逻辑,以独立的服务类形式组织在services包中,供上层路由调用。接口路由层基于Flask的Blueprint机制将系统拆分为认证蓝图、简历蓝图、职位蓝图、AI分析蓝图、管理后台蓝图和API蓝图六个功能模块,每个模块通过装饰器将HTTP请求映射为对应的视图函数,完成参数校验、权限鉴权和响应封装。服务代理层承担与外部大语言模型API的通信职责,通过requests库发起流式调用请求,将DeepSeek返回的增量文本经Server-Sent Events协议实时转发至客户端。前端展示层采用Bootstrap响应式框架构建单页面应用,页面切换由哈希路由机制控制,图表可视化通过ECharts库渲染,AI分析流式内容通过EventSource接口接收并动态更新DOM节点。系统总体架构如图4.1所示。
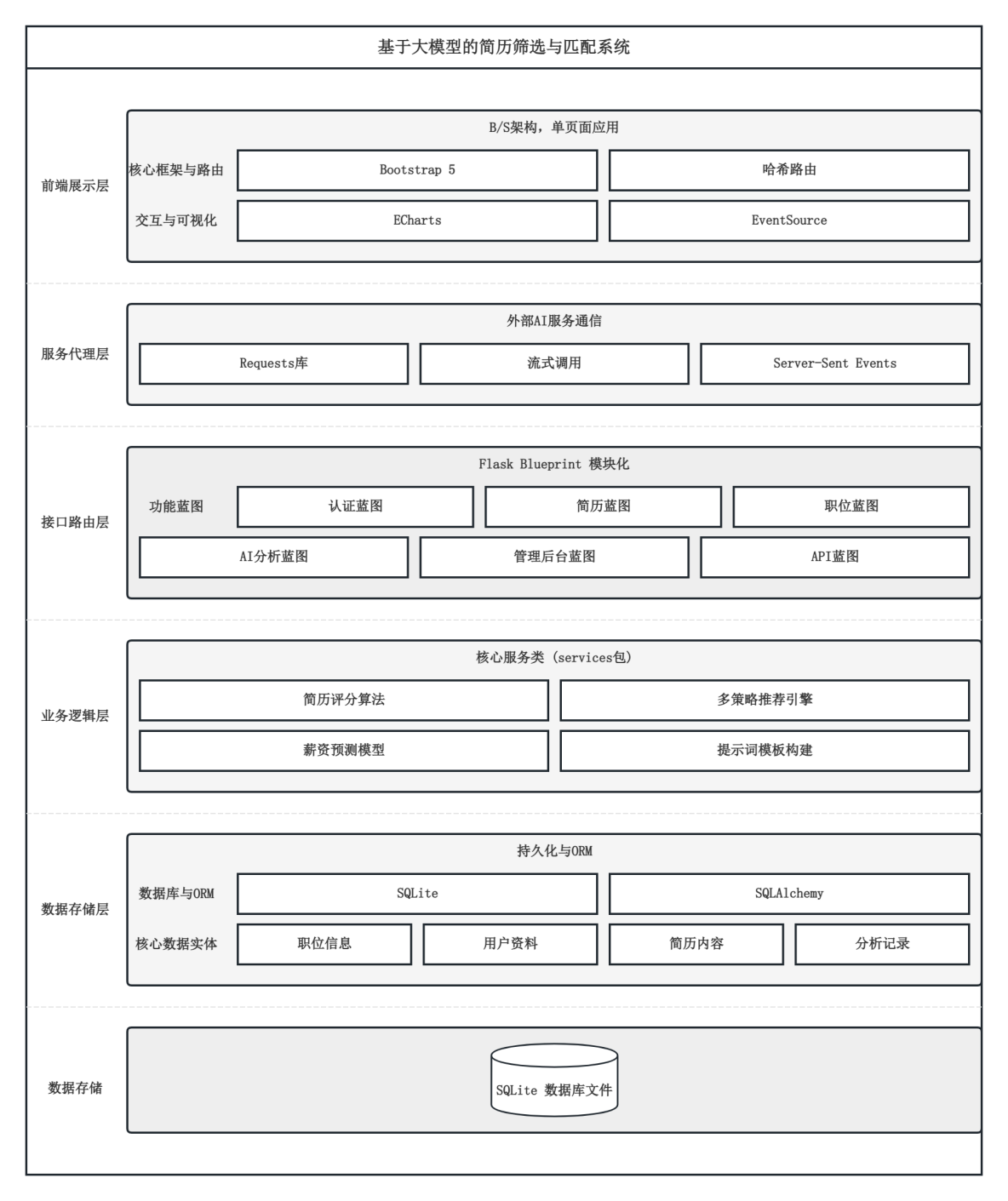
图4.1 系统总体架构图
4.2 系统功能模块设计
本系统旨在为求职者提供从信息检索到决策辅助的全流程智能服务,同时为管理员提供就业市场数据看板。系统功能划分为六大核心模块:用户认证模块负责注册、登录、个人信息管理与密码修改,基于JWT令牌实现无状态身份校验与管理员权限区分;职位搜索与收藏模块支持关键词、职位类型、工作地点和薪资范围四维组合筛选,搜索结果分页展示并支持一键收藏,收藏列表独立管理;简历管理模块提供创建、编辑、删除、设为默认四种操作,简历字段覆盖个人基础信息、求职意向、教育经历、工作经历、项目经历、技能证书和自我评价,支持将AI生成或优化后的内容回填保存;AI智能分析模块包含简历分析、简历生成和简历优化三个子功能,通过DeepSeek大语言模型API结合模板化提示词实现完整性、技能匹配度和竞争力三项评分的流式输出,生成功能基于用户填写的从业背景信息自动合成结构化简历,优化功能在分析基础上提供内容润色和字段建议并支持一键应用;薪资预测模块接收职位名称、行业、城市、公司性质和公司规模五项特征参数,调用已训练的XGBoost回归模型输出月薪估计值与置信区间,同步展示特征重要性排序和相似职位参考记录;管理后台模块面向管理员提供用户管理、职位管理、收藏管理及数据分析看板,看板集成职位热度趋势折线图、行业竞争度组合图、地域机会分布图、技能需求词云图等多维可视化报表,支持按日期范围筛选数据并生成智能分析报告摘要。系统功能模块划分如图4.2所示。
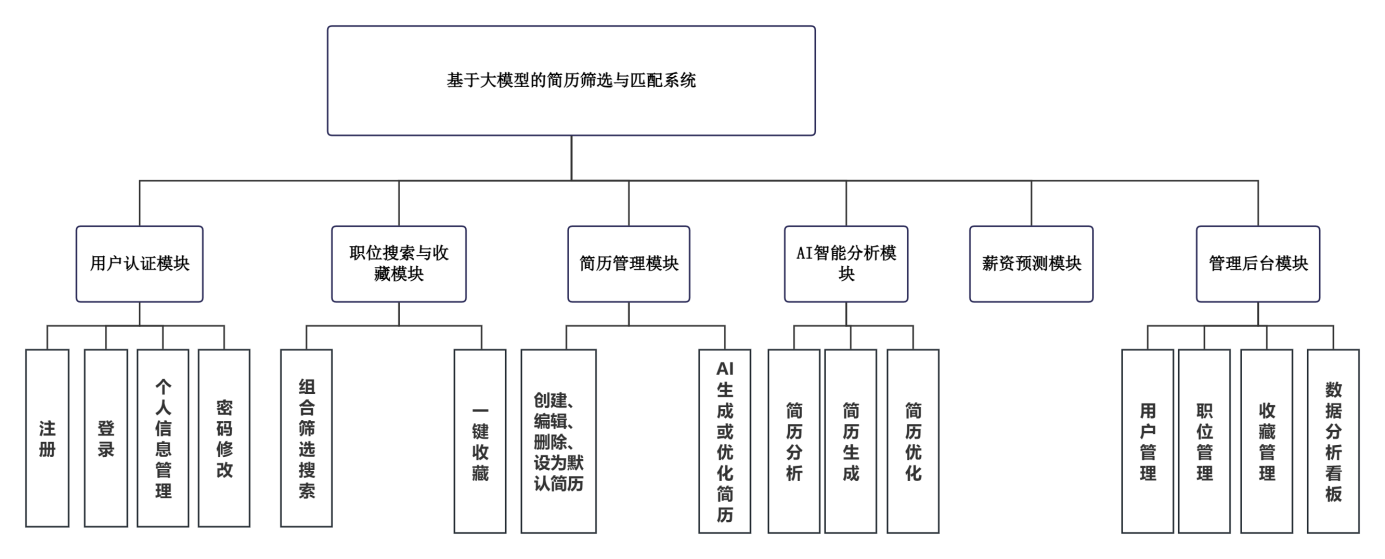
图4.2 系统功能模块图
4.3 数据库设计
4.3.1 数据关系设计
本系统选用SQLite关系型数据库进行数据存储,数据表之间存在明确的外键关联约束。核心实体包括用户、简历、职位、收藏记录和简历分析记录五类。用户与简历之间为一对多关系,一个用户可创建多份简历,简历通过user_id外键关联至用户表主键,删除用户时级联删除其下所有简历。用户与收藏记录之间为一对多关系,收藏记录通过user_id外键指向用户表。职位与收藏记录之间同样为一对多关系,收藏记录通过job_id外键指向职位表主键,删除职位时级联删除关联收藏。用户与简历分析记录之间为一对多关系,分析记录通过user_id外键指向用户表;简历与分析记录之间亦为一对多关系,分析记录通过resume_id外键指向简历表。收藏记录表作为用户与职位之间的多对多关系中间表,同时承载收藏时间戳信息。系统实体关系如图4.3所示。
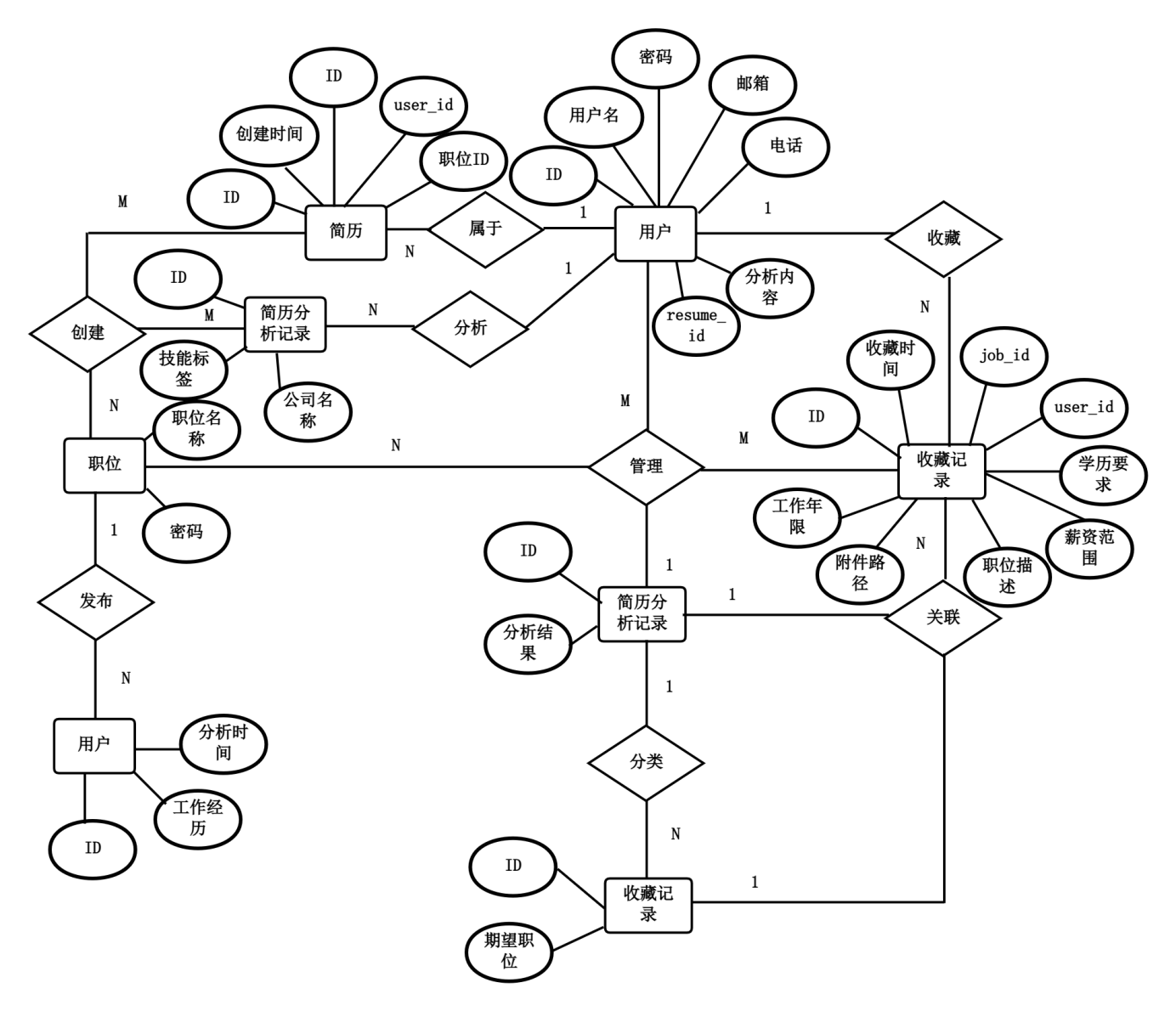
图4.3 系统实体关系图
4.3.2 数据库表设计
本系统数据库由用户信息表、简历信息表、职位信息表、收藏记录表和简历分析记录表共五张数据表组成,涵盖用户认证、简历存储、职位检索、收藏管理及AI分析记录存储的全部数据需求。各表均以自增整型id字段作为主键,外键约束与4.3.1节实体关系图中的关联线一一对应。
用户信息表(user_jobSystem)记录注册用户的身份信息与个人资料,包含用户名、邮箱、手机号、密码哈希值、管理员标识、激活状态、认证状态、头像、性别、出生日期、学历、工作经验、所在城市、创建时间、更新时间及最后登录时间共十七个字段。其中password_hash存储bcrypt算法加密后的密文,is_admin以布尔值区分普通用户与管理员,is_active控制账号启用状态。如表4.1所示
表4.1 用户信息表
|
字段名 |
数据类型 |
允许空 |
默认值 |
说明 |
|
id |
INTEGER |
否 |
自增 |
用户唯一标识 |
|
username |
TEXT |
否 |
无 |
登录用户名,唯一 |
|
|
TEXT |
否 |
无 |
电子邮箱,唯一 |
|
phone |
TEXT |
是 |
NULL |
手机号码 |
|
password_hash |
TEXT |
否 |
无 |
bcrypt加密密码密文 |
|
is_admin |
INTEGER |
否 |
0 |
管理员标志,0否1是 |
|
is_active |
INTEGER |
否 |
1 |
账号激活状态,0禁用1正常 |
|
is_verified |
INTEGER |
否 |
0 |
是否已验证 |
|
avatar |
TEXT |
是 |
NULL |
头像图片链接 |
|
gender |
TEXT |
是 |
NULL |
性别 |
|
birth_date |
TEXT |
是 |
NULL |
出生日期,格式YYYY-MM-DD |
|
education |
TEXT |
是 |
NULL |
学历层次 |
|
work_experience |
TEXT |
是 |
NULL |
工作经验简述 |
|
location |
TEXT |
是 |
NULL |
所在城市 |
|
created_at |
TEXT |
否 |
CURRENT_TIMESTAMP |
记录创建时间 |
|
updated_at |
TEXT |
否 |
CURRENT_TIMESTAMP |
最近一次更新时间 |
|
last_login |
TEXT |
是 |
NULL |
最后登录时间 |
简历信息表(resume_jobSystem)记录用户创建的简历完整内容,包含用户外键、简历标题、是否默认、是否公开、姓名、性别、出生日期、联系电话、邮箱、所在城市、期望职位、期望薪资、期望地点、教育背景、工作经历、项目经历、技能、证书、自我评价、附件路径、创建时间和更新时间共二十二个字段。education、work_experience和project_experience字段以JSON文本格式存储结构化数组,skills和certificates字段以逗号分隔的文本存储,user_id外键关联user_jobSystem表的id主键并设置级联删除。
表4.2 简历信息表
|
字段名 |
数据类型 |
允许空 |
默认值 |
说明 |
|
id |
INTEGER |
否 |
自增 |
简历唯一标识 |
|
user_id |
INTEGER |
否 |
无 |
所属用户ID,外键 |
|
title |
TEXT |
否 |
无 |
简历标题 |
|
is_default |
INTEGER |
否 |
0 |
是否为默认简历,0否1是 |
|
is_public |
INTEGER |
否 |
0 |
是否公开,0否1是 |
|
name |
TEXT |
是 |
NULL |
姓名 |
|
gender |
TEXT |
是 |
NULL |
性别 |
|
birth_date |
TEXT |
是 |
NULL |
出生日期 |
|
phone |
TEXT |
是 |
NULL |
联系电话 |
|
|
TEXT |
是 |
NULL |
电子邮箱 |
|
location |
TEXT |
是 |
NULL |
所在城市 |
|
job_title |
TEXT |
是 |
NULL |
期望职位 |
|
salary |
TEXT |
是 |
NULL |
期望薪资范围 |
|
location_preference |
TEXT |
是 |
NULL |
期望工作地点 |
|
education |
TEXT |
是 |
NULL |
教育背景,JSON数组 |
|
work_experience |
TEXT |
是 |
NULL |
工作经历,JSON数组 |
|
project_experience |
TEXT |
是 |
NULL |
项目经历,JSON数组 |
|
skills |
TEXT |
是 |
NULL |
技能列表,逗号分隔 |
|
certificates |
TEXT |
是 |
NULL |
证书列表,逗号分隔 |
|
self_evaluation |
TEXT |
是 |
NULL |
自我评价文本 |
|
attachment_path |
TEXT |
是 |
NULL |
附件存储路径 |
|
created_at |
TEXT |
否 |
CURRENT_TIMESTAMP |
记录创建时间 |
|
updated_at |
TEXT |
否 |
CURRENT_TIMESTAMP |
记录更新时间 |
职位信息表(job_jobSystem)记录从招聘平台采集的结构化岗位数据,包含岗位名称、公司名称、薪资、城市、区县、行业、标签、公司性质、公司规模、回复数、职位链接、浏览次数、申请次数、收藏次数、创建时间和更新时间共十六个字段。tags字段存储以逗号分隔的技能标签字符串,view_count和favorite_count用于推荐算法的热度计算。
表4.3 职位信息表
|
字段名 |
数据类型 |
允许空 |
默认值 |
说明 |
|
id |
INTEGER |
否 |
自增 |
职位唯一标识 |
|
job_name |
TEXT |
否 |
无 |
岗位名称 |
|
company |
TEXT |
否 |
无 |
公司名称 |
|
salary |
TEXT |
是 |
NULL |
薪资描述文本 |
|
city |
TEXT |
是 |
NULL |
工作城市 |
|
district |
TEXT |
是 |
NULL |
所在区县 |
|
industry |
TEXT |
是 |
NULL |
所属行业 |
|
tags |
TEXT |
是 |
NULL |
技能标签,逗号分隔 |
|
company_nature |
TEXT |
是 |
NULL |
公司性质 |
|
company_size |
TEXT |
是 |
NULL |
公司规模 |
|
reply_count |
TEXT |
是 |
NULL |
回复数量文本 |
|
job_url |
TEXT |
是 |
NULL |
职位详情页链接 |
|
view_count |
INTEGER |
否 |
0 |
浏览次数 |
|
apply_count |
INTEGER |
否 |
0 |
申请次数 |
|
favorite_count |
INTEGER |
否 |
0 |
被收藏次数 |
|
created_at |
TEXT |
否 |
CURRENT_TIMESTAMP |
记录创建时间 |
|
updated_at |
TEXT |
否 |
CURRENT_TIMESTAMP |
记录更新时间 |
收藏记录表(favorite_jobSystem)作为用户与职位之间多对多关系的中间表,包含用户外键、职位外键和创建时间三个字段。user_id外键关联user_jobSystem表的id主键并设置级联删除,job_id外键关联job_jobSystem表的id主键并设置级联删除,两外键组合唯一确保同一用户不会重复收藏同一职位。
表4.4 收藏记录表
|
字段名 |
数据类型 |
允许空 |
默认值 |
说明 |
|
id |
INTEGER |
否 |
自增 |
收藏记录唯一标识 |
|
user_id |
INTEGER |
否 |
无 |
用户ID,外键 |
|
job_id |
INTEGER |
否 |
无 |
职位ID,外键 |
|
created_at |
TEXT |
否 |
CURRENT_TIMESTAMP |
收藏时间 |
简历分析记录表(analysis_jobSystem)记录每次AI分析的评分与完整结果文本,包含用户外键、简历外键、完整性评分、技能匹配度评分、竞争力评分、分析结果文本和创建时间共七个字段。analysis_result字段存储Markdown格式的完整AI分析报告,user_id和resume_id外键分别关联对应主表。
表4.5 简历分析记录表
|
字段名 |
数据类型 |
允许空 |
默认值 |
说明 |
|
id |
INTEGER |
否 |
自增 |
分析记录唯一标识 |
|
user_id |
INTEGER |
否 |
无 |
用户ID,外键 |
|
resume_id |
INTEGER |
否 |
无 |
简历ID,外键 |
|
completeness_score |
INTEGER |
是 |
NULL |
完整性评分,0-100 |
|
skill_match_score |
INTEGER |
是 |
NULL |
技能匹配度评分,0-100 |
|
competitiveness_score |
INTEGER |
是 |
NULL |
竞争力评分,0-100 |
|
analysis_result |
TEXT |
是 |
NULL |
分析报告,Markdown格式 |
|
created_at |
TEXT |
否 |
CURRENT_TIMESTAMP |
记录创建时间 |
第5章 系统开发与实现
5.1 开发环境
本系统采用B/S架构体系,基于Python语言和Flask轻量级Web框架开发,数据库选用SQLite关系型数据库,前端页面采用Bootstrap响应式框架结合原生JavaScript构建。系统开发所需的具体软硬件环境如表5.1所示。
表5.1 系统开发环境
|
硬件环境 |
软件环境 |
|
CPU:Intel Core i5-12400F 2.5GHz |
操作系统:Windows 11 专业版 22H2 |
|
内存:16GB DDR4 |
数据库:SQLite 3.39.0;Python版本:3.10.11 |
|
硬盘:512GB SSD |
Web服务器:Flask 2.3.2内置开发服务器 |
|
浏览器:Google Chrome 114.0 |
|
|
开发工具:Visual Studio Code 1.79 |
除表中所列核心环境外,项目还依赖若干第三方Python库:Flask-CORS 4.0.0用于处理跨域资源共享,Flask-SQLAlchemy 3.0.5提供数据库对象关系映射支持,PyJWT 2.8.0实现JSON Web Token的生成与校验,bcrypt 4.1.0负责密码哈希加密,requests 2.31.0处理向外部的DeepSeek API发起流式调用,pandas 2.0.3用于CSV职位数据读取与特征工程预处理,XGBoost 1.7.6训练薪资预测回归模型,scikit-learn 1.3.0提供模型评估指标与编码工具。前端方面,Bootstrap 5.3.0提供导航栏、卡片、模态框等UI组件,ECharts 5.4.3渲染柱状图、饼图、折线图和词云图等可视化元素。
5.2 数据采集模块实现
招聘职位数据的采集是本系统数据层的起点,采用Selenium自动化测试框架驱动Chrome浏览器模拟真实用户访问行为,结合BeautifulSoup超文本解析库对返回的HTML文档树进行结构化字段提取。采集流程分为列表页采集和详情页采集两个阶段,两者串行执行以确保字段完整性。
列表页采集脚本的核心逻辑封装于login函数中。脚本首先调用webdriver.Chrome初始化浏览器实例,在ChromeOptions中配置“disable-blink-features”“excludeSwitches”和“no-sandbox”三项参数以规避WebDriver特征检测。driver实例创建后加载目标招聘平台首页,通过find_element方法结合XPath表达式定位搜索输入框,填入预设的岗位关键词后点击搜索按钮,页面跳转至结果列表页。等待页面充分渲染后,driver.page_source获取当前页的完整DOM字符串,传入BeautifulSoup构造函数解析为可遍历的标签树对象。
解析环节通过soup.find_all方法定位所有class属性为“joblist-item”的div块级元素,遍历每个岗位卡片逐字段提取信息。岗位ID从div元素的sensorsdata自定义属性中获取,该属性存储了一段JSON格式的埋点数据,调用json.loads解析后按key提取jobId、jobTime、jobYear和jobDegree四个子字段。岗位名称和公司名称分别从span标签的“jname”类和a标签的“cname”类中获取text属性。技能标签位于div标签class为“tags”的容器内,其下的所有子div标签文本通过列表推导向式收集后用管道符拼接为单一字符串。行政区划信息从class为“shrink-0”的div标签中获取文本后按“·”分隔符切分为二级和三级行政单位。每条记录提取完成后追加写入以GBK编码打开的CSV文件,避免中文字段在Excel中打开时出现乱码。翻页操作通过driver.find_element定位下一页按钮并执行click事件,切换至新页面后重复解析流程,直至遍历目标页数。

图5.1 数据采集网站
详情页采集脚本以列表页输出的CSV文件为输入,使用pandas的read_csv函数读取为DataFrame后转换为二维列表逐行遍历。每行数据包含先前采集的十六个基础字段及岗位ID,脚本构造形如“jobs.51job.com/all/{jobid}.html”的详情页URL后驱动浏览器逐条访问。详情页的解析目标为六个扩展字段:岗位全文从class为“bmsg job_msg inbox”的div标签中提取,并按“职能类别:”和“关键字:”两个分割符切分为正文、职能类别和职位关键字三个字段;福利标签从class为“t1”的div标签提取;公司简介从class为“tmsg inbox”的div标签提取;上班地址从class为“fp”的p标签提取。各字段提取均包裹在try-except块中,单条详情页解析失败时对应字段赋空字符串并继续处理下一条,避免整个采集流程因个别页面异常而中断。六个扩展字段按顺序追加至原列表后,以相同格式写入新的CSV文件,最终交付给数据导入模块完成入库。整个采集模块在目标网站的Robots协议允许范围内运行,每次页面加载后设置三至五秒的固定等待时间以控制请求频率。
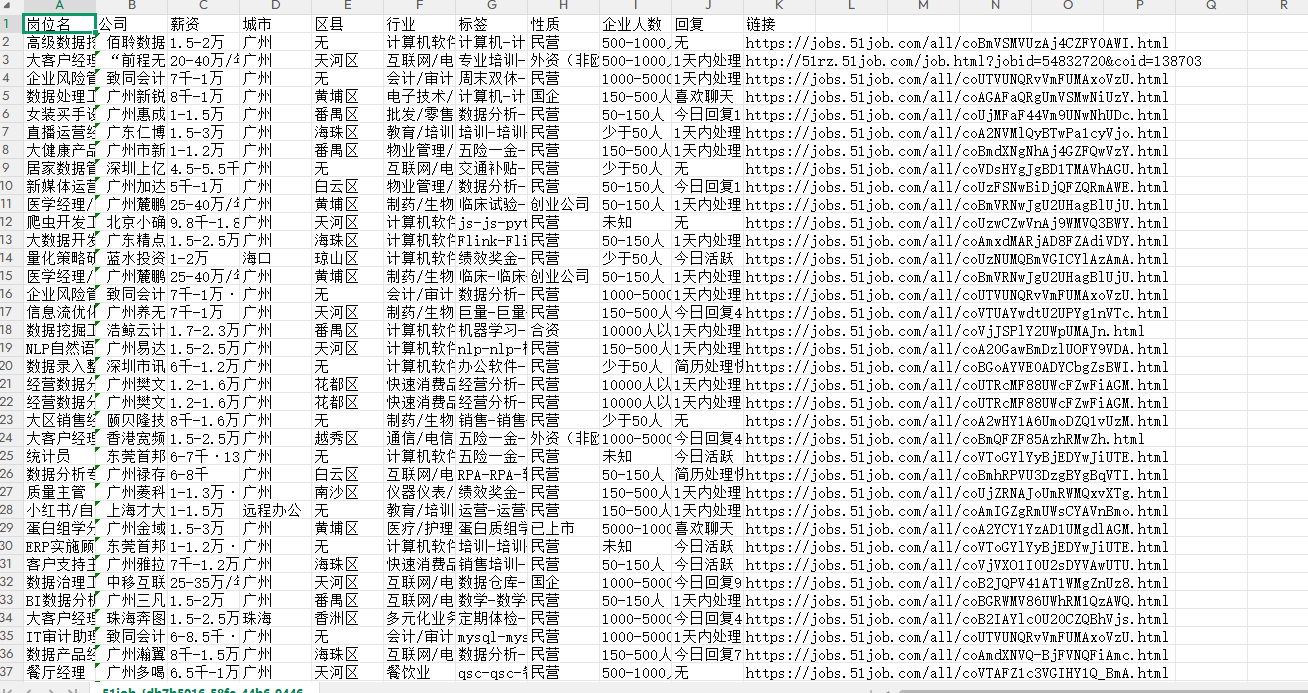
图5.2 数据采集结果
5.3 数据处理模块实现
数据处理模块承担从原始CSV文件到规范化数据库记录的转换职责,在Flask应用启动时的before_request钩子中自动执行,确保系统在接收到首个用户请求前完成数据就绪。处理逻辑封装于import_jobs_from_csv函数,该函数在Job表查询计数为零时触发,仅首次运行执行导入。
函数首先调用pandas的read_csv方法加载data目录下的“51job.csv”文件,指定encoding参数为“gbk”以兼容Windows环境下生成的中文CSV文件。读取完成后返回DataFrame对象,函数通过iterrows迭代器逐行遍历,每次迭代返回行索引和包含该行所有字段值的Series对象。针对每行数据创建Job模型实例,字段映射关系为:CSV列“岗位名”对应job_name属性,“公司”对应company,“薪资”对应salary,“城市”对应city,“区县”对应district,“行业”对应industry,“标签”对应tags,“性质”对应company_nature,“企业人数”对应company_size,“回复”对应reply_count,“链接”对应job_url。其中tags字段在写入前经str()函数强制转换为字符串类型,避免原始数据中可能出现的浮点型标签值引发数据库类型冲突。
实例创建完成后调用db.session.add方法将Job对象注册至当前事务会话,遍历全部行后统一调用db.session.commit提交事务,实现批量插入。若导入过程中任一条记录因字段格式异常或约束冲突导致插入失败,外层的try-except块捕获异常后调用db.session.rollback回滚整个事务,保证数据库状态的原子性——要么全量导入成功,要么保持空表状态等待修正CSV文件后下次重试。导入成功后控制台打印包含总记录数的完成提示,为后续运行提供运维确认信息。
除职位数据外,用户账户数据的初始化也在同一钩子函数中完成。函数通过User.query.filter_by方法依次检查admin和superadmin两个预设账户是否存在,若不存在则创建User实例并分别调用set_password方法设置各自密码,is_admin和is_active字段均置为True,赋予这两个账户最高的系统管理权限。这一设计使得系统在部署后无需额外执行数据库脚本即可拥有可用的管理员身份,降低了运维复杂度。
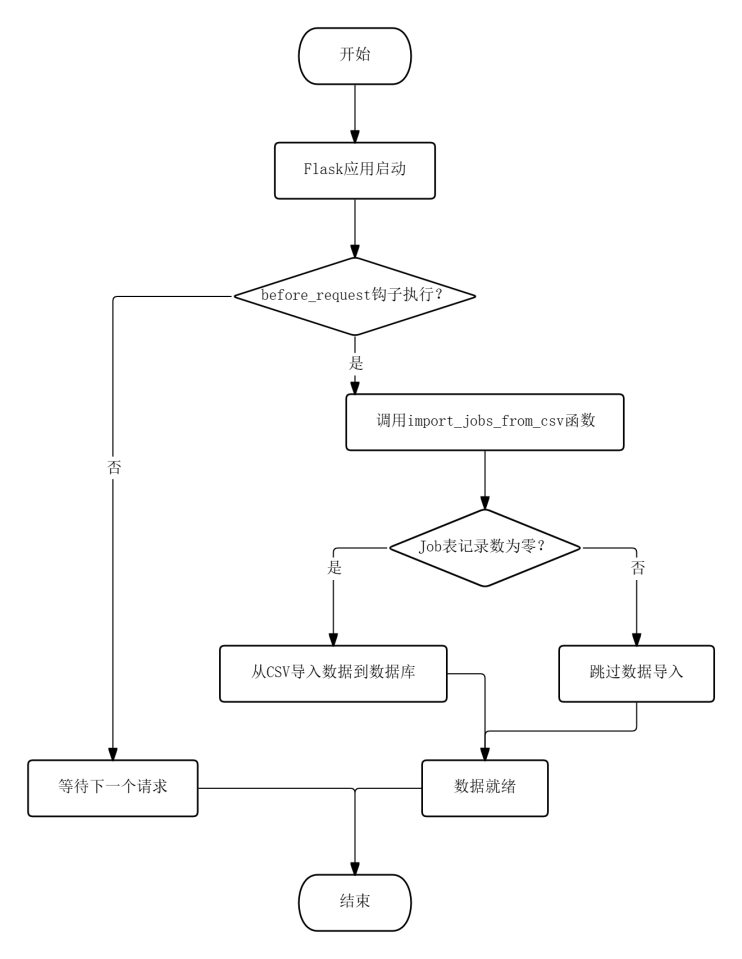
图5.2 数据处理流程
5.3 功能模块实现
5.3.1 用户认证与权限管理模块
用户认证模块是系统安全访问的基础,负责注册、登录、个人信息管理和密码修改等功能。注册接口接收前端表单提交的用户名、邮箱、手机号和密码参数,首先调用email_validator库的validate_email函数校验邮箱格式,通过正则表达式验证手机号是否满足11位数字且首字符为1的规则,密码长度不足六位时返回错误提示。查重环节按用户名、邮箱、手机号顺序依次检索数据库,任一字段冲突即终止注册流程。通过校验后创建User模型实例,调用bcrypt.hashpw方法对原始密码生成盐值哈希,将password_hash字段存储密文。注册成功即签发JWT令牌返回客户端,免去用户二次登录操作。
登录接口支持用户名、邮箱和手机号三种凭证,后端按优先级依次尝试三种匹配方式,避免用户记忆单一字段的负担。验证密码时调用bcrypt.checkpw方法比对哈希值,若连续验证失败则返回统一错误提示以防止账号枚举攻击。登录成功后更新last_login字段为当前时间戳,为后续用户行为分析预留数据基础。个人信息管理分为资料更新和密码修改两个子功能,资料更新接口允许修改性别、出生日期、学历、工作经验和所在城市等非敏感字段,密码修改接口要求先校验旧密码正确性再设置新哈希值。所有涉密接口的路由函数均通过require_auth装饰器实施JWT令牌校验,装饰器从请求头的Authorization字段提取Bearer令牌,解码失败或过期则返回401状态码,阻断未授权访问。
图5.4 用户登录与注册界面
5.3.2 职位搜索与收藏模块
职位搜索模块为求职者提供多维筛选和分页浏览功能。前端搜索栏布置关键词、职位类型、工作地点和薪资范围四个输入框,各框均绑定键盘回车事件以提升操作连贯性。用户点击搜索按钮或敲击回车后,searchJobs函数将四个输入框的值封装为searchParams全局对象,调用apiRequest工具函数向“/api/job/search”端点发起GET请求。
后端路由函数search_jobs从查询字符串中提取keyword、job_type、location、salary_min、salary_max等参数,构建SQLAlchemy动态查询链。关键词搜索通过or_()组合Job.job_name.contains()、Job.company.contains()和Job.tags.contains()三个模糊匹配条件,确保凡与输入词相关的岗位名、公司名或技能标签均能被命中。地点筛选扩展为同时对city和district字段进行contains()匹配,兼顾市级和区级输入。分页通过query.paginate()方法实现,默认每页返回二十条记录。返回前遍历当前页的职位对象列表,拉取当前用户的收藏职位ID集合,为每个岗位的job_dict附加is_favorite布尔字段,前端据此渲染实心或空心心形图标。
收藏功能的实现遵循RESTful设计风格,POST请求到“/api/job/<job_id>/favorite”创建收藏记录并自增职位表的favorite_count字段,DELETE请求则执行逆向操作。前端的toggleFavorite函数读取按钮的active类名判断当前状态,动态切换请求方法和图标样式,避免了额外的状态查询接口。
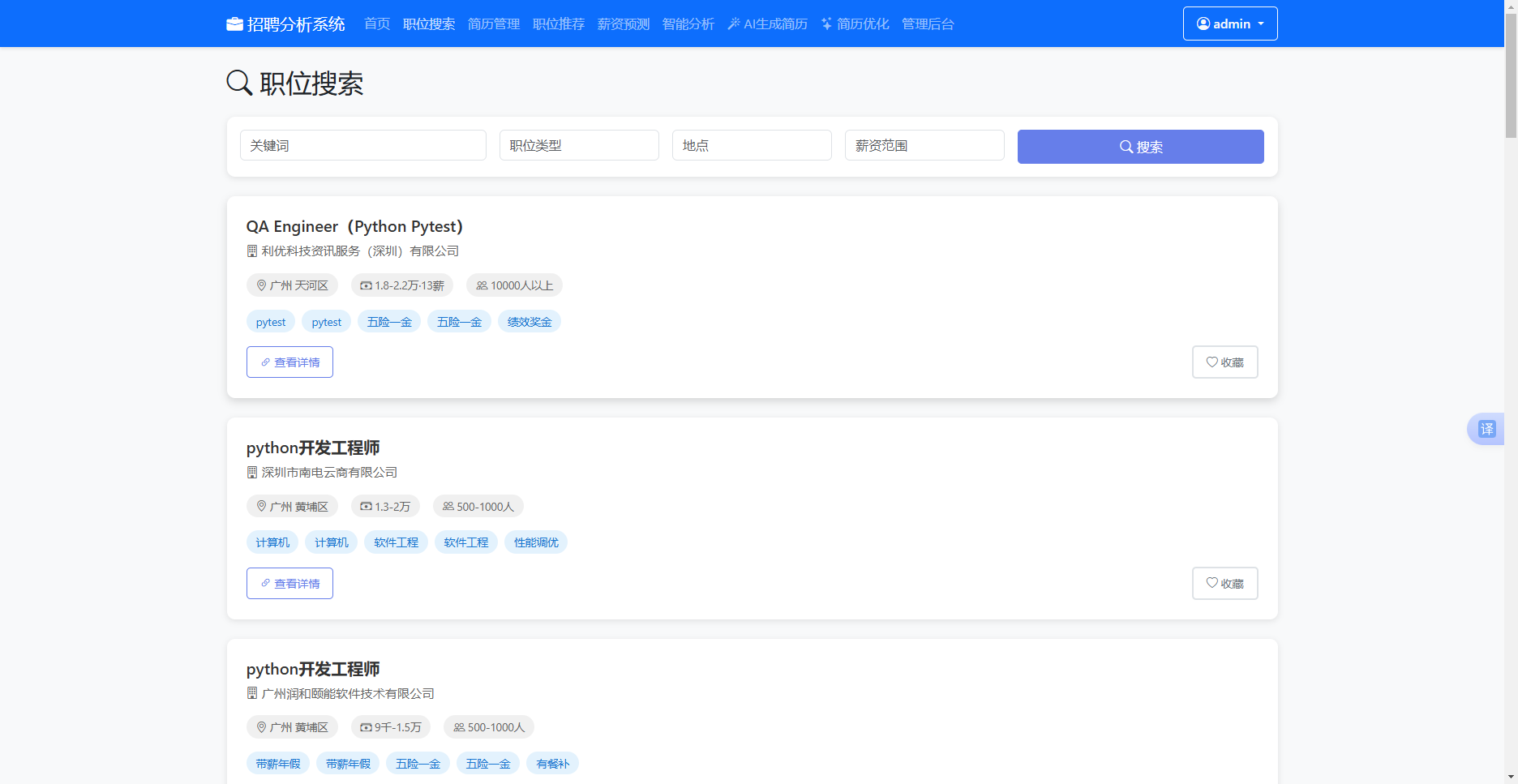
图5.5 职位搜索与收藏界面
5.3.3 简历管理模块
简历管理模块支持创建、编辑、删除和设为默认四种操作,简历表单涵盖二十二个字段,以模态框形式承载。创建简历时,表单顶部设置标题和姓名两个必填项,性别、出生日期、联系方式、期望职位、期望薪资等基础字段采用输入框或下拉选择器收集,教育背景、工作经历和项目经历三个复杂字段以JSON数组形式存储。前端在提交前未做深度校验,后端saveResume函数接收JSON请求体后首先判空title字段,随后检查is_default标志:若设为默认简历,则先将该用户下所有其他简历的is_default字段批量更新为False,再插入新记录,确保默认简历的全局唯一性。
编辑简历时,前端通过apiRequest获取已有简历详情,将各字段值回填至模态框表单控件,标题区域动态切换为“编辑简历”,提交方法根据隐藏域中的resumeId判断执行PUT或POST请求。删除操作触发confirm确认对话框,后端按主键匹配用户所有记录后执行级联清除。设为默认功能封装为独立的POST端点,路由接收resumeId参数后先执行批量取消默认、再设置目标简历为默认的两个数据库写操作。简历列表以卡片布局展示,每张卡片渲染标题、姓名、期望职位、期望地点和薪资信息,并依据is_default和is_public字段显示对应徽章标签。
图5.6 简历管理界面
5.3.4 AI简历分析模块
AI简历分析模块是本系统智能化的核心组件之一,采用流式传输实现分析报告的实时渐进渲染。用户在分析页面通过下拉菜单选中目标简历后点击分析按钮,前端的startAnalysis函数将resumeId封装为请求体,向“/api/ai/analyze”端点发起POST调用。该调用使用fetch API的标准Promise链,但在获取响应后并未直接等待完整JSON,而是调用response.body.getReader()以流模式逐块读取响应体。
后端analyze_resume路由函数首先按resume_id和user_id检索简历,确认归属权后调用build_analysis_prompt函数构建提示词。该函数将简历的姓名、性别、学历、工作经历、项目经历、技能、证书和自我评价等字段按预设模板逐项填充,模板前置角色设定语句将DeepSeek模型定位为“专业的简历分析师和职业规划顾问”,输出格式约束为七段式Markdown结构,明确要求在各评分段落以固定格式标注数值,便于后续正则表达式提取。提示词构建完成后,后端以stream=True参数调用requests.post向DeepSeek API发起流式请求,响应体按行迭代解析,跳过空行和非data字段行,提取choices[0].delta.content中的增量文本,通过yield语句逐块产出。Flask的stream_with_context生成器与Response对象配合,将普通视图函数转换为Server-Sent Events流式端点,响应头设置text/event-stream类型和no-cache缓存策略。
前端EventSource实例接收到每个data块后,调用marked.parse方法将Markdown增量文本实时转换为HTML并追加至分析内容容器。当接收到type为done的事件时,提取其中的三项评分数字写入评分卡片,并触发从零渐增的动画效果增强视觉反馈。完整分析结果同步存入analysis_jobSystem表,供用户日后回溯查看。
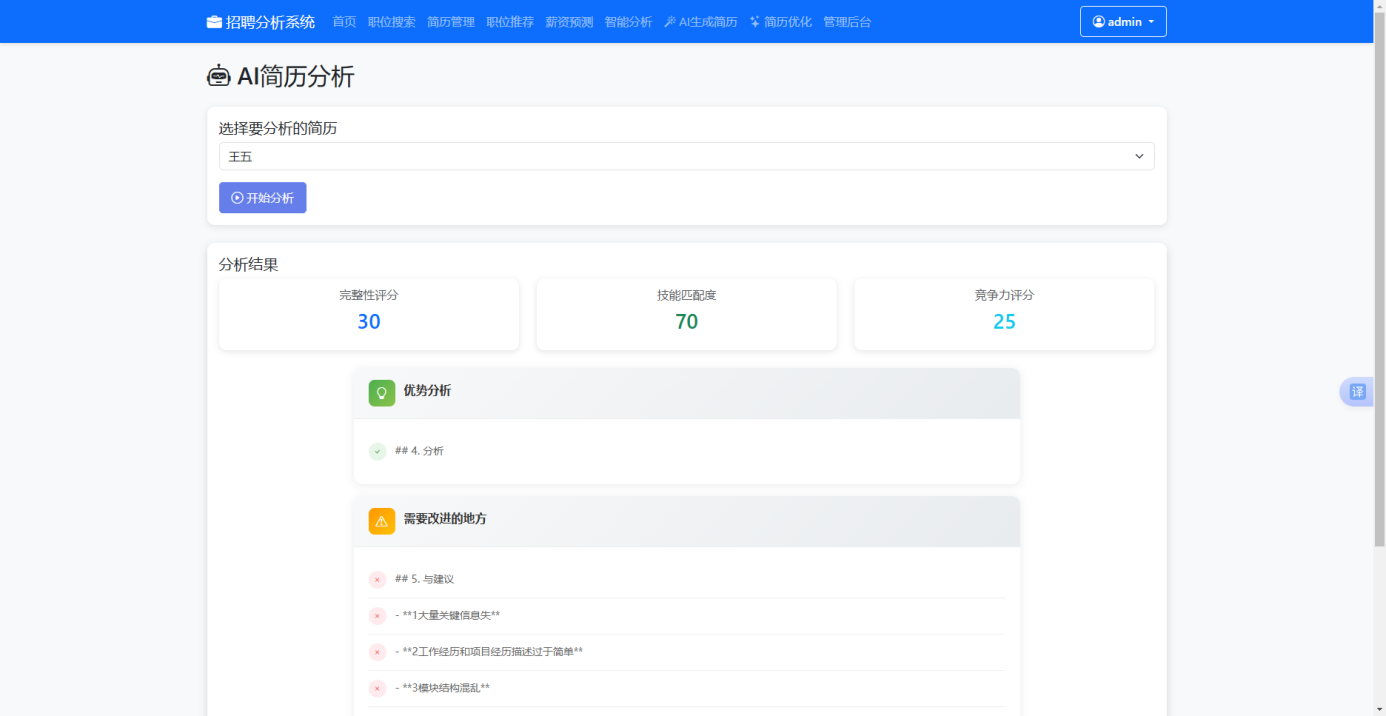
图5.7 AI简历分析界面
5.3.5 AI简历生成与优化模块
AI简历生成功能面向从零开始创建简历的用户场景。前端生成表单按信息类别划分为基本信息、教育背景、工作经历、技能与项目、期望五个区域,收集姓名、性别、出生年份、学历、专业、工作年限、当前职位、目标行业、关键技能、项目描述和薪资期望等结构化字段。表单提交时,generateResume函数将所有字段封装为扁平JSON对象,通过POST请求发送至“/api/ai/generate”端点。
后端generate_resume路由函数接收用户信息后,将其填充至build_generate_prompt模板,模板以“你是一位专业的简历优化师和职业顾问”开头,通过章节编号和分项指令约束输出结构,要求模型依次生成基本信息、求职意向、教育背景、工作经历、项目经历、技能特长和自我评价七个章节,并在末尾附上结构化JSON数据块。API调用采用与简历分析相同的流式传输机制,前端将收到的增量内容累积后调用formatResumeContent函数进行二次结构化渲染。该函数通过正则表达式分离纯文本章节与JSON代码块,将Markdown章节按二级标题拆分为独立卡片,技能部分解析为标签云样式展示,联系方式提取为图标加文本的横向排列,最终呈现为视觉层次分明的简历预览页。
AI简历优化功能在分析基础上增加了“一键应用”交互。优化请求发送至“/api/ai/optimize”端点,后端首先调用calculate_resume_scores函数计算三项评分并立即通过yield回传,然后构建优化提示词调用模型。前端在接收到scores类型事件时触发评分圈图的动画函数animateScore,该函数利用CSS transition将SVG圆圈的stroke-dashoffset属性从初始周长值逐步缩减至目标偏移量,同步递增数字显示值。模型输出的优化建议经formatOptimizeResult函数按优势分析、改进项和优化建议三类解析为带图标的分组卡片。若模型返回了结构化JSON优化数据,前端显示应用按钮,用户点击后系统将优化数据通过“/api/ai/apply-optimization”端点写回原简历记录,完成从分析到优化的闭环操作。
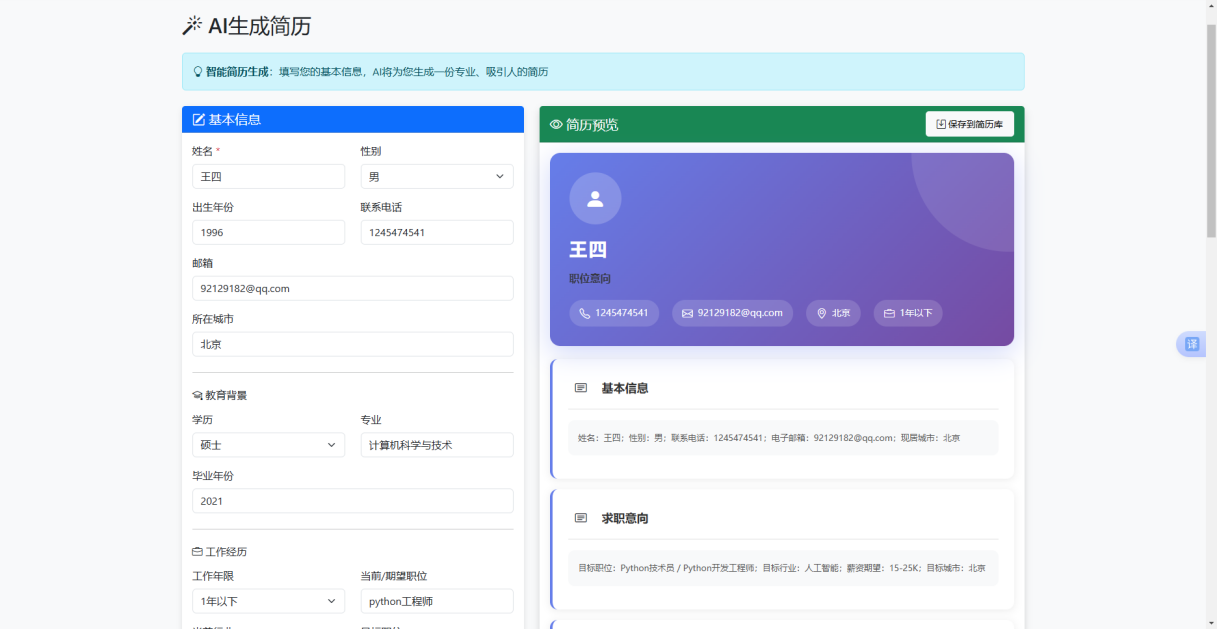
图5.8 AI简历生成界面
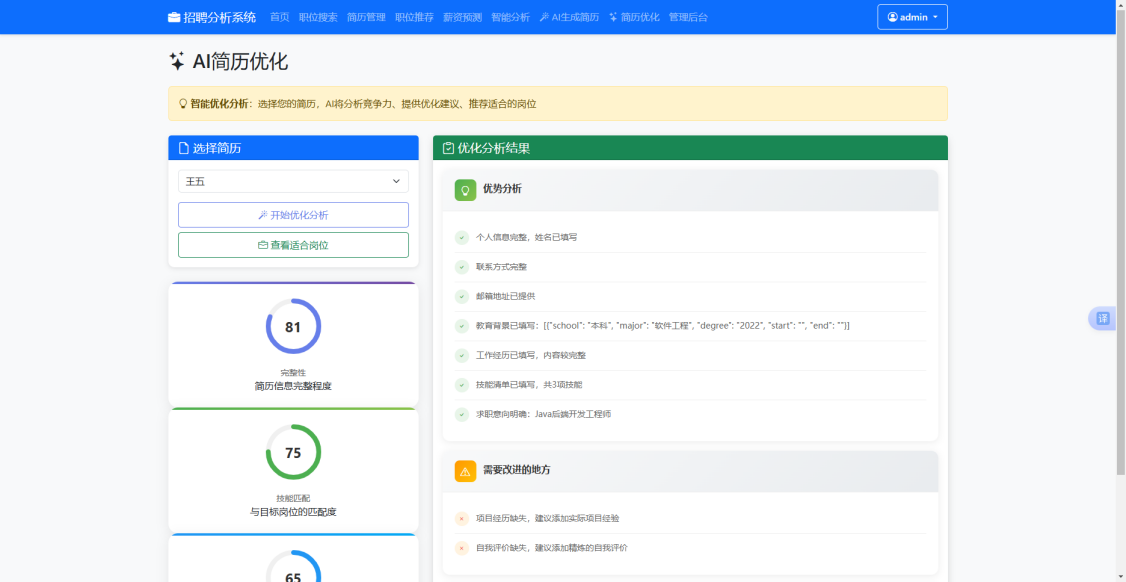
图5.9 AI简历优化界面
5.3.6 薪资预测模块
薪资预测模块将XGBoost回归模型部署为在线推理服务,为求职者提供定量的薪酬估计参考。前端预测表单包含五个输入控件:职位名称文本框、行业下拉选择器预置计算机软件、互联网、金融等十个选项、城市下拉选择器预置十个主要城市、公司性质下拉选择器涵盖民营、国企、外资等五种类型、公司规模下拉选择器按人数分七档。表单绑定submit事件,提交时predictSalary函数将五个字段的值组合为请求体,向“/api/salary/predict”端点发起POST调用。
后端predict_salary路由函数首先从请求体提取job_name、industry、city、company_nature和company_size五个参数,对job_name进行非空校验后调用salary_prediction_service实例的predict_salary方法。该方法首先检查模型实例是否已加载,若内存中无模型对象则尝试从models目录读取pickle序列化文件,反序列化失败时自动触发train_model方法重新训练。训练流程从job_jobSystem表中筛选salary字段非空的记录,调用parse_salary_to_number函数将“8千-1.5万”等中文薪资文本通过正则提取数字并依据“千/万”单位转换为数值型月均薪资标签。五个类别特征依次经过LabelEncoder编码为整型ID,编码器内部维护一个known_classes集合,预测时若遇到训练期未出现的新标签值则映射至最常见类别,防止模型报错中断。编码后的特征向量输入XGBoost模型的predict方法,输出浮点型月薪预测值后乘以系数得到置信区间上下界。
模型的特征重要性属性feature_importances_按字段名映射为键值对,连同预测值、区间和相似职位列表打包返回。相似职位检索通过_get_similar_jobs方法实现,该方法先按城市加行业加职位关键词组合查询,若候选结果数量不足则依次放宽城市和行业条件,最终回退到最近入库职位作为兜底推荐。前端接收响应后,displayPredictionResult函数将预测薪资格式化为万元单位显示,薪资区间以破折号连接呈现,特征重要性渲染为横向进度条列表,相似职位以带相似度徽章和外部链接的卡片列表展示。
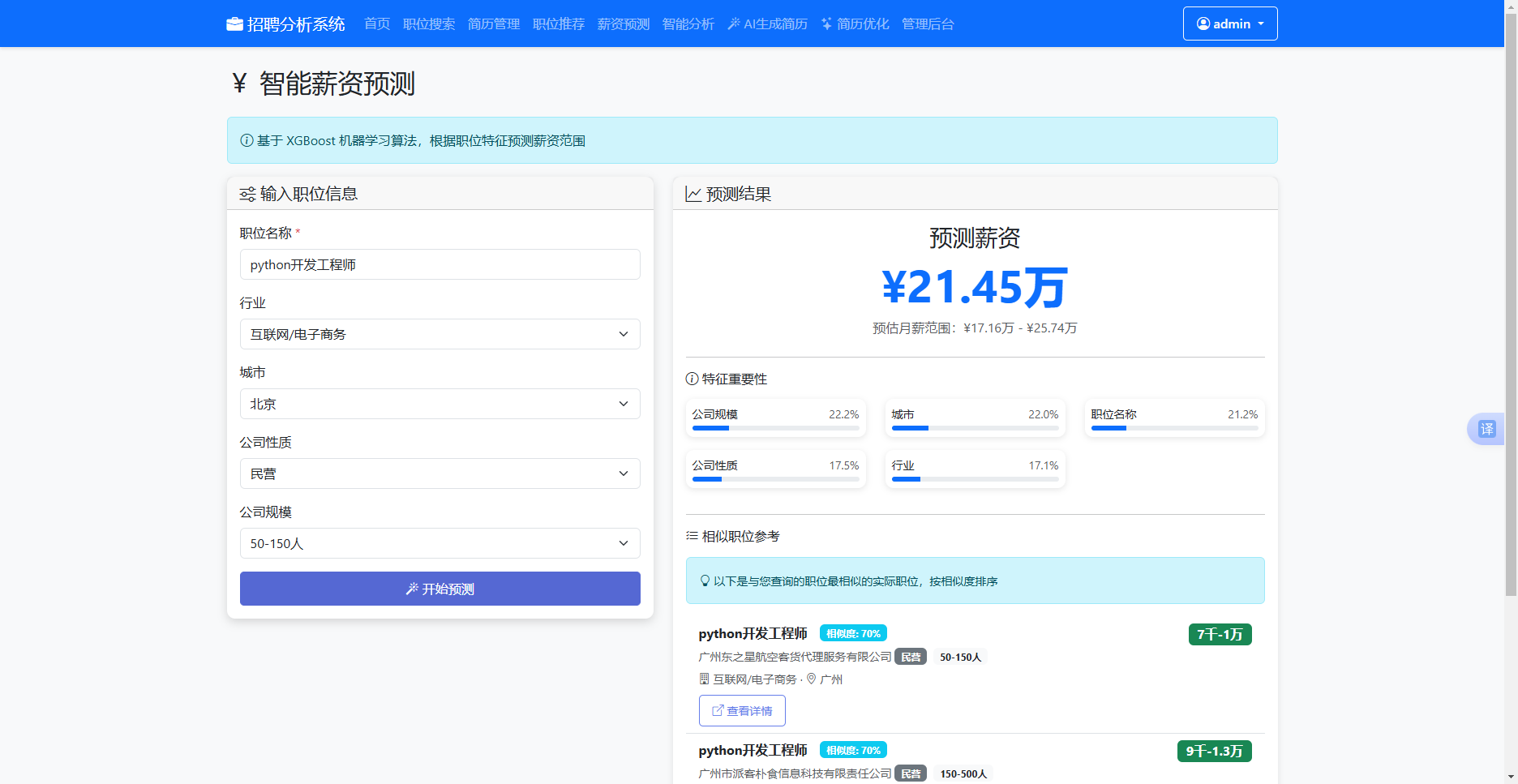
图5.10 薪资预测界面
5.3.7 职位推荐模块
职位推荐模块采用加权多策略融合算法,在不依赖用户显式评分数据的前提下生成个性化推荐列表。前端推荐页面无筛选控件,用户通过导航栏进入后自动触发loadRecommendations函数,向“/api/job/recommendations”端点请求分页数据。
后端get_recommendations路由函数首先检查当前用户是否设有默认简历,若存在则提取其期望职位、技能标签和地点偏好作为内容匹配的依据。随后遍历job_jobSystem表全量职位记录,对每个岗位计算五项子得分。内容匹配得分通过calculate_content_match函数计算:职位名称包含简历期望职位词则加0.4分,简历技能标签与岗位tags字段的公共词项占比乘以0.3分,地点偏好命中城市或区县加0.15分,薪资字段存在加固定0.15分。热度得分取view_count与favorite_count两倍之和除以一百后截断至1.0上限。时间衰减得分采用线性衰减公式,计算当前日期与职位创建日期的天数差d,衰减因子为max(0, 1-d/365),使得一年以上陈旧的职位衰减至零。协同过滤得分通过calculate_collaborative_filtering函数统计与当前用户有共同收藏记录的其他用户群中同时收藏当前职位的人数比例。个性化得分依据用户历史收藏中行业和职位名称的重合次数给予微量加分。五项得分按配置文件中的权重向量乘以对应系数后累加为最终评分,所有职位按评分降序排列后分页返回。每条职位卡片在标题右侧以红色徽章标注匹配度百分比,增强用户对推荐依据的感知。
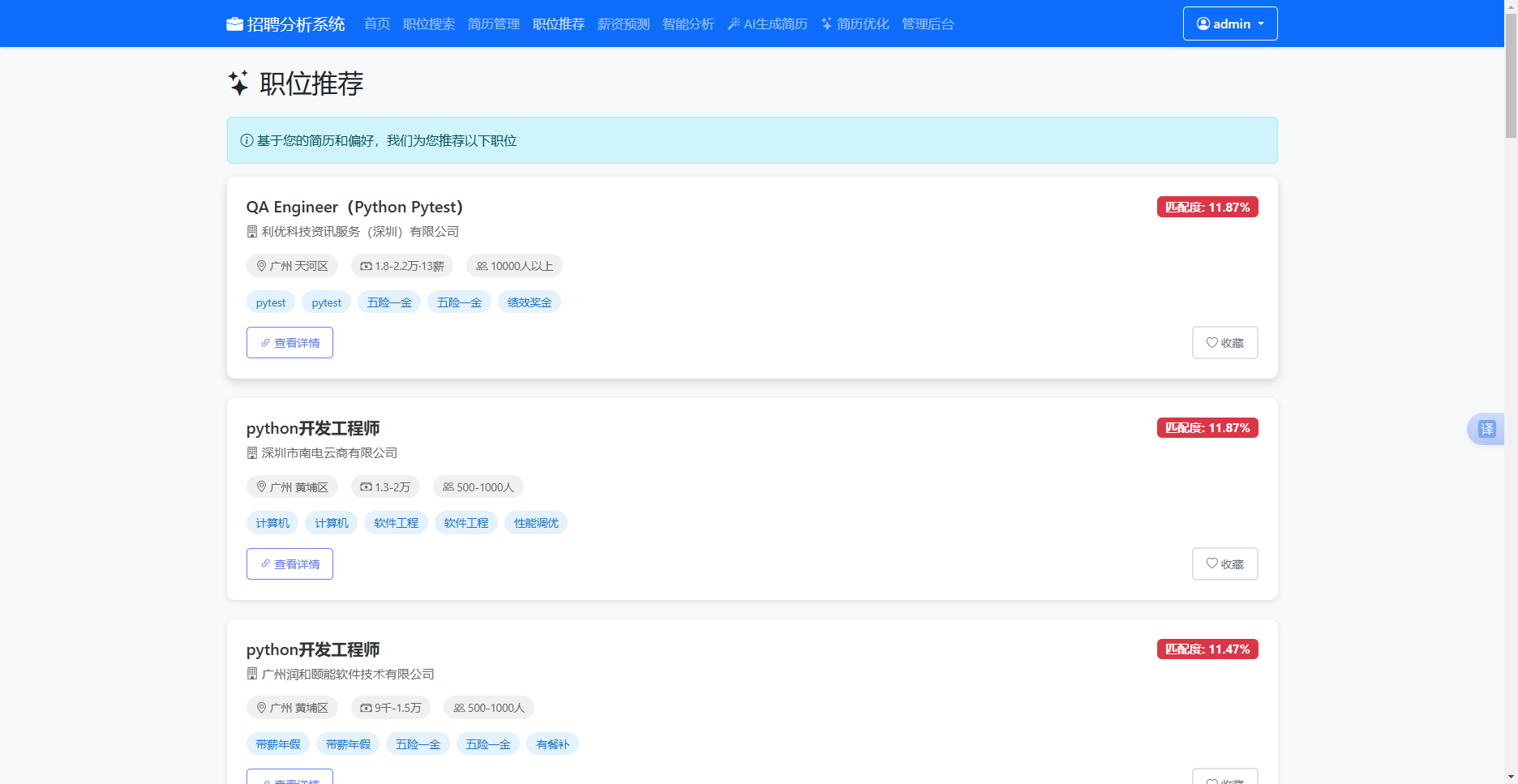
图5.11 职位推荐界面
5.3.8 管理后台数据分析模块
管理后台数据分析模块面向系统管理员提供统计概览、可视化图表和智能分析报告三项功能。管理员进入后台页面时,loadAdminDashboard函数同步发起三个API请求:统计接口“/api/admin/statistics”返回用户总数、活跃用户数、管理员数、职位总数、简历总数和收藏总数六项指标,四项数字卡片分别渲染为蓝、绿、青、橙色背景的统计面板;仪表盘分析接口“/api/admin/analytics/dashboard”返回热门职位列表、薪资分布、行业分布、城市分布和技能需求五类数据。
薪资分布数据的渲染通过renderSalaryChart函数实现,该函数获取页面中salary-chart容器后调用echarts.init初始化图表实例,将接口返回的name-value键值对数组映射为X轴类目和Y轴数值,series设置为蓝色柱状图。行业分布和城市分布同理,分别挂载至industry-chart和city-chart容器,采用饼图和柱状图两种形式展示。技能需求词云图通过renderSkillChart函数调用WordCloud.js库渲染,该函数先将原始计数值按平方根归一化缩放至十二到六十像素之间的字体大小区间,然后调用WordCloud函数在skill-chart画布上绘制彩色随机朝向的词云。
智能分析报告功能整合了三个独立分析接口。applyDateFilter函数读取日期筛选控件的起止值后,分别请求job-trend、industry-competition和regional-opportunity三个端点。职位热度趋势数据经renderJobTrendChart函数渲染为面积折线图,X轴显示日期序列,Y轴展示每日职位发布数量,底部添加ECharts的dataZoom滑动条控件支持时间范围缩放。行业竞争度数据包含各行业的职位数、公司数、竞争指数和热度指数四个指标,renderIndustryCompetitionChart函数采用双Y轴混合图表,左轴显示职位数量柱状图,右轴叠加竞争指数和热度指数两条折线,辅以图例区分。地域机会分布数据经renderRegionalOpportunityChart函数渲染为三系列组合图,柱状图表示各城市职位数量,两条折线分别表示平均薪资和机会指数,右Y轴刻度同时适用于薪资和指数两种量纲。generateIntelligentReport函数汇总三项分析结果后将文本摘要注入页面顶部的蓝色提示卡片,使管理员无需逐图解读即可快速获取关键结论。
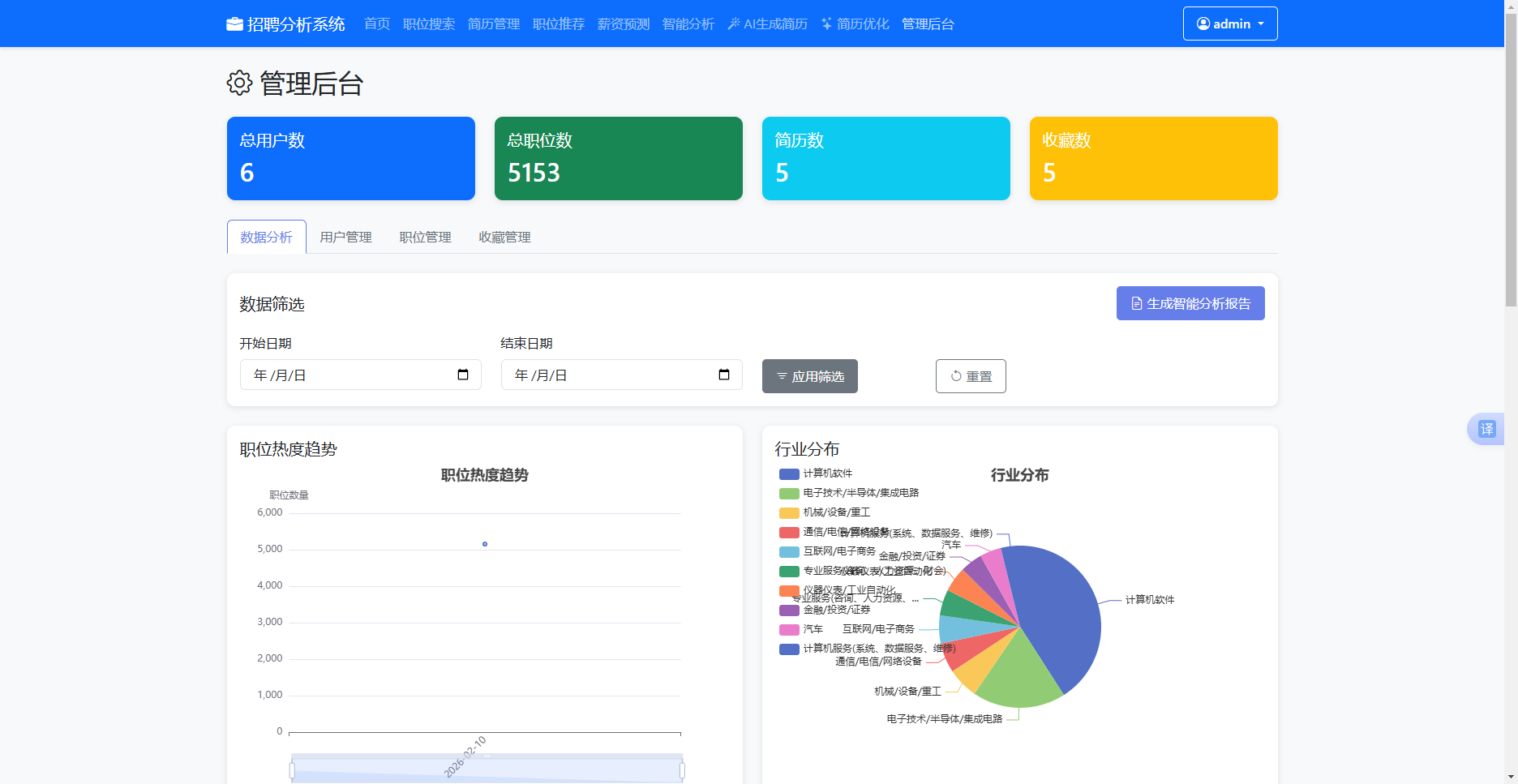
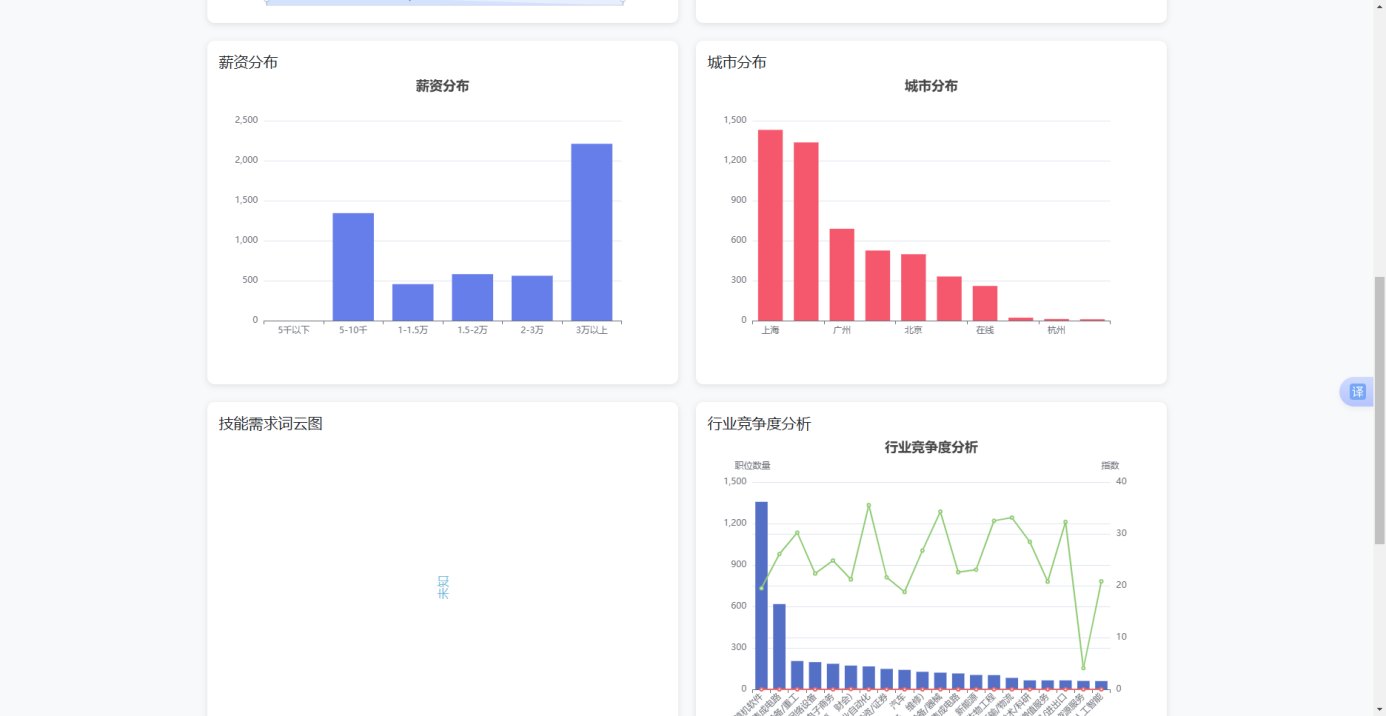
图5.12 管理后台数据分析界面

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐


 1
1 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)