【OpenClaw】通过 Nanobot 源码学习架构---(5)Context目录
x00 概要
OpenClaw 应该有40万行代码,阅读理解起来难度过大,因此,本系列通过Nanobot来学习 OpenClaw 的特色。
Nanobot是由香港大学数据科学实验室(HKUDS)开源的超轻量级个人 AI 助手框架,定位为"Ultra-Lightweight OpenClaw"。非常适合学习Agent架构。
丰富的上下文信息是 Agent 有效规划和行动的基础。一个 Agent 在工作时需要访问的”上下文”如下:
| 上下文类型 | 举例 | 存储方式 |
|---|---|---|
| 对话历史 | 用户刚才说了什么 | JSON / 数据库 |
| 长期记忆 | 用户偏好、过往总结 | 向量数据库 / 知识图谱 / 文本 |
| 外部知识 | RAG 检索的文档 | 向量数据库 / API / 文本 |
| 工具定义 | 可调用的函数描述 | 代码 / MCP 协议 / 文本 |
| 人类输入 | 标注、纠正、审核 | 文本 / 表单 |
| 临时草稿 | 推理中间结果 | 内存 / 临时文件 |
这些东西格式不同、存储不同、访问方式不同。如果没有统一抽象,每接一个新资源就得写一堆胶水代码。这些东西怎么存、怎么选、怎么压缩、怎么塞进那个有限的 token 窗口里——这才是真正决定 AI 效果的关键。
ContextBuilder 类是 Nanobot Agent 的「上下文大脑」,将分散的身份、记忆、技能、运行时信息整合为 LLM 可识别的标准化对话上下文;其核心价值为:屏蔽了上下文构建的复杂性,为 Agent 提供「开箱即用」的完整对话上下文,是连接 Agent 各模块与 LLM 的核心枢纽。
注:本系列借鉴的文章过多,可能在参考文献中有遗漏的文章,如果有,还请大家指出。
0x01 提示词系统
1.1 OpenClaw
OpenClaw 的提示词系统由一组放置在工作区目录下的Markdown文件组成,每个文件承担特定职责。这几个被注入的Markdown文件来自Workspace 的一组 .md 文件,每个文件都有独特的作用,而且易于读写:
- AGENTS.md:操作手册。Agent 应该如何思考,何时使用哪个工具,遵循什么安全规则,按什么顺序做事。
- SOUL.md:性格与灵魂。语气、边界、优先级。希望 Agent 简洁明了不给多余建议?写在这里。想要一个友好的助手?也写在这里。
- USER.md:你的用户画像。如何称呼你,你的职业,你的偏好。Agent 在每次回复前都会读取这个文件。
- MEMORY.md:长期记忆。绝不能丢失的事实。
- YYYY-MM-DD.md:每日日志。今天发生了什么,哪些任务正在进行,你们讨论了什么。到了明天,Agent 会打开昨天的日志并接续上下文。
- BOOTSTRAP.md:首次运行仪式(一次性,仅全新工作空间注入),如引导对话等
- IDENTITY.md:身份与氛围。很短的文件,但它奠定了整体的基调。
- HEARTBEAT.md:定期检查清单。“检查邮件”、“看看监控是否在运行”。
- TOOLS.md:本地工具提示。脚本存放在哪里,哪些命令可用。这样 Agent 就不需要去猜,而是确切知道。
1.2 Nanoboot
在 Nanoboot 中也是类似的 Markdown 文件系统,比如:
BOOTSTRAP_FILES = ["AGENTS.md", "SOUL.md", "USER.md", "TOOLS.md", "IDENTITY.md"]
SOUL.md 的内容如下:
# Soul
I am nanobot 🐈, a personal AI assistant.
## Personality
- Helpful and friendly
- Concise and to the point
- Curious and eager to learn
## Values
- Accuracy over speed
- User privacy and safety
- Transparency in actions
## Communication Style
- Be clear and direct
- Explain reasoning when helpful
- Ask clarifying questions when needed
AGENTS.md内容如下:
# Agent Instructions
You are a helpful AI assistant. Be concise, accurate, and friendly.
## Scheduled Reminders
When user asks for a reminder at a specific time, use `exec` to run:
```
nanobot cron add --name "reminder" --message "Your message" --at "YYYY-MM-DDTHH:MM:SS" --deliver --to "USER_ID" --channel "CHANNEL"
```
Get USER_ID and CHANNEL from the current session (e.g., `8281248569` and `telegram` from `telegram:8281248569`).
**Do NOT just write reminders to MEMORY.md** — that won't trigger actual notifications.
## Heartbeat Tasks
`HEARTBEAT.md` is checked every 30 minutes. Use file tools to manage periodic tasks:
- **Add**: `edit_file` to append new tasks
- **Remove**: `edit_file` to delete completed tasks
- **Rewrite**: `write_file` to replace all tasks
When the user asks for a recurring/periodic task, update `HEARTBEAT.md` instead of creating a one-time cron reminder.
1.3 Claw0
我们用Claw0进行对比论证,Claw0中指出,系统提示词从磁盘上的文件组装. 换文件, 换性格。
其架构如下:
Startup Per-Turn
======= ========
BootstrapLoader User Input
load SOUL.md, IDENTITY.md, ... |
truncate per file (20k) v
cap total (150k) _auto_recall(user_input)
| search memory by TF-IDF
v |
SkillsManager v
scan directories for SKILL.md build_system_prompt()
parse frontmatter assemble 8 layers:
deduplicate by name 1. Identity
| 2. Soul (personality)
v 3. Tools guidance
bootstrap_data + skills_block 4. Skills
(cached for all turns) 5. Memory (evergreen + recalled)
6. Bootstrap (remaining files)
7. Runtime context
8. Channel hints
|
v
LLM API call
Earlier layers = stronger influence on behavior.
SOUL.md is at layer 2 for exactly this reason.
其要点如下:
- BootstrapLoader: 从工作区加载最多 8 个 markdown 文件, 有单文件和总量上限.
- SkillsManager: 扫描多个目录查找带 YAML frontmatter 的
SKILL.md文件. - MemoryStore: 双层存储 (常驻 MEMORY.md + 每日 JSONL), TF-IDF 搜索.
- _auto_recall(): 用用户消息搜索记忆, 将结果注入提示词.
- build_system_prompt(): 将 8 个层组装为一个字符串, 每轮重新构建.
0x02 ContextBuilder 基本功能
ContextBuilder 是 Nanobot 框架中智能体对话上下文的核心构建器,负责将「身份定义、引导文件、长期记忆、技能信息、运行时元数据、用户消息」等多维度信息整合为标准化的 LLM 对话上下文(system prompt + 消息列表),是连接 Agent 各模块(MemoryStore/SkillsLoader)与 LLM 的关键桥梁。
2.1 定义
class ContextBuilder:
"""Builds the context (system prompt + messages) for the agent."""
BOOTSTRAP_FILES = ["AGENTS.md", "SOUL.md", "USER.md", "TOOLS.md", "IDENTITY.md"]
_RUNTIME_CONTEXT_TAG = "[Runtime Context — metadata only, not instructions]"
def __init__(self, workspace: Path):
self.workspace = workspace
self.memory = MemoryStore(workspace)
self.skills = SkillsLoader(workspace)
数据依赖层级图如下:
ContextBuilder(顶层)
├─ workspace(输入参数)
├─ Memorystore(依赖实例)
│ ├─ workspace(输入参数)
│ ├─ MEMORY.md(文件路径)
│ └─ HISTORY.md(文件路径)
│
└─ SkillsLoader(依赖实例)
├─ workspace(输入参数)
├─ workspace/skills/(工作区技能目录)
流程闭环:初始化 → 上下文构建 → LLM 调用 / 工具执行 → 记忆整合 → 上下文更新 → 循环,形成完整的 Agent 执行闭环。
2.2 核心特色
- 模块化上下文构建:将系统提示词拆分为「身份核心、引导文件、记忆、常驻技能、技能摘要」多个模块,按需拼接,结构清晰且可扩展;
- 多源信息融合:整合静态引导文件(AGENTS.md/SOUL.md 等)、动态记忆(MemoryStore)、技能体系(SkillsLoader)、运行时元数据(时间 / 渠道 / 环境),形成完整的 Agent 上下文;
- 多媒体兼容:支持用户消息中嵌入 Base64 编码的图片,适配多模态 LLM 的输入格式;
- 标准化消息管理:提供工具调用结果、助手回复的标准化添加方法,严格遵循 LLM 对话消息格式规范;
- 运行时元数据隔离:将渠道、时间等运行时元数据标记为「仅元数据非指令」,避免干扰 LLM 的核心决策逻辑;
- 灵活的技能加载:区分「常驻技能(always=true)」和「技能摘要」,常驻技能直接嵌入上下文,其他技能仅提供摘要(需通过 read_file 工具读取),平衡上下文长度与功能完整性。
2.3 如何调用
2.3.1 _process_message
_process_message 是单条消息处理的核心入口,支持系统消息、斜杠命令、普通对话三种场景,完成「上下文构建→代理循环→结果保存→响应返回」全流程。
async def _process_message(
self,
msg: InboundMessage,
session_key: str | None = None,
on_progress: Callable[[str], Awaitable[None]] | None = None,
) -> OutboundMessage | None:
"""Process a single inbound message and return the response."""
# System messages: parse origin from chat_id ("channel:chat_id")
if msg.channel == "system":
messages = self.context.build_messages(
history=history,
current_message=msg.content, channel=channel, chat_id=chat_id,
)
final_content, _, all_msgs = await self._run_agent_loop(messages)
self._save_turn(session, all_msgs, 1 + len(history))
self.sessions.save(session)
return OutboundMessage(channel=channel, chat_id=chat_id,
content=final_content or "Background task completed.")
2.3.2 _run_agent_loop()
_run_agent_loop 函数是智能体的核心执行循环,通过不断调用大模型并根据响应决定是否调用工具,直到模型返回最终回答或达到最大迭代次数。
_run_agent_loop 会调用 ContextBuilder 来构建消息。
async def _run_agent_loop(
self,
initial_messages: list[dict],
on_progress: Callable[..., Awaitable[None]] | None = None,
) -> tuple[str | None, list[str], list[dict]]:
messages = initial_messages
while iteration < self.max_iterations:
response = await self.provider.chat(
messages=messages,
)
if response.has_tool_calls:
messages = self.context.add_assistant_message(
messages, response.content, tool_call_dicts,
reasoning_content=response.reasoning_content,
)
for tool_call in response.tool_calls:
messages = self.context.add_tool_result(
messages, tool_call.id, tool_call.name, result
)
else:
messages = self.context.add_assistant_message(
messages, clean, reasoning_content=response.reasoning_content,
)
return final_content, tools_used, messages
0x03 图例
3.1 关键交互
ContextBuilder 是核心枢纽,聚合 SkillsLoader(技能)和 MemoryStore(记忆)的输出,构建标准化 LLM 上下文;详细交互如下:
- ContextBuilder 与 MemoryStore 交互
ContextBuilder初始化(workspace)
↓
Memorystore(workspace) ← 创建实例
↓
build_system_prompt() → memory.get_memory_context() ← 获取长期记忆
↓
返回记忆上下文字符串
- ContextBuilder与SkillsLoader交互
ContextBuilderskillsLoader
↓
ContextBuilder初始化(workspace) SkillsLoader(workspace) ← 创建实例
↓
build_system_prompt()→skills.get_always_skills() ← 获取常驻技能列表
↓
load_skills_for_context() ← 加载技能内容
↓
build_skills_summary() ← 构建技能摘要
↓
返回技能相关内容字符串
3.2 设计特点

0x03 重点函数
我们依据核心流程流程图来梳理重点函数。
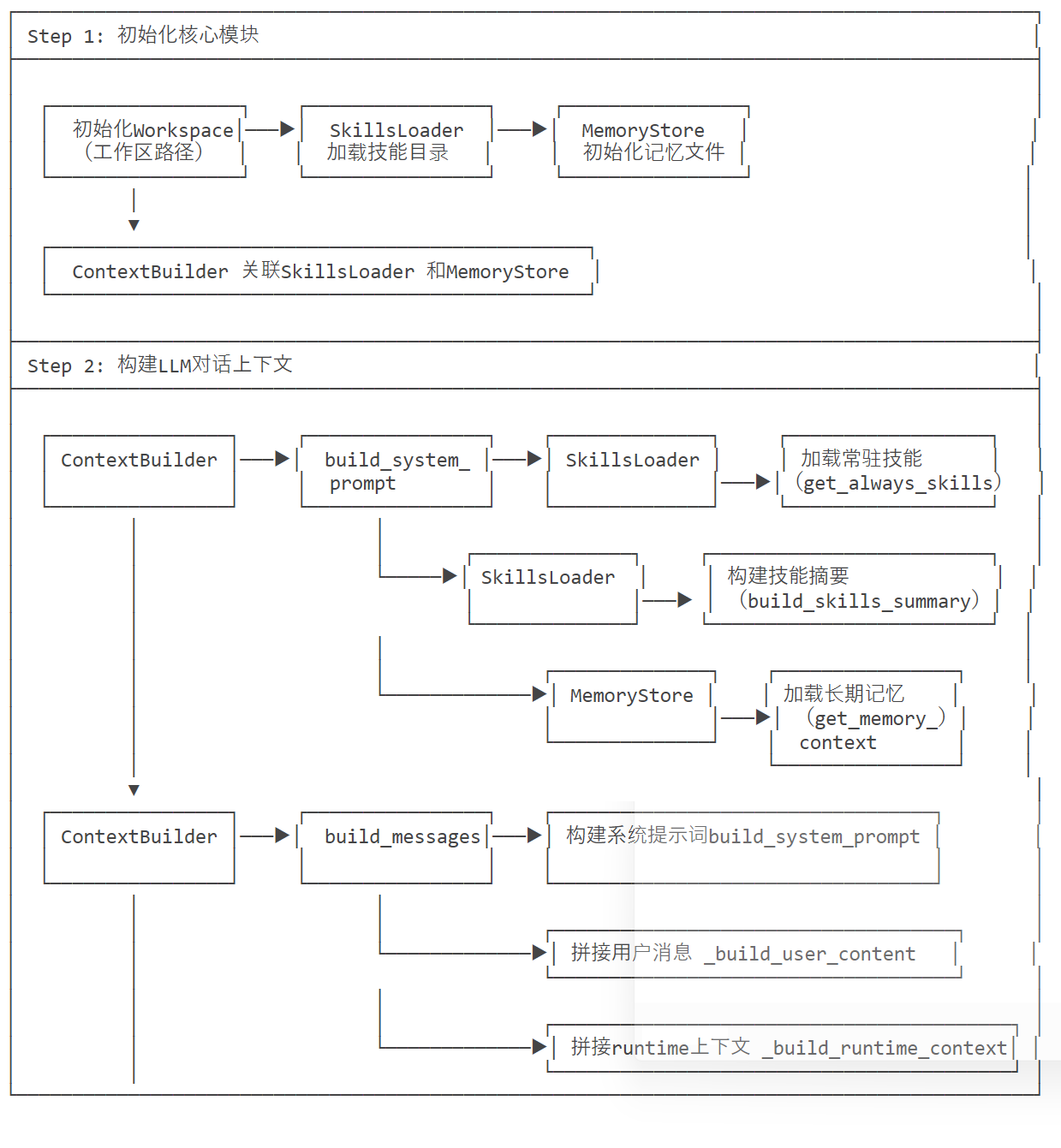
3.1 build_messages()
3.1.1 返回值
build_messages()` 最终返回一个 符合 LLM 对话格式的消息列表(list [dict [str, Any]]),每个字典代表一条对话消息,严格遵循「role + content」核心结构(扩展支持工具调用、多模态等字段)。
这个列表是 Nanobot 调用 LLM 时的完整输入上下文,包含系统提示、历史对话、运行时元数据、当前用户消息(支持文本 + 图片),是 Agent 与 LLM 交互的核心载体。
返回的消息列表按固定顺序包含以下 5 类核心内容(无内容时仍保留结构,空值会被上游逻辑过滤):
| 消息角色 (role) | 内容 (content) 核心构成 | 特殊字段 / 说明 |
|---|---|---|
| system | 由 build_system_prompt() 生成的完整系统提示(核心基座) |
无特殊字段,纯文本;是整个 Agent 的「身份 + 规则 + 技能 + 记忆 + 环境」总定义 |
| 继承自 history | 历史对话消息(可能包含 user/assistant/tool 等角色) | 完全复用传入的 history 列表结构,保留所有历史上下文 |
| user | 运行时元数据(时间 / 时区 / 渠道 / 聊天 ID),带固定标签 [Runtime Context — metadata only, not instructions] |
纯文本;仅作为元数据,LLM 不会将其视为用户指令 |
| user | 当前用户消息(文本 + 可选的 base64 编码图片) | 单文本 / 文本 + 图片列表;图片为 image_url 格式,兼容 OpenAI 多模态 API 规范 |
3.1.2 生成逻辑
build_messages() 的生成逻辑如下:
- 核心内容生成依赖
build_system_prompt()(系统提示)、_build_runtime_context()(元数据)、_build_user_content()(用户消息)三大辅助函数; - 生成逻辑是模块化拼接 + 条件过滤,兼顾灵活性(支持多模态 / 技能 / 记忆)和规范性(符合 LLM API 格式);
def build_messages(
self,
history: list[dict[str, Any]],
current_message: str,
skill_names: list[str] | None = None,
media: list[str] | None = None,
channel: str | None = None,
chat_id: str | None = None,
) -> list[dict[str, Any]]:
"""Build the complete message list for an LLM call."""
中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐


 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)