别只会调 API! 程序员必须搞懂的大模型基础知识在这里
文章目录
相信不少搞开发的同学都有这个体会:DeepSeek、ChatGPT、Claude 天天在用,但真要问"它是怎么工作的",脑子里一片空白。平时只能靠网上扒来的提示词模板东拼西凑,碰到模型答非所问、前后矛盾,也只能干瞪眼,根本不知道问题出在哪。
说白了,不懂点底层的东西,这些工具用起来就永远差那么一口气。
所以我最近在把自己学习AI时记录的东西整理成了这篇笔记,就用大白话把大模型到底是怎么一回事说清楚。
一、大模型到底是什么?
一句话定义:大模型(LLM,Large Language Model)= 海量数据 + 深度学习算法 + 超强算力训练出来的超大神经网络。
如果你觉得这句话还是太抽象,我们换个比喻:
想象你要培养一个"博学多才的助手",你让他读完了互联网上几乎所有的文章、书籍、代码、论坛帖子——大约相当于 500万套四大名著的文字量 ,经过数月的"闭关修炼"(GPU集群训练),他逐渐学会了语言的规律和知识的模式。这个助手,就是大模型。
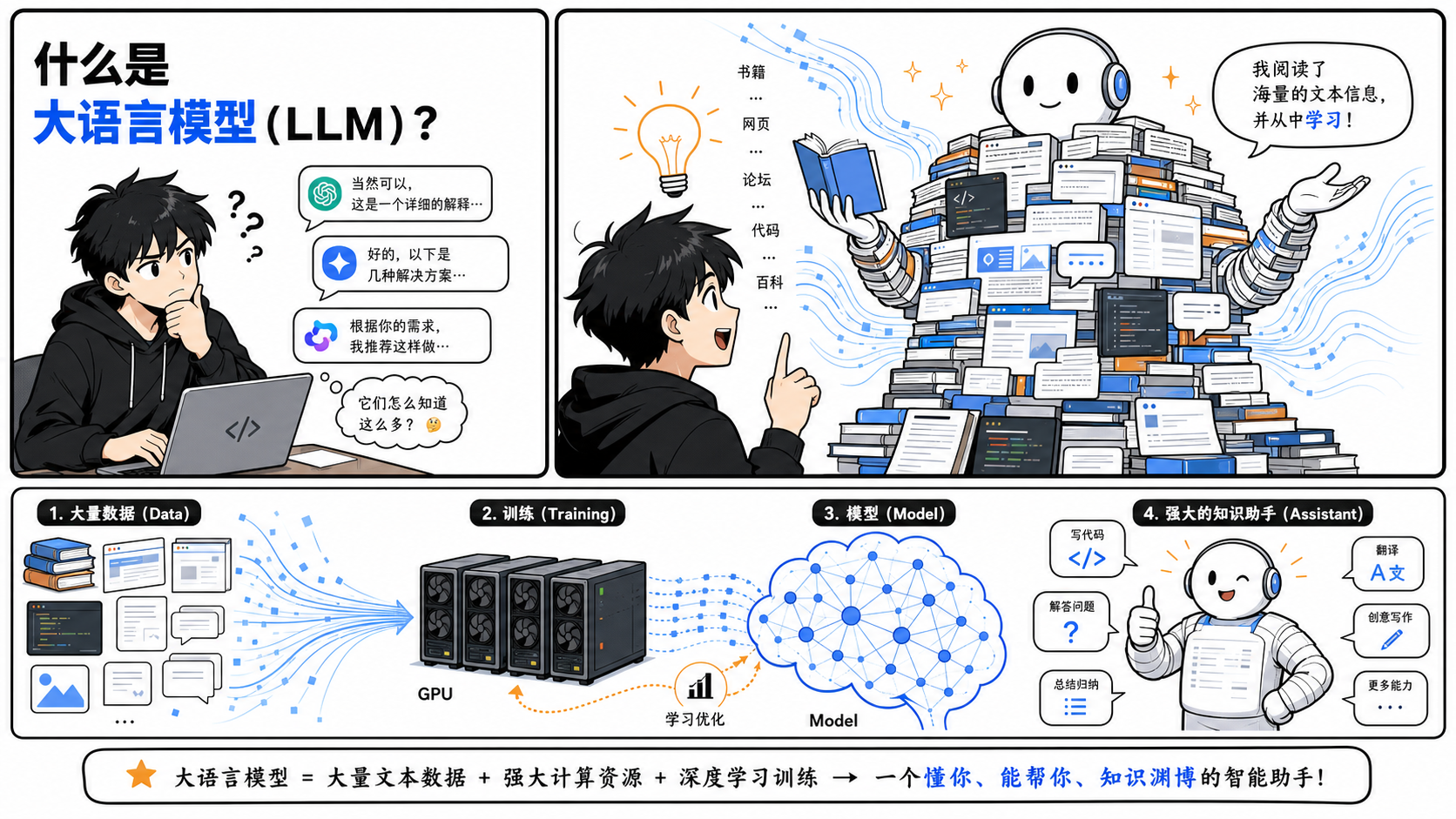
用更技术化的语言说:大语言模型是一种基于人工神经网络的语言模型,其"大"体现在两个维度 :
- 参数量巨大:通常在数十亿至数万亿级别(GPT-3 含 1750 亿参数)
- 训练数据规模惊人:需要海量无标注文本进行自监督学习
二、大模型在 AI 家族里处于什么位置?
很多人容易把 AI、机器学习、深度学习、大模型混在一起。它们的关系大致可以这样看:
人工智能 (AI)
└── 机器学习 (Machine Learning)
└── 深度学习 (Deep Learning)
├── 生成式AI (Generative AI) ← 能生成图片、音频、视频
└── 大语言模型 (LLM) ← 专注文本理解与生成
大语言模型不是凭空出现的新物种,而是深度学习在自然语言处理领域长期发展的结果。早期的 NLP 模型通常只能解决单一任务,比如分词、分类、翻译;而大模型把语言理解、生成、推理、代码补全等能力压到同一个模型里,通用性明显更强。
三、大模型的核心原理与技术
核心原理:预测下一个词
大模型最核心的任务,其实是预测下一个 Token。
给它一段上下文,它会计算下一个位置最可能出现什么,然后生成一个 Token;再把这个 Token 接回上下文,继续预测下一个。如此循环,最后得到一整段回答。
特斯拉前 AI 总监 Andrej Karpathy 有过一个很形象的说法:大模型本质上可以看成两个文件,一个是参数文件,也就是神经网络的权重;另一个是运行这些权重的代码文件。
整个工作流程如下:
- Tokenization(分词):将输入文本切分成一个个 Token(可以是词、子词或字符)
- Embedding(向量化):把每个 Token 映射为高维向量,让计算机能"理解"语义
- Transformer 注意力机制:通过编码器和解码器,捕捉词与词之间的上下文关系
- Next Token Prediction(预测):基于已有上下文,计算出最可能出现的下一个 Token
- Auto-regressive 生成:重复上述过程,一个词一个词地生成完整回复
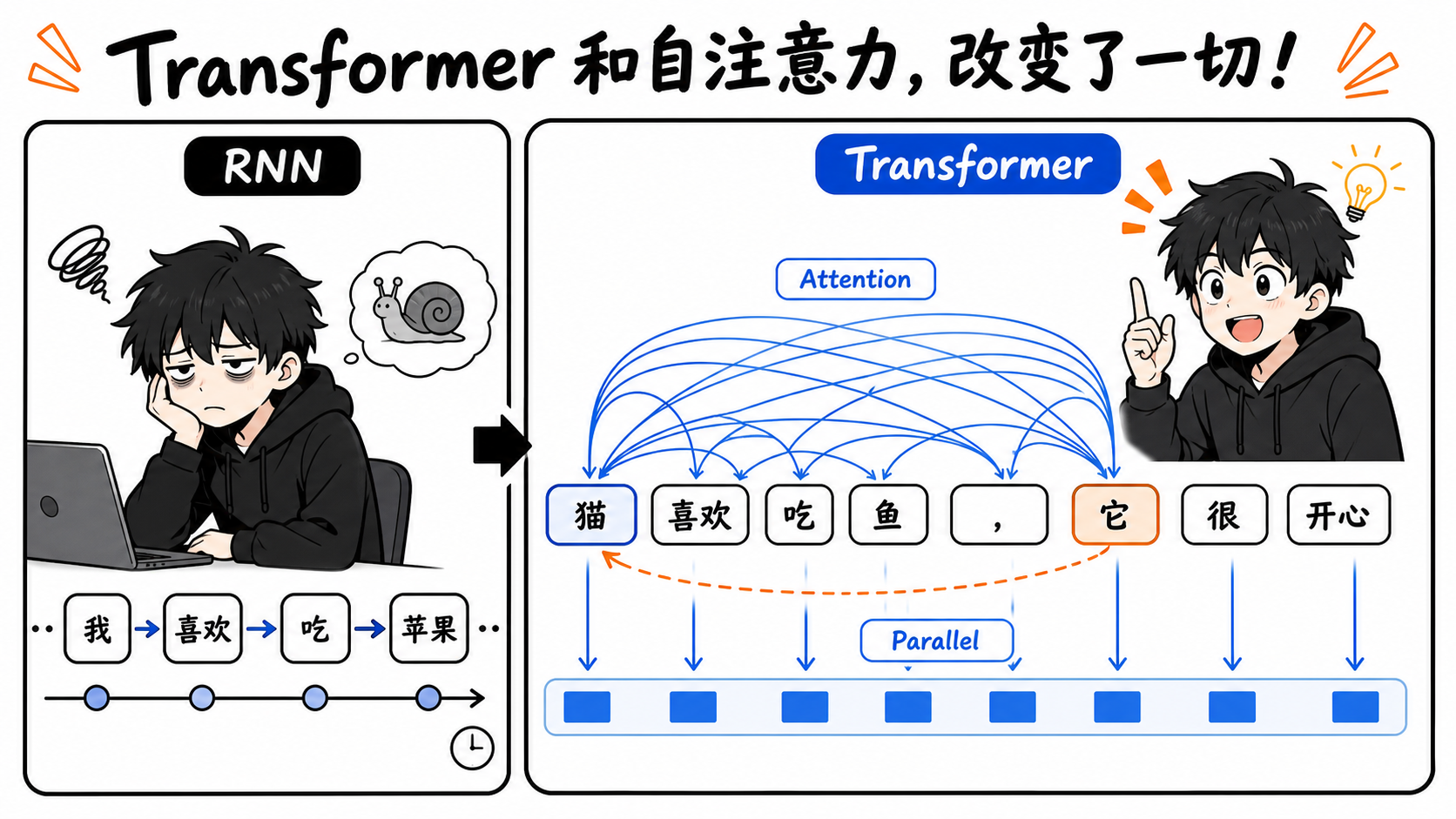
核心技术:Transformer架构
大模型能发展到今天的规模,离不开一个关键架构:Transformer。它由 Google 在 2017 年提出,后来成为几乎所有主流大语言模型的基础。
Transformer之前,大家咋做的?
之前处理语言任务,主要靠 RNN(循环神经网络)。
RNN的处理方式(串行):
"我" → "喜欢" → "吃" → "苹果"
↓ ↓ ↓ ↓
hidden1→hidden2→hidden3→hidden4→输出
致命缺点:
- ⚠️ 串行计算,不能并行,训练慢到怀疑人生
- ⚠️ 长程依赖问题:句子太长,前面的信息容易"忘掉"
Transformer:注意力机制才是王道
Transformer的核心是Self-Attention(自注意力机制)。
🎯 类比理解:
你在读"那只猫坐在垫子上,它看起来很舒服"这句话时,你的大脑会自动把"它"和"猫"关联起来。
Self-Attention就在做同样的事——让模型在处理每个词时,都能"回头看"全文所有词,并计算哪些词对当前最重要。
# 简化版 Self-Attention 计算示意(PyTorch风格伪代码)
import torch
import torch.nn.functional as F
def self_attention(Q, K, V):
"""
Q: Query矩阵 - "我想找什么?"
K: Key矩阵 - "我有什么?"
V: Value矩阵 - "我的实际内容是什么?"
"""
d_k = Q.size(-1) # 向量维度
# 第一步:计算Q和K的相似度(注意力分数)
scores = torch.matmul(Q, K.transpose(-2, -1)) / (d_k ** 0.5)
# 第二步:softmax归一化,得到注意力权重(概率分布)
attn_weights = F.softmax(scores, dim=-1)
# 第三步:用权重对V加权求和,得到输出
output = torch.matmul(attn_weights, V)
return output, attn_weights
Transformer 的革命性优势:
- ✅ 并行计算:所有词同时处理,GPU利用率拉满
- ✅ 全局视野:每个词都能直接"看到"句子里的所有其他词
- ✅ 可以无限堆叠层数:这是模型"变大"的基础
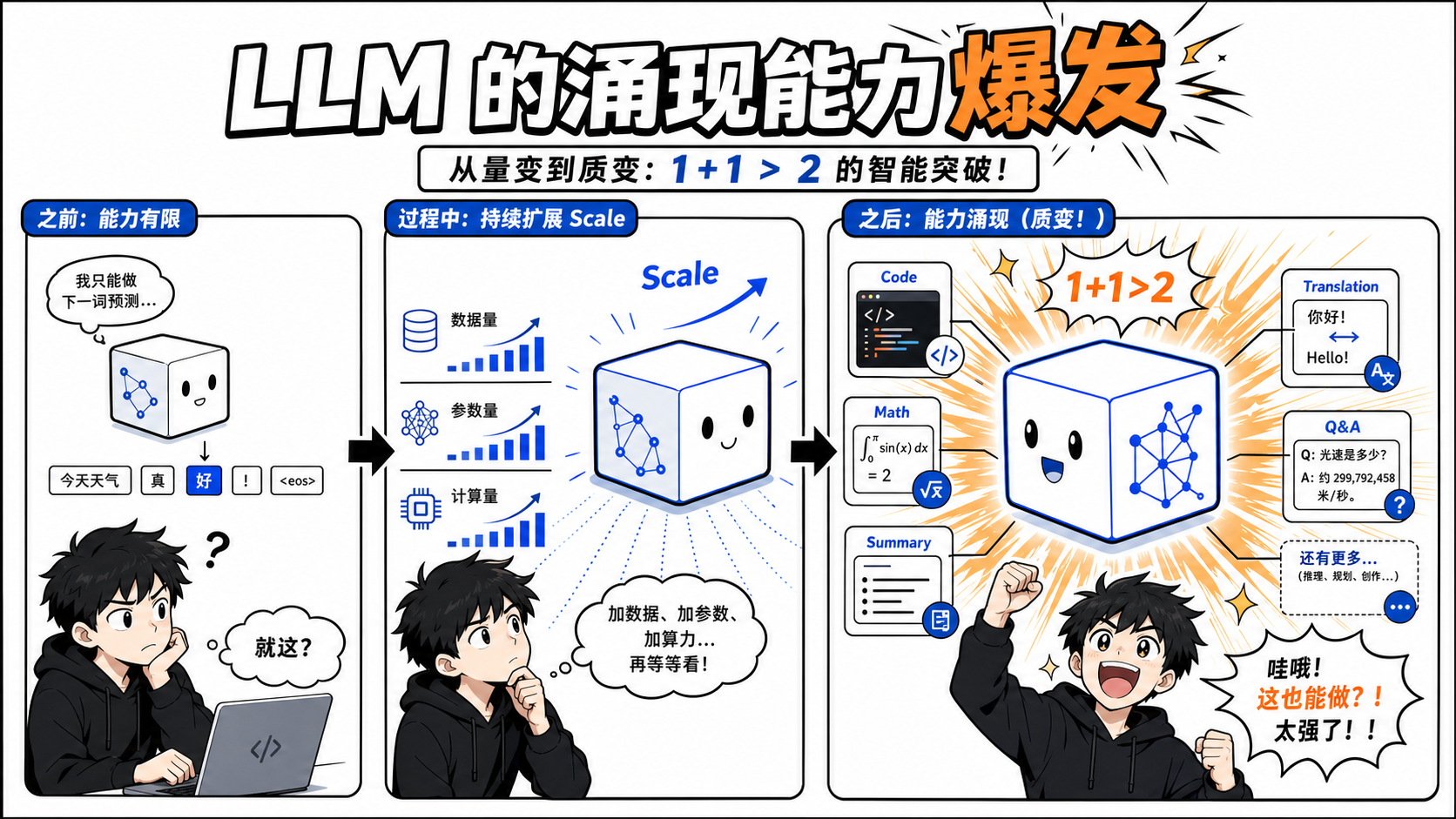
四、为什么叫"大"模型?
这里的“大”,不只是说数据多,更重要的是参数规模极大。
参数越多,模型能表示的模式越复杂,能够承载的语言规律、知识关联和任务行为也越丰富。当然,参数多不一定自动等于效果好,还要看数据质量、训练方法、模型架构和对齐方式。
| 模型 | 参数量 | 研发方 |
|---|---|---|
| GPT-3 | 1750 亿 | OpenAI |
| GPT-4 | 未公开(估计万亿级) | OpenAI |
| LLaMA 3 | 700 亿 | Meta |
| 文心一言 (ERNIE) | 未公开 | 百度 |
| ChatGLM | 60 亿~千亿 | 清华/智谱AI |
大模型训练中有一个很重要的经验规律,叫 Scaling Law(规模法则):在数据、参数和算力配比合理的前提下,模型规模扩大,性能通常会继续提升。今天的大模型能力,很大一部分就是在这个规律上不断堆出来的。
五、最神奇的地方:涌现能力
大模型让研究者真正惊讶的地方,是一些能力在小模型上并不明显,模型规模变大后却突然表现出来。这类现象通常被称为 涌现能力(Emergent Ability)。
例如,没有人逐条教 GPT-4 写每一种程序,但它能根据需求写出可运行代码;也没有人为每一道数学题单独写规则,它却能处理相当一部分推理题。模型并不是靠规则库逐条匹配,而是在大量语料和训练目标中学到了更通用的模式组合能力。
这也是大模型和很多传统 AI 系统的重要区别:传统系统往往围绕特定任务设计,而大模型更像一个通用语言接口,能把许多任务都转成文本理解和文本生成问题。
六、几行代码了解如何用 Java 调用大模型 API
理解原理之后,再看 API 调用会清楚很多。下面用 Spring AI 演示一个最基础的大模型调用。
// 引入 Spring AI 依赖后,注入 ChatClient
@RestController
@RequestMapping("/ai")
public class LlmDemoController {
private final ChatClient chatClient;
// Spring AI 自动装配 ChatClient
public LlmDemoController(ChatClient.Builder builder) {
this.chatClient = builder.build();
}
/**
* 最简单的大模型调用示例
* GET /ai/chat?message=什么是大模型
*/
@GetMapping("/chat")
public String chat(@RequestParam String message) {
// 直接调用大模型,返回文本回复
return chatClient.prompt()
.user(message)
.call()
.content();
}
/**
* 携带系统提示词(System Prompt)的调用
* 可以让大模型扮演特定角色
*/
@GetMapping("/chat/role")
public String chatWithRole(@RequestParam String message) {
return chatClient.prompt()
.system("你是一位专业的Java技术专家,请用简洁的语言回答问题")
.user(message)
.call()
.content();
}
}
核心配置(application.yml):
spring:
ai:
openai:
api-key: ${OPENAI_API_KEY} # 替换为你的 API Key
base-url: https://api.openai.com
chat:
options:
model: gpt-4o
temperature: 0.7 # 0=严谨确定,1=创意发散
💡这里最值得注意的是 temperature 参数。它控制的是模型生成时的随机性:写代码、做事实问答时可以调低,比如
0.1或0.2;写文案、头脑风暴时可以适当调高,比如0.7或0.8。
七、大模型的能力版图
大语言模型的能力远不止聊天。常见场景包括:
- 文本生成:写文章、邮件、报告、产品说明。
- 代码生成与审查:生成代码、解释代码、辅助排查问题。
- 语言翻译:在多种语言之间转换表达。
- 摘要提取:压缩长文档,提炼核心信息。
- 情感分析:判断评论、反馈、工单中的情绪倾向。
- 知识问答:结合 RAG,把企业文档、知识库接入问答系统。
- 多模态理解:像 GPT-4o、Gemini 这类模型,已经可以处理图片、音频、视频等输入。
这些能力看起来分散,本质上很多都可以转成“理解输入文本,再生成合适输出”的问题。大模型强的地方,正是把大量任务统一到了这个框架里。
八、大模型 ≠ 万能,你必须知道的局限
大模型好用,但不能当成绝对可靠的信息源。实际项目里,尤其要注意这些限制:
| 局限性 | 说明 |
|---|---|
| 幻觉(Hallucination) | 大模型可能自信地给出错误答案 |
| 知识截止日期 | 训练数据有时效性,不了解最新事件 |
| 上下文窗口限制 | 一次对话能处理的 Token 有上限 |
| 高昂的推理成本 | 千亿参数模型推理需要大量 GPU |
| 隐私风险 | 输入数据可能被模型提供商存储 |
其中最容易踩坑的是幻觉。模型生成的内容看起来可能很像真的,语气也很肯定,但不代表事实一定正确。凡是涉及业务决策、法律、医疗、金融、生产环境代码的内容,都应该有额外校验。
理解这些限制,才能在项目里正确使用它:让它做辅助生成、归纳、草拟、检索后的总结,而不是把所有判断都交给它。
九、一句话总结
大模型 = 在海量文本上训练出来的超大神经网络,通过预测下一个 Token,形成了理解和生成人类语言的能力。
它不是魔法,也不是数据库,更不是搜索引擎。它本质上是一个在海量文本里学到语言统计规律和知识关联的概率模型。预测下一个 Token 是它最基本的动作,问答、写作、翻译、代码生成等能力,都是这个动作在足够大的数据、参数和算力规模下延展出来的结果。
理解了这一点,再去使用大模型,预期会更准确:它擅长生成、改写、归纳和组合,也可能编造、遗漏和误判。把它当成一个强大的协作工具,而不是一个永远正确的答案机器,才更接近它真正的用法。
如果这篇文章对你有帮助,欢迎点赞收藏⭐,后续将继续更新《大模型系列》——包括提示词、MCP、RAG、Agent等进阶内容,敬请关注!

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐

 14
14 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)