别只看向量检索快不快:我从报错、维护和交接三个角度,重新做了一遍 RAG 知识库
先把结论放前面。
如果你做的是知识库问答、文档检索、客服辅助、内部资料搜索、项目文档中台这类事情,真正决定一个方案能不能长期活下去的,往往不是“首屏召回快不快”,而是“出问题以后好不好修、换人以后接不接得住、文档更新以后会不会炸”。
我前面做向量数据库、RAG 和 API 接入时,最初也很容易陷进一个误区:总想把向量检索跑得更快一点,top_k 再调一调,chunk 再切细一点,embedding 模型再换一个。结果越往后做越发现,很多项目真正卡住的不是召回率,而是维护成本。
所以后来我换了一个角度看“向量引擎”。
我不再把它当成一个单纯的检索层,而是把它当成一层“故障缓冲层”和“交接层”。
它的价值不是把所有问题都变没,而是把很多原本分散在脚本、接口、数据库、前端、任务队列里的小麻烦,统一收口成一套可以排查、可以替换、可以交接的流程。对个人开发者和中小团队来说,这一点特别重要。
因为项目一旦进入真实使用,日常最常见的不是“系统完全不能跑”,而是下面这些更琐碎、但更消耗人的问题:
- 某个文档更新后,旧答案还在被召回。
- 某个客户端改了
base_url,另一端还在用旧配置。 - 批量导入一多,
429、408、401开始轮着出现。 - 开发者自己能看懂的日志,过两个月别人看不懂。
- 机器从测试环境迁到线上后,延迟和错误率突然变了。
这些问题都不是“向量技术不行”,而是工程化没收好。
这篇文章我就不从“技术概念科普”切入了,而是换成一个更贴近实际的角度:如果你不是在做演示,而是在做要交付、要维护、要交接的知识库,向量引擎到底能帮你少掉哪些坑。
一、我后来为什么开始重视“维护视角”
刚开始做 RAG 的时候,我的关注点很单一,就是检索效果。
很典型的思路是:
- 文档做 embedding。
- 存进向量库。
- 查询时 top_k 检索。
- 结果喂给大模型。
- 看答案像不像那么回事。
如果只是验证 demo,这样没问题。
但只要你真的把它放到日常项目里,问题就会慢慢浮出来。不是一下子炸,而是像小毛病一样不断冒出来:
- 搜索结果一开始还行,文档一更新就开始漂。
- 某些用户问法很像,结果召回却不稳定。
- 前端和后端都能调通,但某些环境里就是报错。
- 新人接手以后,第一件事不是改业务,而是先问“这套东西怎么跑起来”。
我后来意识到,向量引擎这类工具,最该看的不是单次检索,而是一个月后的系统状态。
我会开始问这些问题:
- 这个方案能不能在低配机器上稳定跑?
- 文档更新以后,是局部重建还是整库重来?
- 一个接口报错以后,是不是 3 分钟能定位?
- 这套流程写给别人看,别人能不能复现?
- 如果明天换一个 embedding 模型,改动会不会很大?
这几个问题一旦开始进入视野,你对向量引擎的看法就会变。
以前我会觉得“向量引擎”这个词有点泛,像是把很多能力打包后重新命名。后来我更愿意把它理解成一层工程中台。它不负责替你做业务判断,但它会决定你的业务系统是不是容易出血。
二、为什么很多知识库项目,死在维护而不是死在效果
这个现象很常见。
很多项目在初期演示时都没问题,甚至看起来还挺惊艳:
- 上传文档,马上能问答。
- 检索结果还算准确。
- 大模型回答也挺像那么回事。
但一到后期,就开始出现三类问题。
1. 数据更新频繁,旧向量没处理干净
知识库不是静态网页,它会变。
产品文档会更新,FAQ 会改,制度会重写,技术手册会补版本,接口参数会新增。只要文档会变,旧向量就不能一直留着不管。
最麻烦的情况不是“完全查不到”,而是“查到了旧版本,还很像正确答案”。这类错误最难发现,因为它看起来并不离谱,但实际会误导用户。
2. 接口和环境不统一,报错越来越多
很多小团队一开始接入时,都是临时写个脚本试通。后来系统一多,就会出现:
- Python 脚本用的是一个
base_url。 - 后端服务用的是另一个
base_url。 - 前端还在直连旧域名。
- 同一个 API Key 在不同地方配置了不同权限。
这个时候一旦报错,你排查的就不是一个问题,而是一条混乱的链路。
3. 只有一个人懂,交接风险很高
这点特别现实。
很多知识库项目最初都很小,基本是一个人或者两个人搭起来的。第一个人写代码的时候,心里有完整上下文,知道哪一步该做什么。半年后换了人,代码还在,文档还在,但没人知道:
- chunk 是怎么切的。
- 向量是哪个模型生成的。
- 缓存为什么放在这里。
- 报错时到底看哪一层日志。
系统并没有“坏掉”,但它已经变得不容易维护了。
这也是我后来越来越重视向量引擎的原因。它的意义不只是“帮你检索”,更是“帮你把流程讲清楚、把边界收起来、把责任落到明确的地方”。
三、我现在评估一个向量引擎,先看这 4 个维度
以前我看方案会先看性能,现在我先看维护成本。
我会用下面四个维度去判断一个向量引擎是否适合长期用:
- 接入是否简单
- 排错是否容易
- 更新是否可控
- 交接是否清晰
这四个维度,几乎比“快 20%”更重要。
1. 接入是否简单
真正好的方案,不应该逼你一开始就读一大堆文档。
最起码要做到:
- 清楚的
base_url。 - 明确的鉴权方式。
- 可读的请求体。
- 返回字段稳定。
- 出错时能看懂。
如果接口设计本身就乱,那后面所有工作都会被拖慢。
2. 排错是否容易
对小团队来说,接口一旦报错,最贵的不是请求本身,而是排查时间。
我很看重这些信息是否齐全:
- 请求 ID。
- 原始响应体。
- 状态码。
- 具体失败阶段。
- 是 embedding 阶段失败,还是检索阶段失败,还是生成阶段失败。
如果这些信息能清楚地打出来,很多问题其实很快就能定位。
3. 更新是否可控
文档更新后最怕两件事:
- 全量重建太慢。
- 局部更新不干净。
比较理想的做法,是把文档版本、chunk 版本、embedding 模型版本拆开管理。这样出了问题以后,至少知道该回滚哪一层,而不是整套系统一起动。
4. 交接是否清晰
这个维度很多人会忽略。
但如果你的项目后面还要交给别人、扩给别人、甚至给业务同学看,那系统就不能只对你一个人友好。
我会尽量让它具备这些特征:
- 配置集中。
- 说明文档清楚。
- 核心参数固定。
- 日志能对应到操作。
- 失败时有明确兜底。
一个系统如果只能“我自己能修”,那它其实不算稳定。
四、三种路线,换成维护视角后差异很大
还是那三种常见路线:
- 自建 Milvus / FAISS。
- 直接对接第三方向量 API。
- 用向量引擎做中间层或中转层。
如果只看初始能力,它们看起来差别没有那么大。
但如果把“后续维护”放进去,差异会明显很多。
| 维度 | 自建 Milvus / FAISS | 直接第三方向量 API | 向量引擎中间层 |
|---|---|---|---|
| 初始部署 | 较重 | 最轻 | 中等 |
| 排错成本 | 偏高 | 中等偏高 | 相对更低 |
| 更新成本 | 容易受索引和部署影响 | 取决于接口和调用策略 | 可通过统一层收口 |
| 交接难度 | 容易变复杂 | 接口简单但分散 | 比较容易标准化 |
| 对小团队友好度 | 中等 | 高 | 高 |
| 对长期项目友好度 | 取决于运维能力 | 取决于稳定性和费用 | 通常更均衡 |
| 对多客户端接入 | 需要自己统一 | 容易出现多份写法 | 更适合统一管理 |
1. 自建 Milvus / FAISS
优点是控制权高。
问题是你要自己负责很多外围事情:
- 备份。
- 扩容。
- 索引构建。
- 服务健康检查。
- 版本升级。
- 故障恢复。
如果团队里有人很熟这一套,那没问题。可一旦人少、时间紧、需求还在变,它的维护成本会很明显。
2. 直接第三方向量 API
这个方案的好处是快,特别适合做原型验证。
但一旦开始长期使用,常见问题会变成:
- 网络波动。
- 超时。
- 鉴权错误。
- 调用限制。
- 参数不一致。
你会发现很多问题并不是“模型不准”,而是“外部接口不稳定、链路不统一”。
3. 向量引擎中间层
我现在更倾向把它当成“统一接口 + 统一排错 + 统一更新”的一层。
它不一定替你做所有底层工作,但它可以把:
- 文档处理。
- 批量 embedding。
- 查询缓存。
- 错误重试。
- 日志记录。
- 多客户端兼容。
这些本来很零散的动作,变成一条可以复用的流程。
对长期项目来说,这类中间层特别有价值。因为系统不是只给今天用的,它是要给明天、下个月、换人以后继续用的。
五、我现在搭一套向量引擎,最先做的不是性能,而是稳定
如果你是第一次做,我建议从一个很朴素的最小闭环开始。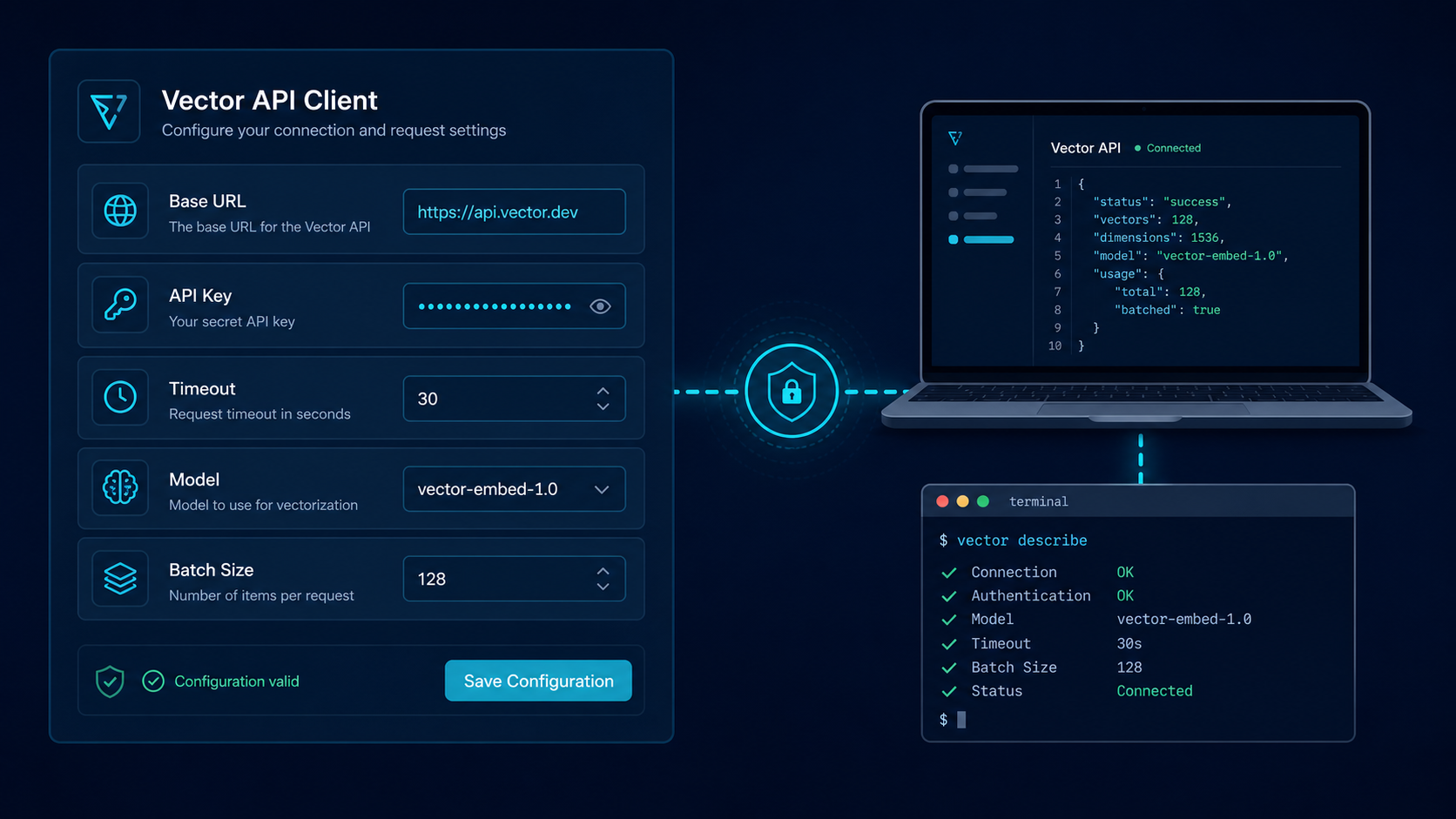
先别想太多花活,先把下面四件事做好:
- 配置管理。
- 请求封装。
- 错误日志。
- 缓存和重试。
1. 配置管理
先把所有核心参数放到一个地方,不要散落在脚本里。
VECTOR_BASE_URL=https://your-vector-gateway.example.com
VECTOR_API_KEY=your_api_key_here
VECTOR_EMBED_MODEL=bge-m3
VECTOR_TIMEOUT=30
VECTOR_TOP_K=5
VECTOR_BATCH_SIZE=32
VECTOR_NAMESPACE=kb-prod
2. 一个统一的请求封装
不要每个脚本都单独写一份请求逻辑。
import os
import time
from typing import List, Dict, Any
import requests
BASE_URL = os.getenv("VECTOR_BASE_URL", "").rstrip("/")
API_KEY = os.getenv("VECTOR_API_KEY", "")
MODEL = os.getenv("VECTOR_EMBED_MODEL", "bge-m3")
TIMEOUT = int(os.getenv("VECTOR_TIMEOUT", "30"))
class VectorClient:
def __init__(self):
self.session = requests.Session()
self.session.headers.update({
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json",
})
def request(self, path: str, payload: Dict[str, Any]) -> Dict[str, Any]:
url = f"{BASE_URL}{path}"
resp = self.session.post(url, json=payload, timeout=TIMEOUT)
resp.raise_for_status()
return resp.json()
def embeddings(self, texts: List[str]) -> Dict[str, Any]:
return self.request("/embeddings", {
"model": MODEL,
"input": texts,
})
def search(self, query: str, top_k: int = 5, namespace: str = "kb-prod") -> Dict[str, Any]:
return self.request("/search", {
"model": MODEL,
"query": query,
"top_k": top_k,
"namespace": namespace,
})
3. 批量处理和去重
知识库项目很容易重复导入,所以先做去重,再做批量。
import hashlib
def hash_text(text: str) -> str:
return hashlib.sha256(text.strip().encode("utf-8")).hexdigest()
def dedup_texts(texts: List[str]) -> List[str]:
seen = set()
result = []
for t in texts:
key = hash_text(t)
if key in seen:
continue
seen.add(key)
result.append(t)
return result
def batch_embeddings(client: VectorClient, texts: List[str], batch_size: int = 32, retries: int = 3):
texts = dedup_texts(texts)
all_rows = []
for i in range(0, len(texts), batch_size):
batch = texts[i:i + batch_size]
last_error = None
for attempt in range(retries):
try:
resp = client.embeddings(batch)
all_rows.extend(resp.get("data", []))
last_error = None
break
except Exception as e:
last_error = e
time.sleep(2 ** attempt)
if last_error:
raise last_error
return all_rows
4. 错误日志要能回放
很多项目一开始没把日志写全,等出错才发现没法定位。
我现在会至少记录这些东西:
- 请求时间。
- 请求 ID。
- 接口路径。
- 请求体摘要。
- 响应状态码。
- 原始错误信息。
这不是“为了看起来专业”,而是为了让后面的人能接住。
六、最常见的坑,不是模型,是配置和版本
做向量引擎和 RAG,我踩过最久的坑,往往都很普通。
1. base_url 写错
这个问题特别常见。
你以为是模型错了,实际上只是请求地址多了一个 /,或者少了一个版本前缀。
排查时最有效的办法不是猜,而是把最终请求 URL 直接打印出来。
2. API Key 没统一
有时候不是 Key 不对,而是系统里同时存在多个 Key:
- 测试 Key。
- 生产 Key。
- 旧 Key。
- 某个脚本里手写的临时 Key。
这会让排错非常痛苦。最好的方式就是把 Key 收敛到统一配置源,尽量别散在脚本里。
3. chunk 版本没管住
文档更新以后,chunk 也要更新。
如果你只更新了原文,但没有重新标记 chunk 版本,那么系统就可能把旧 chunk 和新 chunk 混在一起,结果看上去像是“命中了”,实际上内容已经不一致了。
4. 缓存没有失效机制
缓存是好东西,但没有失效策略就会变成坑。
至少要考虑这几个维度:
- 文档 hash 变了没有。
- 模型版本变了没有。
- 业务版本变了没有。
- 关键字段更新了没有。
5. 只测一次成功,不测长期稳定
这也是很多 demo 项目最容易忽略的地方。
一次成功不代表长期稳定。真正有价值的是:
- 连续请求一百次,错误率是多少。
- 文档更新后,召回是否一致。
- 高峰期并发上来以后,是否开始抖动。
- 新人接手后,是否还能在半小时内跑通。
七、排错时,我会按这个顺序看问题
向量引擎相关报错,最好别上来就怀疑模型。
我通常会按下面这个顺序排查:
第一步:确认请求链路
base_url对不对。- 鉴权头对不对。
- 路径对不对。
- 请求方法对不对。
第二步:看原始响应
很多时候错误信息已经写在响应体里了,只是我们没打印出来。
第三步:看数据层
- 文档有没有真正入库。
- namespace 是否一致。
- chunk 是否被切坏。
- 检索条件是不是过严。
第四步:看并发和超时
- batch 是否太大。
- timeout 是否太短。
- 重试是否过多。
- 是否触发了限流。
第五步:看版本和缓存
- 模型版本是否变化。
- 缓存是否失效。
- 旧配置是否还在用。
下面这个表,是我常见的排错速查。
| 现象 | 常见原因 | 优先检查项 |
|---|---|---|
| 401 | 鉴权失败 | API Key、Header |
| 403 | 权限不足 | 账户权限、IP 白名单 |
| 404 | 地址错误 | base_url、路径前缀 |
| 408 | 超时 | batch、timeout |
| 429 | 限流 | 并发、重试、缓存 |
| 结果为空 | 数据没入库或 namespace 不对 | 数据层、配置层 |
| 结果不准 | chunk 或模型策略问题 | 切分、模型、重排 |
| 前端跨域 | 直连接口 | 改走后端代理 |
我后来形成的一个习惯是:任何报错先别急着重写代码,先把请求和响应打完整。
很多问题其实只差一个完整日志。
八、如果你是小团队,别让“可用”变成“难维护”
这句话是我这几个月最深的体会。
很多系统不是做不出来,而是做出来之后太难维护。
小团队最怕的不是能力不够,而是把时间都花在重复修修补补上。
所以我后来会刻意让系统满足几个“可维护”条件:
- 配置集中。
- 接口统一。
- 日志完整。
- 更新可回滚。
- 数据可追踪。
- 新人能看懂。
如果这几个条件没满足,哪怕系统今天跑得很快,后面也可能慢慢变成“只剩一个人敢碰”的东西。
对个人开发者
最重要的是把流程跑通,不要过度架构。
对小型创业团队
最重要的是把接入方式统一起来,不要每个模块一套写法。
对企业内部知识库
最重要的是版本和权限,不要让旧答案和旧数据混在一起。
对外包项目
最重要的是交接和说明,不要把系统做成只有你自己会修。
九、我更愿意把向量引擎看成“工程保险层”
这个比喻是我后来慢慢想清楚的。
向量引擎不是帮你炫技的,它更像保险层。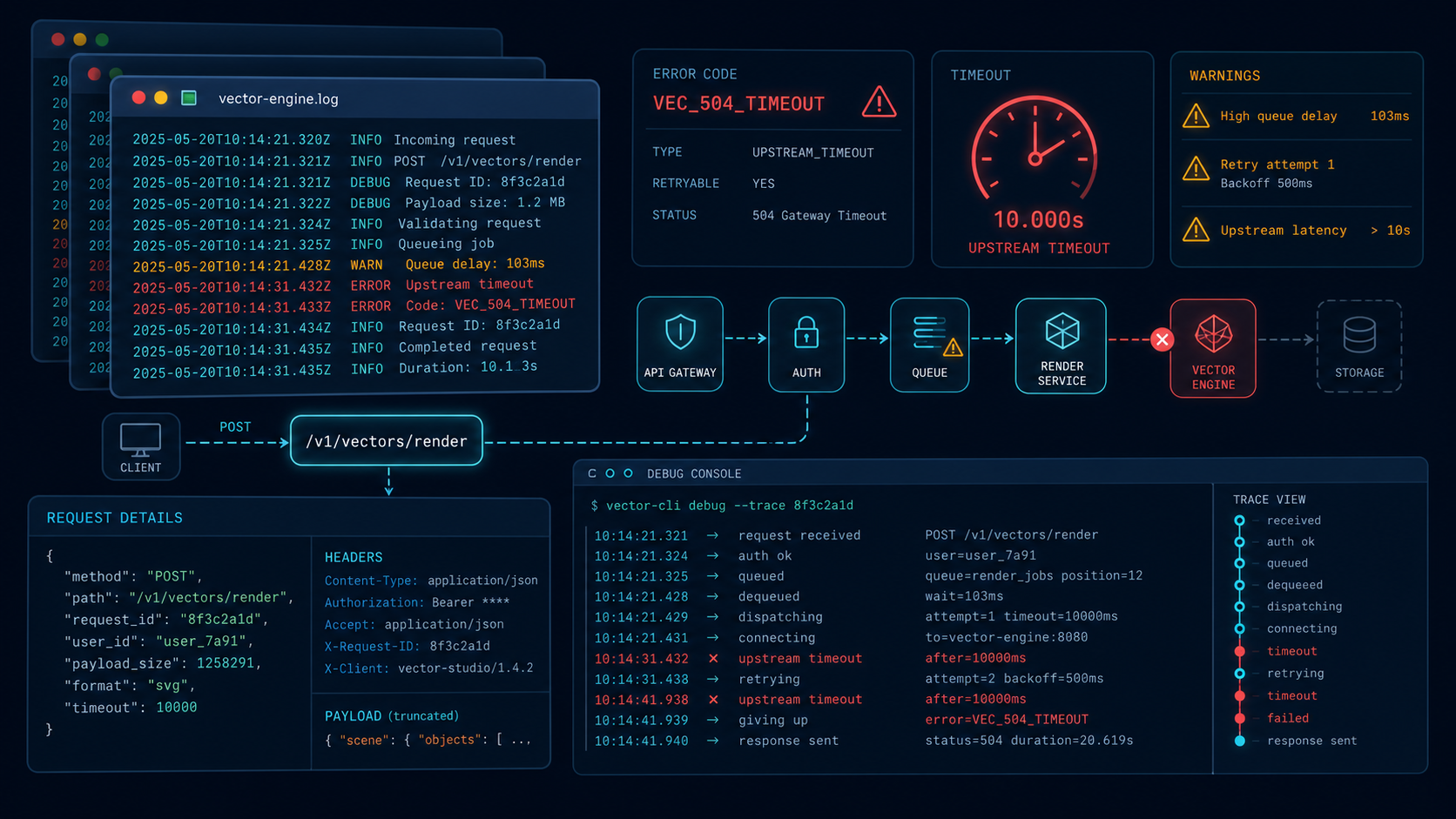
它不一定让你瞬间快很多,但它会在下面这些场景里帮你少掉很多损失:
- API 波动时,先靠缓存顶一顶。
- 文档更新时,局部更新而不是全量重来。
- 并发上来时,先排队而不是直接打爆。
- 新人接手时,先看统一接口而不是一堆脚本。
- 线上报错时,先看统一日志而不是全仓搜索。
这类价值很难在一张宣传页里写明白,但它在长期项目里特别明显。
我现在做知识库的时候,更多关注的是“系统会不会在未来三个月继续好用”,而不是“今天能不能跑出一个漂亮 demo”。
这两种目标看上去差不多,实际上不是一个层面的事。
十、不同文档规模,我会怎么选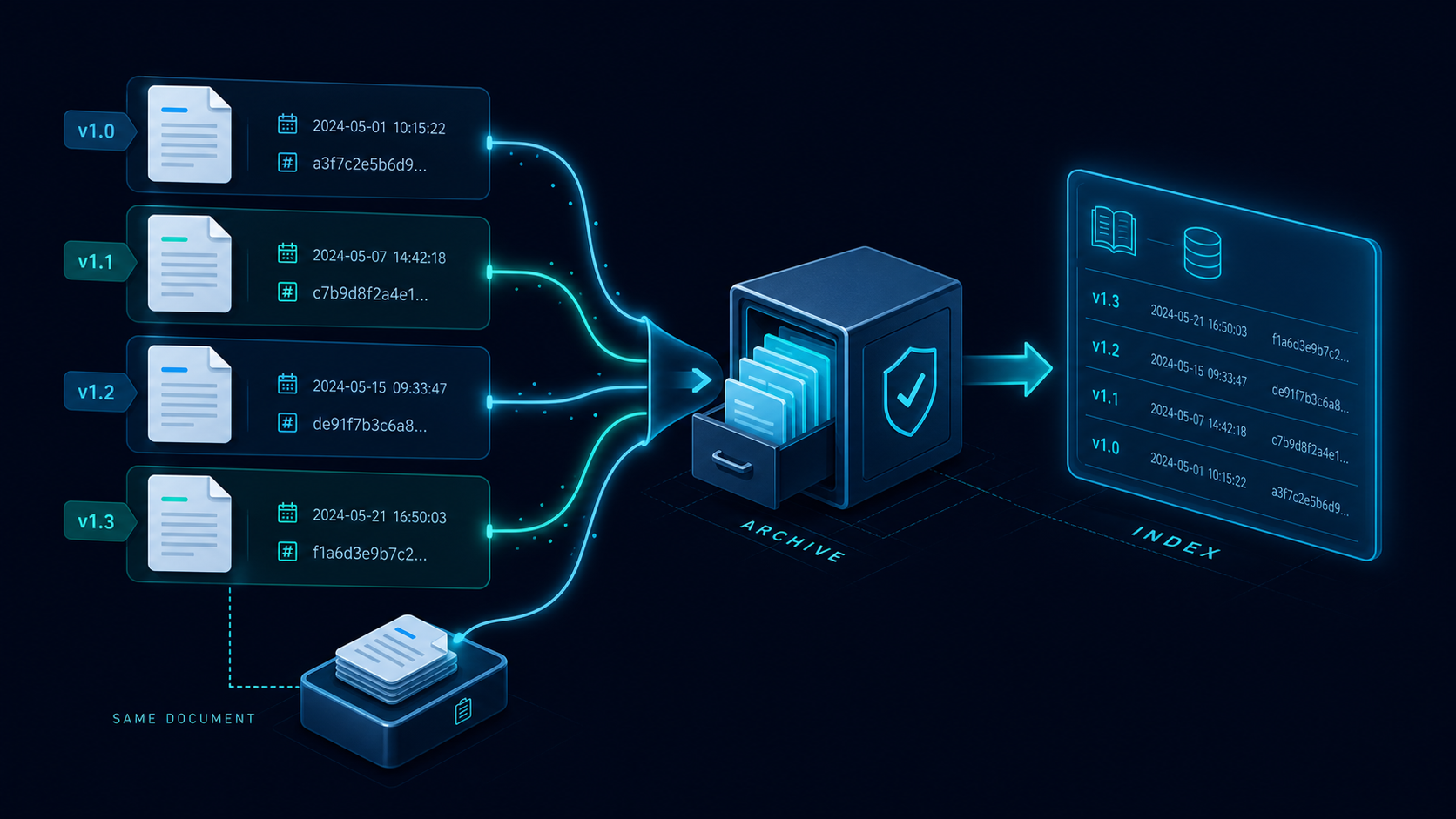
1. 万级文档
优先轻量化。
- 先把文档清洗和切分做好。
- 先跑通基础检索。
- 先别急着堆复杂分布式。
2. 十万级文档
优先稳定性。
- 批量处理。
- 缓存。
- 去重。
- 版本管理。
- 统一日志。
3. 百万级文档
优先架构边界。
- 分片。
- 冷热分层。
- 混合检索。
- 权限隔离。
- 定期重建。
这个阶段已经不是“哪个工具更顺手”的问题,而是“系统是否能持续扩展”的问题。
十一、我整理资料时常用的入口
做这类项目久了,最浪费时间的事情之一,就是到处找接口说明、参数模板、排错文档、客户端写法。
我后来会把常用的参数查阅、标准接口地址、报错处理思路、不同客户端接入说明放在一个资料入口里,平时查配置会方便很多:资料入口
我把它当成技术资料页,而不是别的什么。重点是少翻找、少重复确认、少走弯路。
十二、FAQ
Q1:向量引擎和向量数据库有什么区别?
向量数据库更偏存储和检索底座,向量引擎更偏工程编排和流程封装。前者像地基,后者像把流程串起来的中枢。
Q2:为什么我一开始接得上,后面反而越来越乱?
因为前期只解决了“能跑”,没有解决“怎么维护”。配置、日志、版本、缓存、重试这些没统一,后面一定会乱。
Q3:小团队有必要自建 Milvus 吗?
如果团队里有人能长期维护,当然可以考虑。否则很多时候中间层方案更省时间,也更适合不断变化的业务。
Q4:为什么向量 API 明明能调用,结果还是经常报错?
常见原因是网络、限流、鉴权、超时、请求体大小和环境配置不统一。别只盯模型,先看链路。
Q5:RAG 做出来以后,为什么答案还是忽高忽低?
多数情况下不是“生成模型问题”,而是检索层不稳。chunk、top_k、重排、缓存、版本这几项往往更关键。
Q6:缓存是不是越多越好?
不是。
缓存要有失效规则,否则会把旧答案长期留住。文档更新后,缓存必须知道什么时候该失效。
Q7:前端能不能直接调向量接口?
不建议。
尤其是涉及密钥、权限、日志和稳定性的时候,最好走后端代理。
Q8:多语言接入难不难?
不难。
如果接口统一,Python、Node、Java、Go 都只是换一层请求封装。真正难的是前期没统一,后面每个人都写了一份不同的接法。
十三、最后我想说的
我现在看向量引擎,已经不太会先问“它快不快”了。
我更想知道的是:
- 它能不能在文档更新后继续稳定工作。
- 它能不能在报错后快速定位。
- 它能不能在换人以后还接得住。
- 它能不能让一个小团队少掉很多重复劳动。
如果这几个问题答得比较稳,那它对我来说就不是一个“炫技术名词”,而是一个真正能帮项目活下来的工程组件。
对个人开发者来说,它是帮你少踩坑的工具。
对小团队来说,它是帮你减少返工的中间层。
对知识库项目来说,它是把文档、检索、问答、更新、排错统一起来的稳定器。
我后面还会继续整理更细的实操内容,比如:
- Python 和 Node.js 的双端接入模板。
- 批量导入时的去重和缓存策略。
- 十万级文档的索引和更新方案。
- RAG 场景下怎么做重排和召回调优。
如果你正在做向量检索、RAG 知识库、文档中台或者 API 接入,最值得先想明白的不是“选哪家”,而是“这套东西谁来维护、怎么交接、出错怎么修”。
把这几个问题想清楚,很多方案其实会自然分出高下。
如果你也碰到过向量 API 报错、知识库更新混乱、或者 RAG 接口接得七零八落的情况,不妨先把链路收口,再谈效果。系统能长期稳定,才是真的省时间。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐


 13
13 0
0- 0



 已为社区贡献51条内容
已为社区贡献51条内容

所有评论(0)