【AI】DeepSeek微调代码实例
python代码微调deepseek大模型
知识库可以解决AI大模型知识储不足的问题,但如果想要让模型变得更加"智能",更加"专业",还需要对大模型做进一步的优化,也就是微调
一、项目要求
1、GPU要求: 16G
2、代码运行环境:python3.0
3、代码运行工具:pycharm或者vscode
没有GPU的同学可以考虑免费的算力平台:
腾讯Cloud Studio:Cloud Studio
百度飞桨:飞桨AI Studio星河社区-人工智能学习与实训社区
阿里天池:天池大数据众智平台-阿里云天池
谷歌Colab(科学上网):https://colab.research.google.com/
这里推荐使用腾讯的Cloud Studio平台,每个月赠送10000分钟免费的算力时长,提供16GB GPU的高性能服务器,是我运行代码时遇到问题最少的平台。下面以Cloud Studio平台为例创建项目,本地有GPU环境的可以直接跳到第三步
二、创建项目
打开腾讯Cloud Studio官网,点击登录,进入高性能工作空间
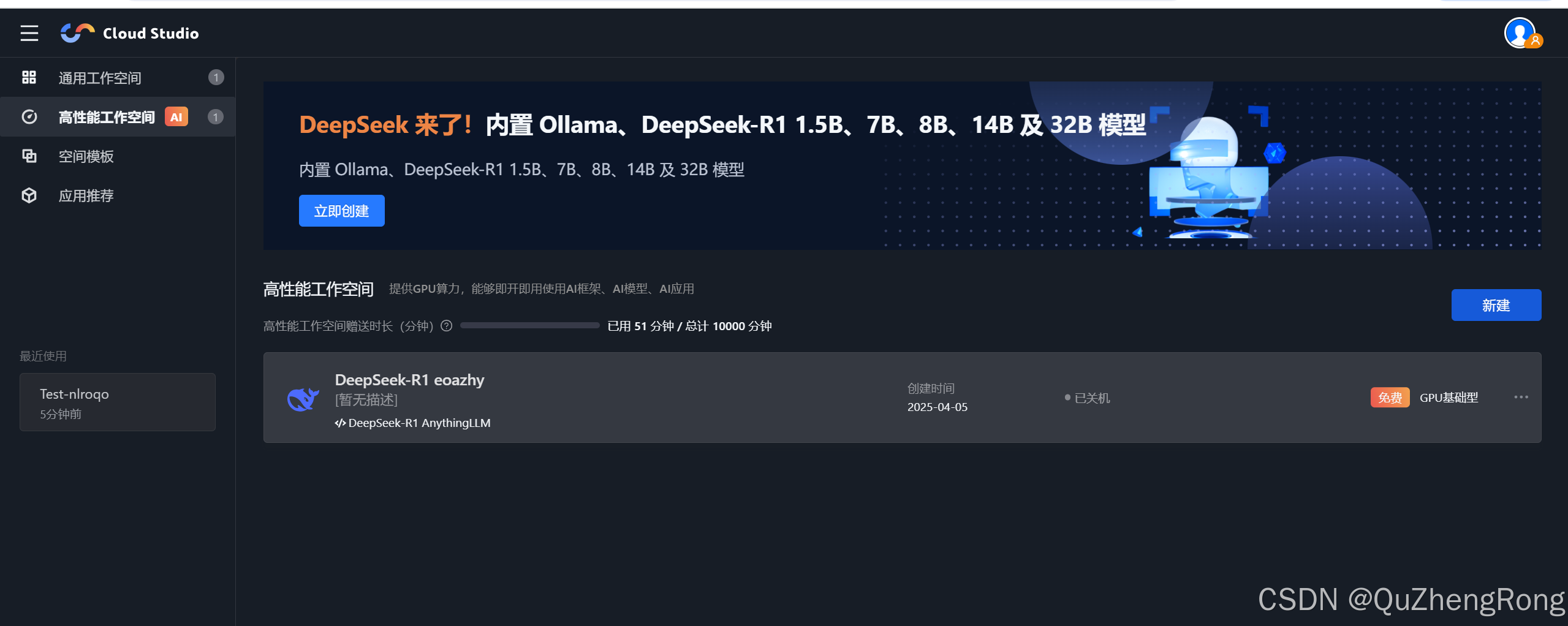
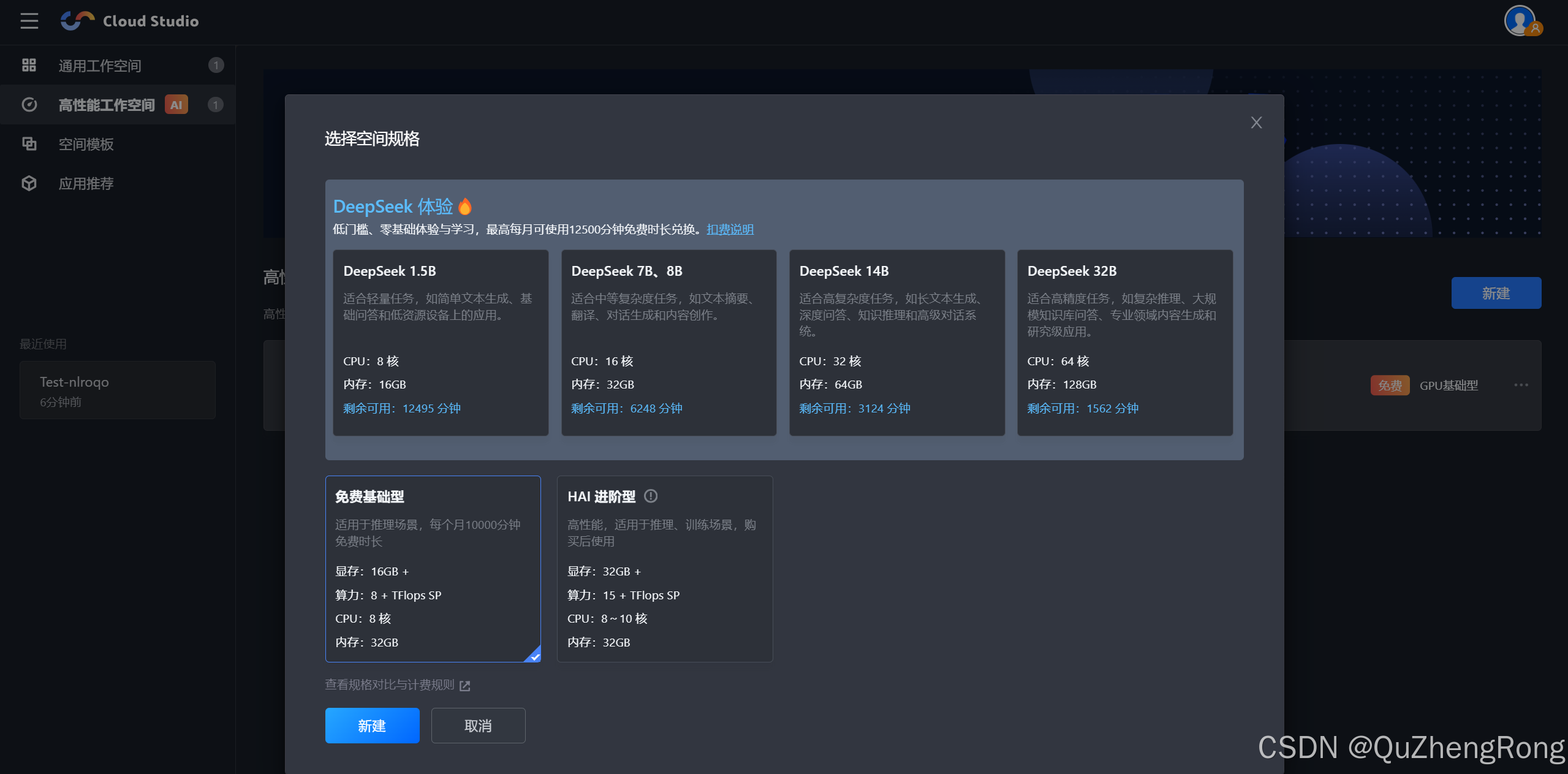
点击新建,选择免费基础型,等待开机
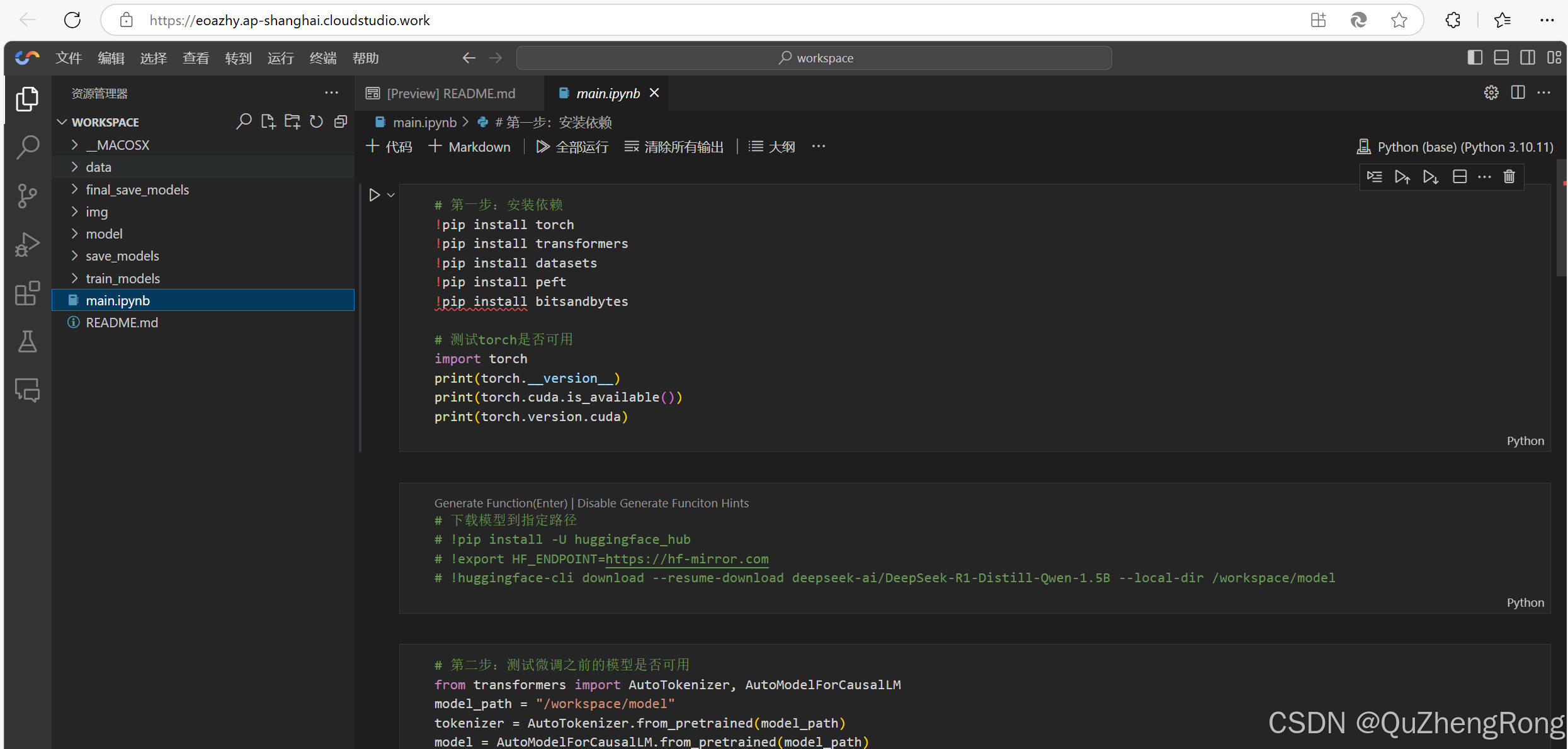
开机成功后进入vscode编辑器页面,不得不说这个编辑器挺不错的,很贴近程序员的开发环境,整个工作空间其实就是一台linux服务器+可视化vscode
在右上方选择python解释器,选好后在vscode的工作目录新建一个main.ipynb文件(有的话可以跳过)
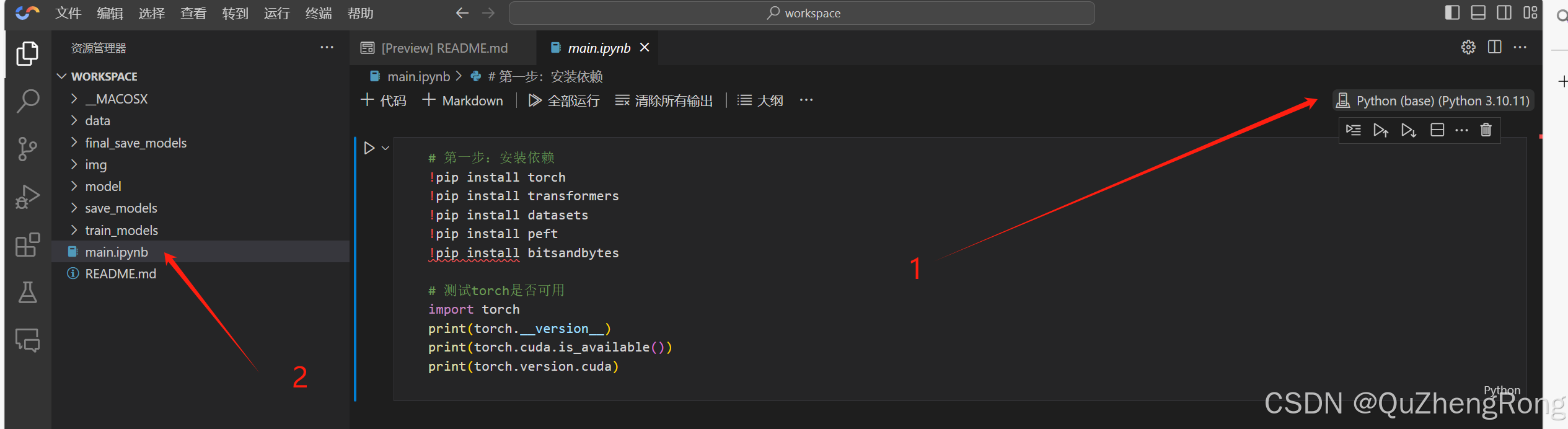
ipynb文件是交互式python记事本,在运行时可以保留数据状态,有点类似debugger,后续的代码都放在main.ipynb里运行
三、代码示例
1、安装依赖
使用本地GPU环境的直接在dos窗口执行指令
pip install torch
pip install transformers
pip install datasets
pip install peft
pip install bitsandbytes
pip install huggingface_hub使用Cloud Studio工作空间的新建终端,在终端下执行指令
2、下载大模型
打开终端,下载DeepSeek-R1-Distill-Qwen-1.5B模型到指定目录,注意区分linux和window环境,两个环境配置下载地址的指令不同
# 安装huggingface下载工具
pip install -U huggingface_hub
# linux配置下载地址
export HF_ENDPOINT=https://hf-mirror.com
# window配置下载地址
$env:HF_ENDPOINT = "https://hf-mirror.com"
# 下载模型到指定目录下
# 指令最后的/workspace/model是目录地址,可以按需替换
huggingface-cli download --resume-download deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B --local-dir /workspace/model
3、下载训练数据集
训练数据集链接: https://pan.baidu.com/s/13qg4_lRsUHAjsEpc176XmA?pwd=bcgs 提取码: bcgs
下载训练数据集后将文件上传到指定目录,比如Cloud Studio工作空间上传到/workspace/data/目录,也可以放在其他目录,后续修改训练代码中的路径即可
4、代码
# 第一步:安装依赖
# 测试torch是否可用
import torch
print(torch.__version__)
print(torch.cuda.is_available())
print(torch.version.cuda)
# 按需替换路径
# 训练前模型路径
model_path = "/workspace/model"
# 训练模型路径
train_path = "/workspace/train_models"
# 训练后模型保存路径
save_path = "/workspace/save_models"
# 合并后模型保存路径
final_save_path = "/workspace/final_save_models"
# 训练数据路径
data_path = "/workspace/data/datasets.jsonl"
# 第二步:测试微调之前的模型是否可用
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(model_path)
print("-----模型加载成功------")
# 测试模型问答能力
# from transformers import pipeline
# pipe = pipeline("text-generation",model=model,tokenizer=tokenizer)
# prompt = "tell me some singing skills"
# generated_texts = pipe(prompt,max_length=512,num_return_sequences=1)
# print("开始回答:-----",generated_texts[0]["generated_text"])
# 第三步:制作数据集
from datasets import load_dataset
dataset = load_dataset("json",data_files={"train": data_path},split="train")
print("数据量:" , len(dataset))
# 拆分数据集,训练和测试数据集比例为9:1
train_test_split = dataset.train_test_split(test_size=0.1)
train_dataset = train_test_split["train"]
eval_dataset = train_test_split["test"]
print(f"train dataset len: {len(train_dataset)}")
print("-----完成训练数据的准备工作-----")
# 第四步:编写tokenizer处理工具
def tokenizer_function(many_samples):
texts = [f"{prompt}\n{completion}" for prompt,completion in zip(many_samples["prompt"],many_samples["completion"])]
tokens = tokenizer(texts,truncation=True,max_length=512,padding="max_length")
tokens["labels"] = tokens["input_ids"].copy()
return tokens
tokenized_train_dataset = train_dataset.map(tokenizer_function,batched=True)
tokenized_eval_dataset = eval_dataset.map(tokenizer_function,batched=True)
print("-----完成tokenizing-----")
print(tokenized_train_dataset[0])
# 第五步:量化设置
from transformers import BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(load_in_8bit=True)
model = AutoModelForCausalLM.from_pretrained(model_path,quantization_config=quantization_config,device_map="auto")
print("------已经完成量化模型的加载------")
# 第六步 lora微调设置
from peft import get_peft_model,LoraConfig, TaskType
lora_config = LoraConfig(r=8,lora_alpha=16,lora_dropout=0.05,task_type=TaskType.CAUSAL_LM)
model = get_peft_model(model,lora_config)
model.print_trainable_parameters()
print("----lora微调设置完毕-----")
# 第七步:设置训练步数
from transformers import TrainingArguments,Trainer
training_args = TrainingArguments(
output_dir=train_path,
num_train_epochs=10,
per_device_train_batch_size=4,
gradient_accumulation_steps=8,
fp16=True,
logging_steps=10,
save_steps=100,
eval_strategy="steps",
eval_steps=10,
learning_rate=3e-5,
logging_dir="./logs",
run_name="deepseek-r1-1.5b-test"
)
print("-----训练参数设置完毕------")
# 定义训练器
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_train_dataset,
eval_dataset=tokenized_eval_dataset
)
print("----开始训练---")
trainer.train()
print("----训练完成---")
# 第八步:保存lora模型
model.save_pretrained(save_path)
tokenizer.save_pretrained(save_path)
print("---lora模型已经保存-----")
# 保存全量模型
from peft import PeftModel
base_model = AutoModelForCausalLM.from_pretrained(model_path)
model = PeftModel.from_pretrained(base_model,save_path)
model = model.merge_and_unload()
model.save_pretrained(final_save_path)
tokenizer.save_pretrained(final_save_path)
print("------全量模型已经保存-----")
# 第九步:测试全量模型
from transformers import pipeline
model = AutoModelForCausalLM.from_pretrained(final_save_path)
tokenizer = AutoTokenizer.from_pretrained(final_save_path)
pipe = pipeline("text-generation",model=model,tokenizer=tokenizer)
prompt = "tell me some singing skills"
generated_texts = pipe(prompt,max_length=512,num_return_sequences=1)
print("开始回答:-----",generated_texts[0]["generated_text"])Cloud Studio可以按步添加代码,然后一步一步执行,由于ipynb的特性数据状态不会丢失,执行完第二步后可以正常执行第三步,变量会一直保留

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)