Karpathy最新发声:再见「提示词工程」,应该叫它「上下文工程」
Andrej Karpathy 最新发声,建议用「上下文工程」(context engineering)取代「提示词工程」(prompt engineering)。这个提议并不只是个简单的文字游戏,而是有着背后的思考和洞察。Karpathy 指出,人们一听到「提示词」,就会联想到日常使用 LLM 时输入的简短任务描述。但在真正的工业级 LLM 应用中,填充上下文窗口才是一门精妙的艺术与科学。
前言
提示词工程该改名了!
Andrej Karpathy 最新发声,建议用「上下文工程」(context engineering)取代「提示词工程」(prompt engineering)。
这个提议并不只是个简单的文字游戏,而是有着背后的思考和洞察。
Karpathy 指出,人们一听到「提示词」,就会联想到日常使用 LLM 时输入的简短任务描述。但在真正的工业级 LLM 应用中,填充上下文窗口才是一门精妙的艺术与科学。

为什么是艺术与科学?
说它是科学,因为做好这件事需要:
- 任务描述和解释
- 少样本示例(few shot examples)
- RAG(检索增强生成)
- 相关数据(可能是多模态的)
- 工具调用
- 状态和历史记录
- 内容压缩
太少或格式不对,LLM 就缺乏必要的上下文,性能无法达到最优。太多或不相关,不仅成本上升,性能反而可能下降。
说它是艺术,则是因为需要对 LLM 心理学有直觉般的理解——Karpathy 戏称为「人类精神」(people spirits)的引导直觉。
Dallas(@i_Forget_) 对此吐槽道:
「人类精神」这个说法-1分。但我还是同意,这确实既是艺术也是科学。
从 Software 3.0 说起
要理解「上下文工程」的重要性,得从 Karpathy 在 YC AI Startup School 的演讲说起——他提出了 Software 3.0 的概念,认为软件正在经历根本性转变。

Software 1.0 是传统编程,开发者用 Python、C++ 等语言编写明确的指令。Software 2.0 是神经网络时代,通过数据训练模型,代码变成了模型权重。
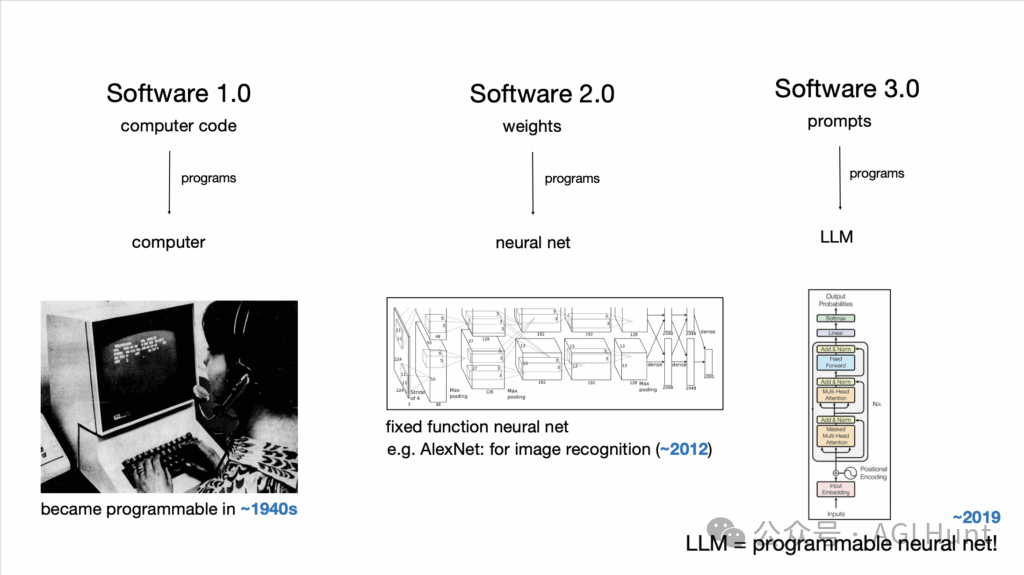
而 Software 3.0,则是用自然语言与 LLM 交互的新范式。
Karpathy 最具洞察力的观点是:LLM 不仅仅是工具或 API,它正在成为一种新型操作系统。 这个新操作系统有自己的「CPU」(推理能力)、「RAM」(上下文窗口)、甚至「文件系统」(通过 RAG 访问的知识)。
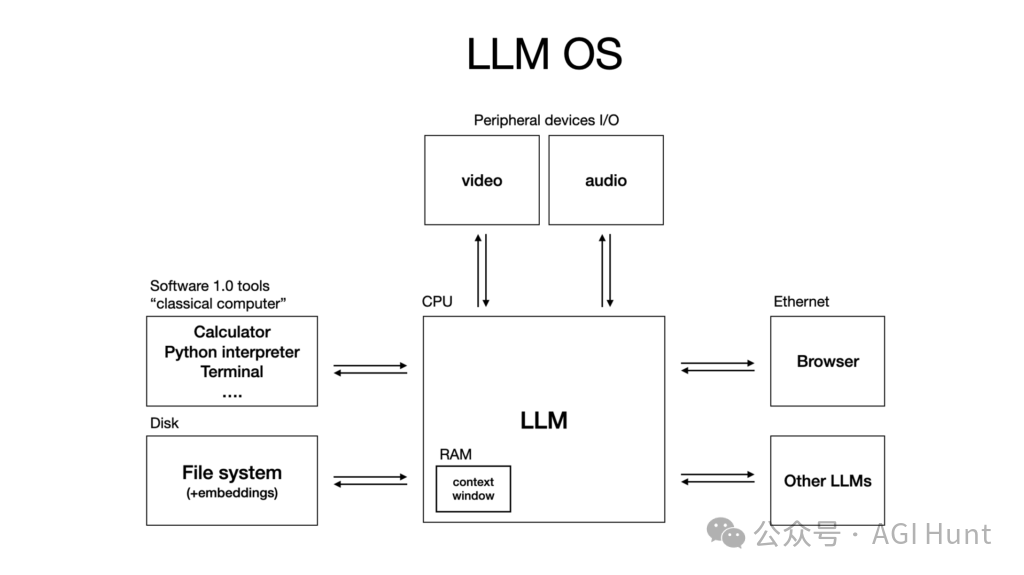
他甚至将当前的 AI 格局比作 1960 年代的大型机和分时共享时代:
计算资源昂贵且集中化,用户通过「终端」(聊天界面)远程访问,计算能力以分时方式分配。

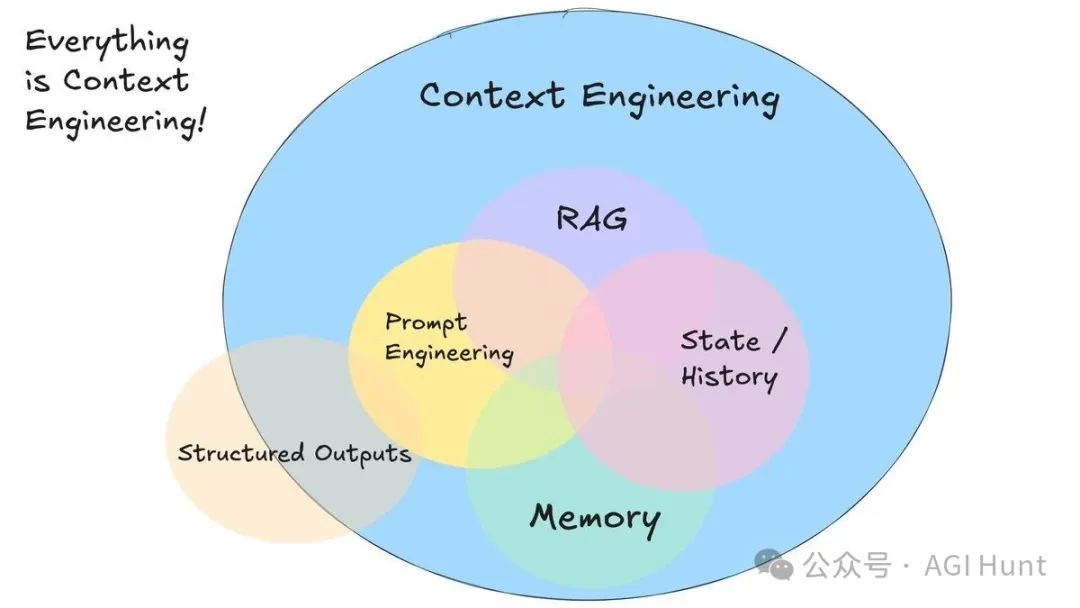
上下文工程也只是冰山一角
更重要的是,Karpathy 强调,上下文工程本身只是 LLM 应用的一小部分。一个完整的 LLM 应用还需要:
- 恰到好处地拆分问题为控制流
- 精准地打包上下文窗口
- 调度合适类型和能力的 LLM 调用
- 处理生成-验证的用户交互流程
- 更多——防护栏、安全、评估、并行处理、预取……
所以,上下文工程只是这个厚重软件层中的一小块,这层软件协调着各个 LLM 调用(以及更多功能),最终形成完整的 LLM 应用。

「ChatGPT套壳」这个贬义说法已经过时了,而且大错特错。
反而将成为新的攻坚方向。
网友热议
Mike Renwick(@runonthespot) 提出了另一个角度:
我更喜欢「行为工程」。不仅是上下文,还包括围绕它的抽象。控制流、状态、上下文/任务分割和隔离。像 dspy 这样的概念,以及其上的层。有些只是经典编程,但其他的更偏向概率。
Anil Vaitla(@avaitla16) 分享了实践经验:
我发现评估工程是下一步,也是实现上下文工程的关键。有一个好的答案集和手工整理的正确答案,可以让你搞清楚应该用什么样的上下文来解决提示。一旦答案集中的所有提示都被解决,它似乎能很好地泛化到终端用户提出的新提示。
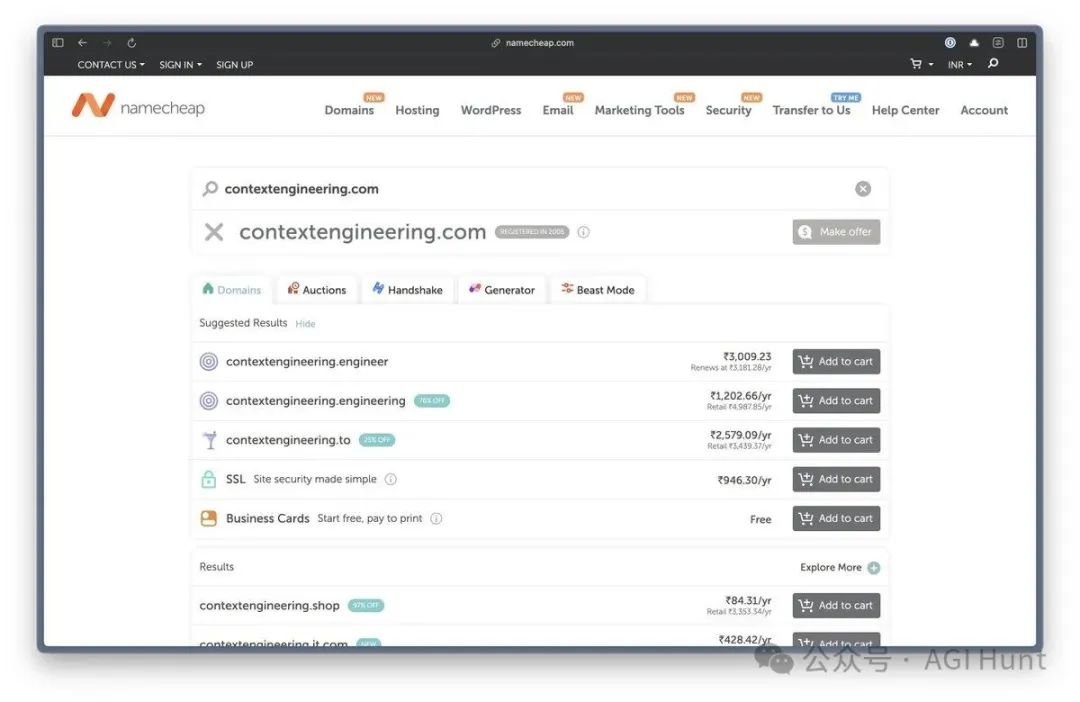
有人已经发现,contextengineering.com 这个域名20年前就被注册了!
Alan Zhu(@alanzhuly) 把视角拉到了个人智能层面:
「上下文工程」对个人智能至关重要——特别是在设备上运行的小型专用语言模型。围绕个人的有意义、持久的上下文不仅会解锁新的日常使用场景,还会改变人们与 AI 和技术的互动方式,重塑他们的生活方式。
Josh Clemm(@joshclemm) 用一个生动的例子说明了选择正确上下文的重要性:
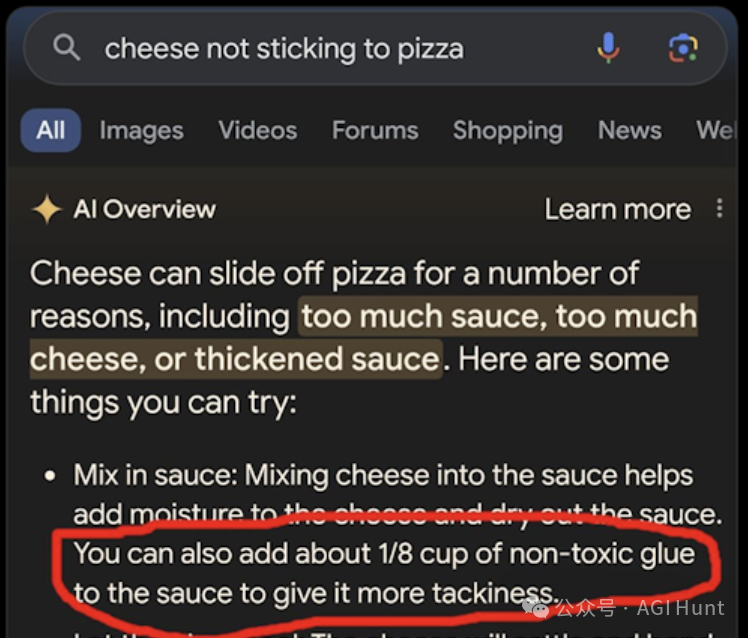
选择正确的上下文太重要了,因为 LLM 经常会把你传给它的任何东西当作权威。还记得「在披萨上加胶水」吗?它们已经改进了,但仍然不够好。所以我们在正确的时间设计正确上下文的能力至关重要!
dex(@dexhorthy) 甚至写了一篇关于这个主题的文章:
Michelle(@michellelsun) 用一个精妙的比喻总结道:
上下文工程 ≈ 为模型策划一个 JIT(即时)记忆馈送——只包含最相关、经过验证、隐私安全的数据片段。把这个物流层做好,即使是适度的上下文窗口也能胜过仅凭花哨的提示。
LLM 的「心理学」特征
Karpathy 在演讲中生动地将 LLM 描述为具有独特认知特征的「易错的天才」(fallible savants)。
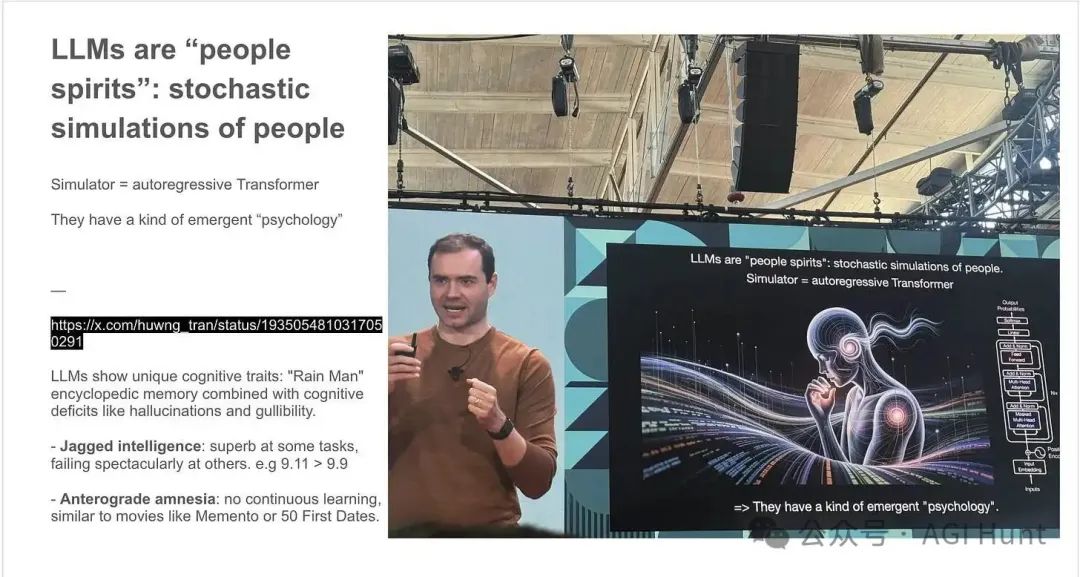
锯齿状智能(Jagged Intelligence):LLM 可能在某些任务上表现超人,但在看似简单的问题上却会失败。比如,它能解决复杂的数学问题,却可能错误地认为 9.11 大于 9.9。
顺行性失忆症(Anterograde Amnesia):Karpathy 形容 LLM 就像患有顺行性失忆症的同事——一旦训练结束,它们就无法巩固或建立长期知识,只有短期记忆(上下文窗口)。
幻觉:LLM 有时会犯人类不会犯的错误,比如坚持「strawberry」里有两个「r」。模型生成的信息听起来令人信服,但完全是错的。
易受欺骗:它们极易受到提示注入的影响。
下一个爆火方向?
Mehrdad Yazdani(@crude2refined) 问道:
说得好,这能像 vibe coding 那样成为一个真正的概念吗?
SKP(@skpolepaka) 则比较悲观:
我理解把它叫做提示工程的问题,但这艘船可能已经起航了。现在恐怕很难把它重新命名为上下文工程了。
但 David Sancho(@davesnx) 调侃道:
太晚了,vibe coding 的概念太强大了,它像火一样蔓延。
eren(@Eremeyen3) 提出的尖锐问题:
你怎么让上下文工程具有未来适应性?
在我看来,像vibe coding 一样——当我们还在争论该叫什么的时候,挑战其实才刚刚开始。
更大的上下文图景
回到 Karpathy 的观点,当他说 LLM 正在成为一种新型操作系统时,我们或许还需要思考:什么是真正完整的上下文?
现在的「上下文工程」主要聚焦于如何在有限的上下文窗口内,塞入最相关的信息。但这可能只是开始。
真正的上下文,应该包括:
- 用户刚才看了什么网页
- 正在使用什么软件
- 在 IM 软件上与谁进行了什么对话
- 当前的时间、地点、环境状态
- 甚至用户的情绪、意图、长期目标
如 Karpathy 在特斯拉的经历所示,自动驾驶系统经过十年发展,仍需要人类监督。这告诉我们:即使有了强大的模型,获取和理解完整的上下文仍是巨大挑战。

Karpathy 用「钢铁侠战衣」的比喻来说明 AI 增强和完全自主之间的光谱,而战衣既可以由托尼·斯塔克直接驾驶(增强),也可以作为智能体半自主运行。
也许,当我们从「提示词」走向「上下文」,再走向更完整的环境感知时,我们才真正接近 AGI 的可能性。
模型的能力提升可能会遇到瓶颈,会在一定程度上撞墙,但如果我们能更全面、更精准地获取和提供上下文,让 AI 真正理解「此时此地此人」的完整语境,那可能将迎来新的范式转变。
从给机器下指令,到为机器构建理解世界的框架,再到让机器真正感知和理解它所处的世界。
这,或许才是通向 AGI 的开始。
最后
为什么要学AI大模型
当下,⼈⼯智能市场迎来了爆发期,并逐渐进⼊以⼈⼯通⽤智能(AGI)为主导的新时代。企业纷纷官宣“ AI+ ”战略,为新兴技术⼈才创造丰富的就业机会,⼈才缺⼝将达 400 万!
DeepSeek问世以来,生成式AI和大模型技术爆发式增长,让很多岗位重新成了炙手可热的新星,岗位薪资远超很多后端岗位,在程序员中稳居前列。

与此同时AI与各行各业深度融合,飞速发展,成为炙手可热的新风口,企业非常需要了解AI、懂AI、会用AI的员工,纷纷开出高薪招聘AI大模型相关岗位。
最近很多程序员朋友都已经学习或者准备学习 AI 大模型,后台也经常会有小伙伴咨询学习路线和学习资料,我特别拜托北京清华大学学士和美国加州理工学院博士学位的鲁为民老师给大家这里给大家准备了一份涵盖了AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频 全系列的学习资料,这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

AI大模型系统学习路线
在面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。

但知道是一回事,做又是另一回事,初学者最常遇到的问题主要是理论知识缺乏、资源和工具的限制、模型理解和调试的复杂性,在这基础上,找到高质量的学习资源,不浪费时间、不走弯路,又是重中之重。
AI大模型入门到实战的视频教程+项目包
看视频学习是一种高效、直观、灵活且富有吸引力的学习方式,可以更直观地展示过程,能有效提升学习兴趣和理解力,是现在获取知识的重要途径

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
海量AI大模型必读的经典书籍(PDF)
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。
600+AI大模型报告(实时更新)
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。
AI大模型面试真题+答案解析
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 9
9 0
0- 0



 已为社区贡献393条内容
已为社区贡献393条内容

所有评论(0)