【AI大模型入门教程】一文讲清向量数据库和嵌入模型,零基础小白收藏这一篇就够了!!
关注AI、大模型的朋友们应该都听过用RAG(Retrieval-augmented Generation,检索增强生成)搭建知识库,RAG的基础组成之二就是向量数据库和嵌入模型。
前言
关注AI、大模型的朋友们应该都听过用RAG(Retrieval-augmented Generation,检索增强生成)搭建知识库,RAG的基础组成之二就是向量数据库和嵌入模型。在正式阅读本文前,我们先来看几个问题:
1、什么是向量?
2、什么是文本/图片向量化?
3、什么是向量数据库?有哪些向量数据库?
4、将数据保存进向量数据库后,该如何检索查询?
5、向量数据库和Mysql的查询与什么区别和不同?
向量数据库
Vector是向量或矢量的意思,向量是数学里的概念,而矢量是物理里的概念,但二者描述的是同一件事。向量的准确定义:向量是用于表示具有大小和方向的量。具体而言,向量可以在不同的维度空间中定义,最常见的是二维和三维空间中的向量,但理论上也可以有更高维的向量。例如,在二维平面上的一个向量可以写作(x,y),这里x和y分别表示该向量沿两个坐标轴方向上的分量;而在三维空间里,则会有一个额外的z坐标,即(x,y,z)。
如我们所见,每个数值向量都有 x 和 y 坐标(或者在多维系统中是 x、y、z,…)。x、y、z… 是这个向量空间的轴,称为维度。对于我们想要表示为向量的一些非数值实体,我们首先需要决定这些维度,并为每个实体在每个维度上分配一个值。
例如,在一个交通工具数据集中,我们可以定义四个维度:“轮子数量”、“是否有发动机”、“是否可以在地上开动”和“最大乘客数”。然后我们可以将一些车辆表示为:

因此,我们的汽车Car向量将是 (4, yes, yes, 5),或者用数值表示为 (4, 1, 1, 5)(将 yes 设为 1,no 设为0)。向量的每个维度代表数据的不同特性,维度越多对事务的描述越精确,我们可以使用“是否有翅膀”、“是否使用柴油”、“最高速度”、“平均重量”、“价格”等等更多的维度信息。
每个向量都有一个长度和方向。例如,在这个图中,p 和 a 指向相同的方向,但长度不同。p 和 b 正好指向相反的方向,但有相同的长度。然后还有c,长度比p短一点,方向不完全相同,但很接近。
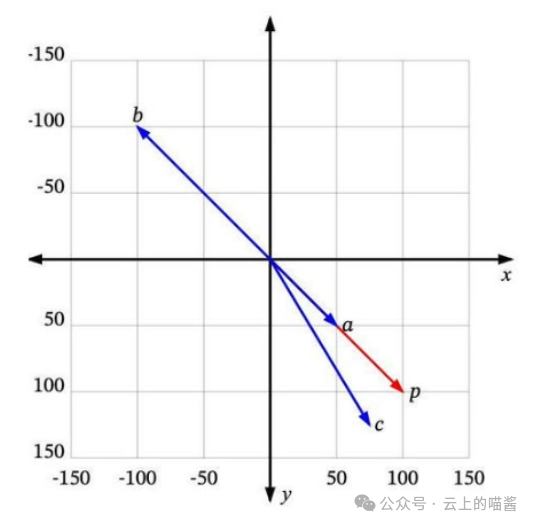
那么,哪一个最接近 p 呢?
如果“相似”仅仅意味着指向相似的方向,那么a 是最接近 p 的。接下来是 c。b 是最不相似的,因为它正好指向与p 相反的方向。如果“相似”仅仅意味着相似的长度,那么 b 是最接近 p 的(因为它有相同的长度), 接下来是 c,然后是 a。
由于向量通常用于描述语义意义,仅仅看长度通常无法满足需求。大多数相似度测量要么仅依赖于方向,要么同时考虑方向和大小。
在数学中向量间的相似度测量即相似度计算,有四种常见的计算方法,这里不展开讨论。
- 欧几里得距离 Euclidean distance
- 曼哈顿距离 Manhattan distance
- 点积 Dot product
- 余弦相似度 Cosine similarity
向量存储(Vector Database/VectorStore)是一种用于存储和检索高维向量数据的数据库或存储解决方案,它特别适用于处理那些经过嵌入模型转化后的数据。在向量数据库中,查询与传统关系数据库不同,它们执行相似性搜索,而不是精确匹配。当给定一个向量作为查询时,VectorStore返回与查询向量“相似"的向量。比如说在使用一个商城系统的向量数据库进行查询的时候,用户输入“北京”,其可能返回的结果会是 “中国、北京、华北、首都、奥运会” 等信息;输入“沈阳”,其返回结果可能会是“东北、辽宁、雪花、重工业”等信息。当然,返回的信息取决于向量数据库中存在的数据。用户可以通过参数的设置来限定返回的情况,进而适配不同的需求。
向量数据库用于将您的数据与Al模型集成。在使用它们时的第一步是将您的数据加载到向量数据库中。然后,当要将用户查询发送到AI模型时,首先检索一组相似文档。然后,这些文档作为用户问题的上下文,并与用户的查询一起发送到Al模型。这种技术被称为检索增强生(RetrievalAugmentedGeneration, RAG )。
说人话核心就是将文本、图像和视频等等转换为一组浮点数数组(即向量)后进行存储的系统就是向量数据库,其查询与传统关系数据库不同,向量数据库执行相似性搜索,而不是精确匹配。当给定一个向量作为查询时,向量数据库返回与查询向量“相似"的向量。
能做向量数据库有如下产品
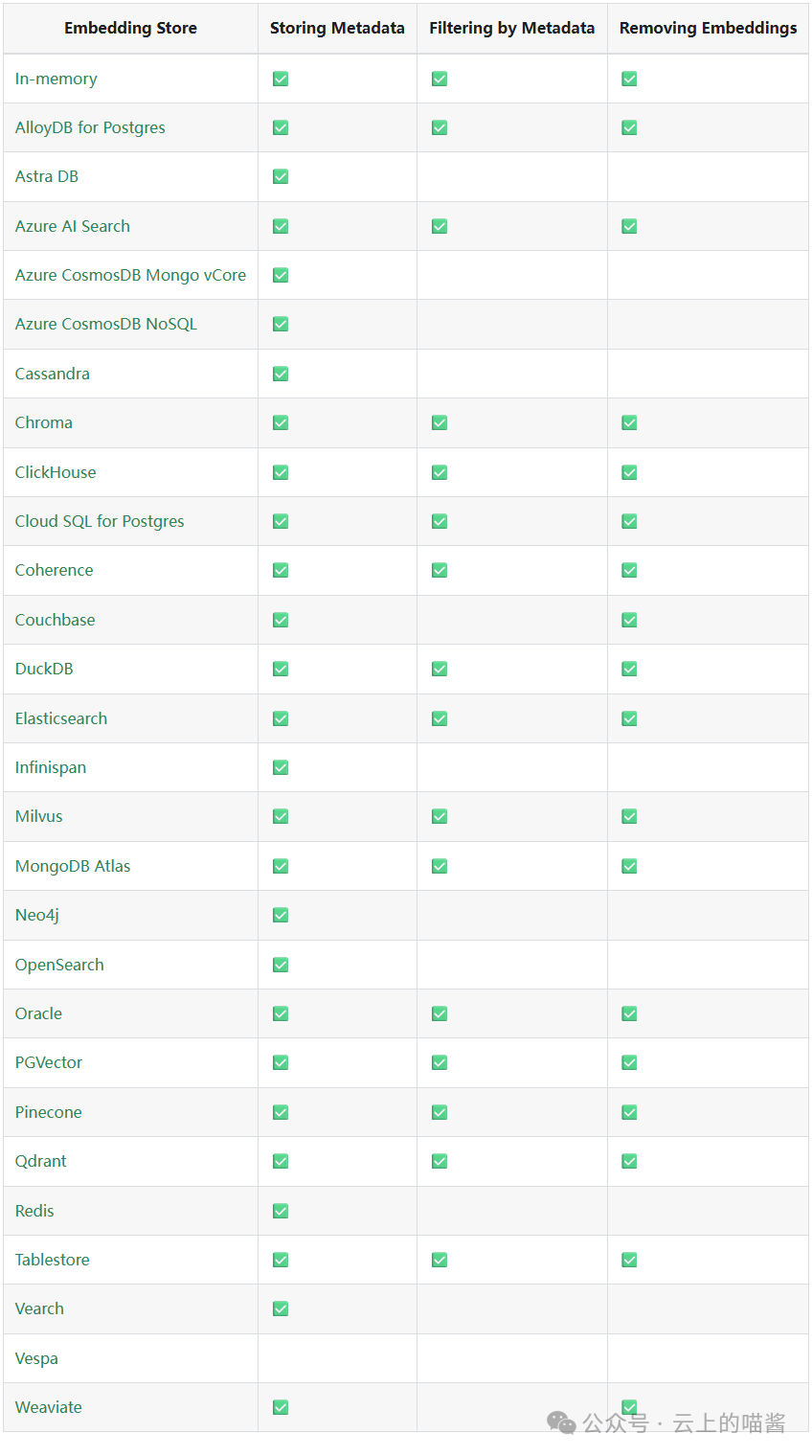
*上图源于:*https://docs.langchain4j.dev/integrations/embedding-stores/
嵌入模型
嵌入模型(Embedding Model)和向量数据库(Vector Database/Vector Store)是一对亲密无间的合作伙伴,也是 AI 技术栈中紧密关联的两大核心组件,两者的协同作用构成了现代语义搜索、推荐系统和 RAG(Retrieval Augmented Generation,检索增强生成)等应用的技术基础。
嵌入(Embedding)的工作原理是将文本、图像和视频转换为称为向量(Vectors)的浮点数数组。这些向量旨在捕捉文本、图像和视频的含义。嵌入数组的长度称为向量的维度(Dimensionality)。
嵌入模型是嵌入过程中采用的模型。当前EmbeddingModel的接口主要用于将文本转换为数值向量,接口的设计主要围绕这两个目标展开:
-
可移植性:该接口确保在各种嵌入模型之间的轻松适配。它允许开发者在不同的嵌入技术或模型之间切换,所需的代码更改最小化。这一设计与Spring模块化和互换性的理念一致。
-
简单性:嵌入模型简化了文本转换为嵌入的过程。通过提供如embed(String text)和embed(Document document)这样简单的方法,它去除了处理原始文本数据和嵌入算法的复杂性。这个设计选择使开发者,尤其是那些初次接触AI的开发者,更容易在他们的应用程序中使用嵌入,而无需深入了解其底层机制。
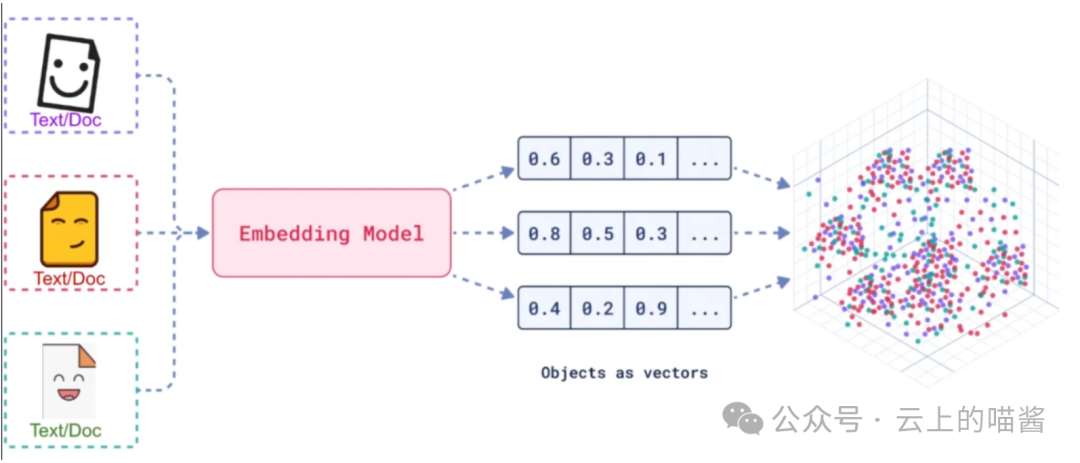
嵌入模型是一种机器学习模型,旨在在连续的低维向量空间中表示数据(例如文本、图像或其他形式的信息)。这些嵌入可以捕获数据之间的语义或上下文相似性,使机器能够更有效地执行比较、聚类或分类等任务。
假设你想描述不同的水果。你不用长篇大论,而是用数字来描述甜度、大小和颜色等特征。例如,苹果可能是[8,5.7],而香蕉是[9,7,4]。这些数字使比较或对相似的水果进行分组变得更容易。
代码演示
上述讲了理论概念,没有实际操作会不够具象化理解,嵌入模型选择阿里百炼平台的通用文本向量-v3(text-embedding-v3),当然你也可以选择其他平台的嵌入模型,如BAAI/bge-m3等
向量数据库选择Qdrant,使用Docker容器方式运行:
docker run -d -p 6333:6333 -p 6334:6334 qdrant/qdrant
#运行后浏览器访问http://localhost:6333/dashboard#/welcome 进入可视化页面
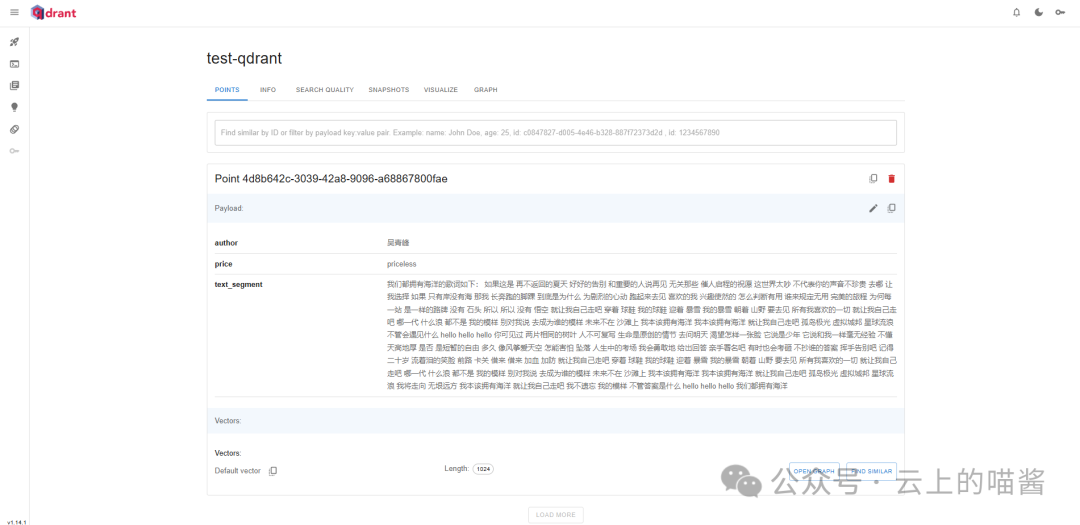
 将吴青峰演唱的《我们都拥有海洋》歌词通过text-embedding-v3嵌入模型(1024维)向量化后存入Qdrant
将吴青峰演唱的《我们都拥有海洋》歌词通过text-embedding-v3嵌入模型(1024维)向量化后存入Qdrant

附录:lanchain4j代码实现
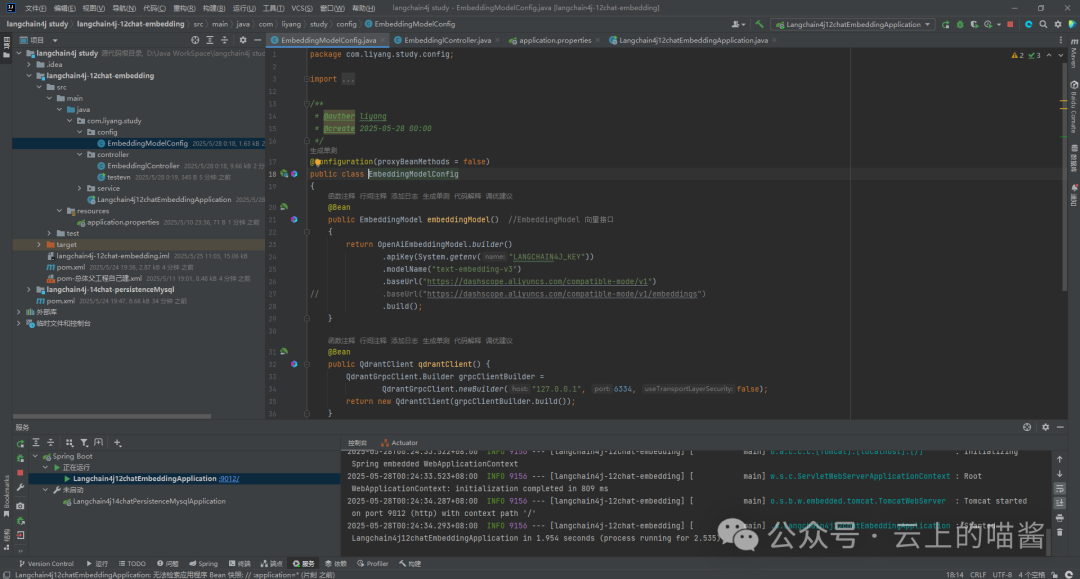
EmbeddingModelConfig
package com.liyang.study.config;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.model.openai.OpenAiEmbeddingModel;
import dev.langchain4j.store.embedding.EmbeddingStore;
import dev.langchain4j.store.embedding.qdrant.QdrantEmbeddingStore;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @auther liyang
* @create 2025-05-28 00:00
*/
@Configuration(proxyBeanMethods = false)
public class EmbeddingModelConfig
{
@Bean
public EmbeddingModel embeddingModel() //EmbeddingModel 向量接口
{
return OpenAiEmbeddingModel.builder()
.apiKey(System.getenv("LANGCHAIN4J_KEY"))
.modelName("text-embedding-v3")
.baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1")
// .baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1/embeddings")
.build();
}
@Bean
public QdrantClient qdrantClient() {
QdrantGrpcClient.Builder grpcClientBuilder =
QdrantGrpcClient.newBuilder("127.0.0.1", 6334, false);
return new QdrantClient(grpcClientBuilder.build());
}
@Bean
public EmbeddingStore<TextSegment> embeddingStore() {
return QdrantEmbeddingStore.builder()
.host("127.0.0.1")
.port(6334)
.collectionName("test-qdrant")
.build();
}
}
EmbeddinglController
package com.liyang.study.controller;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.model.output.Response;
import dev.langchain4j.store.embedding.EmbeddingSearchRequest;
import dev.langchain4j.store.embedding.EmbeddingSearchResult;
import dev.langchain4j.store.embedding.EmbeddingStore;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.grpc.Collections;
import jakarta.annotation.Resource;
import lombok.extern.slf4j.Slf4j;
import dev.langchain4j.model.embedding.EmbeddingModel;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import dev.langchain4j.data.embedding.Embedding;
import java.util.Vector;
import static dev.langchain4j.store.embedding.filter.MetadataFilterBuilder.metadataKey;
/**
* @auther liyang
* @create 2025-05-28 00:00
*/
@RestController
@Slf4j
public class EmbeddinglController
{
@Resource
private EmbeddingModel embeddingModel;
@Resource
private QdrantClient qdrantClient;
@Resource
private EmbeddingStore<TextSegment> embeddingStore;
/**
* 文本向量化测试,看看形成向量后的文本
* http://localhost:9012/embedding/embed
* @return
*/
@GetMapping(value = "/embedding/embed")
public String embed()
{
String prompt = """
我们都拥有海洋的歌词如下:
如果这是 再不返回的夏天
好好的告别 和重要的人说再见
无关那些 催人启程的祝愿
这世界太吵 不代表你的声音不珍贵
去哪 让我选择
如果 只有岸没有海
那我 长奔跑的脚踝
到底是为什么
为剧烈的心动
跑起来去见 喜欢的我
兴趣使然的
怎么判断有用 谁来规定无用
完美的旅程
为何每一站 是一样的路牌
没有 石头 所以 所以 没有 悟空
就让我自己走吧
穿着 球鞋 我的球鞋
迎着 暴雪 我的暴雪
朝着 山野 要去见
所有我喜欢的一切
就让我自己走吧
哪一代 什么浪 都不是 我的模样
别对我说 去成为谁的模样
未来不在 沙滩上 我本该拥有海洋
我本该拥有海洋 就让我自己走吧
孤岛极光 虚拟城邦 星球流浪
不管会遇见什么 hello hello hello
你可见过 两片相同的树叶
人不可复写 生命是原创的情节
去问明天 渴望怎样一张脸
它说是少年 它说和我一样毫无经验
不懂 天高地厚
是否 是短暂的自由
多久 像风筝爱天空
怎能害怕 坠落
人生中的考场
我会勇敢地 给出回答
亲手署名吧
有时也会考砸 不抄谁的答案
挥手告别吧
记得二十岁 流着泪的笑脸
前路 卡关 借来 借来 加血 加防
就让我自己走吧
穿着 球鞋 我的球鞋
迎着 暴雪 我的暴雪
朝着 山野 要去见
所有我喜欢的一切
就让我自己走吧
哪一代 什么浪 都不是 我的模样
别对我说 去成为谁的模样
未来不在 沙滩上 我本该拥有海洋
我本该拥有海洋 就让我自己走吧
孤岛极光 虚拟城邦 星球流浪
我将走向 无垠远方
我本该拥有海洋 就让我自己走吧
我不遗忘 我的模样
不管答案是什么 hello hello hello
我们都拥有海洋
""";
Response<Embedding> embeddingResponse = embeddingModel.embed(prompt);
System.out.println(embeddingResponse);
return embeddingResponse.content().toString();
}
/** http://localhost:9012/embedding/createCollection
* 新建向量数据库实例和创建索引:test-qdrant
* 类似mysql create database test-qdrant
*/
@GetMapping(value = "/embedding/createCollection")
public void createCollection()
{
var vectorParams = Collections.VectorParams.newBuilder()
.setDistance(Collections.Distance.Cosine)
.setSize(1024)
.build();
qdrantClient.createCollectionAsync("test-qdrant", vectorParams);
}
/*
http://localhost:9012/embedding/add
往向量数据库新增文本记录
*/
@GetMapping(value = "/embedding/add")
public String add()
{
String prompt = """
我们都拥有海洋的歌词如下:
如果这是 再不返回的夏天
好好的告别 和重要的人说再见
无关那些 催人启程的祝愿
这世界太吵 不代表你的声音不珍贵
去哪 让我选择
如果 只有岸没有海
那我 长奔跑的脚踝
到底是为什么
为剧烈的心动
跑起来去见 喜欢的我
兴趣使然的
怎么判断有用 谁来规定无用
完美的旅程
为何每一站 是一样的路牌
没有 石头 所以 所以 没有 悟空
就让我自己走吧
穿着 球鞋 我的球鞋
迎着 暴雪 我的暴雪
朝着 山野 要去见
所有我喜欢的一切
就让我自己走吧
哪一代 什么浪 都不是 我的模样
别对我说 去成为谁的模样
未来不在 沙滩上 我本该拥有海洋
我本该拥有海洋 就让我自己走吧
孤岛极光 虚拟城邦 星球流浪
不管会遇见什么 hello hello hello
你可见过 两片相同的树叶
人不可复写 生命是原创的情节
去问明天 渴望怎样一张脸
它说是少年 它说和我一样毫无经验
不懂 天高地厚
是否 是短暂的自由
多久 像风筝爱天空
怎能害怕 坠落
人生中的考场
我会勇敢地 给出回答
亲手署名吧
有时也会考砸 不抄谁的答案
挥手告别吧
记得二十岁 流着泪的笑脸
前路 卡关 借来 借来 加血 加防
就让我自己走吧
穿着 球鞋 我的球鞋
迎着 暴雪 我的暴雪
朝着 山野 要去见
所有我喜欢的一切
就让我自己走吧
哪一代 什么浪 都不是 我的模样
别对我说 去成为谁的模样
未来不在 沙滩上 我本该拥有海洋
我本该拥有海洋 就让我自己走吧
孤岛极光 虚拟城邦 星球流浪
我将走向 无垠远方
我本该拥有海洋 就让我自己走吧
我不遗忘 我的模样
不管答案是什么 hello hello hello
我们都拥有海洋
""";
TextSegment segment1 = TextSegment.from(prompt);
segment1.metadata().put("author", "吴青峰");
segment1.metadata().put("price", "priceless");
Embedding embedding1 = embeddingModel.embed(segment1).content();
String result = embeddingStore.add(embedding1, segment1);
System.out.println(result);
return result;
}
@GetMapping(value = "/embedding/query1")
public void query1(){
Embedding queryEmbedding = embeddingModel.embed("我们都拥有海洋歌词说了什么").content();
EmbeddingSearchRequest embeddingSearchRequest = EmbeddingSearchRequest.builder()
.queryEmbedding(queryEmbedding)
.maxResults(1)
.build();
EmbeddingSearchResult<TextSegment> searchResult = embeddingStore.search(embeddingSearchRequest);
System.out.println(searchResult.matches().get(0).embedded().text());
}
@GetMapping(value = "/embedding/query2")
public void query2(){
Embedding queryEmbedding = embeddingModel.embed("我们都拥有海洋的演唱者是谁").content();
EmbeddingSearchRequest embeddingSearchRequest = EmbeddingSearchRequest.builder()
.queryEmbedding(queryEmbedding)
.filter(metadataKey("author").isEqualTo("吴青峰"))
.maxResults(1)
.build();
EmbeddingSearchResult<TextSegment> searchResult = embeddingStore.search(embeddingSearchRequest);
System.out.println(searchResult.matches().get(0).embedded().text());
}
}
最后
为什么要学AI大模型
当下,⼈⼯智能市场迎来了爆发期,并逐渐进⼊以⼈⼯通⽤智能(AGI)为主导的新时代。企业纷纷官宣“ AI+ ”战略,为新兴技术⼈才创造丰富的就业机会,⼈才缺⼝将达 400 万!
DeepSeek问世以来,生成式AI和大模型技术爆发式增长,让很多岗位重新成了炙手可热的新星,岗位薪资远超很多后端岗位,在程序员中稳居前列。

与此同时AI与各行各业深度融合,飞速发展,成为炙手可热的新风口,企业非常需要了解AI、懂AI、会用AI的员工,纷纷开出高薪招聘AI大模型相关岗位。
最近很多程序员朋友都已经学习或者准备学习 AI 大模型,后台也经常会有小伙伴咨询学习路线和学习资料,我特别拜托北京清华大学学士和美国加州理工学院博士学位的鲁为民老师给大家这里给大家准备了一份涵盖了AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频 全系列的学习资料,这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

AI大模型系统学习路线
在面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。

但知道是一回事,做又是另一回事,初学者最常遇到的问题主要是理论知识缺乏、资源和工具的限制、模型理解和调试的复杂性,在这基础上,找到高质量的学习资源,不浪费时间、不走弯路,又是重中之重。
AI大模型入门到实战的视频教程+项目包
看视频学习是一种高效、直观、灵活且富有吸引力的学习方式,可以更直观地展示过程,能有效提升学习兴趣和理解力,是现在获取知识的重要途径

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
海量AI大模型必读的经典书籍(PDF)
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。
600+AI大模型报告(实时更新)
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。
AI大模型面试真题+答案解析
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 9
9 0
0- 0



 已为社区贡献393条内容
已为社区贡献393条内容

所有评论(0)