从零到一搭建RAG系统,高效利用大模型实现RAG知识库,工作原理+实战部署
RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合了信息检索和文本生成的技术框架,旨在通过引入外部知识库来提升生成模型(如GPT等)的准确性和可靠性。RAG知识库是这一技术的核心组成部分,它存储了结构化或非结构化的海量数据(如文档、网页、数据库等),供模型在生成答案时动态检索并参考。
1、什么是RAG
RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合了信息检索和文本生成的技术框架,旨在通过引入外部知识库来提升生成模型(如GPT等)的准确性和可靠性。RAG知识库是这一技术的核心组成部分,它存储了结构化或非结构化的海量数据(如文档、网页、数据库等),供模型在生成答案时动态检索并参考。
2、RAG架构及执行流程
传统的生成模型依赖预训练时学到的参数化知识,因训练数据过时或领域局限导致生成内容不准确(即幻觉问题)。
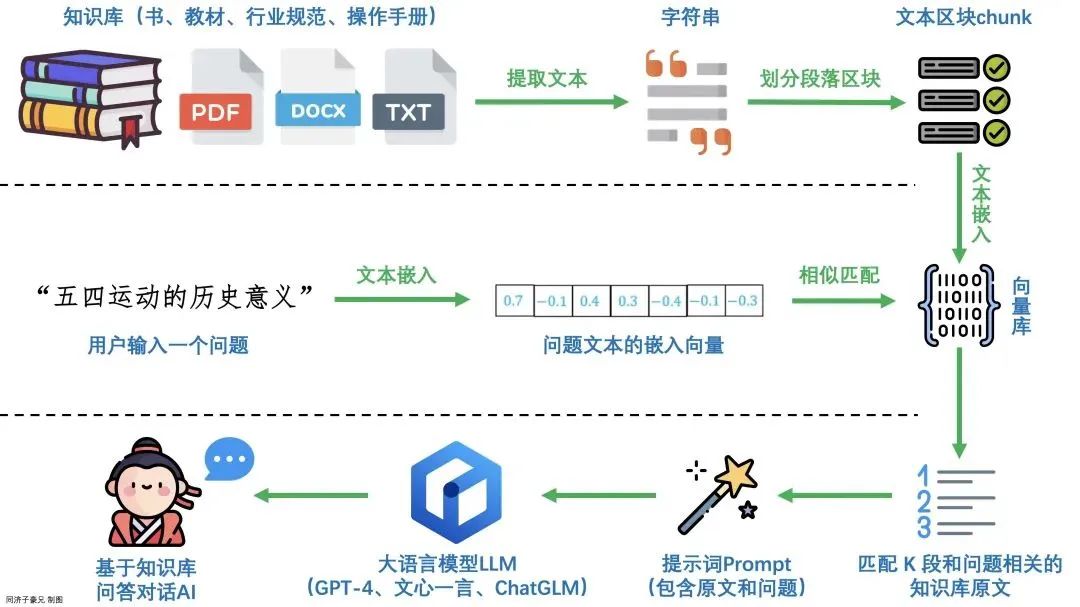
执行流程:
1、提取语料库内容,转化为向量
2、文本向量写入向量数据库
3、文本搜索,通过文本转向量,向量相似度搜索
4、调用大模型生成结果
第一步:语料库及转化为向量
可以通过deepseek等大模型生成,比如:请给我生成一个套出租房屋业务客服语料库。生成好后,复制到本地txt文件。
# 内容提取和段落划分很简单
def get_chunk_list():
with open("dataset/1.txt", encoding='utf-8') as fp:
data = fp.read()
chunk_list = data.split("\n\n")
return [chunk for chunk in chunk_list if chunk]
向量化处理我们借助于ollama,官网https://ollama.com下载。
安装好后,我们可以直接在命令行安装模型。
ollama pu11 nomic-embed-text
把文本内容转化为向量
# 文本妆化为向量
def ollama_embedding_by_api(text):
url = "http://127.0.0.1:11434/api/embeddings"
res = requests.post(
url=url,
json={
"model": "nomic-embed-text",
'prompt': text
}
)
return res.json()['embedding']
第二步:语料库内容嵌入向量数据库
向量数据库有很多:chromadb、Faiss、Qdrant、Elasticsearch等等。 今天我们就使用chromadb,直接本地安装使用。
# 安装向量数据库
pip install chromadb
# 批量导入向量数据库
def bulk_insert_collection(lines):
collection = get_collection()
ids = [str(uuid.uuid4()) for _ in range(len(lines))]
vectors = [ollama_embedding_by_api(line) for line in lines]
collection.add(
ids=ids,
documents=lines,
embeddings=vectors
)
通过update和delete函数对表更新和删除操作,调整语料。
collection.update(ids=['id'],documents=['text'])
collection.delete(ids=['id'])
第三步:向量相似度搜索
检索数据转化为向量化数据,然后进行查询
def query_text(text):
vector = ollama_embedding_by_api(text)
collection = get_collection()
# n_result 匹配数量 2
res = collection.query(
query_embeddings=[vector, ],
query_texts=text,
n_results=2)
return "\n".join(res['documents'][0])
第四步:文本大模型润色
使用文本大模型进行推理,安装deepseak蒸馏的r1模型
# 继续使用ollama进行安装
ollama pull deepseek-r1:1.5b
根据自己的应用场景或行业定义提示词。
def get_deepseek_response(question,answer):
prompt = f"""你是一个房屋出租客服机器人,任务是根据参考
信息回然用户问题,如果参考信息不足以回然用户问题,
请回复不知道,不要去杜撰任何信息,请用中文同然。
参考信息:{question},来回答问题:{answer}
"""
res = requests.post(
url="http://127.0.0.1:11434/api/generate",
json={
"model": "deepseek-r1:1.5b",
'prompt': prompt,
'stream': False,
}
)
return res.json()['response']
第五步:测试运行
写入预料到向量数据库
bulk_insert_collection(get_chunk_list())
检索并文本输出
question = '你好,我想租房'
answer = query_text(question)
res = get_deepseek_response(question,answer)
print(res)
总结起来就是:知识库是将知识数据的索引保存到向量数据库中,然后利用prompt的向量到向量数据库中搜索,根据阈值搜到符合要求的,并对搜索到的知识进行二次处理,然后连同prompt一起作为上下文提交给大模型。
那么,如何系统的去学习大模型LLM?
作为一名从业五年的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
由于篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~
👉大模型学习指南+路线汇总👈
我们这套大模型资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。

👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。
👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。
👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。
👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 30
30 0
0- 0



 已为社区贡献311条内容
已为社区贡献311条内容

所有评论(0)