CoTKR:解决图RAG需要将检索到的子图转为 LLM 能理解的形式,传统方法无关信息过多、会遗漏关键细节、没有和问题语义对齐
对应特征:LLMs 对一次性的大段“摘要”或“线性拼接的三元组”理解可能有限,要想兼顾复杂问题的多跳信息、又要剔除冗余,就需要一个能够分步地推理、再分步地总结的机制。之所以用这个子解法,是因为问题往往是多跳、且检索到的子图中有大量不相关或冗余信息。若一次性将所有三元组简单拼接(或一次性做一个概括性总结),可能会遗漏关键细节或加入许多无关内容,从而影响回答准确率。简要技术/公式令表示第步的已生成内容
CoTKR:解决图RAG需要将检索到的子图转为 LLM 能理解的形式,传统方法无关信息过多、会遗漏关键细节、没有和问题语义对齐
论文:CoTKR: Chain-of-Thought Enhanced Knowledge Rewriting for Complex Knowledge Graph Question Answering
代码:https://github.com/wuyike2000/CoTKR
论文大纲
├── 1 背景与问题【提出研究需求】
│ ├── 1.1 LLM 在知识密集型任务中的局限【说明现状】
│ │ ├── 幻觉(hallucination)问题【模型局限】
│ │ └── 知识陈旧与不准确【模型缺陷】
│ ├── 1.2 现有 RAG(Retrieval-Augmented Generation)方案【技术背景】
│ │ ├── 基于三元组的直接拼接【Triple】
│ │ ├── 三元组转文本【KG-to-Text】
│ │ └── 简要总结三元组【Summary】
│ └── 1.3 存在的挑战【引出不足】
│ ├── 冗余或遗漏关键信息【信息噪声】
│ ├── 单步重写无法捕捉复杂语义【多跳推理不足】
│ └── 模型与 QA 偏好不一致【导致性能损失】
├── 2 CoTKR 方法提出【核心创新点】
│ ├── 2.1 Chain-of-Thought Enhanced Knowledge Rewriting【方法核心】
│ │ ├── 交替生成推理轨迹与知识【Reasoning 与 Summarization 互相交织】
│ │ ├── 逐步过滤不相关信息【按问题语义抽取】
│ │ └── 生成组织良好的知识表示【对齐问句逻辑】
│ └── 2.2 PAQAF:从 QA 反馈中进行偏好对齐【训练策略】
│ ├── 用 QA 的答案质量评价知识表示【构造偏好对】
│ ├── 利用直接偏好优化 (DPO) 调整模型【缩小偏好差距】
│ └── 与 ChatGPT 生成参考知识相结合【进一步提升质量】
├── 3 技术细节【方法如何实现】
│ ├── 3.1 预备知识与定义【前置概念】
│ │ ├── 知识图谱 (KG) 结构【三元组 (s, r, o)】
│ │ └── KGQA 任务描述【从 KG 获取答案】
│ ├── 3.2 CoTKR 的工作流程【方法步骤】
│ │ ├── Reasoning【输出所需知识点】
│ │ ├── Summarization【基于 Reasoning 提炼信息】
│ │ └── 交替循环生成最终知识表示【多轮迭代】
│ └── 3.3 训练框架:SFT 与 PAQAF【模型如何学到】
│ ├── 初始监督微调 (SFT)【ChatGPT 生成参考示例】
│ └── 偏好对齐 (PAQAF)【利用 QA 反馈作优选】
├── 4 实验与评测【方法效果验证】
│ ├── 4.1 数据集【实验环境】
│ │ ├── GrailQA【多域大规模数据】
│ │ └── GraphQuestions【特征丰富的问答数据】
│ ├── 4.2 实验设置【模型与对比】
│ │ ├── 基线方法【Triple / KG-to-Text / Summary 等】
│ │ ├── 检索方案【2-Hop / BM25 / GS】
│ │ └── QA 模型选择【ChatGPT / Llama-2 / Llama-3 / Mistral】
│ ├── 4.3 评价指标【衡量性能】
│ │ ├── Accuracy (Acc)【正确性】
│ │ ├── Recall【覆盖率】
│ │ └── Exact Match (EM)【严格匹配】
│ └── 4.4 主要结果【实验发现】
│ ├── 相比传统方法,CoTKR 显著提升【验证有效性】
│ ├── 不同检索方法下均表现稳定【鲁棒性】
│ └── 消融实验显示数据增广与偏好对齐收益明显【探索关键组件】
├── 5 讨论与局限性【对当前工作的思考】
│ ├── 5.1 方法适用范围【仅在 KGQA 领域验证】
│ ├── 5.2 对封闭模型依赖【ChatGPT 数据生成误差】
│ └── 5.3 如何拓展到其他类型知识来源【挑战与潜在方向】
├── 6 伦理考虑【使用大模型的潜在风险】
│ ├── 6.1 可能的事实错误与歧视倾向【价值偏见、种族或性别问题】
│ ├── 6.2 数据隐私与使用开源模型成本【API 依赖和费用问题】
│ └── 6.3 负责任地发布与使用【代码开源与限制声明】
└── 7 总结与未来工作【总结成果并展望】
├── 7.1 主要贡献【CoTKR + PAQAF 的有效性】
├── 7.2 实际应用前景【更复杂多跳推理与跨模态扩展】
└── 7.3 后续研究方向【减少对 ChatGPT 依赖、泛化更多数据源】
CoTKR 核心方法 概念图:
├── 1 CoTKR 核心方法【概述方法】
│ ├── 1.1 输入:问题和相关子图【输入】
│ │ ├── 问题 (q)【问题描述】
│ │ └── 子图 (G')【从知识图谱 (KG) 中提取的相关三元组】
│ ├── 1.2 处理过程:交替生成推理与总结【处理过程】
│ │ ├── Reasoning(推理)【推理阶段】
│ │ │ ├── 输入:问题 (q) 和子图 (G')【输入】
│ │ │ └── 输出:推理链 (z)【推理结果】
│ │ │ ├── 任务:分解问题,确定所需的相关知识【分解问题】
│ │ │ └── 技术:自然语言推理 (NLI)、关系抽取【推理步骤】
│ │ ├── Summarization(总结)【总结阶段】
│ │ │ ├── 输入:推理链 (z) 和子图 (G')【输入】
│ │ │ └── 输出:总结知识表示 (k)【总结结果】
│ │ │ ├── 任务:提炼子图中的关键信息,去除冗余【信息筛选】
│ │ │ └── 技术:文本生成、信息压缩【总结技术】
│ │ └── 输出:交替生成推理和总结后的最终知识表示 (X)【输出】
│ │ ├── 任务:构建简洁、有效且符合语义的知识表示【输出任务】
│ │ └── 技术:生成式预训练模型 (GPT)、序列到序列模型【生成技术】
│ ├── 1.3 输出:最终生成的知识表示【输出】
│ │ ├── 结果:优化后的知识表示 (k)【最终输出】
│ │ ├── 任务:为问题提供清晰且结构化的答案【问题回答】
│ │ └── 技术:生成式回答、自然语言生成【答案生成】
│ └── 1.4 连接技术:CoTKR 的交替步骤【处理衔接】
│ ├── Reasoning 与 Summarization 的交替生成【衔接方式】
│ ├── 目标:逐步精炼答案的质量【逐步优化】
│ └── 技术:链式推理、逐步总结【技术整合】
│
├── 2 训练框架:如何优化 CoTKR【模型训练】
│ ├── 2.1 输入:训练数据集【输入】
│ │ ├── 数据:问题 q、子图 G' 和参考答案【训练数据】
│ │ └── 训练方式:监督微调 (SFT)、偏好对齐 (PAQAF)【训练方法】
│ ├── 2.2 处理过程:生成与优化【训练过程】
│ │ ├── 生成:使用大语言模型生成初步知识表示 (k)【生成步骤】
│ │ ├── 优化:利用 QA 模型反馈调整生成结果【优化过程】
│ │ └── 技术:偏好优化 (DPO)、直接偏好优化【优化方法】
│ └── 2.3 输出:优化后的训练模型【输出】
│ ├── 结果:优化后的 CoTKR 模型【训练结果】
│ └── 任务:提高知识生成质量和准确性【模型精度】
│
├── 3 偏好对齐(PAQAF):通过 QA 反馈优化 CoTKR【偏好对齐】
│ ├── 3.1 输入:QA 反馈和偏好对【输入】
│ │ ├── QA 模型反馈:基于生成的答案质量【反馈来源】
│ │ └── 偏好对:通过评价对生成的知识表示进行排序【偏好评估】
│ ├── 3.2 处理过程:根据反馈优化生成模型【反馈优化】
│ │ ├── 对比:生成两个不同的知识表示【生成对比】
│ │ ├── 评估:使用 QA 模型评估生成结果的质量【质量评估】
│ │ └── 优化:基于偏好对调整模型参数【优化过程】
│ └── 3.3 输出:优化后的知识表示【输出】
│ ├── 结果:更加符合 QA 模型需求的知识表示【反馈结果】
│ └── 任务:通过对齐反馈提升模型性能【提升模型效果】
│
└── 4 技术实现:如何实现 CoTKR【技术架构】
├── 4.1 生成推理与总结的架构设计【架构设计】
│ ├── Reasoning:利用大语言模型生成推理链【生成推理】
│ └── Summarization:通过自然语言生成模型总结信息【信息总结】
├── 4.2 使用 Llama-2、Llama-3 作为模型基础【基础模型】
│ ├── 采用 Llama-2 进行知识重写【重写过程】
│ └── 通过 Llama-3 增强生成能力【增强效果】
└── 4.3 模型训练:SFT 与 DPO 的结合【模型训练】
├── SFT:监督微调来初始化知识重写模型【模型初始化】
└── DPO:偏好对齐技术优化最终模型【偏好调整】
理解
要解决什么类别的问题?又是要解决什么具体问题?(务必具体)
-
类别问题:论文所要解决的是一个“知识图谱问答(KGQA)”类别的问题。
具体来说,随着大模型(LLM)在各类自然语言处理任务上表现优异,人们开始将其与“检索增强生成(Retrieval-Augmented Generation, RAG)”相结合,用于在知识密集型场景(如复杂知识图谱问答)中减少“幻觉(hallucination)”现象。
-
具体问题:在知识图谱问答中,通常需要先检索与问题相关的一部分图谱子图(subgraph),再将这部分子图内容“改写”成能让大语言模型看得懂的自然语言描述(而不是生硬的三元组形式)。
可是,当问题非常复杂时,已有的改写方法往往会:
- 包含许多无关信息,导致模型输出冗长且容易混淆。
- 遗漏关键信息或逻辑链,导致答案不准确。
- 改写的语义和问题并不总是对齐,甚至会破坏逻辑顺序,使模型难以进行多步推理。
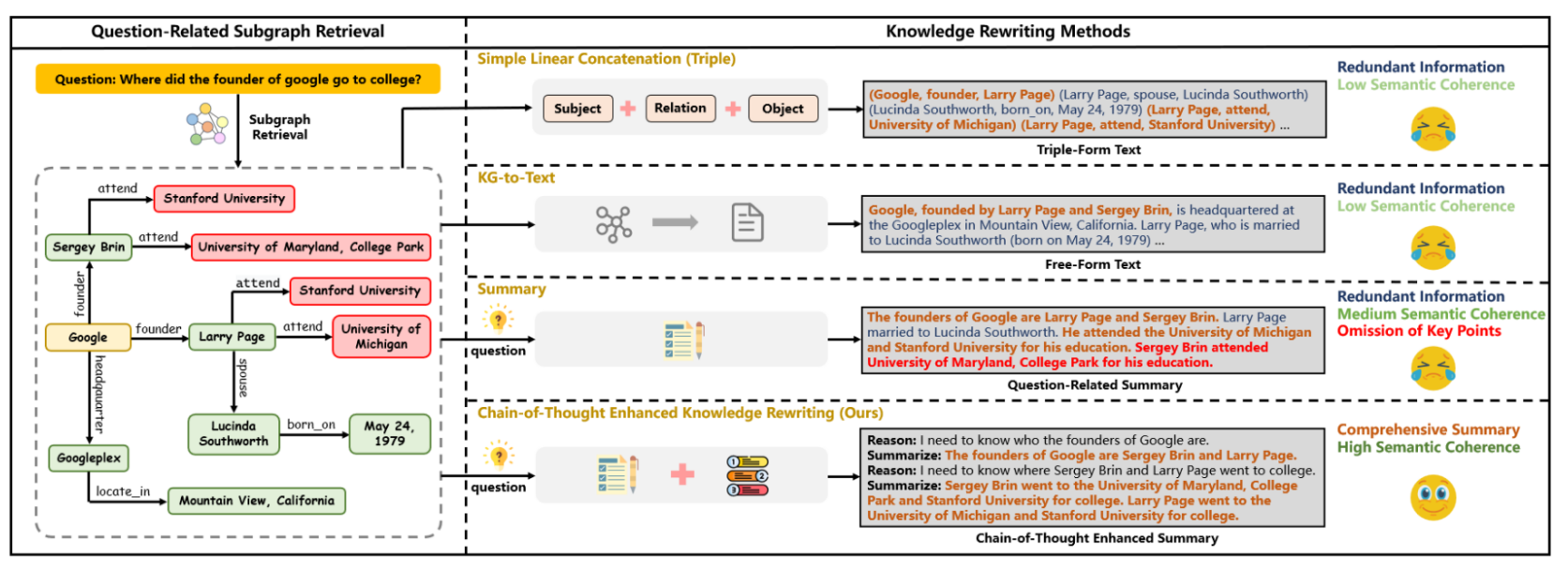
对比四种“知识改写”方法
这张图主要分为左右两大部分:
- 左侧:展示了从知识图谱里检索到的一小片子图(Subgraph),其中包含一些实体和关系(如某科技公司、其创始人、就读的大学等)。这个子图是“问题相关子图检索”的结果。
- 右侧:给出了四种常见(或代表性)的知识改写方法,并配合简单示意说明了它们各自的文本形式和缺陷/优点。
1. Simple Linear Concatenation (Triple)
- 做法:将子图中的三元组 (Subject, Relation, Object) 直接拼接成字符串,比如 “(Google, founder, Larry Page) (Larry Page, spouse, Lucinda Southworth)…” 等。
- 特点/缺点:
- 虽然简单,但产生的大段“Triple-Form Text”往往冗余信息多、语义衔接松散,难以让大语言模型清晰提炼关键点。
2. KG-to-Text
- 做法:将三元组直接转成一种自然语言风格的陈述句,如 “Google, founded by Larry Page and Sergey Brin, is headquartered at…”
- 特点/缺点:
- 虽然比纯三元组更加连贯,但容易把子图全部无差别地展开,仍存在大量与问题无关的上下文,导致冗余且容易混淆。
3. Summary
- 做法:围绕给定问题(如“Where did the founder of google go to college?”)写一个“与问题相关的简要总结”。
- 特点/缺点:
- 相比前两种做法,Summary 会“有针对性”地去掉一些明显无关的信息,语义连贯性有所提升。
- 不过,因为一次性总结有可能遗漏关键点,或没能详细说明多个实体;在图中标注为“可能省略了一些关键事实”(Omission of Key Points)。
4. Chain-of-Thought Enhanced Knowledge Rewriting (CoTKR)
- 做法:把“推理过程”与“知识改写”交替进行,边想边写,即先 Reason 再 Summarize。
- 例如图中先说“Reason: 我需要知道谁是创始人”,接着“Summarize: XXX是这家公司的创始人”……然后再针对“去哪里上大学”进行下一步 Reason & Summarize。
- 特点/优势:
- 在图中被标为“Comprehensive Summary / High Semantic Coherence”,即既能去掉杂乱信息,又能把关键点都写清楚,且前后逻辑顺畅。
- 相比其它做法,既减少了冗余,也避免了遗漏,能给下游问答模型更有条理的上下文。
综观右侧的四种方法,从上到下,信息的“冗余度”逐渐降低,而语义“连贯度”逐渐提高,体现了 CoTKR 在多步推理时能更好地提炼并组织知识的优势。
因此,CoTKR的提出背景就在于:如何在复杂 KGQA 场景下,生成更“有条理、能帮助推理”的知识表述,让大语言模型能根据该表述更好地回答问题。
CoTKR 的核心性质可以概括为:
- 性质:它能够以“链式思维(Chain-of-Thought,CoT)”的方式,引导模型逐步推理,并在每一步推理时插入相应的知识改写或摘要。这样做能够在改写时过滤掉冗余信息,补充关键缺失信息,并确保整个知识表述与问题的多步推理逻辑保持一致。
- 成因:
- 分步推理机制:将一个复杂问题拆解成若干可管理的推理环节,在推理环节与知识总结环节交替进行时,模型自然就能“只改写当前最需的知识”,从而避免一次性罗列过多杂乱内容。
- 问答偏好对齐:通过引入“PAQAF(Preference Alignment from Question Answering Feedback)”来评价不同改写方式对问答模型的帮助程度,并据此进行偏好优化,让改写器更贴合问答任务需求。这使得最终的知识表述在准确性、相关性上更胜一筹。
把回答大问题的过程拆成多个小问题,每一步只改写当前最关键的知识,同时保留原有链式推理思路,让最终答案更准确、更省时。
正例(CoTKR 改写思路)
-
问题:
“患者有哪些主要症状?服用什么药物可以缓解这些症状?” -
检索到的病例子图(简化示意)包含:
- (患者A, 主诉症状, 咳嗽)
- (患者A, 主诉症状, 发热)
- (患者A, 已使用药物, 抗生素X)
- (患者A, 已使用药物, 止咳糖浆Y)
- …(其他三元组,如家庭住址、既往病史等)
-
传统简单改写(反面做法)
- 往往把所有三元组直接堆成大段文字,例如:
「患者A,主诉症状:咳嗽、发热;既往病史:轻微胃炎;居住地:X市Y区;已使用药物:抗生素X、止咳糖浆Y;家庭成员:…」 - 内容又长又混杂,不仅有地址、家庭成员等次要信息,而且没有突出对诊断最重要的部分。
- 往往把所有三元组直接堆成大段文字,例如:
-
CoTKR 改写(正面做法)
- 推理步1:先明确“需要哪些核心症状”。
- 「我需要知道患者A的主诉症状是什么。」
- 知识总结1:只写本步最相关内容:
- 「患者主要出现咳嗽和发热。」
- 推理步2:接着说“要了解能缓解这些症状的用药信息”。
- 「我需要知道患者已使用的药物,或常见可缓解咳嗽、发热的处方。」
- 知识总结2:
- 「患者已使用的药物包括抗生素X和止咳糖浆Y,可用于缓解发烧、咳嗽。」
- 推理步1:先明确“需要哪些核心症状”。
-
结果:
- 面对同一个问题(症状+用药),采用 CoTKR 方式后,问诊/回答模型可以快速锁定患者的核心症状和对应的药物方案,输出的诊断建议更准确、更简洁。
反例(仅做简要比较)
-
问题:
“患者有哪些主要症状?服用什么药物可以缓解这些症状?” -
若仍沿用简单“串三元组”的方法:
- 将包括家庭住址、既往病史、亲属信息等通通罗列,难以突出“咳嗽、发热”及药物要点。
- 示例内容可能包含:
「患者A 曾经患过胃炎、居住于X市Y区,家庭成员 4 人,其中一人有慢性气管炎…已使用药物包括抗生素X、止咳糖浆Y…」 - 这些并非当下问题(主要症状与用药)最关键的内容,模型需要自行筛选,很容易出错或遗漏。
-
后果:
- 诊断或答复模型看到大量背景与家属信息,浪费上下文空间;
- 容易忽略该次就诊的关键:咳嗽、发热及对应的药物,使得答案要么冗长要么不准确。
通过正反例对比可以看出,CoTKR 在医疗问诊场景下的思路是:
- 先用“推理步”明确诊断思路;
- 在每一步仅“摘取最相关的症状或用药信息”;
- 分步呈现给后续模型或医生参考。
这样就能避免一次性罗列所有信息导致的混乱,也不会遗漏关键用药与症状,有助于更精准地给出诊疗建议或答案。
CoTKR,全称“Chain-of-Thought Enhanced Knowledge Rewriting”,指的是在知识图谱问答的流程中,引入链式推理思路,将“推理步骤”与“知识改写”交替进行,使得每一步都能生成与该步推理需求相符的自然语言知识表述。
它还配合“问答偏好对齐”(PAQAF)来自动微调改写结果,让最终的知识表述对问答模型最友好。
- 归纳总结:
- 基于多步推理:分解复杂问题,从而分步检索、归纳关键知识;
- 交替的“推理—总结”流程:在需要什么、缺什么的提示下去改写知识;
- 偏好对齐:利用问答模型的反馈来选择最优改写风格;
- 提升问答精准性:减少无关信息干扰,避免漏关键信息,答案更可靠。
解法拆解


1. 按照逻辑关系中文拆解【解法】
整体解法(总述)
CoTKR 的主要目标是:在复杂知识图谱问答(KGQA)中,将检索到的子图(通常是若干条 RDF 三元组)转换为对大模型(LLM)“更友好”的自然语言形式,并且在此过程中融入类 Chain-of-Thought(CoT)的推理线索。
通过分步的“推理-总结”交替,来逐步过滤无关信息、补充关键证据,并最终生成符合问题语义需求、能最大化帮助问答模型的知识表示。
此外,还通过“问答反馈偏好对齐(PAQAF)”的策略,利用 QA 模型给出的回答质量来进一步优化重写模块,达到让“知识重写”与“问答模型”偏好一致的目标。
从宏观上看,CoTKR 的解法可以拆分为以下三个子解法(每个子解法都源于特定的“特征”或“需求”),它们一起构成一个完整流程:
子解法1:交替式多步重写(在自然语言中融合“推理-总结”交互)
- 对应特征:LLMs 对一次性的大段“摘要”或“线性拼接的三元组”理解可能有限,要想兼顾复杂问题的多跳信息、又要剔除冗余,就需要一个能够分步地推理、再分步地总结的机制。
- 之所以用这个子解法,是因为问题往往是多跳、且检索到的子图中有大量不相关或冗余信息。若一次性将所有三元组简单拼接(或一次性做一个概括性总结),可能会遗漏关键细节或加入许多无关内容,从而影响回答准确率。
简要技术/公式:
令 表示第 步的已生成内容(包括先前的“推理文本”和“知识总结”),
-
在第 步的“推理”阶段,模型根据输入 { q , G ′ , X t − 1 } \{q, G', X_{t-1}\} {q,G′,Xt−1} 得到推理线索 z t , r z_{t,r} zt,r(如公式 (2) 所示):
z t , r = R ( q , G ′ , X t − 1 ) z_{t,r} = R(q, G', X_{t-1}) zt,r=R(q,G′,Xt−1)
这里 R ( ⋅ ) R(\cdot) R(⋅) 是知识重写模型的生成函数。
-
在紧随的“总结”阶段,模型再结合输入 { q , G ′ , X t − 1 , z t , r } \{q, G', X_{t-1}, z_{t,r}\} {q,G′,Xt−1,zt,r} 生成与当前推理需求对应的知识 z t , k z_{t,k} zt,k(可理解成“当前步知识要点”),如公式 (3):
( z t , k = R ( q , G ′ , X t − 1 , z t , r ) (z_{t,k} = R\bigl(q, G', X_{t-1}, z_{t,r}\bigr) (zt,k=R(q,G′,Xt−1,zt,r)
二者交替进行并累积到知识序列 { X 1 , X 2 , … } \{X_1, X_2, \dots\} {X1,X2,…} 中,直到覆盖了问题所需的所有信息。
子解法2:监督微调 + 问答反馈偏好对齐(PAQAF)
- 对应特征:单纯让模型直接学“如何对三元组做自然语言重写”可能会与下游问答模型的“偏好”不一致;并且如果使用开源大模型(如 Llama 系列)来做知识重写,还需要先学习 ChatGPT 或 GPT-4 那种更高质量的重写风格。
- 之所以用这个子解法,是因为在问答场景下,“有帮助的知识重写”并不等同于“看起来流畅的文本”。需要一个面向“最终问答是否正确”的优化环节,去对齐重写模型与问答模型的真实需求。
其内部又可拆分为两个阶段:
- 阶段 A:监督微调(Supervised Fine-tuning)
-
使用 ChatGPT 生成的高质量重写示例 { ( x , k ) } \{(x, k)\} {(x,k)} 形式)做“参考知识表示”,来对开源 LLM(如 Llama-2/3)进行微调。公式 (4) 所示:
max θ ∑ ( x , k ) ∈ D T log p θ ( k ∣ x ) \max_{\theta} \sum_{\bigl(x,k\bigr) \in D_{T}} \log p_\theta(k \mid x) maxθ∑(x,k)∈DTlogpθ(k∣x)
-
这样,开源模型就能初步具备“把 KG 三元组重写成自然语言”的能力。
-
- 阶段 B:偏好对齐(Direct Preference Optimization, DPO)
-
用下游问答反馈来“打分”不同重写风格,以此构造“偏好对” { ( k + , k − ) } \{(k_+, k_-)\} {(k+,k−)}。
-
然后用公式 (5)-(6) 的直接偏好优化(DPO),最小化:
L D P O ( θ ∗ ; θ ) = − ∑ ( x , k + , k − ) ∈ P [ log σ ( r ( x , k + ) − r ( x , k − ) ) ] L_{\mathrm{DPO}}(\theta^*; \theta) = -\sum_{(x, k_+, k_-) \in P} \Bigl[\log \sigma\bigl(r(x, k_+) - r(x, k_-)\bigr)\Bigr] LDPO(θ∗;θ)=−∑(x,k+,k−)∈P[logσ(r(x,k+)−r(x,k−))]
其中 ( r ( ⋅ ) ) (r(\cdot)) (r(⋅)) 是根据问答结果得到的“偏好打分”, σ \sigma σ 是 sigmoid 函数。
这样可使重写模型更倾向于输出被下游 QA 模型验证更优的版本。
-
子解法3:数据增强(Data Augmentation for Rewriting)
- 对应特征:ChatGPT 等闭源大模型往往能输出多样化、质量较高的重写数据,如果仅使用单一的“原版重写”,训练集多样性不足,限制了重写模型的上限。
- 之所以用这个子解法,是因为在实际 KGQA 任务中,有些问题需要更灵活的语句组织方式,才能突出重点、或避免无关内容。让 ChatGPT 生成多种“同义改写(paraphrase)”能增加训练多样性、避免过拟合。
通过将 ChatGPT 的 paraphrase 版本与“差的重写版本”一起做对比,来强化模型区分好坏重写的能力,并在 DPO 训练中收敛得更快、效果更好。
示例(简化版本)
- 给定一个多跳问题:“某测量系统具有单位是伏特/米的电场强度,那么它的面积单位是什么?”
- 首先检索到与该测量系统相关的子图(三元组若干条),然后在子解法1中分两步:
- 推理:这里我们先“推断”测量系统是“国际单位制”,确定要去找其面积单位。
- 总结:在众多检索到的三元组中,提取出“平方米 (m^2)”和“平方公里 (km^2)”等可能有用的单位。
- 子解法2 中,我们用 ChatGPT 生成一些参考答案来指导微调。再让 QA 模型去回答,如果 QA 模型判断“以 m^2 为主”更对,就偏好这个重写。
- 子解法3 中,我们再让 ChatGPT 产出更多种写法,比如强调“Square meter”或“Square kilometer”,增加训练多样性。最后经由偏好对齐后,模型会更容易输出正确且简洁的知识重写,帮助 QA 模型答出 “Square meter / Square kilometer”。
- 这些子解法是什么样的逻辑链?是链条,还是网络,以决策树形式列出来
整体看,CoTKR 的核心流程大体呈线性链式展开,但其在“子解法1”的内部,有一个“多步循环”的结构(原因是“推理-总结”是交替式的迭代过程)。
如果用决策树形态来展示,可以近似这样表示:
[开始:检索到子图 G']
↓
┌───> 子解法1 (交替式多步推理-总结) ───┐
│ │
│ 生成候选知识表征 ↓
│ │
└───<----------------------------------┘ (若还需下一步推理)
↓
子解法2 阶段A: 监督微调 (SFT)
↓
子解法2 阶段B: 偏好对齐 (DPO)
↓
子解法3: 利用 ChatGPT 做数据增强
↓
[最终获得高质量知识重写]
↓
[输入给 QA 模型做问答]
可以看到,这些子解法严格上是一个大环与几个子过程相互嵌套:
- 子解法1 内部是循环(推理 → 总结),直到完成整合。
- 子解法2 与 子解法3 都是训练/对齐层面的方法,前后会迭代进行一些数据采样、偏好评估,再回到重写模型的参数更新。
- 分析是否有隐性方法(不是书本上的方法,而是解法中的关键步骤)
在 CoTKR 中,有几个“隐性方法”值得注意,可能在原论文中只是一笔带过或嵌在实验环节里:
-
隐性方法 A:基于答案实体数量的初步偏好判断
- 文中提到,如果要区分哪个重写版本更好,可以先看该重写输出的上下文中,QA 模型是否能正确包含更多答案实体。这相当于在显式“预先打分”之前,进行了一次基于“答案实体覆盖率”的简单判断。
- 这是一个“实践中发现有效”的关键步骤:事先筛掉太不相关的重写,减少后续与 QA 模型交互的成本。论文中并未将它单独定名为算法,但实际上这是一个“隐性过滤手段”。
-
隐性方法 B:多步推理与多步总结之间的“指针式”衔接
- 在子解法1 中,每步推理完会让模型自己“点名”下一步要挖掘哪些三元组,才能缩小范围。这种“指针/标记”机制让模型不会在下一步总结时丢失上下文逻辑。
- 论文主要展示了(2)、(3)这两个公式,但其实在实现时,需要给模型一个额外的“自我提示”,相当于“隐性指针”,使得每步总结都只在前一步选定的候选三元组上做文本转换。
这两点都属于原本没有明确在书本或通用“知识重写”中规定的“细节设计”,可以视为本方法的“隐性关键方法”。
- 分析是否有隐性特征(特征不在问题、条件中,而是解法的中间步骤)
在 CoTKR 的实现中,确实出现了一些“中间步骤”的特征,没有在传统定义里明确,比如:
- 隐性特征 A:多轮推理迭代过程中,LLM 需要依赖上一步产生的“推理链”来决定下一步究竟使用哪些三元组做“总结”。这让“推理链的质量”本身变成了新的特征:
如果推理链出错或者冗长,下一步总结就可能带入偏差。
- 隐性特征 B:在偏好对齐阶段引入的“多样性”需求。即当我们从知识重写模型中采样多个候选重写时,要求它们在语义上尽量差异较大,才能有效地对模型做出偏好训练。
这在普通的多样性采样里是常见做法,但该工作又跟 KGQA 场景结合,要求同一个子图的多个重写间要覆盖不同信息结构,从而帮助 QA 模型区分优劣。
这些隐性特征均在中间步骤中体现,而不是原问题或原条件直接显现出来,需要在算法实现时特别注意。
-
方法可能存在哪些潜在的局限性?
-
依赖外部强模型(如 ChatGPT)生成训练数据
- 若 ChatGPT 本身产生了不准确或含偏见的文本,会将噪声带入重写模型;此外,调用闭源大模型有成本和隐私风险。
-
多步推理可能导致累积误差
- 每一步的推理-总结若不够准确,会把错误信息往后传递;虽然该工作中有一定的纠错机制(如多步筛选、QA 反馈),但仍不能完全避免。
-
偏好对齐(PAQAF)需要较多 QA 交互
- 为了获取对比并构造偏好对,必须多次调用问答模型,成本较高。如果 QA 模型也不够强,反馈信号的准确度会削弱。
-
主要面向 KGQA 场景
- 该方法在传统文本 RAG 或表格数据上也许可以借鉴,但论文本身只在知识图谱问答上实验;跨领域的泛化性还需进一步验证。
总结
- 子解法1(交替式多步重写):解决“单步转换易冗余、漏关键信息”的痛点。
- 子解法2(监督微调 + 问答反馈对齐):解决“重写模型与下游 QA 偏好不一致”的痛点。
- 子解法3(数据增强):通过多样化的高质量改写,解决“训练多样性不足、易过拟合”的痛点。
它们组合成一个总体“链状 + 局部循环”的方案。
内部还包含一些隐性的关键方法和特征,如基于答案覆盖率的筛选、多步“指针式”衔接、差异化采样等。
在实际应用时,仍需要考虑依赖大模型的成本、误差累积、以及在其他数据类型或任务中的适用性。
CoTKR 的训练框架(两大阶段)
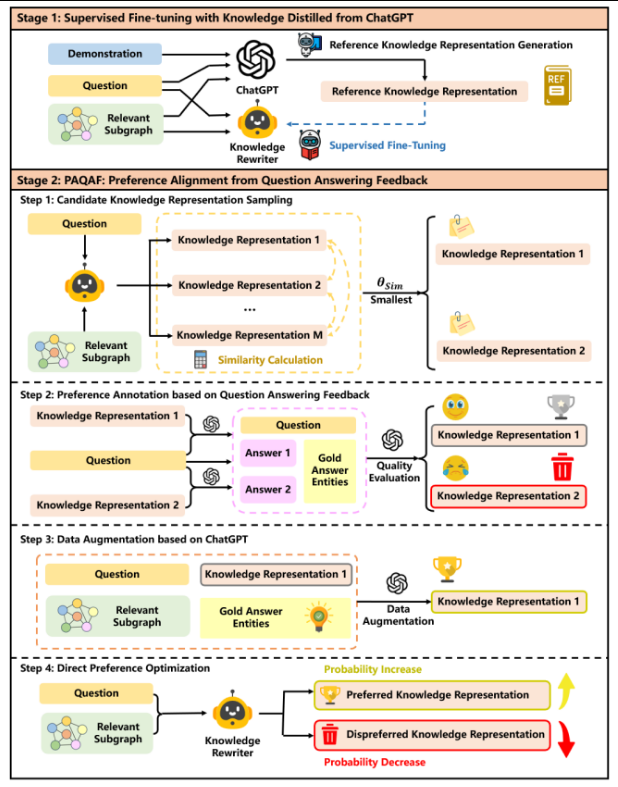
这张图用更流程化的方式展示了 CoTKR 的训练方法,分为 Stage 1 和 Stage 2:
Stage 1:Supervised Fine-tuning with Knowledge Distilled from ChatGPT
- Reference Knowledge Representation Generation
- 先利用 ChatGPT 生成“高质量的参考知识改写”(相当于金标准或教师示例)。
- Supervised Fine-Tuning
- 让自有的开源模型(Knowledge Rewriter)学着模仿这个“参考改写”。
- 目标:初步掌握如何将子图转成自然语言、且与问题相关。
Stage 2:PAQAF (Preference Alignment from Question Answering Feedback)
这是关键创新点:让改写器与“问答模型的需求”对齐,进一步精炼改写质量。
- Step 1: Candidate Knowledge Representation Sampling
- 对同一问题+子图,模型可能采样出多种候选改写(Knowledge Representation 1、2、…M)。
- 先用相似度计算,选出差异较大的两种表述,以便后续对比。
- Step 2: Preference Annotation based on Question Answering Feedback
- 把这两种改写分别当成上下文,去问“QA 模型”并比较回答质量(看是否包含正确答案实体、是否准确等)。
- 根据回答质量,标记出“Preferred Knowledge Representation”和“Dispreferred Knowledge Representation”。
- Step 3: Data Augmentation based on ChatGPT
- 为了丰富训练数据,可能对“Preferred”那份改写进一步用 ChatGPT 做释义或改写,形成更多正样本。
- Step 4: Direct Preference Optimization
- 最后,用“Preferred / Dispreferred”配对,进行 DPO(Direct Preference Optimization)训练,让模型在同一个输入下更倾向生成优选改写,远离劣质改写。
通过这两阶段过程,CoTKR 一方面先学到 ChatGPT 的优秀改写风格,另一方面再借助问答任务的实际反馈做“偏好对齐”,从而得到在下游问答中表现更好的知识改写能力。
提问
1. 关于多步推理与噪声传播
Q:在引入多步链式推理(CoT)时,如果检索到的子图里含有大量噪声或错误信息,CoTKR 的分步摘要是不是可能反复引用这些错误,导致每一步都带来新的错误累积?作者在文中是如何应对“噪声传播”问题的?
A:论文提到,CoTKR 在每一步的“Summarize”环节会根据上一轮“Reason”明确当前需求,尽量只提取与该需求高度相关的三元组或事实。
这样做虽然不能完全杜绝噪声,但至少能降低将无关信息无限放大的风险。
此外,作者也实验性地结合了“检索方法改进”和“问答反馈偏好对齐”,从结果上减少了错误信息继续流转的机会。
但若检索本身错误很大,CoTKR 也无法彻底消除这部分错误——它只是降低了“内在放大”的概率,而不是“完全免疫噪声”。
2. 与三元组直接拼接相比的实质差别
Q:在一些先前研究里,三元组形式(Triple-Form)给大模型看,反而在简单问题上表现不错。那么 CoTKR 有无场景下会退化到和“三元组拼接”差不多的效果?作者是否在论文中给出细粒度对比?
A:论文中确实提到,针对极简单的问题(如只需单跳推理),三元组直接拼接也能达到不错效果。
有时甚至看似效率更高,因为不必分步写摘要。然而对于多跳或逻辑较复杂的问题,三元组拼接会暴露大量无关细节,让模型在解读时容易“跑偏”。
作者在实验中做了详细对比:当问题涉及多跳且信息量大时,CoTKR 能显著降低冗余、提升正确率;问题很简单时,CoTKR 与 Triple 的差距可能不那么大,甚至接近持平,但不会明显劣于 Triple。
3. 为什么要先用 ChatGPT 生成参考改写?
Q:作者采用了 ChatGPT 生成“参考知识表示”供初始监督学习,这意味着在开源模型上依赖一个更强闭源模型的输出。要是 ChatGPT 本身存在幻觉或错误,怎么办?作者是否讨论过用 GPT-4、Claude 等其他模型作教师会不会更好?
A:论文中说明,选择 ChatGPT 主要是看中其稳定性与生成质量,以及相对较低的成本。
确实,如果 ChatGPT 本身回答不准确,那么生成的知识改写也可能带有错误,进而“带偏”开源模型。
不过,在第二阶段 PAQAF (偏好对齐)时,会用问答反馈来剔除错误或劣质的改写,做进一步修正。
对于换用 GPT-4 或其他模型,作者并未在论文中给出正式对比,但暗示使用更强大的教师模型应该有潜力带来更好的初始监督效果。
4. CoTKR 在选择多大规模的 LLM 时最合适?
Q:作者实验里既用到了 7B~13B 级别的开源 LLM,也使用过 ChatGPT 这样的闭源大模型。是否有讨论过在上百亿、千亿规模的模型上,CoTKR 是否仍有价值?大模型本身就可以“自动总结”了,真的需要这种额外的链式改写吗?
A:论文指出,即便大模型能“自动总结”,在面对多跳、结构化知识时,也容易出现漏关键信息或大量无关上下文的情况。
CoTKR 的核心理念是“让模型在生成答案前,有一份专门针对问题的高质量知识表示”,而不是让模型“自说自话”从庞大子图里扒拉信息。
作者并没有在超大规模模型(上百亿参数)上做全面测试,但指出一般来说,越强的模型越少依赖额外改写;然而在极复杂问题上,或与 KG 的配合场景里,“问答前的链式改写”依然能减少错误和幻觉。
5. PAQAF 的计算开销与收益
Q:第二阶段的 PAQAF 需要在同一个问题上生成多份候选改写,然后分别让下游问答模型执行回答、比较质量。这样会不会在大规模数据集上算力开销过大,得不偿失?
A:作者并不否认该过程开销较高,但他们提供了多种“降本”策略:
- 先通过相似度筛选只留最不相似的两份候选,让比较次数从 M 减少到 2;
- 用精简数据集或自适应采样来减小训练开销;
- 可以对不同问题分批处理,把偏好数据“复用”到相似问题上。
作者认为相比带来的性能提升,这种额外训练消耗是值得的,尤其是在对准确率和可控性要求高的场景里。
6. 是否会在长尾知识或低频关系上失效?
Q:论文的实验覆盖了不少 KGQA 基准,但有些长尾实体或罕见关系并未在训练中频繁出现。对于这类低频知识的改写,CoTKR 是否也能保证较好质量?
A:作者在论文中承认,如果某些关系几乎没见过,CoTKR 在改写时的自然语言模板或常见表达也可能是“学习不足”的。
不过,链式思维的一个好处是——即使是低频知识,只要在“推理步”里能定位到该关系,就可以把局部三元组照搬进来或做简单自然语言化,不至于完全忽视。
因此即便会有一定退化,也往往好过一次性大规模拼接。如果严重依赖该低频关系,准确度仍有下降风险,但不会比其他方法更糟。
7. 与表格数据或文本数据结合的通用性
Q:论文主要在知识图谱(KG)上做实验。如果把知识来源换成表格、网页文档或其他半结构化数据,CoTKR 能否平移?作者有没有讨论过“多模态”或“跨模态”扩展?
A:论文中提到的“知识改写”,本质是把“结构化事实”变成易被大模型理解的自然语言。
对于表格和半结构化文本,大致也可以做类似处理:分步挑选行列、摘要条目等。
但作者并未展开多模态场景,文中只聚焦于 KGQA。想拓展到图像/音频等多模态,可能需要更多特定处理。
作者仅在结论或展望中简单提到这一点,可见目前尚无实装实验。
8. 是否存在过度总结、信息丢失的风险?
Q:一次性 Summarize 法会漏关键信息,而 CoTKR 是“多次 Summarize”,会不会在每一步“滤掉”一些在后续推理中才突然需要的重要事实?作者做了哪些保护措施?
A:CoTKR 每个“Reason”步骤都要回溯原始子图 G′,并不是只在上一阶段的摘要里找信息。
因此,即使某些事实在第一轮 Summarize 没提到,只要后续 Reason 检测到需要,就能重新访问原始子图做补充。
作者认为,这比单次摘要更灵活,不太会错过事后突然关键的信息。
当然,如果 G′ 里本来就找不到该事实,CoTKR 也无法无中生有。
9. 作者如何衡量“高语义连贯度”?
Q:在对比图里,CoTKR 被标为“High Semantic Coherence”,请问作者用什么客观方式去衡量“连贯度”?是人工打分?还是有特定的自动化指标?
A:根据论文细节,作者采用了多种评估方法:
- 自动指标:如回答正确率(Acc)或实体召回率(Recall)间接反映了“表示是否全面连贯”——如果知识写得混乱会导致答不对。
- 人工标注:一些实验引入人类评审对生成文本做可读性、相关性打分,也包含对连贯性的主观评价。
作者承认目前缺乏一个完全统一、量化的“语义连贯度”分数,但多指标结合能够较好地说明问题。
10. 是否能防止大模型“编造新事实”?
Q:CoTKR 通过链式改写减少幻觉,但如果问答模型本身在生成答案时依旧喜欢“编故事”,CoTKR 真的能阻止这点吗?作者在论文中有没有给出理论或实验论证?
A:作者强调,CoTKR 只负责在回答前给出相对准确、连贯的知识上下文,提供可靠输入,确实能减小“编造”的概率。
但大模型输出是否仍会“脑补”与事实无关的内容,取决于模型内部机制及解码策略。
作者实验结果表明,当给出优质上下文时,大模型的幻觉率显著下降,但并不意味着 100% 消除——尤其是在生成型模型对回答长度或样式有更高自由度时。
因此,CoTKR 是一种“降低风险”的方法,不是“彻底杜绝幻觉”的终极方案。
提示词
知识重写方法的提示词
[指令 Instruction]
你的任务是将一个知识图(knowledge graph)转换为一个或多个句子。该知识图为:{triples}。
请写出相应的句子:
Summary Prompt
[指令 Instruction]
你的任务是总结从以下三元组中对回答问题有帮助的相关知识。
Triples: {triples}
Question: {question}
Knowledge:
CoTKR Prompt
[指令 Instruction]
你的任务是总结从以下三元组中对回答问题有帮助的相关信息。请分步骤思考,并迭代地生成推理链和对应的知识。
Triples: {triples}
Question: {question}
使用 Triple/KG-to-Text/Summary 知识进行问答的 Prompt
[指令 Instruction]
你的任务是基于可能相关的知识来回答下列问题。尽量使用给定知识中的原始用词来回答问题。但如果你认为这些知识无用,你可以忽略它并给出你自己的猜测。
Knowledge: {knowledge}
Question: {question}
Answer:
使用 CoTKR/CoTKR+PA 知识进行问答的 Prompt
[指令 Instruction]
你的任务是基于可能相关的推理链来回答下列问题。尽量使用给定知识中的原始用词来回答问题。但如果你认为这些知识无用,你可以忽略它并给出你自己的猜测。
Knowledge: {knowledge}
Question: {question}
Answer:
偏好标注提示词(Preference Annotation Prompt)
[指令 Instruction]
你的任务是根据预定义的标准来评价两个对同一问题的回答质量。请避免任何位置偏见,确保回答出现的顺序不会影响你的判断。不要因为回答的长短而影响你的评价。尽量客观。
[标准 Criteria]
在本次评价中,主要考虑以下标准:
1. 准确性(Accuracy):回答应包含尽可能多的答案实体,并使用答案实体的原始表达。
2. 相关性(Relevance):回答应切中问题的要点。
Question: {question}
Answer: {answer}
Response A: {response A}
Response B: {response B}
[评价规则 Evaluation Rule]
先比较这两个回答并给出简短的说明。然后只输出一个字符:
- 如果你认为 Response A 更好,输出 "A"
- 如果你认为 Response B 更好,输出 "B"
- 如果你认为两者相当,输出 "C"
最后在新的一行上,只重复输出该字母即可。
数据增强提示词(Data Augmentation Prompt)
[指令 Instruction]
你是一名为“问题回答(Question Answering)”进行知识图总结的助手。我会给你“Question”、“Triple”、“Answer”以及“Knowledge”。你的任务是将原始的“Knowledge”改写成一种更有帮助的表达形式,以便回答问题。“Paraphrased Knowledge”应包含所有答案实体的原始用词。
Question: {question}
Triple: {triples}
Answer: {answer}
Knowledge: {knowledge}
Paraphrased Knowledge:
GPT-4-score 提示词
[指令 Instruction]
你的任务是评估对问题的回答质量,判断是否所有答案实体都出现在该回答中。
Question: {question}
Answer: {answer}
Response: {response}
请先比较该回答与正确答案,并给出简短的说明。
然后只输出一个数字:
- 如果回答中包含了所有答案实体,则输出 "1"
- 如果没有全部包含,则输出 "0"
最后在新的一行上,再重复输出这个数字即可。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 24
24 0
0- 0



 已为社区贡献68条内容
已为社区贡献68条内容

所有评论(0)