FastSpeech2Conformer:ESPKIT工具包在Conformer模型推动下的最新进展
在本研究中,我们介绍了ESPnet:端到端语音处理工具包的最新进展,主要涉及一种最近提出的架构——Conformer,即卷积增强的Transformer。本文展示了广泛的端到端语音处理应用的结果,如自动语音识别(ASR)、语音翻译(ST)、语音分离(SS)和文本到语音(TTS)。我们的实验揭示了使用Conformer在不同任务上获得的各种训练技巧和显著的性能优势。这些结果具有竞争力,甚至超越了当前
温馨提示:
本篇文章已同步至"AI专题精讲" ESPKIT工具包在Conformer模型推动下的最新进展
摘要
在本研究中,我们介绍了ESPnet:端到端语音处理工具包的最新进展,主要涉及一种最近提出的架构——Conformer,即卷积增强的Transformer。本文展示了广泛的端到端语音处理应用的结果,如自动语音识别(ASR)、语音翻译(ST)、语音分离(SS)和文本到语音(TTS)。我们的实验揭示了使用Conformer在不同任务上获得的各种训练技巧和显著的性能优势。这些结果具有竞争力,甚至超越了当前最先进的Transformer模型。我们准备使用开源和公开可用的语料库为上述所有任务发布一体化配方,并提供预训练模型。我们这项工作的目标是通过减少通常需要高资源准备的最先进研究环境的负担,为我们的研究社区做出贡献。
关键词— Conformer, Transformer, 端到端语音处理
1. 引言
Transformer架构最近引起了极大的兴趣,并因其在各种序列到序列任务中的有效性而成为主导模型,如机器翻译、语言建模(LM)和自动语音识别(ASR)[1–6]。Transformer模型成功的一个原因是多头自注意力层比循环神经网络(RNNs)能更好地学习长距离的全局上下文。然而,对于语音处理任务,不仅全局上下文重要,局部信息对于捕捉语音的某些特定属性(如协同发音和单调性)也至关重要。另一方面,卷积神经网络(CNNs)擅长提取细粒度的局部特征模式。最近,Gulati等人[7]提出了一种结合自注意力和卷积的ASR模型新架构,命名为Conformer。通过这种设计,自注意力层学习全局上下文,而卷积模块同步高效地捕捉局部相关性。
除了ASR任务,其他语音处理任务在提供局部信息时也能获得类似的益处和改进。在本研究中,我们旨在探索Conformer在各种端到端语音处理应用中的效率,包括自动语音识别(ASR)、语音翻译(ST)、语音分离(SS)和文本到语音(TTS)。我们在大量公开可用的语料库上提供了Conformer与Transformer的深入比较,并尽力分享使用Conformer的实用指南(如学习率、超参数、网络结构)。我们还准备向社区发布可复现的配方和最先进的设置,以继承我们令人兴奋的成果。
本研究的贡献包括:
• 我们将Conformer架构扩展到各种端到端语音处理应用,并与Transformer进行比较实验。
• 我们分享了Conformer训练的实用指南,如学习率、Conformer块的核大小和模型架构等。
• 我们在开源工具包ESPnet [8–10]中提供了大量公开可用语料库的可复现基准结果、配方、设置和训练良好的模型。
2. Conformer
我们的Conformer模型由[7]中提出的Conformer编码器和Transformer解码器组成。编码器是一个多块架构,每个块由位置前馈(FFN)模块、多头自注意力(MHSA)模块、卷积(CONV)模块和最后的另一个FFN模块堆叠而成。我们在每个模块之前应用层归一化(LN),并在之后应用dropout和残差连接(预归一化),如[5, 11]中所述。本节描述了编码器中每个模块的细节。
2.1. 多头自注意力模块
MHSA模块的思想是学习一种对齐方式,其中序列中的每个标记都学会从其他标记中收集信息[12, 13]。对于每个单头h,注意力计算的输出可以表示为:
注意力计算公式如下:
Att ( Q h , K h , V h ) = Softmax ( Q h K h T d att ) V h ( 1 ) \text{Att}(Q_h, K_h, V_h) = \text{Softmax} \left( \frac{Q_h K_h^T}{\sqrt{d_{\text{att}}}} \right) V_h\qquad{(1)} Att(Qh,Kh,Vh)=Softmax(dattQhKhT)Vh(1)
其中,查询(Query)、键(Key)和值(Value)是通过输入序列 X ∈ R T × d in X \in \mathbb{R}^{T \times d^{\text{in}}} X∈RT×din 进行线性变换得到的:
Q h = W q h X , K h = W k h X , V h = V q h X Q_h = W_q^h X, \quad K_h = W_k^h X, \quad V_h = V_q^h X Qh=WqhX,Kh=WkhX,Vh=VqhX
投影权重矩阵分别为 W q h , W k h , W v h , V q h ∈ R d in × d ff W_q^h, W_k^h, W_v^h, V_q^h \in \mathbb{R}^{d^{\text{in}} \times d^{\text{ff}}} Wqh,Wkh,Wvh,Vqh∈Rdin×dff,其中 d att d_{\text{att}} datt 表示注意力的维度,而 H H H 代表注意力头的总数量。
缩放因子 1 d att \frac{1}{\sqrt{d_{\text{att}}}} datt1 旨在对点积结果进行缩放,以避免因注意力维度过大而导致的数值过大问题。为了能够同时关注不同的表示子空间,每个注意力头的输出会被拼接(concatenate)在一起,并输入到一个全连接层(fully-connected layer),计算过程如下:
MHSA ( Q , K , V ) = Concat ( head 1 , … , head H ) W o ( 2 ) \text{MHSA}(Q,K,V) = \text{Concat}(\text{head}_1, \dots, \text{head}_H) W^o\qquad{(2)} MHSA(Q,K,V)=Concat(head1,…,headH)Wo(2)
head h = Att ( Q h , K h , V h ) ( 3 ) \text{head}_h = \text{Att}(Q_h, K_h, V_h)\qquad{(3)} headh=Att(Qh,Kh,Vh)(3)
其中, W o ∈ R d att × d att W^o \in \mathbb{R}^{d^{\text{att}} \times d^{\text{att}}} Wo∈Rdatt×datt 是一个输出线性投影矩阵。
此外,Conformer 还借鉴了 Transformer-XL [3] 的位置编码方案,以生成更好的位置信息,使输入序列能够适应不同的长度,该方法称为相对位置编码(relative positional encodings)。对于输入序列 X X X,计算过程如下:
X = X + Dropout ( MHSA ( LN ( X ) ) ) ( 4 ) X = X + \text{Dropout}(\text{MHSA}(\text{LN}(X)))\qquad{(4)} X=X+Dropout(MHSA(LN(X)))(4)
2.2. 卷积模块
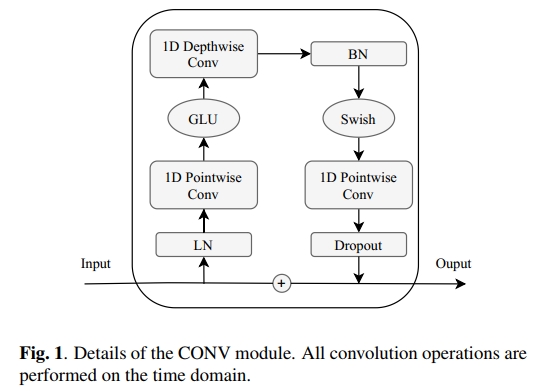
图 1 展示了 CONV 模块的详细结构。该模块首先经过一个 1 维逐点卷积层(1-D pointwise convolution layer),然后通过门控线性单元(GLU, Gated Linear Units)激活函数 [14]。1 维逐点卷积层会将输入通道数加倍,而 GLU 激活函数会在通道维度上将输入拆分成两部分,并执行逐元素乘法(element-wise product)。随后,该模块依次包含:
- 1 维深度卷积层(1-D depthwise convolution layer),
- 批量归一化层(Batch Normalization, BN),
- Swish 激活函数,
- 另一个 1 维逐点卷积层。
2.3. 逐点前馈模块
原始Transformer中的FFN模块由两个线性变换组成,中间有一个ReLU激活函数,如下所示:
F F N ( X ) = W 2 R e L U ( W 1 X + b 1 ) + b 2 ( 5 ) FFN(X)=W_2ReLU(W_1X+b_1)+b_2\qquad{(5)} FFN(X)=W2ReLU(W1X+b1)+b2(5)
其中, W 1 ∈ R d att × d att \mathbf{W}_1 \in \mathbb{R}^{d^{\text{att}} \times d^{\text{att}}} W1∈Rdatt×datt 和 W 2 ∈ R d att × d att \mathbf{W}_2 \in \mathbb{R}^{d^{\text{att}} \times d^{\text{att}}} W2∈Rdatt×datt 是线性投影矩阵, d att d^{\text{att}} datt 表示线性层的隐藏维度。
与Transformer不同,Conformer引入了另一个FFN模块,并将ReLU激活函数替换为Swish激活函数。此外,受Macaron-Net [5] 的启发,两个FFN模块采用半步方案,并夹在MHSA和CONV模块之间。数学上,对于输入X,输出为:
X = X + 1 2 × D r o p o u t ( F F N ( L N ( X ) ) ) ( 6 ) \mathbf{X}=\mathbf{X}+\frac{1}{2}\times\mathrm{Dropout}(\mathrm{FFN}(\mathrm{LN}(\mathbf{X})))\qquad{(6)} X=X+21×Dropout(FFN(LN(X)))(6)
2.4. Conformer 模块
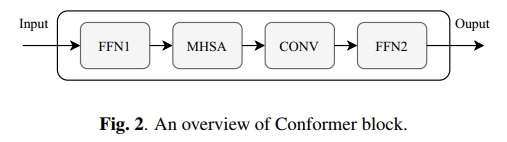
图 2 展示了如何将每个模块组合在一起。Conformer 模块与 Transformer 模块的区别包括:相对位置编码、集成的 CONV 模块以及 Macaron-Net 风格的一对 FNN 模块。
3. 语音应用
在 ASR(自动语音识别)任务中,Conformer 模型从输入的 80 维 log-mel 滤波器组特征序列 X(可能包含或不包含 3 维音高特征)中预测目标字符序列或字节对编码(BPE)标记序列 Y。X 首先在卷积层中以 4 倍因子进行子采样(如 [4] 中所述),然后输入编码器和解码器以计算交叉熵(CE)损失。编码器输出还用于计算连接主义时间分类(CTC)损失 [17],用于联合 CTC-注意力训练和解码 [18]。在推理过程中,通过浅层融合结合了标记级或词级语言模型(LM)[19]。
ST(语音翻译)任务采用与 ASR 相同的框架。它直接将源语言的语音映射为目标语言的对应翻译。为了消除严重的欠拟合问题,我们通过预训练的 ASR 编码器初始化 ST 编码器,并从预训练的机器翻译(MT)解码器开始 ST 解码器,如 [9] 中所述。
对于 SS(语音分离)任务,Conformer 模型被优化为在给定语音混合的情况下估计每个说话者的时频掩码。模型使用话语级排列不变损失(uPIT)[20] 进行训练。与 ASR 系统不同,此处的 Conformer 模型仅包含编码器,后跟一个额外的线性层和激活函数以预测掩码。
TTS(文本到语音)任务将 Conformer 编码器用于非自回归 TTS 模型 [21–23],这些模型与持续时间预测器 [21] 协作,从音素或字符序列生成 log-mel 滤波器组特征序列。整个模型通过最小化目标特征的 L1 损失和持续时间的均方误差(MSE)损失进行优化。
4. 语音识别实验
4.1. 实验设置
为了评估 Conformer 模型的有效性,我们在总共 25 个 ASR 语料库上进行了实验,涵盖了各种录音环境(干净、嘈杂、远场、混合语音)、语言(英语、普通话、日语、西班牙语、低资源语言)和规模(10 - 960 小时)。大多数语料库遵循与 Kaldi [24] 相同的数据准备流程。在某些语料库中,我们还使用了速度扰动 [25](比例为 0.9、1.0、1.1)和 SpecAugment [26] 进行数据增强。
对于每个语料库,我们的Conformer模型的详细配置与ESPnet Transformer的配方相同[27](编码器层数=12,解码器层数=6,前馈网络维度=2048,注意力头数=4,注意力维度=256)。特别是,Librispeech的注意力头数和注意力维度有所不同(注意力头数=8,注意力维度=512)。卷积子采样层由2层CNN组成,具有256个通道,步幅为2,卷积核大小为3。对于不同的语料库,我们训练20-100个周期,并将最后10个最佳检查点的平均值作为最终模型。我们在相应的开发集上调整学习率系数(例如,1-10)和CONV模块的卷积核大小(例如,5-31)以获得最佳结果。详细设置可以参考ESPnet配方 [ 3 ] ^{[3]} [3]。
4.2 结果
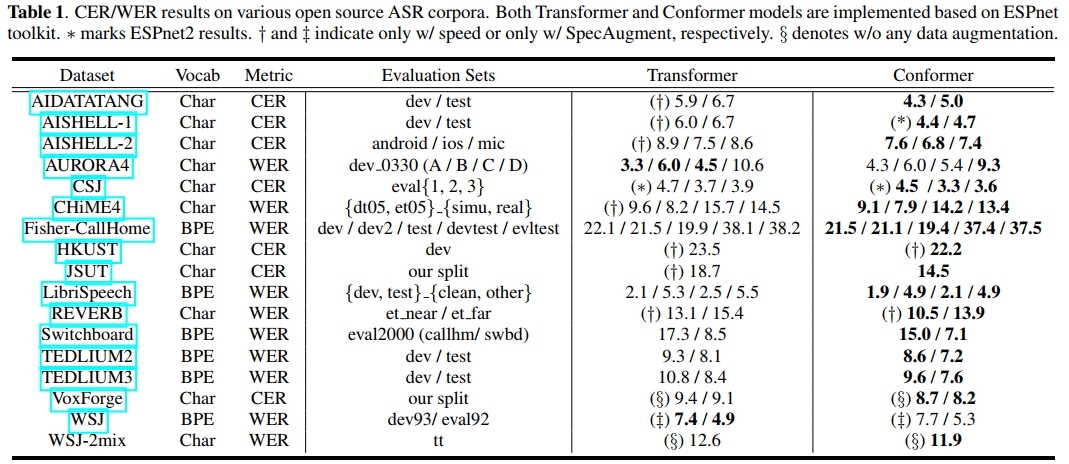
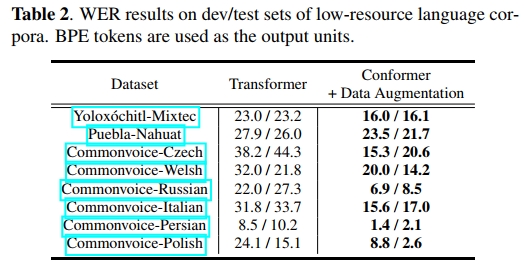
表1展示了每个语料库上的字符错误率(CER)和词错误率(WER)结果。可以看出,在我们的实验中,Conformer模型在14/17个语料库上优于Transformer,甚至在AIDATATANG和AISHELL-1等语料库上达到了最先进的结果。与单说话者语音不同,Conformer在多说话者WSJ-2mix数据上也比Transformer带来了约7%的相对提升。此外,我们还进行了实验以研究Conformer模型在低资源语言语料库上的泛化能力,如表2所示。与Transformer模型相比,Conformer在所有8种不同语言中均实现了超过15%的相对改进。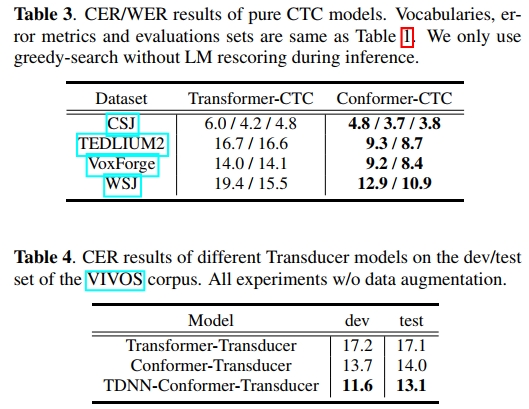
由于我们的Conformer模型使用了与Transformer相同的解码器框架,性能提升可能来自于CONV模块提供的额外局部信息。因此,我们通过训练纯CTC模型或使用Conformer编码器的Transducer模型来研究CONV模块的影响。表3总结了两款纯CTC模型的CER/WER结果,而表4展示了不同Transducer模型的CER结果。我们在所有Transducer模型中使用单层LSTM解码器。详细设置可参考ESPnet配方。3. Conformer-CTC和TDNN-Conformer-Transducer模型均显示出一致的改进,Conformer-CTC模型甚至在带有解码器的情况下取得了与Transformer竞争的结果。从上述结果可以得出结论,Conformer在各种类型的ASR语料库中表现出卓越的性能,即使在具有挑战性的远场、混合语音和低资源语言场景中也是如此。
4.3 讨论
以下是我们实验中的一些训练技巧:
- 当Conformer在训练集上出现准确率突然下降时,降低学习率可以使训练更加稳定。我们针对不同语料库使用了f1, 2, 5, 10g范围内的学习率。
- CONV模块的卷积核大小与语料库中输入句子的长度相关。我们针对不同语料库使用了f5, 7, 15, 31g范围内的卷积核大小。
- 除了预热训练策略[1]外,OneCycleLR[28]学习调度器也可以为基于自注意力的模型提供稳定的训练。
5. 语音翻译实验
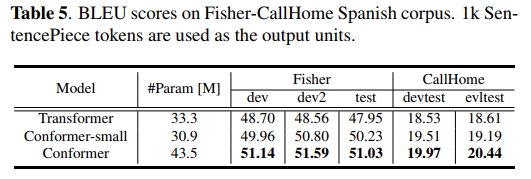
我们所有ST模型的配置与第4.1节中描述的ASR系统相同。在训练过程中,我们使用分别在ASR和MT平行数据上优化的预训练编码器和解码器初始化模型参数。我们在Fisher-CallHome西班牙语料库上进行了ST实验,并在五个常见的测试集上进行了评估。我们使用Fisher-dev集作为开发集。输入语音特征与ASR系统相同,输出标记为1k BPE标记。使用了相同的数据增强技术以提高性能。
在ST任务中,Conformer模型相比基线Transformer模型也实现了约10%的相对提升。为了验证这些提升不仅仅是因为增加了CONV和FFN模块而增加了模型参数,我们还通过将dff从2048减少到1024来训练一个Conformer-small模型,以保持参数预算的公平比较。尽管将dff减半后BLEU分数略有下降,但我们的Conformer-small模型仍然显著优于Transformer模型。
6. 语音分离实验
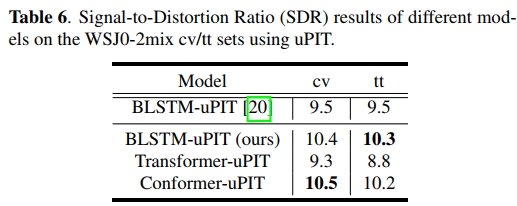
在语音分离(SS)任务中,我们在WSJ0-2mix语料库上将Conformer模型与Transformer和双向长短期记忆(BLSTM)模型进行了比较。两种模型均基于相位敏感掩码(PSM)和ReLU激活函数,使用uPIT [20] 进行训练。输入特征是通过8 kHz采样频率、32 ms帧长和16 ms帧移计算的129维短时傅里叶变换(STFT)幅度谱。BLSTM-uPIT模型包含3层BLSTM(d = 896),而Transformer-uPIT和Conformer-uPIT模型由3个模块组成(dff = 896;datt = 1024;H = 8)。
表6总结了不同模型在WSJ0-2mix数据集上的信号失真比(SDR)[29] 结果,这是当前用于验证单声道语音分离的基准数据集。结果表明,我们的Conformer-uPIT模型与BLSTM-uPIT模型相比取得了具有竞争力的结果,并且相较于Transformer-uPIT模型实现了显著提升。
7. TTS实验
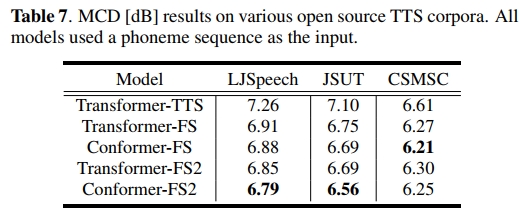
在TTS实验中,我们使用三个常见语料库进行评估:LJSpeech(22.05 kHz,英语,24小时)、JSUT(24 kHz,日语,10小时)和CSMSC(24 kHz,普通话,12小时),这些语料库均由单一女性说话者的语音组成。我们将基于Conformer的非自回归模型与基于Transformer的模型进行比较,包括Transformer-TTS [30]、FastSpeech(FS)[21]和FastSpeech2(FS2)[22]。我们使用了datt = 368、dff = 1536和H = 2。FS的编码器和解码器块数设置为6,FS2设置为4。对于FS2,我们使用[23]中引入的标记平均音高和能量预测,而不是量化的音高和能量预测,以避免过拟合。至于神经声码器,我们使用了Parallel WaveGAN [31]的开源实现4。除神经声码器外,所有模型均使用ESPnet2实现。训练配置、生成样本和预训练模型可在Github3上获取。
表7显示了梅尔倒谱失真(MCD),它是通过0-34阶梅尔倒谱和动态时间规整(DTW)计算的,以匹配真实值和预测值之间的长度。结果表明,基于Conformer的模型在所有语料库中均带来了持续的改进,在比较模型中实现了最佳性能。
8. 结论
我们利用大量公开可用的语料库,在多种语音应用中对Conformer模型进行了比较研究。具体来说,实验在25个ASR语料库(17个常见数据集+8个低资源数据集)、1个ST语料库、1个SS语料库和3个TTS语料库上进行。实验结果表明,基于Conformer的模型在许多ASR、ST和TTS任务中取得了显著改进,并在SS任务中获得了具有竞争力的结果。我们相信,本文中描述的各种基准测试结果、可复现的配方、训练良好的模型以及训练技巧将加速Conformer在语音应用中的研究。我们希望通过提供这些最新的研究环境,填补大型企业的高资源研究环境与学术界或小型研究团体之间的差距。
论文名称:
RECENT DEVELOPMENTS ON ESPNET TOOLKIT BOOSTED BY CONFORMER
论文地址:
https://arxiv.org/pdf/2010.13956

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 21
21 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)