InstructRAG:基于指令图的检索增强生成在LLM任务规划中的应用
大型语言模型(LLMs)的最新进展使其能够作为智能体用于复杂任务的规划。现有方法通常依赖于思考-行动-观察(TAO)过程来增强LLMs的表现,但这些方法往往受到LLMs对复杂任务有限知识的限制。检索增强生成(RAG)通过利用外部数据库为生成提供依据,提供了新的机会。本文中,我们确定了将RAG应用于任务规划中的两个关键挑战(可扩展性和迁移性)。我们提出了InstructRAG,这是一种在多智能体元强
王征*
华为新加坡研发中心
新加坡
wangzheng155@huawei.com
周俊杰
华为新加坡研发中心
新加坡
chew/jun.jie@huawei.com
摘要
大型语言模型(LLMs)的最新进展使其能够作为智能体用于复杂任务的规划。现有方法通常依赖于思维-行动-观察(TAO)过程来增强LLM性能,但这些方法往往受到LLM对复杂任务知识有限的限制。检索增强生成(RAG)通过利用外部数据库为生成提供依据,提供了新的机会。在本文中,我们确定了将RAG应用于任务规划中的两个关键挑战(可扩展性和可迁移性)。我们提出了InstructRAG,这是一种新颖的解决方案,基于多智能体元强化学习框架来应对这些挑战。InstructRAG包括一个用于组织过去指令路径(正确动作序列)的图、一个使用强化学习扩展图覆盖范围以提高可扩展性的RL-Agent,以及一个使用元学习改进任务泛化以提高可迁移性的ML-Agent。这两个智能体经过端到端训练以优化整体规划性能。我们在四个广泛使用任务规划数据集上的实验表明,InstructRAG显著提升了性能,并能高效适应新任务,相较于最佳现有方法最多提高了19.2%的性能。
CCS 概念
- 信息系统 → 信息检索。
关键词
大型语言模型,检索增强生成,智能体规划
ACM 引用格式:
王征,Teo Shu Xian,Chew Jun Jie,石伟。2025. InstructRAG: 利用指令图上的检索增强生成进行基于LLM的任务规划。在第48届国际ACM SIGIR信息检索研究与发展会议论文集(SIGIR
Teo Shu Xian*
华为新加坡研发中心
新加坡
teo.shu.xian@huawei.com
石伟
华为新加坡研发中心 新加坡 w.shi@huawei.com
∗{ }^{*}∗ 25),7月13日至18日,2025年,帕多瓦,意大利。ACM,纽约,NY,美国,16页。https://doi.org/10.1145/3726302.3730009
1 引言
随着大型语言模型(LLMs)的重大进步,最近出现了一种趋势,即使用LLMs作为智能体来解决各种现实世界的规划任务。这些任务包括多步推理 [38]、具身任务 [24, 25, 34]、网上购物 [39] 和科学推理 [29] 等等。许多近期针对规划问题的解决方案,如ReAct [41]、KnowAgent [42]、WKM [19]、Reflexion [23]、FireAct [3]、NAT [30] 和ETO [27],都遵循思维-行动-观察(TAO)过程。在思维阶段,LLM利用其推理能力创建计划,通过将任务分解为一系列子任务。在行动阶段,LLM确定所需的特定行动,例如选择使用哪个工具。在观察阶段,它捕捉执行行动的结果并从外部环境提供反馈给LLM,从而促进后续TAO步骤的规划。在这个过程中,思维和行动由LLM生成,而观察则由环境实现。现有解决方案采用多种策略,包括提示 [23, 41] 或微调 [3, 19, 27, 30, 42],以改善LLM生成的思维和行动,从而实现更有效的规划。特别是,KnowAgent [42] 将预定义规则整合到提示中,确保生成的思维表现出逻辑性的行动转换。例如,它防止在未先对主题进行搜索操作的情况下查找实体,如HotPotQA [38] 所示。Reflexion [23] 将自我反思总结纳入TAO过程,以指导后续试验。WKM [19] 训练了一个世界知识模型,根据人类解决问题的经验生成思维。
尽管这些现有方法旨在增强LLM规划,但它们往往受限于LLM本身固有的局限性,例如其对复杂任务的知识有限。检索增强生成(RAG)的快速发展为解决这些局限性提供了新的机会,通过利用外部数据库。通过将LLM生成锚定在检索到的信息上,RAG通过在规划过程中集成相关数据来提升性能。在此背景下,我们认识到任务特定性质的信息检索在有效生成规划中起着关键作用。例如,考虑来自HotPotQA的问题“Scott Derrickson和Ed Wood是否具有相同的国籍?”如图1(a)所示。该问题的一个潜在检索计划涉及一系列动作(本文称为指令路径):首先使用Google Search查找关于Scott Derrickson的信息(记为Search[Scott Derrickson]),然后查找包含关键词“国籍”的句子(Lookup[nationality]),接着进行Search[Ed Wood]和Lookup[nationality]。这些指令针对具体问题,并可能根据所涉及的主题或实体而有所不同。类似的现象也可以在ALFWorld具身任务中观察到,其中指令可能包括Goto[shelf 6],然后Take[vase 2 from shelf 6]。
在本文中,我们从两个方面讨论任务特定性质,目标是通过RAG弥合任务特定问题与从存储在数据库中的过去经验中得出的指令之间的差距。(1)可扩展性:这指的是问题落在外部数据库涵盖范围内的任务。具体来说,我们将成功的指令路径预先存储在数据库中,每条路径针对特定任务量身定制。为了应对与这些任务相关的问题,我们探索一种范式,结合指令以扩展数据库的覆盖范围。如图1(a)所示,有两条成功指令路径P11P_{1}^{1}P11和P21P_{2}^{1}P21,分别用于解决Q11Q_{1}^{1}Q11和Q21Q_{2}^{1}Q21问题。这些路径由五个指令组成:搜索(a)Scott Derrickson,(b)Ed Wood,和(c)Christopher Nolan,以及查找与(d)国籍和(e)出生地相关的实体。通过将这些指令按顺序组合,例如(a)→(e)→(c)→(e)(a) \rightarrow(e) \rightarrow(c) \rightarrow(e)(a)→(e)→(c)→(e),我们可以生成一条新的指令路径,用于解决原始路径未涵盖但共享相同任务的新问题(即查询位置的任务)。提出可扩展性以增强数据库应对更广泛问题的能力。(2)可迁移性:这指的是问题超出外部数据库涵盖任务范围的任务。我们注意到,基于LLM的任务规划实际上需要支持广泛的任务。可迁移性对于弥合不同任务(即预建数据库中的任务和当前问题)在RAG系统中的差距至关重要。为此,有必要扩展数据库以纳入不同任务所需的新指令,例如根据开发集更新与新任务相关的指令。此外,与RAG关联的某些可训练模块可以快速适应以容纳新任务。
新解决方案。虽然近期研究努力 [11, 12, 22] 已尝试将RAG技术应用于任务规划,但这些方法在几个方面存在不足:i) [12] 主要针对特定领域,如视频游戏中的决策制定,使得其设计难以推广到本文研究的更广泛的规划任务。ii) [22] 专注于通过搜索引擎进行多跳推理(例如,使用Google搜索访问维基百科知识),但在搜索引擎不适用的任务(如具身任务或网上购物)中的有效性尚未得到探索。iii) [11] 仅依赖于存储过去的经历并通过AKNN检索相似的经历,而没有识别出诸如可扩展性和可迁移性等关键方面。这一差距导致次优性能,正如我们的实验所证明的那样。
为此,我们提出了InstructRAG,一种基于多智能体元强化学习框架的新解决方案。对于(1),我们设计了一个指令图来实例化数据库。在这个图中,节点和边代表两组集合:节点包含相似的指令,而边代表相应的任务,所有这些都源自过去的成功指令路径。这种方法的理由有两个:1) 图提供了一种自然结构来组织路径,并通过聚类与各种任务相关的相似指令来促进新路径的集成。2) 每个节点充当一个连接点,允许通过组合存储在其内部的指令来创建新路径,每个边记录沿路径的任务(及其相关问题)。这种组织使我们能够有效地在数据库中结构化过去的经历。进一步,我们设计了一个RL-Agent,利用强化学习在图上识别候选路径,目标是优化数据库的覆盖范围以增强其可扩展性。对于(2),我们探索将元学习方法引入RAG管道。具体而言,我们引入了一个额外的智能体,称为ML-Agent,它通过元学习从RL-Agent提供的候选路径中选择一条路径。这条选定的路径随后被用作提示中的上下文学习示例,旨在通过在元更新阶段仅使用少量问答对更新LLM来增强其对新任务的泛化能力。这里,两个智能体在TAO过程中协作 [41],通过基于LLM的思想和行动生成来促进任务规划。我们注意到RL-Agent生成供ML-Agent选择的候选路径,而ML-Agent则评估所选路径的整体有效性,并将此反馈作为RL-Agent的奖励。这种交互形成了一个良性循环,从而提升了规划性能。
总之,我们做出了以下贡献。
- 我们对利用RAG进行基于LLM的任务规划进行了系统研究,并确定了潜在技术应具备的两个关键属性(即可扩展性和可迁移性)。据我们所知,这是首次尝试此类研究。
- 我们提出了一个新的解决方案InstructRAG,其中包括三个关键组件:指令图、RL-Agent和ML-Agent。这些组件被集成到一个多智能体元强化学习框架中,明确训练以优化端到端任务规划性能。
- 我们在四个广泛使用的任务规划数据集上进行了广泛的实验:HotpotQA [38]、ALFWorld [25]、Webshop [39] 和ScienceWorld [29],跨越三种典型的LLM。我们的InstructRAG可以与可训练的LLM(如GLM-4 [9])进行微调,也可以与冻结的LLM(如GPT-4o mini [1]和DeepSeekV2 [7])集成。结果表明,InstructRAG在四个数据集上分别比最佳基线方法提高了约19.2%、9.3%、6.1%和10.2%的性能。此外,InstructRAG能够通过少量样本学习快速适应新任务,实现了高效的性能。
2 相关工作
基于LLM的智能体规划。为了解决复杂任务,人类通常将任务分解为较小的子任务,然后评估计划的有效性。类似地,基于LLM的智能体也遵循这一惯例,我们根据智能体在规划过程中是否接收反馈将现有技术分类。可以在 [28, 37] 中找到关于基于LLM的智能体规划的详细调查。在
无反馈规划中,智能体不会接收影响未来动作的反馈。该类别的主要技术包括 (1) 单路径推理 [21, 35],(2) 多路径推理 [2,31,40][2,31,40][2,31,40],以及 (3) 使用外部规划器 [5, 13]。具体来说,对于 (1),CoT [35] 展示了LLM如何使用提示来处理复杂任务的推理步骤,从而引导LLM逐步计划和执行动作。对于 (2),CoT-SC [31] 探索多种推理路径以解决复杂任务。最初,它使用CoT生成多个推理路径及其各自答案。随后,选择频率最高的答案作为最终输出。对于 (3),设计了外部规划器来为特定领域生成计划。例如,LLM+P [13] 通过使用正式的规划域定义语言(PDDL)来定义机器人规划任务。它利用外部规划器,如Fast Downward规划器 [10],该规划器使用启发式搜索来处理PDDL公式。规划器生成的结果随后由LLM转换回自然语言。
在带反馈的规划中,通常通过接收动作后的反馈来提高有效性,这支持长视距规划。这种反馈可以来自 (1) 环境 [3, 41],(2) 人类 [19, 42],和 (3) 模型 [16, 23]。对于 (1),ReAct [41] 提出了 TAO 过程,其中语言模型生成用于规划的思路,行动涉及与环境的互动,观察则包括基于行动的外部反馈(如搜索引擎结果)。FireAct [3] 使用各种方法生成 TAO,然后将其转换为 ReAct 格式以微调小型语言模型。对于 (2),KnowAgent [42] 将动作知识(包括决定动作转换的规则)整合到提示中,以增强 LLM 的规划能力。这种知识来源于人类输入和 GPT-4 [1]。此外,WKM [19] 被引入以使用世界知识模型促进智能体规划。该模型通过比较由人类注释的选择轨迹与由经验丰富的智能体探索的拒绝轨迹进行训练。对于 (3),Reflexion [23] 使用口头反馈来增强智能体基于先前失败的规划。它将自我评估的二进制或标量反馈转化为文本摘要,然后作为附加上下文添加到智能体在后续规划中的提示中。在本文中,我们探讨了一种基于 RAG 的新方法来进行任务规划,重点强调两种关键属性:可扩展性和可迁移性在技术发展中的重要性。
检索增强生成。RAG 通过查询外部数据库获取相关信息来增强 LLM 的生成,从而为后续文本生成提供依据。最近的研究利用 RAG 进行任务规划 [11, 12, 22, 33]。具体来说,RAT [33] 通过迭代修订与任务查询相关的检索信息来增强 CoT,从而提高 LLM 在长视距生成任务中的推理能力。RAP [11] 存储过去的经历,包括情境和动作-观察轨迹,并根据其与当前情况的相似性进行检索。目标是通过利用来自类似任务的记忆示例来推导适当的行动。PlanRAG [12] 针对决策 QA 任务设计,采用先规划后检索的方法。LLM 首先生成一个计划来指导分析,然后通过构建查询从外部数据库中检索信息。它还持续评估重新规划的需求。GenGround [22] 探索了一种先生成后接地的方法来处理多跳推理任务。它将一个复杂问题分解成子问题,为每个子问题生成一个即时答案,然后用检索到的信息对其进行修订。这个修订后的答案告知下一个子问题,直到得出最终答案。在本文中,我们提出在多智能体元强化学习框架内实现 InstructRAG,以系统地解决利用 RAG 应对特定任务问题和存储过往经验之间的差距。
通过上下文学习(ICL)改进LLM的元学习。为了增强LLM对未见任务的可迁移性,已经开发了元学习方法 [4, 6, 18, 26]。这些方法通过对多样化的任务进行微调预训练的LLM,在训练期间通过在提示前附加任务特定示例来格式化为ICL实例。这些方法遵循模型无关元学习(MAML)原则 [8]。具体来说,MAML-en-LLM [26] 探索了广泛的参数空间,以学习真正可泛化的参数,这些参数在离散任务上表现良好,并能有效适应未见任务。MTIL [6] 研究了将元学习应用于多任务指令学习 [32],旨在增强在零样本设置下对未见任务的泛化能力。MetaICL [18] 使LLM能够在广泛的训练任务中进行上下文学习。其目的是通过在测试时条件于少数训练示例而不需参数更新或任务特定模板来提高模型学习新任务的能力。在本文中,我们提出了一种新颖的元强化学习框架以提高可迁移性,其中两个协作智能体专门用于规划任务。这种方法明显不同于该领域的现有方法论。
3 问题陈述
我们通过RAG(基于外部数据库,即指令图)探讨了基于LLM的任务规划问题。在此背景下,我们确定了应满足的两个实际属性:
- 可扩展性:它应该通过遍历图上的现有指令(节点)并将它们组合成新的指令序列(路径)来扩展指令图的范围。这将帮助LLM完成在构建图时没有预定义路径的任务。
- 可迁移性:任务规划作为一种实践中的能力,涉及开发能够快速适应新任务的技术。例如,训练好的模型应能从小量新数据中快速学习新任务。
4 方法论
4.1 InstructRAG概述
提出的InstructRAG通过关注两个关键属性:可扩展性和可迁移性,解决了基于LLM的任务规划面临的挑战。它包括几个组成部分:指令图构建(第4.2节)、RL-Agent(第4.3节)和ML-Agent(第4.4节)。这些部分被集成到一个多智能体元强化学习框架中,详细说明了三个阶段:训练、少量样本学习和测试(第4.5节)。
训练。我们在图1中展示了整体框架。具体来说,训练任务(已见任务)分为支持集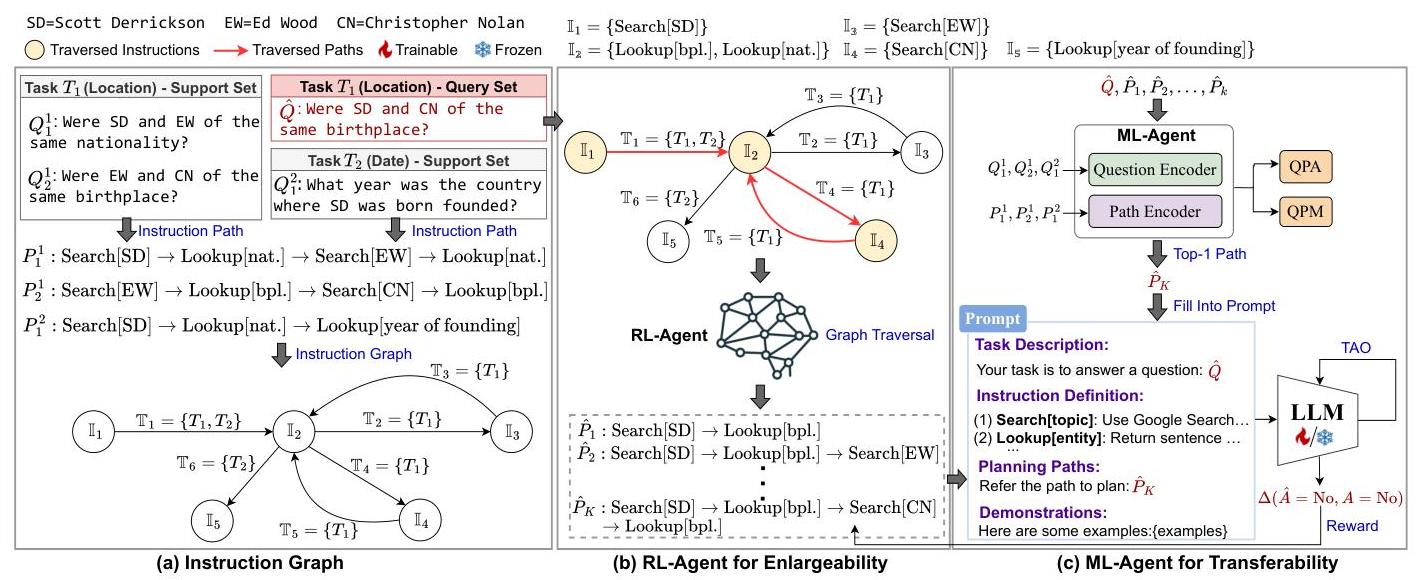
图1:在HotpotQA上展示的带有多智能体元强化学习的InstructRAG架构。
支持集和查询集。对于支持集,用于通过从问题中提取指令路径并基于这些路径构建图来构造指令图。此外,路径和相应的问题有助于RL-Agent的预热启动,并通过两项预训练任务:问题路径对齐(QPA)和问题路径匹配(QPM)对ML-Agent进行预训练。对于查询集,用于查询图并在多智能体框架内训练RL-Agent和ML-Agent。RL-Agent通过图遍历找到候选路径,这被建模为马尔可夫决策过程(MDP),并使用强化学习进行优化。RL-Agent被训练以处理在构建图时未见过的问题,通过组合指令形成路径来解决这些问题,从而扩大指令图的能力。然后,ML-Agent根据候选路径的表示从中选择最相关的路径,该路径用于构建提示,以便LLM预测最终答案,遵循TAO过程。我们注意到,通过上下文学习方式考虑可迁移性,其中LLM通过条件于提示中的任务特定路径来学习新任务。ML-Agent通过元学习优化此过程,无论是使用可训练还是冻结的LLM。
少量样本学习和测试。一旦RL-Agent和ML-Agent的参数经过元训练,我们使用少量样本集上的支持集快速调整模型参数以适应测试任务(未见任务)。然后基于这些测试任务的查询集进行测试。
4.2 指令图
指令。指令 III 表示由LLM执行的具体动作,例如,Search[Scott Derrickson] 是一条指令,意味着使用Google搜索查找有关Scott Derrickson的相关信息,如图1(a)所示。
指令路径。指令路径 PiI=⟨I1,I2,…,I∣P∣⟩P_{i}^{I}=\left\langle I_{1}, I_{2}, \ldots, I_{|P|}\right\ranglePiI=⟨I1,I2,…,I∣P∣⟩ 表示LLM按照步骤执行动作以完成第jjj个任务的第iii个问题的指令序列,
例如,P12P_{1}^{2}P12 : Search[Scott Derrickson] →\rightarrow→ Lookup[nationality] →\rightarrow→ Lookup[year of founding] 表示解决任务T2T_{2}T2的问题Q12Q_{1}^{2}Q12的指令路径,如图1(a)所示。
指令图。指令图 G(∀,E)G(\forall, \mathbb{E})G(∀,E) 表示为一个有向图,用于组织属于各种任务的问题的指令路径,其中∀\forall∀和E\mathbb{E}E分别代表图中的节点和边。每个节点I∈V\mathbb{I} \in \mathbb{V}I∈V表示一组指令,即I={I1,I2,…,I∣I∣}\mathbb{I}=\left\{I_{1}, I_{2}, \ldots, I_{|\mathbb{I}|}\right\}I={I1,I2,…,I∣I∣},聚集相似的指令。每条边T∈E\mathbb{T} \in \mathbb{E}T∈E表示一组任务,即T={T1,T2,…,T∣T∣}\mathbb{T}=\left\{T_{1}, T_{2}, \ldots, T_{|\mathbb{T}|}\right\}T={T1,T2,…,T∣T∣},记录路径上涉及的任务及其相关问题。
图表构建与见解。我们分两个步骤介绍图表构建过程,如图1(a)所示的例子。详细过程见算法1。
步骤1(生成指令路径):我们将数据集分为两部分:支持集和查询集,遵循元学习设置。支持集用于图表构建,而查询集用于查询图表以训练可扩展性和可迁移性,将在第4.3节和第4.4节中分别讨论。对于支持集中的每个问题,我们使用现有的任务规划技术[23, 41, 42]生成其指令路径。我们选择能够正确规划问题的路径进行构建,确保规划基于准备好的数据库,与RAG的目标一致。
步骤2(插入阈值为δ\deltaδ的指令):然后,我们迭代地将生成路径中的每个指令,即P11,P21,P32P_{1}^{1}, P_{2}^{1}, P_{3}^{2}P11,P21,P32,插入到图GGG中。P11P_{1}^{1}P11的前两个指令初始化为创建两个节点集,即I1←\mathbb{I}_{1} \leftarrowI1← Search[Scott Derrickson]和I2←\mathbb{I}_{2} \leftarrowI2← Lookup[nationality],对应于记录涉及任务{T1}\left\{T_{1}\right\}{T1}的边集T1\mathbb{T}_{1}T1。这里需要注意的是,相邻指令不应插入到同一个节点中,因为这会破坏它们之间的过渡。为了插入下一个指令Search[Ed Wood],我们对除其相邻节点中的指令外的所有指令进行AKNN搜索[17](即,Lookup[nationality] ∈I2\in \mathbb{I}_{2}∈I2),识别出最相似的指令Search[Scott Derrickson],其与节点集I1\mathbb{I}_{1}I1中的相似度值(例如余弦相似度)为ψ\psiψ。然后,我们定义一个阈值δ\deltaδ来控制插入。如果ψ<δ\psi<\deltaψ<δ,则创建一个新的节点集I3\mathbb{I}_{3}I3并将该指令插入到这个新节点中,即I3←Search[\mathbb{I}_{3} \leftarrow \operatorname{Search}[I3←Search[ Ed Wood];否则,将该指令插入到识别出的节点I1\mathbb{I}_{1}I1中。这个过程继续进行,直到所有指令都被插入。此外,我们注意到当指令Lookup[nationality]的P12P_{1}^{2}P12被插入到I2\mathbb{I}_{2}I2中(余弦相似度为1.0),任务T2T_{2}T2也被添加到边集T1\mathbb{T}_{1}T1中,结果为{T1,T2}\left\{T_{1}, T_{2}\right\}{T1,T2}。
我们提出了两个关于图形构建的关键见解:(1) 图形自然地组织指令路径,其中节点和边被表示为集合,以实现跨任务灵活整合相似指令。(2) 阈值控制指令相似性,形成交叉节点,从而创建超出原始数据的新路径。例如,将Lookup[nationality]和Lookup[birthplace]合并到I2\mathbb{I}_{2}I2中,可以启用类似I1→I2→\mathbb{I}_{1} \rightarrow \mathbb{I}_{2} \rightarrowI1→I2→ I4→I2\mathbb{I}_{4} \rightarrow \mathbb{I}_{2}I4→I2的新路径,从而提高图的可扩展性以覆盖更多问题(例如,图1(a)中的Q^\hat{Q}Q^)。
算法 1: 指令图构建
输入: 支持集(S)(\mathbb{S})(S); 阈值(δ)(\delta)(δ)
(IC←3,TC←2//)(I C \leftarrow 3, T C \leftarrow 2 / /)(IC←3,TC←2//) 两个计数器分别用于节点和边集
对于每个(Tj∈S(1≤j≤∣S∣))(T_{j} \in \mathbb{S}(1 \leq j \leq|\mathbb{S}|))(Tj∈S(1≤j≤∣S∣)) do
对于每个(QjI∈Tj(1≤i≤∣Tj∣))(Q_{j}^{I} \in T_{j}\left(1 \leq i \leq\left|T_{j}\right|\right))(QjI∈Tj(1≤i≤∣Tj∣)) do
获取一个正确的(PiI=⟨I1,I2,…,I∣PiI∣⟩)(P_{i}^{I}=\left\langle I_{1}, I_{2}, \ldots, I_{|P_{i}^{I}|}\right\rangle)(PiI=⟨I1,I2,…,I∣PiI∣⟩)用于(QiI)(Q_{i}^{I})(QiI)
(I′←0//)(\mathbb{I}^{\prime} \leftarrow \mathbf{0} / /)(I′←0//) 记录最后一个节点集
对于(k=1,2,…,∣PiI∣)(k=1,2, \ldots,|P_{i}^{I}|)(k=1,2,…,∣PiI∣) do
如果(i=1)(i=1)(i=1)且(j=1)(j=1)(j=1)且(k<3)(k<3)(k<3)则
(I1⋅add(I1),I2⋅add(I2),T1←Edge(I1,I2))(\mathbb{I}_{1} \cdot \operatorname{add}\left(I_{1}\right), \mathbb{I}_{2} \cdot \operatorname{add}\left(I_{2}\right), \mathbb{T}_{1} \leftarrow \operatorname{Edge}\left(\mathbb{I}_{1}, \mathbb{I}_{2}\right))(I1⋅add(I1),I2⋅add(I2),T1←Edge(I1,I2))
(T1⋅add(T1),G⋅addEdge(T1),I′←I2)(\mathbb{T}_{1} \cdot \operatorname{add}\left(T_{1}\right), G \cdot \operatorname{addEdge}\left(\mathbb{T}_{1}\right), \mathbb{I}^{\prime} \leftarrow \mathbb{I}_{2})(T1⋅add(T1),G⋅addEdge(T1),I′←I2)
继续
回忆 (In)(\mathbb{I}_{n})(In) 和 (ψ)(\psi)(ψ) 对于 (Ik)(I_{k})(Ik) 使用 AKNN 在 (G⋅V−I′)(G \cdot \mathbb{V}-\mathbb{I}^{\prime})(G⋅V−I′) 上
如果 (ψ<δ)(\psi<\delta)(ψ<δ) 则
(IIC⋅add(Ik),TTC←Edge(I′,IIC))(\mathbb{I}_{I C} \cdot \operatorname{add}\left(I_{k}\right), \mathbb{T}_{T C} \leftarrow \operatorname{Edge}\left(\mathbb{I}^{\prime}, \mathbb{I}_{I C}\right))(IIC⋅add(Ik),TTC←Edge(I′,IIC))
(TTC⋅add(Tj),G⋅addEdge(TTC))(\mathbb{T}_{T C} \cdot \operatorname{add}\left(T_{j}\right), G \cdot \operatorname{addEdge}\left(\mathbb{T}_{T C}\right))(TTC⋅add(Tj),G⋅addEdge(TTC))
(I′←IIC,IC←IC+1,TC←TC+1)(\mathbb{I}^{\prime} \leftarrow \mathbb{I}_{I C}, I C \leftarrow I C+1, T C \leftarrow T C+1)(I′←IIC,IC←IC+1,TC←TC+1)
否则
(In⋅add(Ik))(\mathbb{I}_{n} \cdot \operatorname{add}\left(I_{k}\right))(In⋅add(Ik))
如果 (Edge(I′,In)∈G)(\operatorname{Edge}\left(\mathbb{I}^{\prime}, \mathbb{I}_{n}\right) \in G)(Edge(I′,In)∈G) 则
获取边 ((I′,In))(\left(\mathbb{I}^{\prime}, \mathbb{I}_{n}\right))((I′,In)) 表示为 (I′)(\mathbb{I}^{\prime})(I′)
(T′⋅add(Tj))(\mathbb{T}^{\prime} \cdot \operatorname{add}\left(T_{j}\right))(T′⋅add(Tj))
否则
(TTC←Edge(I′,In),TTC⋅add(Tj))(\mathbb{T}_{T C} \leftarrow \operatorname{Edge}\left(\mathbb{I}^{\prime}, \mathbb{I}_{n}\right), \mathbb{T}_{T C} \cdot \operatorname{add}\left(T_{j}\right))(TTC←Edge(I′,In),TTC⋅add(Tj))
(G⋅addEdge(TTC),TC←TC+1)(G \cdot \operatorname{addEdge}\left(\mathbb{T}_{T C}\right), T C \leftarrow T C+1)(G⋅addEdge(TTC),TC←TC+1)
(I′←In)(\mathbb{I}^{\prime} \leftarrow \mathbb{I}_{n})(I′←In)
25 返回指令图 GGG
4.3 RL-Agent:在指令图上检索指令路径
给定一个指令图 GGG,我们通过图遍历来探索其可扩展性,以检索解决不在构建时存在的问题(即查询集中的问题)的各种指令路径。为了实现这一点,我们训练一个代理进行遍历,它检查图中的每条路径,例如通过深度优先搜索
(DFS)。对于每个节点,代理根据节点中的指令和由其边连接的任务(即状态)决定是否在路径中包含或排除该节点(即动作)。高质量的检索路径有利于后续规划,反映在一个端到端指标上,如HotPotQA [38] 的F1分数(即奖励),然后可以指导指令选择。此过程构成一个马尔可夫决策过程 (MDP),我们使用强化学习 (RL) 来优化它。
构建决策环境。指令图 GGG 通常包含大量通过组合每个节点的不同指令形成的指令路径。为了管理这一点,我们将RL-Agent的检索限制为 KKK 条相关的指令路径,记为 P^1,P^2,…,P^K\hat{P}_{1}, \hat{P}_{2}, \ldots, \hat{P}_{K}P^1,P^2,…,P^K,这些路径随后在下一阶段由ML-Agent(将在第4.4节中介绍)用于规划,其中 KKK 是一个可以通过调整以达到最佳性能的超参数。我们首先对所有指令进行一次AKNN搜索以查询 Q^\hat{Q}Q^。代理的遍历从最相似的指令(对应于节点)开始使用DFS。一旦代理排除一个节点并回溯到另一分支,就形成了一条指令路径。此过程继续进行,直到检索到 KKK 条路径。
状态。假设我们有一个输入问题 Q^\hat{Q}Q^ 并访问一个节点 I\mathbb{I}I(一组指令),以及它的入度边 T\mathbb{T}T(一组任务)。我们使用三个余弦相似度 CS(⋅,⋅)C S(\cdot, \cdot)CS(⋅,⋅) 定义状态 s\mathbf{s}s,即
s=(maxIi∈ICS(vQ^,vIi),maxTj∈TCS(vQ^,vTj),maxQkIi∈TcCS(vQ^,vQkIi)),vTj=1∣Tj∣∑k=1∣Tj∣vQkI and c=argmaxTc∈TCS(vQ^,vTc), \begin{aligned} & \mathbf{s}=\left(\max _{I_{i} \in \mathbb{I}} C S\left(\mathbf{v}_{\hat{Q}}, \mathbf{v}_{I_{i}}\right), \max _{T_{j} \in \mathbb{T}} C S\left(\mathbf{v}_{\hat{Q}}, \mathbf{v}_{T_{j}}\right), \max _{Q_{k}^{I_{i}} \in T_{c}} C S\left(\mathbf{v}_{\hat{Q}}, \mathbf{v}_{Q_{k}^{I_{i}}}\right)\right), \\ & \mathbf{v}_{T_{j}}=\frac{1}{\left|T_{j}\right|} \sum_{k=1}^{\left|T_{j}\right|} \mathbf{v}_{Q_{k}^{I}} \text { and } c=\underset{T_{c} \in \mathbb{T}}{\arg \max } C S\left(\mathbf{v}_{\hat{Q}}, \mathbf{v}_{T_{c}}\right), \end{aligned} s=(Ii∈ImaxCS(vQ^,vIi),Tj∈TmaxCS(vQ^,vTj),QkIi∈TcmaxCS(vQ^,vQkIi)),vTj=∣Tj∣1k=1∑∣Tj∣vQkI and c=Tc∈TargmaxCS(vQ^,vTc),
其中 v\mathbf{v}v. 表示嵌入向量。我们通过以下方式构建状态:(1) 查找节点中最相似的指令,(2) 识别边缘中最相似的任务,记为 TcT_{c}Tc(其嵌入计算为属于该任务的问题嵌入的平均值),(3) 查找 TcT_{c}Tc 内最相似的问题。
动作。设 aaa 表示一个动作,在图遍历中有两个选择:通过选择最相似的指令将其加入路径 P^i(1≤i≤K)\hat{P}_{i}(1 \leq i \leq K)P^i(1≤i≤K) 并搜索其相连节点,或者排除该节点并从另一个分支回溯搜索,从而形成一条指令路径。动作 aaa 正式定义为:
a=1 (包含) or 0 (排除) a=1 \text { (包含) or } 0 \text { (排除) } a=1 (包含) or 0 (排除)
考虑到执行动作的后果,它将环境转移到下一个状态 s′\mathbf{s}^{\prime}s′,影响用于构建状态的节点或边。值得注意的是,可以进一步纳入一些预定义规则以约束动作空间(例如,在HotpotQA [42]中避免在未先执行搜索的情况下查找信息的规则),这有助于更准确地选择路径。
奖励。设 rrr 表示奖励,它对应于一条指令路径对LLM生成的答案 A^\hat{A}A^ 的端到端反馈。具体来说,当ML-Agent从 KKK 条路径中选择一条路径并将其写入提示中时,LLM生成答案 A^\hat{A}A^。可以使用特定度量 Δ(⋅,⋅)\Delta(\cdot, \cdot)Δ(⋅,⋅)(例如F1分数)评估该答案,定义为:
r=Δ(A^,A) r=\Delta(\hat{A}, A) r=Δ(A^,A)
其中 AAA 表示真实答案。设计奖励的原理是为了在多代理环境中实现联合优化,其中RL-Agent提供路径供ML-Agent写入提示,提示的反馈影响RL-Agent的路径检索。因此,两个代理可以联合优化以提高整体性能。
策略学习。我们涉及两个阶段来训练MDP策略:预热启动(WS)和策略梯度(PG)。在WS中,目标是赋予代理基本的包含或排除指令的能力。为了实现这一点,我们从支持集中随机抽样问题。对于每个问题,我们在 GGG 上随机抽样节点并使用方程1构建其状态。如果节点位于该问题的指令路径上,则该状态与标记为1的动作相关联;否则,标记为0。我们收集这些状态-动作对,并使用二元交叉熵训练RL-Agent:
LWS=−y∗log(P)+(y−1)∗log(1−P) \mathcal{L}_{\mathrm{WS}}=-y * \log (P)+(y-1) * \log (1-P) LWS=−y∗log(P)+(y−1)∗log(1−P)
其中 yyy 表示标签,PPP 是正类的预测概率。在PG中,主要目标是开发一个策略 πθ(a∣s)\pi_{\theta}(a \mid \mathbf{s})πθ(a∣s),以指导代理根据给定的状态 s\mathbf{s}s 对查询集中的问题执行动作 aaa,目标是最大化累积奖励 RRR。我们使用REINFORCE算法 [36] 学习此策略,其中 θ\thetaθ 表示RL-Agent的参数。损失函数定义为:
LPG=−Rlnπθ(a∣s) \mathcal{L}_{\mathrm{PG}}=-R \ln \pi_{\theta}(a \mid \mathbf{s}) LPG=−Rlnπθ(a∣s)
4.4 ML-Agent:为规划生成提示
在ML-Agent中,由RL-Agent识别的最相关路径被选择并集成到LLM的提示中。我们使用元学习(ML)通过ML-Agent管理可迁移性。理由是代理被训练为通过前置示例规划路径构建提示作为上下文学习(ICL)实例,这可以通过仅更新少量示例来潜在地提高LLM对新任务的泛化能力,如在[18,26][18,26][18,26]中所证明的那样。下面,我们讨论ML-Agent的模型架构和训练细节。
模型架构。如图1©所示,我们的ML-Agent使用[20]中的文本编码器结构作为问题编码器和路径编码器。它使用两个具有共享自注意力层的变压器模块捕获潜在特征。我们将指令路径和问题视为以[EOS]标记结束的两个文本序列,并从最高变压器层在这些[EOS]标记处的激活中派生它们的特征表示。ML-Agent被训练为对齐问题和指令路径表示,并基于这些表示的余弦相似性检索最相关的路径。值得注意的是,模型不使用路径选择的KKK-分类器,确保架构独立于KKK超参数且无需在调整KKK时重新训练。
ML-Agent 训练。ML-Agent 训练包括两个阶段:预训练(PT)和微调(FT)。在 PT 中,我们使用两个预训练任务优化代理:问题路径对齐(QPA)和
问题路径匹配(QPM)。对于 QPA,目标是通过对比方法将问题和路径表示对齐,即将相似对拉近并推动不相似对远离。具体来说,我们从支持集中采样一批问题-路径对(例如,图 1 中的 Q1IQ_{1}^{I}Q1I 和 P1IP_{1}^{I}P1I)。对于每对,记为 <QiI,PiI><Q_{i}^{I}, P_{i}^{I}><QiI,PiI>,其中 QiI∈QQ_{i}^{I} \in QQiI∈Q 和 PiI∈PP_{i}^{I} \in \mathcal{P}PiI∈P,我们通过两个编码器获得它们的嵌入向量 vi,jQ\mathbf{v}_{i, j}^{Q}vi,jQ 和 vi,jP\mathbf{v}_{i, j}^{P}vi,jP。我们将 vi,jP\mathbf{v}_{i, j}^{P}vi,jP 视为 vi,jQ\mathbf{v}_{i, j}^{Q}vi,jQ(锚点)的正例,因为 QiIQ_{i}^{I}QiI 和 PiIP_{i}^{I}PiI 是配对的,而批次中的其他路径被视为负例。对比损失,记为LQ,P\mathcal{L}_{Q, P}LQ,P,通过比较正例和负例来鼓励路径与锚问题对齐,即
LQ,P=∑QiI∈Q−logexp(vi,jQ⋅vi,jP/τ)∑Pi′I′∈P,i′≠i,j′≠jexp(vi,jQ⋅vi′,j′P/τ) \mathcal{L}_{Q, P}=\sum_{Q_{i}^{I} \in Q}-\log \frac{\exp \left(\mathbf{v}_{i, j}^{Q} \cdot \mathbf{v}_{i, j}^{P} / \tau\right)}{\sum_{P_{i^{\prime}}^{I^{\prime}} \in \mathcal{P}, i^{\prime} \neq i, j^{\prime} \neq j} \exp \left(\mathbf{v}_{i, j}^{Q} \cdot \mathbf{v}_{i^{\prime}, j^{\prime}}^{P} / \tau\right)} LQ,P=QiI∈Q∑−log∑Pi′I′∈P,i′=i,j′=jexp(vi,jQ⋅vi′,j′P/τ)exp(vi,jQ⋅vi,jP/τ)
其中 τ\tauτ 表示温度参数。对称地,我们可以基于 vi,jP\mathbf{v}_{i, j}^{P}vi,jP 定义 LP,Q\mathcal{L}_{P, Q}LP,Q。总体损失 LQPA\mathcal{L}_{\mathrm{QPA}}LQPA 则定义为:
LQPA=(LQ,P+LP,Q)/2 \mathcal{L}_{\mathrm{QPA}}=\left(\mathcal{L}_{Q, P}+\mathcal{L}_{P, Q}\right) / 2 LQPA=(LQ,P+LP,Q)/2
对于 QPM,我们通过二元分类任务将问题与路径对齐。模型预测问题-路径对是否匹配(标记为1)或不匹配(标记为0)。训练目标使用二元交叉熵损失,定义如下:
LQPM=−y∗log(P)+(y−1)∗log(1−P) \mathcal{L}_{\mathrm{QPM}}=-y * \log (P)+(y-1) * \log (1-P) LQPM=−y∗log(P)+(y−1)∗log(1−P)
其中 yyy 表示标签,PPP 表示正类的预测概率。最后,ML-Agent 使用多任务学习方法进行训练,损失函数 LPT\mathcal{L}_{\mathrm{PT}}LPT 定义为:
LPT=LQPA+LQPM \mathcal{L}_{\mathrm{PT}}=\mathcal{L}_{\mathrm{QPA}}+\mathcal{L}_{\mathrm{QPM}} LPT=LQPA+LQPM
在 PT 中,我们进一步使用查询集中的问题对模型进行微调。具体来说,对于每个问题 Q^∈Q^\hat{Q} \in \hat{Q}Q^∈Q^,我们使用 RL-Agent 检索 KKK 条路径。我们采用硬负样本挖掘策略,其中检索到的 KKK 条路径被视为问题 Q^\hat{Q}Q^ 的硬负样本。此外,我们从其他问题中采样路径并将它们添加到 KKK 条路径中,形成一个路径池,记为 P^\hat{P}P^。然后通过比较每条路径在 P^\hat{P}P^ 中生成的答案 A^\hat{A}A^ 与真实答案 AAA 来评估性能。基于特定度量 Δ(A^,A)\Delta(\hat{A}, A)Δ(A^,A),最佳路径记为 P^\hat{P}P^ 并作为 Q^\hat{Q}Q^ 的正例,而池中的其他路径被视为负例。微调阶段的损失函数 LPT\mathcal{L}_{\mathrm{PT}}LPT 定义为:
LFT=(LQ,P′+LP,Q′)/2LQ,P′=∑Q^∈Q^−logexp(vQ^⋅vP^/τ)∑P^∈P^,P^≠P^exp(vQ^⋅vP^/τ) \begin{aligned} & \mathcal{L}_{\mathrm{FT}}=\left(\mathcal{L}_{Q, P}^{\prime}+\mathcal{L}_{P, Q}^{\prime}\right) / 2 \\ & \mathcal{L}_{Q, P}^{\prime}=\sum_{\hat{Q} \in \hat{Q}}-\log \frac{\exp \left(\mathbf{v}^{\hat{Q}} \cdot \mathbf{v}^{\hat{P}} / \tau\right)}{\sum_{\hat{P} \in \hat{P}, \hat{P} \neq \hat{P}} \exp \left(\mathbf{v}^{\hat{Q}} \cdot \mathbf{v}^{\hat{P}} / \tau\right)} \end{aligned} LFT=(LQ,P′+LP,Q′)/2LQ,P′=Q^∈Q^∑−log∑P^∈P^,P^=P^exp(vQ^⋅vP^/τ)exp(vQ^⋅vP^/τ)
其中 vQ^\mathbf{v}^{\hat{Q}}vQ^ 和 vP^\mathbf{v}^{\hat{P}}vP^ 分别表示 Q^\hat{Q}Q^ 和 P^\hat{P}P^ 的嵌入向量。LP,Q′\mathcal{L}_{P, Q}^{\prime}LP,Q′ 是基于 LQ,P′\mathcal{L}_{Q, P}^{\prime}LQ,P′ 的对称定义。
LLM生成的提示结构。由ML-Agent返回的路径 P^\hat{P}P^ 用于构建引导LLM生成答案(记为 A^\hat{A}A^)的提示。我们的提示由四个部分组成,如图1©所示。(1) 任务描述:这部分介绍任务,详细说明要解决的具体问题 Q^\hat{Q}Q^。(2) 指令定义:这部分提供每个指令的定义,例如Search[topic]或Lookup[entity]。(3) 规划路径:集成路径 P^\hat{P}P^ 创建结构化计划,指导LLM通过逐步行动解决 Q^\hat{Q}Q^。(4) 示例:提供规划路径的示例,为LLM提供参考和上下文。此外,InstructRAG框架支持与可训练LLM(例如,根据[42]使用真实路径微调GLM-4 [9])以及冻结LLM(例如,GPT-4o mini [1]和DeepSeek-V2 [7])集成,以利用其固有的规划能力。
算法 2: InstructRAG - 训练阶段
输入 : 训练支持集 (S;)(\mathbb{S} ;)(S;) 训练查询集 (Q)(\mathbb{Q})(Q)
随机初始化RL-Agent的 (θ)(\theta)(θ) 和ML-Agent的 (η)(\eta)(η)
使用算法1通过 (S)(\mathbb{S})(S) 构建指令图 (G)(G)(G)
当未完成时执行以下操作:
从 (T)(\mathcal{T})(T) 中采样一批任务
对于每个 (Ti∈T(1≤i≤∣T∣)(T_{i} \in \mathcal{T}(1 \leq i \leq|\mathcal{T}|)(Ti∈T(1≤i≤∣T∣) 执行以下操作:
根据等式4相对于 (B)(\mathcal{B})(B) 问题计算 (∇θLWSTi(RL−Agentθ))(\nabla_{\theta} \mathcal{L}_{\mathrm{WS}}^{T_{i}}\left(\mathrm{RL}^{-} \mathrm{Agent}_{\theta}\right))(∇θLWSTi(RL−Agentθ)) 对于 (S)(\mathbb{S})(S) 中的 (Ti)(T_{i})(Ti)
计算适应后的 (θi′←θ−α∇θLWSTi(RL−Agentθ))(\theta_{i}^{\prime} \leftarrow \theta-\alpha \nabla_{\theta} \mathcal{L}_{\mathrm{WS}}^{T_{i}}\left(\mathrm{RL}^{-} \mathrm{Agent}_{\theta}\right))(θi′←θ−α∇θLWSTi(RL−Agentθ))
根据等式9相对于 (B)(\mathcal{B})(B) 问题计算 (∇θLP∣′(ML−Agentη))(\nabla_{\theta} \mathcal{L}_{\mathrm{P} \mid}^{\prime}\left(\mathrm{ML}^{-} \mathrm{Agent}_{\eta}\right))(∇θLP∣′(ML−Agentη)) 对于 (S)(\mathbb{S})(S) 中的 (Ti)(T_{i})(Ti)
计算适应后的 (ηi′←η−α∇θLP∣′(ML−Agentη))(\eta_{i}^{\prime} \leftarrow \eta-\alpha \nabla_{\theta} \mathcal{L}_{\mathrm{P} \mid}^{\prime}\left(\mathrm{ML}^{-} \mathrm{Agent}_{\eta}\right))(ηi′←η−α∇θLP∣′(ML−Agentη))
更新 (θ←θ−β∇θ∑TiLP∣′(RL−Agentθi′))(\theta \leftarrow \theta-\beta \nabla_{\theta} \sum_{T_{i}} \mathcal{L}_{\mathrm{P} \mid}^{\prime}\left(\mathrm{RL}^{-} \mathrm{Agent}_{\theta_{i}^{\prime}}\right))(θ←θ−β∇θ∑TiLP∣′(RL−Agentθi′)) 根据等式5相对于所有采样任务的问题在 (Q)(\mathbb{Q})(Q) 中
更新 (η←η−β∇η∑TiLP∣′(ML−Agentηi′))(\eta \leftarrow \eta-\beta \nabla_{\eta} \sum_{T_{i}} \mathcal{L}_{\mathrm{P} \mid}^{\prime}\left(\mathrm{ML}^{-} \mathrm{Agent}_{\eta_{i}^{\prime}}\right))(η←η−β∇η∑TiLP∣′(ML−Agentηi′)) 根据等式10相对于所有采样任务的问题在 (Q)(\mathbb{Q})(Q) 中
返回训练后的RL-Agent (θ)(_{\theta})(θ) 和 ML-Agent (η)(_{\eta})(η)
算法 3: InstructRAG - 少样本学习阶段
输入 : 测试支持集 (S′;)(\mathbb{S}^{\prime} ;)(S′;) RL-Agent (θ;)(_{\theta} ;)(θ;) ML-Agent (η)(_{\eta})(η)
使用算法1将 (S′)(\mathbb{S}^{\prime})(S′) 插入 (G)(G)(G),并获得 (G′)(G^{\prime})(G′)
对于每个 (Ti∈S′(1≤i≤∣S′∣))(T_{i} \in \mathbb{S}^{\prime}\left(1 \leq i \leq\left|\mathbb{S}^{\prime}\right|\right))(Ti∈S′(1≤i≤∣S′∣)) 执行以下操作:
(θi′←θ−α∇θLWSTi(RL−Agentθ)−β∇θLP∣′(RL−Agentθ))(\theta_{i}^{\prime} \leftarrow \theta-\alpha \nabla_{\theta} \mathcal{L}_{\mathrm{WS}}^{T_{i}}\left(\mathrm{RL}^{-} \mathrm{Agent}_{\theta}\right)-\beta \nabla_{\theta} \mathcal{L}_{\mathrm{P} \mid}^{\prime}\left(\mathrm{RL}^{-} \mathrm{Agent}_{\theta}\right))(θi′←θ−α∇θLWSTi(RL−Agentθ)−β∇θLP∣′(RL−Agentθ)) 根据等式4和等式5相对于 (B)(\mathcal{B})(B) 问题对于 (Ti)(T_{i})(Ti) 在 (S′)(\mathbb{S}^{\prime})(S′) 中
(ηi′←η−α∇ηLP∣′(ML−Agentη)−β∇ηLP∣′(ML−Agentη))(\eta_{i}^{\prime} \leftarrow \eta-\alpha \nabla_{\eta} \mathcal{L}_{\mathrm{P} \mid}^{\prime}\left(\mathrm{ML}^{-} \mathrm{Agent}_{\eta}\right)-\beta \nabla_{\eta} \mathcal{L}_{\mathrm{P} \mid}^{\prime}\left(\mathrm{ML}^{-} \mathrm{Agent}_{\eta}\right))(ηi′←η−α∇ηLP∣′(ML−Agentη)−β∇ηLP∣′(ML−Agentη)) 根据等式9和等式10相对于 (B)(\mathcal{B})(B) 问题对于 (Ti)(T_{i})(Ti) 在 (S′)(\mathbb{S}^{\prime})(S′) 中
返回针对每个任务调整后的RL-Agent (θi′)(_{\theta_{i}^{\prime}})(θi′) 和 ML-Agent (ηi′)(_{\eta_{i}^{\prime}})(ηi′)
算法 4: InstructRAG - 测试阶段
输入 : 测试查询集 (Q′;)(\mathbb{Q}^{\prime} ;)(Q′;) RL-Agent (θi′;)(_{\theta_{i}^{\prime}} ;)(θi′;) ML-Agent (ηi′)(_{\eta_{i}^{\prime}})(ηi′)
对于每个 (Ti∈Q′(1≤i≤∣Q′∣))(T_{i} \in \mathbb{Q}^{\prime}\left(1 \leq i \leq\left|\mathbb{Q}^{\prime}\right|\right))(Ti∈Q′(1≤i≤∣Q′∣)) 执行以下操作:
运行 RL-Agent (θi′)(_{\theta_{i}^{\prime}})(θi′) 和 ML-Agent (ηi′)(_{\eta_{i}^{\prime}})(ηi′) 处理 (Ti)(T_{i})(Ti) 中的问题
使用度量 (Δ(⋅,⋅))(\Delta(\cdot, \cdot))(Δ(⋅,⋅)) 评估有效性
返回所有任务的平均有效性
4.5 InstructRAG框架
我们在三个阶段展示了InstructRAG框架:(1)训练阶段,(2)少样本学习阶段,和(3)测试阶段。在(1)中,框架采用元学习方法[8],使用来自已见任务的支持集和查询集协作训练两个代理。在(2)中,使用少样本例子快速调整代理参数以适应未见任务。在(3)中,使用查询集评估这些未见任务上的适应效果。
训练阶段。如算法2所示,该过程输入来自已见训练任务的支持集和查询集,并输出训练后的RL-Agent和ML-Agent。支持集用于按照算法1的详细步骤构建指令图 GGG。然后迭代训练两个代理。在每次迭代中,RL-Agent和ML-Agent分别表示为RL-Agent θ{ }_{\theta}θ 和ML-Agent η{ }_{\eta}η,参数分别为 θ\thetaθ 和 η\etaη。当适应新任务 TiT_{i}Ti 时,参数 θ\thetaθ 和 η\etaη 使用支持集(α\alphaα 表示学习率)根据等式4和9更新为 θ′\theta^{\prime}θ′ 和 η′\eta^{\prime}η′。使用 B\mathcal{B}B 个问题进行一到多次梯度下降更新后快速计算更新后的参数。随后,通过改进RL-Agent θi′{ }_{\theta_{i}^{\prime}}θi′ 的性能(使用等式5)和ML-Agent ηi′{ }_{\eta_{i}^{\prime}}ηi′ 的性能(使用等式10),分别针对查询集中的采样任务优化模型参数(β\betaβ 表示学习率)。我们的训练方法旨在优化两个代理,使得在新任务上只需少量梯度步骤即可产生最有效的行为。
少样本学习阶段。如算法3所示,该过程将训练后的RL-Agent θ{ }_{\theta}θ 和ML-Agent η{ }_{\eta}η 调整为针对每个任务 TiT_{i}Ti 的单独模型,分别记为RL-Agent θi′{ }_{\theta_{i}^{\prime}}θi′ 和ML-Agent ηi′{ }_{\eta_{i}^{\prime}}ηi′。这种调整涉及使用算法1在测试支持集 S′\mathcal{S}^{\prime}S′ 上扩展图 GGG 至 G′G^{\prime}G′。对于每个任务,使用来自 S′\mathcal{S}^{\prime}S′ 的少样本问题执行梯度下降以适应RL-Agent θ{ }_{\theta}θ(根据等式4和5)和ML-Agent η{ }_{\eta}η(根据等式9和10)。
测试阶段。如算法4所示,每个任务 TiT_{i}Ti 使用相应的调整模型(RL-Agent θi′{ }_{\theta_{i}^{\prime}}θi′ 和ML-Agent ηi′{ }_{\eta_{i}^{\prime}}ηi′)在测试查询集 Q′\boldsymbol{Q}^{\prime}Q′ 上执行。使用特定度量 Δ(⋅,⋅)\Delta(\cdot, \cdot)Δ(⋅,⋅) 评估所有任务的平均有效性。
5 实验
5.1 实验设置
数据集。按照之前的研究所述 [19, 42],我们在四个广泛使用的任务规划数据集上进行了实验:HotpotQA [38]、ALFWorld [25]、Webshop [39] 和 ScienceWorld [29]。HotpotQA 设计用于多跳推理任务,包含大约113K对问答对,源自维基百科。ALFWorld 允许代理在模拟环境中完成具身任务(例如,将清洗过的苹果放入厨房冰箱)。Webshop 是一个网络应用程序,模拟在线购物环境,代理导航网页以查找、定制和购买商品,基于文本指令指定产品要求。ScienceWorld 评估代理在小学科学课程水平上的科学推理能力。
为了设置元学习,在 HotpotQA 中,我们使用数据集中12种答案类型(例如,人物、地点、日期)定义任务,其中随机选择6种类型作为已见训练任务,6种类型作为未见测试任务。对于 ALFWorld,我们使用其提供的已见任务和未见任务分别进行训练和测试。对于 Webshop,我们根据产品类别定义任务,其中随机抽取60%的类别用于训练,其余用于测试。对于 ScienceWorld,我们利用它来评估 InstructRAG 在跨数据集上的泛化能力,专注于完全新的任务。
基线。我们仔细回顾了文献并确定了以下基线方法:ReAct [41]、WKM [19]、Reflexion [23]、GenGround [22] 和 RAP [11]。这些对应于第2节讨论的近期代表性技术。对于 GenGround,我们使用 Llamaindex [14] 实现了一个检索器,以找到支持 LLM 生成答案的相关信息,其中我们存储了以前成功经验中的 TAO 三元组,并利用检索到的相似三元组作为检索器的输出。相同的数据(即,来自训练和测试任务的支持集)被用来准备检索方法(即,GenGround 和 RAP)的外部数据库。此外,我们将 InstructRAG 和基线集成到三种典型的 LLM 中,分别是 GLM-4 [9]、GPT-4o mini [1] 和 DeepSeek-V2 [7] 进行比较。
为了确保公平的性能比较,我们注意到:1) 基线和 InstructRAG 都配置了相同的设置,包括相同的检索器和骨干 LLM;2) 我们遵循原始论文中指定的超参数设置。
评估指标。按照 [15, 19, 42],我们评估了 InstructRAG 在四个数据集上的有效性。对于 HotPotQA,使用 F1 分数,将代理的答案与真实答案进行比较。对于 ALFWorld,使用成功率,这是一个二元指标(0 或 1),指示代理是否成功完成任务。对于 WebShop 和 ScienceWorld,使用范围从 0 到 1 的奖励分数来衡量任务完成水平。总体而言,更高的值表示更好的结果。我们注意到,所有报告的实验结果都具有统计显著性,通过 t 检验验证,p<0.05。
实现细节。我们使用 Python 3.7 实现了 InstructRAG 和基线。构建指令图的阈值 δ\deltaδ 设置为 0.4 。在 RL-Agent 中,我们实现了一个两层前馈神经网络。第一层包含 20 个神经元,使用 tanh 激活函数,第二层包含 2 个神经元,对应于包含或排除节点的动作空间。我们使用 Adam 随机梯度下降,学习率为 0.001 来优化策略,奖励折扣设置为 0.99 。在 ML-Agent 中,选择路径的超参数 KKK 经验性地设置为 3 。为了提高训练效率,我们在训练过程中缓存了 LLM 生成的输入和输出。
5.2 实验结果
(1) 效果评估(与基线方法的比较)。我们在表1中评估了 InstructRAG 在三个LLM上未见任务上相对于基线方法的效果。InstructRAG 一致地优于基线方法,表现出更优的效果。值得注意的是,它在 HotpotQA、ALFWorld 和 Webshop 上分别比最佳基线(RAP)提高了 19.2%19.2 \%19.2%、9.3%9.3 \%9.3% 和 6.1%6.1 \%6.1%。这种提升可以归因于两个因素:1) InstructRAG 采用基于图的指令路径组织方法,允许将它们组合成新路径以实现更有效的规划,而不是像 RAP 那样独立地将它们存储在外部数据库中;2) 它利用元学习方法高效地使训练好的模型适应各种任务。
(2) 效果评估(跨数据集的泛化能力)。我们进一步评估了 InstructRAG 的泛化能力,通过将训练好的 InstructRAG 模型从 HotpotQA 应用到 ScienceWorld 数据集中的全新任务。结果如表2所示。一致地,InstructRAG 在所有数据集上均优于最佳基线方法 RAP,提升了 6%−10%6\%-10\%6%−10%。
(3) 效果评估(在已见训练任务上的表现)。我们也报告了在已见训练任务上的表现。与 RAP 相比,观察到了类似的改进,如表3所示,在 HotpotQA、ALFWorld 和 Webshop 上的平均改进分别为 21.9%21.9\%21.9%、10.8%10.8\%10.8% 和 10.4%10.4\%10.4%。
(4) 效果评估(对噪声的鲁棒性)。我们通过引入带控制噪声率的噪声路径(即,过去经验中的失败指令路径)来评估指令图中错误历史路径对任务表现的影响,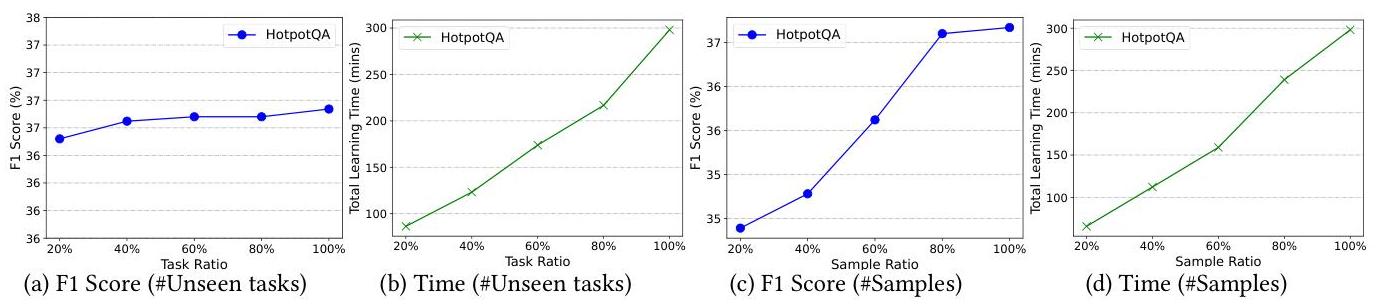
图2:在HotpotQA上使用DeepSeek-V2关于未见任务或样本数量的F1分数和少样本学习时间。
表5:在HotpotQA上验证可扩展性(RL-Agent)和可迁移性(ML-Agent)的消融研究。
| 组件 | F1 分数 |
|---|---|
| InstructRAG | 37.17\mathbf{3 7 . 1 7}37.17 |
| 无指令图 | 32.87 |
| 无RL-Agent | 33.45 |
| 无RL-Agent预热启动 | 34.37 |
| 无RL-Agent策略梯度 | 36.18 |
| 无ML-Agent | 34.78 |
| 无ML-Agent预训练 | 36.19 |
| 无ML-Agent微调 | 36.24 |
表6:阈值 δ\deltaδ 和运行时效率的影响。
| δ\deltaδ | 0.0 | 0.2 | 0.4 | 0.6 | 0.8 | 1.0 |
|---|---|---|---|---|---|---|
| F1 分数 | 34.02 | 35.19 | 37.17\mathbf{3 7 . 1 7}37.17 | 36.61 | 36.48 | 35.93 |
| 构建时间(秒) | 19.61 | 21.27 | 20.87\mathbf{2 0 . 8 7}20.87 | 21.65 | 23.08 | 22.07 |
| 训练时间(小时) | 23.26 | 23.64 | 23.93\mathbf{2 3 . 9 3}23.93 | 24.81 | 25.13 | 25.17 |
| 少样本时间(分钟/任务) | 26.35 | 26.89 | 27.10\mathbf{2 7 . 1 0}27.10 | 28.01 | 28.47 | 28.51 |
| 测试时间(秒) | 33.87 | 34.46 | 34.74\mathbf{3 4 . 7 4}34.74 | 35.85 | 36.45 | 36.47 |
| 节点数量 | 5 | 29 | 286\mathbf{2 8 6}286 | 666 | 720 | 725 |
表7:检索路径数量 KKK 的影响。
| KKK | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| F1 分数 | 34.78 | 36.16 | 37.17\mathbf{3 7 . 1 7}37.17 | 36.98 | 36.77 |
| 测试时间(秒) | 32.05 | 33.57 | 34.74\mathbf{3 4 . 7 4}34.74 | 35.31 | 42.09 |
从 0%0 \%0% 到 50%50 \%50%。为了比较,我们使用了 RAP,这是最好的基线方法,其数据库中也包含噪声路径。基于 DeepSeek-V2 的 HotPotQA 的 F1 分数结果如表4所示。值得注意的是,即使噪声率达到 50%50 \%50%,InstructRAG 的性能仍然相对稳定,仅下降了 11.1%11.1 \%11.1%。这种鲁棒性源于多样化的指令组合,有助于选择适当的路径并有效减轻噪声。
(5) 消融研究。我们进行了消融研究以评估 InstructRAG 内部不同组件的贡献,如表5所示。我们评估了以下修改:(1) 省略指令图并允许 InstructRAG 直接从存储的单个路径中检索相关路径;(2) 省略 RL-Agent 并使用基于阈值的方法决定节点的包含或排除,(3) 预热阶段,(4) 策略梯度阶段;(5) 省略 ML-Agent 并仅依赖 RL-Agent 返回的路径进行测试以处理未见任务,(6) 预训练阶段,(7) 微调阶段。我们观察到,指令图中的知识显著提升了 11.6%11.6 \%11.6%,并且 RL-Agent 和 ML-Agent 分别贡献了整体改进的 11.1%11.1 \%11.1% 和 6.9%6.9 \%6.9%。
(6) 参数研究(构建指令图的阈值 δ\deltaδ 和运行时效率)。如表6所示,我们从0.0到1.0变化阈值 δ\deltaδ 来控制图构建过程。随着 δ\deltaδ 增加,创建更多节点,但构建时间保持稳定。这是因为使用AKNN索引的总指令数对阈值不敏感。我们观察到,随着 δ\deltaδ 增加,F1 分数先增加然后减少。当 δ=0.0\delta=0.0δ=0.0 时,只有少量指令节点集可以管理所有指令,由于集合大小较大,难以准确识别给定问题的指令。相反,当 δ=1.0\delta=1.0δ=1.0 时,图简化为单独的指令路径,失去组合指令成新路径的灵活性。因此,适度的 δ\deltaδ 导致最佳性能。此外,我们展示了 δ\deltaδ 增加时的训练、少样本学习和测试时间。值得注意的是,训练和少样本学习需要显著多于图构建的时间,主要原因是语言生成相比算法构建有更高的计算需求。此外,图构建是一次性的过程,发生在数据预处理期间。
(7) 参数研究(检索候选路径的数量 KKK)。我们从1到5变化检索路径的数量 KKK,并在表7中报告了F1分数和测试时间。正如预期的那样,随着 KKK 增大,测试时间也会增加,因为考虑了更多的候选路径。我们观察到,当 KKK 达到3时,整体性能趋于收敛,此时可以从指令图中检索出潜在的最佳路径。
(8) 少样本学习的影响。InstructRAG 包含一个少样本学习阶段,以便快速适应每个任务。我们根据任务数量或每个任务的样本数量报告其有效性及少样本学习时间,基于 DeepSeek-V2。如图2(a)-(b) 所示,我们将任务比例从0.2变到1.0,观察到随着任务数量增加,有效性保持稳定,表明在不同任务之间具有强大的可迁移性。由于包含了额外的训练数据,运行时间随着任务数量的增加而增加。此外,我们将每个任务的样本比例从0.2变到1.0。如图2©和图2(d)所示,我们观察到有效性提高并在样本的约80%处收敛,同时随着用于训练的样本数量增加,运行时间也增加。我们注意到,平均而言,一个任务需要27.1分钟进行适应,并且不同的任务可以并行处理。GLM-4 和 GPT-4o mini 的结果显示了类似的趋势,因此出于简洁起见省略了这些结果。
6 结论
在本文中,我们系统地研究了利用RAG进行任务规划,并确定了两个关键属性:可扩展性和可迁移性。我们介绍了InstructRAG,这是一种新颖的多智能体元强化学习解决方案,整合了指令图、RL-Agent和ML-Agent以优化端到端任务规划性能。我们在四个广泛使用的数据集上进行的大量实验,涵盖了各种LLM,证明了InstructRAG提供了卓越的性能,并展示了使用少样本示例快速适应新任务的能力。作为未来的研究方向,我们计划扩展InstructRAG以适应更多任务。
参考文献
[1] Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altersschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 技术报告。arXiv 预印本 arXiv:2303.08774 (2023).
[2] Maciej Besta, Nils Blach, Alex Kubicek, Robert Gerstenberger, Michal Podstawski, Lukas Gianinazzi, Joanna Gajda, Tomasz Lehmann, Hubert Niewiadomski, Piotr Nyczyk, et al. 2024. 思维图:使用大型语言模型解决复杂问题。在AAAI,第38卷,17682-17690页.
[3] Baian Chen, Chang Shu, Ehsan Shareghi, Nigel Collier, Karthik Narasimhan, 和 Shunyu Yao. 2023. Fireact:朝向语言代理微调。arXiv 预印本 arXiv:2310.05915 (2023).
[4] Yanda Chen, Ruiaj Zhong, Sheng Zha, George Karypis, 和 He He. 2022. 通过语言模型上下文调优进行元学习。在ACL。719-730页.
[5] Gautier Dagan, Frank Keller, 和 Alex Lascarides. 2023. 动态规划与FLM。arXiv 预印本 arXiv:2309.06391 (2023).
[6] Budhaditya Deb, Ahmed Hassan, 和 Guoqing Zheng. 2022. 使用元学习增强自然语言生成的指令。在EMNLP。6792-6808页.
[7] DeepSeek-AI. 2024. DeepSeek-V2:一种强大、经济高效的专家混合语言模型。arXiv 预印本 arXiv:2405.04434 (2024).
[8] Chelsea Finn, Pieter Abbeel, 和 Sergey Levine. 2017. 模型无关的元学习用于深度网络的快速适应。在ICML, PMLR, 1126-1135页.
[9] Team GLM, Aohan Zeng, Bin Xie, Bowen Wang, Chenhui Zhang, Da Yin, Diego Rojas, Guanyu Feng, Hanlin Zhao, Hanyu Lai, 等人. 2024. ChatGLM:从GLM-130B到GLM-4的所有工具的大规模语言模型系列。arXiv 预印本 arXiv:2406.12793 (2024).
[10] Malte Helmert. 2006. 快速向下规划系统。JAIR 26 (2006), 191−246191-246191−246.
[11] Tomoyuki Kagiya, Thong Jing Yuan, Yuxuan Lou, Jayashree Karlekar, Sugiri Pranata, Akira Kinose, Koki Oguri, Felix Wick, 和 Yang You. 2024. RAP: 使用情境记忆的检索增强规划,适用于多模态FLM代理。arXiv 预印本 arXiv:2402.03610 (2024).
[12] Myoonghwa Lee, Seonho An, 和 Min-Soo Kim. 2024. PlanRAG: 作为一种决策者的生成性大规模语言模型的计划后检索增强生成。arXiv 预印本 arXiv:2406.12430 (2024).
[13] Re Liu, Yuqian Jiang, Xiaohan Zhang, Qiang Liu, Shiaj Zhang, Joydeep Biswas, 和 Peter Stone. 2023. ULMP+ P: 赋予大规模语言模型最优规划能力。arXiv 预印本 arXiv:2304.11477 (2023).
[14] Jerry Liu. 2022. LlamaIndex. https://doi.org/10.5281/zenodo. 1234
[15] Zhiwei Liu, Weiran Yao, Jianguo Zhang, Le Xue, Shelby Heinecke, Rithesh Murthy, Yihao Feng, Zeysan Chen, Juan Carlos Niebles, Devuanh Arpit, 等人. 2023. Boba: 基准和编排增强自主代理的FLM。arXiv 预印本 arXiv:2309.05960 (2023).
[16] Aman Madsan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dairi, Shrimai Prabhumoye, Yiming Yang, 等人. 2024. 自我重新精炼:通过自我反馈进行迭代精炼。NeurIPS 36 (2024).
[17] 尤·亚·马尔科夫和德米特里·亚·雅舒宁. 2018. 使用分层可导航小世界图的有效且稳健的近似最近邻搜索。TPAMI 42, 4 (2018), 824-836.
[18] Sewon Min, Mike Lewis, Luke Zettlemoyer, 和 Hannaneh Hajishirzi. 2021. MetaICL: 学习在上下文中学习。arXiv 预印本 arXiv:2110.15943 (2021).
[19] Shusfei Qiao, Bunnan Fang, Ningyu Zhang, Yuqi Zhu, Xiang Chen, Shumin Deng, Yong Jiang, Pengjun Xie, Fei Huang, 和 Huajun Chen. 2024. 使用世界知识模型的代理规划。arXiv 预印本 arXiv:2405.14205 (2024).
[20] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastre, Amanda Askell, Pamela Mishkin, Jack Clark, 等人. 2021. 通过自然语言监督学习可转移的视觉模型。在ICML, PMLR, 8748-8763.
[21] Shreyas Sundara Raman, Vanya Cohen, Eric Rosen, Ifrah Idrees, David Paulius, 和 Stefanie Tellex. 2022. 使用大型语言模型进行规划通过纠正性重提示。在 NeurIPS Workshop.
[22] Shi Zhongliang, Zhang Shuo, Sun Weiwei, Gao Shen, Ren Pengjie, Chen Zhumin, 和 Ren Zhaochun. 2024. 在检索增强生成中先生成再接地以进行多跳问答。ACL (2024).
[23] Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, 和 Shunyu Yao. 2024. Reflexion: 具有语言强化学习的代理。NeurIPS 36 (2024).
[24] Mohit Shridhar, Jesse Thomason, Daniel Gordon, Yonatan Bisk, Winson Han, Rooebeh Mottaghi, Luke Zettlemoyer, 和 Dieter Fox. 2020. ALFRED: 解读日常任务的接地指令基准。在 IEEE/CVF 计算机视觉与模式识别会议录。10740-10749.
[25] Mohit Shridhar, Xingdi Yuan, Marc-Alexandre Côté, Yonatan Bisk, Adam Trischler, 和 Matthew Hausknecht. 2020. ALFWorld: 对齐文本和具身环境以进行交互学习。arXiv 预印本 arXiv:2010.03768 (2020).
[26] Sanchif Sinha, Yuguang Yue, Victor Soto, Mayank Kulkarni, Jianhua Lu, 和 Aidong Zhang. 2024. MAML-en-LLM: 改进模型无关的元训练以提高上下文学习能力。KDD (2024).
[27] Yilan Song, Da Yin, Xiang Yue, Jie Huang, Sujian Li, 和 Bill Yuchen Lin. 2024. 试错法:基于FLM代理的探索性轨迹优化。arXiv 预印本 arXiv:2403.02502 (2024).
[28] Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakaï Tang, Xu Chen, Yankai Lin, 等人. 2024. 基于大型语言模型的自主代理综述。计算机科学前沿 18, 6 (2024), 186345.
[29] Ruoyao Wang, Peter Jansen, Marc-Alexandre Côté, 和 Prithviraj Ammanabrolu. 2022. ScienceWorld: 您的代理是否比五年级学生更聪明?在 EMNLP. 11279–11298.
[30] Renxi Wang, Haonan Li, Xudong Han, Yixuan Zhang, 和 Timothy Baldwin. 2024. 学习失败:将负面示例整合到微调作为代理的大规模语言模型中。arXiv 预印本 arXiv:2402.11651 (2024).
[31] Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Askanksha Chowdhrey, 和 Denny Zhou. 2022. 自我一致性改进了语言模型中的链式思维推理。arXiv 预印本 arXiv:2203.11171 (2022).
[32] Yizhong Wang, Swaroop Mishra, 等人. 2022. 在1600多个语言任务中通过上下文指令基准测试泛化能力。arXiv 预印本 arXiv:2204.07705 2 (2022).
[33] Zihao Wang, Anji Liu, Haowei Lin, Jiaqi Li, Xiaojian Ma, 和 Yitao Liang. 2024. RAT: 检索增强思维引发长期生成中的情境感知推理。arXiv 预印本 arXiv:2403.05313 (2024).
[34] Zhaowei Wang, Hongming Zhang, Tianqing Fang, Ye Tian, Yue Yang, Kaixin Ma, Xiaoman Pan, Yangqiu Song, 和 Dong Yu. 2024. DIYScene: 使用多样化场景和对象基准LVLMs进行对象导航。arXiv 预印本 arXiv:2410.02730 (2024).
[35] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, 等人. 2022. 链式思维提示引发大规模语言模型中的推理。NeurIPS 35 (2022), 24824-24837.
[36] Ronald J Williams. 1992. 连接主义强化学习的简单统计梯度跟随算法。机器学习 8, 3 (1992), 229-256.
[37] Zhiheng Xi, Wenxiang Chen, Xin Guo, Wei He, Yזwen Ding, Boyang Hong, Ming Zhang, Junzhe Wang, Senjie Jin, Enyu Zhou, 等人. 2023. 基于大规模语言模型的代理的兴起与潜力:综述。arXiv 预印本 arXiv:2309.07864 (2023).
[38] Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, 和 Christopher D Manning. 2018. HotpotQA: 多样且可解释的多跳问答数据集。在 EMNLP. 2369-2380.
[39] Shunyu Yao, Howard Chen, John Yang, 和 Karthik Narasimhan. 2022. Webshop: 朝着具有接地语言代理的可扩展真实世界网络交互方向发展。NeurIPS 35 (2022), 20744-20757.
[40] Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, 和 Karthik Narasimhan. 2024. 思维树:使用大型语言模型进行深思熟虑的问题解决。NeurIPS 36 (2024).
[41] Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, 和 Yuan Cao. 2022. React: 在语言模型中协同推理和行动。arXiv 预印本 arXiv:2210.03629 (2022).
[42] Yuqi Zhu, Shusfei Qiao, Yixin Ou, Shumin Deng, Ningyu Zhang, Shiwei Lyu, Yue Shen, Lei Liang, Jinjie Gu, 和 Huajun Chen. 2024. KnowAgent: 为基于FLM的代理提供知识增强规划。arXiv 预印本 arXiv:2403.03101 (2024).
A 附录
A. 1 InstructRAG 的三个阶段概述
InstructRAG 的三个阶段——训练、少量样本学习和测试——总结在表8中。
A. 2 提示词
我们分别在表9、表10和表11中提供了HotpotQA、ALFWorld和Webshop的InstructRAG提示词。
A. 3 关于使用多智能体进行任务规划的讨论
我们提供了一个讨论,以解释在任务规划中同时使用RL-Agent和ML-Agent而不是修改单一智能体(例如,通过设置 K=1K=1K=1 来调整RL-Agent)的原因。本研究中的任务规划需要解决两个关键属性:可扩展性和可迁移性。这些属性在某种程度上是正交的:可扩展性涉及组合已见任务中的指令,而可迁移性则侧重于快速适应未见任务。单个智能体很难同时在两个方向上有效优化。因此,我们设计了一个多智能体框架,由两个不同的智能体协作:RL-Agent为ML-Agent提供候选路径,而ML-Agent为RL-Agent提供奖励。这种战略性的分工使我们能够通过多智能体元强化学习明确优化可扩展性和可迁移性,并通过表5中的消融研究验证了解决方案。
A. 4 使用其他LLM进行少量样本学习
我们在图3中报告了GLM-4和GPT-4o mini的F1分数和少量样本学习时间。总体而言,可以观察到类似的趋势,这与DeepSeek-V2的结果一致。
A. 5 定性结果
InstructRAG和RAP都利用过去的经历(例如,指令路径)来引导LLM规划。表12、表13和表14分别展示了InstructRAG和RAP在HotpotQA、ALFWorld和Webshop上的规划轨迹。我们注意到,InstructRAG将来自相关任务的多条路径组合成一条指令路径,有效地引导LLM规划。这通过成功计划中的几个指令(用黄色突出显示)重叠得以证明。具体来说,我们在表12中分析了规划结果。InstructRAG通过结合基于共同指令search[Piers Haggard]的两条路径表现出优势。这种方法有效地连接了两个关键项——代表小说的Anthony Minghella和代表《天才里波雷》电影改编版的Piers Haggard。这些连接使LLM能够在生成的想法中正确构建查询公式(例如Thought 5),从而检索有关电影导演的信息。相比之下,RAP难以根据其检索到的经历生成正确的查询。它生成的想法无法支持有效的查询构建,通常导致规划陷入僵局。
表8:InstructRAG在三个阶段的概述。
| InstructRAG | 训练阶段 | 少样本学习阶段 | 测试阶段 |
|---|---|---|---|
| 任务 | 已见训练任务 | 未见测试任务 | 未见测试任务 |
| 给定数据 | 支持集和查询集 | 支持集 | 查询集 |
| 指令图 | G(用支持集构建) | G’(将支持集扩展到G) | G’ |
| 目标 | 每次迭代: 1. 抽样一批任务 2. 在支持集上通过LWS\mathcal{L}_{W S}LWS优化RL-Agent并通过LPT\mathcal{L}_{P T}LPT优化ML-Agent 3. 在所有采样任务的查询集上通过LPG\mathcal{L}_{P G}LPG和LFT\mathcal{L}_{F T}LFT联合优化RL-Agent和ML-Agent |
1. 在每个任务的支持集上通过LWS\mathcal{L}_{W S}LWS更新训练好的RL-Agent并通过LPT\mathcal{L}_{P T}LPT更新ML-Agent 2. 在每个任务的支持集上通过LPG\mathcal{L}_{P G}LPG和LFT\mathcal{L}_{F T}LFT联合更新RL-Agent和ML-Agent |
报告所有任务查询集上的平均有效性 |
表9:HotpotQA整体计划的提示。
通过交错思考、行动、观察步骤解决问答任务。思考可以对当前情况进行推理,行动可以有三种类型:
(1) Search[entity],它在维基百科上搜索确切的实体并返回第一段(如果存在)。如果没有,则返回一些相似的实体供搜索。
(2) Lookup[keyword],它返回当前段落中包含关键词的下一句。
(3) Finish[answer],它返回答案并完成任务。
这里有一些例子。
[例子]
这里是提供的动作序列:
[指令路径]。
评估对任务的初步理解,并在过程中出现新的见解或要求时调整方法。
如果某个动作没有产生有用信息或导致死胡同,重新考虑之前的步骤或在“Search”和“Lookup”之间切换以收集更多相关信息。
现在你需要完成以下任务:
[问题]
表10:ALFWorld整体计划的提示。
与家庭互动以解决问题。以下是合法动作:go, take, clean, use, examine, look, heat, cool, open, close, toggle, put, think。生成动作时,响应的第一词必须是上述列出的合法动作之一。
这里有一些例子。
[例子]
这里是提供的动作序列:
[指令路径]。
评估对任务的初步理解,并在过程中出现新的见解或要求时调整方法。
现在你需要完成以下任务:
[问题]
表11:Webshop整体计划的提示。
你是一个高级推理代理,负责与购物网站互动。以下是合法动作:
(1) search[keyword]:你可以使用特定关键词进行搜索(如果 “has_search_bar” 为 True)。保持关键词简短明了。避免过于详细的描述。仅包括有助于识别产品的关键词。
(2) click[clickables]:你可以点击可用的可点击项目。
这里有一些例子。
[例子]
这里是提供的动作序列:
[指令路径]。
评估对任务的初步理解,并在过程中出现新的见解或要求时调整方法。
现在你需要完成以下任务:
[问题]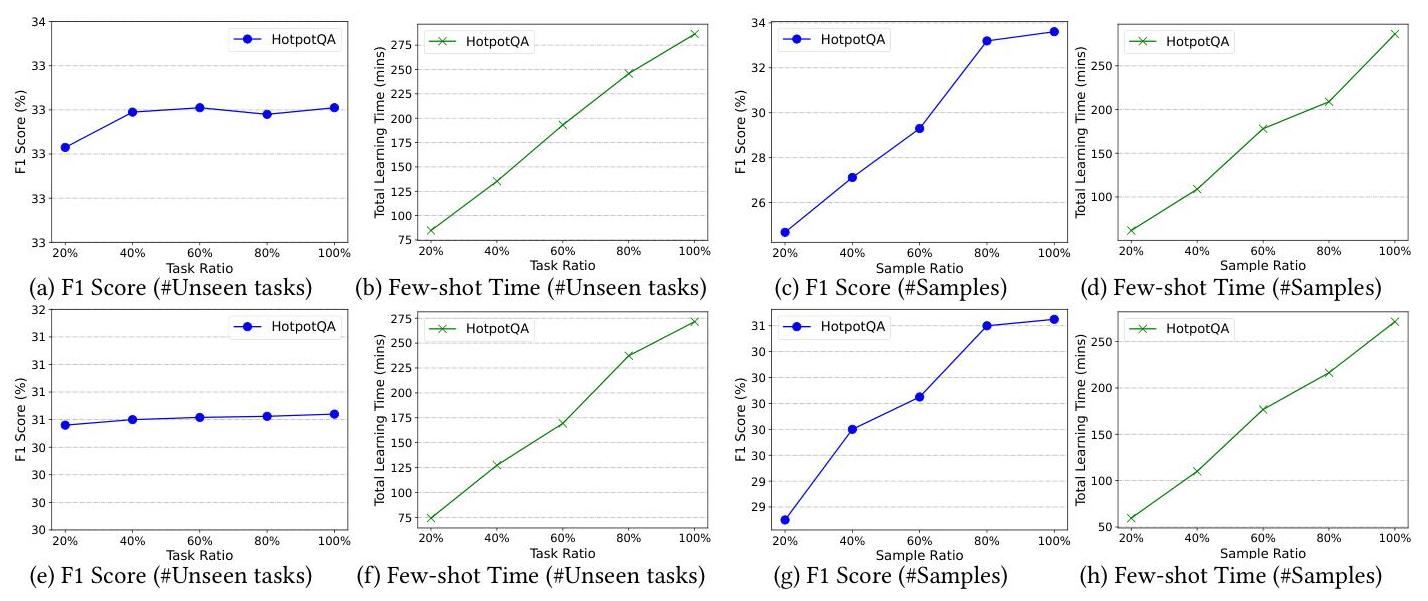
图3:关于HotpotQA中未见任务或样本数量的F1分数和少样本学习时间,其中(a)-(d)为GLM-4,(e)-(h)为GPT-4o mini。
表12:InstructRAG和RAP在HotpotQA轨迹上的比较,其中我们将任务、成功结果和失败结果分别用紫色、绿色和红色突出显示。不同的颜色用于标记指令路径中的指令,该路径结合了路径1和路径2。路径中的连接指令用灰色突出显示,规划轨迹中与指令路径重叠的指令(动作)用黄色突出显示。
任务描述:你的任务是回答一个问题。
"The Decline of Western Civilization"和"The Talented Mr. Ripley"的导演中,谁年龄更大?
InstructRAG
指令路径:Search[Anthony Minghella] → Search[Piers Haggard] → Search[The Decline of Western Civilization] → Search[Penelope Spheeris] (从结合的任务中派生:“Anthony Minghella和Piers Haggard都是电影导演吗?”和“哪位导演,Piers Haggard还是Penelope Spheeris,最著名的是以其作品包括名为’The Decline of Western Civilization’的三部曲而闻名的纪录片导演?”)
组合自:
路径1:Search[Anthony Minghella] → Search[Piers Haggard] → Finish[yes]
路径2:Search[Piers Haggard] → Search[The Decline of Western Civilization] → Search[Penelope Spheeris] → Finish[Penelope Spheeris]
Thought 1: 我需要搜索 ‘The Decline of Western Civilization’ 和 ‘The Talented Mr. Ripley’ 的导演,找到他们的出生日期,然后比较它们以确定谁更年长。
Act 1: Search[The Decline of Western Civilization]
Obs 1: The Decline of Western Civilization 是一部1981年的美国纪录片,拍摄于1979年和1980年…
Thought 2: ‘The Decline of Western Civilization’ 的导演是 Penelope Spheeris。我需要搜索她的出生日期。
Act 2: Search[Penelope Spheeris]
Obs 2: Penelope Spheeris(生于1945年12月2日)[1] 是一位美国电影导演、制片人和编剧…
Thought 5: 我需要搜索1999年电影 ‘The Talented Mr. Ripley’ 的导演。正确的搜索术语应该是 ‘The Talented Mr. Ripley (film)’。
Act 5: Search[The Talented Mr. Ripley (film)]
Obs 5: The Talented Mr. Ripley 是一部由 Anthony Minghella 编写和执导的1999年美国心理惊悚片,改编自 Patricia Highsmith 的同名小说…
Thought 6: ‘The Talented Mr. Ripley’(1999年电影)的导演是 Anthony Minghella。我需要搜索他的出生日期。
Act 6: Search[Anthony Minghella]
Obs 6: Anthony Minghella,CBE(1954年1月6日 - 2008年3月18日)是一位英国电影导演、剧作家和编剧…
Thought 7: Anthony Minghella 出生于1954年1月6日。比较出生日期,1945年12月2日(Penelope Spheeris)= 1954年1月6日(Anthony Minghella),所以 Penelope Spheeris 更年长。
Act 7: Finish[Penelope Spheeris]
Obs 7: 情节结束,答案正确
成功标志 = True,成功率 = 1.0
RAP
路径:分别从任务中检索:“哪位导演,Piers Haggard 或 Penelope Spheeris,最著名的是以其作品包括名为 ‘The Decline of Western Civilization’ 的三部曲而闻名的纪录片导演?”,“Anthony Minghella 和 Piers Haggard 都是电影导演吗?”,“Extra,是一部关于电视、电影和剧院中临时演员的英国情景喜剧,该剧由 BBC 和 HBO 联合制作,由 Ricky Dene Gervais 创作、编写和导演,他是一位出生于哪一天的英国喜剧演员、演员、作家、制片人、导演、歌手和音乐家?”,以及 “由 Adam Herz 编写并由兄弟 Paul 和 Chris Weitz 执导的青少年性喜剧电影,主演了一位因她在 Jessica 角色中最著名的演员”。
Thought 1: 我需要识别 ‘The Decline of Western Civilization’ 和 ‘The Talented Mr. Ripley’ 的导演以确定谁更年长。Act 1: Search[The Decline of Western Civilization]
Obs 1: The Decline of Western Civilization 是一部1981年的美国纪录片,拍摄于1979年和1980年…
Thought 2: Penelope Spheeris 是 ‘The Decline of Western Civilization’ 的导演。接下来,我需要找到 ‘The Talented Mr. Ripley’ 的导演。
Act 2: Search[The Talented Mr. Ripley]
Obs 2: The Talented Mr. Ripley 是 Patricia Highsmith 于1955年创作的心理惊悚小说…
Thought 3: 对 ‘The Talented Mr. Ripley’ 的搜索提供了关于小说及其改编的信息,但没有提到1999年电影版的导演。我需要搜索1999年电影 ‘The Talented Mr. Ripley’ 的导演。
Act 3: Search[director of The Talented Mr. Ripley 1999 film]
Obs 3: 未能找到1999年电影 ‘The Talented Mr. Ripley’ 的导演…
Thought 4: 我需要直接通过搜索电影标题并从提供的信息中识别导演来搜索1999年电影 ‘The Talented Mr. Ripley’ 的导演。
Act 4: Search[The Talented Mr. Ripley 1999 film]
Obs 4: 未能找到1999年电影 ‘The Talented Mr. Ripley’…
Thought 5: 我需要直接通过搜索电影标题并从提供的信息中识别导演来搜索1999年电影 ‘The Talented Mr. Ripley’ 的导演。
Act 5: Search[The Talented Mr. Ripley 1999 film]
Obs 5: 未能找到1999年电影 ‘The Talented Mr. Ripley’…
Thought 6: 我需要直接通过搜索电影标题并从提供的信息中识别导演来搜索1999年电影 ‘The Talented Mr. Ripley’ 的导演。
Act 6: Search[The Talented Mr. Ripley 1999 film]
Obs 6: 未能找到1999年电影 ‘The Talented Mr. Ripley’…
Thought 7: 我需要直接通过搜索电影标题并从提供的信息中识别导演来搜索1999年电影 ‘The Talented Mr. Ripley’ 的导演。
Act 7: Search[The Talented Mr. Ripley 1999 film]
Obs 7: 未能找到1999年电影 ‘The Talented Mr. Ripley’…
参考论文:https://arxiv.org/pdf/2504.13032

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 34
34 0
0- 0



 已为社区贡献285条内容
已为社区贡献285条内容

所有评论(0)