AI绘图教程|Stable Diffusion(SD)提示词的使用指南以及相关注意事项
提示词通常是在文生图和图生图的时候会使用到,提示词由多个描述性词汇组成,由逗号隔开,结尾不需要加分隔符(注:一般都是英文词汇和英文逗号)。提示词分为正向提示词(positive prompt)和反向提示词(negative prompt),用来告诉AI我们想要生成什么和不想生成什么。SD提示词支持多种类型的表达方式,包括英语单词、短语,自然语言,颜文字、emoji表情我们固定种子点为4182552
今天给大家分享的是Stable Diffusion提示词相关内容
01、提示词基本概述


提示词通常是在文生图和图生图的时候会使用到,提示词由多个描述性词汇组成,由逗号隔开,结尾不需要加分隔符(注:一般都是英文词汇和英文逗号)。
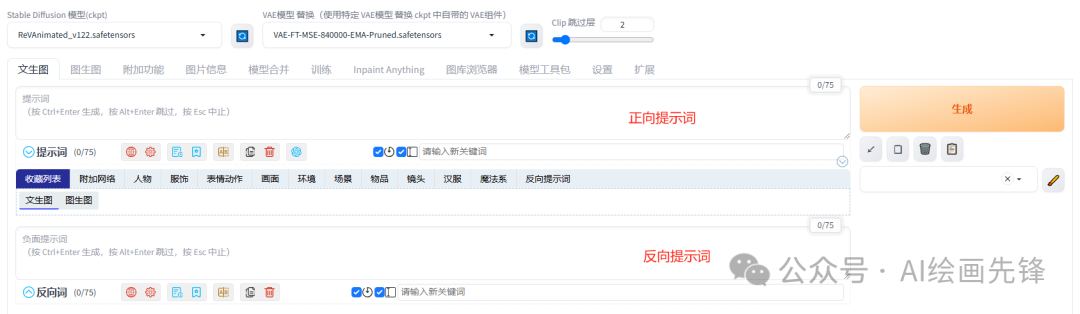
提示词分为正向提示词(positive prompt)和反向提示词(negative prompt),用来告诉AI我们想要生成什么和不想生成什么。
SD提示词支持多种类型的表达方式,包括英语单词、短语,自然语言,颜文字、emoji表情
我们固定种子点为4182552405,使用MajicMixRealistic_V7模型,对比英语单词、颜文字、emoji表情看下效果:

SD对于这3种提示词都可以识别,但识别效果上稍微有点差别
02、提示词顺序


提示词网上有个说法建议按如下顺序进行书写:
综述(图像质量+风格+镜头效果+光照效果+主题)
主体(人物&对象+动作+服装+饰品+道具)
细节(场景+环境)
1)、质量提示词通常是整个画面的清晰度,分辨率,质量等等关键词汇组成。
如:masterpiece,best quality,8k,Ultra-high resolution
2)、风格提示词如有则建议放在质量提示词后面,例如某个画家或某些影视作品的风格
如:ghibli style
3)、镜头效果通常用来体现主体在画面中的位置,
如长镜头(long shot),短镜头(short shot),全景镜头(panoramic)等,镜头通常最后只选择其中一种即可。
4)、光照效果
通常是环境的灯光效果
如电影级照明(cinematic lighting), 丁达尔效应(tyndall effect), 体积光(volumetric lighting)等
5)、主题提示词这里通常是指整个画面呈现什么样的主题,与风格有所区别,如深色主题(dark theme),明亮主题(bright theme)等
6)、主体提示词通常这里才是描绘我们整体想生成的作品内容
如:1girl,beautiful face,long hair,white hair,
7)、动作提示词通常这里是我们主体的一些动作表现,
如跑(running),走(walking),笑(smile)等
8)、服装提示词这里是我们主体的服装表现,
如裙子(dress),鞋子(shoes),外套(coat)等
9)、饰品提示词
这里通常是主体身上的一些饰品,
如头花(hair flower),手镯(bracelet),项链(necklace)等
10)、道具提示词通常这里是主体相关的道具,
如手提包(handbag),话筒(microphone),照相机(camera)等等
11)、场景提示词通常这里放主体所在的一些场景提示词,例如城市(city),咖啡厅(coffer shop),商场(mall)等
12)、环境提示词这里通常是所处的自然环境,
如白天(day),晚上(night),雨天(rain)等
实际我测试的时候,基本符合这个说法,下面我给大家演示下:
使用提示词:panda,bicycle,park 包含标点符号一共6个tokens
种子数:-1 随机种子
分辨率:512*512
迭代步数:30
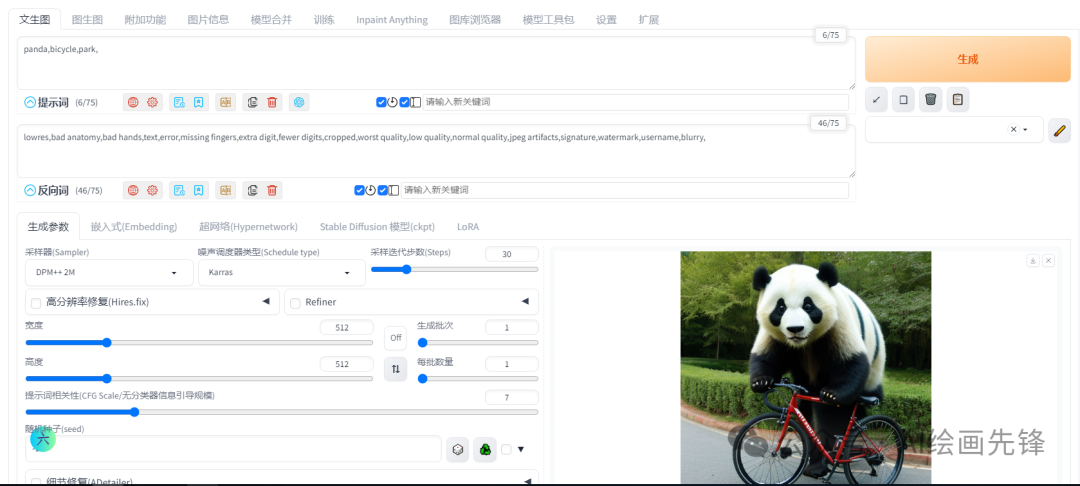
提示词中的熊猫、自行车、公园在生成的图片都体现出来了,现在我把熊猫的单词顺序移到提示词的后面
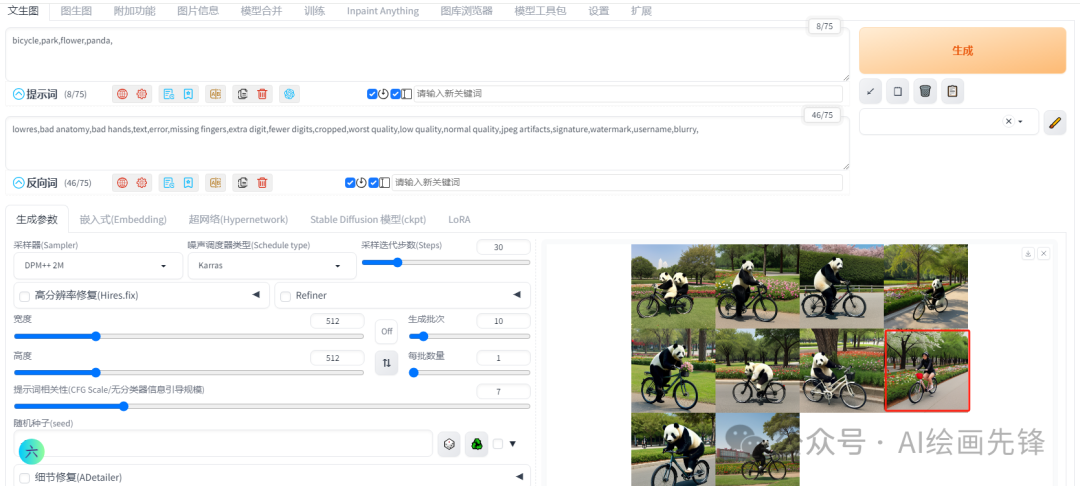
同一批生成的10个照片有1个没有出现熊猫,分析可能是把熊猫移动到后面后,权重变低了,抽卡的过程可能会出现没有熊猫。
这个问题在网上看过一篇类似的文章:说是把熊猫移动到提示词的后面后,很大概率抽卡的图片没有熊猫,分析原因是:
提示词的位置顺序对其所营造的语境有着重要影响,这一点对于使用过ChatGPT的用户来说应该并不陌生,ChatGPT会根据上下文来理解你的意图。
SD的语言模型部分也是遵循这一原理。例如,当我最初输入的提示词是“panda(熊猫), bicycle(自行车), city(城市), flower(花)”时,模型可能会按照这些词的顺序将它们连贯起来,理解为“熊猫在有花的城市里骑车”的场景。然而,当调整提示词的顺序,将熊猫放到最后时,模型可能首先会联想到“自行车在有花的城市里”的画面。但随后,当我在这个场景中突然加入一个熊猫时,模型可能会感到困惑,不太理解熊猫在这个场景中的具体意义,以至于最终生成的图片中甚至可能不会出现熊猫。
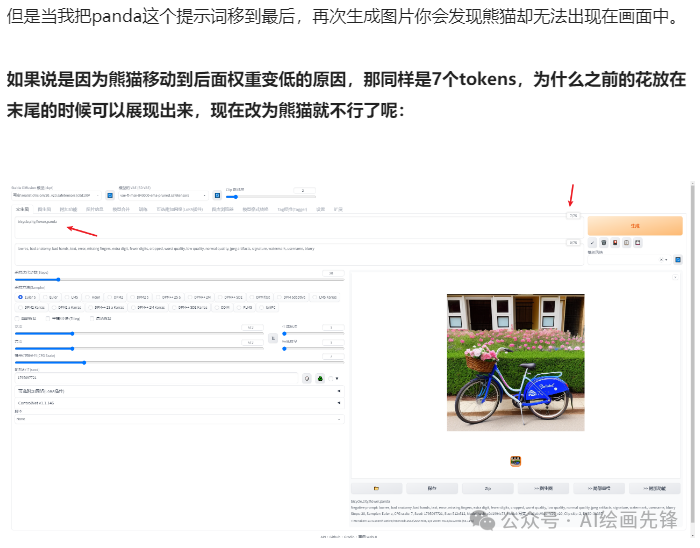
我使用新版本没有测试出来这个问题,可能是新版本的SD语言模块优化了这个问题,提示词按照顺序调整权重。
03、提示词权重语法

上节我们讨论过,提示词在列表中的位置越靠前,其权重就越高。不过,在撰写提示词时,还有其他方法可以增加其权重,这其中就涉及到了运用各种提示词符号的技巧。
1)、逗号(,)
提示词之间是通过逗号进行分隔,这样也可以认为逗号在一定程度上具有权重排序的功能,即逗号前面的提示词权重大于逗号后面的权重。
2)、圆括号()
提升提示词的权重至原来的1.1倍。如果存在多层圆括号,则其权重为1.1的N次方(N为圆括号的层数)。
如,对于((1girl)),1girl的权重就被提升为1.1×1.1=1.21倍,以此类推。
3)、冒号(😃
用来自定义词汇的权重。即使该词汇在列表中排在后面,我们也可以通过冒号来提升它的权重。通常,冒号会与圆括号一起使用。
如,(1girl:1.5)表示1girl的权重被设定为1.5倍。
4)、花括号{}能够提升词汇的权重至原来的1.05倍。其使用方法与圆括号类似。
如,对于{{1girl}},1girl的权重就被提升为1.05×1.05=1.1025倍。
5)、方括号[]
具有降低权重的作用,会将词汇的权重降低至原来的1/1.05倍。
如,[1girl]表示1girl的权重被降低为0.952倍。
这些符号怎样书写使用,书写方式一般有两种,第一种是直接以叠括号的方式书写:
(提示词):圆括号每层增加1.1倍
{提示词}:花括号每层增加1.05倍
[提示词]:方括号每层降低1.1倍
这样的写法稍微有点复杂,推荐另一种写法:**
**
(提示词:权重数值),其中权重数值的范围0.1-100,数值大于1代表提高权重,小于1代表降低权重。
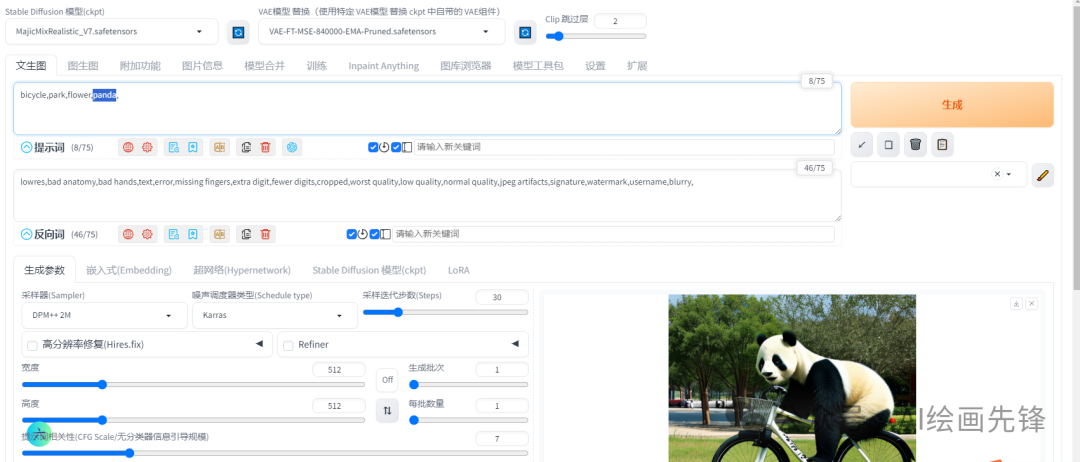
如:bicycle,park,flower,(panda:1.2),圆括号把熊猫括起来,后面跟上一个:1.2,表示熊猫的权重是1.2倍
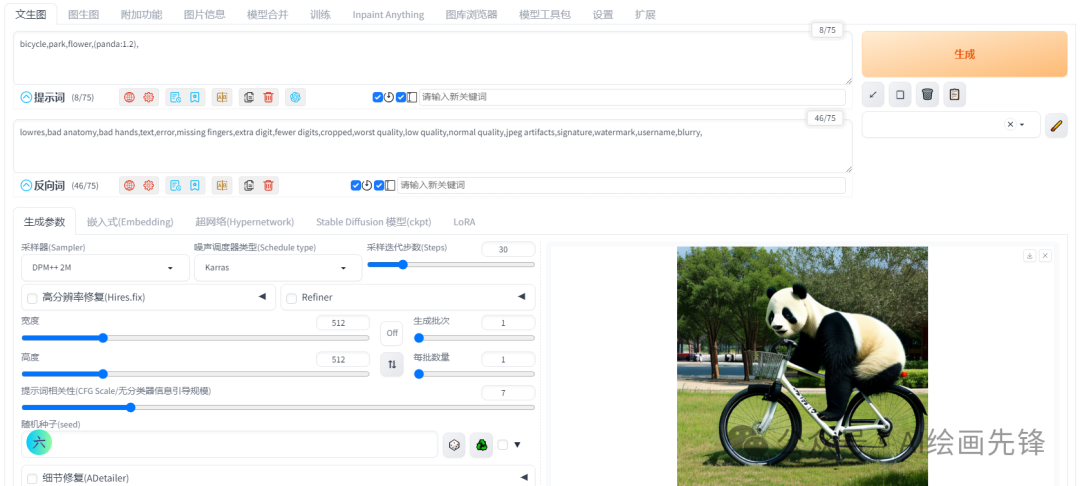
上面这两种方法操作还是有些麻烦,这里给大家推荐一种快捷键的操作方法:
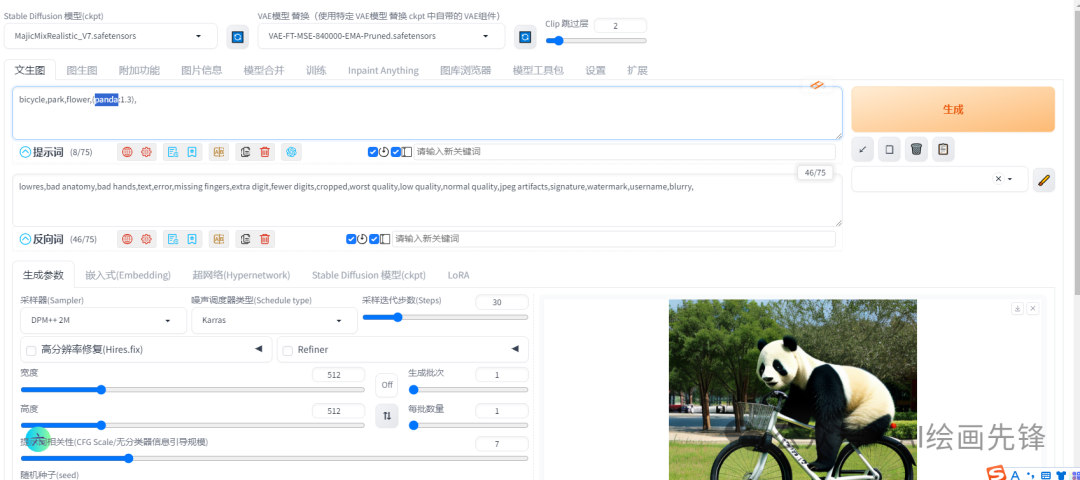
我想要调整“熊猫”这个提示词的权重,可以先使用鼠标将其选中。
通过按住CTRL键的同时,利用键盘的上下方向键,我就可以方便地更改这个提示词的权重数值了。这种方法省去了每次手动输入括号和冒号的繁琐步骤,使得操作更加便捷。
04、交替语法

这种语法允许你在每一步中交替计算不同的提示词,其书写格式为:
[提示词1|提示词2|…],你可以添加多个提示词,
但需要注意的是,这种语法不支持为提示词添加权重。
这种语法的典型应用是创建融合图像。例如,我可以在方括号中写入“熊猫”和“狗”这两个提示词,并用竖线分隔它们。这样,SD模型就会在第一步计算“熊猫”的特征,第二步计算“狗”的特征,第三步再次计算“熊猫”的特征,以此类推,最终生成一个融合了“熊猫”和“狗”特征的图像。
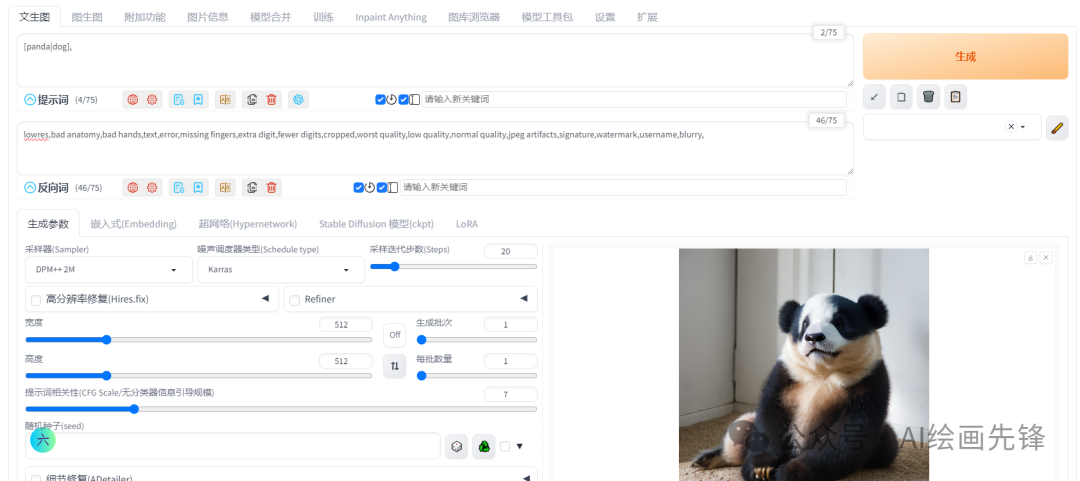
这样的熊猫|狗 是不是特可爱
它也能添加多个提示词,例如我这里分别写了熊猫,狗和老虎,它就会先第一步计算熊猫,第二步计算狗,第三步计算老虎以此类推:
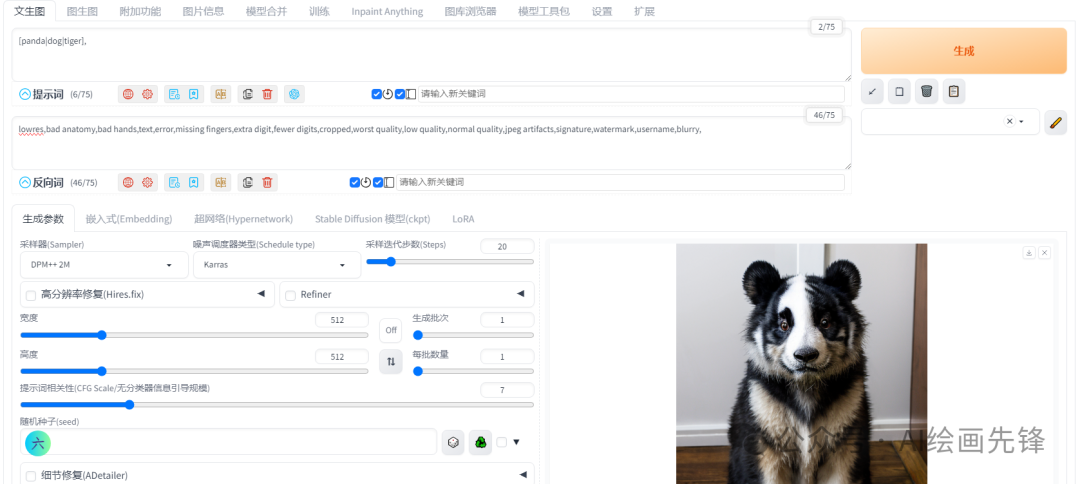
05、组合语法


组合语法与交替语法在某些方面相似,但它们的计算原理有所不同。组合语法更像是将各个提示词的结果直接相加,并且它还支持为提示词添加权重。其书写方式是:
将提示词依次列出,并使用“连接词”进行连接,如“提示词1 AND 提示词2 AND …”,其中提示词的数量可以是多个。
- AND连接词
提示词1 AND 提示词2 AND
如提示词:1girl,green AND red hair
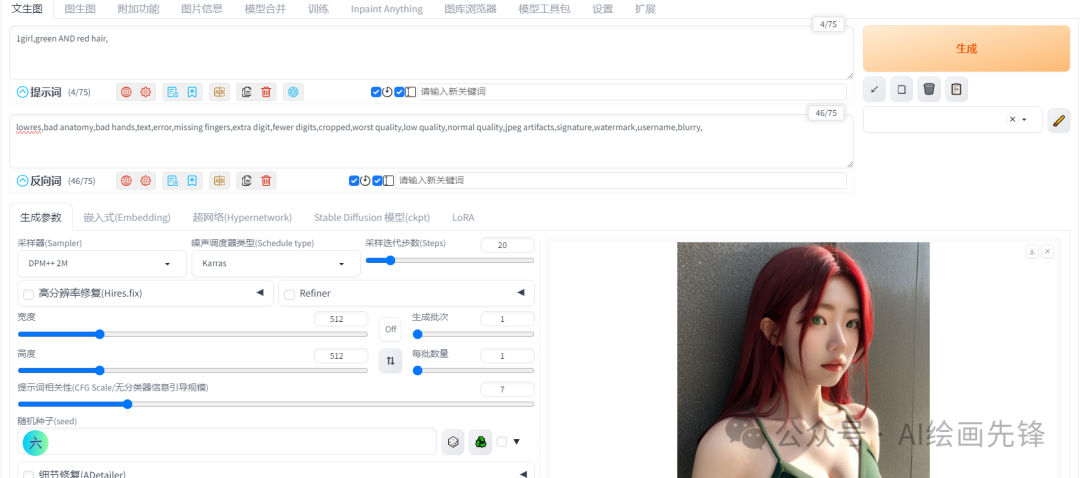
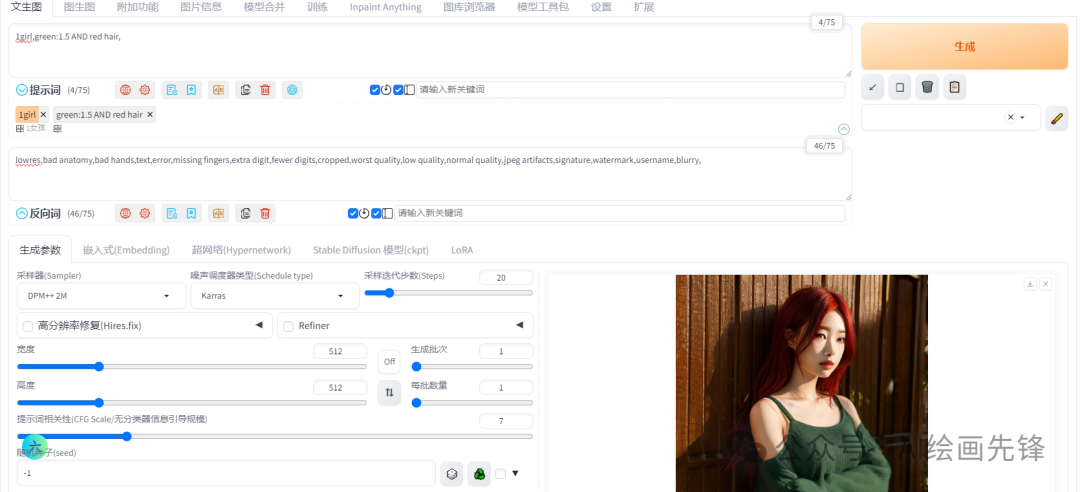
AND是以后右边的为主题,然后融合了AND左边的一点颜色。当提示词后面不输入数值的时候权重默认为1,你也可以在提示词后面冒号加数值的方式手动赋予权重:
我个人认为,组合语法更适合用于场景的融合。比如,当我输入的提示词是“熊猫”和“海洋”时,画面中虽然会同时出现熊猫和海洋的元素,但它们可能各自独立。
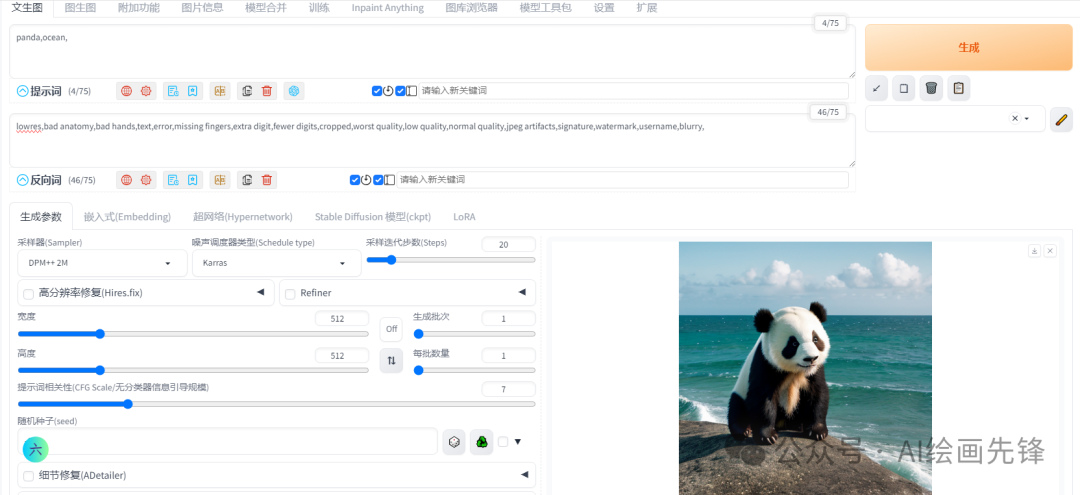
然而,当我使用“AND”将这两个提示词组合起来后,效果就仿佛是将一个熊猫的图像和一个海洋的图像融合在了一起,熊猫甚至会被呈现为在水中。
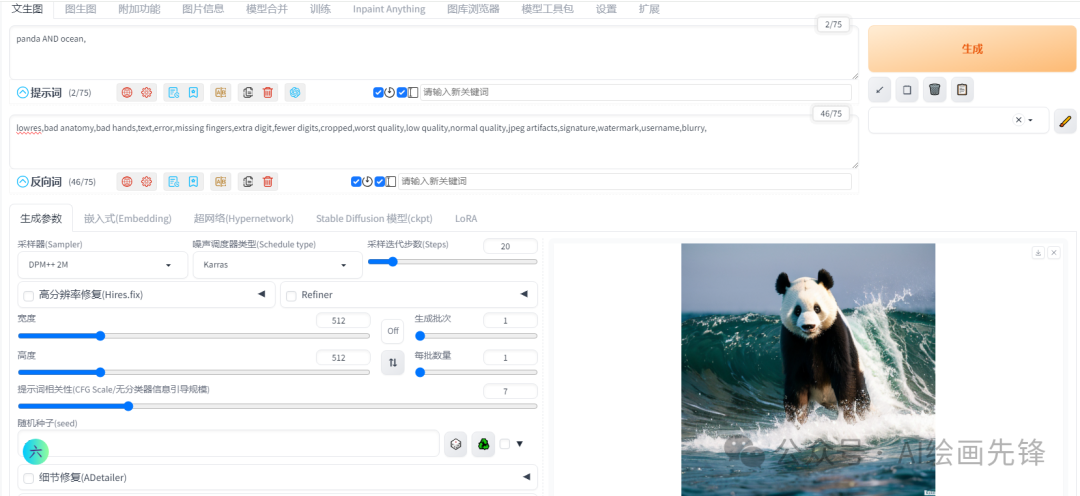
这两种现象也不是绝对的,多次抽卡,“熊猫”和“海洋”中间不加入AND,也可以抽卡出熊猫在水里的图片
2)and
将多个词缀聚合成一个提示词组,如:1girl,white hair and black hair
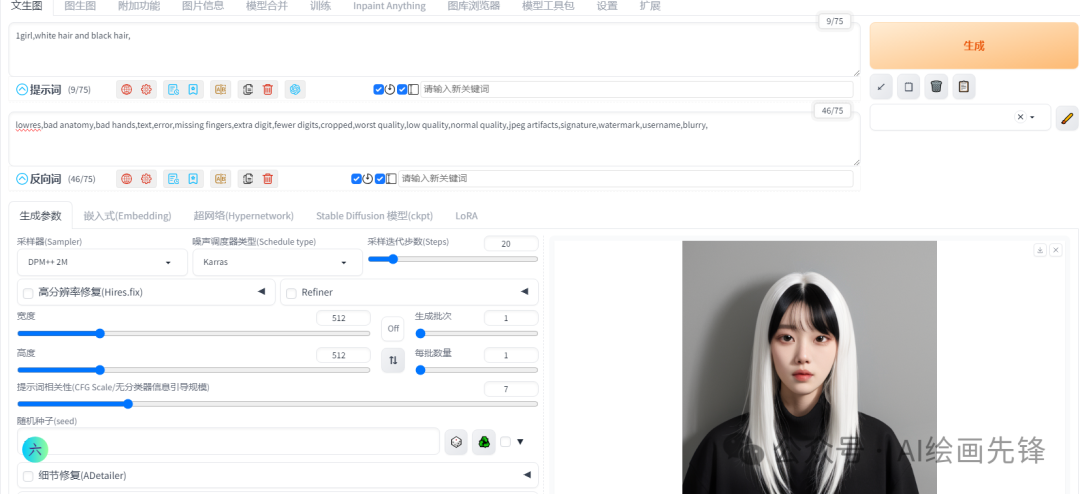
生成的头发每次抽卡没有规律,有时候是全部白头发,有时白头发中间有黑头发。也可以给每个关键词调整权重
查相关的资料说的是:and前后的初始权重一致,实际测试发现权重偏向于and前面的词
- 竖(|)
这个是交替渲染的一个连接词,我们可以看下效果
例如:1girl,(green|red|yellow) hair
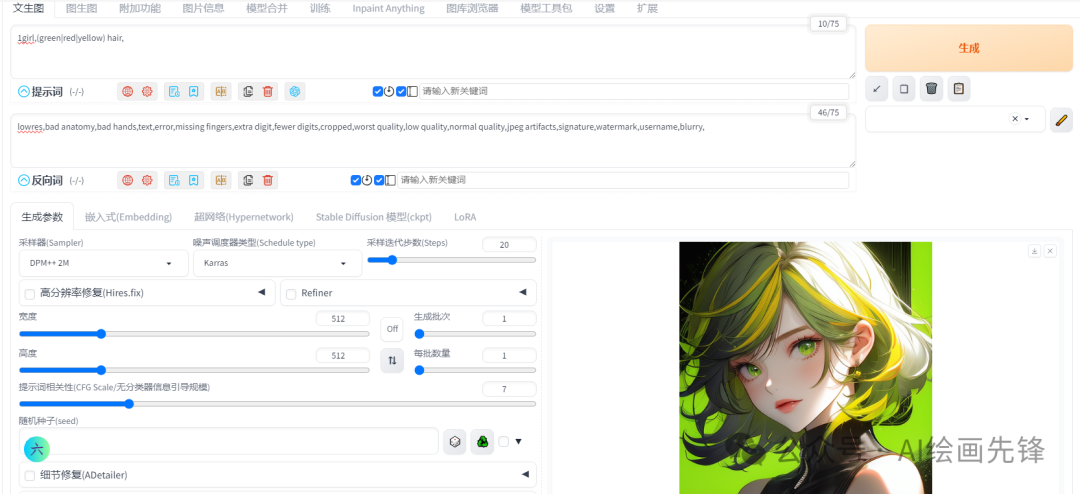
SD会先绘画绿色的头发,再将红色的头发渲染上去,最后再将黄色的头发渲染上去,会融合不同的颜色,不会有非常明显的颜色分块。抽卡生成图片的时候,绿色和红色会不太明显,偏重于黄色
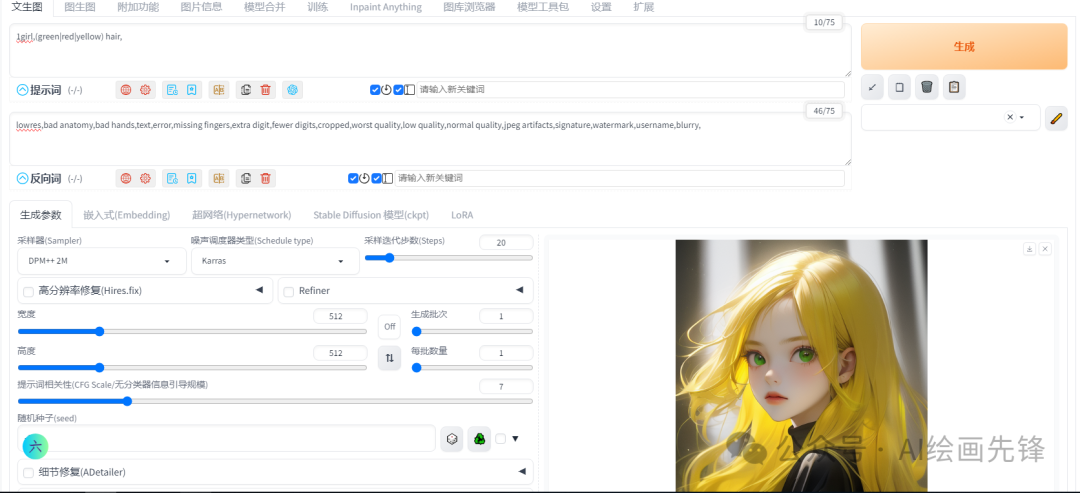
4)加号(+)
这个与AND连接符功能类似,
1girl,(green hair)+(red hair)+(yellow hair)
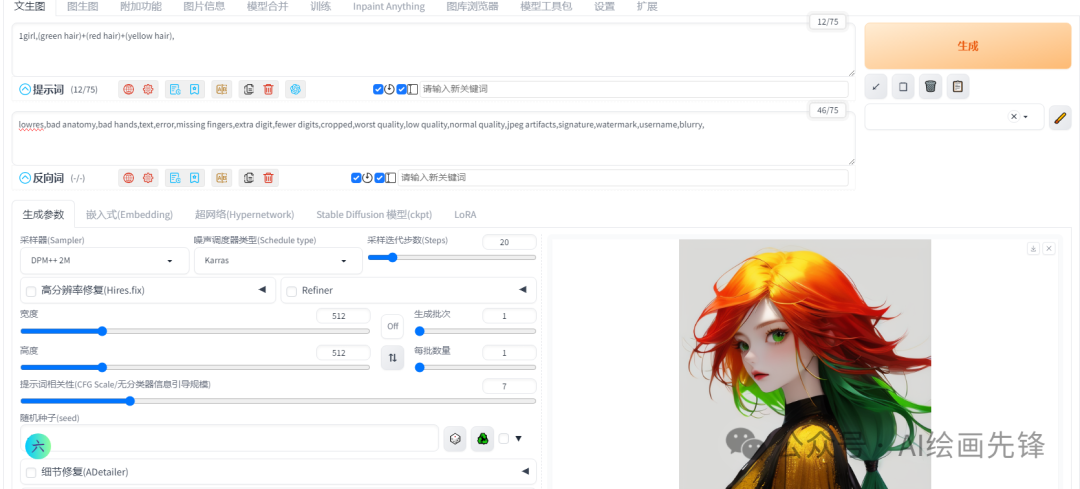
多个提示词进行融合后的图像
5)下划线(_)
会将多个关键词进行融合
1girl,(green hair)(red hair)(yellow hair)
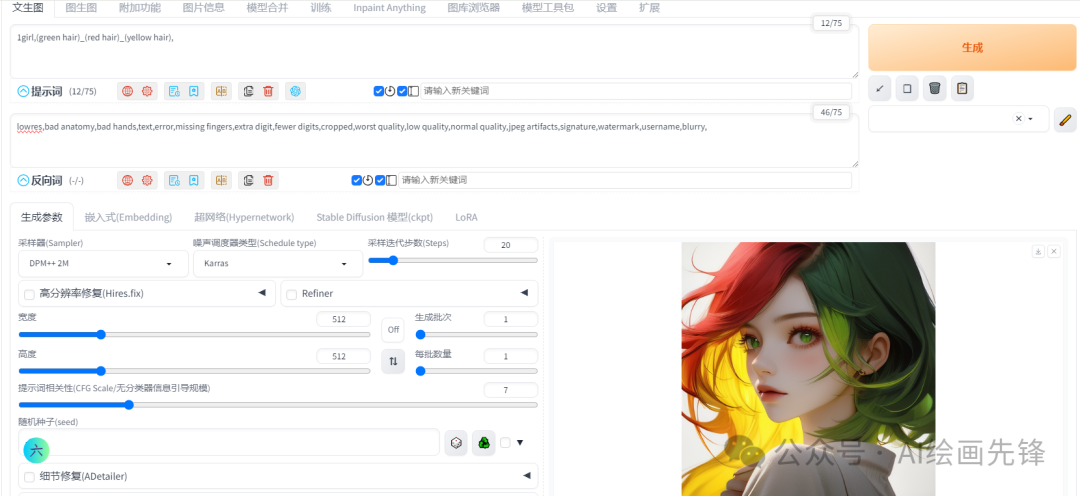
测试看and、+、_ 三个连接词的效果基本一样
06、*打断语法*


SD的语言模型具有结合上下文进行理解的能力,而“打断语法”则是一种用于切断前后提示词之间联系的技巧,其书写方式为大写字母“BREAK”。
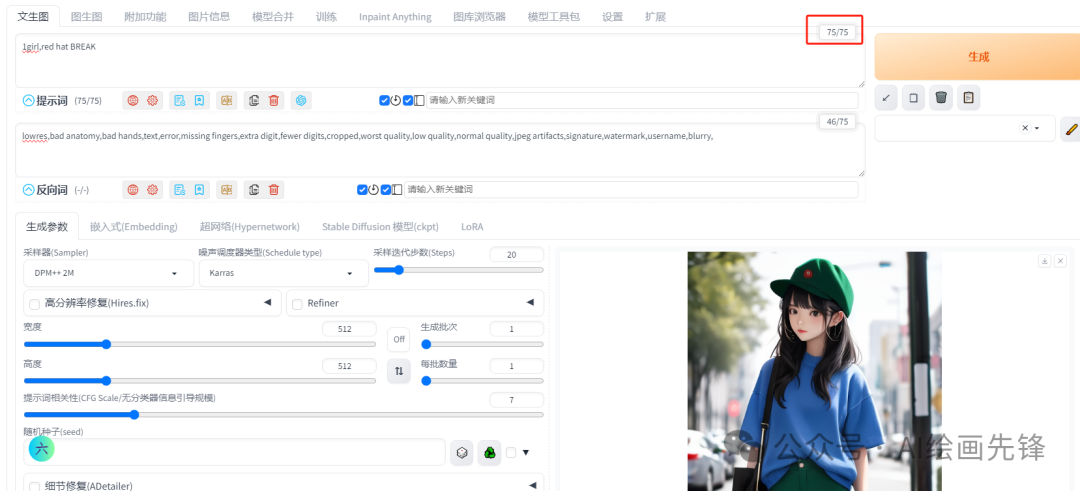
先看一个例子,提示词为“girl, red hat, blue clothes, green pants”:
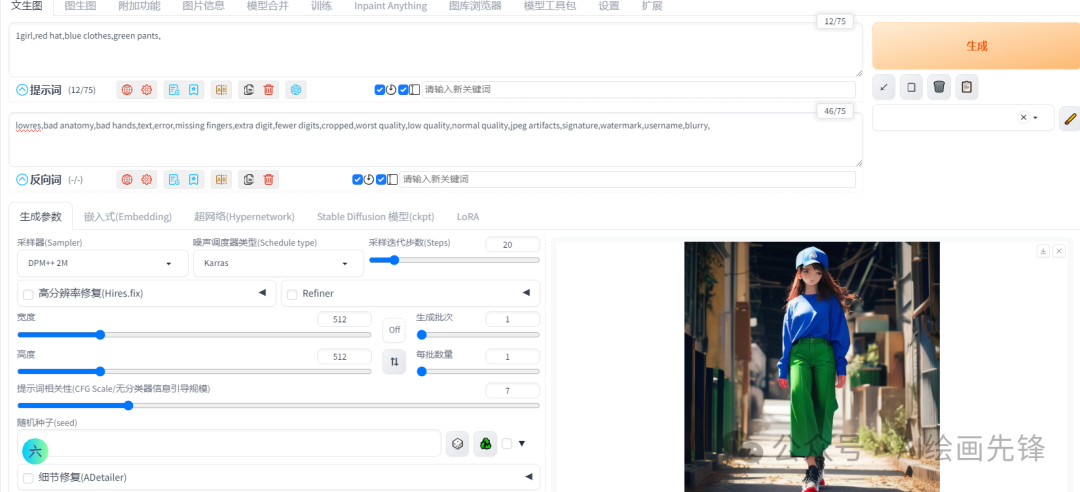
你会发现原本应该是红色的帽子变成了蓝色的帽子。这是由于“red hat”这个提示词受到了“blue clothes”的干扰和影响,导致颜色判断出现了偏差。这就是我们常说的“提示词污染”现象。值得注意的是,当前的tokens数量只有12个,而它们的最大值可以达到75个。
当我们在帽子和衣服之间加入BREAK这个打断语法观察一下,现在tokens的数量变成了81,最大值变成150:
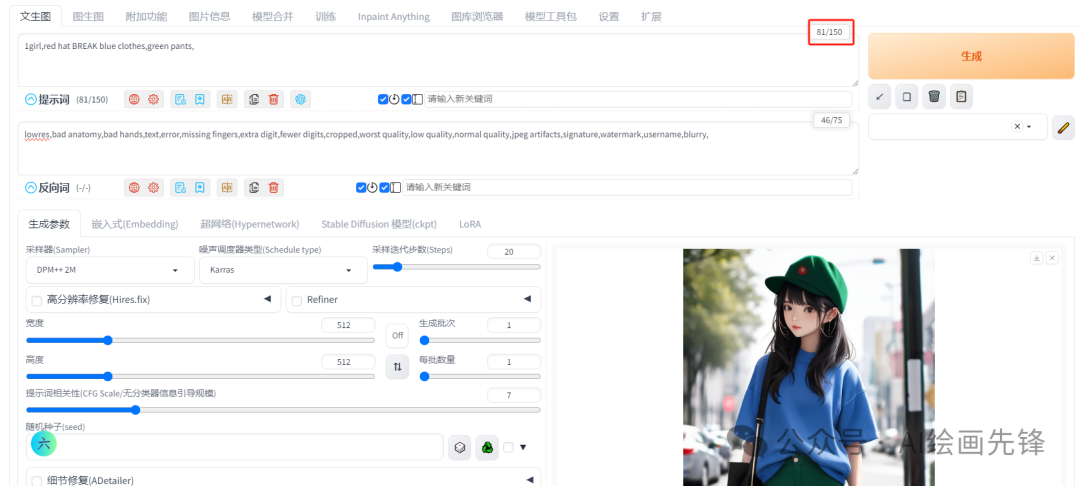
这就是打断语法发挥作用的原理。SD的标准处理方式是每75个tokens组成一个组,如果超出这个数量,就会被分割成两个组分别进行计算,然后再合并生成图像。
第75个tokens与第76个tokens之间的关联性相对较弱。而BREAK这个语法的作用就相当于强制将提示词填充到每组的75个tokens位置,从而打断前后提示词之间的关联性。
如果我们只保留BREAK语法之前的提示词,并删除其后的内容,那么tokens的数量就恰好达到了75个。
由于这种打断关联性的操作,在一定程度上可以减少提示词污染的情况,使得生成的图像更加符合我们的预期。
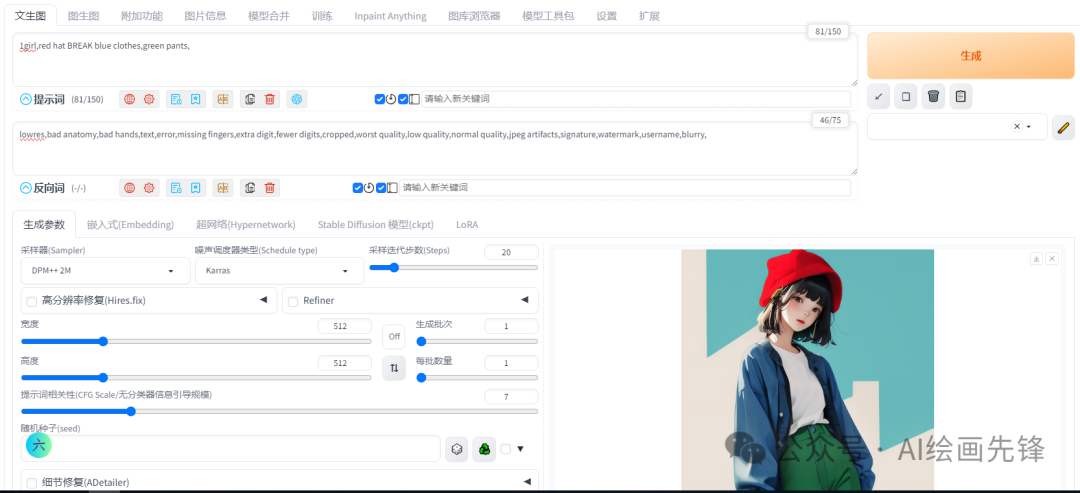
但是测试发现打断关联性后,red hat 的作用好像减弱了,变成随机生成帽子的颜色,抽卡多次才能抽取到红色的帽子,原因暂时还没研究出来。
07、调用Lora


调用Lora通常是由<>包围
1)、在SD界面点击Lora,会显示目前你已有的lora
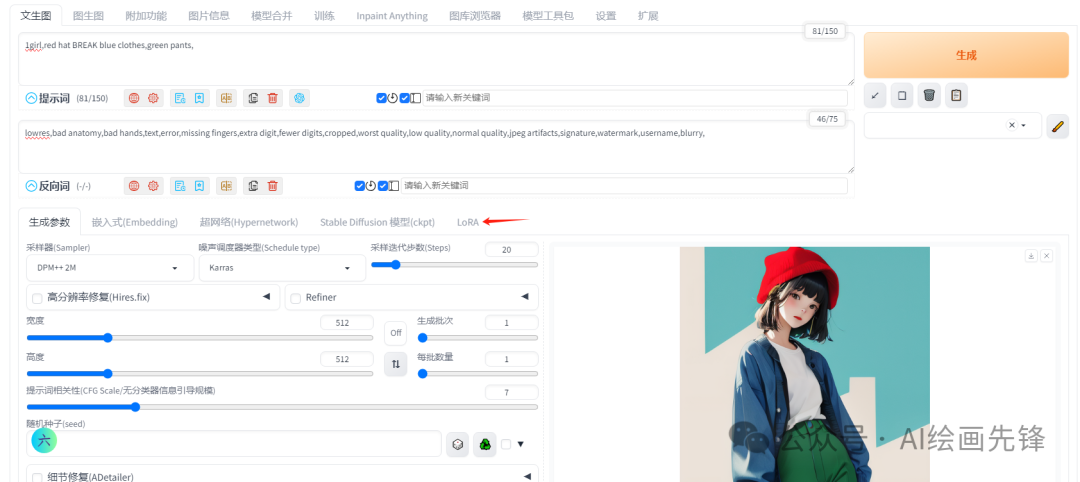
我们只需要点击需要使用的Lora,就可以在提示词里自动加载该Lora,
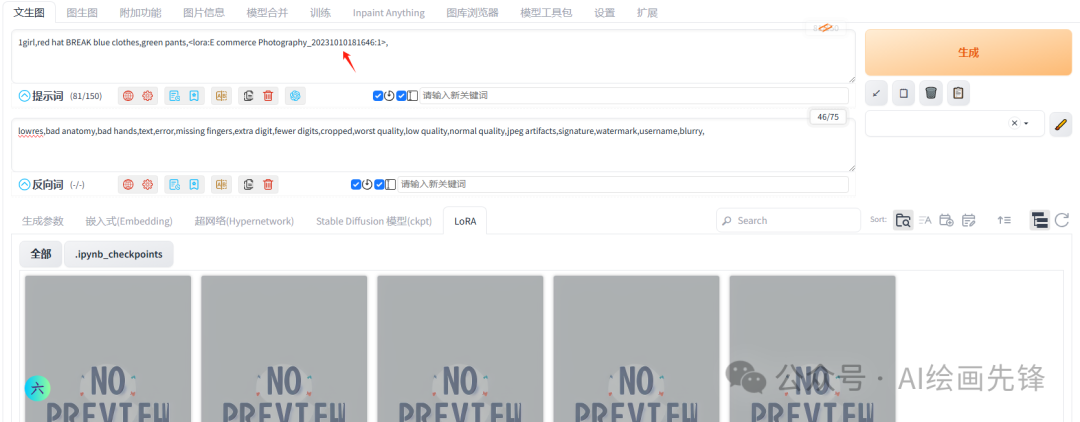
部分lora提示词需要触发词,在调用这个lora时,需要加入触发词
08、常用的提示词


1)、提高质量的正向提示词
| 正向提示词 | 描述 |
|---|---|
| HDR, UHD, 8K (HDR、UHD、4K、8K和64K) | 这样的质量词可以带来巨大的差异提升照片的质量 |
| best quality | 最佳质量 |
| masterpiece | 杰作 |
| Highly detailed | 画出更多详细的细节 |
| Studio lighting | 添加演播室的灯光,可以为图像添加一些漂亮的纹理 |
| ultra-fine painting | 超精细绘画 |
| sharp focus | 聚焦清晰 |
| physically-based rendering | 基于物理渲染 |
| extreme detail description | 极其详细的刻画 |
| Professional | 加入该词可以大大改善图像的色彩对比和细节 |
| Vivid Colors | 给图片添加鲜艳的色彩,可以为你的图像增添活力 |
| Bokeh | 虚化模糊了背景,突出了主体,像 iPhone 的人像模式 |
| (EOS R8, 50mm, F1.2, 8K, RAW photo:1.2) | 摄影师对相机设置的描述 |
| High resolution scan | 让你的照片具有老照片的样子赋予年代感 |
| Sketch | 素描 |
| Painting | 绘画 |
2)、艺术风格代表的提示词
| 艺术风格 | 艺术家 |
|---|---|
| 肖像画(Portraits) | Derek Gores, Miles Aldridge, Jean Baptiste-Carpeaux, Anne-Louis Girodet |
| 风景画(Landscape) | Alejandro Bursido, Jacques-Laurent Agasse, Andreas Achenbach, Cuno Amiet |
| 恐怖画(Horror) | H.R.Giger, Tim Burton, Andy Fairhurst, Zdzislaw Beksinski |
| 动漫画(Anime) | Makoto Shinkai, Katsuhiro Otomo, Masashi Kishimoto, Kentaro Miura |
| 科幻画(Sci-fi) | Chesley Bonestell, Karel Thole, Jim Burns, Enki Bilal |
| 摄影(Photography) | Ansel Adams, Ray Earnes, Peter Kemp, Ruth Bernhard |
| 概念艺术家(视频游戏)(Concept artists (video game)) | Emerson Tung, Shaddy Safadi, Kentaro Miura |
3)、常用的反向提示词
| 反向提示词 | 描述 |
|---|---|
| mutated hands and fingers | 变异的手和手指 |
| deformed | 畸形的 |
| bad anatomy | 解剖不良 |
| disfigured | 毁容 |
| poorly drawn face | 脸部画得不好 |
| mutated | 变异的 |
| extra limb | 多余的肢体 |
| ugly | 丑陋 |
| poorly drawn hands | 手部画得很差 |
| missing limb | 缺少的肢体 |
| floating limbs | 漂浮的四肢 |
| disconnected limbs | 肢体不连贯 |
| malformed hands | 畸形的手 |
| out of focus | 脱离焦点 |
| long neck | 长颈 |
| long body | 身体长 |
4)、镜头视角
| 提示词 | 描述 |
|---|---|
| dynamic angle | 动态角度 |
| from above | 从上方 |
| from below | 从下面 |
| wide shot | 广角宽景 |
| Aerial View | 空中俯瞰视图 |
5)、主体远近
| 提示词 | 描述 |
|---|---|
| full body shot | 全身 |
| cowboy shot | 半身 |
| close-up shot | 接近 |
6)、光线
| 提示词 | 描述 |
|---|---|
| cinematic lighting | 电影光 |
| dynamic lighting | 动感光 |
7)、主体视线
| 提示词 | 描述 |
|---|---|
| looking at viewer | 画面中的物体或人物在直接面对画面或观众 |
| looking at another | 两个角色正在相互交流或对视 |
| looking away | 看着别的方向,不直视对方 |
| looking back | 回头看 |
| looking up | 摄像机或观察者的视角调整为向上看 |
8)、画风
| 提示词 | 描述 |
|---|---|
| sketch, one-hour drawing challenge | 草图、速写、手绘风 |
| photograph, photorealistic | 照片 |
9)、表情
| 提示词 | 描述 |
|---|---|
| blush | 脸红 |
| wet sweat | 大汗 |
| flying sweatdrops | 飞汗 |
10)、服装
| 提示词 | 描述 |
|---|---|
| china dress | 旗袍 |
| sailor dress | 水手服 |
| school uniform | 校服 |
| sailor senshi uniform | 水手服 |
11)、风景指定
| 提示词 | 描述 |
|---|---|
| underwater | 水下 |
| shinto shrine | 神社 |
12)、姿势指定
| 提示词 | 描述 |
|---|---|
| hands on | hands on own face, hands on feet, hands on breast |
| kneeling | 跪下 |
| hand between legs | 腿夹手 |
| hair flip | 将头发向后或向一侧甩动的动作 |
| skirt flip | 裙子甩起来 |
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!
需要的可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

1.stable diffusion安装包 (全套教程文末领取哈)
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。
最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。

2.stable diffusion视频合集
我们在学习的时候,往往书籍代码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入门stable diffusion,科学有趣才能更方便的学习下去。

3.stable diffusion模型下载
stable diffusion往往一开始使用时图片等无法达到理想的生成效果,这时则需要通过使用大量训练数据,调整模型的超参数(如学习率、训练轮数、模型大小等),可以使得模型更好地适应数据集,并生成更加真实、准确、高质量的图像。

4.stable diffusion提示词
提示词是构建由文本到图像模型解释和理解的单词的过程。可以把它理解为你告诉 AI 模型要画什么而需要说的语言,整个SD学习过程中都离不开这本提示词手册。

5.AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

这份完整版的学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 23
23 0
0- 0



 已为社区贡献260条内容
已为社区贡献260条内容

所有评论(0)