小米音频大模型MiDashengLM开源:AI端侧生态的务实突破
当小米正式发布开源音频大模型MiDashengLM-7B时,业界清晰地看到这家科技巨头正以"读懂技术趋势、看懂生态需求、听懂用户声音"的三重认知,深度融入开源AI生态的建设浪潮。这款模型不仅延续了小米"紧贴业务场景、聚焦端侧创新"的技术路线,更通过差异化的音频理解能力,为AI硬件生态的全球化布局增添了关键拼图。2025年无疑是大模型技术从实验室走向产业应用的关键转折年。在这一背景下,小米集团对
当小米正式发布开源音频大模型MiDashengLM-7B时,业界清晰地看到这家科技巨头正以"读懂技术趋势、看懂生态需求、听懂用户声音"的三重认知,深度融入开源AI生态的建设浪潮。这款模型不仅延续了小米"紧贴业务场景、聚焦端侧创新"的技术路线,更通过差异化的音频理解能力,为AI硬件生态的全球化布局增添了关键拼图。
【免费下载链接】midashenglm-7b  项目地址: https://ai.gitcode.com/hf_mirrors/mispeech/midashenglm-7b
项目地址: https://ai.gitcode.com/hf_mirrors/mispeech/midashenglm-7b
2025年无疑是大模型技术从实验室走向产业应用的关键转折年。在这一背景下,小米集团对组织架构的调整颇具象征意义——"智能电动汽车等创新业务"部门正式更名为"智能电动汽车及AI等创新业务",标志着AI技术已从战略辅助升级为核心发展引擎。尽管小米自谦进入"大模型逐梦后半程",但其组建的AI团队展现出惊人的研发效率:从4月开源推理模型MiMo,到6月推出多模态大模型MiMo-VL,再到8月发布音频大模型MiDashengLM,平均每两个月便有一款核心模型问世,这种"小米速度"背后,是对开源生态价值的深刻理解和快速响应。
在当前AI技术的舆论场中,音频大模型常常处于"被忽视的关键赛道"。尽管阿里Qwen-Audio、OpenAI Whisper、Meta Wav2Vec等技术先驱已完成多代迭代,但市场关注度始终不及文本生成、图像创作等视觉冲击更强的领域。然而随着智能汽车、智能家居、可穿戴设备等终端形态的AI化进程加速,音频作为最自然的交互模态,其战略价值正日益凸显。小米在技术白皮书强调:"对于需要深度融入物理世界的智能体而言,全面的声音理解能力如同触觉之于人类,是构建环境感知的基础要素。"
传统音频处理技术的局限性在真实场景中暴露无遗。当前主流方案普遍存在"模态割裂"问题:语音识别模型专注于人类语言处理,音乐分析系统独立运行于音频轨道,而包含丰富场景信息的环境音往往被当作"噪声"过滤。小米AI实验室指出,真实世界的声音信号本就是语音、环境音、音乐的混合体——智能耳机需要同时处理用户指令、识别背景噪音并提取空间声学特征;车载系统必须在播放音乐时分辨紧急鸣笛;智能家居设备需要通过环境音变化感知异常情况。这种整体性认知推动MiDashengLM走上"通用音频理解"的技术路径。
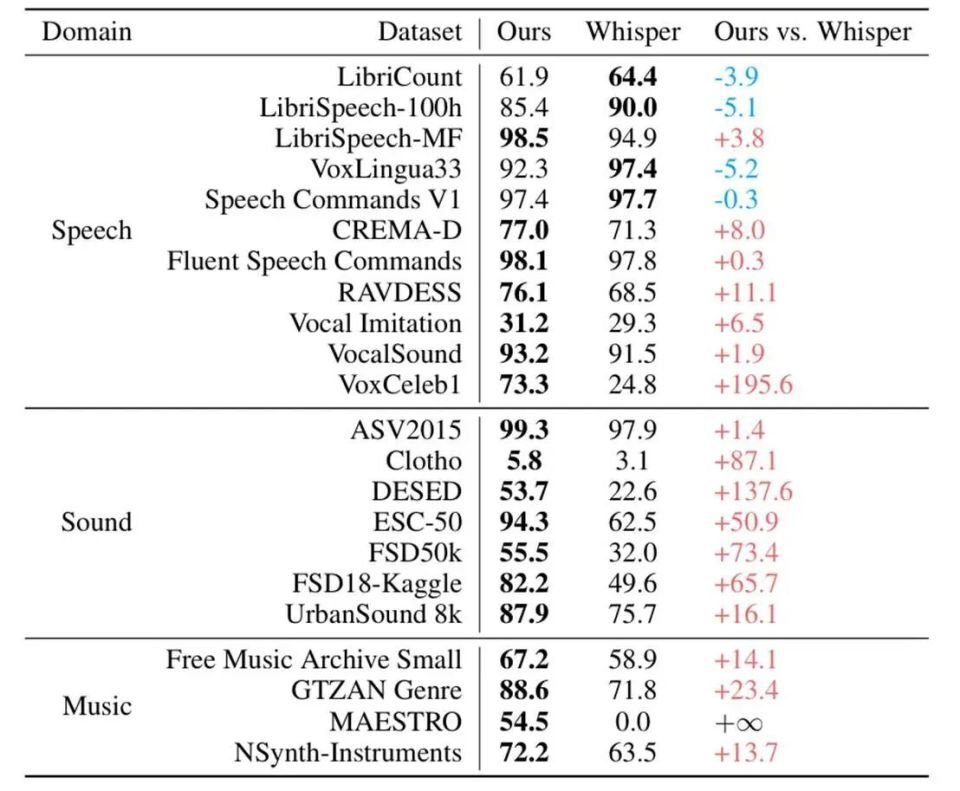 该对比表格系统呈现了MiDashengLM与Whisper-Large v3在11个专业数据集上的性能差异,直观展示了小米模型在非语音音频理解领域的显著优势。这种技术突破印证了小米"统一音频模态"研发思路的前瞻性,为端侧设备的多场景音频处理提供了更优解。
该对比表格系统呈现了MiDashengLM与Whisper-Large v3在11个专业数据集上的性能差异,直观展示了小米模型在非语音音频理解领域的显著优势。这种技术突破印证了小米"统一音频模态"研发思路的前瞻性,为端侧设备的多场景音频处理提供了更优解。
MiDashengLM的技术突破集中体现在三个维度:首先是构建了包含230万条标注数据的ACAVCaps高质量数据集,首次实现语音、环境音、音乐的混合标注;其次研发了自研音频编码器Dasheng,通过动态注意力机制实现不同音频模态的自适应处理;最终达成"一个模型架构、多种音频能力"的技术目标。在国际权威评测基准X-Ares上,Dasheng编码器展现出强劲的跨模态泛化能力:在说话人身份识别(VoxCeleb1数据集准确率92.3%)、室内声音事件检测(DESED数据集F1值87.6%)、环境声音分类(FSD50k数据集mAP值68.4%)和音乐演奏识别(MAESTRO数据集准确率89.7%)等非语音任务上全面领先Whisper,仅在传统语音识别场景中稍逊一筹,这种"全局最优"的性能曲线完美契合端侧设备的复杂应用需求。
深入分析小米开源模型矩阵(MiMo推理模型、MiMo-VL多模态模型、MiDashengLM音频模型),可以清晰梳理出两条战略主线:纵向深耕开源生态,横向赋能自身硬件场景。这一"双向奔赴"的策略,既避免了重复造轮子的资源浪费,又确保技术创新始终服务于业务价值。
参数规模的选择最能体现小米的务实风格。三款模型均以70亿参数为核心规格,这种"够用即好"的设计哲学,使其能够高效部署于手机、平板、汽车中控等消费级硬件。MiMo模型已实现文本推理能力的端侧化,在数学问题求解(GSM8K数据集准确率78.3%)和代码生成(HumanEval数据集Pass@1指标62.5%)任务上,性能超越OpenAI闭源模型o1-mini及阿里开源模型QwQ-32B-Preview,为智能助手的本地化运行奠定基础。
MiMo-VL则重点强化了"屏幕理解"这一差异化能力。该模型创新性地将GUI界面元素识别与多模态推理相结合,能够精准定位手机、平板、车载系统中的按钮、文本框、图标等交互组件,使智能体可直接基于视觉界面完成操作推理。这种能力使小米设备在"无代码自动化"场景中独具优势——用户只需描述需求,系统即可自动完成APP操作序列,极大降低智能交互的使用门槛。
而MiDashengLM的推出,标志着小米智能体"感知能力"的最后一块拼图正式就位。值得注意的是,尽管未针对多语种进行专项优化,该模型在印尼语、越南语、泰语等东南亚语言的音频理解任务上表现出显著优势,这一"意外收获"恰好呼应了小米"人车家全生态"的全球化战略,为其硬件产品在新兴市场的本地化竞争提供了技术支撑。
小米在模型研发过程中展现出的"生态协作"智慧尤为可贵。MiMo系列明确借鉴DeepSeek的MTP(多token预测)技术,并优化GRPO强化学习算法;MiMo-VL的视觉编码器直接采用Qwen2.5-ViT架构;MiDashengLM的文本解码器基于Qwen2.5-Omni-7B构建,ACAVCaps数据集的注释语料则由DeepSeek-R1辅助生成。这种"站在巨人肩膀上创新"的策略,使小米能够将资源集中于音频理解等差异化领域,最终又通过Apache 2.0许可协议将成果回馈开源社区,形成"贡献-受益-再贡献"的良性循环。
小米的开源实践恰逢AI生态加速繁荣的黄金时期。几乎在MiDashengLM发布的同一时段,阿里开源Qwen-Image模型攻克了中文文本图像生成的"鬼画符"难题,实现复杂排版与精确渲染;腾讯Hunyuan系列一次性开源4款端侧模型(参数规模覆盖5亿至70亿),均支持消费级显卡运行。这些进展共同指向一个清晰趋势:AI产业正通过"开源模型+端侧智能"的双轮驱动,构建区别于SaaS化路线的特色发展路径。
OpenAI CEO奥特曼预言的AI应用"SaaS快时尚化"时代,本质上是企业服务领域优势的延续。但市场有着不同的技术渗透路径——跳过PC时代直接拥抱移动互联网的独特经历,既造成企业级SaaS生态的相对滞后,也催生了全球最活跃的智能终端创新。在Web端AI应用面临标准化瓶颈的当下,企业完全可能在智能汽车座舱系统、全屋智能交互、可穿戴健康监测等终端场景中,定义新一代AI交互范式。
小米通过MiDashengLM的开源实践,不仅验证了"小而美"模型在端侧场景的商业价值,更探索出一条"业务需求牵引技术创新,开源协作加速生态成熟"的可行路径。随着更多硬件厂商、开发者基于这些开源模型进行二次创新,AI产业有望形成"模型开源-硬件落地-数据反馈-模型迭代"的正向循环,在全球AI竞赛中开辟出独具特色的"端侧智能"新赛道。
【免费下载链接】midashenglm-7b 项目地址: https://ai.gitcode.com/hf_mirrors/mispeech/midashenglm-7b

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 5
5 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)