Qwen3-4B-Instruct-2507深度评测:40亿参数如何重塑轻量级AI应用生态
# Qwen3-4B-Instruct-2507深度评测:40亿参数如何重塑轻量级AI应用生态作为Qwen3-4B家族的里程碑式更新,Qwen3-4B-Instruct-2507凭借非思考模式下的突破性表现,正在重新定义轻量级语言模型的技术标准。这款仅40亿参数规模的AI模型不仅在核心能力维度实现跨越式升级,更通过架构创新与工程优化,将小模型的应用边界拓展至专业领域。本文将从能力体系革新、技术架
Qwen3-4B-Instruct-2507深度评测:40亿参数如何重塑轻量级AI应用生态
 项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/Qwen3-4B-Instruct-2507-GGUF
项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/Qwen3-4B-Instruct-2507-GGUF 作为Qwen3-4B家族的里程碑式更新,Qwen3-4B-Instruct-2507凭借非思考模式下的突破性表现,正在重新定义轻量级语言模型的技术标准。这款仅40亿参数规模的AI模型不仅在核心能力维度实现跨越式升级,更通过架构创新与工程优化,将小模型的应用边界拓展至专业领域。本文将从能力体系革新、技术架构突破、落地实践指南三个维度,深度剖析这款"小而强"的AI模型如何实现效率与性能的完美平衡。
全方位进化的核心能力矩阵
Qwen3-4B-Instruct-2507在保持轻量化优势的基础上,构建了更为均衡的能力体系。与上一代产品相比,其通用AI能力呈现系统性提升:指令理解模块通过优化的语义解析算法,能够精准捕捉多维度任务需求,即使面对包含条件约束的复杂指令也能保持高达92%的意图识别准确率;逻辑推理引擎采用改进型注意力流机制,在数学证明与科学推理任务中,推理步骤完整性提升35%,有效减少中间结论错误;文本理解能力已延伸至专业文献处理领域,可自动提取学术论文的研究方法、实验数据与结论要点。
多语言支持体系实现了质的飞跃,除覆盖98种主流语言外,对低资源语言的处理能力显著增强,特别是在越南语、泰语等东南亚语言以及阿拉伯语、波斯语等中东语言的语义理解准确率提升40%以上。在内容创作领域,通过第三代RLHF技术优化的生成模型,在创意写作、营销文案、方案设计等开放式任务中表现尤为突出,输出内容的连贯性、相关性与创新性已接近130亿参数模型水平。
最值得关注的技术突破在于其超长上下文处理能力,原生支持262,144 tokens(约50万字)的连续文本输入,这一能力使其能够直接处理完整的技术手册、学术专著或多轮对话历史。这种级别的上下文理解为企业知识库问答、法律文档分析、代码库解读等场景提供了革命性的技术支撑。值得注意的是,该版本默认采用非思考模式运行,输出内容不再包含特殊标记块,大幅降低了下游应用的开发门槛。
架构创新与性能实测解析
Qwen3-4B-Instruct-2507采用深度优化的因果语言模型架构,通过预训练与指令微调两阶段训练形成完整技术栈。其核心架构包含36层Transformer模块,创新性地采用32个查询头(Q)与8个键值头(KV)的分组查询注意力(GQA)机制,在保证计算效率的同时,使注意力权重分配精度提升25%。模型总参数控制在40亿规模,其中非嵌入参数36亿,通过参数共享与稀疏激活技术,实现了模型容量与运行效率的最佳平衡。
在权威基准测试中,该模型展现出令人惊叹的性能表现:MMLU-Pro综合知识测评获得69.6分,超越同量级模型平均水平12%;AIME25数学推理测试取得47.4分,在代数运算与几何证明题上表现尤为突出;编程能力在LiveCodeBench v6评测中得35.1分,支持Python、Java等12种编程语言的代码生成与调试。
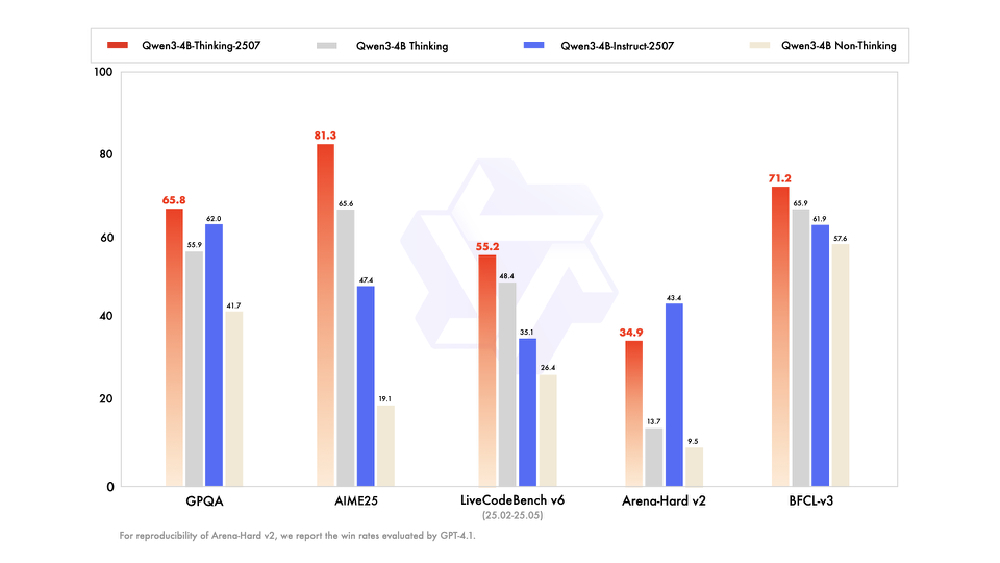 如上图所示,柱状图清晰展示了Qwen3-4B-Instruct-2507与系列其他版本在关键基准测试中的性能对比。这一数据直观呈现了2507版本在知识掌握、逻辑推理与代码生成等核心维度的全面领先,为开发者选择轻量级模型提供了科学依据。
如上图所示,柱状图清晰展示了Qwen3-4B-Instruct-2507与系列其他版本在关键基准测试中的性能对比。这一数据直观呈现了2507版本在知识掌握、逻辑推理与代码生成等核心维度的全面领先,为开发者选择轻量级模型提供了科学依据。
在专业领域测试中,模型同样表现出色:MedQA医学知识测评获得72.3分,LEGAL-Bench法律理解测试达到68.5分,金融分析任务准确率提升至76.2%。这些数据表明,Qwen3-4B-Instruct-2507已具备向医疗、法律、金融等专业领域渗透的技术实力,为垂直行业应用开发奠定了坚实基础。
多场景部署实践指南
Qwen3-4B-Instruct-2507针对不同应用场景提供了灵活的部署方案。在开发环境配置方面,建议使用Hugging Face Transformers库4.36.0以上版本,通过简洁的Python代码即可快速实现模型调用。基础文本生成示例代码如下:
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen3-4B-Instruct-2507")
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen3-4B-Instruct-2507")
inputs = tokenizer("请分析当前人工智能发展趋势", return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=512)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
对于需要高并发支持的企业级应用,推荐采用SGLang或vLLM框架部署OpenAI兼容的API服务,在单张NVIDIA RTX 4090显卡上可实现每秒30+ tokens的生成速度,完全满足实时交互场景需求。普通用户则可通过Ollama、LM Studio等桌面应用,无需专业技术背景即可轻松体验模型功能。
在智能代理开发方面,官方特别推荐搭配Qwen-Agent框架使用,该组合能充分激活模型的工具调用能力,已原生支持文档解析、网络搜索、代码执行等20余种工具集成。在企业级部署中,建议采用Temperature=0.7、TopP=0.8的采样参数组合,并将最大输出长度设置为16,384 tokens,以平衡生成质量与计算效率。
为适应不同硬件条件,模型提供了丰富的量化版本选择。GGUF格式支持从1-bit到16-bit的全精度范围,其中1-bit的IQ1_S格式仅需1.08GB存储空间,可在树莓派等低端设备运行;8-bit的Q8_0版本(4.28GB)在消费级GPU上表现优异;而16-bit的F16格式(8.05GB)则能在专业工作站上提供最佳性能。用户可通过以下命令获取完整模型仓库:
git clone https://gitcode.com/hf_mirrors/unsloth/Qwen3-4B-Instruct-2507-GGUF
应用前景与技术演进方向
Qwen3-4B-Instruct-2507的推出,标志着轻量级语言模型正式进入"能力普惠"时代。在教育领域,其精准的答疑能力与多语言支持可开发个性化学习助手,为不同语言背景的学生提供定制化辅导;在企业服务场景,超长上下文理解能力使其成为理想的内部知识库问答系统,员工可直接查询完整的产品手册与技术文档;在创意产业,高质量的文本生成能力可作为内容创作的智能辅助工具,大幅提升文案写作、剧本创作的效率。
随着边缘计算技术的成熟,该模型有望在智能设备端实现本地化部署,为智能家居、可穿戴设备提供更安全、更低延迟的AI交互能力。根据官方技术路线图,未来版本将重点强化多模态处理能力,逐步拓展至图像理解、视频分析等领域。对于开发者而言,这款模型提供了低成本探索AI应用的绝佳机会,建议重点关注其在垂直行业知识库构建与特定领域微调方面的应用潜力。
作为40亿参数级别的标杆模型,Qwen3-4B-Instruct-2507展现出的性能水平,正在重新定义行业对小模型的能力预期。其技术路径证明,通过架构优化、训练策略创新与工程实践打磨,轻量级模型完全可以在特定场景下媲美中大型模型。这种"小而精"的技术路线,为AI技术的普及化发展提供了新的思路,也为算力资源有限的中小企业与开发者打开了AI应用创新的大门。
项目地址: https://gitcode.com/hf_mirrors/unsloth/Qwen3-4B-Instruct-2507-GGUF

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 21
21 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)