调用讯飞星火认知大模型实现问答
初始化一个用于处理讯飞星火大模型 WebSocket 认证的类,接收四个参数:APPID(应用ID)、APIKey(API密钥)、APISecret(API密钥对应的密钥)和 Spark_url(API地址),再使用 urlparse 解析 URL,获取主机名(host)和路径(path)。需要将‘YOUR_APPID'、’YOUR_API_KEY'、‘YOUR_API_SECRET'替换为自己的
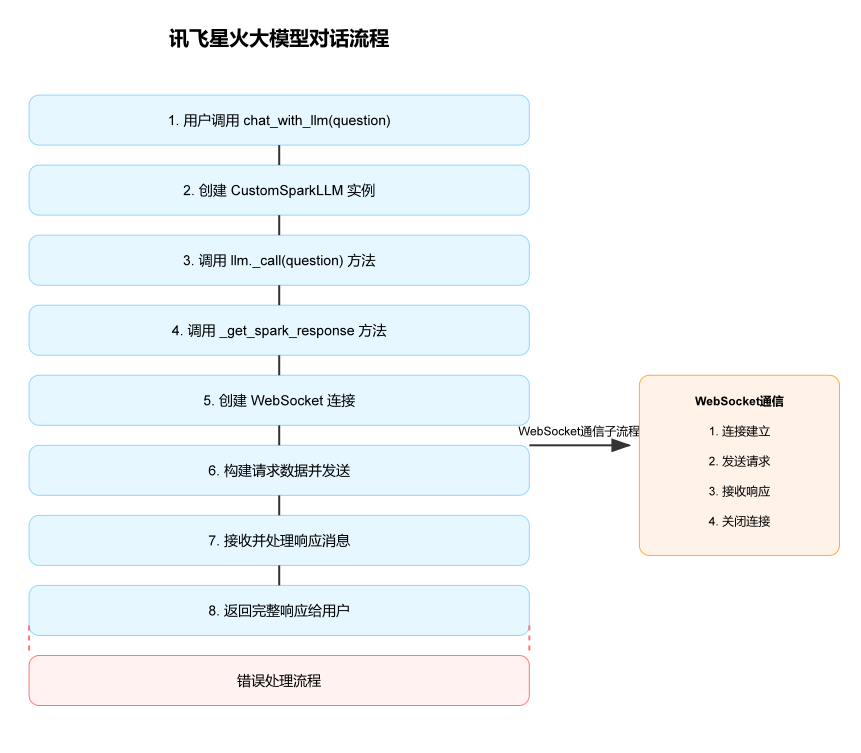
本次通过使用Websocket协议调用星火认知大模型api实现问答功能,首先需要设置环境变量:
os.environ['SPARK_APPID'] = 'YOUR_APPID'
os.environ['SPARK_API_KEY'] = 'YOUR_API_KEY'
os.environ['SPARK_API_SECRET'] = 'YOUR_API_SECRET'需要将‘YOUR_APPID'、’YOUR_API_KEY'、‘YOUR_API_SECRET'替换为自己的相应信息,获取这些信息,需要进入讯飞控制台,选择自己使用的版本,右侧可以看的所需要的信息。
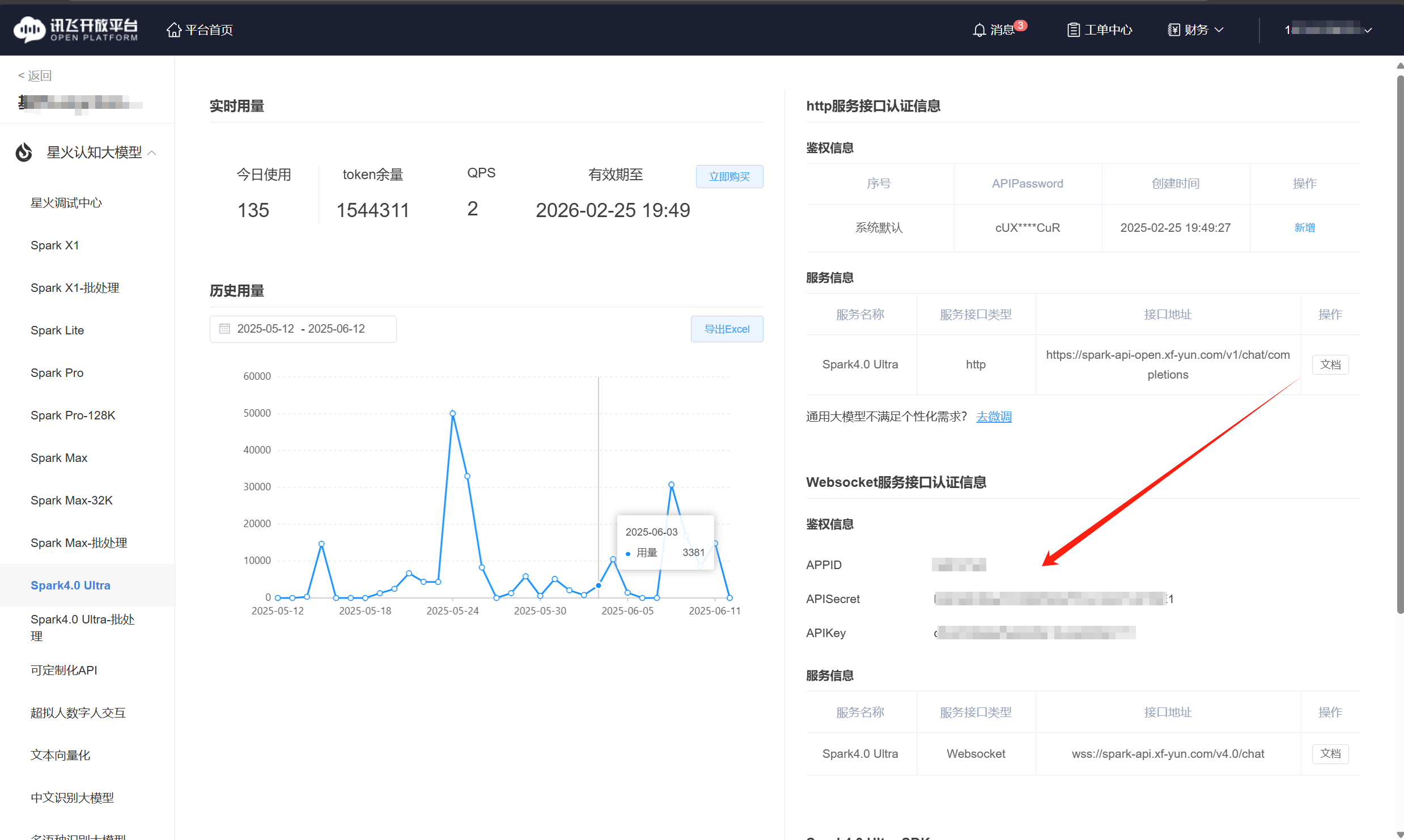
初始化一个用于处理讯飞星火大模型 WebSocket 认证的类,接收四个参数:APPID(应用ID)、APIKey(API密钥)、APISecret(API密钥对应的密钥)和 Spark_url(API地址),再使用 urlparse 解析 URL,获取主机名(host)和路径(path)。
class Ws_Param(object):
def __init__(self, APPID, APIKey, APISecret, Spark_url):
self.APPID = APPID
self.APIKey = APIKey
self.APISecret = APISecret
self.host = urlparse(Spark_url).netloc
self.path = urlparse(Spark_url).path
self.Spark_url = Spark_url按照星火认知模型文档要求生成时间戳,首先获取当前时间,再将时间转换为 RFC1123 格式(例如:Thu, 12 Jun 2025 08:00:49 GMT)。
now = datetime.now()
formatted_date = format_date_time(mktime(now.timetuple()))构造签名原文,按照讯飞API的要求,拼接签名字符串,包含三个部分:host、date 和请求行(GET + 路径 + HTTP版本),每部分用换行符分隔。
signature_origin = "host: " + self.host + "\n"
signature_origin += "date: " + formatted_date + "\n"
signature_origin += "GET " + self.path + " HTTP/1.1"使用 HMAC-SHA256 算法对签名原文进行加密,使用 APISecret 作为密钥,将结果进行 Base64 编码。
signature_sha = hmac.new(self.APISecret.encode('utf-8'),
signature_origin.encode('utf-8'),
digestmod=hashlib.sha256).digest()
signature_sha_base64 = base64.b64encode(signature_sha).decode(encoding='utf-8')构建认证头信息,包含:api_key:API密钥,algorithm:使用的加密算法(hmac-sha256)、headers:参与签名的头部字段、signature:生成的签名,对整个认证头进行 Base64 编码。
authorization_origin = f'api_key="{self.APIKey}", algorithm="hmac-sha256", headers="host date request-line", signature="{signature_sha_base64}"'
authorization = base64.b64encode(authorization_origin.encode('utf-8')).decode(encoding='utf-8')将认证信息组合成字典,使用 urlencode 将字典转换为 URL 查询字符串,将查询字符串附加到原始 URL 后面,从而生成最终URL。
v = {
"authorization": authorization,
"date": formatted_date,
"host": self.host
}
return self.Spark_url + '?' + urlencode(v)完整代码:
class Ws_Param(object):
def __init__(self, APPID, APIKey, APISecret, Spark_url):
self.APPID = APPID
self.APIKey = APIKey
self.APISecret = APISecret
self.host = urlparse(Spark_url).netloc
self.path = urlparse(Spark_url).path
self.Spark_url = Spark_url
def create_url(self):
now = datetime.now()
formatted_date = format_date_time(mktime(now.timetuple()))
signature_origin = "host: " + self.host + "\n"
signature_origin += "date: " + formatted_date + "\n"
signature_origin += "GET " + self.path + " HTTP/1.1"
signature_sha = hmac.new(self.APISecret.encode('utf-8'),
signature_origin.encode('utf-8'),
digestmod=hashlib.sha256).digest()
signature_sha_base64 = base64.b64encode(signature_sha).decode(encoding='utf-8')
authorization_origin = f'api_key="{self.APIKey}", algorithm="hmac-sha256", headers="host date request-line", signature="{signature_sha_base64}"'
authorization = base64.b64encode(authorization_origin.encode('utf-8')).decode(encoding='utf-8')
v = {
"authorization": authorization,
"date": formatted_date,
"host": self.host
}
return self.Spark_url + '?' + urlencode(v)接下来将构建CustomSparkLLM(LLM)方法,此方法继承自 LangChain 的 LLM 基类,其中需要定义必要的认证信息:appid、api_key、api_secret,同时设置讯飞星火大模型的 WebSocket URL 和模型版本(我选择4.0Ultra)
class CustomSparkLLM(LLM):
appid: str = Field(default_factory=lambda: os.environ['SPARK_APPID'])
api_key: str = Field(default_factory=lambda: os.environ['SPARK_API_KEY'])
api_secret: str = Field(default_factory=lambda: os.environ['SPARK_API_SECRET'])
spark_url: str = "wss://spark-api.xf-yun.com/v4.0/chat"
domain: str = "4.0Ultra"https://www.xfyun.cn/doc/spark/Web.html#_1-%E6%8E%A5%E5%8F%A3%E8%AF%B4%E6%98%8E
进入上述链接查看所选择版本的请求地址。
添加LLM类型标识,标识这是一个讯飞星火大模型,实现 LangChain 要求的 _llm_type 属性
@property
def _llm_type(self) -> str:
return "spark"创建主要调用方法,实现 LangChain 的 _call 方法,同时接收用户输入的问题,返回模型的回答。
def _call(self, prompt: str, stop=None) -> str:
response = self._get_spark_response(prompt)
return responseWebSocket 响应获取流程包括创建连接并设置回调函数以处理连接事件。
def _get_spark_response(self, prompt: str) -> str:
wsParam = Ws_Param(self.appid, self.api_key, self.api_secret, self.spark_url)
wsUrl = wsParam.create_url()
ws = websocket.WebSocketApp(
wsUrl,
on_message=self._on_message,
on_error=self._on_error,
on_close=self._on_close,
on_open=self._on_open
)创建连接状态管理,将必要的参数附加到 WebSocket 对象上,初始化响应存储和连接状态标志。
ws.appid = self.appid
ws.api_key = self.api_key
ws.api_secret = self.api_secret
ws.domain = self.domain
ws.prompt = prompt
ws.response = ""
ws.is_closed = False设置超时处理,实现30秒超时机制,防止连接无限等待。
timeout = 30 # 设置30秒超时
start_time = time.time()
while not ws.is_closed and time.time() - start_time < timeout:
time.sleep(0.1)进行消息处理,理接收到的消息,检查响应状态码,累积响应内容,在回答完成时关闭连接。
def _on_message(self, ws, message):
try:
data = json.loads(message)
if data["header"]["code"] != 0:
ws.response = f"Error: {data['header']['message']}"
ws.close()
return
content = data["payload"]["choices"]["text"][0]["content"]
ws.response += content
if data["header"]["status"] == 2:
ws.close()完善错误处理、连接关闭处理,处理连接错误并记录错误信息并关闭连接;标记连接已关闭
,检测是否超时。
def _on_error(self, ws, error):
ws.response = f"Error: {str(error)}"
ws.close()def _on_close(self, ws, close_status_code, close_msg):
ws.is_closed = True完成以上步骤就可以进行发送请求了,在连接建立时发送请求,设置好模型参数:
- temperature: 0.88(控制回答的随机性)
- max_tokens: 4096(最大输出长度)
def _on_open(self, ws):
data = {
"header": {
"app_id": ws.appid,
"uid": "12345"
},
"parameter": {
"chat": {
"domain": ws.domain,
"temperature": 0.88,
"max_tokens": 4096
}
},
"payload": {
"message": {
"text": [
{"role": "user", "content": ws.prompt}
]
}
}
}
ws.send(json.dumps(data))建立测试对话,实验代码是否实现了与其功能。
if __name__ == "__main__":
question = "我是一名大学生"
response = chat_with_llm(question)
print(f"问题: {question}")
print(f"回答: {response}") 可在终端看到运行结果,即使运行成功,后续可按照各自预期修改大模型参数。
问题: 我是一名大学生
回答: 那很棒呀!大学生活丰富多彩,充满了各种学习和成长的机会呢。你可以参 加各种社团活动拓展兴趣,结交志同道合的朋友,在学业上也能深入钻研专业知识 ,为未来打下坚实的基础。你学的是什么专业呀?
火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 19
19 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)