人工智能能预测未来吗?LLM 代理的下一个前沿领域!FutureX
通过提供一个公平、动态、极具挑战性的评估平台,我们希望激励学术界和工业界的研究人员共同开发下一代人工智能代理,在复杂、高风险、现实世界的领域中,能够与专业人类分析师的水平相媲美,甚至超越。模型在 4 级任务(开放式、高波动性)上的得分特别低,这有力地验证了基准的难度分层是准确的,并且可以有效地衡量从基本回忆到复杂推理的一系列能力。这正是我们希望 AI 具备的终极能力。通过查看模型的预测与共识之间的
在过去的几年里,大型语言模型(LLM)取得了惊人的进步。它们不再只是文本生成器,而是逐渐演变成能够规划、使用工具以及与现实世界交互的自主“代理”。然而,摆在我们面前的一个尖锐问题是:我们如何才能真正评估这些智能体的核心情报?现有的基准测试,如 GAIA 和 Browsercamp,虽然很有价值,但大多是静态的。这意味着他们的问题和答案是固定的,并且很容易包含在模型的大量训练数据中,从而导致评估结果失真。更重要的是,他们要求人工智能解决已知的问题。因此,我们介绍 FutureX,一个 live benchmark designed for predicting unknown future .
预测未来需要代理,就像人类专家一样,在充满不确定性的动态环境中收集信息、分析趋势并做出决策。这正是我们希望 AI 具备的终极能力。然而,为此目的建立公平、未受污染的评估标准充满了方法和技术挑战。
愿景 #
我们坚信,FutureX 有潜力成为 LLM 智能体发展的关键驱动力。通过提供一个公平、动态、极具挑战性的评估平台,我们希望激励学术界和工业界的研究人员共同开发下一代人工智能代理,在复杂、高风险、现实世界的领域中,能够与专业人类分析师的水平相媲美,甚至超越。我们的工作才刚刚开始。我们欢迎您阅读我们的技术报告以了解更多详细信息,并与我们一起探索人工智能的未来。
什么是 FutureX?#
FutureX 是未来预测的动态、实时基准测试,建立在以下核心功能之上:
- 无数据污染: 通过要求预测未来事件,它确保答案不能存在于任何模型的训练数据中。每周大约有 500 个新活动 。
- 现实世界的挑战: 代理分析实时的真实世界信息,以预测未来事件,而不是在模拟中作。
- 大型: 利用覆盖多个域的 195 个高质量资源 (选自 2,000 多个网站 )。
- 全自动管道: 闭环系统自动收集问题,每天运行 27 个代理 ,并对结果进行评分。
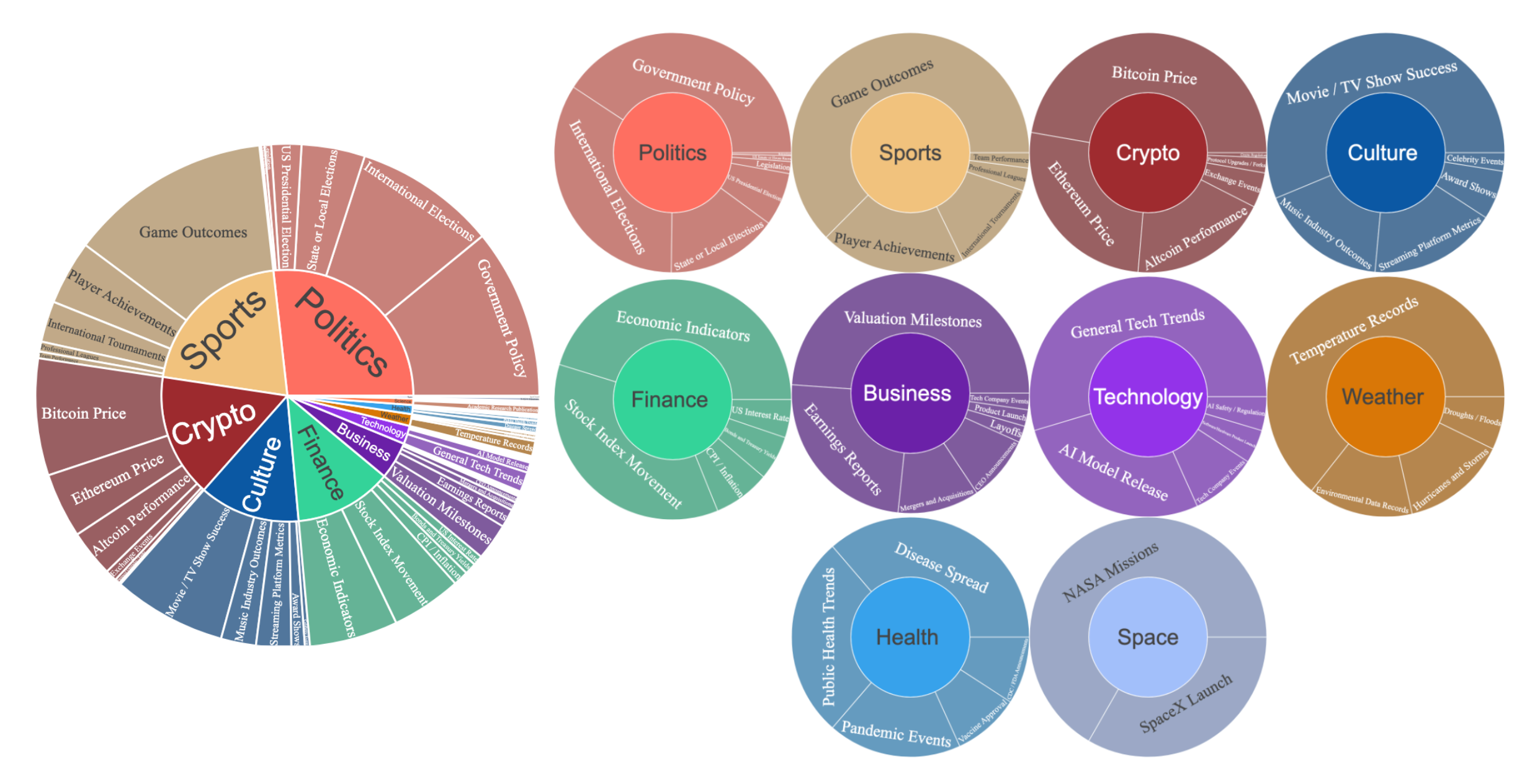
FutureX 中包含的事件域。
FutureX# 的四个难度等级
为了更精细地评估智能体能力,我们精心设计了预测任务,分为四个难度递增级别:
|
水平
|
层
|
事件类型
|
重点
|
规划
|
推理
|
搜索
|
|---|---|---|---|---|---|---|
|
1
|
基本
|
选择很少
|
从给定列表中少于 4 个选项中进行选择。
|
弱
|
弱
|
弱
|
|
2
|
广泛搜索
|
多种选择
|
详尽的辨别和返回所有正确的期货。
|
弱
|
中等
|
中等
|
|
3
|
深度搜索
|
开放式
(低波动性) |
交互式搜索和综合
导航源(单击、滚动、过滤) 整合证据以获得答案。 |
中等
|
中等
|
强
|
|
4
|
超级代理
|
开放式
(高波动性) |
预测高波动性、开放式事件
进行广泛的信息搜索原因 在深度不确定性下进行预测超级 代理层 |
强
|
强
|
强
|
我们如何构建 FutureX?#
为了应对实时更新的挑战,我们构建了一个完全闭环的自动化评估系统。系统每天自动收集新问题,运行 27 个模型进行预测,并在活动结束后自动检索结果并对其进行评分。这种技术复杂程度远远超过了传统的静态评估框架。

FutureX 的建设管道。
研究结果:当前的人工智能智能体在未来预测中的表现如何?#
1. 目前 Grok-4 领先,其次是 Gemini Deep Research 和 GPT-o4-mini。#
在四种模型类型中,Grok-4 的整体性能最高,其次是 Gemini-2.5-flash Deep Research GPT-o4-mini (Think&Search) 和 Seed1.6 (豆包)。
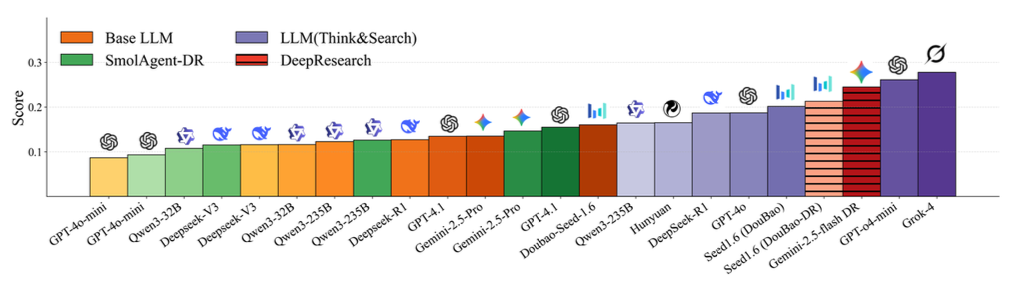
7 月 20 日至 8 月 3 日期间的综合排名。
2. 难度等级有效 。#
随着任务难度从 1 级增加到 4 级,所有模型的性能都会持续下降。模型在 4 级任务(开放式、高波动性)上的得分特别低,这有力地验证了基准的难度分层是准确的,并且可以有效地衡量从基本回忆到复杂推理的一系列能力。
3. 大型语言模型(LLM)在简单任务上表现良好 。#
在 1 级(单选)任务中,不使用工具的基本 LLM 表现异常出色。值得注意的是,豆包-种子 1.6-思维甚至优于一些配备搜索工具的智能体。这表明 1 级任务主要测试模型的内部知识,区分更高级模型的能力有限。
4. 工具的使用对于较艰巨的任务至关重要 。#
随着任务变得越来越复杂(尤其是 2 级和 3 级),可以使用 Web 搜索等外部工具的代理的性能明显优于仅依赖静态内部知识的模型。这凸显了实时信息访问和工具增强推理在解决复杂动态问题方面的关键作用。
5. 顶级车型表现出不同的能力。#
- 在知识检索任务(1 级和 2 级)中,
豆包-种子 1.6-思维是基础 LLM 中表现最好的。 - 在最具挑战性的开放式任务(3 级和 4 级)中,
Grok-4、Gemini Deep Research和GPT-o4-mini脱颖而出。它们实现了准确性和效率之间的出色平衡(更少的搜索、更快的推理),甚至超过了更昂贵的深度研究模型。
6. AI 智能体仍然落后于人类 。#
目前,LLM 智能体的整体预测能力仍落后于人类专家。
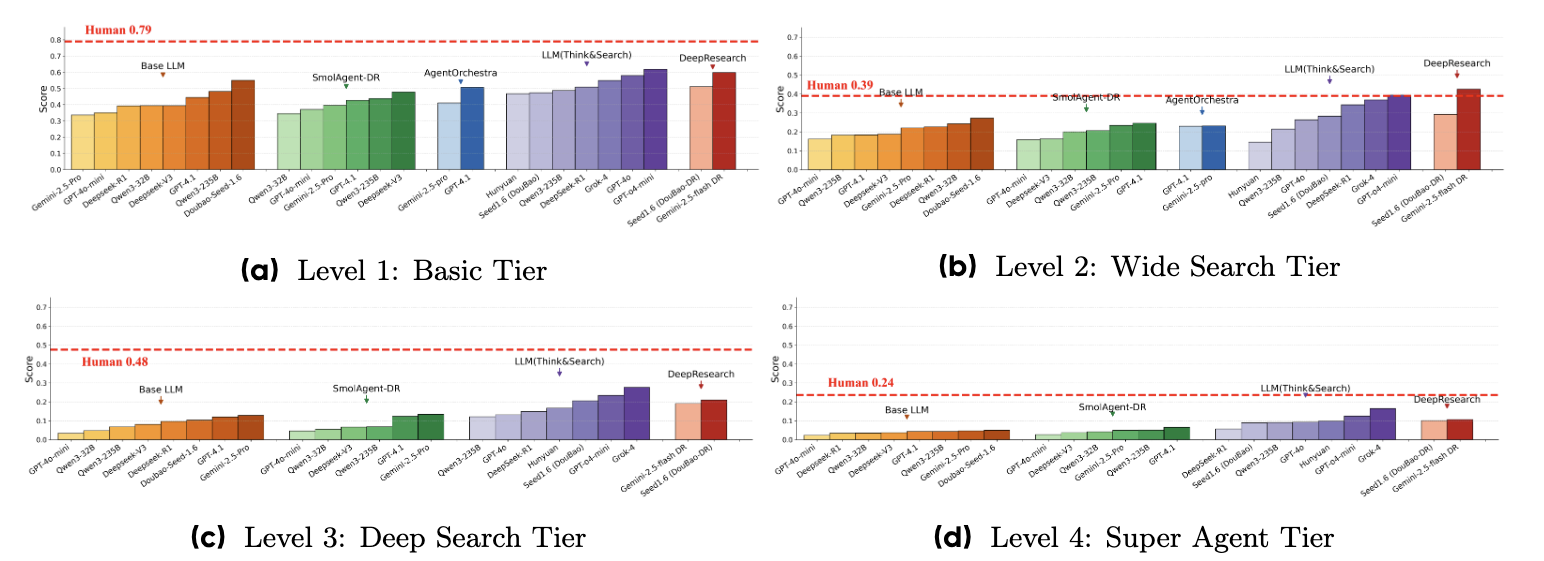
不同层次的表现。
S&P500
FutureX-S&P500 专注于 S&P 500 指数成分股的财务数据预测 。通过将模型的预测结果与人类专业分析师的共识估计以及最终公布的实际财报数据进行对比,我们希望了解:LLM 在财务数据预测方面能在多大程度上与人类金融专家匹敌甚至超越?
总排行榜
为什么选择标准普尔 500 指数财务预测?#
- 季度更新和可复制性 :财务报告每季度发布一次,为持续跟踪模型迭代提供了一个自然的“赛道”。
- 防止现有数据污染 :历史事件很容易搜索或不可避免地被训练到模型中,因此无法确保公平评估。
- 自然人类专家控制组 :华尔街分析师在该领域积累了多年经验,提供了可量化的基线。共识估计可以理解为人类专家的平均水平。
- 实用商业价值 :如果预测能够显着优于分析师,则可能会带来显着的阿尔法。
目标 #
标准普尔 500 指数预测评估 (LLM 与卖方分析师)
- 核心评估问题 :大型语言模型(LLMs)在预测上市公司的财务业绩方面能否超过华尔街分析师(来自雅虎财经)的普遍估计?
- 当前任务 :对标准普尔 500 指数成分股(根据 2025 年 6 月 30 日的名单)对下一季度的“ 每股收益 ”和“ 收入 ”(2025 年第二季度)进行点预测
- 核心指标 :
-
胜率 – 这衡量 LLM 的预测是否比分析师的共识估计更准确。对于每只股票,我们将 LLM 预测与实际报告值的绝对误差与分析师共识估计与实际值的绝对误差进行比较。如果 LLM 的误差较小,则算作“胜利”。
-
公式:胜率 = Number of LLM winsTotal number of predictions×100%Total number of predictionsNumber of LLM wins×100%
-
地点:LLM 在以下情况下 ∣LLM Forecast−Actual∣<∣Analyst Consensus−Actual∣∣LLM Forecast−Actual∣<∣Analyst Consensus−Actual∣ 获胜
-
-
平均绝对百分比误差 (MAPE) – 这衡量预测误差的平均大小占实际值的百分比。它提供了一种标准化方法来比较不同股票和财务指标的预测准确性,无论其绝对值如何。
-
分子式:MAPE = 1n×∑∣Forecast−Actual∣∣Actual∣×100%n1×∑∣Actual∣∣Forecast−Actual∣×100%
-
注意:对于每个股票预测,对于大于 30% 的误差,MAPE 的上限为 30%,以消除可能扭曲整体评估的极端异常值。
-
-
评估时间表 #
我们遵循时间表:
• 2025 年 6 月 30 日(锁定样本): 获得 SP500 成分股的共识估计
• 2025 年 6 月 30 日至 7 月 2 日(批量获取 LLM 响应): 使用相同的提示获取模型的预测
• 财报季(滚动财务业绩发布): 获取财务公告并滚动更新排名
• 财报季结束(总结和分析): 总体排名和结论
主要结果
1. 胜率比较
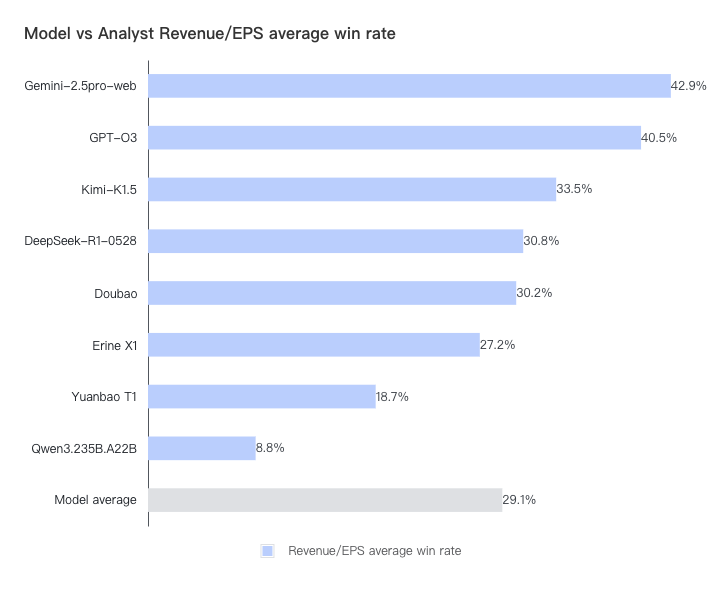
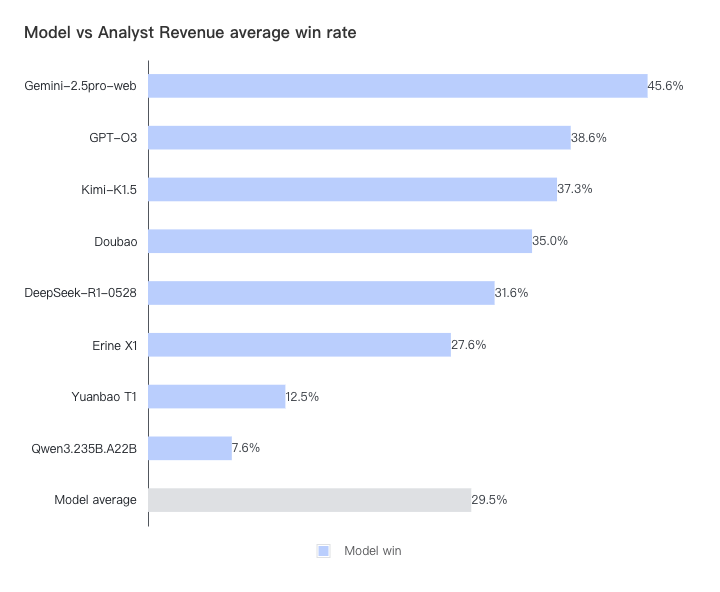
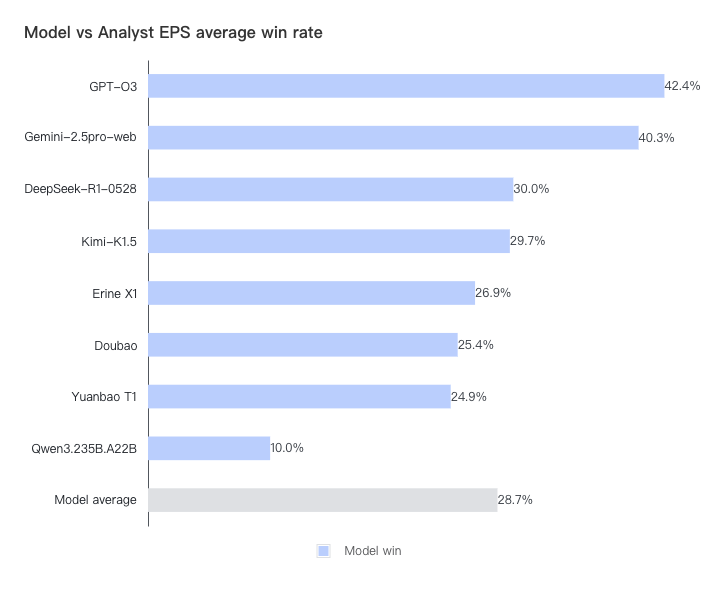
在模型的最终胜率方面,Gemini 和 GPT-o3 表现异常出色,两类预测的平均胜率分别达到了 43% 和 41%。 中国一线模特为 Kimi/DeepSeek/豆宝和 Erine,胜率在 34-27% 左右。但目前还没有机型的胜率超过 50%, 说明与专业分析师的水平仍有一定差距(通常,高于/低于共识的净利润会影响公司发布时的股价。如果该模型对分析师的净收益预测胜率超过 50%,则意味着该模型的短期财务预测能力已经超过华尔街分析师,其结果可以产生投资价值)。每个模型对分析师的收入/每股收益胜率分别如下:
2. 误差比较
从误差与实际公布业绩相比来看, 分析师表现更为稳定, 营收和每股收益的平均误差幅度均最小。
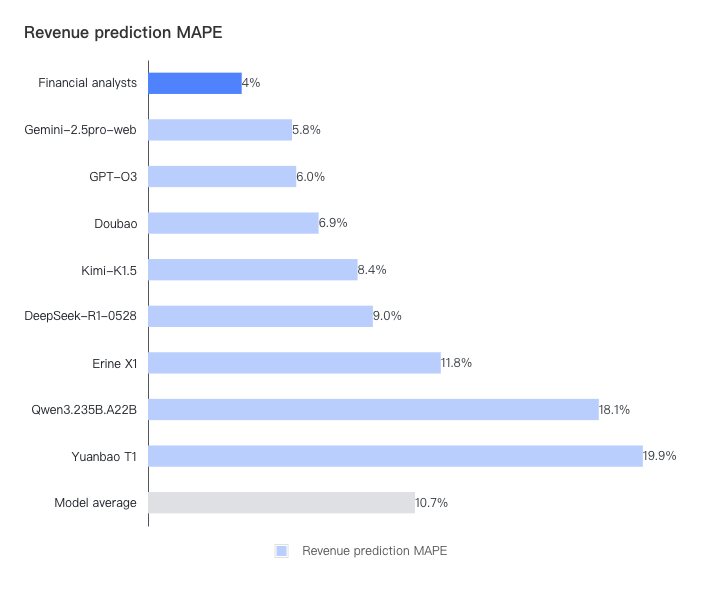
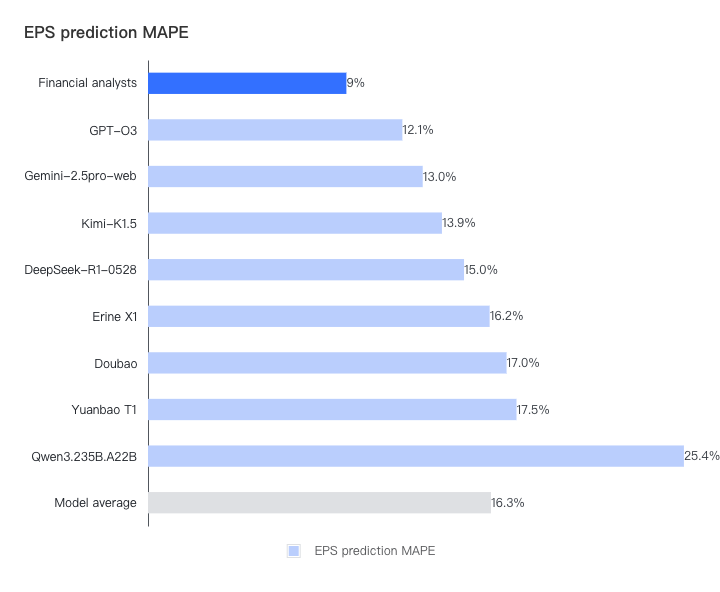
注:如果每个模型和分析师的净利润和收入的 MAPE 大于 30%,则上限为 30%,以防止单个数据点产生重大影响。
3. 案例 #
通过查看模型的预测与共识之间的差异,我们可以看到,尽管我们的输入提示明确指出模型应该通过自己的分析得出自己的结论,但部分结果(例如,大约 35% 的 O3 收入预测 )仍然非常接近当时的分析师共识预测 。大模型倾向于使最终答案非常接近共识。如果我们将收入差异小于 0.5% 且净收入差异小于 1% 的情况视为平局 ,则在重新计算结果后,模型和分析师之间的差距会变得更加明显。新结果如下:
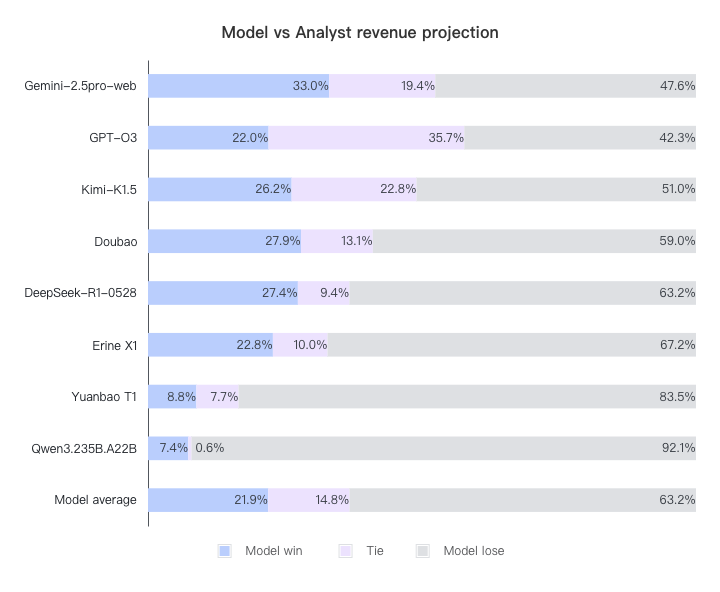
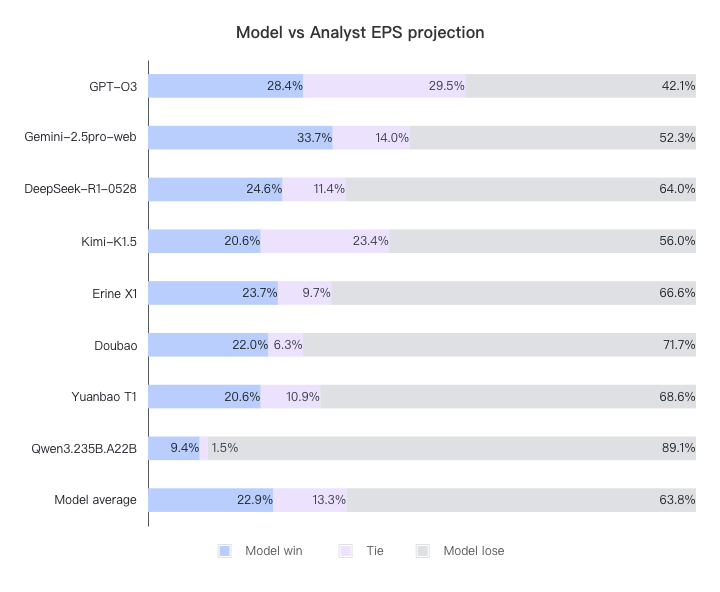

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 15
15 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)