Scaling Proprioceptive-Visual Learning with Heterogeneous Pre-trained Transformers
模型还不够大” (Not distinctively large yet):作者承认,虽然 HPT 用了 1B 参数,但在 LLM(大语言模型)动辄 100B+ 的规模面前,这只能算“中等规模”。这也暗示了:机器人领域的数据量(Token 数)相比互联网文本,还是太少了。HPT 使用的是监督学习(也就是行为克隆 BC)。这意味着机器人最好也就是和人类演示者一样好,它无法超越人类(不像 AlphaG
|
序号 |
属性 | 值 |
|---|---|---|
| 1 | 论文名称 | HPT |
| 2 | 发表时间/位置 | 2024/NeurIPS 2024 - 何凯明 - 看到大佬专门看一下这篇论文 |
| 3 | Code | Scaling Proprioceptive-Visual Learning with Heterogeneous Pre-trained Transformer |
| 4 | 创新点 |
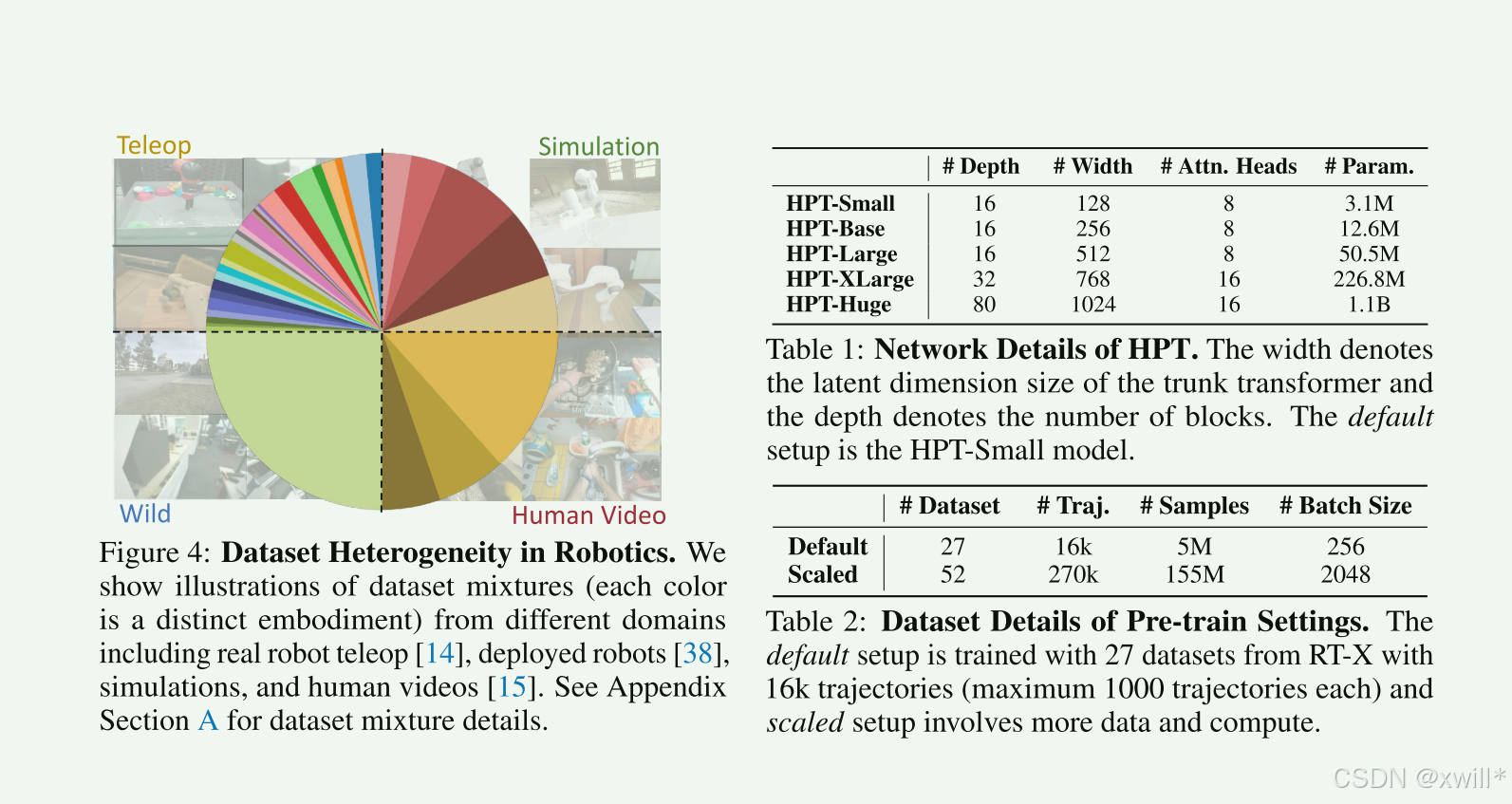
1:Stem-Trunk-Head 的模块化设计,抛弃了“大一统”的模型结构,采用了三段式设计来解耦差异性和通用性。 Stem (茎/适配器): 负责“翻译”。针对不同的机器人(不同的摄像头、不同的关节数),设计专属的 Stem,将异构输入压缩成统一格式。 Trunk (躯干/主干): 负责“思考”。一个巨大的共享 Transformer,不接触原始数据,只处理抽象的 Token。 Head (头/解码器): 负责“执行”。将抽象决策翻译回具体机器人的电机指令。 这种设计使得模型可以无限扩展,新来一个机器人,只需做一个新的 Stem/Head 插上去,中间的大脑不用动。 2:本体感觉与视觉的“强力对齐” ,以前的模型主要靠“看”(视觉),忽略了机器人手臂的实时位置(本体感觉),导致微调困难。 HPT 设计了专门的 Proprioception Tokenizer。它将复杂的图像和本体感觉分别压缩为极少的 16 个 Token(相比之下 Octo 用了 256+ 个)。这种“信息瓶颈”设计强迫 Trunk 忽略细节噪音,只学习最核心的物理规律和语义信息。 3:数据跨域异构扩展 使用了 52 个数据集(Octo 的 2 倍),参数量达到 1B。证明了只要模型够大,数据越杂(异构性越高),模型反而越聪明,而不是被搞晕。 4:“冻结主干”的迁移学习, HPT 证明了在微调新任务时,完全冻结主干网络 (Freeze Trunk),只训练轻量级的 Stem 和 Head,就能达到 SOTA 效果。 这意味着 Trunk 真正学到了通用的“世界模型”,具有极强的特征提取能力,大大降低了下游任务的训练成本(防过拟合) 5:在实验的时候可以发现,数据越多loss越好,这种大力出奇迹似乎在哪个领域都很好用。其次就是如果数据异构型比较大的话,调整比较大的Batch Size效果会好很多。-还是需要设备呀! |
| 5 | 引用量 | 解决数据异构型,把各种机器人数据统一编码成 token,再用大规模 Transformer 预训练,就能获得真正的“通用机器人大模型”。 |
一:提出问题
目前训练通用机器人的主要问题是之一是异构性(Heterogeneity)。以往的机器人学习方法通常只针对特定的形态(Embodiment)*和特定任务收集数据进行训练,这种方式昂贵且容易过拟合。这项工作研究了如何通过在跨越不同形态和任务的大规模机器人数据上进行*异构预训练,来学习策略表示(Policy Representations)。
本文提出了一种异构预训练 Transformer(Heterogeneous Pre-trained Transformers, 简称 HPT)通过预训练一个大型的、可共享的策略神经网络主干(Trunk),来学习一种与任务和具体形态无关(Task and Embodiment Agnostic)的共享表示。这种通用架构将来自不同形态机器人的特定本体感觉(proprioception)和视觉(vision)输入对齐(Aligns)为一个短的 Token 序列,然后处理这些 Token 以映射到控制不同任务的机器人动作。
什么是异构性?
机器人 A:单臂,7 个关节,有一个深度相机。
机器人 B:双臂,每臂 6 个关节,只有 RGB 相机。
机器人 C:四足狗,12 个关节,带激光雷达。
这就像让一个运动员既要学会打篮球,又要学会踢足球,还要学会游泳。以往的方法通常是“专人专用”,而 HPT 想做一个“全能运动员”。
HPT核心架构:主干与对齐 (Trunk & Alignment)
Shared Trunk(共享主干): 这是一个巨大的 Transformer 网络(大脑)。它的目标是学习通用的物理规律和运动常识,它不关心具体控制的是哪只手。
Alignment(对齐):
不同的机器人有不同的传感器(视觉、本体感觉)。
HPT 的做法是把这些乱七八糟的输入,先通过某种方式“翻译”成一种通用的语言(Token 序列),再喂给主干网络。就像无论是中文、英文还是法文输入,先翻译成“世界语”,再由大脑处理。
之前做机器人太难了,每个任务都要单独收数据。虽然想学 NLP/CV 做大模型(Foundation Models),但机器人数据有一个独特的难题——异构性(Heterogeneity)。异构性主要体现在两个方面:
-
本体感觉(Proprioception): 也就是机器人的身体结构。有的手是两指夹,有的是吸盘;有的是 7 个关节,有的是 6 个。以前的工作往往忽略本体感觉的预训练,这会导致过拟合(死记硬背动作)。
-
视觉(Vision): 摄像头位置不同(手腕上 vs. 架子上),环境光照不同。
而HPT解决异构的核心思路就是对齐:就像不管你说中文还是英文,我都先翻译成“思维语”,再进行思考。这样新来一个机器人,只要学“翻译”那一步就行了。
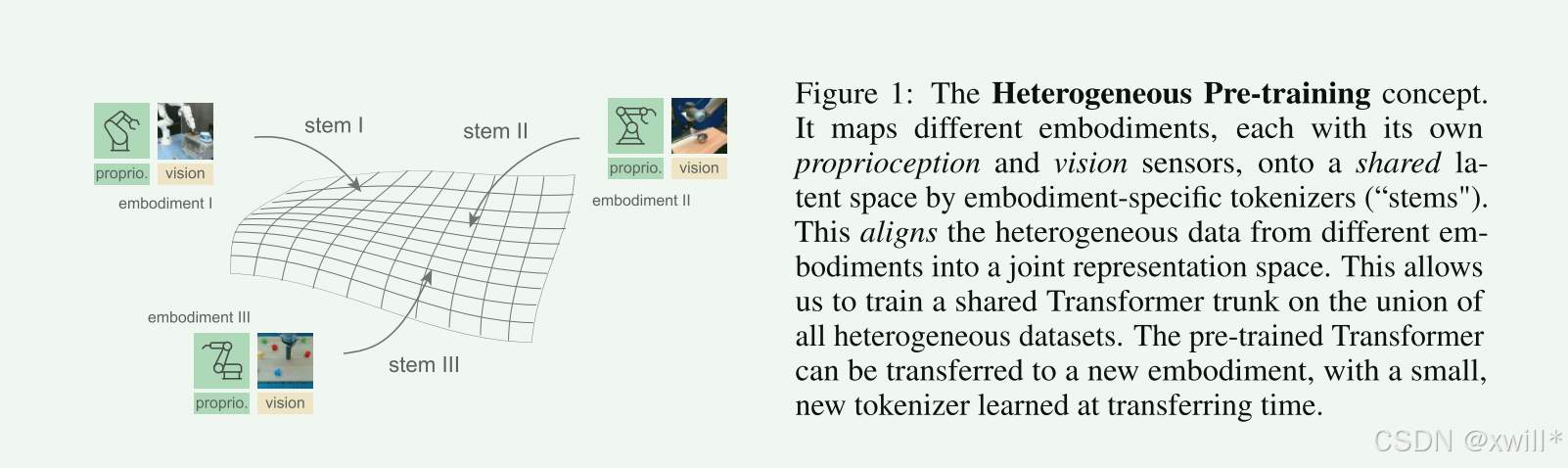
HPT 架构,分为三部分:
-
Stem (茎/主干接口): 针对特定机器人的 Tokenizer。负责把具体的传感器数据变成 Token。-对齐各种传感器的输入
-
Trunk (躯干/主干): 共享的 Transformer。这是大脑,所有机器人共用这一套权重。
-
Head (头/解码器): 针对特定任务的动作输出。
这种层级结构受到了人类神经系统的启发(脊髓处理反馈,大脑处理决策)。
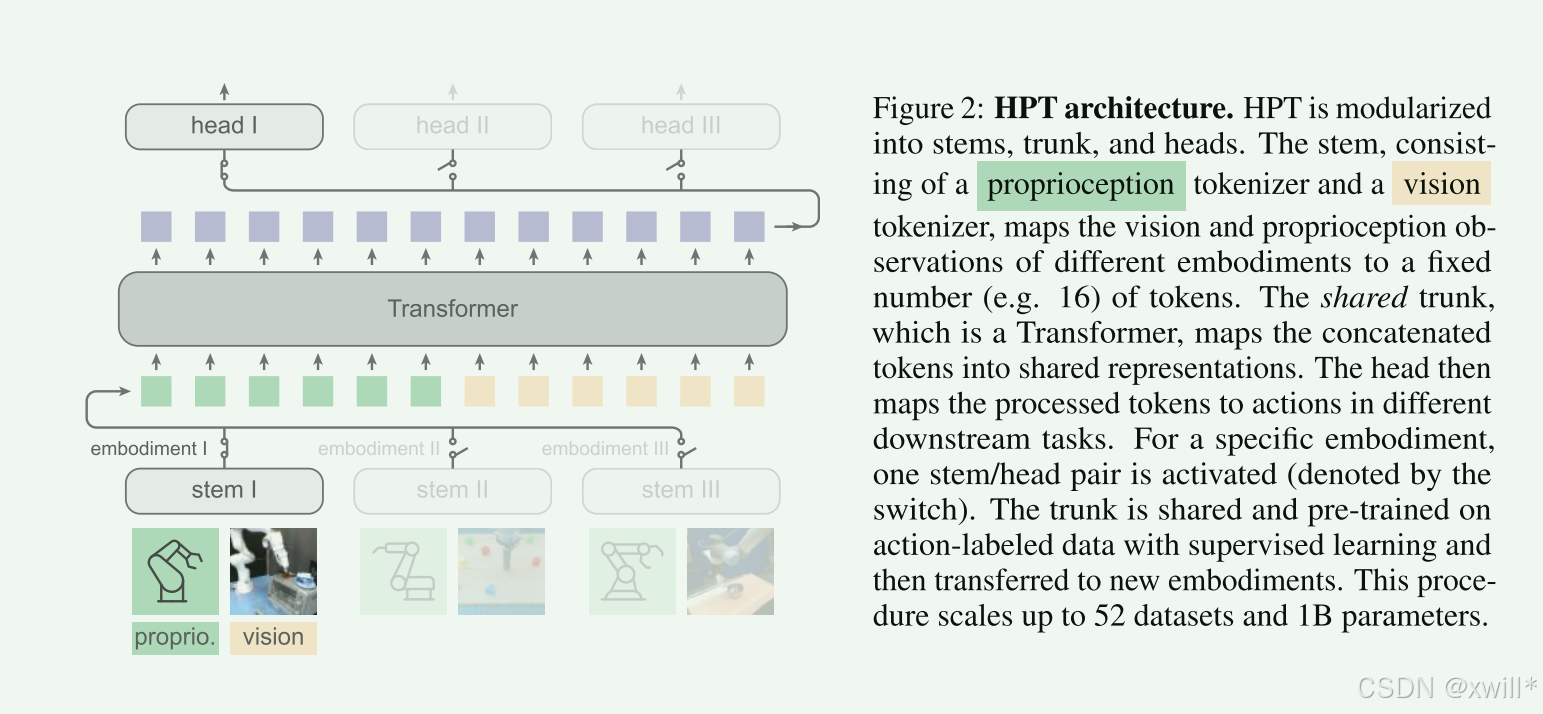
二:解决方案
1 Stem (茎 / 适配器) —— 解决“输入异构”
它的任务是“翻译”。不管是单臂还是双臂,是 RGB 相机还是深度相机,Stem 都要把这些乱七八糟的输入,压缩成固定数量、固定维度的Token。
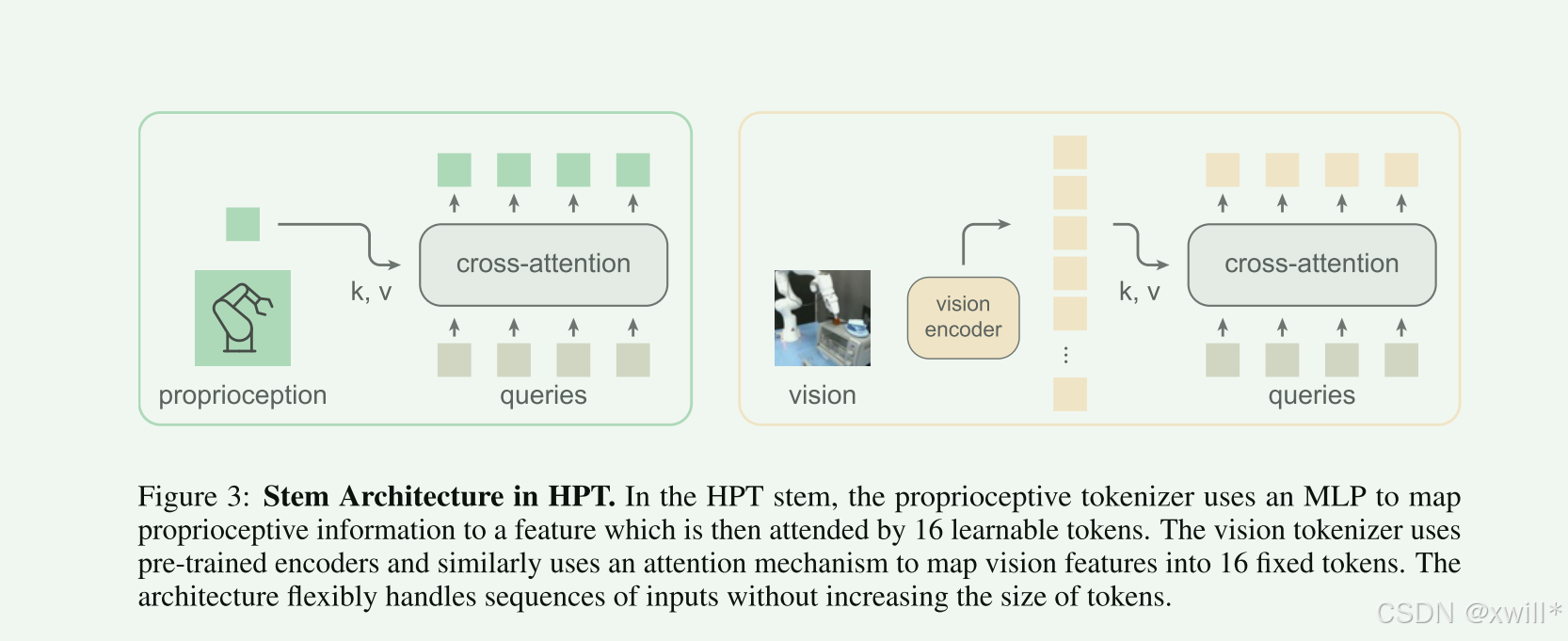
本体感觉 (Proprioception Tokenizer):
-
输入:机器人的关节角度、末端位置(长度不一样)。
-
处理:先过一个 MLP,然后用 Attention(注意力机制) 将其映射到 16 个 Token。
-
以前的模型(如 Octo)往往忽略本体感觉,或者直接拼接到图像上。HPT 把它当成一等公民,专门用 Token 表示。
视觉 (Vision Tokenizer):
-
输入:图片序列。
-
处理:用冻结的 ResNet 提取特征,然后同样用 Attention 压缩成 16 个 Token。
2 Trunk (躯干 / 主干) —— 共享大脑
这是一个标准的 Transformer。它不关心输入来自哪个机器人,它只负责处理那 32 个 Token(16 个本体感觉 + 16 个视觉)。在训练时,所有 52 个数据集的数据都会流经这个 Trunk。它是所有机器人的“公约数”(公约数就是对大家都适用的部分)。
所有机器人,在进入 Trunk 之前,都被编码成同一种格式,固定长度的 32 个 Token(16 proprio + 16 visual)。所以, 无论原始输入多异构,Trunk 看到的都是标准化的 32 个 Token。不同机器人:输入不同、任务不同,但它们都必须经过一个 通用的表示学习模块。它学到的是 对所有机器人、所有任务、所有身体结构都有效的知识。
3 Head (头 / 解码器) —— 解决“输出异构”
负责把 Trunk 处理好的抽象特征,翻译回具体机器人的动作指令(比如 7 个电机的电压)。通常是使用一个简单的 MLP(多层感知机)实现。每个任务或每个机器人都有自己专属的 Head。
4 训练目标
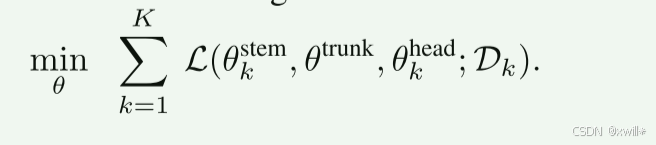
多任务学习,同时优化所有模块。
-
Trunk (主干): 每次迭代都更新。因为它什么数据都看。 是全局共享知识库。
-
Stem/Head (茎/头): 只有当 Batch 里采样到对应机器人的数据时,才更新对应的茎和头。 stems 和 heads 是不同机器人与任务的接口模块
使用 Huber Loss 进行行为克隆(Behavior Cloning),以比较预测的动作和真实动作。注意这里没有提到 Diffusion(扩散模型),这与 Octo 不同,HPT 更侧重于表示学习(Representation Learning)。
5 迁移学习
如何将预训练好的HPT模型,迁移到新的机器人上,具体操作流程如下:
-
Freeze the Trunk (冻结主干): 原文说:"freeze the weights of the trunk."这与 Octo 不同。Octo 建议微调整个模型,而 HPT 认为它的主干已经学到了完美的通用特征,不需要动。
-
Reinitialize Stem & Head (重置茎和头):你需要为你的新机器人初始化一个新的 Stem(因为它有独特的传感器)和一个新的 Head(因为它有独特的动作空间)。
-
Train: 只训练这两个轻量级的“转接头”,中间的大脑保持不变。三:实验
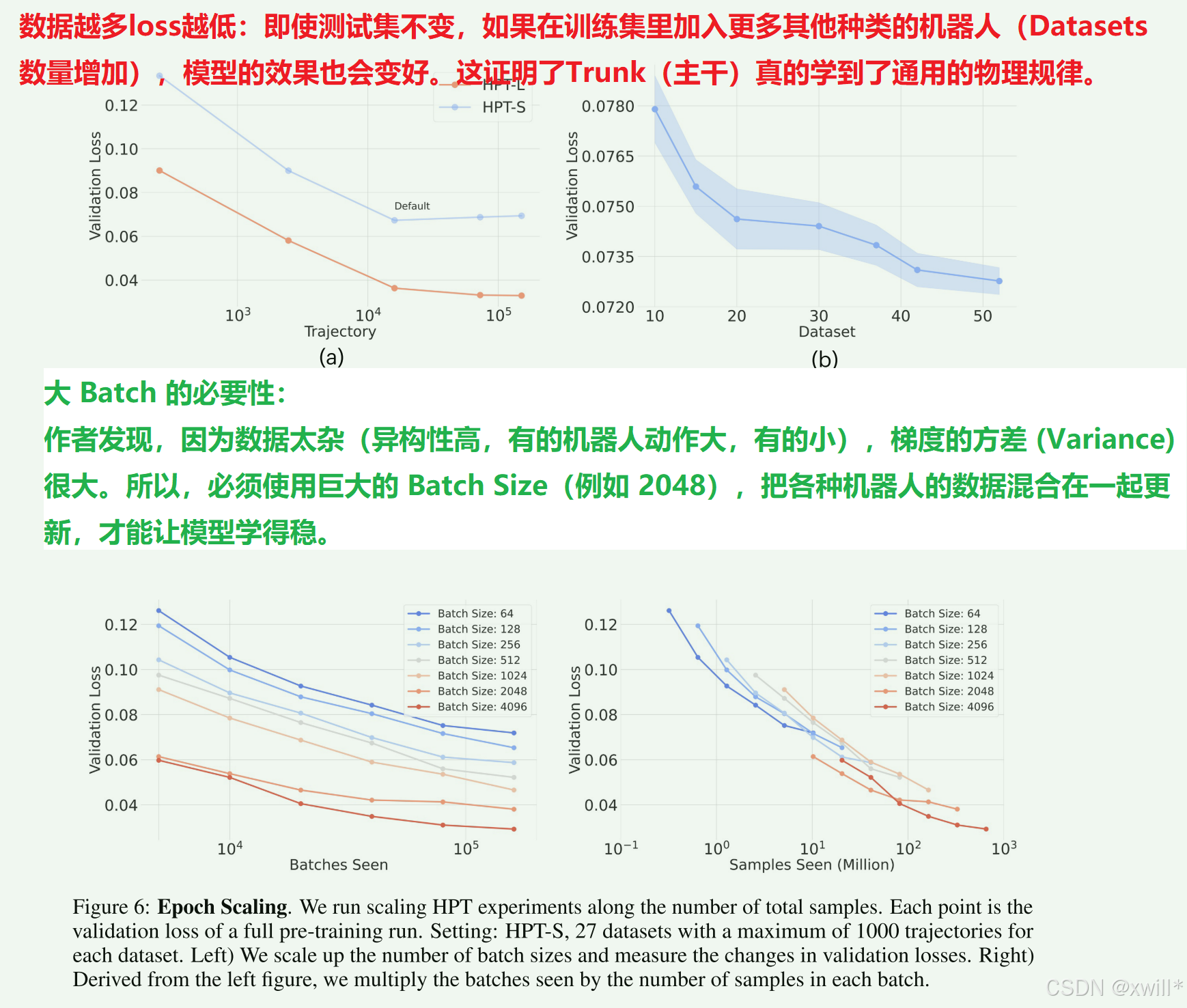
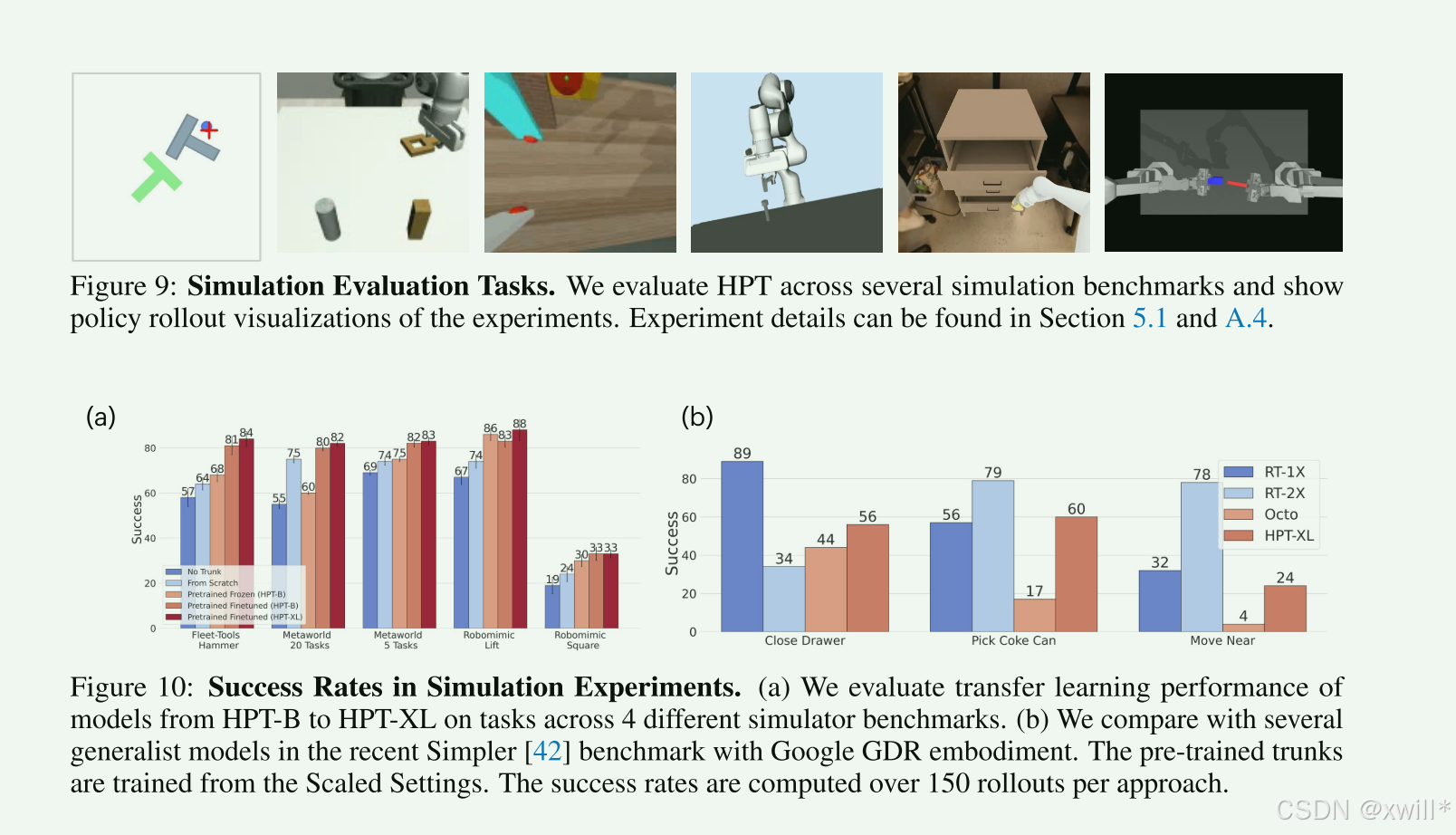
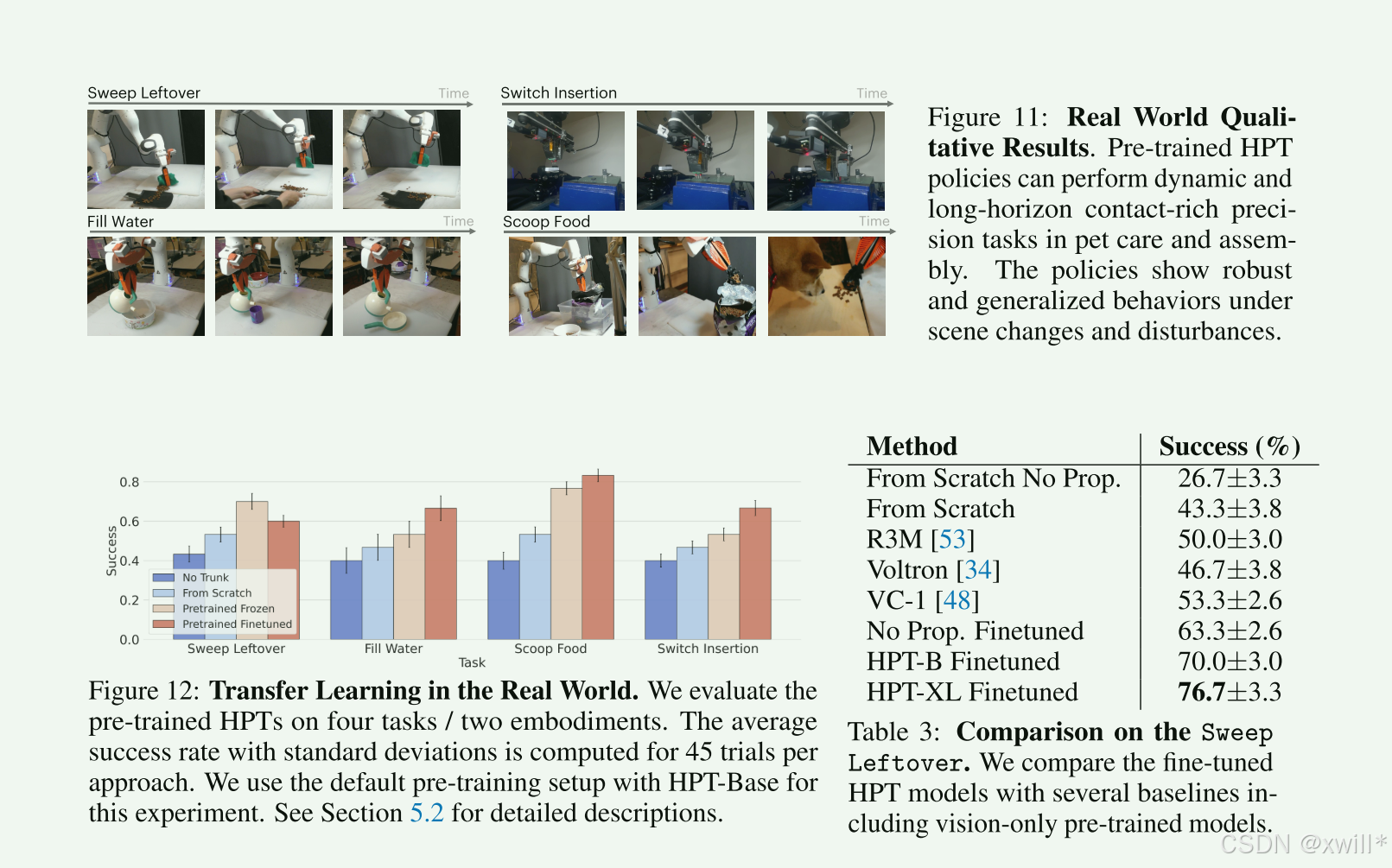
四:总结
“模型还不够大” (Not distinctively large yet):作者承认,虽然 HPT 用了 1B 参数,但在 LLM(大语言模型)动辄 100B+ 的规模面前,这只能算“中等规模”。
-
这也暗示了:机器人领域的数据量(Token 数)相比互联网文本,还是太少了。
“监督学习的上限” (Imitation Limit):HPT 使用的是监督学习(也就是行为克隆 BC)。这意味着机器人最好也就是和人类演示者一样好,它无法超越人类(不像 AlphaGo 可以通过自我博弈变强)。
-
这也解释了为什么可靠性低于 90%:因为人类演示数据里本身就包含噪音和失误。
“评估太简单” (Tasks are too easy):作者提到现在的测试任务都是“短程任务”(Short-horizon),比如“拿起苹果”。这种简单的任务,可能并不需要 1B 参数的大脑。这就像用爱因斯坦的大脑去考小学数学,体现不出优势。未来的研究需要更复杂的长程任务。
此外,还存在,不同机器人类别划分太过于粗略,训练时候没办法学习多样性。没有严格筛选噪声或低质量数据。的问题

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 26
26 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)