【爆肝干货】小白也能玩转!RAG三大黑科技LongRAG、Self-RAG、GraphRAG全解析,代码直接复制就能用!
RAG技术已从简单向量匹配发展为三种高级变体:LongRAG通过大块重叠保持上下文连贯性,适合长文档分析;Self-RAG引入反思机制评估检索质量和答案可信度,适合高风险场景;GraphRAG构建知识图谱实现多跳推理,擅长关系密集领域的查询。选择取决于业务需求:长上下文且精度优先选LongRAG,质量要求高选Self-RAG,复杂关系查询选GraphRAG。三者可组合使用,嵌入模型选择、分块策略和
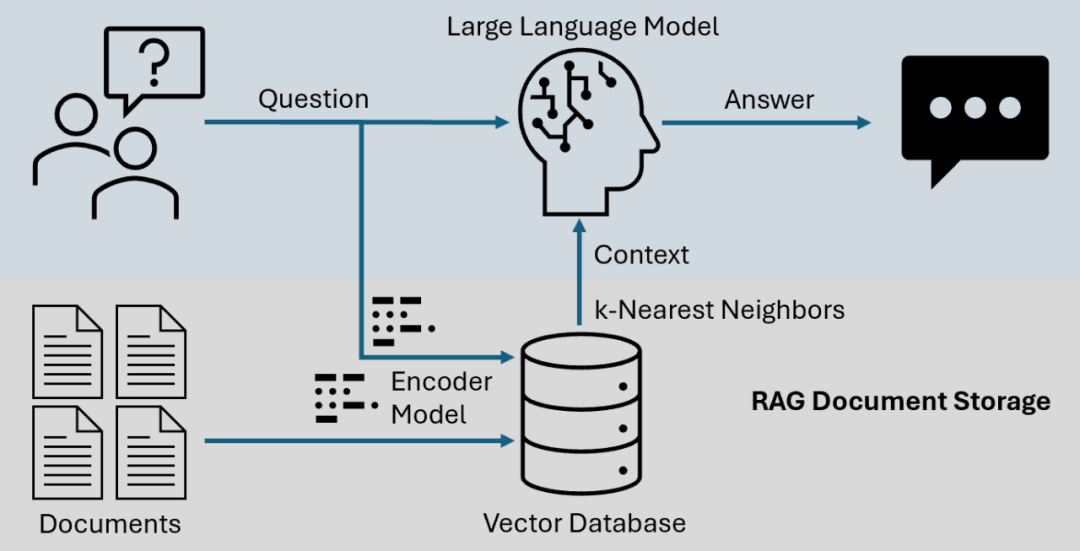
检索增强生成(RAG)早已不是简单的向量相似度匹配加 LLM 生成这一套路。LongRAG、Self-RAG 和 GraphRAG 代表了当下工程化的技术进展,它们各可以解决不同的实际问题。
一、传统 RAG 的核心限制
标准的 RAG 流程大概是这样的:把文档分割成小块、向量化、通过余弦相似度检索、喂给 LLM。这套路对很多场景确实够用,但会遇到很多问题,比如:
跨越式的上下文依赖。一个完整的逻辑链条可能横跨几千个词,而小块划分会把它们切散。其次是检索的盲目性,系统拉回来的内容有没有真正用处,完全没有办法自检。最后就是关系的表达能力。向量相似度再相关,也就是找找"感觉差不多"的内容,实体间的复杂联系它看不见。
高级 RAG 的这几种变体,正是为了解决这些问题而设计的。
二、LongRAG:保持上下文的连贯性
LongRAG 的核心想法其实不复杂:既然现在的 LLM 支持更长的上下文窗口(32K、100K,甚至 1M 个 token),为什么还要固执于 512 token 这样的小块呢?与其切割成碎片,不如用分层的方式来组织。
这套方案做了三件事:1、对整个文档或很大的部分进行整体嵌入,保留其整体语义;2、要分块的话,块要大得多(4K-8K token)并且保持 20-30% 的重叠,这样能维持叙述的流畅性;3、检索回来的不是零散的片段,而是完整的、连贯的段落或文档。
来看个原型级别的 Python 实现:
from typing import List, Dict
import numpy as np
class LongRAGRetriever:
def __init__(self, model, chunk_size=8000, overlap=1600):
self.model = model
self.chunk_size = chunk_size
self.overlap = overlap
self.doc_embeddings = []
self.documents = []
def create_long_chunks(self, text: str) -> List[str]:
"""Create overlapping large chunks"""
chunks = []
start = 0
while start < len(text):
end = start + self.chunk_size
chunk = text[start:end]
chunks.append(chunk)
start += (self.chunk_size - self.overlap)
return chunks
def index_document(self, doc: str, metadata: Dict):
"""Index document with hierarchical embedding"""
# 嵌入整个文档
doc_embedding = self.model.embed(doc)
# 用重叠方式创建大块
chunks = self.create_long_chunks(doc)
chunk_embeddings = [self.model.embed(c) for c in chunks]
self.doc_embeddings.append({
'doc_id': len(self.documents),
'doc_embedding': doc_embedding,
'chunk_embeddings': chunk_embeddings,
'chunks': chunks,
'full_text': doc,
'metadata': metadata
})
self.documents.append(doc)
def retrieve(self, query: str, top_k: int = 3) -> List[Dict]:
"""Retrieve relevant long-form content"""
query_embedding = self.model.embed(query)
# 先在文档层级做匹配
doc_scores = [
np.dot(query_embedding, doc['doc_embedding'])
for doc in self.doc_embeddings
]
# 拿到最相关的几个文档
top_doc_indices = np.argsort(doc_scores)[-top_k:][::-1]
results = []
for idx in top_doc_indices:
doc_data = self.doc_embeddings[idx]
# 在每份文档内找最佳的块
chunk_scores = [
np.dot(query_embedding, emb)
for emb in doc_data['chunk_embeddings']
]
best_chunk_idx = np.argmax(chunk_scores)
# 返回最佳块周围的扩展上下文
context_chunks = self._get_extended_context(
doc_data['chunks'],
best_chunk_idx
)
results.append({
'text': ''.join(context_chunks),
'score': doc_scores[idx],
'metadata': doc_data['metadata']
})
return results
def _get_extended_context(self, chunks: List[str],
center_idx: int) -> List[str]:
"""Get extended context around relevant chunk"""
start = max(0, center_idx - 1)
end = min(len(chunks), center_idx + 2)
return chunks[start:end]
这套方案在几类问题上表现不错。法律文档分析中因为合同条款和法律论述往往环环相扣跨度很长。研究论文检索也受益明显,方法论通常需要整段的连贯阅读才能理解。代码库搜索也一样,函数和类只有放到模块的完整上下文才能用。
但是我呢提就是延迟会上升 2-5 倍,因为处理的数据量摆在那儿。但准确率有 15-25% 的提升。内存需求会翻三四倍。所以这招合适的场景是准确率比速度更值钱的地方。
三、Self-RAG:让检索有自我意识
Self-RAG 有点不同。它在系统里埋入了反思的能力,不是盲目地拉数据然后生成,而是在关键点上进行判断,这些判断点用特殊的反思标记来表现:
检索标记(Retrieve Token)决定这个查询到底需不需要去检索。有些问题 LLM 直接能答,没必要多此一举;相关性标记(Relevance Token)评估检索回来的内容有没有用;支持标记(Support Token)检查生成的答案有没有真正建立在检索内容的基础上;批评标记(Critique Token)对整个回答做个质量评分。
这套系统可以分为三个互相穿插的环节:
class SelfRAGSystem:
def __init__(self, retriever, generator, critic):
self.retriever = retriever
self.generator = generator
self.critic = critic
def generate_with_reflection(self, query: str,
max_iterations: int = 3):
"""Generate answer with self-reflection"""
# 第一步:判断是否需要检索
retrieve_decision = self.critic.should_retrieve(query)
if not retrieve_decision:
# 不需要检索就直接生成
return self.generator.generate(query)
# 第二步:检索并评估相关性
retrieved_docs = self.retriever.retrieve(query)
relevant_docs = []
for doc in retrieved_docs:
relevance_score = self.critic.assess_relevance(
query, doc
)
if relevance_score > 0.7: # 阈值
relevant_docs.append(doc)
if not relevant_docs:
# 没找到相关的也回退到直接生成
return self.generator.generate(query)
# 第三步:生成并验证
best_answer = None
best_score = -1
for _ in range(max_iterations):
# 生成候选答案
answer = self.generator.generate(
query, context=relevant_docs
)
# 评估这个答案有多少支持度,质量如何
support_score = self.critic.check_support(
answer, relevant_docs
)
quality_score = self.critic.assess_quality(answer)
# 综合评分
total_score = 0.6 * support_score + 0.4 * quality_score
if total_score > best_score:
best_score = total_score
best_answer = answer
# 分数够高就不用再试了
if total_score > 0.9:
break
return {
'answer': best_answer,
'confidence': best_score,
'sources': relevant_docs,
'reflections': {
'retrieved': retrieve_decision,
'relevance': len(relevant_docs),
'support': support_score
}
}
这里面的批评组件需要好好训练,通常的做法是用有相关性标注的数据进行监督微调,然后结合强化学习用准确预测作为奖励,对比学习用来区分什么是支持的、什么是不支持的声明。
反思标记可以有几种实现路径:在模型词汇表里加特殊标记(比如 [RETRIEVE]、[RELEVANT]),或者在模型的分类器头上操作,甚至用外部的评估模型组成一个集成。
上线的时候要考虑几个问题:每多一轮反思就多增加 20-40% 的推理成本,所以要根据业务要求来平衡;对于法律、医疗这类高风险场景,反思的阈值要设高一点;普通聊天应用可以宽松一些。另外就是监控也很关键,要看系统多久会触发检索,这能告诉你是否用复杂了还是没用够。
四、GraphRAG:从向量相似度到关系图谱
GraphRAG 则换了个思路:与其比较向量的相似度,不如用图的方式来表示文档间的关系。实体成了节点,它们的关系成了边。查询时不是找"最像"的内容,而是找连接最紧密的子图。
这个过程分为几步。首先是实体提取,从文本里识别出人名、地名、概念等;然后是关系抽取,找出它们之间的时间、因果、层级等关联;再是图构建,把这些信息组织成一个知识图谱;最后在查询时,从这个图里拉出相关的子图。
图的构建和查询
class GraphRAGBuilder:
def __init__(self, entity_extractor, relation_extractor):
self.entity_extractor = entity_extractor
self.relation_extractor = relation_extractor
self.graph = NetworkGraph()
def build_graph(self, documents: List[str]):
"""Build knowledge graph from documents"""
for doc in documents:
# 提取实体
entities = self.entity_extractor.extract(doc)
# 把实体加成节点
for entity in entities:
self.graph.add_node(
entity['text'],
entity_type=entity['type'],
context=entity['surrounding_text']
)
# 提取关系
relations = self.relation_extractor.extract(
doc, entities
)
# 把关系加成边
for rel in relations:
self.graph.add_edge(
rel['source'],
rel['target'],
relation_type=rel['type'],
confidence=rel['score'],
evidence=rel['text_span']
)
def enrich_graph(self):
"""Add derived relationships and metadata"""
# 计算节点的重要性(PageRank 等)
self.graph.compute_centrality()
# 发现社群和聚类
self.graph.detect_communities()
# 如果有时间戳就加上时间序列
self.graph.add_temporal_edges()
查询时需要做多跳推理:
class GraphRAGRetriever:
def __init__(self, graph, embedder):
self.graph = graph
self.embedder = embedder
def retrieve_subgraph(self, query: str,
max_hops: int = 2,
max_nodes: int = 50):
"""Retrieve relevant subgraph for query"""
# 识别查询里涉及的实体
query_entities = self.entity_extractor.extract(query)
# 在图里找对应的节点
seed_nodes = []
for entity in query_entities:
matches = self.graph.find_similar_nodes(
entity['text'],
similarity_threshold=0.85
)
seed_nodes.extend(matches)
# 从这些节点出发扩展子图
subgraph = self.graph.create_subgraph()
visited = set()
for seed in seed_nodes:
self._expand_from_node(
seed,
subgraph,
visited,
current_hop=0,
max_hops=max_hops
)
# 按相关性给节点排序
ranked_nodes = self._rank_subgraph_nodes(
subgraph, query
)
# 提取并格式化成文本
context = self._format_graph_context(
ranked_nodes[:max_nodes],
subgraph
)
return context
def _expand_from_node(self, node, subgraph, visited,
current_hop, max_hops):
"""Recursively expand subgraph"""
if current_hop >= max_hops or node in visited:
return
visited.add(node)
subgraph.add_node(node)
# 获取邻接节点
neighbors = self.graph.get_neighbors(node)
for neighbor, edge_data in neighbors:
# 把边加到子图里
subgraph.add_edge(node, neighbor, edge_data)
# 继续递归扩展
self._expand_from_node(
neighbor,
subgraph,
visited,
current_hop + 1,
max_hops
)
def _format_graph_context(self, nodes, subgraph):
"""Convert subgraph to textual context"""
context_parts = []
for node in nodes:
# 加上节点本身的信息
context_parts.append(f"Entity: {node.text}")
context_parts.append(f"Type: {node.entity_type}")
# 加上和其他节点的关系
edges = subgraph.get_edges(node)
for edge in edges:
context_parts.append(
f"- {edge.relation_type} -> {edge.target.text}"
)
return "\n".join(context_parts)
微软的 GraphRAG 实现加了一层摘要的机制:先从文档里用 LLM 提取实体和关系构建初始图,然后用 Leiden 算法这类方法识别出社群,为每个社群生成摘要,形成多层级的抽象结构。查询时先定位到相关社群,再往下钻到具体实体。
这套方式特别擅长处理三类问题:探索性的查询(“这批文档的主要话题是什么”),需要多跳推理的查询(“A 通过 B 怎么连到 C”),还有时间序列的分析(“这个实体的关系怎么演变的”)。
五、如何选择
说了这么多,到底该用哪个?这取决于你的具体情况。
用 LongRAG 的前提是文档本身就有很强的内部关联性,你的 LLM 支持足够长的上下文(32K 起),而且准确性比响应速度更值钱。它特别适合报告、论文、书籍这类结构化文档。
Self-RAG 则适合对答案的准确性和可信度有较高要求的场景。假如检索出错带来的损失很大,或者查询的复杂度差异很大(有些直接能答,有些得查资料),Self-RAG 的反思机制就显出价值。用推理速度会慢一些的代价换来的是更可控的质量。
GraphRAG 适合领域里实体关系很丰富的情况。如果查询通常需要理解多个实体间的联系,或者涉及时间演变、层级关系这类复杂的关联,用图来表示就能发挥威力。
但是这三个方案可以组合使用:比如 LongRAG 加 GraphRAG,先用图结构定位到相关的文档集群,然后取完整的文档而不是片段。或者 Self-RAG 加 GraphRAG,用反思能力来决定图遍历的路径,什么时候往深处走,什么时候停止。甚至可以设计三阶段的流程:先用 GraphRAG 做基于实体的初步检索,再用 Self-RAG 筛选相关性,最后用 LongRAG 组织上下文。
六、工程考量
嵌入模型的选择
不同的 RAG 变体对嵌入能力的需求有差异。LongRAG 需要嵌入在文档和块两个层级都能工作,最好选用在长序列上用对比学习训练过的模型;Self-RAG 需要嵌入能够捕捉细粒度的语义差异,用于精准的相关性评估;GraphRAG 则需要对实体有特殊的理解,在实体链接任务上微调的模型会表现更好。
分块策略
传统的等长分块对于高级 RAG 太粗糙了。语义分块在段落、章节、话题转换的自然边界处切割;递归分块能建立父子关系的层级结构;滑动窗口用重叠的块在边界保留上下文;结构感知分块要尊重 Markdown 标题、XML 标签、代码块这些结构信息。
Python 的 LangChain 和 LlamaIndex 库都内置了这些分块策略的支持。
重排序的价值
在初步检索后加一层重排序模型,根据查询-文档的交互特征重新评分,这能显著提升效果。通常能带来 10-20% 的准确率提升并且延迟增加很少。
总结
RAG 的进化路径已经很清楚了:LongRAG 解决的是信息碎片化,当你有计算资源处理长上下文、需要保留完整语义的时候就用它;Self-RAG 带来了反思能力,减少假阳性,提高可信度,特别适合高风险应用;GraphRAG 则是针对关系密集的领域,能发现向量方法完全看不到的连接。
随着 LLM 和上下文窗口的继续进化,RAG 的形态也会不断调整。关键是要理解自己的业务约束:文档特点、查询模式、容错度、算力成本,然后有针对性地选择技术组合。
那么,如何系统的去学习大模型LLM?
作为一名深耕行业的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
由于篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~
👉大模型学习指南+路线汇总👈
我们这套大模型资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。

👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。
👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。
👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。
👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 21
21 0
0- 0



 已为社区贡献347条内容
已为社区贡献347条内容

所有评论(0)