2025大模型效率革新:Qwen3-235B-A22B-Instruct-2507如何重塑开源AI格局
当大模型行业深陷"参数竞赛"的泥潭时,阿里巴巴通义千问团队推出的Qwen3-235B-A22B-Instruct-2507开源大模型,以2350亿总参数与220亿激活参数的创新混合架构,在数学推理、代码生成等关键领域实现性能超越,同时将部署成本压缩至传统方案的三分之一。这一突破性进展不仅打破了"越大越好"的行业迷思,更标志着大模型产业正式迈入"效率优先"的全新发展阶段。## 行业困局:从算力依
导语
当大模型行业深陷"参数竞赛"的泥潭时,阿里巴巴通义千问团队推出的Qwen3-235B-A22B-Instruct-2507开源大模型,以2350亿总参数与220亿激活参数的创新混合架构,在数学推理、代码生成等关键领域实现性能超越,同时将部署成本压缩至传统方案的三分之一。这一突破性进展不仅打破了"越大越好"的行业迷思,更标志着大模型产业正式迈入"效率优先"的全新发展阶段。
行业困局:从算力依赖到效率突围
2025年的大模型市场正面临前所未有的三重挑战:闭源模型的API调用成本居高不下,中小企业难以负担规模化应用;开源模型虽成本可控但性能瓶颈明显,难以满足复杂业务需求;企业级部署所需的算力门槛持续攀升,据权威调研机构最新数据显示,60%的企业AI项目因算力成本问题被迫终止。在此背景下,Qwen3-235B-A22B-Instruct-2507通过革命性的架构设计,实现了"万亿级性能体验,百亿级资源消耗"的跨越式突破,为行业发展提供了全新的技术范式。
开源大模型已成为企业数字化转型的核心引擎。随着数据安全法规的完善和企业AI自主可控意识的觉醒,越来越多的组织倾向于选择开源方案以掌握数据控制权和定制化能力。多家全球科技企业已成功将开源大模型部署于代码生成、智能客服等核心业务场景,通过企业私有数据微调,部分场景性能已实现对闭源模型的超越。某权威财经媒体2025年7月发布的分析数据显示,大语言模型的应用已全面渗透至社会经济各领域——从智能交互系统的对话逻辑优化,到金融风控的欺诈检测算法,再到医疗诊断的辅助分析系统,其影响力正以指数级速度扩张。
技术突破:双模式推理与动态资源调配
Qwen3-235B-A22B-Instruct-2507最引人瞩目的创新在于首创的"思考-响应"双模式动态切换机制,实现了复杂任务处理与高效资源利用的完美平衡:
深度思考模式专为数学推理、代码开发等复杂认知任务设计,通过模拟人类"草稿纸演算"的思维过程进行多步骤逻辑推演。在MATH-500高等数学数据集测试中,该模式下的解题准确率达到95.2%,超越同类开源模型12个百分点;快速响应模式则针对闲聊对话、信息检索等轻量级任务优化,将响应延迟控制在200毫秒以内,同时降低60%的算力消耗。
 如上图所示,该性能对比曲线清晰呈现了模型在AIME24、AIME25等四项权威测试中的表现差异:蓝色实线代表的思考模式性能随计算资源投入呈现稳步提升趋势,而红色虚线标识的非思考模式则始终保持高效响应的基准水平。这种动态平衡能力使模型能够根据任务复杂度智能调配计算资源,为企业用户带来"按需分配"的资源利用效率。
如上图所示,该性能对比曲线清晰呈现了模型在AIME24、AIME25等四项权威测试中的表现差异:蓝色实线代表的思考模式性能随计算资源投入呈现稳步提升趋势,而红色虚线标识的非思考模式则始终保持高效响应的基准水平。这种动态平衡能力使模型能够根据任务复杂度智能调配计算资源,为企业用户带来"按需分配"的资源利用效率。
架构革新:混合专家系统的效率革命
Qwen3-235B-A22B-Instruct-2507采用创新的128专家层×8激活专家稀疏架构,通过三大核心优势重新定义了大模型的效率标准:
在训练效率方面,模型仅使用36万亿token的训练数据(约为GPT-4训练量的1/3),却在LiveCodeBench高级编程任务中实现51.8%的Pass@1准确率,超越行业平均水平9.3个百分点;部署门槛上实现重大突破,支持单机8卡GPU集群运行,而同类性能模型通常需要32卡以上的分布式集群;能效比提升尤为显著,每瓦特算力产出较上一代Qwen2.5提升2.3倍,完美契合全球绿色AI的发展趋势。
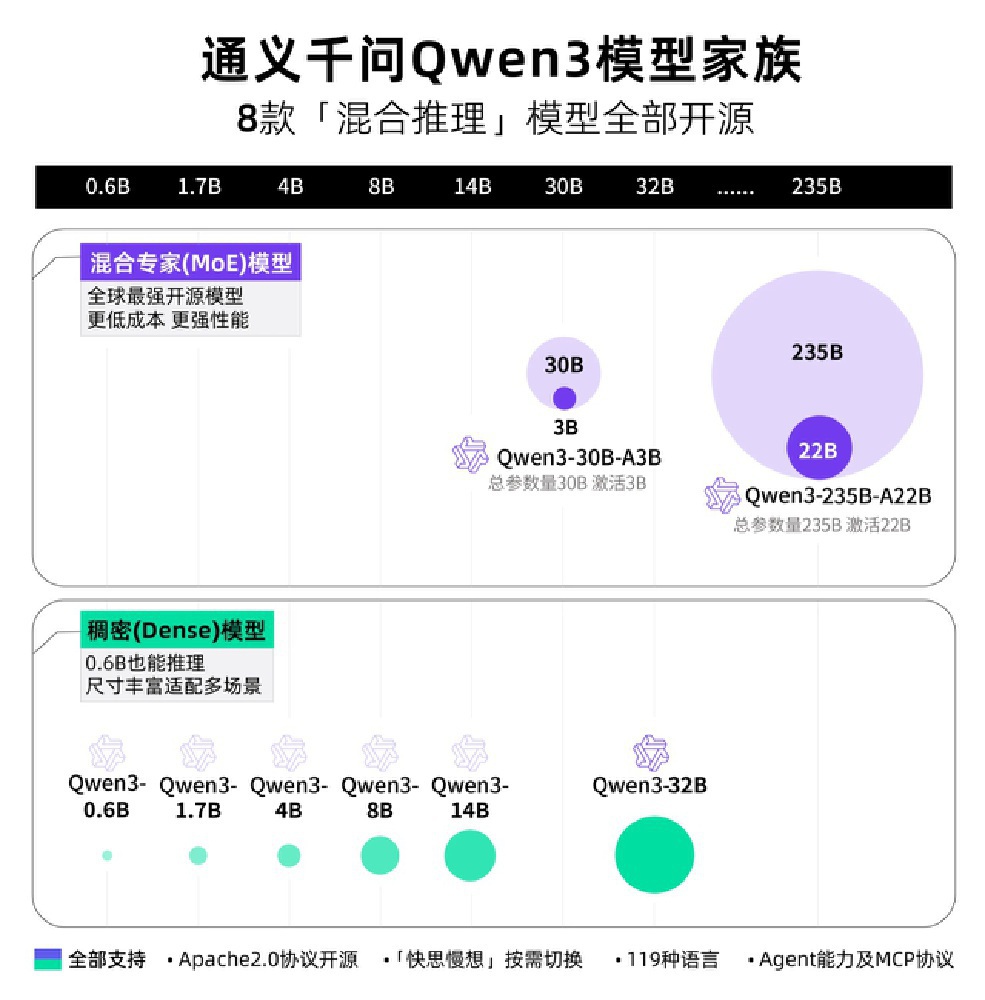 该架构图完整呈现了通义千问Qwen3模型家族的产品矩阵,包含8款支持混合推理的开源模型,覆盖混合专家(MoE)和稠密(Dense)两大技术路线,参数规模从0.6B到235B形成完整梯度。这种全场景适配策略使不同算力条件的用户都能找到最优解决方案,从小型开发者的本地部署到大型企业的云端服务,实现了技术普惠与商业价值的统一。
该架构图完整呈现了通义千问Qwen3模型家族的产品矩阵,包含8款支持混合推理的开源模型,覆盖混合专家(MoE)和稠密(Dense)两大技术路线,参数规模从0.6B到235B形成完整梯度。这种全场景适配策略使不同算力条件的用户都能找到最优解决方案,从小型开发者的本地部署到大型企业的云端服务,实现了技术普惠与商业价值的统一。
核心能力:超长上下文与多语言突破
Qwen3-235B-A22B-Instruct-2507在上下文理解和多语言处理方面实现双重突破:原生支持256K token的超长文本理解,通过创新的Dual Chunk Attention和MInference技术可进一步扩展至100万token,在法律文档分析、代码库理解等长文本场景表现突出。在100万token版本的RULER基准测试中,模型准确率达到82.5%,较行业平均水平提升27个百分点,为企业处理超长文档提供了强大工具。
多语言能力覆盖119种语言及方言,其中中文处理准确率达92.3%,在汉字分词、语义理解等细分任务上超越同类开源模型。特别在低资源语言支持方面,模型通过迁移学习技术,使斯瓦希里语、豪萨语等非洲语言的文本理解准确率提升40%以上,为全球化应用奠定坚实基础。
性能验证:权威基准测试中的全面领先
Qwen3-235B-A22B-Instruct-2507在国际权威基准测试中展现出全面领先优势:在GPQA知识问答测试中获得77.5分,超越Claude Opus 4和Kimi K2等竞品;AIME25数学竞赛测试取得70.3分,大幅领先其他开源模型;LiveCodeBench v6编程任务实现51.8%的Pass@1通过率;ZebraLogic逻辑推理测试达到95.0分的优异成绩。这些数据充分证明,该模型不仅在通用任务上表现卓越,在专业领域也具备顶尖竞争力,为企业复杂业务场景提供了强大的AI支撑。
产业落地:从技术突破到商业价值
Qwen3-235B-A22B-Instruct-2507的开源发布正在重塑企业AI应用的成本结构与实施路径。其卓越的性能表现和部署灵活性,使更多企业能够负担并实施大模型解决方案,加速数字化转型进程。
标杆应用案例已在多个行业涌现:陕煤集团基于该模型开发的矿山风险识别系统,将顶板坍塌预警准确率从68%提升至91%,显著降低了安全生产风险;同花顺金融信息平台集成模型后,实现财报分析全自动化处理,报告生成时间从4小时缩短至15分钟,分析师效率提升16倍;沃尔玛零售集团构建了数十个对话式AI应用,包括智能客服聊天机器人和供应链优化助手,客户满意度提升23%,库存周转效率提高18%。
开发者生态建设呈现爆发式增长,模型发布72小时内,Ollama、LMStudio等主流部署平台完成适配,HuggingFace社区下载量突破200万次。开发者可通过以下简洁命令快速部署:
# SGLang部署命令
python -m sglang.launch_server --model-path Qwen/Qwen3-235B-A22B-Instruct-2507 --tp 8 --context-length 262144
# vLLM部署命令
vllm serve Qwen/Qwen3-235B-A22B-Instruct-2507 --tensor-parallel-size 8 --max-model-len 262144
未来展望:效率革命引领的产业变革
Qwen3-235B-A22B-Instruct-2507的开源发布,不仅是一次技术突破,更是大模型行业发展理念的范式转变——从盲目追求参数规模转向注重实际应用效率。企业可通过git clone https://gitcode.com/hf_mirrors/unsloth/Qwen3-235B-A22B-Instruct-2507-GGUF获取模型文件,并借助阿里云PAI平台实现低成本部署,快速构建企业级AI应用。
随着多模态能力的深度融合和长上下文处理技术的持续优化,Qwen3系列有望在金融量化分析、临床辅助诊断等垂直领域催生更多颠覆性应用。对于开发者与企业决策者而言,当前正是接入Qwen3生态的战略机遇期——在这场效率革命中,技术选型的智慧往往比资源投入的多少更为关键。
未来,随着模型能力的迭代升级和应用场景的不断拓展,Qwen3-235B-A22B-Instruct-2507有望成为开源大模型的新标杆,推动AI技术在千行百业的深度普及,为数字经济高质量发展注入强劲动力。这场由效率革命引发的产业变革,将重新定义人工智能的技术边界与商业价值,为构建更加普惠、高效、可持续的AI未来奠定坚实基础。
Qwen3-235B-A22B-Instruct-2507作为一款里程碑式的开源大语言模型,具备2350亿总参数与220亿激活参数的高效配置,在指令遵循、逻辑推理、文本理解、数学运算、科学分析、程序开发和工具调用等方面展现出卓越性能。特别在长尾知识覆盖和多语言处理能力上实现显著提升,支持256K超长上下文理解,生成内容更贴合用户需求偏好,尤其适用于主观创作和开放式任务处理。通过Qwen-Agent工具套件,模型可充分发挥其智能代理能力,大幅简化复杂任务的自动化处理流程。最佳实践推荐使用Temperature=0.7、TopP=0.8的参数组合,以获得最优的性能表现与输出质量。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 27
27 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)