Megatron-LM学习笔记(3)模型并行 Model Parallel
Megatron框架中的模型并行实现方法,重点分析了张量并行(TP)、流水线并行(PP)、数据并行(DP)和上下文并行(CP)等多维并行策略。文章阐述了MPU工具如何管理并行训练环境,包括并行组初始化、通信封装和资源协调。通过分析rank分配逻辑和不同并行维度的组织方式,解释了如何实现高效的大模型训练。特别讨论了各并行策略的特点及其组合应用,如TP优先分配以保证通信效率、PP的流水线特性等。最后指
Part 3. 模型并行
Megatron中实现了多维度的并行。除了数据并行外,最常用的就是张量并行,对于宽度比较大的模型,采用张量并行来利用GPU的高带宽是有效的训练措施。megatron中使用MPU(Model Parallelism Utilities) 实现模型并行训练的实用工具,负责管理张量并行、流水线并行和数据并行的分组与通信。其核心功能包括并行环境的初始化、通信操作的封装以及分布式计算资源的协调。Megatron中的parallel state和MPU是一样的(别名)
首先从arguments.py中解析命令行参数:–tensor-model-parallel-size。在initialize megatron函数中调用finish_mpu_init->_initialize_distributed。这个函数会调用init process group(或者在之前已经调用过了),然后会通过mpu.initialize_model_parallel()函数来进行最关键的步骤。
-
验证GPU数量可以被各个维度整除,world_size % total_parallel == 0, total_parallel = tp_size * pp_size * cp_size
-
计算DP组 data_parallel_size = world_size // total_parallel,同时要保证DP组能被EP大小整除即DP % EP。简单认为,DP即有多少分模型的copy,EP就是把一个copy分到几张卡上。也就是说一个DP组内至少能做到EP被均匀切分。其实就是针对MLP的一种张量并行,看图就很明白了,EP为2则需要把专家放到两张卡上,EP为4则表示一组内有四个GPU,每张卡上放一个专家,本质上和对普通的FFN做TP是一样的
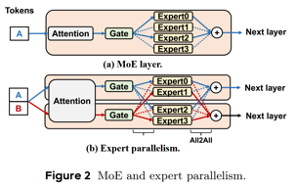
-
用一个rank generator来组织GPU各个rank之间的逻辑联系,比如可以传入 get ranks tp,即给出所有TP通信组,返回一个列表的列表(如[[0, 1], [2, 3], …],其中 [0, 1] 是一个TP组,[2, 3] 是另一个TP组),pp-tp则获得所有PP和TP组成的通信组,每一个通信组内部其实就是一个完整的模型(注,最新版本不再用rank generator,但是思想是差不多的)
-
开始构建组:
- 先DP,再dp-cp,之后是tp-pp,tp-ep-pp,tp,pp,特殊处理embedding组(最开始和最后的embedding是共享的),tp-dp-cp,tp-dp,tp-cp,
- 接下来设置tp-ep,ep,dp,dp-cp,这里都设置independent-ep=True,是要获取独立的EP组,我们会得到DP mod EP group,如果设置为false则获取完整的DP组
- 传入什么维度,表示返回其他维度相同、传入维度不同的分组,比如传入DP则给出DP rank不同的组,tp-pp则是完整的模型,tp-ep-pp是有ep情况下完整的模型组,tp是传入tp组(组内需要all to all通信获取完整输出)
-
最后set global memory buffer。
此时initialize Megatron就结束了,进行了完整的模型并行分割设置。注意此时模型本身并没有出现在其中。
一些问题和理解:
为什么要按照tp-cp-ep-dp-pp的顺序?
因为tp对连接的要求最高。最先分配TP rank可以尽可能保证TP通信的卡被放在同一台机器上(或者说机内)。
global_rank = tp_idx + cp_idxtp + ep_idxtpcp + dp_idxtpcpep + pp_idxtpcpepdp
可以看到DP是尽量往后放的,不同的DP rank之间也是需要做梯度的all reduce来保证模型更新一致。
为什么PP放在最后?因为PP不同阶段的模型是不需要做参数的通信的。当然也有备用顺序是把DP和PP换位置,这样可以让DP分散的更远,可能做到不同机柜不同DP组来做特定的安排和布局。
CP到底是什么?就是把序列中的样本分散到不同的rank上,各自先算各自的KV。这时候需要用Q来做注意力,则互相交换KV。此时大家都有完整的KV和部分Q,用这个Q计算对应的注意力得到各自块上各个token的Output,后续就可以放到FFN里去了(不需要全局依赖)。反向传播的时候,对应的激活梯度也是要all reduce来传播到不同的卡上的。
SP是什么?序列并行是针对TP的一个增强,比如本来的LayerNorm这些是没有被TP分开的,如果启用SP则会进一步增强这一点,能够减少激活占用的显存以及部分计算负担
CP和DP的参数是一样的,所以在Megatron里使用CP-DP来做完整的梯度归约。但是注意DP组之间归约梯度要除以DP size,而对于CP,他们的梯度是同一条样本里不同的组成部分,是没有除以CP的。
这么多并行,到底某某并行是什么意思?简而言之,什么东西并行,就代表对应组里什么东西不一样。例如:管道并行,管道不一样,同一组内拥有管道的不同阶段;数据并行,同一组内拥有数据的不同片段;张量并行,同一组内拥有不同的张量(模型参数矩阵的上下部分);上下文并行,同一组内有不同的上下文部分。
用Megatron中自带的例子来说明。16张卡,2x8卡,TP=2,PP=4,会创建一个DP=8的组。
优先分配TP:因此0、1,2、3是分组的,他们拥有模型同一层或者一部分的各一半参数。
其次分配DP:DP的含义是数据不同,但是拥有相同的模型部分。因此按照0、2;1、3;4、6的方式来分,此时0和2都拥有相同的模型部分,具体有什么在PP以后说;
最后分配PP:要求PP=4,因此要接着DP组的范围来(同一个DP内有相同的模型参数,不能再干扰到他们),所以是0、4、8、12这样分。
总体上各卡拥有的就是0、1、2、3卡有流水线的第一阶段,01、23各自有相同的模型部分的上下半;之后传递到下一阶段4、5、6、7…….以此类推
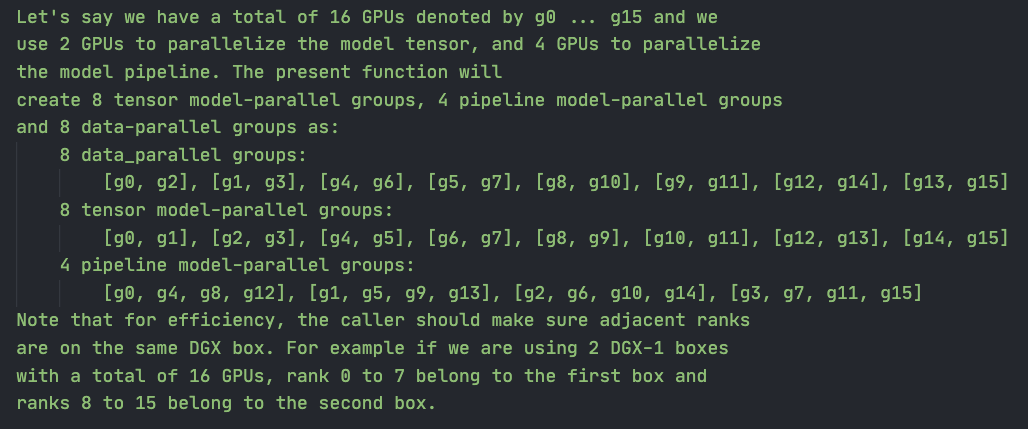
另外在早一些版本的Megatron里是限制CP和EP同时使用的,可能一开始是出于工程实现的考虑。但是现在已经可以开启了。
关于pipeline parallel,可以参考飞桨的这篇文章:流水线并行技术与飞桨优化实现详解
补充:为什么CP里,明明有因果限制,有前面token的卡完全不需要获取后面token卡的KV来计算,但是大部分实现仍然要做所有卡的计算呢?其实all reduce实现更高效,虽然传输的数据更多一些,但是后续也更好融入流水线来对齐,同时防止部分卡负载很高其他卡闲着。当然token位置是会被记录下来的,防止破坏因果性质。
所以有一些直接的改进:不再按顺序切分sequence而是更随机一点,防止有的卡太闲了;也有的改进是通过累加来减小显存占用的。
接下来要做的是set up model and optimizer。这个函数中之前也提到过,会设置模型和优化器。但是具体的时候会有其特点。
- model使用get model,调用model provider func。这个provider是我们一开始就传入的函数,位于pretrain_gpt.py中。这里的model provider其实就是返回一个megatron能够训练的模型。legacy模式会用老的实现,这里主要关注新版本的实现。在model = GPTModel中,会传入config以及layer spec等,有这些能够构建一个完整的模型。
- 模型
最核心的函数就是get_model。这个函数会调用model provider,根据不同的rank自动切模型并行。简单来说,模型在初始化的时候就会获取当前rank的并行组策略,然后各自保留需要的参数。具体的后续再看模型结构了。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 22
22 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)