计算机毕业设计之基于大数据的热播电视剧数据分析与预测系统设计与实现(源码+定制+开发) 基于Python的大数据热播电视剧趋势预测系统设计 基于Spark的大规模电视剧播放数据分析
本文介绍了程序员阿龙的技术背景与服务内容。阿龙是Java领域专家,拥有10W+粉丝,担任CSDN特邀作者、博客专家等职,精通SpringBoot、Vue等全栈技术。他提供毕业设计全流程服务,包括功能实现、论文指导、降重及答辩辅导,并承诺项目售后支持。文章详细讲解了Python、Hadoop、Scrapy等关键技术,展示了爬虫代码实例和系统测试方法,最后附有联系方式获取项目源码。阿龙凭借丰富的实战经
博主介绍:
✌我是阿龙,一名专注于Java技术领域的程序员,全网拥有10W+粉丝。作为CSDN特邀作者、博客专家、新星计划导师,我在计算机毕业设计开发方面积累了丰富的经验。同时,我也是掘金、华为云、阿里云、InfoQ等平台的优质作者。通过长期分享和实战指导,我致力于帮助更多学生完成毕业项目和技术提升。技术范围:
我熟悉的技术领域涵盖SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app、大数据、物联网、机器学习等方面的设计与开发。如果你有任何技术难题,我都乐意与你分享解决方案。主要内容:
我的服务内容包括:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写、论文撰写与辅导、论文降重、长期答辩答疑辅导。我还提供腾讯会议一对一的专业讲解和模拟答辩演练,帮助你全面掌握答辩技巧与代码逻辑。🍅获取源码请在文末联系我🍅
温馨提示:文末有 CSDN 平台官方提供的阿龙联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的阿龙联系方式的名片!

目录:
为什么选择我(我可以给你的定制项目推荐核心功能,一对一推荐)实现定制!!!
一、详细操作演示视频
在文章的尾声,您会发现一张电子名片👤,欢迎通过名片上的联系方式与我取得联系,以获取更多关于项目演示的详尽视频内容。视频将帮助您全面理解项目的关键点和操作流程。期待与您的进一步交流!
承诺所有开发的项目,全程售后陪伴!!!

2 相关工具及介绍
2关键技术介绍
2.1python开发语言
Python是一种高级编程语言,由荷兰人Guido van Rossum于1989年创立,并于1991年首次发布。Python的设计哲学强调代码的可读性和简洁性,因此它被广泛应用于各种领域,包括Web开发、数据分析、人工智能和科学计算等。Python语言的最大特点是其语法简洁明了,易于学习和使用。Python支持多种编程范式,包括面向对象编程、函数式编程和过程式编程。Python还拥有丰富的标准库和第三方库,可以帮助开发者快速实现各种功能。在Web开发方面,Python有许多优秀的框架,如Django和Flask,它们可以帮助开发者快速构建高效的Web应用。这些框架提供了许多内置的功能,如数据库访问、表单处理和用户认证等,大大简化了Web开发的过程。在数据分析方面,Python是最受欢迎的编程语言之一。Python的pandas库提供了强大的数据处理和分析功能,可以帮助开发者轻松处理大量的数据。同时,Python的matplotlib和seaborn库可以用于数据可视化,帮助开发者更好地理解数据。在人工智能和机器学习方面,Python也有着广泛的应用。Python的TensorFlow和PyTorch库是最常用的深度学习框架,它们提供了丰富的工具和接口,可以帮助开发者构建和训练复杂的神经网络模型。
在科学计算方面,Python的NumPy和SciPy库提供了强大的数值计算功能,可以帮助开发者解决各种复杂的数学问题。Python的SymPy库还可以用于符号计算,为科学计算提供了更多的可能。
Python是一种强大而灵活的编程语言,无论你是初学者还是专业开发者,都可以从Python中获益。Python的简洁语法、丰富库和广泛的应用领域使其成为当今最受欢迎的编程语言之一。
2.2 Hadoop框架介绍
Hadoop是一个开源的分布式计算框架,旨在处理大规模数据集的存储和处理。它基于Google的MapReduce论文和Google文件系统(GFS)的概念,并由Apache软件基金会进行开发和维护。
Hadoop的核心组件包括Hadoop分布式文件系统(HDFS)和Hadoop YARN(Yet Another Resource Negotiator)。HDFS是一个可靠、高容错性的文件系统,设计用于在廉价硬件上存储大量数据,并提供高吞吐量的数据访问。YARN是一个资源管理器,负责调度和管理集群中的计算资源,使得多个应用程序可以共享集群资源并以并行方式运行。Hadoop的另一个重要组件是MapReduce,它是一种编程模型和执行引擎,用于将大规模数据集分解为小的数据块,并在分布式环境中进行并行处理。MapReduce模型将计算任务分为两个阶段:Map阶段和Reduce阶段。在Map阶段,数据被划分为若干个键值对,并通过用户定义的函数进行转换。在Reduce阶段,相同键的数据被合并和聚合,生成最终的结果。
Hadoop生态系统还包括许多其他工具和库,如Hive、Pig、HBase等,用于更方便地处理和分析数据。Hive是一个基于SQL的数据仓库工具,可以将结构化数据映射到Hadoop上,并提供类似于SQL的查询语言。Pig是一个高级脚本语言和运行环境,用于在Hadoop上进行数据转换和分析。HBase是一个分布式、可扩展的NoSQL数据库,适用于大规模的随机读写操作。
2.3 Scrapy介绍
Scrapy是一个基于Python的开源网络爬虫框架,用于快速、高效地抓取和提取互联网上的数据。它提供了一套强大的工具和API,使得开发者可以轻松地构建和管理自己的爬虫项目。Scrapy具有高度可定制性的特点。它采用了分布式架构,支持并发请求和异步处理,能够高效地处理大规模的数据抓取任务。同时,Scrapy还提供了丰富的中间件和插件机制,允许开发者根据自己的需求对请求、响应和数据进行处理和扩展。Scrapy还内置了强大的数据提取功能。通过使用XPath或CSS选择器,开发者可以方便地从HTML、XML等结构化数据中提取所需的信息,并进行清洗和转换。此外,Scrapy还支持使用正则表达式和自定义的解析器来处理非结构化数据。
Scrapy还提供了丰富的调度器和去重器,能够有效地控制爬虫的请求流程和避免重复抓取。它还支持多种存储方式,包括文件、数据库和API接口,方便开发者将抓取到的数据保存和导出。
2.4MySQL数据库
MySQL是一种开源的关系型数据库管理系统(RDBMS),被广泛应用于各种规模的企业和个人项目中。它是由瑞典MySQL AB公司开发并推出的,后来被Sun Microsystems收购,最终成为Oracle公司的一部分。MySQL以其高性能、可靠性和灵活性而闻名,成为最受欢迎的数据库之一。
MySQL具有许多优点,其中之一是其简单易用的特性。它采用了SQL(Structured Query Language)作为查询语言,使得用户可以通过简单的命令和语法来操作数据库。MySQL提供了丰富的文档和社区支持,使得初学者可以快速上手并解决问题。MySQL还具备出色的性能和扩展性。它可以处理大量的数据,并支持高并发访问。MySQL使用了多线程架构和高效的索引机制,以提供快速的数据读写和查询响应时间。MySQL还支持主从复制和分布式架构,可以轻松地实现数据的备份和负载均衡,满足不同规模和需求的项目。MySQL的可靠性和稳定性很高。它具备ACID(原子性、一致性、隔离性和持久性)特性,确保数据的完整性和一致性。MySQL还提供了多种备份和恢复机制,可以防止数据丢失和故障发生。MySQL支持多种编程语言的接口,如Python、Java、 PYTHON等,使得开发人员可以方便地与数据库进行交互。它还提供了丰富的存储引擎选项,如InnoDB、MyISAM等,以满足不同应用场景下的需求。
2.5 B/S模式
B/S模式,即浏览器/服务器模式,是一种常见的网络应用架构模式。在B/S模式中,用户通过浏览器作为客户端与服务器进行交互。相比于传统的C/S模式,B/S模式具有许多优势。B/S模式不需要安装客户端软件,只需通过浏览器访问网页即可使用,大大降低了部署和维护成本。B/S模式实现了跨平台和跨设备的应用访问,用户可以在任何具有浏览器的设备上使用应用程序。B/S模式将应用逻辑集中在服务器端,提高了系统的安全性和稳定性,并方便进行版本升级和功能扩展。B/S模式还支持多用户同时访问,实现了信息共享和协同办公。
2.6 django框架
Django是一个基于Python的高级Web框架,由美国开发者Adrian Holovaty和David Beazley于2005年开发,其目标在于简化Web开发的复杂性,提供快速、安全且可扩展的解决方案。该框架遵循MVC(模型-视图-控制器)设计模式,将应用程序逻辑划分为模型、视图和控制器三个部分,使代码结构更加模块化且便于维护。Django内置了强大的ORM(对象关系映射)系统,开发者可以通过对象操作数据库,无需编写冗长的SQL语句,同时它还提供了完善的模板引擎和表单处理机制,从而加快了用户界面的构建过程。此外,Django在安全性方面也表现出色,内置了多项安全防护措施,如防范SQL注入、跨站请求伪造(CSRF)和跨站脚本攻击(XSS),确保Web应用的整体安全性。其支持多种数据库后端,并拥有丰富的第三方插件和扩展库,使得Django在各种规模的项目中都能高效运行。凭借其简洁的语法、强大的功能和活跃的社区支持,Django已成为众多开发者首选的Web框架,为快速开发高质量Web应用提供了坚实基础。
2.7 vue框架
Vue.js是一款轻量级的JavaScript框架,用于构建用户界面。它采用MVVM(Model-View-ViewModel)架构模式,使得开发者能够更加高效地组织代码并实现数据与视图的双向绑定。Vue.js具备简单易学、灵活高效的特点,支持组件化开发,使得构建复杂的单页应用变得简单直观。与此同时,Vue.js拥有丰富的插件和工具库,如Vue Router和Vuex,这些工具进一步提升了项目的开发效率和可维护性。总之,Vue.js是一个功能强大且开发友好的前端框架,适用于各种规模的项目,深受开发者的喜爱。
 系统实现界面展示:
系统实现界面展示:
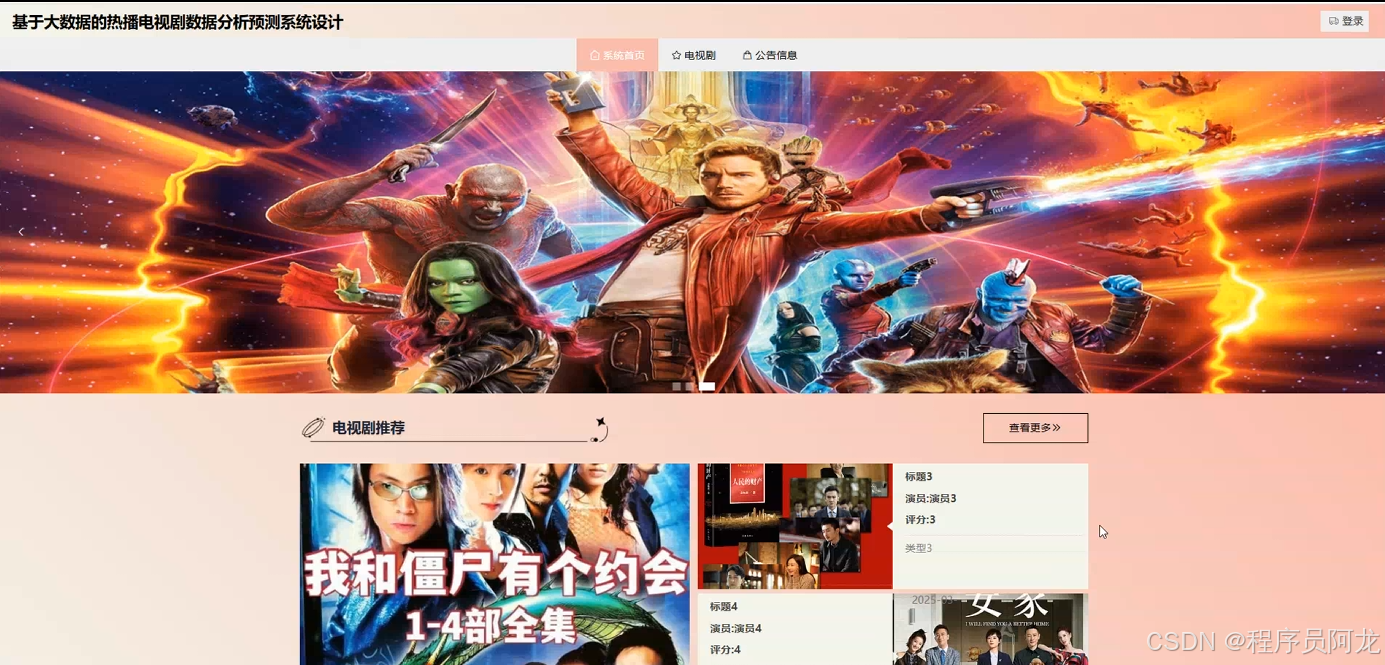
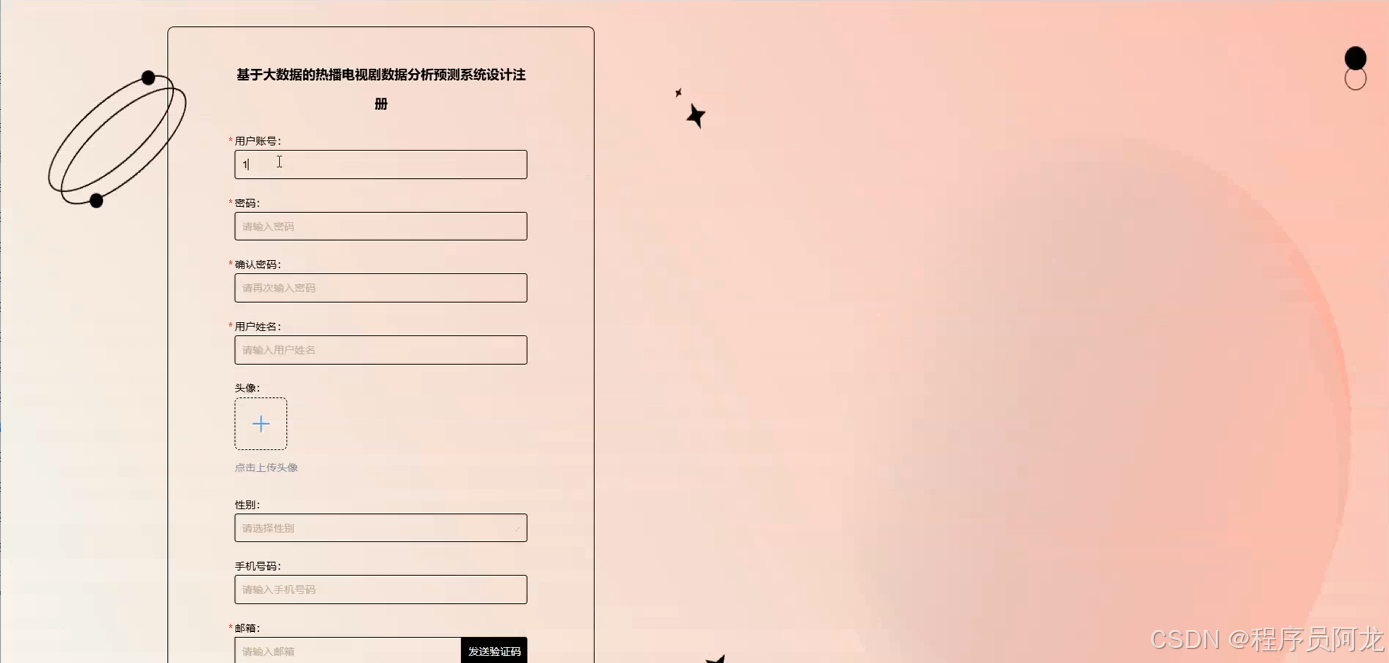
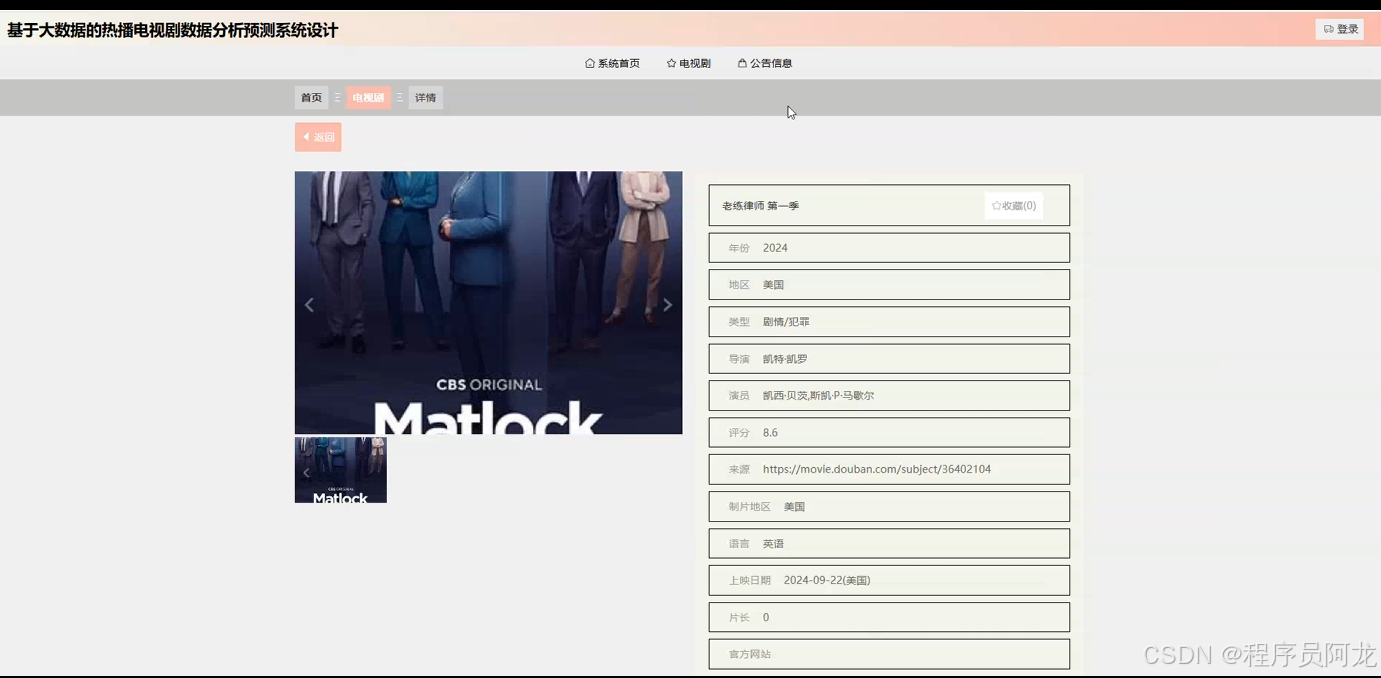
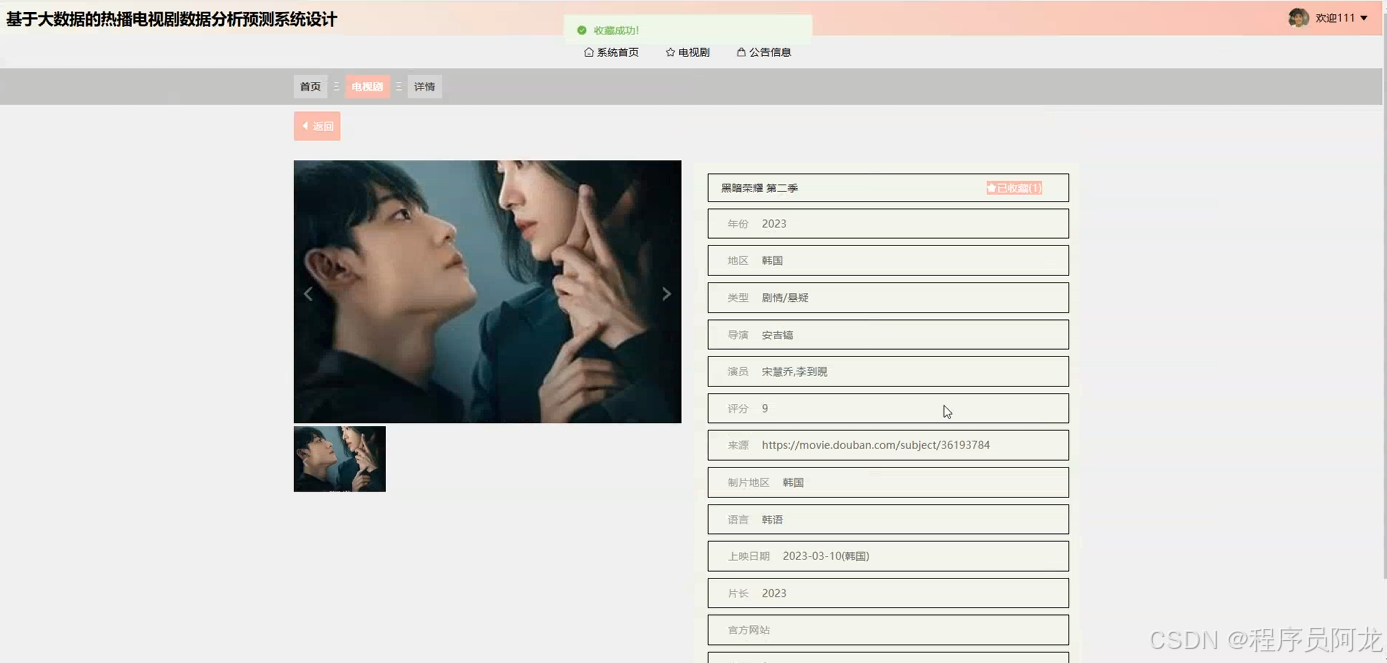
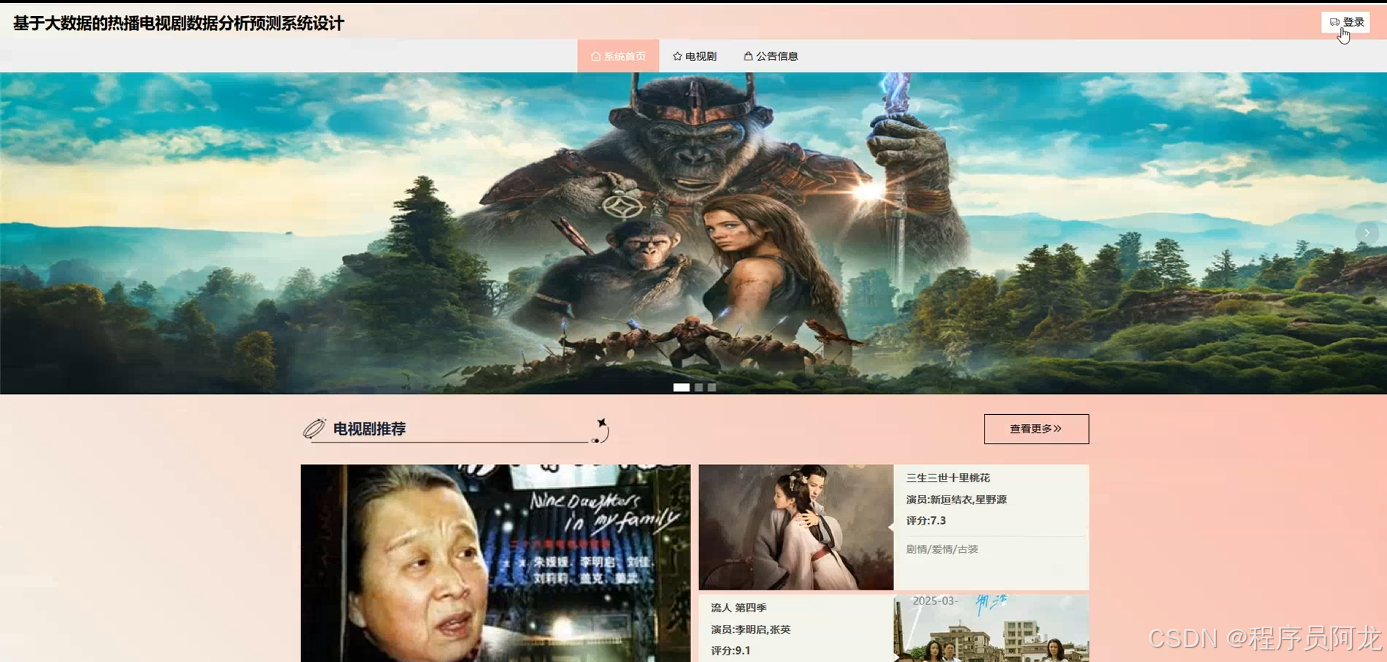
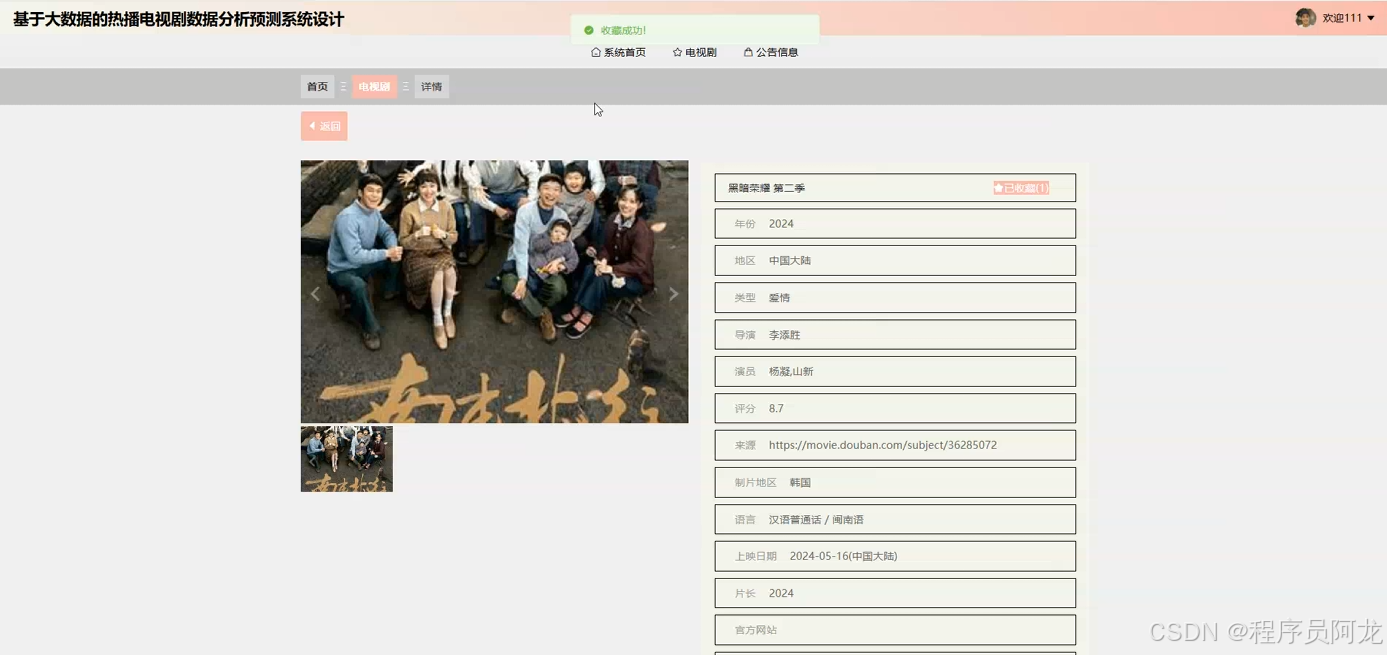
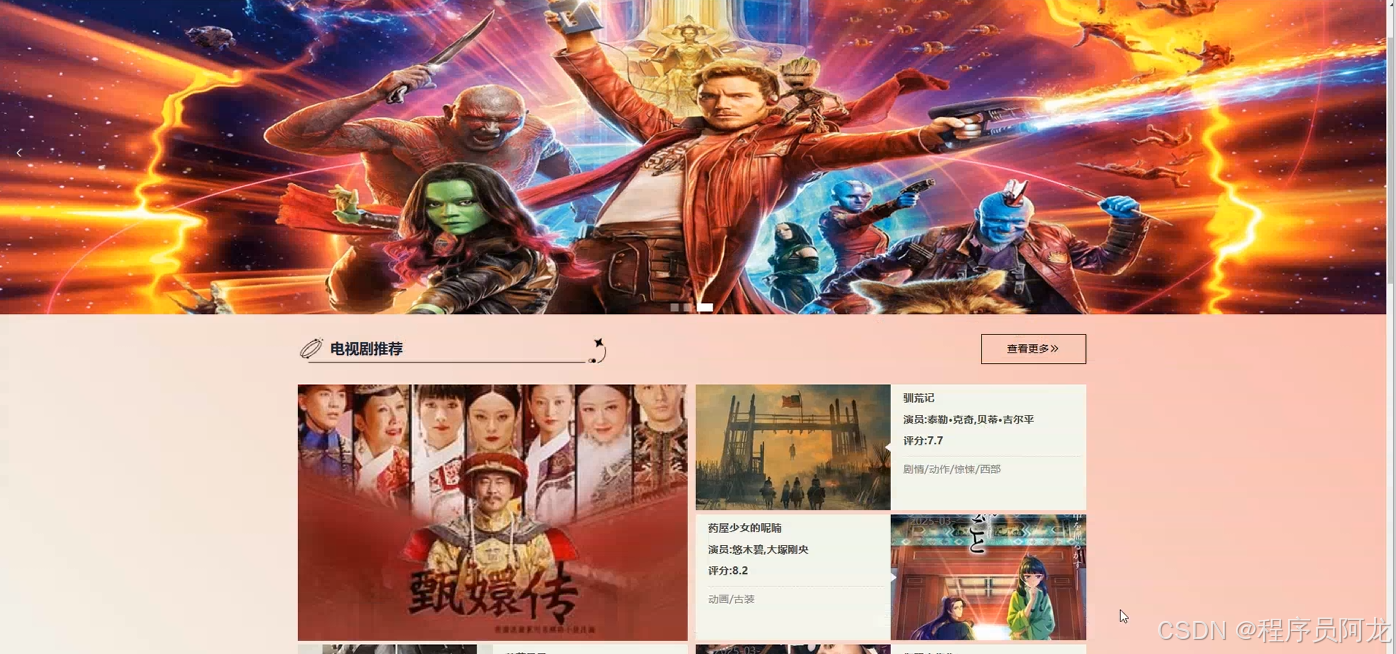
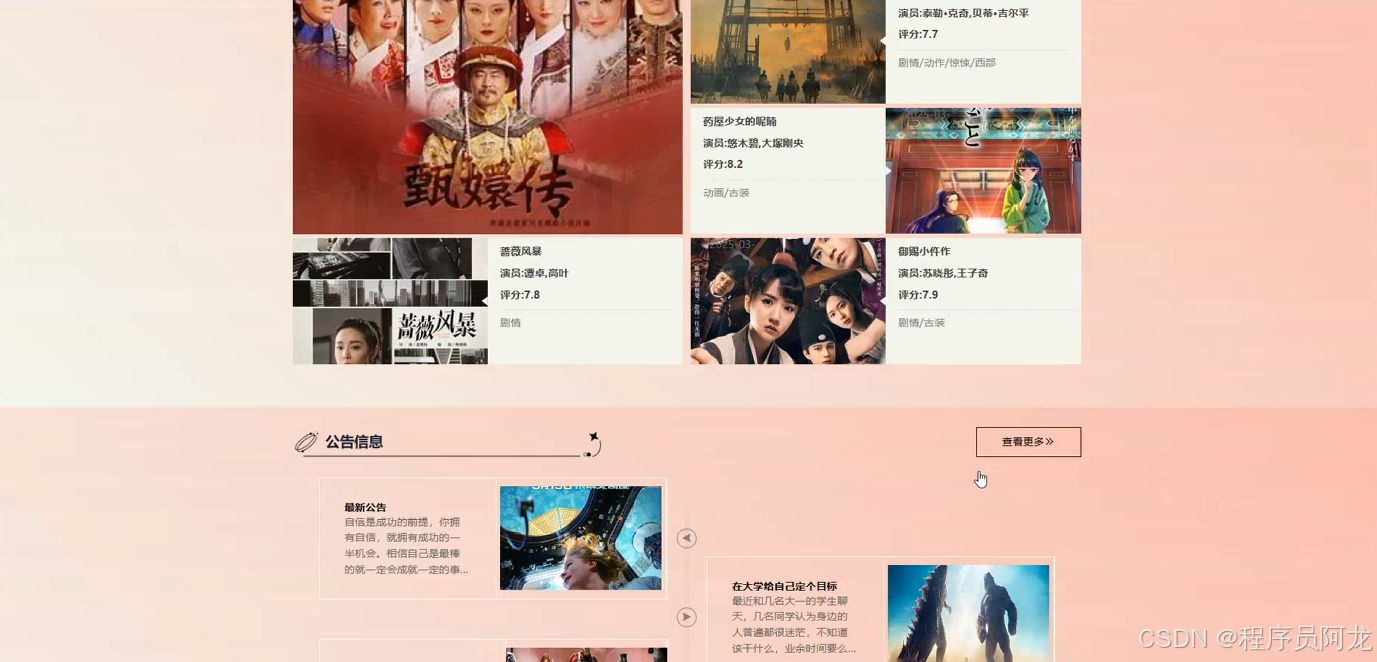


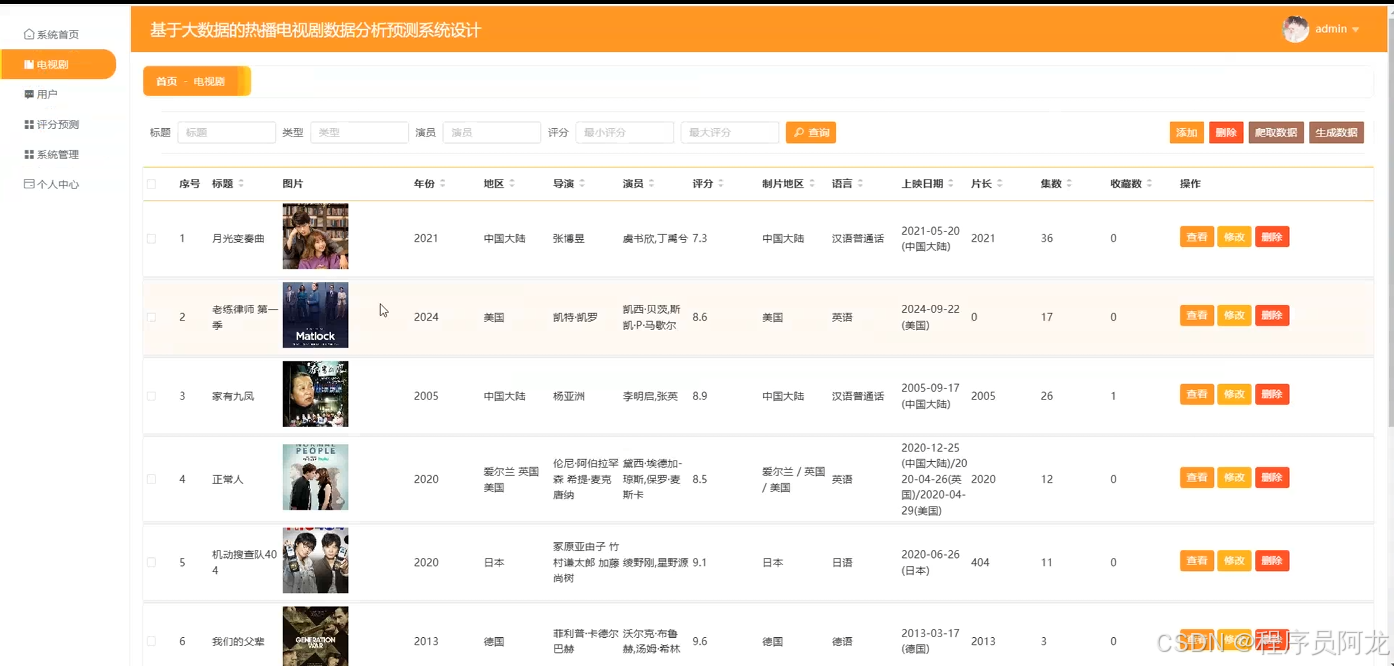
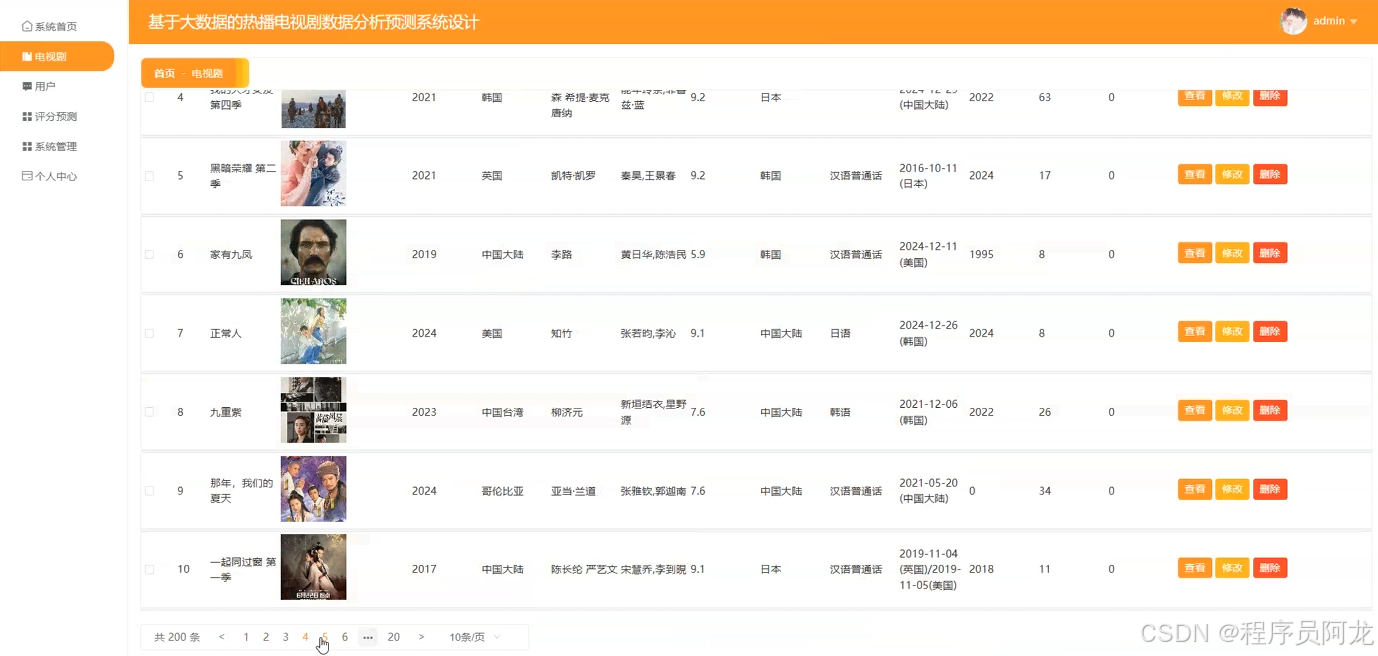
爬虫代码分析:
port time
from datetime import datetime,timedelta
import datetime as formattime
import re
import random
import platform
import json
import os
import urllib
from urllib.parse import urlparse
import requests
import emoji
import numpy as np
from DrissionPage import Chromium
import pandas as pd
from sqlalchemy import create_engine
from selenium.webdriver import ChromeOptions, ActionChains
from scrapy.http import TextResponse
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
import pandas as pd
from sqlalchemy import create_engine
from selenium.webdriver import ChromeOptions, ActionChains
from scrapy.http import TextResponse
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.chrome.service import Service
# 电视剧
class DoubanSpider(scrapy.Spider):
name = 'doubanSpider'
spiderUrl = 'https://m.douban.com/rexxar/api/v2/tv/recommend?refresh=0&start={}&count=20&selected_categories=%7B%7D&uncollect=false&tags=&ck=vwdJ'
start_urls = spiderUrl.split(";")
protocol = ''
hostname = ''
realtime = False
headers = {
"referer":"https://movie.douban.com/explore"
}
def __init__(self,realtime=False,*args, **kwargs):
super().__init__(*args, **kwargs)
self.realtime = realtime=='true'
def start_requests(self):
plat = platform.system().lower()
if not self.realtime and (plat == 'linux' or plat == 'windows'):
connect = self.db_connect()
cursor = connect.cursor()
if self.table_exists(cursor, 'kb690wga_douban') == 1:
cursor.close()
connect.close()
self.temp_data()
return
pageNum = 1 + 1
for url in self.start_urls:
if '{}' in url:
for page in range(1, pageNum):
next_link = url.format(page)
yield scrapy.Request(
url=next_link,
headers=self.headers,
callback=self.parse
)
else:
yield scrapy.Request(
url=url,
headers=self.headers,
callback=self.parse
)
# 列表解析
def parse(self, response):
_url = urlparse(self.spiderUrl)
self.protocol = _url.scheme
self.hostname = _url.netloc
plat = platform.system().lower()
if not self.realtime and (plat == 'linux' or plat == 'windows'):
connect = self.db_connect()
cursor = connect.cursor()
if self.table_exists(cursor, 'kb690wga_douban') == 1:
cursor.close()
connect.close()
self.temp_data()
return
data = json.loads(response.body)
try:
list = data["items"]
except:
pass
for item in list:
fields = DoubanItem()
try:
fields["title"] = emoji.demojize(self.remove_html(str( item["title"] )))
except:
pass
try:
fields["pic"] = emoji.demojize(self.remove_html(str( item["pic"]["normal"] )))
except:
pass
try:
fields["years"] = int( item["year"])
except:
pass
try:
fields["area"] = emoji.demojize(self.remove_html(str( item["card_subtitle"].split("/")[1].strip() )))
except:
pass
try:
fields["director"] = emoji.demojize(self.remove_html(str( item["card_subtitle"].split("/")[3].strip() )))
except:
pass
try:
fields["actors"] = emoji.demojize(self.remove_html(str( item["card_subtitle"].split("/")[4].strip().replace(" ",",") )))
except:
pass
try:
fields["score"] = float( item["rating"]["value"])
except:
pass
try:
fields["laiyuan"] = emoji.demojize(self.remove_html(str("https://movie.douban.com/subject/"+str( item["id"]) )))
except:
pass
detailUrlRule = item["id"]
detailUrlRule ="https://movie.douban.com/subject/"+str( detailUrlRule)
if detailUrlRule.startswith('http') or self.hostname in detailUrlRule:
pass
else:
detailUrlRule = self.protocol + '://' + self.hostname + detailUrlRule
fields["laiyuan"] = detailUrlRule
yield scrapy.Request(url=detailUrlRule, meta={'fields': fields}, callback=self.detail_parse)
# 详情解析
def detail_parse(self, response):
fields = response.meta['fields']
try:
fields["types"] = str( response.xpath('''//div[@id="info"]//span[@property="v:genre"]/text()''').extract()[0].strip())
except:
pass
try:
if '(.*?)' in '''制片国家/地区:</span>(.*?)<br/>''':
fields["zpdq"] = str( re.findall(r'''制片国家/地区:</span>(.*?)<br/>''', response.text, re.S)[0].strip())
else:
if 'zpdq' != 'xiangqing' and 'zpdq' != 'detail' and 'zpdq' != 'pinglun' and 'zpdq' != 'zuofa':
fields["zpdq"] = str( self.remove_html(response.css('''制片国家/地区:</span>(.*?)<br/>''').extract_first()))
else:
try:
fields["zpdq"] = str( emoji.demojize(response.css('''制片国家/地区:</span>(.*?)<br/>''').extract_first()))
except:
pass
except:
pass
try:
if '(.*?)' in '''语言:</span>(.*?)<br/>''':
fields["lang"] = str( re.findall(r'''语言:</span>(.*?)<br/>''', response.text, re.S)[0].strip())
else:
if 'lang' != 'xiangqing' and 'lang' != 'detail' and 'lang' != 'pinglun' and 'lang' != 'zuofa':
fields["lang"] = str( self.remove_html(response.css('''语言:</span>(.*?)<br/>''').extract_first()))
else:
try:
fields["lang"] = str( emoji.demojize(response.css('''语言:</span>(.*?)<br/>''').extract_first()))
except:
pass
except:
pass
try:
if '(.*?)' in '''span[property="v:initialReleaseDate"]::text''':
fields["releasedate"] = str( re.findall(r'''span[property="v:initialReleaseDate"]::text''', response.text, re.S)[0].strip())
else:
if 'releasedate' != 'xiangqing' and 'releasedate' != 'detail' and 'releasedate' != 'pinglun' and 'releasedate' != 'zuofa':
fields["releasedate"] = str( self.remove_html(response.css('''span[property="v:initialReleaseDate"]::text''').extract_first()))
else:
try:
fields["releasedate"] = str( emoji.demojize(response.css('''span[property="v:initialReleaseDate"]::text''').extract_first()))
except:
pass
except:
pass
try:
fields["runtime"] = int( response.xpath('''//div[@id="info"]//span[@class="pl" and contains(text(), '片长')]/following-sibling::text()[1]''').extract()[0].strip().replace("分钟",""))
except:
pass
try:
if '(.*?)' in '''div#info span.pl:contains("官方网站") + a''':
fields["gfurl"] = str( re.findall(r'''div#info span.pl:contains("官方网站") + a''', response.text, re.S)[0].strip())
else:
if 'gfurl' != 'xiangqing' and 'gfurl' != 'detail' and 'gfurl' != 'pinglun' and 'gfurl' != 'zuofa':
fields["gfurl"] = str( self.remove_html(response.css('''div#info span.pl:contains("官方网站") + a''').extract_first()))
else:
try:
fields["gfurl"] = str( emoji.demojize(response.css('''div#info span.pl:contains("官方网站") + a''').extract_first()))
except:
pass
except:
2.7 测试概述
系统测试就是对项目是否存在错误而运行程序的一种检测方式。系统测试对于一个软件来说极为重要,并且在开发过程中占有很大的比重。每一次功能的实现都伴随着很多次的测试。它是软件是否能用的检测环节,对于软件质量的评估有着重要影响。系统能否被验收成功是测试中最后一个至关重要的环节。
2.8软件测试原则
当进行软件测试时,有一些原则需要遵循,以确保测试的有效性和效率。
第一:测试应该尽早开始。在需求分析和系统设计阶段就应该进行测试准备,以便尽早发现系统的不足之处。这样可以降低修复成本,提高开发效率。测试人员应该在分析需求时就参与进来,确保需求具备可测试性和正确性。
第二:测试应该是全面的。测试应该覆盖软件的各个功能模块和不同的使用场景,以确保软件在各种情况下都能正常运行。测试还应该关注软件的性能、安全性和可用性等方面,以全面评估软件的质量。
随着软件开发的复杂性增加,手动测试已经无法满足需求。自动化测试可以提高测试的效率和准确性,减少人为错误。通过编写自动化测试脚本,可以快速执行大量的测试用例,并及时发现问题。软件的开发是一个迭代的过程,每个迭代都会引入新功能和修复旧问题。因此,测试也应该是一个持续的过程,与开发同步进行。持续集成和持续交付等技术可以帮助实现持续测试,确保软件在每个迭代中都能达到预期的质量标准。通过测试不仅仅是为了发现问题,更重要的是提供有价值的反馈给开发人员。测试人员应该及时向开发人员报告问题,并提供详细的复现步骤和环境信息,以便开发人员能够快速定位和解决问题。
2.9测试用例
(1)用户登陆测试用例
表 6-1 用户登录用例表
|
项目/软件 |
编制时间 |
20xx/xx/xx |
||||
|
功能模块名 |
用户登陆模块 |
用例编号 |
xxxx |
|||
|
功能特性 |
用户身份验证 |
|||||
|
测试目的 |
验证是否输入合法的信息,允许合法登陆,阻止非法登陆 |
|||||
|
测试数据 |
用户名=1密码=a1身份= 非认证用户 |
|||||
|
操作步骤 |
操作描述 |
数 据 |
期望结果 |
实际结果 |
状态 |
|
|
1 |
输入用户名和密码 |
用户名= 1密码=1 |
显示进入后的页面。 |
同期望结果。 |
正常 |
|
|
2 |
输入用户名和密码 |
用户名= 1密码=aaa |
显示警告信息“不存在该用户名或密码错误!” |
同期望结果。 |
正常 |
|
|
3 |
输入用户名和密码 |
用户名= aaa密码=1 |
显示警告信息“不存在该用户名或密码错误” |
同期望结果。 |
正常 |
|
|
4 |
输入用户名和密码 |
用户名=“” 密码=“” |
显示警告信息“用户名密码不能为空!” |
同期望结果。 |
正常 |
|
(2)用户注册测试用例
表 6-2 用户注册用例表
|
项目/软件 |
编制时间 |
20xx/xx/xx |
|||||
|
功能模块名 |
用户注册模块 |
用例编号 |
xxxx |
||||
|
功能特性 |
用户注册 |
||||||
|
测试目的 |
验证私注册是否成功,注册数据是否合法 |
||||||
|
测试数据 |
用户名=aaa 密码=aaa电子邮件=dwa@qq.com |
||||||
|
操作步骤 |
操作描述 |
数 据 |
期望结果 |
实际结果 |
测试状态 |
||
|
1 |
输入注册数据 |
用户名= aaa密码=aaa 电子邮件=dwa@qq.com |
提示:注册成功!转入用户主页 |
同期望结果。 |
正常 |
||
|
2 |
输入注册数据 |
用户名= aaa密码=aaa 电子邮件=dwa@qq.com |
提示:用户名已注册 |
同期望结果。 |
正常 |
||
|
3 |
输入注册数据 |
用户名= aaa密码=”” 电子邮件=dwa@qq.com |
提示:密码不能为空 |
同期望结果。 |
正常 |
||
|
4 |
输入注册数据 |
密码=aaa 电子邮件=dwa@qq.com |
提示:用户名为空 |
同期望结果。 |
正常 |
||



 论文部分参考:
论文部分参考:
为什么选择我(我可以给你的定制项目推荐核心功能,一对一推荐)实现定制!!!
我是程序员阿龙,专注于软件开发,拥有丰富的编程能力和实战经验。在过去的几年里,我辅导了上千名学生,帮助他们顺利完成毕业项目,同时我的技术分享也吸引了超过50W+的粉丝。我是CSDN特邀作者、博客专家、新星计划导师,并在Java领域内获得了多项荣誉,如博客之星。我的作品也被掘金、华为云、阿里云、InfoQ等多个平台推荐,成为各大平台的优质作者。
已经为上百名同学获得优秀毕业生!
源码获取
文章下方名片联系我即可~
大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻
精彩专栏推荐订阅:在下方专栏

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 17
17 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)