RAG技术全家桶:16种检索增强生成方案,从入门到实战,助你成为AI开发达人
RAG技术已从简单的"检索+生成"发展为多种专业路径,包括标准RAG、图增强RAG、记忆增强RAG、多模态RAG等16种类型。每种技术针对不同挑战设计,如准确性、延迟、合规性和上下文处理等。文章详细分析了各类RAG的关键特征、优势、应用场景和工具示例,帮助开发者根据需求选择合适的RAG方案,构建高效、准确的大模型应用。
🚀 RAG(检索增强生成)技术早已超越了其最初的形式。
当人们听到“检索增强生成”(RAG)时,通常会想到经典的流程:检索文档 → 输入给大语言模型(LLM)→ 生成答案。
但在实际应用中,RAG 已经发展出许多专门的技术路径,每种都是为了解决在准确性、延迟、合规性和上下文处理等方面的不同挑战而设计的。
以下是一些最重要的类别:
➤ 标准 RAG (Standard RAG) - 最初的检索 + 生成模式(如 RAG-Sequence, RAG-Token),是技术的基础形态。
➤ 图增强 RAG (Graph RAG) - 将大语言模型与知识图谱连接起来,用于结构化推理,在复杂关系推理中表现出色。
➤ 记忆增强 RAG (Memory-Augmented RAG) - 为智能体提供外部记忆,支持长期上下文和个性化交互,是Agentic RAG的核心组件之一。
➤ 多模态 RAG (Multi-Modal RAG) - 支持跨文本、图像、音频、视频的检索与生成,是当前的重要发展趋势。
➤ 流式 RAG (Streaming RAG) - 针对实时数据(如行情、日志)进行实时检索。
➤ 开放域问答 RAG (ODQA RAG) - 开放域问答,是最早也是最流行的应用之一。
➤ 领域特定 RAG (Domain-Specific RAG) - 为法律、医疗或金融等领域定制的检索方案。
➤ 混合 RAG (Hybrid RAG) - 结合稠密检索和稀疏检索,以提高召回率。
➤ 自反思 RAG (Self-RAG) - 让模型在最终输出前进行反思和优化,具有自我评估和调整的能力。
➤ 假设文档嵌入 (HyDE) - 通过首先生成“模拟”文档来嵌入,以改进检索。
➤ 递归/多步 RAG (Recursive / Multi-Step RAG) - 支持多跳检索和推理链。
其他如 智能体驱动RAG (Agentic RAG)、模块化RAG、知识增强RAG、上下文感知RAG等,最好将其视为系统设计模式,而非严格的类别,但它们是对特定用例非常有用的扩展。特别是智能体驱动RAG,通过引入智能体架构,实现了从“被动检索”到“主动推理”的范式跃迁,是技术演进的重要方向。
📊 下图大致勾勒了不同类型的 RAG、它们的特性、优势、应用场景及工具示例。(提示:用户提供的原文提及的图片在此无法显示,但相关技术特征已整合在上述要点中。)
👉 无论您是在构建生产级助手、领域特定的副驾,还是实时监控系统,选择合适的 RAG 技术路径都至关重要。
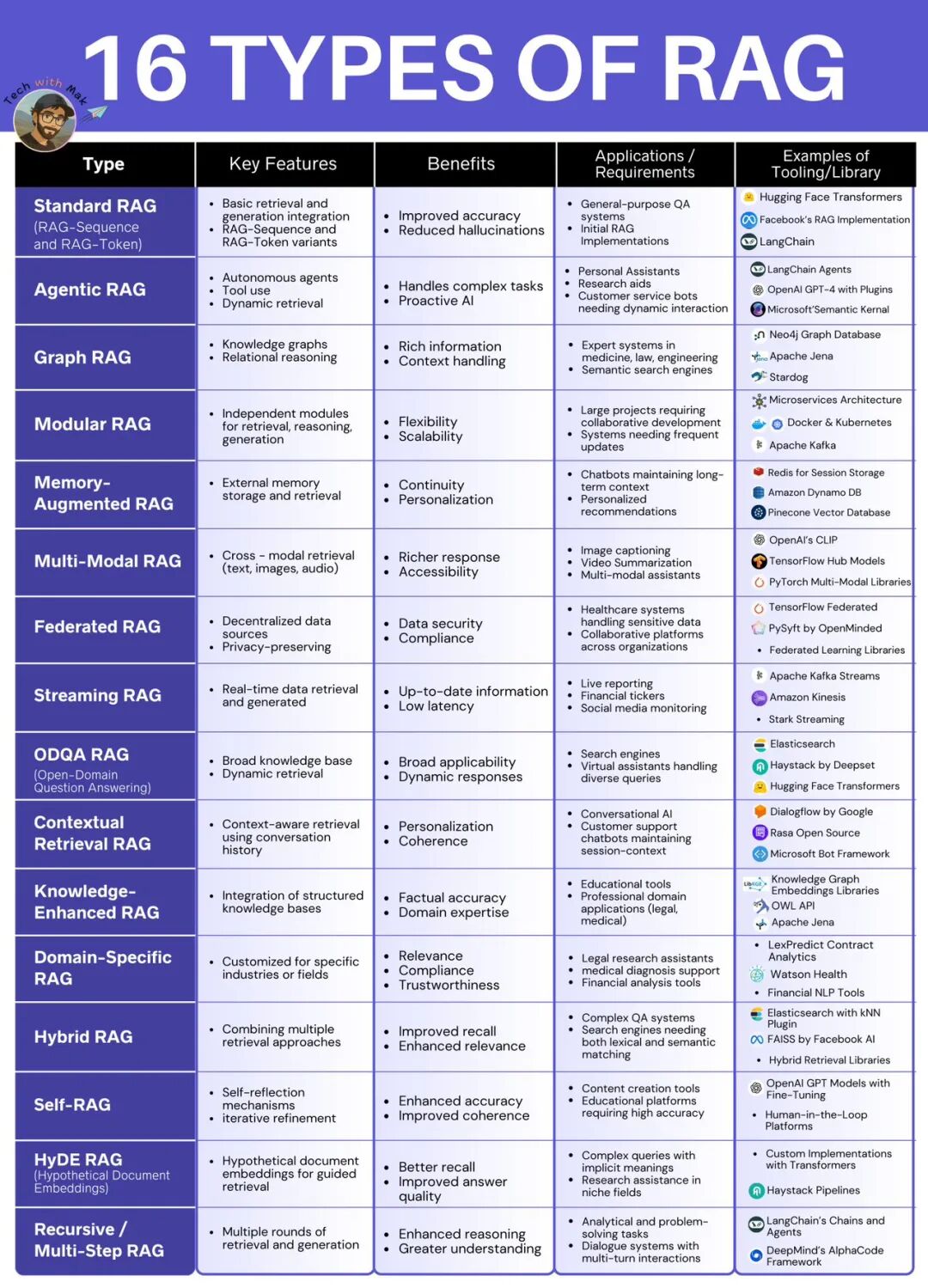
对各类型RAG方案解读16种不同类型的RAG(检索增强生成)系统。每种类型都从关键特征、优势、应用场景/需求以及工具/库示例四个方面进行了说明。
- Standard RAG (RAG-Sequence and RAG-Token)
- 关键特征: 基础的检索和生成集成。
- 优势: 提高准确性,减少幻觉。
- 应用场景: 通用问答系统,初始RAG实现。
- 工具示例: Hugging Face Transformers, Facebook’s RAG Implementation, LangChain。
- Agentic RAG
- 关键特征: 自主代理,工具使用,动态检索。
- 优势: 处理复杂任务,主动AI。
- 应用场景: 个人助理,研究助手,需要动态交互的客户服务平台。
- 工具示例: LangChain Agents, OpenAI GPT-4 with Plugins, Microsoft Semantic Kernel。
- Graph RAG
- 关键特征: 知识图谱,关系推理。
- 优势: 丰富信息,上下文处理。
- 应用场景: 医学、法律、工程领域的专家系统,语义搜索引擎。
- 工具示例: Neo4j Graph Database, Apache Jena, Stardog。
- Modular RAG
- 关键特征: 独立模块用于检索、推理、生成。
- 优势: 灵活性,可扩展性。
- 应用场景: 需要协作开发的大型项目,需要频繁更新的系统。
- 工具示例: Microservices Architecture, Docker & Kubernetes, Apache Kafka。
- Memory-Augmented RAG
- 关键特征: 外部记忆存储和检索。
- 优势: 连续性,个性化。
- 应用场景: 长期上下文维护的聊天机器人,个性化推荐。
- 工具示例: Redis for Session Storage, Amazon Dynamo DB, Pinecone Vector Database。
- Multi-Modal RAG
- 关键特征: 跨模态检索(文本、图像、音频)。
- 优势: 更丰富的响应,可访问性。
- 应用场景: 图像字幕,视频摘要,多模态助手。
- 工具示例: OpenAI’s CLIP, TensorFlow Hub Models, PyTorch Multi-Modal Libraries。
- Federated RAG
- 关键特征: 去中心化数据源,隐私保护。
- 优势: 数据安全,合规性。
- 应用场景: 处理敏感数据的医疗系统,跨组织协作平台。
- 工具示例: TensorFlow Federated, PySyft by OpenMined, Federated Learning Libraries。
- Streaming RAG
- 关键特征: 实时数据检索和生成。
- 优势: 最新信息,低延迟。
- 应用场景: 实时报告,金融票据,社交媒体监控。
- 工具示例: Apache Kafka Streams, Amazon Kinesis, Stark Streaming。
- ODQA RAG (Open-Domain Question Answering)
- 关键特征: 广泛的知识库,动态检索。
- 优势: 广泛适用性,动态响应。
- 应用场景: 搜索引擎,处理多样查询的虚拟助手。
- 工具示例: Elasticsearch, Haystack by Deepset, Hugging Face Transformers。
- Contextual Retrieval RAG
- 关键特征: 使用对话历史的上下文感知检索。
- 优势: 个性化,连贯性。
- 应用场景: 对话式AI,保持会话上下文的客户支持聊天机器人。
- 工具示例: Dialogflow by Google, Rasa Open Source, Microsoft Bot Framework。
- Knowledge-Enhanced RAG
- 关键特征: 结构化知识库的集成。
- 优势: 事实准确性,领域专长。
- 应用场景: 教育工具,专业领域应用(法律、医疗)。
- 工具示例: Knowledge Graph Embeddings Libraries, OWL API, Apache Jena。
- Domain-Specific RAG
- 关键特征: 针对特定行业或领域的定制化。
- 优势: 相关性,合规性,可信度。
- 应用场景: 法律研究助手,医疗诊断支持,财务分析工具。
- 工具示例: LexPredict Contract Analytics, Watson Health, Financial NLP Tools。
- Hybrid RAG
- 关键特征: 结合多种检索方法。
- 优势: 提高召回率,增强相关性。
- 应用场景: 复杂问答系统,需要词法和语义匹配的搜索引擎。
- 工具示例: Elasticsearch with kNN Plugin, FAISS by Facebook AI, Hybrid Retrieval Libraries。
- Self-RAG
- 关键特征: 自我反思机制,迭代优化。
- 优势: 增强准确性,提高连贯性。
- 应用场景: 内容创作工具,需要高准确性的教育平台。
- 工具示例: OpenAI GPT Models with Fine-Tuning, Human-in-the-Loop Platforms。
- HyDE RAG (Hypothetical Document Embeddings)
- 关键特征: 假设文档嵌入用于引导检索。
- 优势: 更好的召回率,提高答案质量。
- 应用场景: 复杂查询(隐含含义),特定领域的研究助手。
- 工具示例: Custom Implementations with Transformers, Haystack Pipelines。
- Recursive / Multi-Step RAG
- 关键特征: 多轮检索和生成。
- 优势: 增强推理能力,更好的理解力。
- 应用场景: 分析性和问题解决任务,多轮交互的对话系统。
- 工具示例: LangChain’s Chains and Agents, DeepMind’s AlphaCode Framework。
一张图片为理解和选择适合特定需求的RAG系统提供了全面的参考。
那么,如何系统的去学习大模型LLM?
作为一名深耕行业的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
由于篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~
👉大模型学习指南+路线汇总👈
我们这套大模型资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。

👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。
👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。
👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。
👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 7
7 0
0- 0



 已为社区贡献357条内容
已为社区贡献357条内容

所有评论(0)