只有 0.9B 的小个子,凭什么打败了 GPT-4o 的读图能力?[PaddleOCR-VL-0.9B测试体验]
【0.9B小模型如何击败GPT-4o?PaddleOCR-VL的文档识别黑科技】 仅0.9B参数的PaddleOCR-VL在OmniDocBench评测中超越GPT-4o等大模型,其成功秘诀在于创新的两阶段处理:先用PP-DocLayoutV2模型快速分割页面元素并确定阅读顺序,再通过动态分辨率视觉编码器精准识别每个区块。这种"先分块后处理"的流水线方式,使其在复杂表格(准确率
首先写一个比较热门的标题[只有 0.9B 的小个子,凭什么打败了 GPT-4o 的读图能力?]
先是 DeepSeek-OCR 把“长文档低成本读图”这件事卷出了新高度,随即一堆模型跟进,朋友圈、社区、评测榜全在谈“把图片读成结构化”。
整个Hugging Face的趋势版里,前4有3个OCR,甚至Qwen3-VL-8B也能干OCR的活,说一句全员OCR真的不过分。
虽然 DeepSeek 和阿里的 Qwen 都在搞,但我们准备尝试一个“个头很小”的模型——PaddleOCR-VL-0.9B。参数小(脑容量不大),但在专门“读文档”这件事上,它在权威榜单上居然拿了第一,比著名的 GPT-4o 还要准,所以专门拿它来试试效果。
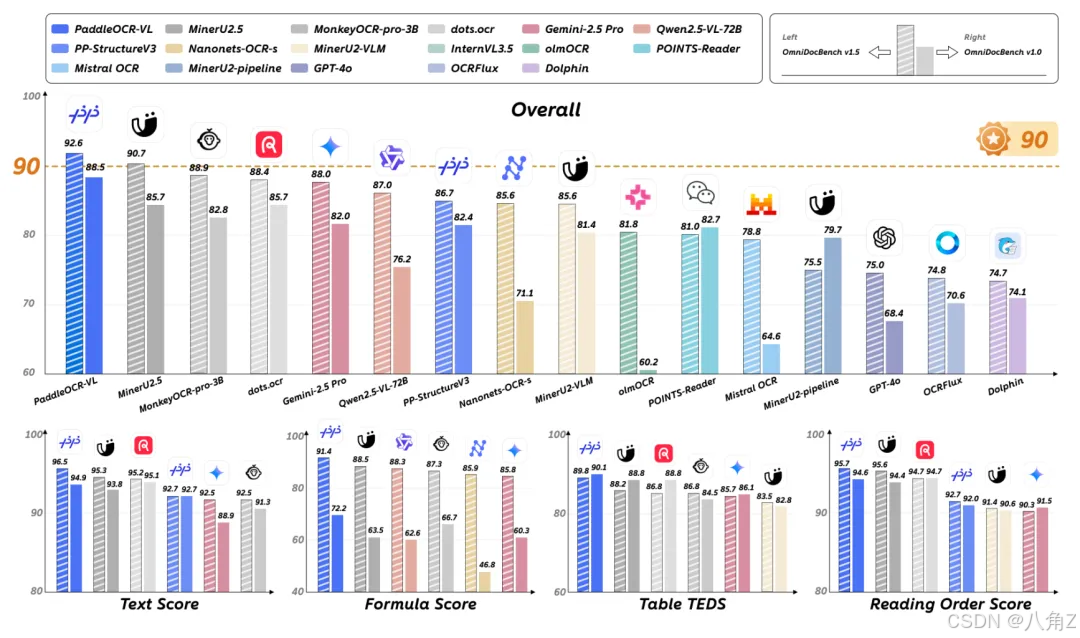
官方技术报告在 OmniDocBench v1.5 的页级评测给了完整对比表:PaddleOCR-VL 92.56(第一),细项里文字 EditDist、公式 CDM、表格 TEDS / TEDS-S、阅读顺序等均领跑;同表格还能看到 GPT-4o、InternVL、Gemini 2.5 Pro 等通用 VLM 的分数对照。
那么它牛在哪里呢?
很多的多模态大模型,是端到端的,他们干OCR的方式其实是非常低效的。
就是你把一整张A4纸扔给它,它需要一口气把这张图上所有的文字、表格、公式、图片、排版等等全都看懂,然后再一口气生成一个完美的Markdown,这个难度,其实也挺地狱级的。
毕竟模型需要同时理解这么多元素,那效果不好也是情有可原的。
然而PaddleOCR-VL-0.9B用了一种新的方式
-
用 PP-DocLayoutV2 布局分析模型做页面元素检测 + 分类 + 阅读顺序预测,把标题/正文/表格/公式各就各位;这一步轻量、成熟、超快。
打个比方,把一页 PDF 想成“杂货摊”。PP-DocLayoutV2 先“扫一眼”,给页面打框+贴标签+排顺序:这块是标题、那块是正文、这里是表格、那边是公式,并按人类阅读顺序标 1、2、3…… 它用的是检测器 + 指针网络,显式建模块与块之间的几何关系,所以多栏/跨栏、长标题这种“麻烦活”在这一步就理顺了。
这一步的产物很“工程化”——一堆小图块(块图)+每块的类别+顺序号。后面的小模型只需对小图块各个击破,自然少犯结构性大错。
-
把裁好的小块图交给 PaddleOCR-VL-0.9B,由 NaViT 风格动态分辨率视觉编码器 + ERNIE-4.5-0.3B 语言模型联手,分别产出 Markdown(文本/表)和 LaTeX(公式)
因为视觉侧用的是 NaViT 风格的“原生分辨率”编码,所以不需要把整页强行缩到固定尺寸,而是让每个块按合适分辨率进入,该清晰的地方(细线、上下标、格线)就不会被缩糊;语言侧用轻量的 ERNIE-4.5-0.3B 作为解码头,直接吐 Markdown 表格/LaTeX 公式 等可落地格式。两者叠起来,109 语言、表格/公式/图表/顺序 全覆盖,还保持小体量和高吞吐。
换句话说,PaddleOCR-VL-0.9B 比较聪明,它采用了“流水线”作业,分两步:
-
第一步:先当“监工”,把图切开。 它有个专门的小助手(PP-DocLayoutV2),先把整张图扫一遍。它不急着认字,而是先圈地盘:
-
第二步:再当“工匠”,精细干活。 切好之后,PaddleOCR-VL 接手。因为它不需要处理整张大图,只需要盯着切好的小图块看,所以哪怕是表格里的一根细线、公式里的一个小上标,它都能看得清清楚楚,直接把结果写成 Markdown 或者 LaTeX 公式。
总结就是:大模型是“囫囵吞枣”,它是“细嚼慢咽”,所以消化得好。
接入业务后,我们发现它有几个绝活:
-
公式和日语: 就算是你随手拍的、有点糊的课堂板书,或者是复杂的数学公式,它都能还原出来。
-
手写体: 那种歪歪扭扭的字,甚至稍微有点乱的,它都能认个八九不离十,还能给你排好版。
-
最强项——复杂表格: 这是它的杀手锏。财报里那种跨行跨列、好几个格子并在一起的“变态表格”,很多大模型读出来是乱的。但这哥们因为先“圈了地盘”,所以能把表格还原得规规矩矩,连表里的单位都不漏。
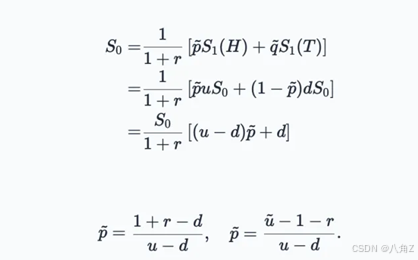
两个字,厉害。
真正决定能不能进生产的,是复杂结构。我紧接着丢了一张财报里的“合并单元格大表”。常见的通用多模态在这类表上容易迷路:要么把合并单元格当成两个格子,要么阅读顺序错位。PaddleOCR-VL 的套路完全是工程化的——先把表这个区域框出来,再把这块图单独识别,最后输出出来的就是一张规规矩矩的 Markdown 表,跨行跨列的逻辑都在,表注和单位也没丢。
不过,
坦白讲,PaddleOCR-VL-0.9B 再猛,也不是“拿来就完美”。我们在票据类图片上踩到的第一个坑,就是它有时会把装饰性的品牌字样当正文一路念下去——最典型就是登机牌上的 “EVA AIR”。LOGO在画面里反复出现、字体又醒目,模型就像被“粘”住一样,把这几个字复读成一整页,甚至把答复拉到截断。对长文档这是致命的:既浪费 token,也把有效信息淹没了。直观感觉就是它的“去重/去水印”意识还不强,遇到背景文字密集或有纹理的票据、海报、展板,容易误把装饰当正文。
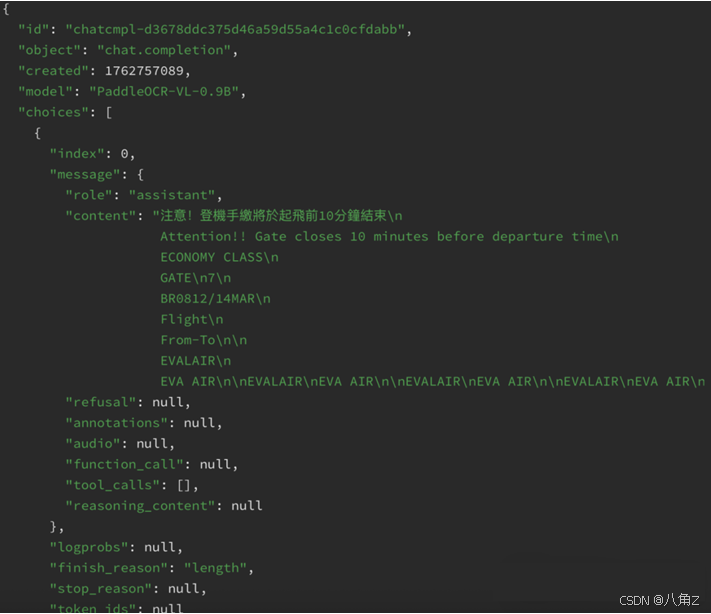
这里有个明显短板就是结构化输出的不稳定。
你让它只返回 JSON,它有时能听话,有时就往内容里混进自由发挥:字段名换成中文、同一个键重复好多遍、或者把一句话解释硬塞进来。更糟的是,偶尔干脆给你一个空的 content,导致你在 choices[0].message.content 读不到东西——这在需要机器对接的场景里等于没法落地。要想让它持续吐合规 JSON,工程侧得上更强的约束或后处理,否则一旦图片复杂、上下文长,输出就会飘。
再就是“字段语义”的理解力,在通用票据里并不始终可靠。像登机牌这种模板化很强的票据,按理说应该很好抽,但它会漏掉 from/to、gate/zone/seat,或者把航班号写成不规范的格式;中文英文混在一起时还会挑容易的先读,难的就空着。你能感到它的强项还是“把图转成可读文本、把表转成 Markdown”,而不是“理解不同票据的行业语义并稳定抽字段”。
还有一个体验层面的槽点:在没有强约束时,它特别容易越写越长。整页识别场景,遇到版面复杂一点的票据或登机牌背板,它会把能看到的文本都念出来,甚至把重复区域反复输出,最后触发长度截断。你如果默认给了很大的 max_tokens,把计费拉满;可是把上限收紧,它又可能把关键信息写少。换句话说,长度控制和重复抑制,模型自身还不够克制。
最后,说一句公道话:手写、斜拍、低清晰度这类难题,它的容错比很多通用 VLM 好,但也谈不上无敌。手写如果接近“医生体”,还是会出错;斜拍+阴影+反光并存时,阅读顺序偶尔会错位,复杂表格的合并单元格也可能被打散。这些不是它一家独有的问题,但在“直接用于生产”的视角看,仍然需要一些工程补偿——比如轻量布局检测、区域去水印、模板校验、正则/字典修正、以及长度/重复的阈值治理。
给大家的建议: 这就好比找了个视力 5.0 的速记员。他能把你给的文件一字不差地敲出来,连表格都能画好。但是,他有时候会把纸上的水印也敲进去,或者你让他填表他非要写作文。 所以,用它的时候,必须配一个“审核员”(写代码做后处理),专门负责把水印删掉、把格式改对,这样才能真正干活。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 20
20 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)