医学大模型事实准确性新突破:基于知识图谱的自动化评估框架FAITH
FAITH框架:基于知识图谱的医学大模型事实核查新方法 研究团队提出FAITH框架,通过医学知识图谱自动核查大语言模型生成内容的准确性。该创新方法将响应分解为原子声明,与知识图谱匹配进行评分,无需参考答案即可评估事实性。实验表明,FAITH在四个医学问答数据集上显著优于传统评估方法,与临床医生判断具有更高相关性,并能有效区分不同能力的模型。框架具备无监督运行、强鲁棒性和良好可解释性等特点,为医疗A

文章摘要
研究者提出了FAITH框架,利用医学知识图谱对大语言模型生成的医学内容进行自动化事实核查。该框架无需参考答案,通过将响应分解为原子声明并与知识图谱匹配来评分,在与临床医生判断的相关性方面显著优于传统方法,为医学AI安全部署提供重要保障。
原文PDF: https://t.zsxq.com/RneoT
正文内容
研究背景:医学AI的"幻觉"难题
大语言模型在医疗健康领域展现出巨大潜力,在各种医学任务中表现出强大能力。然而,在高风险的医疗环境中部署LLM需要严格的验证,以确保信息的准确性和可信度。最令人担忧的是LLM可能产生看似合理但实际上危险错误的信息,即所谓的"幻觉"现象。这种不准确性严重影响利益相关者的信任,成为临床应用和监管批准的重大障碍。
传统的自动化评估方法主要依赖于自然语言处理指标,如BLEU和BERTScore,但这些指标在医疗等专业领域的实用性有限,因为它们需要人工制作的参考答案,而这在实践中很难获得。更重要的是,多项研究表明,这些指标与临床医生的判断相关性较差,因为它们主要关注与参考文本的整体词汇或语义相似性,而人类专家更优先评估LLM生成响应中特定声明的事实准确性。
创新解决方案:FAITH框架横空出世
为了系统评估知识图谱在医学LLM事实核查中的潜在应用,研究团队开发了FAITH(fact-aware evaluation of LLM-generated contents in healthcare)框架——一个基于医学知识图谱的无监督、无参考答案框架。
FAITH框架的工作流程:
- 原子声明分解
:首先将LLM生成的响应分解为原子医学声明(如图1b所示)
- 实体解析映射
:使用实体解析技术将这些声明中的医学实体映射到医学知识图谱中的相应节点
- 证据路径识别
:遍历知识图谱以识别连接相关实体的证据路径
- 事实性评分
:基于路径特征和边语义为每个声明计算事实性分数,最终将个别声明分数聚合为整个响应的总体事实性分数
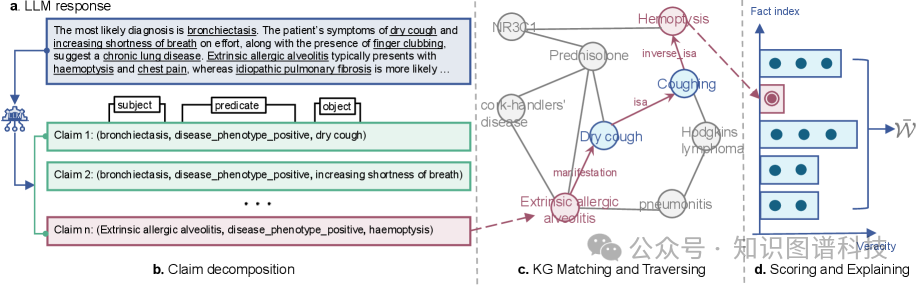
【图1:显示FAITH框架概览,包含LLM生成的医学内容示例、结构化声明处理、知识图谱匹配和评分计算流程】
实验设计与评估体系
研究团队在四个已建立的医学问答任务上评估了FAITH的有效性,包括定量和主观评估:
-
MedQA:医学问答数据集
-
MMLU:多任务语言理解基准
-
MS-AKT:医学知识测试
-
LiveQA:开放式问答
这些数据集涵盖了多项选择题和开放式问题,具有不同的复杂性和覆盖范围。研究使用了UMLS(统一医学语言系统)2025AA版本作为医学知识图谱,该系统整合了超过200个标准生物医学词汇源的知识,包含340万个概念之间的2300多万个关系。
实验结果:显著优势凸显
1. 模型区分能力强
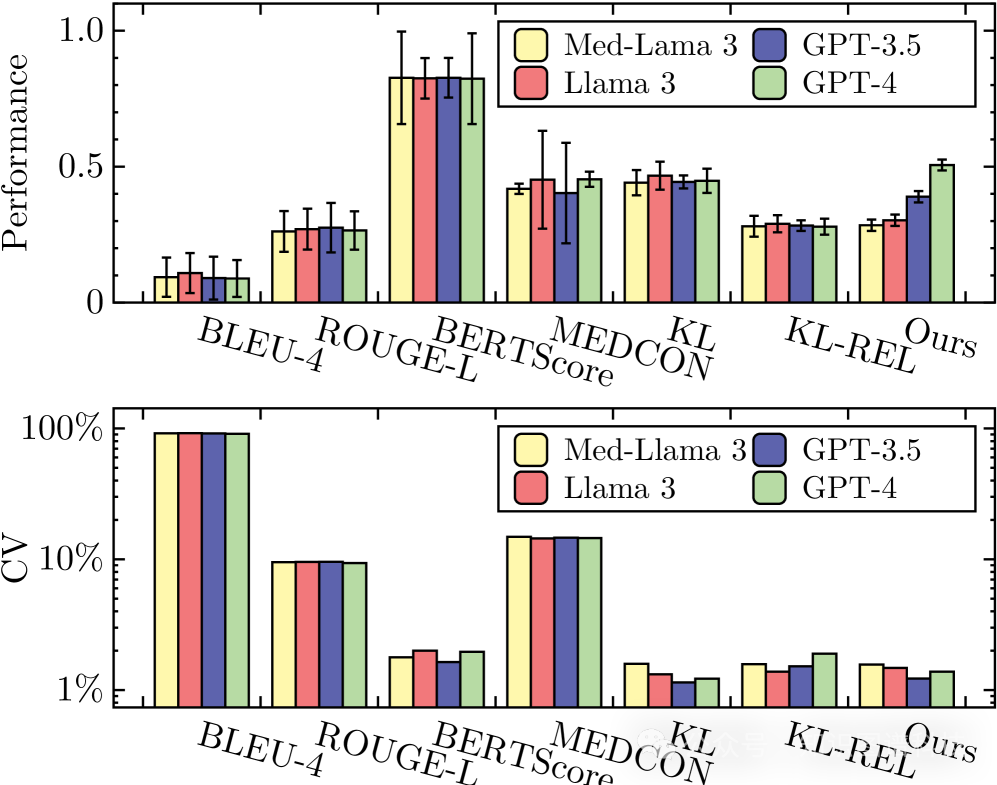
【图2:展示FAITH在四个数据集上对五个不同LLM的评分结果,可靠的指标应该能为不同模型分配可区分的分数】
实验结果表明,FAITH能够有效区分具有不同能力的LLM,并且对文本变化具有鲁棒性。
2. 与临床医生判断高度相关
FAITH与临床医生判断的相关性显著高于传统方法,这主要因为它关注特定医学声明的事实准确性,而非整体文本相似性。
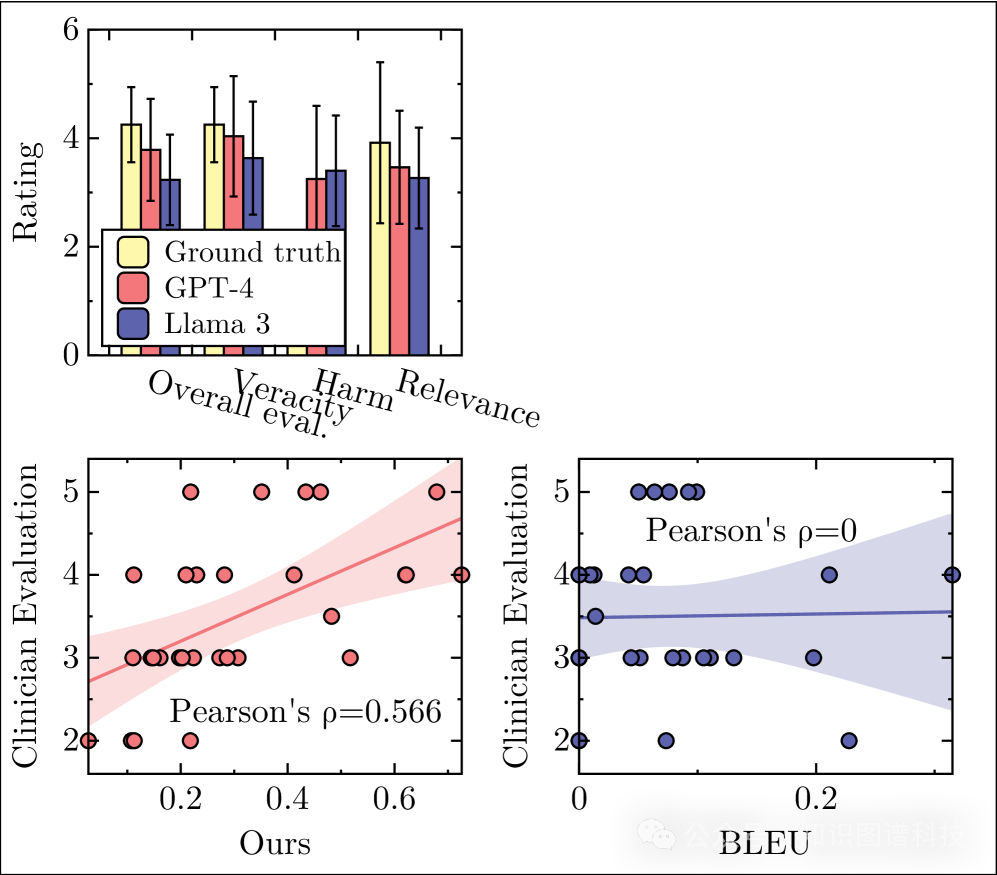
3. 无需参考答案和监督训练
与需要人工制作参考答案的传统方法不同,FAITH可以在没有参考答案或监督训练的情况下工作,使其非常适合现实世界的应用场景。
4. 优秀的可解释性
FAITH通过精确定位哪些特定声明存在问题,提供了比现有方法更好的可解释性,这对于理解和缓解当前LLM的局限性具有重要意义。
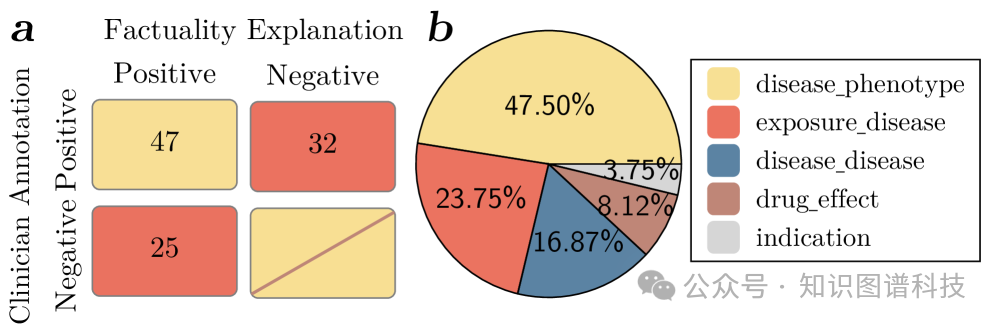
创新特点与技术优势
相比于传统方法,基于知识图谱的事实核查器展现出以下特点:
技术创新点:
- 无参考运作
:不需要参考答案或监督训练,高度适合现实世界环境
- 临床相关性
:与临床医生判断显著更好的相关性
- 鲁棒性强
:对输入文本中的噪声具有鲁棒性,能有效区分不同能力的LLM
- 可解释性优
:通过精确定位可疑声明提供更好的可解释性
实际应用价值:
研究团队还调查了FAITH是否可以作为阈值机制来改善基于LLM的医学系统的安全性,并将其应用于医学摘要和事实验证任务,进行了核心组件的消融分析。
局限性与未来展望
虽然FAITH展现出显著优势,但研究也揭示了一些局限性:
主要限制:
- 知识图谱质量依赖
:框架的可靠性对KG的质量和覆盖范围要求很高。涉及KG中缺失知识的事实声明无法得到验证,可能导致潜在的假阴性结果
- 上游模块依赖
:整个流程依赖于上游医学声明提取模块的性能。虽然基于LLM的提取器证明有效,但这一阶段的错误可能在系统中传播
未来发展方向:
-
整合多个知识图谱以提高覆盖范围
-
开发处理超出KG范围声明的方法
-
改进医学声明提取的准确性
-
扩展到法律、金融等其他关键领域的事实核查
社会影响与应用前景
FAITH通过自动评估LLM响应的事实性,增强了LLM的安全性和可靠性。它作为防范错误信息的关键"护栏",促进临床医生和监管机构的可信采用,同时为开发者提供有针对性的反馈以改进模型。该核心方法还可适用于法律和金融等事实性至关重要的其他关键领域的事实核查。
开源贡献与可复现性
为了促进学术界和工业界的进一步研究,研究团队将FAITH的源代码开源,可在GitHub上获取:https://github.com/COLA-Laboratory/FAITH。
技术发展趋势
随着医学知识图谱技术的不断发展和完善,预计FAITH框架的可靠性将进一步提升。新的医学KG的出现将改善知识覆盖和精度,从而增强整个评估框架的效果。这标志着自动化事实核查技术在医疗AI安全保障方面的重要里程碑。
学术价值与产业意义
这项研究不仅在学术上具有重要价值,为医学AI的安全评估提供了新的范式,同时也具有重要的产业应用前景。对于医疗机构、AI公司、监管部门以及投资机构而言,FAITH框架代表了一个可实施的、可扩展的解决方案,为医学AI的商业化部署提供了重要的安全保障工具。
随着人工智能在医疗领域应用的不断深入,确保AI系统输出的准确性和可靠性将成为行业发展的关键要素。FAITH框架的出现,为这一挑战提供了创新性的技术解决方案,有望成为医学AI质量保证体系的重要组成部分。
标签
#知识图谱 #医学AI #KnowledgeGraph #FactChecking #大模型 #LLM

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 4
4 0
0- 0



 已为社区贡献32条内容
已为社区贡献32条内容

所有评论(0)