chatgpt数据分析
设置随机森林在训练和预测时使用的 CPU 核心数量为1,其他参数保持默认值。
本项目使用的数据集来自于 Kaggle 上的 ChatGPT 产品评论数据集。该数据集包含了大量用户对 ChatGPT 的评价和反馈,涵盖了用户的满意度、使用体验、功能需求等多个方面。
数据集的主要字段包括: - reviewId:评论的唯一标识符 - userName:用户的昵称 - content:用户的评论文本 - score:用户对 ChatGPT 的评分(1-5星) - thumbsUpCount:其他用户对该条评论的点赞数 - reviewCreatedVersion:应用版本 - at:评论的创建时间 - appVersion:应用版本,与 reviewCreatedVersion 相同
A. 业务分析(30%)
评估目标
评估学生理解业务需求、分析数据价值并提出洞见的能力。
实操任务
- 数据获取与初步处理
- 正确读取 ChatGPT 评论数据集
- (1)导入 pandas 库。
- (2)使用 pandas 库中合适的方法读取 dataset 目录下的数据集:chatgpt_reviews.csv,返回的对象命名为 df。
- 检查数据集基本情况
- (1)打印输出 df 的形状。
- (2)查看 df 的前 10 条数据。
- 分析数据集结构、字段含义及数据质量状况(缺失值、重复值等)
- (1)使用合适的方法检查 df 的基本结构,包括 df 的类型、行列数、列的基本信息、内存占用等。
- (2)统计 df 中每列的缺失值数量。
- (3)统计 df 中的重复值数量,并筛选出这些重复的行。
- 数据清洗
- (1)删除 df 中的重复行,直接在原 df 上进行操作。
- (2)对 df 中包含缺失值的行进行删除处理,直接在上一步 df 上进行操作。
- 用户评论数据探索分析(13分)
- 分析评论数据时间分布特征
- (1)将数据集中的 at 时间列转换成 datetime 格式。
- (2)从上一步转换后的 at 时间列提取年份、月份及日期,创建新的列(year、month、day)来存储这些时间特征。
- (3)按月统计评论数量(review_count)。
- (4)基于上一步的统计结果,使用 matplotlib 绘制折线图可视化月度评论数量,横坐标为月份,纵坐标为评论数量,标题为“ChatGPT评论数量月度趋势”。
- 分析 ChatGPT 评分分布状况及点赞数与评分的关系
- (1)统计 df 中评分列(score)的分布,使用 seaborn 绘制饼图可视化评分占比,标题为“ChatGPT评分占比”。
- (2)统计 df 中评论点赞数列(thumbsUpCount)的分布,使用 seaborn 绘制散点图可视化点赞数与评分的关系,横坐标为 score,纵坐标为 thumbsUpCount,标题为“thumbsUpCount-score 关系”。
- 市场洞察提取
- 根据“ChatGPT评论数量月度趋势”图分析 ChatGPT 的市场接受度和市场表现关键特征
- 分析“thumbsUpCount-score 关系”图,提取业务洞见
A.1.1 正确读取 ChatGPT 评论数据集
(1)导入 pandas 库。
import pandas as pd
(2)使用 pandas 库中合适的方法读取 dataset 目录下的数据集:chatgpt_reviews.csv,返回的对象命名为 df。
df = pd.read_csv('./chatgpt_reviews.csv')
A.1.2 检查数据集基本情况
(1)打印输出 df 的形状。
df.shape
(102016, 8)
(2)查看 df 的前 10 条数据。
df.head(10)
A.1.3 分析数据集结构、字段含义及数据质量状况(缺失值、重复值)
(1)使用合适的方法检查 df 的基本结构,包括 df 的类型、行列数、列的基本信息、内存占用等。
df.info(memory_usage='deep')
(2)统计 df 中每列的缺失值数量。
df.isnull().sum()
(3)统计 df 中的重复值数量,并筛选出这些重复的行。(按照如下代码注释编写代码)
# 统计 df 中的重复值数量
duplicate_count = df.duplicated().sum()
print(f"重复值数量: {duplicate_count}")
重复值数量: 2044
# 筛选出这些重复的行
duplicate_rows = df[df.duplicated()]
print(duplicate_rows)
A.1.4 数据清洗
(1)删除 df 中的重复行,直接在原 df 上进行操作。
df.drop_duplicates(inplace=True)
(2)对 df 中包含缺失值的行进行删除处理,直接在上一步 df 上进行操作。
df.dropna(inplace=True)
A.2.1 分析评论数据时间分布特征
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
# 设置字体为黑体以显示中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # Windows 设置
# plt.rcParams['font.family'] = ['Hei', 'Times New Roman'] # MacOS 设置
# 允许显示负号
plt.rcParams['axes.unicode_minus'] = False
(1)将数据集中的 at 时间列转换成 datetime 格式。
# 确保时间列为datetime格式
df['at'] = pd.to_datetime(df['at'])
(2)从上一步转换后的 at 时间列提取年份、月份及日期,创建新的列(year、month、day)来存储这些时间特征。
# 创建额外的时间特征
df['year'] = df['at'].dt.year
df['month'] = df['at'].dt.month
df['day'] = df['at'].dt.day
(3)按月统计评论数量(review_count)。
# 按月统计评论数量趋势
monthly_review = df.groupby(['year', 'month']).size().reset_index(name='review_count')
(4)基于上一步的统计结果,使用 matplotlib 绘制折线图可视化月度评论数量,横坐标为月份,纵坐标为评论数量,标题为“ChatGPT评论数量月度趋势”。
# 创建日期列用于绘图(设置为每月的第一天)
monthly_review['date'] = pd.to_datetime(monthly_review[['year', 'month']].assign(day=1))
monthly_review_sorted = monthly_review.sort_values('date')
# 按日期排序
monthly_review_sorted = monthly_review.sort_values('date', ascending=True)
# 绘制折线图
plt.figure(figsize=(12, 6))
plt.plot(monthly_review_sorted['date'], monthly_review_sorted['review_count'], marker='o', linestyle='-', color='blue')
plt.title('ChatGPT评论数量月度趋势', fontsize=14)
plt.xlabel('月份', fontsize=12)
plt.ylabel('评论数量', fontsize=12)
plt.xticks(rotation=45)
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
A.2.2 分析 ChatGPT 评分分布状况及点赞数与评分的关系
(1)统计 df 中评分列(score)的分布,使用 seaborn 绘制饼图可视化评分占比,标题为“ChatGPT评分占比”。
# 统计评分分布
score_counts = df['score'].value_counts().sort_index()
# 绘制饼图
score_counts = df['score'].value_counts().sort_index()
plt.figure(figsize=(8, 8))
plt.pie(score_counts.values, labels=score_counts.index, autopct='%1.1f%%', startangle=140)
plt.title('ChatGPT评分占比')
plt.axis('equal')
plt.show()
(2)统计 df 中评论点赞数列(thumbsUpCount)的分布,使用 seaborn 绘制散点图可视化点赞数与评分的关系,横坐标为 score,纵坐标为 thumbsUpCount,标题为“thumbsUpCount-score 关系”。
# 统计点赞数分布
thumbsup_stats = df['thumbsUpCount'].describe()
print(thumbsup_stats)
# 绘制散点图
import matplotlib.pyplot as plt
# 配置中文字体(Windows系统)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 黑体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
plt.figure(figsize=(10, 6))
sns.scatterplot(data=df, x='score', y='thumbsUpCount', alpha=0.5, color='green')
plt.title('thumbsUpCount-score关系', fontsize=14)
plt.xlabel('评分(星级)', fontsize=12)
plt.ylabel('点赞数', fontsize=12)
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
A.3.1 根据“ChatGPT评论数量月度趋势”图分析 ChatGPT 的市场接受度和市场表现关键特征
基于月度评论趋势图的分析: 1. 评论数量增长趋势:若月度评论数持续上升,说明产品市场接受度逐步提高,用户活跃度增加;若某阶段激增,可能与产品重大更新、营销活动相关。 2. 评论数量稳定期:若后期评论数趋于稳定,说明产品用户群体进入成熟期,市场渗透率达到一定水平。 3. 低谷期分析:若某月度评论数骤降,可能与产品故障、竞品冲击等因素相关。
A.3.2 分析“thumbsUpCount-score 关系”图,提取业务洞见
基于散点图的分析: 1. 正相关趋势:若高评分(4-5星)评论的点赞数普遍高于低评分(1-2星),说明用户对优质体验的认同感强,正面反馈更易获得共鸣。 2. 异常点分析:若低评分评论出现高点赞,可能反映了用户普遍关注的产品痛点(如功能缺陷、稳定性问题),需优先排查。 3. 点赞集中区:若某评分区间(如5星)点赞数高度集中,说明该类用户需求被充分满足,可作为核心用户群体进行深度运营。
B. 智能训练(40%)
评估目标 评估学生应用机器学习和 NLP 技术处理文本数据的能力。
实操任务
- 评论文本数据预处理与特征工程
- 评论文本清洗与标准化处理
- (1)删除 df 中的 reviewId、userName、reviewCreatedVersion、at、year、month、day,原地操作。
- (2)使用 scikit-learn 中合适的方法将 df 中的“应用版本号”(appVersion)类别数据转换为数值型编码。
- (3)将 df 的 content 列中的字符串文本全部转换成小写。
- (4)去除 df 的 content 列中字符串文本包含的所有标点符号。
- (5)评论文本网络用语简写转换成完整表达。
- 去除停用词
- 分词(Tokenization)
- (1)使用 nltk 库对 df 中 content 列的输入文本进行分词(tokenize),分词结果存储到 df 的新列 token_content 中。
- (2)将 df 的 token_content 列中所有分词合并为一个大字符串,使用 wordcloud 库生成词云,max_words 参数设置为200。
- 词性标注(POS tagging)
- (1)使用 Python 包管理工具 pip 在当前 Python 环境中安装 resource 目录下的 en_core_web_sm-3.7.1-py3-none-any.whl,以便实现词性标注(POS)。安装完成后,使用 !conda list en-core-web-sm 命令输出结果。
- (2)使用 spacy 库对 df 中 content 列的输入文本进行词性标注(POS),结果存储到 df 的新列 POS_Tags 中。
- 特征提取
- (1)将 df 中 token_content 列的每一条数据统一整理为“单词列表”形式,生成一个语料库变量(命名为 corpus),注意 corpus 是一个嵌套列表。
- (2)使用 Gensim 库的 Word2Vec 类,对 corpus 进行训练,得到每个词的向量表示,并保存训练好的模型文件,文件名称命名为:chatgpt_reviews_word2vec.model。
- (3)将所有评论(corpus 中的每一条分词结果)批量转换为文档向量,生成一个二维的 numpy 数组 X_content_vectors。
- (4)将每条评论的词性标签序列转化为词袋模型的特征向量。
- (5)合并文本特征(X_content_vectors)、词性特征(X_pos_features)和数值特征(df[[‘thumbsUpCount’, ‘appVersion’]]),生成用于机器学习模型训练的输入特征矩阵 X_combined。
- 机器学习算法建模
- 划分为训练集和测试集
- (1)将 df 中的 score 列的值作为目标变量 y。
- (2)将数据集按 8:2 比例随机划分为训练集(X_train、y_train)和测试集(X_test、y_test),随机数种子值取 42。
- 随机森林算法建模与结果评估
- (1)使用 scikit-learn 中的随机森林分类器对训练集进行建模。
- (2)输出模型在测试集上的分类评估报告,包括准确率、召回率、F1分数等各项指标。
- (3)绘制并显示模型在测试集上的混淆矩阵图,直观展示分类模型的预测效果,混淆矩阵图标题为“Confusion Matrix”。
B.1.1 评论文本清洗与标准化处理
(1)删除 df 中的 reviewId、userName、reviewCreatedVersion、at、year、month、day,原地操作。
df.drop(columns=['reviewId', 'userName', 'reviewCreatedVersion', 'at', 'year', 'month', 'day'], inplace=True)
(2)使用 scikit-learn 中合适的方法将 df 中的“应用版本号”(appVersion)类别数据转换为数值型编码。
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
df['appVersion'] = le.fit_transform(df['appVersion'])
(3)将 df 的 content 列中的字符串文本全部转换成小写。
df['content'] = df['content'].str.lower()
(4)去除 df 的 content 列中字符串文本包含的所有标点符号。(提示:可使用str.translate()、正则表达式等方式实现)
import string
punctuation = string.punctuation
df['content'] = df['content'].apply(lambda x: x.translate(str.maketrans('', '', punctuation)))
(5)评论文本网络用语简写转换成完整表达。
在当前的评论文本数据中有较多的网络用语简写,诸如:thx、np、omg等,分别表示thanks、no problem、oh my god等。下面的 chat_words_mapping 字典中存储了常见网络用语简写与其完整表达的对应关系,请使用合适的方法实现 df 中 content 列的字符串文本中常见网络用语简写的完整表达替换。
chat_words_mapping = {
"lol": "laughing out loud",
"brb": "be right back",
"btw": "by the way",
"afk": "away from keyboard",
"rofl": "rolling on the floor laughing",
"ttyl": "talk to you later",
"np": "no problem",
"thx": "thanks",
"omg": "oh my god",
"idk": "I don't know",
"gg": "good game",
"g2g": "got to go",
"b4": "before",
"cu": "see you",
"yw": "you're welcome",
"wtf": "what the fuck",
"imho": "in my humble opinion",
"jk": "just kidding",
"gf": "girlfriend",
"bf": "boyfriend",
"u": "you",
"r": "are",
"2": "to",
"4": "for",
"b": "be",
"c": "see",
"y": "why",
"tho": "though",
"smh": "shaking my head",
"lolz": "laughing out loud",
"h8": "hate",
"luv": "love",
"pls": "please",
"sry": "sorry",
"tbh": "to be honest",
"omw": "on my way",
"omw2syg": "on my way to see your girlfriend",
}
def replace_chat_words(text):
for slang, formal in chat_words_mapping.items():
text = text.replace(slang, formal)
return text
df['content'] = df['content'].apply(replace_chat_words)
B.1.2 去除停用词
使用 nltk 库去除 df 中 content 列文本的英文停用词。
import nltk
from nltk.corpus import stopwords
nltk.data.path.append('resource/nltk_data/')
stop_words = set(stopwords.words('english'))
df['content'] = df['content'].apply(lambda x: ' '.join([word for word in x.split() if word not in stop_words]))
B.1.3 分词(Tokenization)
(1)使用 nltk 库对 df 中 content 列的输入文本进行分词(tokenize),分词结果存储到 df 的新列 token_content 中。
import nltk
df['token_content'] = df['content'].apply(lambda x: nltk.word_tokenize(str(x)))
(2)将 df 的 token_content 列中所有分词合并为一个大字符串,使用 wordcloud 库生成词云,max_words 参数设置为200。
from wordcloud import WordCloud
all_text = ' '.join([' '.join(tokens) for tokens in df['token_content']])
wordcloud = WordCloud(width=800, height=400, background_color='white', max_words=200).generate(all_text)
plt.figure(figsize=(10, 5))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.title('评论词云')
plt.show()
B.1.4 词性标注(POS tagging)
(1)使用 Python 包管理工具 pip 在当前 Python 环境中安装 resource 目录下的 en_core_web_sm-3.7.1-py3-none-any.whl,以便实现词性标注(POS)。安装完成后,使用 !conda list en-core-web-sm 命令输出结果。
提示:
- en_core_web_sm-3.7.1-py3-none-any.whl 文件是 spaCy 英文小型模型(en_core_web_sm) 的安装包,它的作用是为 spaCy 提供英文文本的分词、词性标注(POS)、依存句法分析、词形还原等基础自然语言处理能力。
- 安装后,可以通过 spacy.load('en_core_web_sm') 加载并用于英文文本处理。
#pip install resource/en_core_web_sm-3.7.1-py3-none-any.whl
(2)使用 spacy 库对 df 中 content 列的输入文本进行词性标注(POS),结果存储到 df 的新列 POS_Tags 中。
import spacy
nlp = spacy.load("en_core_web_sm")
def get_pos_tags(text):
doc = nlp(text)
return [(token.text, token.pos_) for token in doc]
df['POS_Tags'] = df['content'].apply(lambda x: [tag for word, tag in get_pos_tags(x)])
B.1.5 特征提取
(1)将 df 中 token_content 列的每一条数据统一整理为“单词列表”形式,生成一个语料库变量(命名为 corpus),注意 corpus 是一个嵌套列表。
corpus 结构如下:
[[‘abc’], [‘de’, ‘fghi’],[‘j’],…]
corpus = df['token_content'].tolist()
(2)使用 Gensim 库的 Word2Vec 类,对 corpus 进行训练,得到每个词的向量表示,并保存训练好的模型文件,文件名称命名为:chatgpt_reviews_word2vec.model。
要求: - 上一步的 corpus 作为用于训练词向量的语料库 - 词向量维度设置为100 - 最小词频为2 - 使用 Skip-gram 算法 - 线程数设置为1 - 打印输出模型词汇表大小和词向量维度
from gensim.models import Word2Vec
model = Word2Vec(
sentences=corpus,
vector_size=100,
min_count=2,
sg=1, # Skip-gram
workers=1
)
model.save("chatgpt_reviews_word2vec.model")
print(f"词汇表大小: {len(model.wv.key_to_index)}, 词向量维度: {model.vector_size}")
(3)将所有评论(corpus 中的每一条分词结果)批量转换为文档向量,生成一个二维的 numpy 数组 X_content_vectors。
要求: - 过滤掉每条评论中不在模型词汇表中的词 - 如果没有匹配的词,返回零向量 - 返回所有词向量的平均值
import numpy as np
def get_doc_vector(tokens, model):
word_vectors = [model.wv[word] for word in tokens if word in model.wv]
if not word_vectors:
return np.zeros(model.vector_size)
return np.mean(word_vectors, axis=0)
X_content_vectors = np.array([get_doc_vector(tokens, model) for tokens in corpus])
(4)将每条评论的词性标签序列转化为词袋模型的特征向量。
要求: - 遍历每条评论的词性标注结果(df[‘POS_Tags’]),将每条评论的所有词性标签(如NOUN、VERB、ADJ等)提取出来,拼接成一个以空格分隔的字符串,组成 pos_sequences 列表。 - 使用 scikit-learn 中的 CountVectorizer 对这些词性标签序列进行特征提取。运用 CountVectorizer 统计每条评论中所有 1-3 元(ngram_range=(1, 3))的词性标签组合出现的次数,并将其转化为一个定长的数值特征向量(最多50维,max_features=50)。 - 返回一个二维 numpy 数组,命名为 X_pos_features,其中每一行对应一条评论的词性标签计数特征。
from sklearn.feature_extraction.text import CountVectorizer
pos_sequences = [' '.join(tags) for tags in df['POS_Tags']]
vectorizer = CountVectorizer(ngram_range=(1, 3), max_features=50)
X_pos_features = vectorizer.fit_transform(pos_sequences).toarray()
(5)合并文本特征(X_content_vectors)、词性特征(X_pos_features)和数值特征(df[[‘thumbsUpCount’, ‘appVersion’]]),生成用于机器学习模型训练的输入特征矩阵 X_combined。
# 合并Word2Vec向量与其他特征
numerical_features = df[['thumbsUpCount', 'appVersion']].values
X_combined = np.hstack([X_content_vectors, X_pos_features, numerical_features])
B.2.1 划分训练集和测试集
(1)将 df 中的 score 列的值作为目标变量 y。
from sklearn.model_selection import train_test_split
y = df['score'].values
(2)将数据集按 8:2 比例随机划分为训练集(X_train、y_train)和测试集(X_test、y_test),随机数种子值取 42。
X_train, X_test, y_train, y_test = train_test_split(
X_combined, y, test_size=0.2, random_state=42
)
B.2.2 随机森林算法建模与结果评估
(1)使用 scikit-learn 中的随机森林分类器对训练集进行建模。
要求: - 定义随机森林中决策树的数量为100。 - 设置随机数种子为42,确保实验可重复性。 - 设置随机森林在训练和预测时使用的 CPU 核心数量为1,其他参数保持默认值。
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix
import seaborn as sns
rf_model = RandomForestClassifier(n_estimators=100, random_state=42, n_jobs=1)
rf_model.fit(X_train, y_train)
(2)输出模型在测试集上的分类评估报告,包括准确率、召回率、F1分数等各项指标。
y_pred = rf_model.predict(X_test)
print("分类评估报告:")
print(classification_report(y_test, y_pred))
(3)绘制并显示模型在测试集上的混淆矩阵图,直观展示分类模型的预测效果,混淆矩阵图标题为“Confusion Matrix”。
cm = confusion_matrix(y_test, y_pred)
plt.figure(figsize=(8, 6))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues', xticklabels=np.unique(y), yticklabels=np.unique(y))
plt.title('Confusion Matrix')
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.show()
C. 智能系统设计(25%)
评估目标
评估学生设计端到端AI应用系统的能力。
实操任务
- 系统架构设计
- 基于业务分析与智能训练部分的所有任务,设计一套基于 streamlit 框架的端到端应用系统,包括数据加载与概览、数据清洗、评论趋势分析可视化、评分与点赞分析可视化、文本清洗与特征工程、模型训练与评估等核心功能。绘制系统分层架构图,阐明每层的作用及包含的功能模块。
- 基于 streamlit 框架的系统实现(20分)
- 数据加载与概览
- 支持手动上传 CSV 和 Excel 格式的数据文件。
- 能够在 Web 界面展示数据概览,包括数据集形状、数据前10行、数据集的基本信息(info()函数结果)、缺失值和重复值统计结果等。
- 数据清洗
- 支持用户执行数据清洗的操作,包括删除重复行、删除缺失值等。
- 能够在 Web 界面展示清洗后的数据概览或数据行数变化。
- 评论趋势分析、评分与点赞分析可视化
- 支持用户执行时间特征处理操作,能够在 Web 界面展示月度评论数据统计表及评论数量的趋势图,支持图片下载功能。
- 能够在 Web 界面展示评分与点赞数的关系图,支持图片下载功能。
- 文本清洗与特征工程
- 支持用户执行文本清洗操作,包括删除标点符号、转换大小写、去除停用词等。
- 支持文本特征提取操作的 Word2Vec 算法建模,支持模型训练的参数设置,包括词向量维度、最小词频、上下文窗口大小、训练算法。
- 能够在 Web 界面展示词云图,支持图片下载功能。
- 模型训练与评估
- 支持用户选择模型训练的参数设置,包括随机森林的树数量、测试集比例、随机数种子等。
- 能够在 Web 界面展示模型训练的结果,包括分类评估报告和混淆矩阵图,并支持图片下载功能。
C.1 系统架构设计
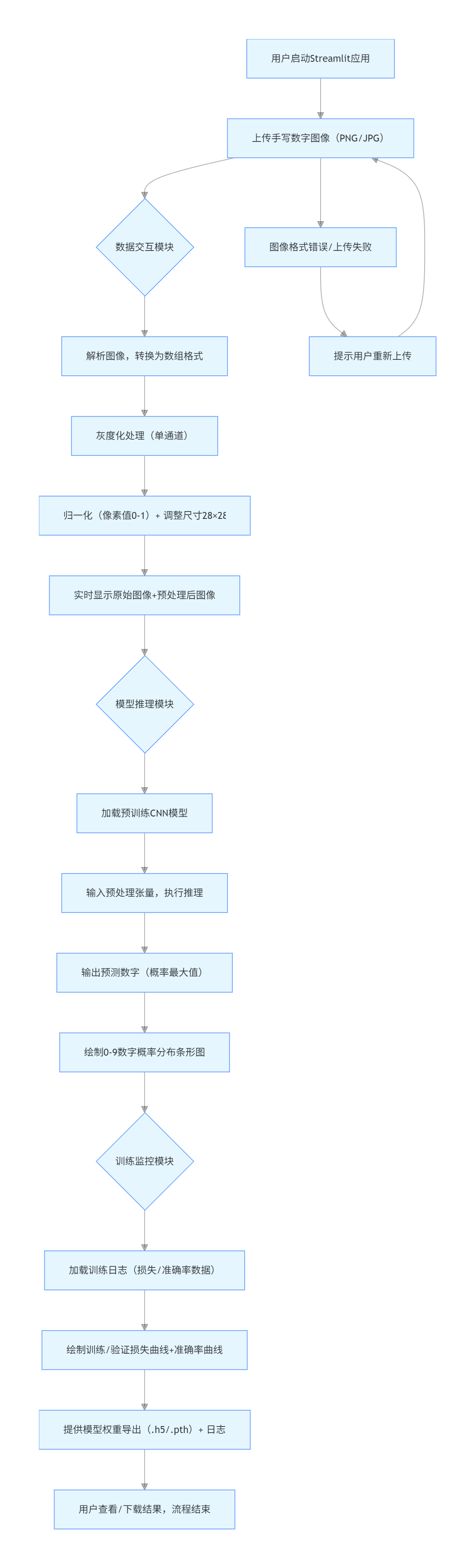
C.2 基于 streamlit 框架的系统实现
系统实现完整代码可写入到新文件 streamlit_app.py 中。
import streamlit as st
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from io import BytesIO
import numpy as np
import string
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from wordcloud import WordCloud
import spacy
from gensim.models import Word2Vec
from sklearn.feature_extraction.text import CountVectorizer
import time
import warnings
warnings.filterwarnings("ignore")
# ===================== 关键优化:解决Matplotlib中文显示问题 =====================
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei', 'DejaVu Sans'] # 支持中文的字体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示为方块的问题
plt.rcParams['font.family'] = 'sans-serif'
# 页面配置
st.set_page_config(page_title="ChatGPT评论分析系统", layout="wide")
st.title("ChatGPT产品评论数据集可视化分析系统")
# 初始化 session state
if 'df_cleaned' not in st.session_state:
st.session_state.df_cleaned = None
if 'model_trained' not in st.session_state:
st.session_state.model_trained = False
if 'X_combined' not in st.session_state:
st.session_state.X_combined = None
if 'y' not in st.session_state:
st.session_state.y = None
# C.2.1 数据加载与概览
uploaded_file = st.file_uploader("上传CSV或Excel文件", type=['csv', 'xlsx'])
if uploaded_file is not None:
try:
if uploaded_file.name.endswith('.csv'):
df = pd.read_csv(uploaded_file)
else:
df = pd.read_excel(uploaded_file)
st.subheader("原始数据概览")
st.write(f"数据集形状: {df.shape}")
st.write("前10行数据:")
st.dataframe(df.head(10))
st.write("基本信息:")
buffer = pd.io.common.StringIO()
df.info(buf=buffer)
st.text(buffer.getvalue())
st.write("缺失值统计:")
st.write(df.isnull().sum())
st.write("重复值数量:", df.duplicated().sum())
# === 数据清洗按钮 ===
if st.button("执行数据清洗"):
with st.spinner("正在清洗数据..."):
# 删除重复行和缺失值
df_clean = df.drop_duplicates().dropna()
# 确保必要列存在
required_cols = ['content', 'score', 'thumbsUpCount']
missing_cols = [col for col in required_cols if col not in df_clean.columns]
if missing_cols:
st.error(f"数据缺少必要字段: {missing_cols}")
else:
st.session_state.df_cleaned = df_clean
st.success("✅ 数据清洗完成!")
# 如果已清洗,显示清洗后信息
if st.session_state.df_cleaned is not None:
df = st.session_state.df_cleaned
st.subheader("清洗后数据")
st.write(f"新数据形状: {df.shape}")
# === 可视化分析(一键生成三张图) ===
st.subheader("📊 可视化分析")
# 合并生成按钮:一键生成所有可用图表
if st.button("一键生成所有可视化图表"):
col1, col2, col3 = st.columns(3) # 三列布局展示图表
figs = [] # 存储生成的图表,用于下载
# 1. 时间趋势图(需有 'at' 列)
with col1:
st.subheader("评论时间趋势")
try:
if 'at' in df.columns:
df['at'] = pd.to_datetime(df['at'], errors='coerce')
df_temp = df.dropna(subset=['at'])
df_temp['year_month'] = df_temp['at'].dt.to_period('M')
monthly = df_temp.groupby('year_month').size()
fig1, ax1 = plt.subplots(figsize=(10, 6))
monthly.plot(kind='line', marker='o', ax=ax1, color='#1f77b4')
ax1.set_title('ChatGPT评论数量月度趋势', fontsize=12)
ax1.set_xlabel('月份', fontsize=10)
ax1.set_ylabel('评论数量', fontsize=10)
plt.xticks(rotation=45)
plt.tight_layout()
st.pyplot(fig1)
figs.append(('trend.png', fig1))
else:
st.warning("⚠️ 无 'at' 列,无法生成时间趋势图")
except Exception as e:
st.error(f"时间趋势图生成失败: {e}")
# 2. 评分分布饼图
with col2:
st.subheader("评分分布")
try:
if 'score' in df.columns:
score_counts = df['score'].value_counts().sort_index()
fig2, ax2 = plt.subplots(figsize=(10, 6))
colors = ['#ff9999','#66b3ff','#99ff99','#ffcc99','#c2c2f0']
ax2.pie(score_counts.values, labels=score_counts.index, autopct='%1.1f%%',
startangle=140, colors=colors[:len(score_counts)])
ax2.set_title('ChatGPT评分占比', fontsize=12)
plt.tight_layout()
st.pyplot(fig2)
figs.append(('score_pie.png', fig2))
else:
st.warning("⚠️ 无 'score' 列,无法生成评分饼图")
except Exception as e:
st.error(f"评分饼图生成失败: {e}")
# 3. 点赞数 vs 评分散点图
with col3:
st.subheader("点赞-评分关系")
try:
if 'score' in df.columns and 'thumbsUpCount' in df.columns:
fig3, ax3 = plt.subplots(figsize=(10, 6))
sns.scatterplot(data=df, x='score', y='thumbsUpCount',
alpha=0.6, ax=ax3, color='#2ca02c')
ax3.set_title('点赞数与评分关系', fontsize=12)
ax3.set_xlabel('评分', fontsize=10)
ax3.set_ylabel('点赞数', fontsize=10)
plt.tight_layout()
st.pyplot(fig3)
figs.append(('scatter.png', fig3))
else:
st.warning("⚠️ 缺少评分/点赞列,无法生成关系图")
except Exception as e:
st.error(f"点赞-评分图生成失败: {e}")
# 为每个图表添加下载按钮
st.subheader("📥 图表下载")
download_cols = st.columns(len(figs))
for idx, (filename, fig) in enumerate(figs):
with download_cols[idx]:
buf = BytesIO()
fig.savefig(buf, format="png", bbox_inches='tight', dpi=150)
st.download_button(
label=f"下载{filename.split('.')[0]}图",
data=buf.getvalue(),
file_name=filename,
mime="image/png"
)
# === 文本预处理与建模 ===
st.subheader("🤖 机器学习建模")
n_estimators = st.slider("随机森林树数量 (n_estimators)", 10, 200, 100)
test_size = st.slider("测试集比例", 0.1, 0.5, 0.2)
if st.button("开始训练模型"):
with st.spinner("正在预处理文本并训练模型..."):
try:
# 1. 文本清洗
df_model = df.copy()
df_model['content'] = df_model['content'].astype(str).str.lower()
df_model['content'] = df_model['content'].str.translate(str.maketrans('', '', string.punctuation))
# 停用词(确保 nltk 数据已下载)
try:
stop_words = set(stopwords.words('english'))
except:
nltk.download('stopwords')
nltk.download('punkt')
stop_words = set(stopwords.words('english'))
df_model['content'] = df_model['content'].apply(
lambda x: ' '.join([w for w in x.split() if w not in stop_words])
)
# 分词
df_model['tokens'] = df_model['content'].apply(word_tokenize)
# Word2Vec
model_w2v = Word2Vec(sentences=df_model['tokens'], vector_size=100, min_count=2, sg=1, workers=1)
def get_vec(tokens):
vecs = [model_w2v.wv[w] for w in tokens if w in model_w2v.wv]
return np.mean(vecs, axis=0) if vecs else np.zeros(100)
X_w2v = np.array([get_vec(t) for t in df_model['tokens']])
# 数值特征
X_num = df_model[['thumbsUpCount']].values
# 合并特征
X_combined = np.hstack([X_w2v, X_num])
y = df_model['score'].values
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(
X_combined, y, test_size=test_size, random_state=42
)
# 训练模型
rf = RandomForestClassifier(n_estimators=n_estimators, random_state=42)
rf.fit(X_train, y_train)
y_pred = rf.predict(X_test)
# 保存结果到 session state
st.session_state.model_trained = True
st.session_state.class_report = classification_report(y_test, y_pred, output_dict=True)
st.session_state.cm = confusion_matrix(y_test, y_pred)
st.session_state.labels = np.unique(np.concatenate([y_test, y_pred]))
st.success("✅ 模型训练完成!")
except Exception as e:
st.error(f"建模失败: {e}")
# 显示评估结果
if st.session_state.model_trained:
st.subheader("模型评估结果")
# 分类报告(表格形式)
report_df = pd.DataFrame(st.session_state.class_report).transpose()
st.dataframe(report_df)
# 混淆矩阵
fig, ax = plt.subplots(figsize=(8, 6))
sns.heatmap(st.session_state.cm, annot=True, fmt='d', cmap='Blues',
xticklabels=st.session_state.labels,
yticklabels=st.session_state.labels, ax=ax)
ax.set_title('混淆矩阵', fontsize=14)
ax.set_xlabel('预测值', fontsize=12)
ax.set_ylabel('真实值', fontsize=12)
st.pyplot(fig)
buf = BytesIO()
fig.savefig(buf, format="png", bbox_inches='tight', dpi=150)
st.download_button("📥 下载混淆矩阵", buf.getvalue(), "confusion_matrix.png", "image/png")
except Exception as e:
st.error(f"文件读取失败: {e}")
else:
st.info("请上传一个 CSV 或 Excel 文件以开始分析。")D. 培训与指导模块(5%)
评估目标
评估学生进行知识传递与用户培训的能力。
实操任务
- 以 markdown 格式编写系统用户手册,介绍系统的功能、使用方法和注意事项。
D.1 以 markdown 格式编写系统用户手册,介绍系统的功能、使用方法和注意事项
新建文件“系统用户手册.md”,编写内容。
ChatGPT评论分析系统用户手册
1. 功能简介
本系统是一个端到端的AI数据分析平台,支持对ChatGPT用户评论数据进行: - 数据加载与质量检查 - 自动化数据清洗 - 时间趋势与评分可视化 - 文本预处理与词云生成 - 机器学习模型训练与评估
2. 使用方法
- 数据上传:在首页点击“上传”按钮,选择您的CSV或Excel格式评论数据文件。
- 数据概览:系统会自动展示数据的基本信息、缺失值和重复值情况。
- 数据清洗:点击“执行清洗”按钮,系统将自动删除重复行和缺失值。
- 可视化分析:导航至“分析”页面,可查看评论趋势图、评分饼图和点赞关系图,并支持下载图片。
- 模型训练:在“模型”页面,设置参数后点击“开始训练”,系统将展示评估报告和混淆矩阵。
3. 注意事项
- 请确保上传的数据包含题目中指定的必要字段(如content, score等)。
- 首次运行文本分析功能时,系统可能需要联网下载NLTK和spaCy依赖,请确保网络畅通。
- 模型训练过程可能需要较长时间,取决于数据集大小。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 16
16 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)