2025年LLM模型综述(25/11/23)
文章出处:
原文:
A Survey of Large Language Models
github: https://github.com/LLMBook-zh/LLMBook-zh.github.io
文章内容中引用图片为论文中所有
背景历史:
模型来源:
阶段:
统计模型阶段:(目标: 解决受限范围内问题: 检索、speech task)
- 假设: Markov assumption: 后一个词依赖离他比较近的前一个词
- n-gram(IR, nlp, ):
- - 问题: 高维灾难
- - 处理手段: back-off estimation, Good-Turing estimation,
NLM阶段: (解决特征提取问题, 减轻人工):MLP(多层 multi-layer perceptron), RNN ,word vectors(word2vec)
PLM阶段 (Pre-trained language models, 根据下游任务学习特征): BERT: pre-training + fine_tuning 的范式(fine_tune各种下游任务),GPT2,BART
LLM阶段:(目标: 通用任务解决者。 副作用: emergent abilities涌现, 模型参数量增大后, 模型突然顿悟了)
- GPT3: 可以解决few-shot tasks。 在当前上下文中学习
- ChatGPT
- PaLM
- GPT4: 复杂问题
一篇遇见未来的论文:
Planning for AGI and beyond
第二节: 背景和GPT系列分析
scaling laws (没明白的部分)
类型 & 公式: KM scaling law & Chinchilla scaling law
按使用: predictable scaling & task-level predicability
涌现:
- 从上下文中学习? in-context learning(ICL): GPT3开始
- 指令遵从 instruction following:
- 逐步推理 step-by-step reasoning
关键技术:
- 大力出奇迹 scaling
- 训练
- 并行算法(DeepSpeed, Megatron-LM )
- 优化技巧(重启来解决loss突增问题, 混合精度训练)
- 能力激发(ability eliciting)(设计合适的任务指令、特殊上下文学习策略, 如cot)
- 对齐调优alignment tuning (使模型契合人类需求(有用、诚实、无害), 策略SFT、RLHF)
- SFT: Supervised fine tune
- RLHF: Reinforcement Learning with human feedback
- 工具操作
- 更新硬件
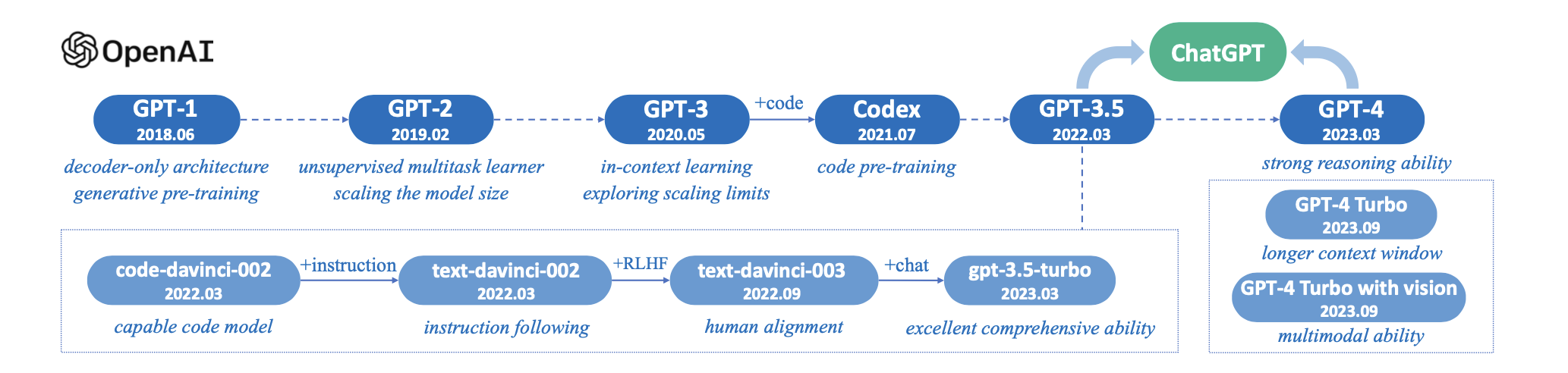
GPT的迭代
gpt1: 生成式、 decorder-only transformer、 无监督预训练 + 有监督微调
gpt2: 去掉微调, 给定input + task, 预测output。 理念转换为:结果获取转为推测下一个词是什么。
问题: 同等数量级, 还不如bert效果好。
gpt3: 大力出奇迹: (ICL)
- codex(GPT3 + 编码数据集) : 推理能力、数学能力大幅提升
- 人工对齐(human alignment )重点文章:PPO(Proximal Policy Optimization 2017 TODO)
InstructGPT3(2022年1月): 正式建立3阶段RLHF算法(对不输出有害内容很有效)
思考: 当技术演进到开始考虑安全问题时, 离大规模应用就不远了?
chatgpt(2022 11月)
- 类似instructGPT3的训练方式
- 更大知识储量、更好推理数学问题能力、多轮对话、人类价值观、可使用工具和app
gpt4(2023 3月)
- RLHF训练
- 干预策略(幻觉、隐私、过度依赖问题。 具体方法: 红队(red teaming), 云扩展计费)
gpt-4v, gpt4 turbo: 更便宜, 支持function call,可复现的输出
gpt4 turbo with vision, DALL·E 多模态:
TTS
gpt5
第三节 LLM来源
模型:
Mistral: 上下文128k, 支持fp8推理, 稀疏MOE(Sparse Moe)
Gemma: 轻量
Qwen:
知识保留(kg retention), 编程 & 数学推理能力提升
Qwen2.5: 指令遵从提升、长输出(8k token)、结构数据理解&生成(json)
GLM : 中文 英文
Baichuan
开源、双语(中文、英文)
特殊领域优秀: 法律、医疗
LLaMA 家族
- instruction tuning & pretraining 生成的变种: Alpaca,Alpaca-Lora, Vicuna
- 多模态系列: LLaVA 、MiniGPT-4、InstructBLIP 、PandaGPT
GPT3系列: ada、babbage、curie、davinci
数据集
预训练数据
网页: CommonCrawl、C4、RedPajama-Data、RefineWeb、WebText
书和学术资料: Book Data、Academic Data
维基百科
Code : github、stackOverflow
混合
fine-tune数据
指令微调数据集:
NLP任务数据: P3、FLAN
聊天: ShareGPT、OpenAssistant、Dolly
合成数据: Self-Instruct-52k、Alpaca、Baize
对齐数据集: HH-RLHF、SHP、PKU-SafeRLHF、Stack Exchange Preferences(Stack Overflow数据集)、Sandbox Alignment Data
使用框架:
Transformers
- DeepSpeed: 有优化library、兼容P有Torch、优化工具 + 分布式训练(memory 优化技术:ZeRO、 gradient checkpoint), pipeline parallelism
- Megatron-LM: model + data parallelism,混合精度训练、 FlashAttention
- JAX: 有已经加速, auto differentiation & just-in-time compilation
- Colossal-AI: 并行训练、memory mgt
- BMTrain: code simplicity, low resource, high availability
- FastMOE: 数据并行、模型并行
- vLLM: 推理快、高吞吐量(Page Attention),continuous batching, Streaming output
- DeepSpeed-MII: blocked KV cache. continuous batching, dynamic SplitFuse, High Performance CUDA kernel
- DeepSpeed-Chat: 复制InstructGPT训练模式、三流程: SFT + reward model fine tune + RLHF、训推一体
第四节 预训练
数据处理
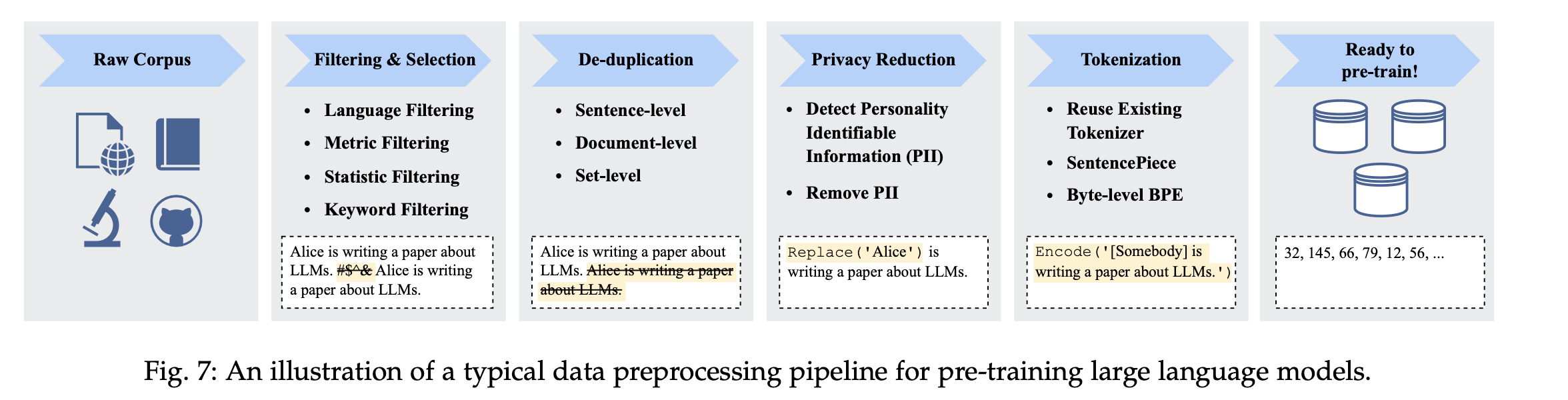
数据来源
数据预处理:
1.筛选: LLm筛选、度量筛选(perplexity)、 统计、关键词筛选
2.去重:
- 去掉私有信息(private信息)
- tokenization:
- BPE (byte pair encoding): 先初始化一个词表, 拆成字符, 每轮逐渐合并(根据频率统计), 循环往复直到合并到指定词表个数. (优点:未处理词会拆分, 平衡效率和覆盖、多语言)(Huggingface的tokenizers, Google的SentencePiece)
- wordpeice(跟BPE差不多, 但是合并的时候先训练一个LM, 给可能pair打分。 每轮选能增加更多与traindata likelihood的pair merge)
- uni-gram(todo): Unigram 方法通过预先训练一个子词概率模型(EM方法),选择使整体句子概率最大化的分词方案。
- 候选生成:从语料中提取高频子词(如字符、常见字符串)作为初始候选集。
- 概率估计:通过统计或语言模型计算每个子词的概率,移除低概率子词迭代优化。
- 分词解码:使用维特比算法(Viterbi)动态规划找到最优分词路径。
- LLM一般会训练一个自己的Library(BPE和unigram的组合)
3. 数据规划:
数据混合: 上采样和下采样(todo), 增加数据源的多样性、优化数据混合、目标导向的用例
数据课程:
- 先学basic knowledge -> 再 target knowledge
- 先学简单、泛化的 -> 有挑战的、特殊的
- 防止模型崩塌, 保持5%的通用用例
(todo)这里有几个预训练的分配例子, 需要多学习下
- 长上下文:(RoPE 、ALiBi、xPos、 even NoPE)
典型架构:
Encoder-decoder
Causal Decoder: 注意力机制:采用严格单向掩码,每个 token 仅能关注自身及左侧 token,即下三角矩阵掩码。
GPT系列
Prefix Decoder: 前缀解码器架构,对输入前缀部分采用双向注意力,输出部分采用单向注意力,旨在平衡输入理解与生成能力。编码与解码使用同一组参数,但由于需动态调整掩码机制,训练收敛速度慢。
感觉是种transformer的改进结构, 想要input的双向信息?
GLM系列
MoE
Emergent (Mamba、RWKV、RetNet、Hyena):
parameterized state space models(SSM )基于RNN、CNN的混合?可以生成类RNN的输出。可用卷积做表示(对有效利用GPU有帮助: 可以使用Parallel Scann, FFT, Chunkwise Recurrent(不懂的一些技术todo))
一般技术
归一化方法: LayerNorm、RMSNorm、DeepNorm
归一化位置(Normalization Position): Post-LN、Pre-LN、Sandwich-LN(todo)
激活函数: GeLU、GLU激活(SwiGLU、 GeGLU, 需要FFN多50%的参数)
Position Embedding(绝对位置编码、相对位置编码(开始可训练)、 RoPE(注意QK先与RoPE相乘, 再算attention, 且V不用乘)、ALiBi(里面有个惩罚函数是预定义的, 应用于BLOOM模型))
Attention:
- Full Attention(MHA)
- Sparse Attention (稀疏Attention)
- MQA、GQA
- Flash Attention(跟硬件有关)(qkv 一个kernel完成啦, nvidia的优化了, 之类)
- Paged Attention(硬件有关, KV cache的分块、分页, vllm里的)
预训练任务:
- Language Model: 预测下一词, 算相似度
- Denoising Autoencoding : 数据去噪(pretrain模型用的少)
- Mixture of Denoisers(MoD, 或者叫UL2 loss):
解码任务:
- 贪婪: beam search, 长度惩罚(length penalty)
- 随机采样: temperature采样(随机性强弱)、top-k采样(按个数截断)、 top-p采样(概率为p以上的采样), η采样(动态threshold)、contrustive search 、 typical sampling
模型训练
优化参数:
batch
learning_rate :
优化器: Adam、AdamW、Adafactor
训练中: 最好是逐步且平滑的, 策略有:
- weight decay
- gradient cliping
- 梯度突增问题:
- 从稍早一点的checkpoint重开始
- 跳过会激增的数据
- 分析原因: 有可能是embedding layer 的特异gradient? 那么 shrink embeding 层的梯度来减轻这个问题
分布式训练(3D并行):
- 数据并行: 复制多个model到不同的卡上, 数据分布式, 最后合并, torch完成
- 流水线并行: 模型layer分开到多个卡上。 会导致GPU利用率变低。 GPipe、 PipeDream
- Tensor并行: 分布式tensor, 比如attention. Megatron-LM、 Colossal-AI
混合精度训练: Fp32 -> FP 16 -> BF16(Brain Floating point 指数位更多, 有效数位更少, 更注意缩放比例)
整体训练策略:
- 3D并行组合、(DeepSpeed, Colossal-AI, Alpa都支持)
- 减少内存冗余:ZeRO、FSDP, activation recomputation技术
- 混合精度训练
- predicable scaling?
N.B.
传统数据并行(Data Parallel)中,每个设备会存储完整的模型参数、梯度和优化器状态(三者合称 “训练三要素”),仅数据分片到不同设备计算 —— 当模型参数超过单设备内存(如千亿参数模型)时,传统并行会直接 “内存溢出”。
ZeRO(有1, 2, 3) 和 FSDP 的核心解法是:将 “训练三要素”分片存储到多个设备(而非单设备存完整副本),仅在计算时临时聚合所需分片,从根本上降低单设备内存压力。
第5章 微调/适应下游任务(adaption training/instruction training)(这章太混乱了)
指令微调(SFT)
格式化(todo):(task-specific(nlp任务数据)、 daily chat(日常对话数据)、 synthetic instruction合成数据 )
影响因素: 量、格式(增加任务描述、例子、CoT例子)、质量、选择(与下游)
调优策略:
平衡数据分布、结合pretrain、 多阶段慢慢调优
其他策略:
多轮对话策略: 不要切分多轮对话内容、整个喂进去
个人信息: 使用指代策略, 用全大写描述词汇指代某个个人信息
拼接
调优影响: 效果提升、任务泛化?领域细化?
经验: 逐步增加instruction复杂度、逐步增加topic类型、增加instruction数量、平衡instruction难度
实验:(todo, 这里有个具体实验, 需要仔细了解他的策略)
结果说明:
- 任务格式化良好的对QA有用、对chat没什么用
- 混合各种instruction有助于提高模型的理解能力
- 增加instruction的复杂度和多样性能提高模型表现
- 只增加instruction条数用处不大, 问题在于平衡instruction的难度
- 大力出奇迹
对齐(与人类价值观对齐, 目标:有帮助、诚实、无害的结果。 Alignment tuning/alignment tax。 会导致模型能力下降)
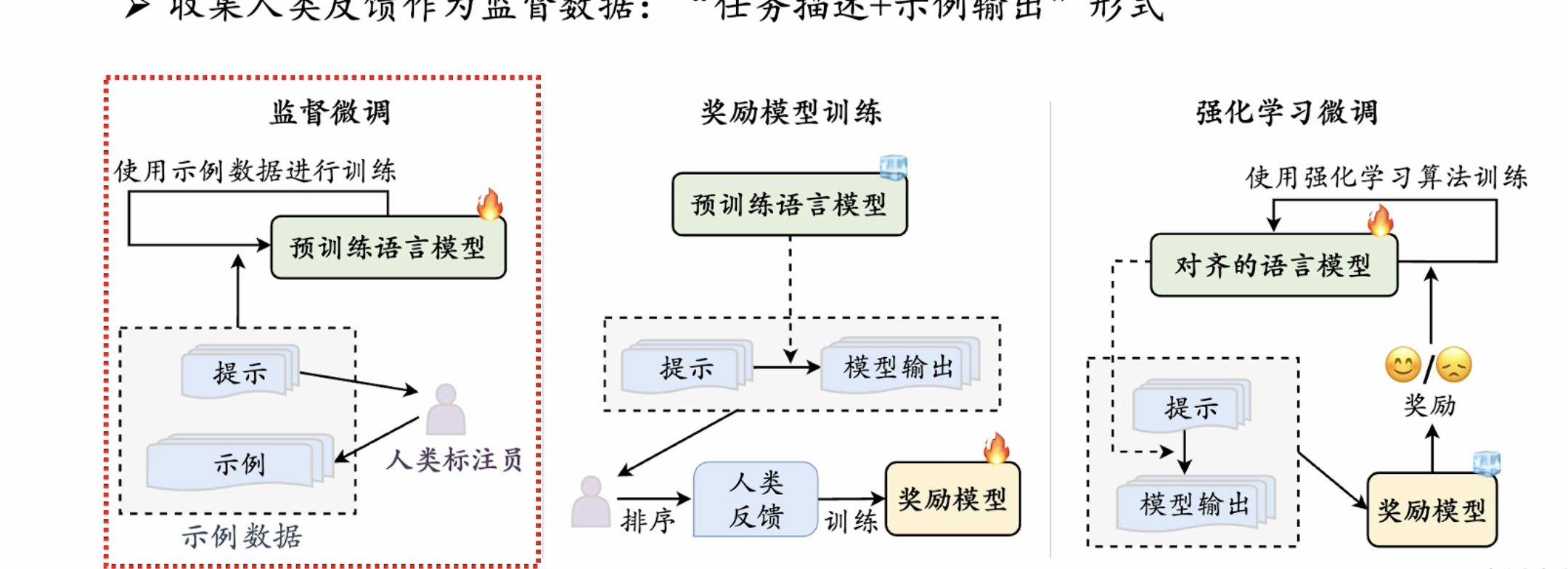
RLHF
组成: 带对齐模型(有初步预训练)、奖励模型(使用人类偏好数据微调的模型, 或从头开始训练的模型)、强化学习算法(PPO (instructGPT使用))
流程:
1. SFT监督微调
收集人类反馈: 任务描述 + 示例输出 -> 给pretrainLM 进行 SFT
标准: 有帮助、诚实、无害
数据准备:
- 标注者: labeler、researcher、 super raters
- 标注形式: 直接评分、成对比较、全排序
- 常用标注平台: ScaleAI(InstructGPT), SurgeAI(WebGPT)、Upwork(InstructGPT)、Amazon mechanical turk(Red-teaming)
- 格式: 排序性、回答问题型、规则型(比如上述目标是否满足)
- 工具: llm作为rule-based reward model
2. 奖励模型训练:
pretrainLM 根据提示生成模型输出-> 人类标注员反馈-> 训练奖励模型
训练方式:
- 打分式: 奖励模型学习单个恢复的得分
- 对比是: 奖励模型学习两个不同回复的偏好关系: 正例、负例
- 排序式: 奖励模型学习多个不同回复的偏好关系
3. 强化学习训练: 对齐pretrain语言模型用强化学习方式训练 -> 根据提示输出 -> 奖励模型打分, 反馈至pretrain强化学习方式训练
- 将对齐看做强化学习问题: PPO算法,
- 增加惩罚项防止模型偏离太远
强化学习:
原理:
目标: G奖励(f策略模型(决策轨迹))-> 最大化这个
问题: 所有的决策轨迹无法遍历, 所以改为采样轨迹。 化简公式如下:
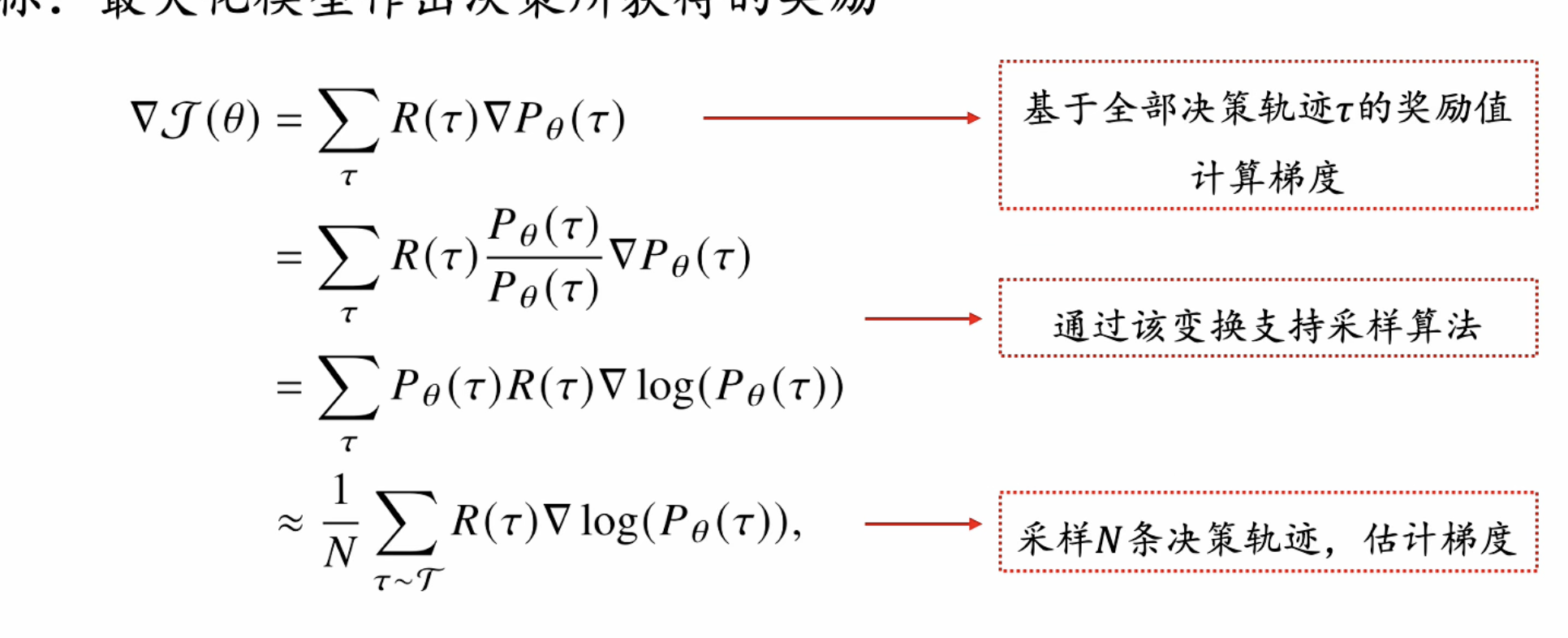
上述变换的问题:
- 训练不稳定: 差策略导致差采样, 导致策略更差, 恶性循环
- 采样效率不高(需要经常和环境互动)
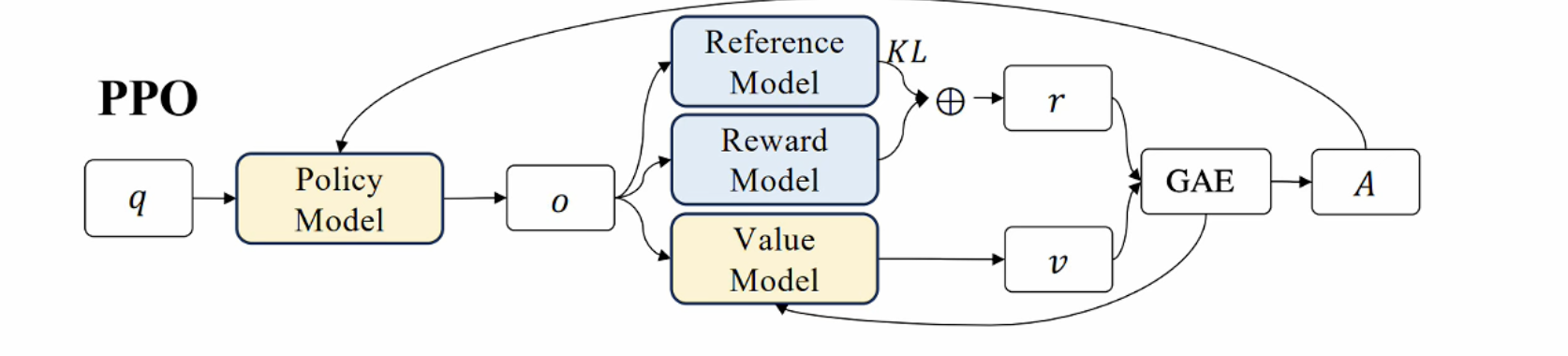
PPO算法(近端策略优化)
整体框架:
- 策略模型:生成决策
- 奖励模型: 打分
- 价值模型: 计算当前决策的价值, 用于修正
- 参考模型: 帮助约束模型, 防止过度更新(策略模型的复制)
改进:
- 优势估计:(尝试理解?: 三个奖励函数, 顺序打分, a1虽然比较差, 但是模型还是会增加这个分数, 导致a2, a3两个比较好的path被打压。 所以解决方式是, 采用一个价值模型先预估和横向比较这些path的打分)
- 优势函数: 代替奖励函数,
- 价值模型(Value Model)
- 重要性采样: (利用off-policy 估计on-policy 交互时的奖励期望): 不用实时环境 -> 可以并行?(通俗点说: 在离线数据上采样 * 在线采样中的分布 -> 得到正确的在线数据采样 )
- 训练稳定性策略:
- 梯度裁剪(clip函数, 概率过大/或者过小的时候裁剪)、KL散度作为惩罚项
- 强化学习前, 先instruction tune, 增强基础能力
- 拒绝性采样(奖励模型从N个输出中选最优的加入SFT或者DPO训练数据
DPO:
建立策略函数和奖励函数之间关系, 不要奖励模型。 直接构建: input, 正例、负例关系
(反向思考: 为什么需要这些中建模型,为什么不直接构建数据? 信息容量无法从数据直接过度到另一个模型, 需要中间模型传递?)
过程监督:(Process-supervised reward models(PRM))
针对模型输出的每个组成部分, 提供步骤级别的奖励信号
问题: 很难对过程里每一步给奖励估计。
方案: 向后采样(当前步骤往后推几步, Hard Estimation: 推出结果, 那么奖励为1, Soft Estimation: 推出结果, 得到正确结果的比例)
缺陷: 无法平衡正例和负例、过度依赖参考模型 & 参考模型太差效果差
弥补方法: 学习策略修改 or 提升策略模型
GRPO:
DPO 扩展, DPO是pair-wise的, GRPO将排序/列表偏好/偏好缺失, 通过引入相对偏好权重,将不同类型偏好统一转换为pair-wise?
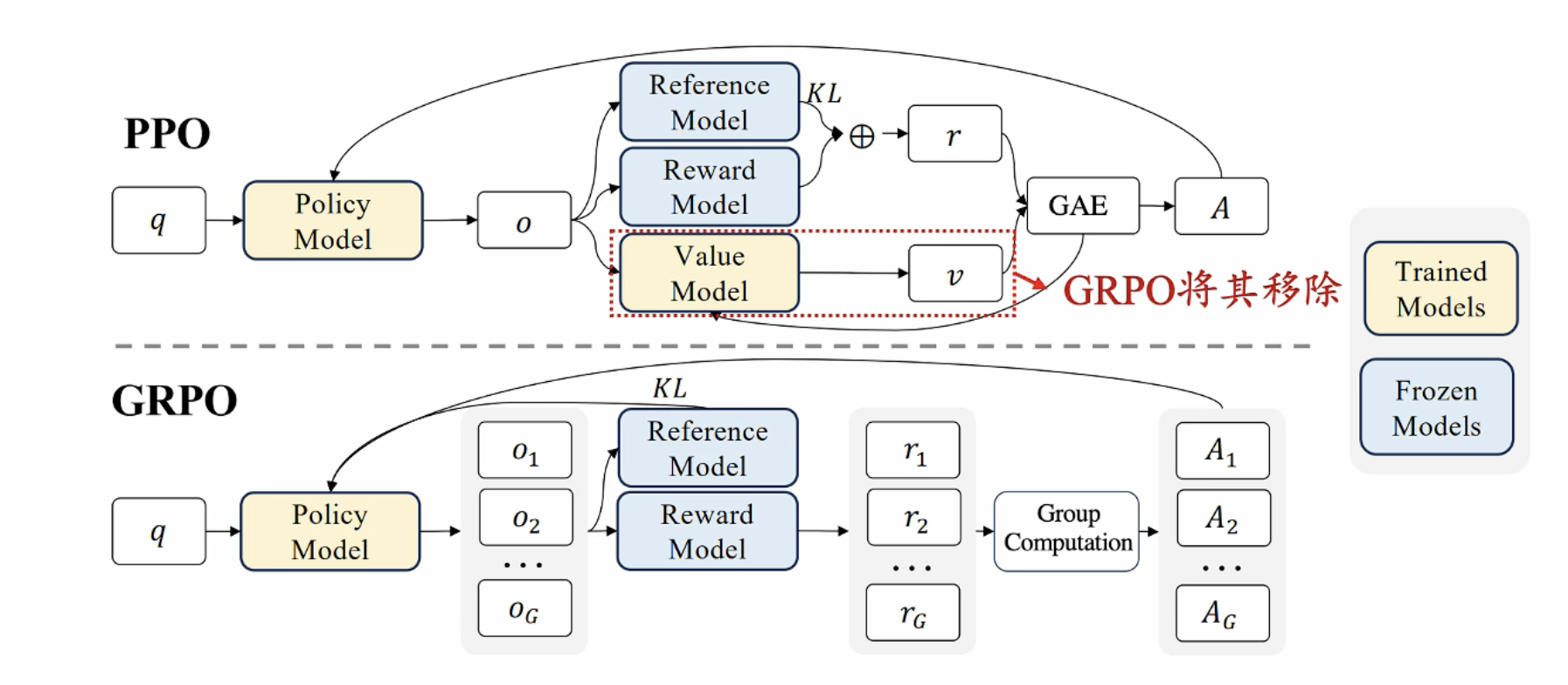
特点:
移除Value 模型 -> 同一个数据输出多个结果, 归一化后计算优势估计(思考: 改变与绝对好学生比,而是用平均值(客观)相互比较)
KL惩罚项-> 无偏估计 : 函数恒为正值, 稳定
RLHF 代表工作:
llama-2
奖励模型: Lranking = 正例 > 负例 并多+一个偏好分数: 减少变化幅度
过程: 前4轮SFT+ 拒绝采样 -> SFT -> PPO 训练(两个奖励函数: safety, helpfulness)
奖励函数的组合方式:if/else判断, 加总, 加权
deepseek里:
循环方式: 一个iteration内:
- 每个step内、每个GRPO内, 更新一次策略模型
- 一个iteration结束后, 所有step后更新奖励模型
强化学习通病: 需要维护多个模型、算法复杂、训练稳定性差(对超参敏感)
使用经验:
RM奖励模型: 每个标准建一个奖励模型, 最后合并奖励模型的结果(加权, 加总, )
对于超参敏感、稳定性差: 先SFT, 再RL
SFT vs RLHF
SFT :
- 优点: 泛化能力, 专业能力
- 缺点: 幻象、依赖数据。 蒸馏这样的teacher模型, 问题会变得更严重
RLHF:
- 优点: 可以重筛优秀数据,改善幻象。 有突破模型原有性质的能力。 改善HHH(helpfulness, harmfulness, honesty).偏好标注更简单。
- 问题: 效率低、训练不稳定(对超参敏感)、依赖SFT启动
完整post train:
Qwen3
- qwen2.5base ->多源数据采集/模型过滤 -> 短文本SFT/长文本SFT -> 离线RL/在线RL -> qwen Instruct
- 数据采集、筛选: 多个专职小模型合成数据 + 评价模型打分
- 微调: 短文本SFT(32768), 长文本SFT(262144)
- RL:
- 离线RL: 微调得到正负例 + DPO,
- 在线RL: 模型回复差异较大的Query + GRPO
LLaMA-3 : 每轮都有SFT + DPO -> 6轮 -> 最终模型是迭代中参数平均
Tulu3: 大样本数据 + 去重(去掉与测试集重合的数据) -> DPO + PPO
DeepSeek-V3:
- MoE + 指令合成 + SFT -> 奖励模型训练 + GRPO训练 -> 最终模型
- 两阶段RL:rule-based(直接比结果) + model-based reward(SFT后模型得到的)
DeepSeek-R1:
- DeepseekV3-base -> 冷启动SFT + 推理RL(用于合成数据) -> RFT&SFT(base模型微调)-> 全场景RL (GRPO)-> 最终模型
- 自己给自己合成长COT数据 -> 长COT数据+ 普通指令SFT -> 全场景RL(融合DS-V3数据)
non-RL技术:
数据:
- 使用reward model: 生成/筛选数据
- 使用LLM, 对一些数据RHLF数据再生成
- 使用agent增加交互性, 生成数据
监督对齐微调(Supervised alignment tuning)
1. DPO(Direct preference optimization):
- 缺陷: 无法平衡正例和负例、过度依赖参考模型 & 参考模型太差效果差
- 弥补方法: 学习策略修改 or 提升策略模型
2. loss里补充 副优化目标: loss函数里增加reward模型结果
模型适配
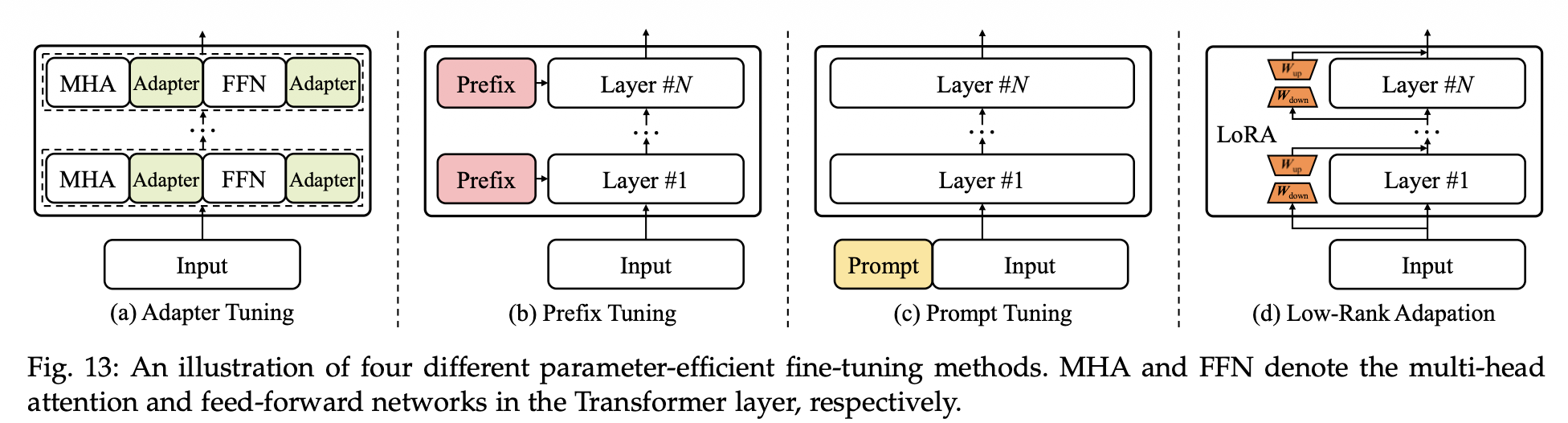
Adapter Tuning: 宽窄宽 适配器, 每次FT这个适配器, 其他部分freeze
prefix tuning: 类似virtual token embeddings
prompt tuning:
Lora: 感觉是adapter tune + prefix tune组合
工具: PEFT(perimeter-efficient fine-tuning): 支持LoRA/AdaLoRA, prefix-tuning, P-Tuning, prompt- tuning
第6章 推理/使用(utilization)
prompting:
内容: 任务描述、输入数据, 上下文信息, prompt风格
设计原则:明确目标、结构成简单 + 细节的子任务、给一些例子、模型友好的表述方式(###, """)、使用角色描述
分析: 能提升复杂问题解决、 数学逻辑类有提升、few-shot/zero-shot
prompt优化:
- 离散:
- Gradient-based:e.g.贪婪search每一个可能提高结果的 token。 遍历token, 找到使loglikelihood升高的gradient
- RL-based: 结合上面的gradientbased, 可知, 可以反向更新gradient, 使用RL方法,增加采样, 减少暴力编辑
- edit-based: 编辑距离?
- LLM-based:
- APE and 变种(一些启发学习)
- GPO
- 连续: 作为embedding层放到模型中训练, (SFT微调task)
- 足够语料:context tuning(todo)
- 不足语料(从充足语料中迁移): Spot,
上下文学习(ICL, in-context learning)
示例设计(demonstration):
- 示例选择: 启发式方法、llm方法(bm25 select, llm加pos/neg标签)
- 示例格式
- 示例排序: llm倾向于重复最接近于input末端的文字, 相关性高的示例应该放到后面
内部机制:
- 生成式机制导致示例对lm的影响很大
- 如何使用: ICL作为任务识别、任务学习方式
- 一些思考: 目标 = 语句(prompt) + weight(LLM)。weight可以提供部分到目标的语言影射, promt可以增加另一些(对于promt和目标的nlp表述相差比较大的内容, ICL可以补充之间的联系)
COT
各种类型的COT: cot, Sample-based Cot, Verification-based cot, tot, Got
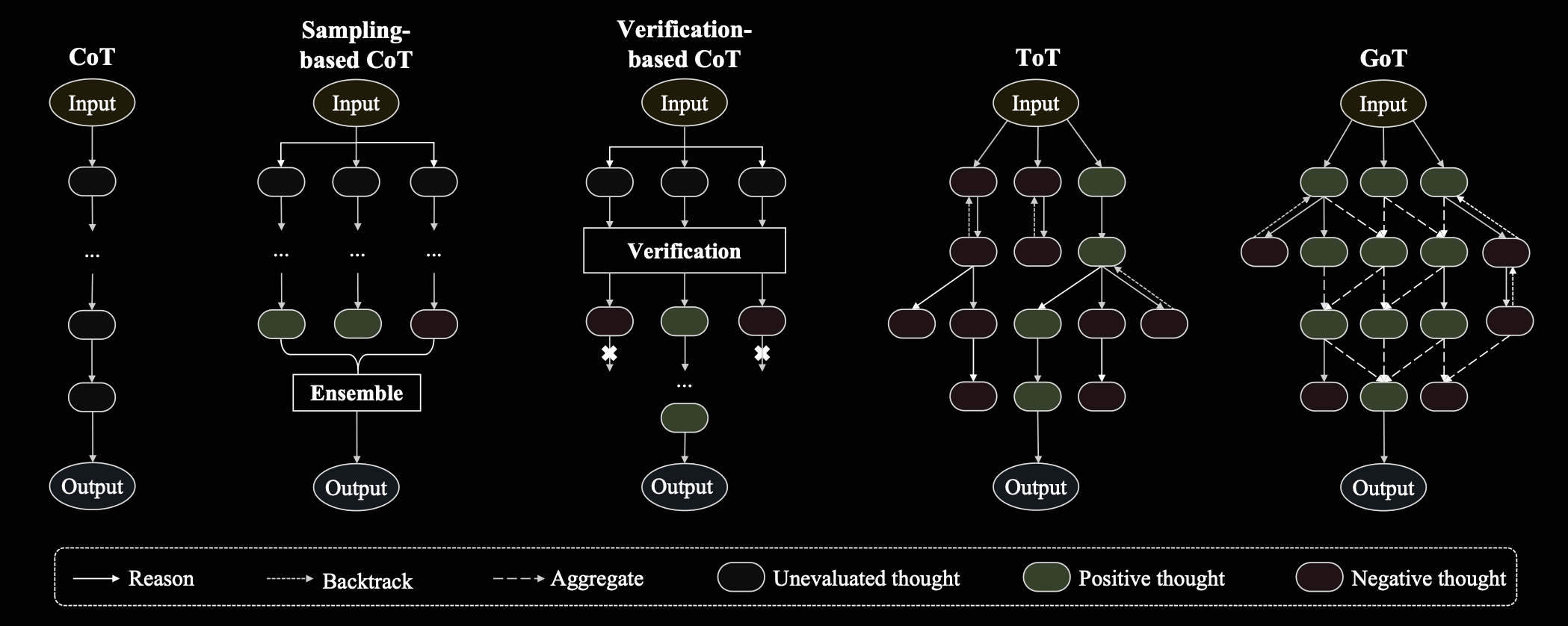
步骤: 先用let's think step by step 生成cot, cot加到模型里重新解决
实践: 不推荐每次都cot, 正常推理无法识别是, cot有效
llm可以产生cot的来源: 对于code的训练导致
Planing(agent, 没写完?)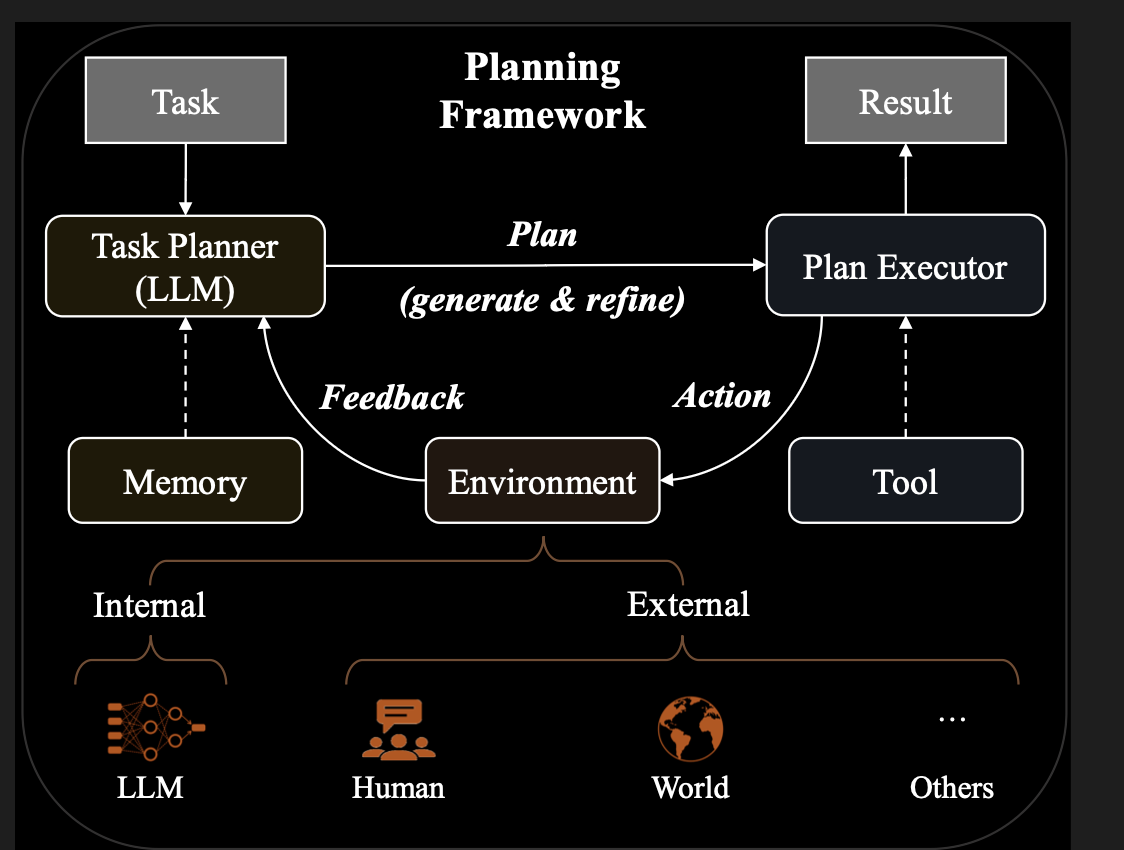
第7章 评价(capability evaluation)
基本能力
- 语言生成任务: language modeling、有条件的语言生成、代码生成
- 问题: 不可靠的生成、领域生成
- 知识使用:closed-book QA: 封闭问题、open-book QA : 开放问题、knowledge completion: 知识补全
- 问题: 幻象: (识别方式: HaluEval、TruthfulQA、 selfcheckGPT )、知识时效
- 复杂推理: 知识推理、符号推理、数学推理
- 问题: 推理不连续、数学计算
高级能力: 人类对齐、环境交互、工具使用
评测标准和方法
数据举例标准: MMLU、BIG-bench(BBH), HELM, 人工()
方法
base LLM 评价标准:
- 知识评价: MMLU、C-Eval
- 推理评价: GSM8K、BBH、MATH
- 结合: OpenCompass
看板Open LLM Leaderboard
finetune效果:
- 人工打分
- 模型打分: AlpacaEval(pair-wise), MT-bench(多轮对话), LLM
- 专业领域: MultiMedQA(医疗, MMLU里有, 具体模型Med-PaLM)、FLUE(金融模型, BBH里有, 具体金融模型BloombergGPT)
后面有些具体评测(todo)
第8章 高级议题

模型的应用方向
增强能力方向:
- 多模态:
- 组成: 图像encoder + llm + 图像/文本表达connection模块
- 训练方式: 两阶段: vision-文本对齐 + visual 指令调优
- 知识图谱(三元组):
- 检索增强LLM
- 检索: train一个小模型来检索、或与KG环境多次交互
- 使用: 序列化检索到的子图, 放到input里(会导致丢失图关系); 把子图改写成text放模型训练
- 协同增强LLM: LLM作为agent发起KG读取, 多轮搜集信息
- 检索增强LLM
LLM在特定领域:
- 医疗(Med-PaLM)、
- 教育、
- 法律(问题: copyright问题, 个人信息泄露、偏见和歧视)、
- 金融: 信息审核、情感分析、实体识别、推理(BloombergGPT、XuanYuan2.0、FinGPT)
- 科学: (PubMedQA、BioASQ)
llm -> AI agent:
其他(todo)
第九章 总结:
1. 长context建模: RoPE、 T5 bias, ALiBi, xPos, even NoPE
RoPE对长上下文的改进方式:
- 直接训:
- 加个缩放系数
- 切分input
- 单元角度切小点, 使max_length -> wavelength
- 还有一个(没看懂跟上一个有什么不同)
适应性contextwindow:
- 并行context窗口
- 强调中间信息的窗口(模型倾向于看input两头, 遗忘中间)
- 选一些token
2. agent: components + workflow.
组成部分: memory、planning、execution
memory: 长期记忆、短期记忆
单智能体典型项目:
通用: AutoGPT(长短期记忆 + 外部工具ES)、GPT-Engineer、 XAgent、
特殊: WebGPT (网络环境)、ProgPrompt(真实环境)、Voyager(采矿)
多智能体: langchain、AgentVerse、AutoGen
目标考虑: 计算cost、人类对齐、能力延伸、鲁棒性+可信性
3. 训练优化:
memery:消耗分析: 模型状态cost、激活cost、其他内存消耗(pytorch、分布式框架DeepSpeed、中间结果 + 碎片)
优化手段:
gradient checkpoint, ZeRO(DeepSpeed)/ FSDP(torch), offload
FlashAttention、sequence parallelism
4. 推理优化
推理效率测量标准
- GPU performance metrics(计算capability, memory 带宽)
- model efficiency metrics
瓶颈分析:
- prefill stage,
- decoding stage
系统级别的优化:
- flash attention & flash-decoding.(GPU, KV cached + query级别, block级别并行)
- PagedAttention(vllm, 减少内存碎片)
- 批管理优化(vllm)
算法层面优化:
- 预测性decoding(speculative decoding)
- cascade inference : 多个模型组合, 负责简单问题的, 负责难问题的。。。
- Non-autogressive decoding 非自回归的
- early-exit
5. 模型压缩(量化, 这块看不进去了 todo)
post-train quantization(PTQ):
- mixed-precision decomposition
- salent weight protection
- fine-grained quantization
- balancing the quantization difficulty
- layer quantization
其他: 注意fine-tune、QAT(Quantization-aware training)
经验:
- weight Q: INT8 weight一般效果最好, int4/int3有一些技巧: layerwise or activation-aware or low-rank adapter tuning. 大模型+int4 > 小模型+int8. INT4平衡性能和一些涌现技能效果最好
- activation Q: 有三种方法: mixed-precision decomposation, fine-grained quantization, difficulty migration. 高质量的int8很困难,
- 低精度llm可以通过加高精度adapter改善 or lora fine-tune or 加一些有目标的fine-tune
蒸馏 or 剪枝
开源工具:
Quant libs: Bitsandbytes, GPTQ-for-LLaMA, AutoGPTQ, llama.cpp
其他lib: Torch-Prunning, LLM-Pruner
6. RAG
组成:
- context retrieval:
- lexical-based retrieval(sparse vector): IR 方式, 词汇表
- semantic retrieval(dense vector): embedding + ANN(近似最近邻)
- prompt construction,(rerank top相关文档, 并组成prompt)
- response generation: (去掉一些没用的, 返回组合结果)
优化:
- query方面: 转写, 重写, 解构
- 结果: rerank, filter, 信息提取, 归纳,
- 需要多次检索的问题: 解决冗余, 冲突?cot,
- RAG增强的训练
7. 幻觉
分类
- 内部幻象(生成信息自相矛盾)、外部幻象(有外部信息依赖, 无法 证明正确)
- 事实性幻象: 实体错误、关系错误、不完整、时效、过度宣称、无法验证
来源:
- 数据质量、
- 数据分布、
- 模型训练方式(decode最大似然方式: 没有提供负例)、
- SFT导致幻象(微调本质是行为clone,目标是知识分布的概率学习。 知识分布≠行为, 模型在猜这个行为的原因),
- 结果生成(prompt设计, decode的模式)
幻想检测:
- 数据资源: TruthfulQA, HaluEval(model-based ), HaluEval2
- 工具: SelfCHeckGPT(uncertainty-based )、HaluAgent(幻想检测智能体), FActScore(tool-based)
成因: 语料量, 预训练知识频率(?)、日常用语不容易幻象 & 复杂指令幻象多
解决方式: 人工对齐、检索增强、改进decode的(认为低层负责语法 +上层负责真实+所以去掉一些底部的logits(DoLa), query+prompt, 外加一个分类器 + 避免回答问题)
8. 复杂推理
多路的long cot
数据构建:
- LongCot data 蒸馏
- Search算法(蒙特卡洛树形搜索MCTS)
- 多agent协作
训练:
- 目标: 格式遵从, 推理能力激活(llm本身有反应和回顾能力)
- 训练方式:
- 监督学习
- RL训练: ReFT(reinforcement fine-tune OpenAI ), GRPO , RLOO 方法

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐


 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)