神经热力学定律在大规模语言模型训练中的应用
本文提出了神经热力学定律(NTL),通过热力学视角分析大规模语言模型(LLM)的训练动态。研究发现,LLM的损失景观具有“河谷”结构,快速动态在谷内平衡,慢速动态沿河演变。通过引入河谷景观的玩具模型,研究展示了热力学量(如温度、熵)和经典热力学原理如何自然地从LLM训练中涌现。这一理论框架不仅为理解LLM训练提供了新视角,还为学习率调度设计提供了直观指导,特别是升温-稳定-衰减(WSD)调度。研究
刘子铭,刘义舟,杰夫·戈尔,马克斯·特格马克
麻省理工学院
摘要
除了神经网络扩展规律之外,人们对大规模语言模型(LLMs)背后的规律知之甚少。我们引入了神经热力学定律(NTL)——一个提供对LLM训练动态新见解的新框架。从理论角度来看,我们证明了关键的热力学量(如温度、熵、热容量、热传导)和经典热力学原理(如热力学三大定律和能量均分定理)自然地出现在河谷损失景观假设下。从实践角度来看,这种科学视角为设计学习率调度提供了直观的指导原则。
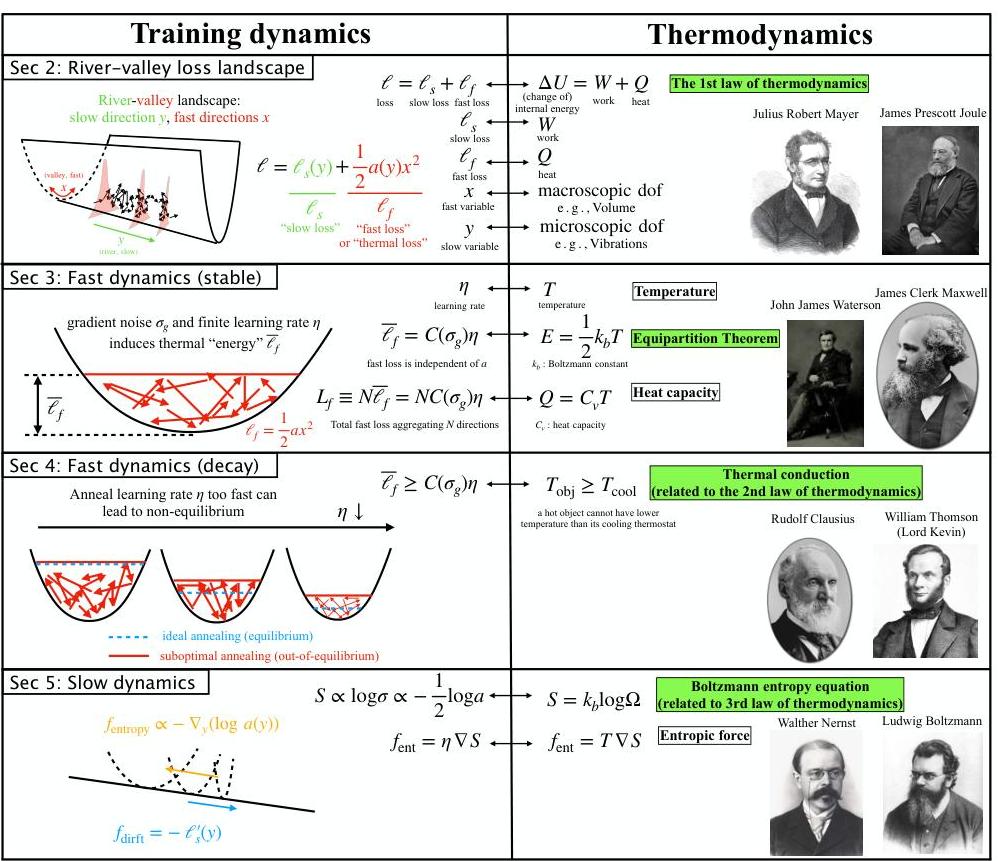
图1:LLM训练动态与热力学之间的联系。
*zmliu@mit.edu
# 1 引言
大型神经网络与热力学系统具有惊人的相似性——两者都涉及大量的自由度并表现出随机动态。因此,探索神经网络与热力学之间的联系并不令人惊讶 [1, 2, 3, 4]。然而,这些研究主要集中在相对容易理解的损失景观的经典机器学习模型上。相比之下,最近的研究才开始揭示大规模语言模型(LLMs)的复杂损失景观,其特征是所谓的“河谷”结构——由尖锐、快速的方向(谷)和平坦、缓慢的方向(河)组成 [5, 6, 7]。直观地说,快速动态在谷内迅速“平衡”,而慢速动态沿河逐渐演变,并受到快速成分的微妙调节。本文的目标是通过神经热力学定律(NTL)的视角来形式化这种直觉。我们展示了关键的热力学量和原则——包括温度、熵、热容量、热传导、热力学三大定律和能量均分定理——如何自然地从LLM的训练动态中出现(见图1中训练动态与热力学之间的联系)。
LLM训练动态与热力学之间的二元性不仅在概念和理论上引人入胜,还提供了实际的见解——例如,在学习率调度的设计方面。在LLM预训练中常用的一种学习率调度是升温-稳定-衰减(WSD)。根据[5, 8],稳定阶段对应于沿河流运动,伴有山谷方向的波动,而衰减阶段则抑制这些山谷变化。受此启发,我们引入了一个河谷景观的玩具模型。这个模型可以解析求解,具有自然的热力学解释,并与实际LLM训练动态显示出强烈的实证一致性。
本文组织如下。快慢动态之间的时间尺度分离使我们可以将总损失函数 ℓ\ellℓ 分解为两个部分——快速部分 ℓf\ell_{f}ℓf 和慢速部分 ℓs\ell_{s}ℓs,这促使我们提出了河谷景观的玩具模型(第2节)。在固定学习率的情况下,快速动态收敛到稳态分布,类似于热平衡(第3节)。当学习率衰减时,分布相应地演化——类似于退火过程(第4节)。此外,快速动态对慢速动态施加了一种有效的熵力,类似于物理学中的熵力(第5节)。值得注意的是,学习率 η\etaη 在所有这些现象中起着核心作用。通过澄清其复杂且有时矛盾的影响,我们得出了设计高效学习率调度的直观指南(第6节),随后是相关工作(第7节)和结论(第8节)。
与主要从经验或现象学角度处理LLM优化(特别是学习率调度设计)的先前工作不同,我们的描述更具机制性。我们的技术贡献如下:
- 快慢分解公式化。在河谷景观中,我们将训练分解为两个过程:(1) 快速动态:要么在固定 η\etaη 下达到平衡,要么在衰减 η\etaη 下进行退火;(2) 慢速动态:沿河流漂移。
-
- 可精确求解的玩具模型。我们介绍了一个可处理的河谷景观玩具模型,捕捉了快慢动态。该模型允许对训练行为和最优学习率调度进行解析求解。
-
- 对LLM的实际相关性。我们证明了玩具模型的见解很好地推广到了实际LLM训练,为学习率调度提供了直观且有效的启发式方法。
-
- 连接物理。神经网络训练与热力学之间的二元性为发展对深度学习更深层次的科学理解奠定了基础。
2 河谷损失景观
近期的工作 [5] 显示,LLM损失景观类似于河谷景观:平坦的河流位于陡峭山谷的底部。训练沿着河流缓慢前进,同时在陡峭的山坡间快速跳跃。在整篇文章中,我们交替使用谷动态 === 快速动态,河动态 === 慢速动态。
学习率 η\etaη 的两难困境 一个好的学习率应该在两个目标之间找到良好的平衡:(A) 促进沿河流方向的进展——通常损失单调递减——这有利于较大的 η\etaη;以及 (B) 最小化沿山谷方向的方差,这有利于较小的 η\etaη。在WSD调度中,稳定阶段负责 (A),而衰减阶段负责 (B) [5]。为了更好地理解这一权衡,我们引入了一个可分析表征沿河流和山谷方向训练动态的玩具模型。
2.1 玩具模型
玩具模型 ℓ(x,y)=c(y)+12a(y)x2\ell(x, y)=c(y)+\frac{1}{2} a(y) x^{2}ℓ(x,y)=c(y)+21a(y)x2 是一个二维的损失函数,类似于图1左上方的河谷景观。它由一个快速变量 xxx 和一个慢速变量 yyy 组成。对于任何固定的 yyy,损失在 x=0x=0x=0 处最小,这描绘出谷底的路径,对应的损失为 c(y)c(y)c(y)。损失函数分解为两个部分:山谷部分 ℓf(x,y)≡12a(y)x2\ell_{f}(x, y) \equiv \frac{1}{2} a(y) x^{2}ℓf(x,y)≡21a(y)x2(称为快速损失或热损失)和河流部分 ℓs(x,y)≡c(y)\ell_{s}(x, y) \equiv c(y)ℓs(x,y)≡c(y)(称为慢速损失)。在文章的其余部分,我们分析了SGD和SignGD在这个景观上的训练动态——在学习率 η\etaη 和梯度噪声 σg\sigma_{g}σg 下——并展示了其与大规模语言模型训练行为的相关性。
2.2 热力学:第一热力学定律
快慢动态的分解让人联想到热力学中的准静态平衡。考虑一个缓慢改变充满气体的腔室体积的活塞:当活塞(慢变量)缓慢移动时,气体分子(快变量)经历快速的热运动并迅速达到新的热平衡。根据第一热力学定律 ΔU=W+Q\Delta U=W+QΔU=W+Q,内部能量的变化 ΔU\Delta UΔU 由功 WWW(与慢动态相关)和热量 QQQ(与快动态相关)组成。这反映了河谷景观中损失函数的分解 ℓ=ℓs+ℓf\ell=\ell_{s}+\ell_{f}ℓ=ℓs+ℓf,其中 ℓs\ell_{s}ℓs 捕捉慢动态,ℓf\ell_{f}ℓf 捕捉快动态。在这种类比中,慢变量 yyy 对应于宏观量,例如体积,而快变量 xxx 对应于微观自由度,例如原子振动。在下一节中,我们将考察 xxx 中的快速波动如何贡献到快损失成分 ℓf\ell_{f}ℓf。尽管这种分解在概念上很有趣,但它尚未提供对 ℓf\ell_{f}ℓf 和 ℓs\ell_{s}ℓs 的定量表征,这是我们将在文章其余部分解决的目标。
3 平衡状态下的谷动态(稳定阶段)
快慢分离允许我们在分析快速动态时将慢变量 yyy 视为固定值。与快速动态相关的是快速损失 ℓf(x,y)≡12a(y)x2\ell_{f}(x, y) \equiv \frac{1}{2} a(y) x^{2}ℓf(x,y)≡21a(y)x2。为了简化,我们忽略对 yyy 的依赖性并写成 ℓf(x)=12ax2\ell_{f}(x)=\frac{1}{2} a x^{2}ℓf(x)=21ax2。我们考虑在该二次函数上的随机梯度下降(SGD)或符号梯度下降(SignGD) 2{ }^{2}2,带有学习率 η\etaη 和梯度噪声 σg\sigma_{g}σg。在这种二次近似下,训练动态收敛到一个高斯稳态分布,p(x)=12πσexp(−x22σ2)p(x)=\frac{1}{\sqrt{2 \pi} \sigma} \exp \left(-\frac{x^{2}}{2 \sigma^{2}}\right)p(x)=2πσ1exp(−2σ2x2),其特征宽度为 σ\sigmaσ。我们的目标是理解 σ\sigmaσ 如何依赖于锐度 aaa、学习率 η\etaη 和梯度噪声 σg\sigma_{g}σg。在第3.1节中,我们推导了 SGD 和 SignSGD 的函数形式 σ=σ(η,a,σg)\sigma=\sigma\left(\eta, a, \sigma_{g}\right)σ=σ(η,a,σg)。第3.2节提供了结果的热力学解释,第3.3节提供了在LLM训练中的实证验证。
3.1 玩具模型:稳态分布
SGD 一个具有学习率 η\etaη 和梯度噪声 σg\sigma_{g}σg 的SGD优化器遵循以下动态:
xt+1=xt−η(axt+σgW˙) x_{t+1}=x_{t}-\eta\left(a x_{t}+\sigma_{g} \dot{W}\right) xt+1=xt−η(axt+σgW˙)
其中 W˙∼N(0,1)\dot{W} \sim \mathcal{N}(0,1)W˙∼N(0,1) 是标准布朗运动。平衡分布是高斯分布 pσ(x)=12πσe−x22σ2p_{\sigma}(x)=\frac{1}{\sqrt{2 \pi} \sigma} e^{-\frac{x^{2}}{2 \sigma^{2}}}pσ(x)=2πσ1e−2σ2x2(详见附录A中的推导)。在平衡状态下,方差保持不变,即 Var(xt+1)=Var(xt)\operatorname{Var}\left(x_{t+1}\right)=\operatorname{Var}\left(x_{t}\right)Var(xt+1)=Var(xt),导致方程 σ2=(1−ηa)2σ2+σg2\sigma^{2}=(1-\eta a)^{2} \sigma^{2}+\sigma_{g}^{2}σ2=(1−ηa)2σ2+σg2,结果为
2{ }^{2}2 为简单起见,我们将动量设为零。注意,SignGD 是 Adam 的一种特殊情况,当 (β1,β2)=(\beta_{1}, \beta_{2})=(β1,β2)= (0,0)(0,0)(0,0) 时。
表1:在一维二次函数 ℓ(x)=12ax2\ell(x)=\frac{1}{2} a x^{2}ℓ(x)=21ax2 上的优化
| 优化器 | SGD | SignGD |
|---|---|---|
| 方程 | xt+1=xt−η(axt+σgW^)x_{t+1}=x_{t}-\eta\left(a x_{t}+\sigma_{g} \hat{W}\right)xt+1=xt−η(axt+σgW^) | xt+1=xt−ηsign(axt+σgW^)x_{t+1}=x_{t}-\eta \operatorname{sign}\left(a x_{t}+\sigma_{g} \hat{W}\right)xt+1=xt−ηsign(axt+σgW^) |
| 稳态分布宽度 σ\sigmaσ | σga(1a−a)\frac{\sigma_{g}}{\sqrt{a\left(\frac{1}{a}-a\right)}}a(a1−a)σg | π4η1+1+32π(σgaη)2\frac{\sqrt{\pi}}{4} \eta \sqrt{1+\sqrt{1+\frac{32}{\pi}\left(\frac{\sigma_{g}}{a \eta}\right)^{2}}}4πη1+1+π32(aησg)2 |
| σ\sigmaσ(平坦极限 aη≪1a \eta \ll 1aη≪1 ) | π2aσg∝η1/2a−1/2σg\sqrt{\frac{\pi}{2 a}} \sigma_{g} \propto \eta^{1 / 2} a^{-1 / 2} \sigma_{g}2aπσg∝η1/2a−1/2σg | (π8)1/4σgηa∝η1/2a−1/2σg1/2\left(\frac{\pi}{8}\right)^{1 / 4} \sqrt{\frac{\sigma_{g} \eta}{a}} \propto \eta^{1 / 2} a^{-1 / 2} \sigma_{g}^{1 / 2}(8π)1/4aσgη∝η1/2a−1/2σg1/2 |
| 热损失 ℓf‾\overline{\ell_{f}}ℓf | σg24η\frac{\sigma_{g}^{2}}{4} \eta4σg2η | π32σgη\sqrt{\frac{\pi}{32}} \sigma_{g} \eta32πσgη |
| 最优衰减计划 | ηt=2a1+116(th=2aη)\eta_{t}=\frac{\frac{2}{a}}{1+\frac{1}{16}}\left(t_{h}=\frac{2}{a \eta}\right)ηt=1+161a2(th=aη2) | ηt=21+116(th=2πσgaη)\eta_{t}=\frac{2}{1+\frac{1}{16}}\left(t_{h}=\sqrt{2 \pi} \frac{\sigma_{g}}{a \eta}\right)ηt=1+1612(th=2πaησg) |
得到 σ=σg/a(2/η−a)\sigma=\sigma_{g} / \sqrt{a(2 / \eta-a)}σ=σg/a(2/η−a)。只有当 0<a<2η0<a<\frac{2}{\eta}0<a<η2 时,该公式才是良好定义的。当 a→2/ηa \rightarrow 2 / \etaa→2/η 时,学习率达到所谓的“稳定性边缘”[9]。由于大多数过参数化模型的方向相对较平,我们感兴趣的是平坦极限情况,当 a≪2/ηa \ll 2 / \etaa≪2/η 时,简化 σ\sigmaσ 到 σ≈η/(2a)σg∝η1/2a−1/2σg1\sigma \approx \sqrt{\eta /(2 a)} \sigma_{g} \propto \eta^{1 / 2} a^{-1 / 2} \sigma_{g}^{1}σ≈η/(2a)σg∝η1/2a−1/2σg1。
SignGD 具有学习率 η\etaη 和梯度噪声 σg\sigma_{g}σg 的SignGD优化器遵循动态:
xt+1=xt−ηsign(axt+σgW^) x_{t+1}=x_{t}-\eta \operatorname{sign}\left(a x_{t}+\sigma_{g} \hat{W}\right) xt+1=xt−ηsign(axt+σgW^)
使用与SGD相同的方差保持条件,我们推导出稳态高斯宽度 σ=π4η1+1+32π(σgaη)2\sigma=\frac{\sqrt{\pi}}{4} \eta \sqrt{1+\sqrt{1+\frac{32}{\pi}\left(\frac{\sigma_{g}}{a \eta}\right)^{2}}}σ=4πη1+1+π32(aησg)2。平坦极限 a≪σg/ηa \ll \sigma_{g} / \etaa≪σg/η 得到 σ≈(π8)1/4σgηa∝η1/2a−1/2σg1/2\sigma \approx\left(\frac{\pi}{8}\right)^{1 / 4} \sqrt{\frac{\sigma_{g} \eta}{a}} \propto \eta^{1 / 2} a^{-1 / 2} \sigma_{g}^{1 / 2}σ≈(8π)1/4aσgη∝η1/2a−1/2σg1/2。详细推导推迟到附录C。结果总结在表1中以供参考。
热损失 平均热损失为 ℓf‾=Ex∼pσ(x)(12ax2)=12aσ2\overline{\ell_{f}}=\mathbb{E}_{x \sim p_{\sigma}(x)}\left(\frac{1}{2} a x^{2}\right)=\frac{1}{2} a \sigma^{2}ℓf=Ex∼pσ(x)(21ax2)=21aσ2。注意到对于SGD和SignGD,σ∝a−1/2\sigma \propto a^{-1 / 2}σ∝a−1/2,因此在 ℓf‾\overline{\ell_{f}}ℓf 中 aaa 被抵消掉,即 ℓf‾∝ησg2\overline{\ell_{f}} \propto \eta \sigma_{g}^{2}ℓf∝ησg2 对于SGD和 ℓf∝ησg\ell_{f} \propto \eta \sigma_{g}ℓf∝ησg 对于SignGD。aaa 的独立性导致了一个有趣的事实:给定两个具有不同锐度 a1≠a2a_{1} \neq a_{2}a1=a2 的方向,它们诱导相同的 ℓf‾\overline{\ell_{f}}ℓf(只要 η\etaη 和 σg\sigma_{g}σg 相同)。这也意味着:无论稳定阶段持续多久(导致沿河流的不同点具有不同的锐度),在衰减阶段中可减少的热损失大致相同,这解释了[10]中的观察结果。平均热损失 ℓf‾\overline{\ell_{f}}ℓf 也可以被解释为在许多谷方向上的平均值。
3.2 热力学:均分定理、温度、热容
锐度的独立性对应于热力学中的均分定理,该定理指出:在一个处于热平衡的系统中,能量在所有二次出现于系统能量中的自由度之间均匀分布。具体来说,E=12kbTE=\frac{1}{2} k_{b} TE=21kbT,其中 kbk_{b}kb 是玻尔兹曼常数,TTT 是温度。特别地,振动自由度的能量独立于弹簧常数,这对应于我们案例中的锐度 aaa。现在我们可以建立优化 ℓf‾∝σgnη\overline{\ell_{f}} \propto \sigma_{g}^{n} \etaℓf∝σgnη (n=1n=1n=1 对于SignGD,n=2n=2n=2 对于SGD)和热力学 E=12kbTE=\frac{1}{2} k_{b} TE=21kbT 之间的映射。忽略常数项,我们得到有效温度 T∼ηT \sim \etaT∼η,即学习率 η\etaη 可以解释为温度。基于这一点,斜率 C≡∂ℓf‾∂ηC \equiv \frac{\partial \overline{\ell_{f}}}{\partial \eta}C≡∂η∂ℓf 可以解释为热容。现在我们可以简单地通过 ℓf‾=Cη\overline{\ell_{f}}=C \etaℓf=Cη 来关联 ℓf‾\overline{\ell_{f}}ℓf 和 η\etaη。当存在 NNN 个谷方向时,总的热损失是对所有谷方向求和 Lf‾=Nℓf‾=NCη\overline{L_{f}}=N \overline{\ell_{f}}=N C \etaLf=Nℓf=NCη。
3.3 实验
GPT-2 实验设置:我们在OpenWebText上预训练一个小型GPT-2模型(基于NanoGPT [11])。我们使用8个V100 GPU,选择块大小为1024,批量大小为480块。我们使用Adam优化器,采用升温-稳定-衰减学习率调度,如图2(a)所示。我们总是使用2000步线性升温,从0升温到 6×10−46 \times 10^{-4}6×10−4。稳定阶段的学习率为 η\etaη。衰减阶段从 η\etaη 开始,并余弦衰减到 ηmin\eta_{\min }ηmin。总训练步数为10k。
我们在玩具模型中已经表明,平均热损失 ℓf‾\overline{\ell_{f}}ℓf 与学习率 η\etaη 成线性关系(假设热平衡)。我们现在展示这种关系适用于大规模语言模型。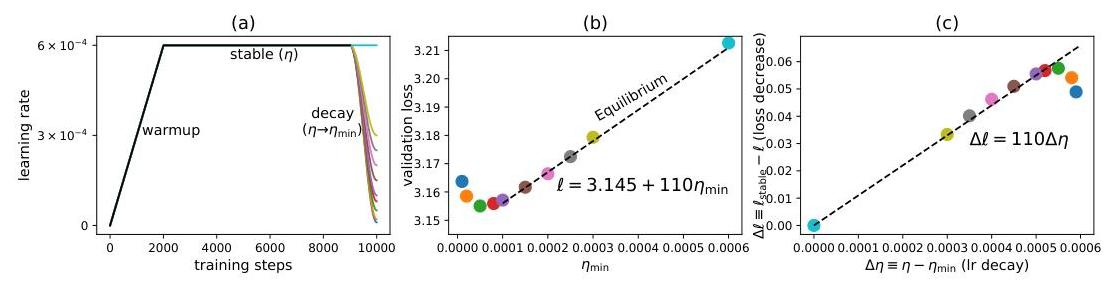
图2:(a) LLM预训练通常使用WSD(升温-稳定-衰减)学习率调度。ηmin\eta_{\min }ηmin 是最终学习率。(b) 验证损失是 ηmin\eta_{\min }ηmin 的线性函数,对于大的 ηmin\eta_{\min }ηmin。© Δℓ\Delta \ellΔℓ 是 Δη\Delta \etaΔη 的线性函数,对于小的 Δη\Delta \etaΔη。
我们有2k步升温,7k步稳定 (η=6×10−4\eta=6 \times 10^{-4}η=6×10−4) 和1k步余弦衰减至 ηmin\eta_{\min }ηmin,这是扫描的。在图2(b)中,我们显示对于大的 ηmin\eta_{\min }ηmin,最终验证损失与 ηmin\eta_{\min }ηmin 成线性关系。由于衰减阶段较短,我们可以假设 ℓs\ell_{s}ℓs 在不同衰减调度之间变化不大。因此,ℓ\ellℓ 可代表 ℓf‾\overline{\ell_{f}}ℓf,我们测量得到 ℓ=3.145+110ηmin\ell=3.145+110 \eta_{\min }ℓ=3.145+110ηmin。与理论热损失 Lf‾=(π32Nσg)η\overline{L_{f}}=\left(\sqrt{\frac{\pi}{32}} N \sigma_{g}\right) \etaLf=(32πNσg)η(对于SignGD 3{ }^{3}3)比较,我们得到 N=110σg32π≈5×106=5MN=\frac{110}{\sigma_{g}} \sqrt{\frac{32}{\pi}} \approx 5 \times 10^{6}=5 \mathrm{M}N=σg110π32≈5×106=5M,其中 σg≈7×10−5\sigma_{g} \approx 7 \times 10^{-5}σg≈7×10−5 是用批次估计的。注意GPT-2 small有124 M参数,而5 M谷方向仅占其总参数的 4%4 \%4%。这是预期的:超参数化模型的大多数方向是平坦的(“河”),只有少量方向是尖锐的(“谷”)。然而,太小的 ηmin\eta_{\min }ηmin 会导致更高的损失,最低损失出现在大约 ηmin≈5×10−5>0\eta_{\min } \approx 5 \times 10^{-5}>0ηmin≈5×10−5>0。当 η\etaη 衰减过快时,热平衡的崩溃导致小的 ηmin\eta_{\min }ηmin 出现非单调行为,我们将在下一节详细说明。
4 谷动态在退火过程中(衰减阶段)
在上一节中,我们已经表明稳态分布的宽度 σ\sigmaσ 依赖于学习率 η\etaη,表现为 σ∝η\sigma \propto \sqrt{\eta}σ∝η。在衰减阶段,当 η\etaη 衰减时,σ\sigmaσ 将随之衰减。如果 η\etaη 衰减足够慢,我们可以期望由于准静态热平衡,σ∝η\sigma \propto \sqrt{\eta}σ∝η 始终成立。但这是最优的吗?可能不是。另一个极端——η\etaη 衰减太快——也不是最优的。这种两难局面是因为 η\etaη 扮演了两个角色:(1) η\etaη 是控制高斯噪声的温度(我们希望 η\etaη 小);(2) η\etaη 是控制时间尺度的步长(我们希望 η\etaη 大)。在 ℓf\ell_{f}ℓf 减少尽可能快的意义上,存在一个“最优”的 η\etaη 衰减调度。
4.1 玩具模型:最优学习率衰减
现在我们考虑一个学习率衰减调度,即一个序列 η0≥η1≥η2≥⋯≥ηT\eta_{0} \geq \eta_{1} \geq \eta_{2} \geq \cdots \geq \eta_{T}η0≥η1≥η2≥⋯≥ηT。SGD(方程(1))的动力学现在变为 xt+1=xt−ηt(axt+σgW)x_{t+1}=x_{t}-\eta_{t}\left(a x_{t}+\sigma_{g} W\right)xt+1=xt−ηt(axt+σgW)。由于该方程是线性的,如果 p(x0)p\left(x_{0}\right)p(x0) 开始时是一个高斯分布,p(xt)p\left(x_{t}\right)p(xt) 将始终保持为高斯分布(尽管高斯宽度随时间变化,记为 σt\sigma_{t}σt)对于所有 t≥0t \geq 0t≥0。假设在 t=0t=0t=0 时,p(x0)p\left(x_{0}\right)p(x0) 已处于学习率为 η\etaη 的热平衡,其高斯宽度为 σ0\sigma_{0}σ0。高斯宽度 σt\sigma_{t}σt 遵循以下递归关系 σt+12=(1−ηta)2σt2+(ηtσg)2=(a2σt2+σg2)ηt2−2aσt2ηt+σt2\sigma_{t+1}^{2}=\left(1-\eta_{t} a\right)^{2} \sigma_{t}^{2}+\left(\eta_{t} \sigma_{g}\right)^{2}=\left(a^{2} \sigma_{t}^{2}+\sigma_{g}^{2}\right) \eta_{t}^{2}-2 a \sigma_{t}^{2} \eta_{t}+\sigma_{t}^{2}σt+12=(1−ηta)2σt2+(ηtσg)2=(a2σt2+σg2)ηt2−2aσt2ηt+σt2,这是一个关于 ηt\eta_{t}ηt 的二次函数。我们希望选择 ηt\eta_{t}ηt 使得 σt+1\sigma_{t+1}σt+1 最小化 ηt=aσt2a2σt2+σg2,σt+12=σg2σt2σg2+a2σt2\eta_{t}=\frac{a \sigma_{t}^{2}}{a^{2} \sigma_{t}^{2}+\sigma_{g}^{2}}, \sigma_{t+1}^{2}=\frac{\sigma_{g}^{2} \sigma_{t}^{2}}{\sigma_{g}^{2}+a^{2} \sigma_{t}^{2}}ηt=a2σt2+σg2aσt2,σt+12=σg2+a2σt2σg2σt2。通过对第二个方程取反,我们得到 1σt+12=1σt2+a2σg2\frac{1}{\sigma_{t+1}^{2}}=\frac{1}{\sigma_{t}^{2}}+\frac{a^{2}}{\sigma_{g}^{2}}σt+121=σt21+σg2a2,这意味着 {1σt2}\left\{\frac{1}{\sigma_{t}^{2}}\right\}{σt21} 构成了一个等差数列。显然 1σt2=1σ02+a2tσg2\frac{1}{\sigma_{t}^{2}}=\frac{1}{\sigma_{0}^{2}}+\frac{a^{2} t}{\sigma_{g}^{2}}σt21=σ021+σg2a2t。相应地,
ηt=1a1+σt2a2(1σ02+a2tσg2)≈η21+tth(th≡2aη) \eta_{t}=\frac{\frac{1}{a}}{1+\frac{\sigma_{t}^{2}}{a^{2}}\left(\frac{1}{\sigma_{0}^{2}}+\frac{a^{2} t}{\sigma_{g}^{2}}\right)} \approx \frac{\frac{\eta}{2}}{1+\frac{t}{t_{h}}}\left(t_{h} \equiv \frac{2}{a \eta}\right) ηt=1+a2σt2(σ021+σg2a2t)a1≈1+tht2η(th≡aη2)
3{ }^{3}3 当 (β1,β2)=(0,0)(\beta_{1}, \beta_{2})=(0,0)(β1,β2)=(0,0) 时,SignGD 是 Adam 的特殊情况。
其中 tht_{h}th 是将 ηt\eta_{t}ηt 减半所需的时间,因此表示学习率衰减的时间尺度。回想一下 ℓf‾=Cη\overline{\ell_{f}}=C \etaℓf=Cη,所以 ℓf,t‾=Cηt\overline{\ell_{f, t}}=C \eta_{t}ℓf,t=Cηt 具有与 ηt\eta_{t}ηt 相同的衰减形式。我们对最优调度做几点备注。
备注1:渐近行为 当 t→∞t \rightarrow \inftyt→∞ 时,学习率 ηt∝t−1\eta_{t} \propto t^{-1}ηt∝t−1,标准差 σt∝t−1/2\sigma_{t} \propto t^{-1 / 2}σt∝t−1/2,损失 ℓf,t‾∝t−1,It=1/σt2∝t(It\overline{\ell_{f, t}} \propto t^{-1}, I_{t}=1 / \sigma_{t}^{2} \propto t\left(I_{t}\right.ℓf,t∝t−1,It=1/σt2∝t(It 是高斯均值的费舍尔信息量)。
备注2:在 t=0t=0t=0 时的不连续性。一个有趣的观察是 η0≠η\eta_{0} \neq \etaη0=η 而是 η0≈η2\eta_{0} \approx \frac{\eta}{2}η0≈2η。这是有道理的,因为既 η0=η\eta_{0}=\etaη0=η 也不 η0=0\eta_{0}=0η0=0 导致损失减少。这种不连续性违背了连续学习率调度的常见智慧。
备注3:当 η→∞\eta \rightarrow \inftyη→∞ 时,衰减时间是有界的。假设我们要将学习率从稳定值 η\etaη 降低到最后值 ηmin\eta_{\min }ηmin。最优衰减需要时间 Td=2aηmin(1−ηminη)<T_{d}=\frac{2}{a \eta_{\min }}\left(1-\frac{\eta_{\min }}{\eta}\right)<Td=aηmin2(1−ηηmin)< 2aηmin\frac{2}{a \eta_{\min }}aηmin2。请注意,衰减时间 TdT_{d}Td 有一个上限 T∗≡2aηminT^{*} \equiv \frac{2}{a \eta_{\min }}T∗≡aηmin2,独立于 η\etaη,这意味着只要使用足够的时间(超过 T∗T^{*}T∗ )进行衰减,原则上可以任意增加稳定的 学习率 η\etaη 而不必担心因衰减不足引起的额外损失。
备注4:SignGD 的最优调度除 tht_{h}th 外与其他相同。SignGD 的最优 η\etaη 衰减调度具有相同的形式 ηt=21+tha\eta_{t}=\frac{2}{1+\frac{t_{h}}{a}}ηt=1+ath2,尽管 th≡2πσgaηt_{h} \equiv \sqrt{2 \pi} \frac{\sigma_{g}}{a \eta}th≡2πaησg 稍有不同。详细推导请参阅附录C。
4.2 热力学:傅里叶传导定律,第二热力学定律
在上述分析中,学习率 η\etaη 具有两个角色:温度和时间尺度,这使得与热力学建立对应关系变得复杂。我们现在研究一种简化的双温度设置,其中类比变得更加清晰。假设快参数 xxx 达到其与学习率 ηA\eta_{A}ηA 的热平衡。在 t=0t=0t=0 时,我们突然将学习率切换到 ηB<ηA\eta_{B}<\eta_{A}ηB<ηA。热宽度 σt\sigma_{t}σt 和热损失 ℓf,t‾≡12aσt2\overline{\ell_{f, t}} \equiv \frac{1}{2} a \sigma_{t}^{2}ℓf,t≡21aσt2 如何随时间演变?
回想SGD在稳态分布中的基本事实:在平坦极限 a≪2ηa \ll \frac{2}{\eta}a≪η2 下,我们有 σ≈η2aσg\sigma \approx \sqrt{\frac{\eta}{2 a}} \sigma_{g}σ≈2aησg,以及 ℓf‾=12aσ2=14ησg2\overline{\ell_{f}}=\frac{1}{2} a \sigma^{2}=\frac{1}{4} \eta \sigma_{g}^{2}ℓf=21aσ2=41ησg2。在 t=0t=0t=0 时,我们有 σ0=ηA2aσg.{σt}\sigma_{0}=\sqrt{\frac{\eta_{A}}{2 a}} \sigma_{g} .\left\{\sigma_{t}\right\}σ0=2aηAσg.{σt} 演变如下 σℓ+12=\sigma_{\ell+1}^{2}=σℓ+12= (a2σt2+σg2)ηB2−2aσt2ηB+σt2\left(a^{2} \sigma_{t}^{2}+\sigma_{g}^{2}\right) \eta_{B}^{2}-2 a \sigma_{t}^{2} \eta_{B}+\sigma_{t}^{2}(a2σt2+σg2)ηB2−2aσt2ηB+σt2,其中划掉的项可以在平坦极限下忽略。我们感兴趣的是 ℓf,t‾\overline{\ell_{f, t}}ℓf,t 如何演变:
ℓf,t+1‾−ℓf,t‾=12a(σt+12−σt2)=12aηB(σg2ηB−2aσt2)=−2aηB(ℓf,t‾−ℓeq‾(ηB)) \overline{\ell_{f, t+1}}-\overline{\ell_{f, t}}=\frac{1}{2} a\left(\sigma_{t+1}^{2}-\sigma_{t}^{2}\right)=\frac{1}{2} a \eta_{B}\left(\sigma_{g}^{2} \eta_{B}-2 a \sigma_{t}^{2}\right)=-2 a \eta_{B}\left(\overline{\ell_{f, t}}-\overline{\ell_{e q}}\left(\eta_{B}\right)\right) ℓf,t+1−ℓf,t=21a(σt+12−σt2)=21aηB(σg2ηB−2aσt2)=−2aηB(ℓf,t−ℓeq(ηB))
其中 ℓeq‾(ηB)≡ηBσg22\overline{\ell_{e q}}\left(\eta_{B}\right) \equiv \frac{\eta_{B} \sigma_{g}^{2}}{2}ℓeq(ηB)≡2ηBσg2 是在平衡条件下给定 η=ηB\eta=\eta_{B}η=ηB 的平均热损失。这个方程类似于傅里叶热传导定律 Q=k(TA−TB)Q=k\left(T_{A}-T_{B}\right)Q=k(TA−TB) :当一个高温物体(温度 TAT_{A}TA )接触一个较冷的表面(温度 TBT_{B}TB )时,热传导功率 QQQ 与其温差成正比,导致指数收敛。类似地,方程(4) 具有指数衰减解 ℓf,t‾=ℓf‾(ηB)+(ℓf‾(ηA)−ℓf‾(ηB))exp(−2aηBt)≥ℓf‾(ηB)\overline{\ell_{f, t}}=\overline{\ell_{f}}\left(\eta_{B}\right)+\left(\overline{\ell_{f}}\left(\eta_{A}\right)-\overline{\ell_{f}}\left(\eta_{B}\right)\right) \exp \left(-2 a \eta_{B} t\right) \geq \overline{\ell_{f}}\left(\eta_{B}\right)ℓf,t=ℓf(ηB)+(ℓf(ηA)−ℓf(ηB))exp(−2aηBt)≥ℓf(ηB)。不等式 ℓf,t‾≥ℓf‾(ηB)\overline{\ell_{f, t}} \geq \overline{\ell_{f}}\left(\eta_{B}\right)ℓf,t≥ℓf(ηB) 与第二热力学定律有关。简单地说,当一个高温物体接触一个冷却恒温器时,高温物体不能被冷却到低于冷却恒温器的温度(无需额外功)。作为合理性检查,我们在附录D中显示:通过使方程(4) 连续,我们也可以获得方程(3) 中的 1/t1 / t1/t 调度。
4.3 实验
玩具实验 我们测试在方程(3) 中推导出的调度的最优性。我们选择损失景观 ℓ=∑i=1n12aθi2(a=2,n=10000)\ell=\sum_{i=1}^{n} \frac{1}{2} a \theta_{i}^{2}(a=2, n=10000)ℓ=∑i=1n21aθi2(a=2,n=10000) 并初始化 θi∼N(0,1)\theta_{i} \sim \mathcal{N}(0,1)θi∼N(0,1)。我们运行SGD,学习率为 η=0.1\eta=0.1η=0.1(手动注入高斯梯度噪声 σg=0.1\sigma_{g}=0.1σg=0.1),共10000步以达到其稳态分布。然后我们执行学习率衰减调度 ηt=bu1+tth\eta_{t}=\frac{b u}{1+\frac{t}{t_{h}}}ηt=1+thtbu,使用各种组合的 (b,th)\left(b, t_{h}\right)(b,th)。我们在图3(a) 中绘制最终损失。我们的理论结果表明 b=1/2b=1 / 2b=1/2 和 th=2aη=10t_{h}=\frac{2}{a \eta}=10th=aη2=10 提供最佳结果(最低损失),这由相图验证。我们还在(b) 和© 中绘制了沿 tht_{h}th 和 bbb 的两个切片,显示最终损失对 tht_{h}th 比对 bbb 更敏感。为了模拟各向异性,我们还尝试了一个各向异性损失 ℓ=∑i=1n12aiθi2(ai=10−2+4i/n,n=10000),θi∼N(0,1)\ell=\sum_{i=1}^{n} \frac{1}{2} a_{i} \theta_{i}^{2}\left(a_{i}=10^{-2+4 i / n}, n=10000\right), \theta_{i} \sim \mathcal{N}(0,1)ℓ=∑i=1n21aiθi2(ai=10−2+4i/n,n=10000),θi∼N(0,1)。我们应用学习率衰减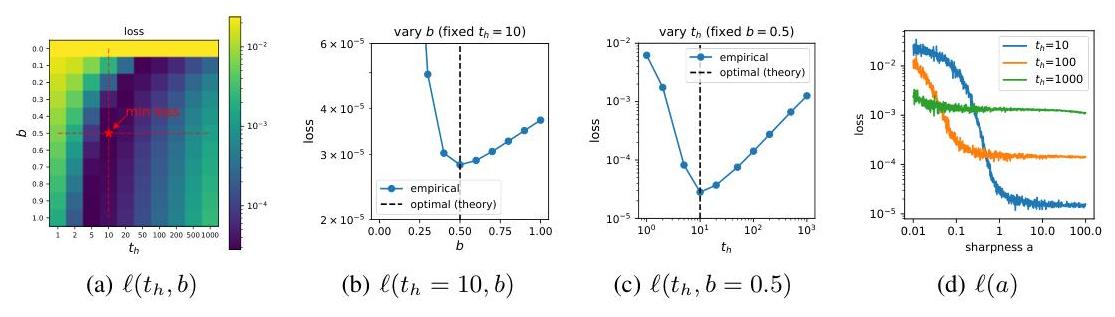
图3:退火玩具示例。(a)(b)© 各向同性损失 ℓ=∑i=1n12aθi2(a=2,n=10000)\ell=\sum_{i=1}^{n} \frac{1}{2} a \theta_{i}^{2}(a=2, n=10000)ℓ=∑i=1n21aθi2(a=2,n=10000)。通过应用衰减调度 ηt=bη0/(1+t/th)\eta_{t}=b \eta_{0} /\left(1+t / t_{h}\right)ηt=bη0/(1+t/th) 获得的最终损失。理论最小值 (b,th)=(0.5,10)\left(b, t_{h}\right)=(0.5,10)(b,th)=(0.5,10)(标记为星号)与数值结果一致。(d) 各向异性损失 ℓ=∑i=1n12aiθi2(ai=10−2+4i/n,n=10000)\ell=\sum_{i=1}^{n} \frac{1}{2} a_{i} \theta_{i}^{2}\left(a_{i}=10^{-2+4 i / n}, n=10000\right)ℓ=∑i=1n21aiθi2(ai=10−2+4i/n,n=10000)。我们设置 b=0.5b=0.5b=0.5 并尝试 th=10,100,1000t_{h}=10,100,1000th=10,100,1000。对于大的 aaa,损失大致保持不变,因为有均分定理在第3节中。然而,小锐度方向具有更高的损失,因为它们的最佳衰减时间 th∝1/at_{h} \propto 1 / ath∝1/a 更大,因此需要更长时间才能收敛。
对LLM的影响 上述结果可以为最近的观察提供见解:(1) 观察到1-sqrt衰减[10] 或优化的衰减[12] 比线性或余弦衰减更好。这些更好的衰减调度与我们推导的 1/t1 / t1/t 调度一致。(2) 衰减到零是次优的,正如[13]中观察到的那样。事实上,最优调度暗示它应该花费无限时间才能达到 ηmin=0\eta_{\min }=0ηmin=0。
5 河流动力学
到目前为止,我们一直在研究 xxx 的快速动态,假设慢变量 yyy 是固定的。本节将研究慢动态如何通过熵力受到快动态的影响。
5.1 玩具模型:熵力
回想一下我们的二维玩具河流-山谷景观是 l(x,y)=12a(y)x2+c(y)≡ℓf+ℓsl(x, y)=\frac{1}{2} a(y) x^{2}+c(y) \equiv \ell_{f}+\ell_{s}l(x,y)=21a(y)x2+c(y)≡ℓf+ℓs,其中 ℓf\ell_{f}ℓf 和 ℓs\ell_{s}ℓs 分别是快速损失和慢速损失。山谷的锐度由 a(y)a(y)a(y) 控制,而 c(y)c(y)c(y) 控制山谷底部。优化器的动力学可以看作是沿 xxx 的快速动态和沿 yyy 的慢速动态。给定一个固定的 yyy,xxx 的稳态分布为 py(x)=12πσ(y)e−x22σ(y)2p_{y}(x)=\frac{1}{\sqrt{2 \pi} \sigma(y)} e^{-\frac{x^{2}}{2 \sigma(y)^{2}}}py(x)=2πσ(y)1e−2σ(y)2x2。我们已经证明 σ(y)=d(η,σg)/a(y)\sigma(y)=d\left(\eta, \sigma_{g}\right) / \sqrt{a(y)}σ(y)=d(η,σg)/a(y),其中对于SGD,d=η/2σgd=\sqrt{\eta / 2} \sigma_{g}d=η/2σg,而对于SignGD,c=(π/8)1/4σgηc=(\pi / 8)^{1 / 4} \sqrt{\sigma_{g} \eta}c=(π/8)1/4σgη。熵力定义为 ℓf\ell_{f}ℓf 沿 yyy 的平均梯度:
Fent=−gˉy=−12a′(y)x2‾=−12a′(y)σ(y)2=−d2(η,σg)2a′(y)a(y) F_{\mathrm{ent}}=-\bar{g}_{y}=-\frac{1}{2} a^{\prime}(y) \overline{x^{2}}=-\frac{1}{2} a^{\prime}(y) \sigma(y)^{2}=-\frac{d^{2}\left(\eta, \sigma_{g}\right)}{2} \frac{a^{\prime}(y)}{a(y)} Fent=−gˉy=−21a′(y)x2=−21a′(y)σ(y)2=−2d2(η,σg)a(y)a′(y)
负号意味着熵力指向锐度减小的方向。山谷底部 ℓs\ell_{s}ℓs 的负梯度为Fbtm=−c′(y)F_{\mathrm{btm}}=-c^{\prime}(y)Fbtm=−c′(y)。总“力”为 F=Fent+FbtmF=F_{\mathrm{ent}}+F_{\mathrm{btm}}F=Fent+Fbtm。
定义熵 注意到 a′(y)/a(y)a^{\prime}(y) / a(y)a′(y)/a(y) 在 Fent F_{\text {ent }}Fent 中可以写成更紧凑的形式 (loga(y))′(\log a(y))^{\prime}(loga(y))′。我们可以定义 S≡−d2(η,σg)2loga(x)S \equiv-\frac{d^{2}\left(\eta, \sigma_{g}\right)}{2} \log a(x)S≡−2d2(η,σg)loga(x),然后 Fent =∇SF_{\text {ent }}=\nabla SFent =∇S。
熵陷阱定义为 Fbtm⋅F≤0F_{\mathrm{btm}} \cdot F \leq 0Fbtm⋅F≤0。当熵力阻止优化器沿河下降时,尽管优化器能够“看到”正确的方向,也会发生熵陷阱。具体例子在附录E中讨论。
5.2 热力学:熵,热力学第三定律
我们想从热力学的角度进一步解释为什么 S(x)∝−12loga(x)S(x) \propto-\frac{1}{2} \log a(x)S(x)∝−21loga(x) 可以被解释为熵。在物理学中,熵被定义为离散系统中的 Sphy =−∑ipilogpiS_{\text {phy }}=-\sum_{i} p_{i} \log p_{i}Sphy =−∑ipilogpi 或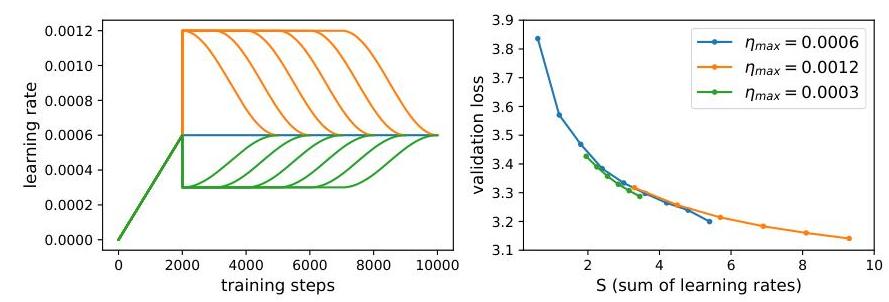
图4:测试LLM中熵力的存在。左:不同稳定学习率 ηmax=0.0003,0.0006,0.0012\eta_{\max }=0.0003,0.0006,0.0012ηmax=0.0003,0.0006,0.0012 和相同 ηmin=0.0006\eta_{\min }=0.0006ηmin=0.0006 的各种学习率调度。右:根据学习率总和绘制验证损失。对于不同的 η\etaη,曲线大致对齐,表明略微负的熵力,对应于沿河流逐渐变窄的山谷。
连续系统中的 Sphy =−∫dxp(x)logp(x)S_{\text {phy }}=-\int d x p(x) \log p(x)Sphy =−∫dxp(x)logp(x)。高斯分布 p(x)=12πσe−x22σ2p(x)=\frac{1}{\sqrt{2 \pi \sigma}} e^{-\frac{x^{2}}{2 \sigma^{2}}}p(x)=2πσ1e−2σ2x2 因此具有熵 Sphy =12log(2πσ2)+12S_{\text {phy }}=\frac{1}{2} \log \left(2 \pi \sigma^{2}\right)+\frac{1}{2}Sphy =21log(2πσ2)+21。插入 σ=d/a\sigma=d / \sqrt{a}σ=d/a 得到 Sphy =−12loga+S_{\text {phy }}=-\frac{1}{2} \log a+Sphy =−21loga+ 12log(2πd)+12\frac{1}{2} \log (2 \pi d)+\frac{1}{2}21log(2πd)+21,其随着 aaa 的变化表现为 S∝−12logaS \propto-\frac{1}{2} \log aS∝−21loga。这与玻尔兹曼熵方程 S=kblogWS=k_{b} \log WS=kblogW 类似,其中 kbk_{b}kb 是玻尔兹曼常数,而 WWW 是微观状态的数量(类似于 σ\sigmaσ)。玻尔兹曼熵方程是热力学第三定律的基础。
5.3 实验
LLM实验 我们想确定在LLM训练中熵陷阱现象发生的程度。技术上,对于大型模型,熵力很难计算:按定义,熵力是三阶导数,因为它们是锐度(二阶导数)的梯度。然而,我们可以通过损失曲线与学习率总和的对齐来探测熵力的存在。在梯度流极限 (η→0)(\eta \rightarrow 0)(η→0) 下,慢动态仅由学习率总和控制 [12],即我们应期望以下两种调度给出相同的最终状态和损失:(i) 学习率为 η\etaη,共 AAA 步;(ii) 学习率为 2η2 \eta2η,共 A/2A / 2A/2 步。然而,对于有限的 η\etaη,由于熵力的存在,这两种调度可能不对齐,因此它们的偏差是熵力大小和方向的指标。由于 ℓs\ell_{s}ℓs 不可直接测量,我们可以尝试控制 ℓf\ell_{f}ℓf 相同(根据第4节要求 ηmin\eta_{\min }ηmin 相同),并测量 ℓ\ellℓ 作为 ℓs\ell_{s}ℓs 的代理。
我们测试了一系列具有不同稳定学习率 η=0.0003,0.0006,0.0012\eta=0.0003,0.0006,0.0012η=0.0003,0.0006,0.0012 的调度(图4左)。稳定阶段可能持续 1000i1000 i1000i 步 (i=0,1,2,3,4,5)(i=0,1,2,3,4,5)(i=0,1,2,3,4,5),衰减阶段持续3k步,余弦过渡到最终学习率 ηmin=0.00064\eta_{\min }=0.0006^{4}ηmin=0.00064。对于每个 η\etaη,我们根据稳定阶段的持续时间变化绘制其验证损失与 η\etaη 总和的关系。图4(b) 显示不同 η\etaη 的曲线合理地相互对齐,尽管较小的 η\etaη 在相同 η\etaη 总和下似乎产生略低的损失,类似于[12]中的观察结果。这一结果表明LLM平均具有略微变窄的山谷结构(相应地,熵力略微为负)。然而,由于计算资源限制,我们的训练处于早期阶段。有趣的是研究当进行更多训练步骤时,熵力是否代表了LLM训练的更显著限制(此时山谷可能变得更陡峭,熵力更大)。
6 发现总结
学习率的作用 我们了解到学习率 η\etaη 在控制训练动态中有三个作用。(1) 高斯宽度:η\etaη 起到温度的作用,控制快速方向上的高斯宽度。(2) 熵力大小:高斯宽度结合山谷锐度共同控制熵力。(3) 时间尺度:控制步长。
4{ }^{4}4 尽管 ηmin\eta_{\min }ηmin 带有“min”下标,它不一定表示最后阶段的最小学习率。最后阶段可以是衰减 (η=0.0012)(\eta=0.0012)(η=0.0012)、稳定 (η=0.0006)(\eta=0.0006)(η=0.0006) 或增长 (η=0.0003)(\eta=0.0003)(η=0.0003)。关键是所有调度都有相同的最终学习率,记为 ηmin\eta_{\min }ηmin。
什么决定了最终损失?总之,我们的结果表明最终损失主要取决于学习率总和 DDD(控制 ℓs\ell_{s}ℓs,见第5节)和 ηmin\eta_{\min }ηmin(控制 ℓf\ell_{f}ℓf,见第3节),但也有由于熵力 Δentropic \Delta_{\text {entropic }}Δentropic (见第5节)和由于退火不足 Δanneal \Delta_{\text {anneal }}Δanneal (见第4节)引起的小修正项。
ℓfinal =ℓ(D,ηmin)+Δentropic +Δanneal . \ell_{\text {final }}=\ell\left(D, \eta_{\min }\right)+\Delta_{\text {entropic }}+\Delta_{\text {anneal }} . ℓfinal =ℓ(D,ηmin)+Δentropic +Δanneal .
实际上,对于GPT2的早期训练阶段,我们发现 Δentropic ∼0\Delta_{\text {entropic }} \sim 0Δentropic ∼0 大致成立,并且当退火阶段不小于3k步时 Δanneal ∼0\Delta_{\text {anneal }} \sim 0Δanneal ∼0。如果我们假设 Δentropic \Delta_{\text {entropic }}Δentropic 和 Δanneal \Delta_{\text {anneal }}Δanneal 可以忽略,唯一减少损失的方法是减少 ℓ(D,ηmin)\ell\left(D, \eta_{\min }\right)ℓ(D,ηmin),这涉及减少 ηmin\eta_{\min }ηmin 和/或增加 DDD。通过在稳定阶段使用更大的步长可以增加 DDD,这一点已在附录G的实验中得到验证。
7 相关工作
优化的物理机制 有限步长的随机梯度下降的动力学与梯度流不同。有限学习率 η\etaη 可以诱导隐式正则化 n2∥∇ℓ∥2\frac{n}{2}\|\nabla \ell\|^{2}2n∥∇ℓ∥2 [14],并且随机梯度也具有各种隐式偏差 [15, 16, 17],引导优化趋向更平坦的极小值 [18, 9],大特征方向 [19],最大化边缘 [20, 21],以及冗余神经元/方向 [16, 22]。除了这些相当普遍的现象外,还进行了大量研究以理解神经网络的损失景观,特别是在过参数化的情况下。研究表明,大型模型表现出模式连通性 [23, 24],这也与最近发现的LLM的河谷景观相关 [5, 7]。
LLM的学习率调度多种多样:余弦衰减 [25]、循环 [26]、Noam [27] 和权重稳定衰减(WSD)[8]。近期的研究已经开始展示WSD调度的优势 [5,12,10] 并关注设计更好的衰减调度,例如在 [10] 中提出的1-sqrt调度和在 [12] 中的优化调度。我们的分析提供了使用WSD调度的另一个理论依据,并解析推导出一个最优衰减调度,其衰减形式为 1/t1 / t1/t(在各向同性假设下)。
热力学与学习 尽管我们是第一个建立热力学与LLM训练动力学之间映射关系的人,但热力学长期以来一直启发并与机器学习有关联:将优化视为热力学过程 [1],学习的统计力学 [4],信息瓶颈 [28],熵梯度下降 [29],玻尔兹曼机 [30],霍普菲尔德网络 [31],扩散模型 [32, 33, 34],网络的热力学解释 [2]。
8 结论
我们提出了一个河谷损失景观的玩具模型,并分析了在SGD和SignGD下的训练动力学。快慢分离使我们能够独立处理山谷和河流方向,从而得出易于解析的结果:快速动态的热平衡和退火,以及慢速动态的漂移。这些解析解在定性和某些情况下定量上与经典热力学概念和定律相似。关键在于,这些结果与大规模语言模型(LLM)训练密切相关,因为近期研究表明LLM损失景观表现出河谷结构。这种优化与热力学之间的双重性提供了一个新的视角来理解和评估现代优化器。虽然我们将留待未来工作,我们在附录F中包含了一个概念验证分析,其中我们通过我们的理论分析了最近提出的FOCUS优化器——其特征为自吸引力 [7]。
局限性。本文中的许多推导采用了物理学家的推理风格——强调直觉、简化和可处理的近似方法——这可能无法满足理论家所期望的数学严谨标准。例如,稳态的高斯近似对许多结果来说并非必要(只有方差重要)。在推导最优学习率衰减调度时,我们假设要么均匀锐度要么一维景观;我们把河流视为直线,尽管实际上可能是弯曲的;为了简单起见,我们忽略了动量和权重衰减。尽管存在这些简化,我们的分析仍然得出了关于LLM训练动力学的非平凡、可检验见解。这项工作的自然扩展包括放松这些假设、在更大规模上验证预测以及推广框架。虽然我们的重点是基于变压器的LLM,但这些受物理学启发的原则可能扩展到其他模型架构。
致谢 Z.L. 和 M.T. 由NSF资助项目PHY-2019786通过IAIFI支持。Z.L. 还得到了Google博士奖学金的支持。
参考文献
[1] Max Welling 和 Yee W Teh。通过随机梯度兰格文动力学实现贝叶斯学习。第28届国际机器学习会议(ICML-11)论文集,第681-688页。Citeseer,2011年。
[2] Shams Mehdi 和 Pratyush Tiwary。人工智能的热力学解释。《自然通讯》,15(1):7859,2024年。
[3] Andreas Engel。学习的统计力学。剑桥大学出版社,2001年。
[4] Yasaman Bahri,Jonathan Kadmon,Jeffrey Pennington,Sam S Schoenholz,Jascha Sohl-Dickstein 和 Surya Ganguli。深度学习的统计力学。《凝聚态物理年度评论》,11(1):501-528,2020年。
[5] Kaiyue Wen,Zhiyuan Li,Jason Wang,David Hall,Percy Liang 和 Tengyu Ma。理解升温-稳定-衰减学习率:从河谷损失景观视角。arXiv预印本arXiv:2410.05192,2024年。
[6] Mingwei Wei 和 David J Schwab。噪声如何影响过度参数化神经网络的黑塞谱。arXiv预印本arXiv:1910.00195,2019年。
[7] Yizhou Liu,Ziming Liu 和 Jeff Gore。FOCUS:一阶集中更新方案。arXiv预印本arXiv:2501.12243,2025年。
[8] Shengding Hu,Yuge Tu,Xu Han,Chaoqun He,Ganqu Cui,Xiang Long,Zhi Zheng,Yewei Fang,Yuxiang Huang,Weilin Zhao 等。MiniCPM:揭示小型语言模型潜力的可扩展训练策略。arXiv预印本arXiv:2404.06395,2024年。
[9] Jeremy M Cohen,Simran Kaur,Yuanzhi Li,J Zico Kolter 和 Ameet Talwalkar。神经网络上的梯度下降通常发生在稳定性边缘。arXiv预印本arXiv:2103.00065,2021年。
[10] Alex Hägele,Elie Bakouch,Atli Kosson,Leandro Von Werra,Martin Jaggi 等。超越固定训练时长的缩放规律与计算最优训练。神经信息处理系统进展,37:76232-76264,2024年。
[11] Andrej Karpathy。NanoGPT。https://github.com/karpathy/nanoGPT,2022年。
[12] Kairong Luo,Haodong Wen,Shengding Hu,Zhenbo Sun,Maosong Sun,Zhiyuan Liu,Kaifeng Lyu 和 Wenguang Chen。用于跨学习率调度预测损失曲线的多幂律。第三届国际学习表示会议论文集,2025年。
[13] Jordan Keller。modded-nanogpt。https://github.com/KellerJordan/modded-nanogpt,2024年。GitHub存储库。
[14] David GT Barrett 和 Benoit Dherin。隐式梯度正则化。arXiv预印本arXiv:2009.11162,2020年。
[15] Daniel Kunin,Javier Sagastuy-Brena,Lauren Gillespie,Eshed Margalit,Hidenori Tanaka,Surya Ganguli 和 Daniel LK Yamins。SGD的极限动态:修改后的损失、相空间振荡和异常扩散。《神经计算》,36(1):151-174,2023年。
[16] Feng Chen,Daniel Kunin,Atsushi Yamamura 和 Surya Ganguli。随机坍缩:梯度噪声如何吸引SGD动态朝向更简单的子网络。神经信息处理系统进展,36:35027-35063,2023年。
[17] Mandt Stephan,Matthew D Hoffman,David M Blei 等。随机梯度下降作为近似的贝叶斯推断。《机器学习研究杂志》,18(134):1-35,2017年。
[18] Zeke Xie,Issei Sato 和 Masashi Sugiyama。深度学习动态的扩散理论:随机梯度下降指数级偏好平坦极小值。arXiv预印本arXiv:2002.03495,2020年。
[19] Jingfeng Wu,Difan Zou,Vladimir Braverman 和 Quanquan Gu。方向很重要:中等学习率下的随机梯度下降的隐式偏差。arXiv预印本arXiv:2011.02538,2020年。
[20] Kaifeng Lyu 和 Jian Li。梯度下降最大化同质神经网络的边界。arXiv预印本arXiv:1906.05890,2019年。
[21] Bohan Wang,Qi Meng,Wei Chen 和 Tie-Yan Liu。同质神经网络的自适应优化算法的隐式偏差。《国际机器学习会议论文集》,第10849-10858页。PMLR,2021年。
[22] Zhi-Qin John Xu,Yaoyu Zhang 和 Zhangchen Zhou。深度学习中冷凝现象综述。arXiv预印本arXiv:2504.09484,2025年。
[23] Timur Garipov,Pavel Izmailov,Dmitrii Podoprikhin,Dmitry P Vetrov 和 Andrew G Wilson。损失面、模式连通性和DNNs的快速集成。神经信息处理系统进展,31,2018年。
[24] Jonathan Frankle,Gintare Karolina Dziugaite,Daniel Roy 和 Michael Carbin。线性模式连通性与彩票假设。《国际机器学习会议论文集》,第3259-3269页。PMLR,2020年。
[25] Ilya Loshchilov 和 Frank Hutter。SGDR:带温重启的随机梯度下降。arXiv预印本arXiv:1608.03983,2016年。
[26] Leslie N Smith。训练神经网络的循环学习率。2017年IEEE计算机视觉应用冬季会议(WACV)论文集,第464-472页。IEEE,2017年。
[27] Ashish Vaswani,Noam Shazeer,Niki Parmar,Jakob Uszkoreit,Llion Jones,Aidan N Gomez,Łukasz Kaiser 和 Illia Polosukhin。注意力就是你所需要的。神经信息处理系统进展,30,2017年。
[28] Naftali Tishby,Fernando C Pereira 和 William Bialek。信息瓶颈方法。arXiv预印本physics/0004057,2000年。
[29] Pratik Chaudhari,Anna Choromanska,Stefano Soatto,Yann LeCun,Carlo Baldassi,Christian Borgs,Jennifer Chayes,Levent Sagun 和 Riccardo Zecchina。熵-SGD:将梯度下降偏向宽谷。《统计力学期刊:理论与实验》,2019(12):124018,2019年。
[30] David H Ackley,Geoffrey E Hinton 和 Terrence J Sejnowski。玻尔兹曼机的学习算法。《认知科学》,9(1):147-169,1985年。
[31] Hubert Ramsauer,Bernhard Schäfl,Johannes Lehner,Philipp Seidl,Michael Widrich,Thomas Adler,Lukas Gruber,Markus Holzleitner,Milena Pavlović,Geir Kjetil Sandve 等。Hopfield网络是你所需要的。arXiv预印本arXiv:2008.02217,2020年。
[32] Jascha Sohl-Dickstein,Eric Weiss,Niru Maheswaranathan 和 Surya Ganguli。利用非平衡热力学进行深度无监督学习。《国际机器学习会议论文集》,第2256-2265页。pmlr,2015年。
[33] Yang Song,Jascha Sohl-Dickstein,Diederik P Kingma,Abhishek Kumar,Stefano Ermon 和 Ben Poole。通过随机微分方程的分数生成建模。arXiv预印本arXiv:2011.13456,2020年。
[34] Jonathan Ho,Ajay Jain 和 Pieter Abbeel。去噪扩散概率模型。神经信息处理系统进展,33:6840-6851,2020年。
附录
A SGD收敛到高斯稳态分布
假设初始点为 x0x_{0}x0 在 t=0t=0t=0。分布是一个delta函数,实际上是一个均值为 μ0=x0\mu_{0}=x_{0}μ0=x0 且 σ0=0\sigma_{0}=0σ0=0 的高斯分布。由于方程(1)的线性性,第ttt步的高斯分布在第t+1t+1t+1步演变成一个新的高斯分布,尽管均值 μt\mu_{t}μt 和标准差 σt\sigma_{t}σt 不同。它们的递归关系为 (t=1,2,3,⋯ )(t=1,2,3, \cdots)(t=1,2,3,⋯)
μt=(1−ηa)μt−1σt2=(1−ηa)2σt−12+η2σg2 \begin{aligned} \mu_{t} & =(1-\eta a) \mu_{t-1} \\ \sigma_{t}^{2} & =(1-\eta a)^{2} \sigma_{t-1}^{2}+\eta^{2} \sigma_{g}^{2} \end{aligned} μtσt2=(1−ηa)μt−1=(1−ηa)2σt−12+η2σg2
其解为
μt=(1−ηa)tx0σt2=(1−(1−ηa)2t)σ2,σ≡σga(2η−a) \begin{aligned} \mu_{t} & =(1-\eta a)^{t} x_{0} \\ \sigma_{t}^{2} & =\left(1-(1-\eta a)^{2 t}\right) \sigma^{2}, \quad \sigma \equiv \frac{\sigma_{g}}{\sqrt{a\left(\frac{2}{\eta}-a\right)}} \end{aligned} μtσt2=(1−ηa)tx0=(1−(1−ηa)2t)σ2,σ≡a(η2−a)σg
其中 σ\sigmaσ 是稳态标准差。无论 x0x_{0}x0 为何值,当 t→∞t \rightarrow \inftyt→∞ 时,μt→0\mu_{t} \rightarrow 0μt→0 且 σt→σ\sigma_{t} \rightarrow \sigmaσt→σ。收敛的时间尺度为 tc=−1/log(1−ηa)t_{c}=-1 / \log (1-\eta a)tc=−1/log(1−ηa)。在平坦极限 aη≪1,tc≈1/(aη)a \eta \ll 1, t_{c} \approx 1 /(a \eta)aη≪1,tc≈1/(aη)。
B SGD推导
B. 1 固定学习率
假设一维损失函数 l(x)=12ax2l(x)=\frac{1}{2} a x^{2}l(x)=21ax2 其中 aaa 是二次函数的二阶导数。具有学习率 η\etaη 和梯度噪声 σg\sigma_{g}σg 的SGD优化器遵循以下动态:
xt+1=xt−η(axt+σgW˙t) x_{t+1}=x_{t}-\eta\left(a x_{t}+\sigma_{g} \dot{W}_{t}\right) xt+1=xt−η(axt+σgW˙t)
平衡分布是高斯分布 p(x)=12πσe−x22σ2p(x)=\frac{1}{\sqrt{2 \pi} \sigma} e^{-\frac{x^{2}}{2 \sigma^{2}}}p(x)=2πσ1e−2σ2x2。在平衡状态下,我们应该有 Var(xt+1)=Var(xt)\operatorname{Var}\left(x_{t+1}\right)=\operatorname{Var}\left(x_{t}\right)Var(xt+1)=Var(xt),即,
σ2=(1−ηa)2σ2+σg2 \sigma^{2}=(1-\eta a)^{2} \sigma^{2}+\sigma_{g}^{2} σ2=(1−ηa)2σ2+σg2
这给出
σ=σga(2η−a) \sigma=\frac{\sigma_{g}}{\sqrt{a\left(\frac{2}{\eta}-a\right)}} σ=a(η2−a)σg
该公式仅在 0<a<2η0<a<\frac{2}{\eta}0<a<η2 时有效。当 a→0a \rightarrow 0a→0(即平坦)时,有限的 σg\sigma_{g}σg 可以导致无限的 σ\sigmaσ(即稳态分布不存在)。当 a→2ηa \rightarrow \frac{2}{\eta}a→η2 时,学习率达到所谓的“稳定性边缘”。特别是当 η>2a\eta>\frac{2}{a}η>a2 时,当 σg→0\sigma_{g} \rightarrow 0σg→0 时,{xt}\left\{x_{t}\right\}{xt} 序列发散。
方程11在图5中进行了实证测试。方程(11)的一个有些意外的特点是,当 a→0a \rightarrow 0a→0 时,σ→∞\sigma \rightarrow \inftyσ→∞,尽管我们之前认为平坦方向是好的,尖锐方向是坏的。方程(11)表明平坦方向与尖锐方向一样坏。
能量均分定理 原始的能量均分思想(在经典统计力学中)是,在热平衡状态下,能量在所有自由度之间平等共享。具体来说,每个自由度都会对能量贡献 12kBT\frac{1}{2} k_{B} T21kBT(kBk_{B}kB:玻尔兹曼常数,TTT:温度),而不考虑底层细节。我们证明了由梯度噪声引起的损失也(大约)独立于锐度 a:⟨l⟩=12a⟨x2⟩=12aσ2a:\langle l\rangle=\frac{1}{2} a\left\langle x^{2}\right\rangle=\frac{1}{2} a \sigma^{2}a:⟨l⟩=21a⟨x2⟩=21aσ2。当 aη≪2,σ≈12aσgηa \eta \ll 2, \sigma \approx \frac{1}{\sqrt{2 a}} \sigma_{g} \sqrt{\eta}aη≪2,σ≈2a1σgη。所以 ⟨l⟩=12aσ2≈12a(12aσgη)2=14σg2η\langle l\rangle=\frac{1}{2} a \sigma^{2} \approx \frac{1}{2} a\left(\frac{1}{\sqrt{2 a}} \sigma_{g} \sqrt{\eta}\right)^{2}=\frac{1}{4} \sigma_{g}^{2} \eta⟨l⟩=21aσ2≈21a(2a1σgη)2=41σg2η。忽略常数,有效温度为 Teff ∝σg2ηT_{\text {eff }} \propto \sigma_{g}^{2} \etaTeff ∝σg2η。梯度噪声随批量大小 BBB 按 σg∝1B\sigma_{g} \propto \frac{1}{\sqrt{B}}σg∝B1 变化。为了降低温度,我们可以增加批量大小或降低学习率。这有一个有趣的含义:在神经网络的训练过程中,可能存在许多这样的平衡方向。无论这些方向有多尖锐,它们对总损失的贡献都相等。假设有 NNN 个这样的方向,由梯度噪声引起的总损失为 lg=N⟨l⟩=14Nσg2ηl_{g}=N\langle l\rangle=\frac{1}{4} N \sigma_{g}^{2} \etalg=N⟨l⟩=41Nσg2η。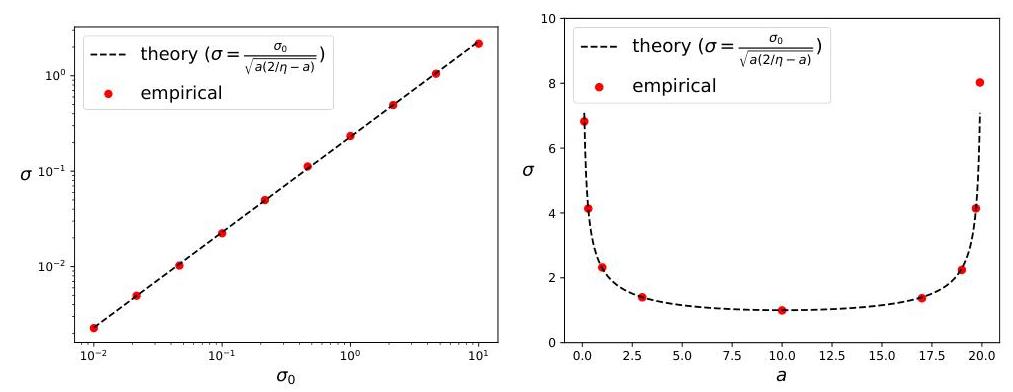
图5:σ\sigmaσ 对梯度噪声 σg\sigma_{g}σg 和锐度 aaa 的依赖关系。
B. 2 学习率衰减
现在我们考虑一个学习率调度,即序列 {ηt}t=0T\left\{\eta_{t}\right\}_{t=0}^{T}{ηt}t=0T。方程(1)现在变为:
xt+1=xt−ηt(axt+σgW˙t) x_{t+1}=x_{t}-\eta_{t}\left(a x_{t}+\sigma_{g} \dot{W}_{t}\right) xt+1=xt−ηt(axt+σgW˙t)
由于该方程是线性的,如果 p(x0)p\left(x_{0}\right)p(x0) 开始时是一个高斯分布,那么 p(xt)p\left(x_{t}\right)p(xt) 将始终保持为高斯分布(具有随时间变化的高斯宽度,记为 σt\sigma_{t}σt )永远如此。假设在 t=0t=0t=0 时,p(x0)p\left(x_{0}\right)p(x0) 已经处于热平衡状态,其高斯宽度由方程(11)给出,即初始条件为 σ0=σ\sigma_{0}=\sigmaσ0=σ。高斯宽度 σt\sigma_{t}σt 遵循以下递归关系:
σt+12=(1−ηta)2σt2+(ηtσg)2=(a2σt2+σg2)ηt2−2aσt2ηt+σt2 \sigma_{t+1}^{2}=\left(1-\eta_{t} a\right)^{2} \sigma_{t}^{2}+\left(\eta_{t} \sigma_{g}\right)^{2}=\left(a^{2} \sigma_{t}^{2}+\sigma_{g}^{2}\right) \eta_{t}^{2}-2 a \sigma_{t}^{2} \eta_{t}+\sigma_{t}^{2} σt+12=(1−ηta)2σt2+(ηtσg)2=(a2σt2+σg2)ηt2−2aσt2ηt+σt2
这是一个关于 ηt\eta_{t}ηt 的二次函数。我们希望选择 ηt\eta_{t}ηt 使得 σt+1\sigma_{t+1}σt+1 最小化:
ηt=aσt2a2σt2+σg2,σt+12=σg2σt2σg2+a2σt2 \eta_{t}=\frac{a \sigma_{t}^{2}}{a^{2} \sigma_{t}^{2}+\sigma_{g}^{2}}, \quad \sigma_{t+1}^{2}=\frac{\sigma_{g}^{2} \sigma_{t}^{2}}{\sigma_{g}^{2}+a^{2} \sigma_{t}^{2}} ηt=a2σt2+σg2aσt2,σt+12=σg2+a2σt2σg2σt2
参考论文:https://arxiv.org/pdf/2505.10559

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 17
17 0
0- 0



 已为社区贡献285条内容
已为社区贡献285条内容

所有评论(0)