学AI的工具箱怎么用?实战篇来了!
项目通过全面特征工程和三模型集成,在二手车价格预测中实现了较高准确率,验证了集成学习的优势。完整代码和资料已开源,可供实践参考。
集成学习:
• 将多个弱分类器按照某种方式组合起来,形成一个强分类器(三个臭裨将赛过诸葛亮)
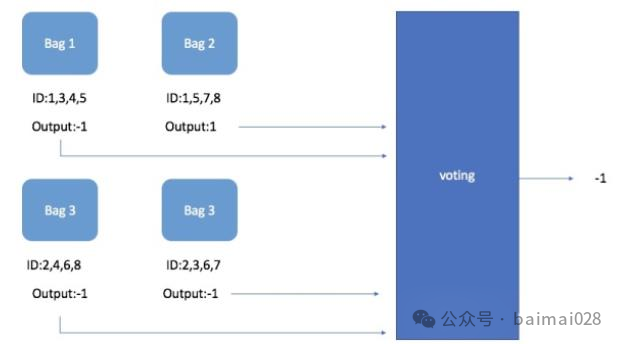
• Bagging,把数据集通过有放回的抽样方式,划分为多个数据集,分别训练多个模型。针对分类问题,按照少数服从多数原则进行投票,针对回归问题,求多个测试结果的平均值
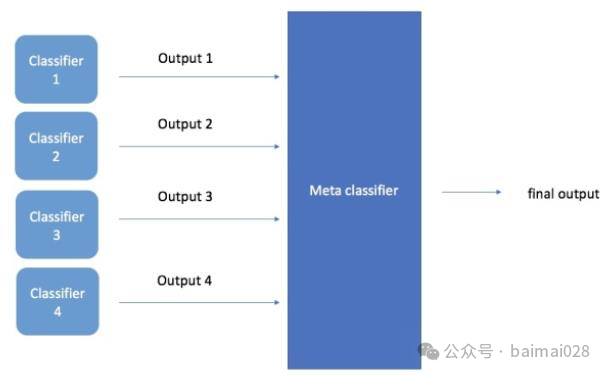
• Stacking,通常是不同的模型,而且每个分类都用了全部训练数据,得到预测结果y1, y2, ..., yk,然后再训练一个分类器 Meta Classifier,将这些预测结果作为输入,得到最终的预测结果
• Boosting,与Bagging一样,使用的相同的弱学习器,不过是以自适应的方法顺序地学习这些弱学习器,即每个新学习器都依赖于前面的模型,并按照某种确定性的策略将它们组合起来
• 两个重要的 Boosting 算法:AdaBoost(自适应提升)和Gradient Boosting(梯度提升)
• AdaBoost,使用前面的学习器用简单的模型去适配数据,然后分析错误。然后会给予错误预测的数据更高权重,然后用后面的学习器去修复
• Boosting通过把一些列的弱学习器串起来,组成一个强学习器
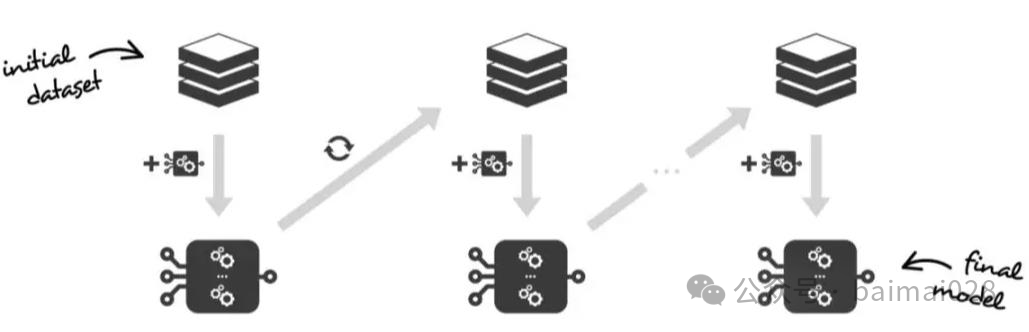
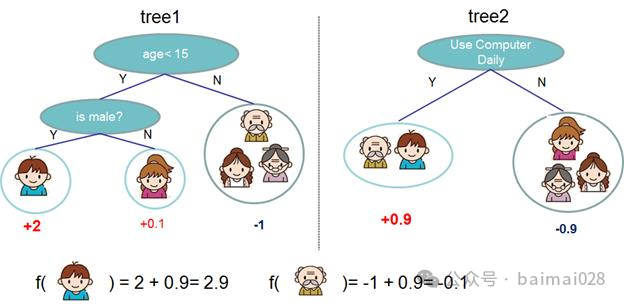
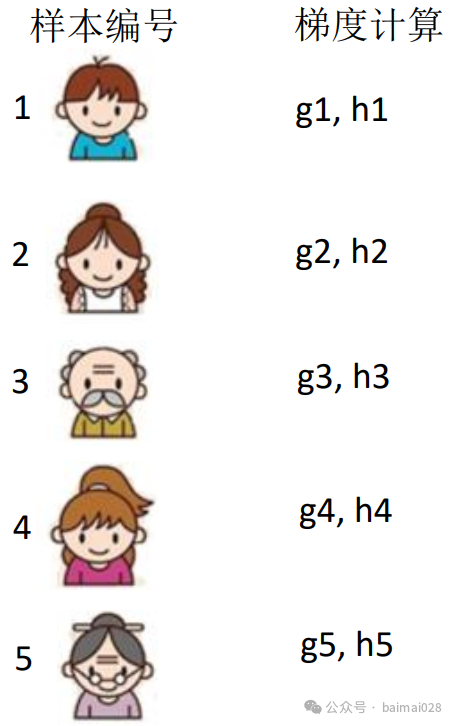
集成学习:训练弱学习器,并添加到集成模型中
更新:基于当前的集成学习结果,更新训练集(值 或权重)
Boosting与Bagging:
• 结构上,Bagging是基分类器并行处理,而Boosting是串行处理
• 训练集,Bagging的基分类器训练是独立的,而Boosting的训练集是依赖于之前的模型
• 作用,Bagging的作用是减少variance(方差),而Boosting在于减少bias(偏差)
对于Bagging,对样本进行重采样,通过重采样得到的子样本集训练模型,最后取平均。因为子样本集的相似性,而且使用相同的弱学习器,因此每个学习器有近似相等的bias和variance,因为每个学习器相互独立,所以可以显著降低variance,但是无法降低bias
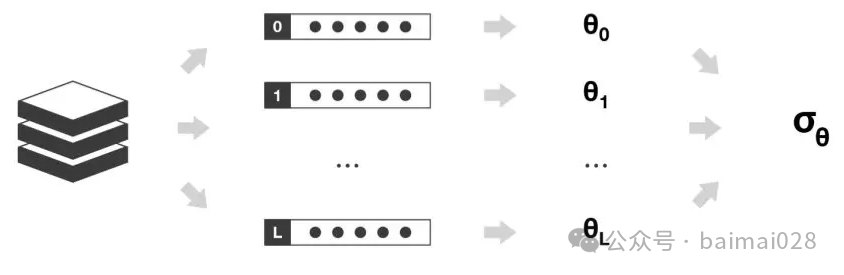
对于Boosting,采用顺序的方式最小化损失函数,所以bias自然是逐步下降,子模型之和不能显著降低variance
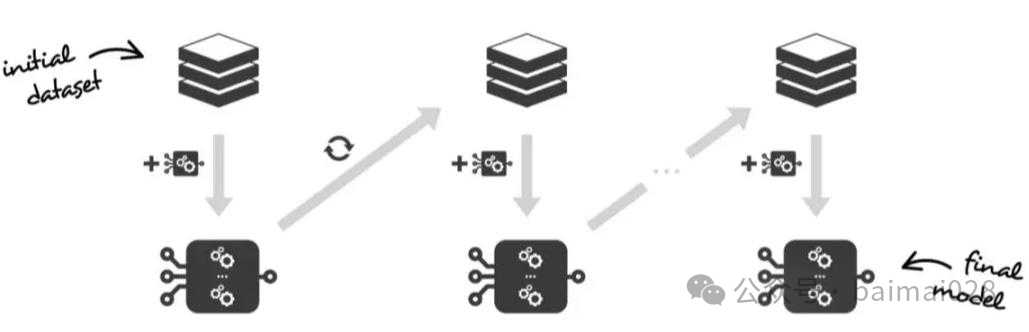
Gradient Boosting集成学习:
• XGBoost, LightGBM, CatBoost, NGBoost实际上是对GBDT(Gradient Boost Decisioning Tree)方法的不同实现,针对同一目标、做了不同的优化处理


XGBoost:
https://arxiv.org/abs/1603.02754
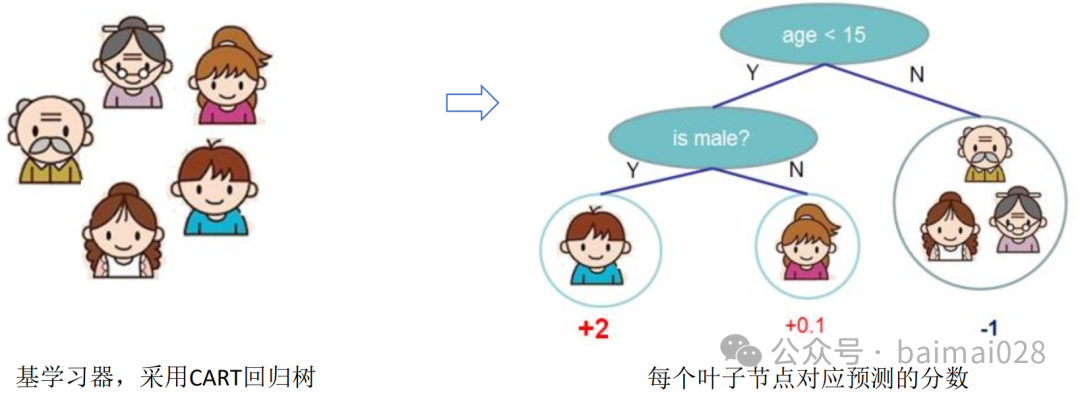
• 对于一个问题,INPUT X: age, gender, occupation, ....
Target y: How does the person like computer games?
• 目标函数=损失函数 + 正则化项
Obj(Θ) = L(Θ)+ Ω(Θ)
L(Θ)是损失函数:拟合数据
Ω(Θ)是正则化项:惩罚复杂模型
• 误差函数尽量拟合训练数据,正则化项鼓励简单的模型
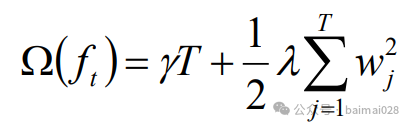
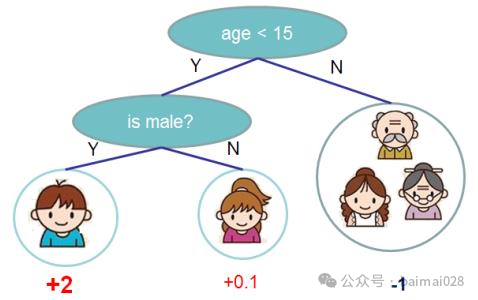
Ω(ƒt)用于控制树的复杂度,防止过拟合,使得模型更简化, 也使得最终的模型的预测结果更稳定
T:叶子数量
wj:叶子分数的L2正则项
γ :加入新叶子节点引入的复杂度代价
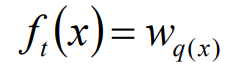
w 代表叶子向量, q表示树的结构
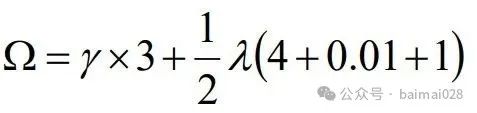
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

Tree Ensemble 集成学习 :
• 单个CART回归树过于简单,可以通过多个CART回归树组成一个强学习器
• 预测函数,样本的预测结果=每棵树预测分数之和
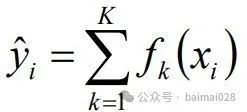
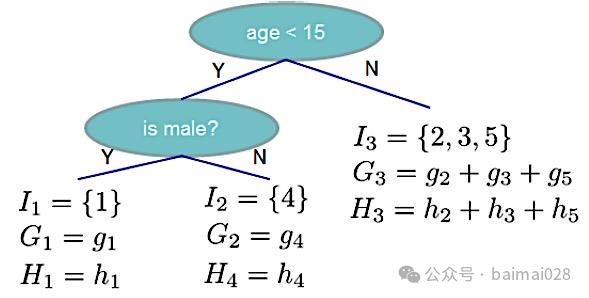
• 目标函数优化
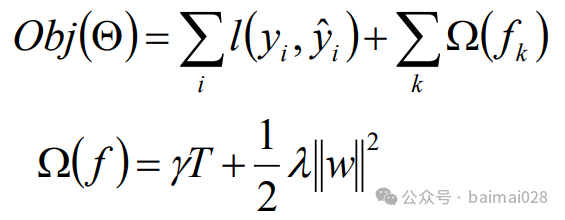
正则项是由叶子结点的数量和叶子结点权重的 平方和决定
XGBoost 的目标函数:


XGBoost 的目标函数:
• Obj 目标函数也称为结构分数(打分函数),代表当指定一个树的结构的时候,我们在目标上最多可以减少多少
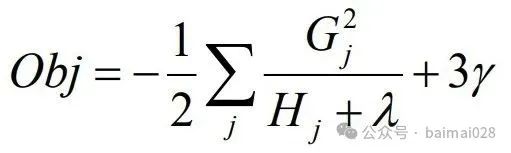
分数越小,代表树的结构越好
XGBoost的目标函数:
• 求Obj分数最小的树结构,可以穷举所有可能,但计算量太大
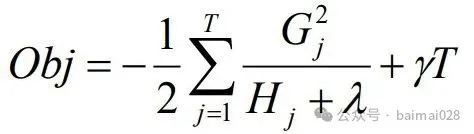
• 使用贪心法,即利用打分函数(计算增益)
以Gain作为是否分割的条件,Gain看作是未分割前的Obj减去分割后的左右Obj,

如果Gain<0,则此叶节点不做分割,分割方案个数很多,计算量依然很大
XGBoost的分裂节点算法:
• 贪心方法,获取最优分割节点(split point)将所有样本按照gi从小到大排序,通过遍历,查看每个节点是否需要分割
• 对于特征值的个数为n时,总共有n−1种划分
• Step1,对样本扫描一遍,得出GL,GR
• Step2,根据Gain的分数进行分割
• 通过贪心法,计算效率得到大幅提升,XGBoost重新定义划分属性,即Gain,而Gain的计算是由目标损失函数obj决定的
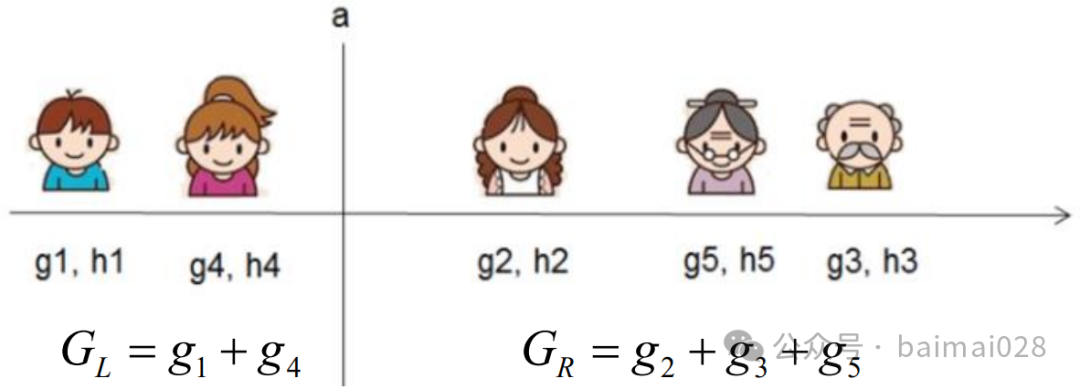

XGBoost的分裂节点算法(近似算法,Histogram 2016 paper):
• 对于连续型特征值,样本数量非常大,该特征取值过多时,遍历所有取值会花费很多时间,且容易过拟合
• 方法,在寻找split节点的时候,不会枚举所有的特征值,而会对特征值进行聚合统计,然后形成若干个bucket(桶),只将bucket边界上的特征值作为split节点的候选,从而获得性能提升
• 从算法伪代码中该流程还可以分为两种,全局的近似是在新生成一棵树之前就对各个特征计算分位点并划分样本,之后在每次分裂过程中都采用近似划分,而局部近似就是在具体的某一次分裂节点的过程中采用近似算法

XGBoost算法特点:
• XGBoost将树模型的复杂度加入到正则项中,从而避免过拟合,泛化性能好
• 损失函数是用泰勒展开式展开的,用到了一阶导和二阶导,可以加快优化速度
• 在寻找最佳分割点时,采用近似贪心算法,用来加速计算
• 不仅支持CART作为基分类器,还支持线性分类器,在使用线性分类器的时候可以使用L1,L2正则化
• 支持并行计算,XGBoost的并行是基于特征计算的并行,将特征列排序后以block的形式存储在内存中,在后面的迭代中重复使用这个结构。在进行节点分裂时,计算每个特征的增益,选择增益最大的特征作为分割节点,各个特征的增益计算可以使用多线程并行
• 优点:速度快、效果好、能处理大规模数据、支持自定义损失函数等
• 缺点:算法参数过多,调参复杂,不适合处理超高维特征数据
XGBoost工具:
• https://github.com/dmlc/xgboost
参数分为:
• 通用参数:对系统进行控制
• Booster参数:控制每一步的booster(tree/regression)
• 学习目标参数:控制训练目标的表现
通用参数:
• booster,模型选择,gbtree或者gblinear。gbtree使用基于树的模型进行提升计算,gblinear使用线性模型进行提升计算。[default=gbtree]
• silent,缄默方式,0表示打印运行时,1表示以缄默方式运行,不打印运行时信息。[default=0]
• nthread,XGBoost运行时的线程数,[default=缺省值是当前系统可以获得的最大线程数]
• num_feature,boosting过程中用到的特征个数,XGBoost会自动设置
Booster参数:
• eta [default=0.3],为了防止过拟合,更新过程中用到的收缩步长。在每次提升计算之后,算法会直接获得新特征的权重。 eta通过缩减特征的权重使提升计算过程更加保守,取值范围为[0,1]
• gamma [default=0],分裂节点时,损失函数减小值只有大于等于gamma节点才分裂,gamma值越大,算法越保守,越不容易过拟合,但性能就不一定能保证,需要trade off,取值范围 [0,∞]
• max_depth [default=6] ,树的最大深度,取值范围为[1,∞],典型值为3-10
• min_child_weight [default=1],一个子集的所有观察值的最小权重和。如果新分裂的节点的样本权重和小于min_child_weight则停止分裂 。这个可以用来减少过拟合,但是也不能太高,会导致欠拟合,取值范围为[0,∞]
• subsample [default=1],构建每棵树对样本的采样率,如果设置成0.5,XGBoost会随机选择50%的样本作为训练集
• colsample_bytree [default=1],列采样率,也就是特征采样率
• lambda [default=1, alias: reg_lambda],L2正则化,用来控制XGBoost的正则化部分
• alpha [default=0, alias: reg_alpha],L1正则化,增加该值会让模型更加收敛
• scale_pos_weight [default=1],在类别高度不平衡的情况下,将参数设置大于0,可以加快收敛
学习目标参数:
• objective [ default=reg:linear ],定义学习目标,reg:linear,reg:logistic,binary:logistic,binary:logitraw,count:poisson,multi:softmax,multi:softprob,rank:pairwise
• eval_metric,评价指标,包括rmse,logloss,error,merror,mlogloss,auc,ndcg,map等
• seed[ default=0 ],随机数的种子
• dtrain,训练的数据
• num_boost_round,提升迭代的次数,也就是生成多少基模型
• early_stopping_rounds,早停法迭代次数
• evals:这是一个列表,用于对训练过程中进行评估列表中的元素。形式是evals = [(dtrain,'train'),(dval,'val')]或者是evals = [(dtrain,'train')],对于第一种情况,它使得我们可以在训练过程中观察验证集的效果
• verbose_eval ,如果为True,则对evals中元素的评估输出在结果中;如果输入数字,比如5,则每隔5个迭代输出一次
• learning_rates:每一次提升的学习率的列表
X_train, X_valid, y_train, y_valid = train_test_split(train_X, train_y, test_size=.2)# 使用XGBoostmodel = xgb.XGBClassifier(max_depth=8, #树的最大深度n_estimators=1000, #提升迭代的次数,也就是生成多少基模型min_child_weight=300, #一个子集的所有观察值的最小权重和colsample_bytree=0.8, #列采样率,也就是特征采样率subsample=0.8, #构建每棵树对样本的采样率eta=0.3, # eta通过缩减特征的权重使提升计算过程更加保守,防止过拟合seed=42 #随机数种子)
model.fit(X_train, y_train,eval_metric='auc', eval_set=[(X_train, y_train), (X_valid, y_valid)],verbose=True,#早停法,如果auc在10epoch没有进步就stopearly_stopping_rounds=10)model.fit(X_train, y_train)prob = model.predict_proba(test_data)
param = {'boosting_type':'gbdt','objective' : 'binary:logistic', #任务目标'eval_metric' : 'auc', #评估指标'eta' : 0.01, #学习率'max_depth' : 15, #树最大深度'colsample_bytree':0.8, #设置在每次迭代中使用特征的比例'subsample': 0.9, #样本采样比例'subsample_freq': 8, #bagging的次数'alpha': 0.6, #L1正则'lambda': 0, #L2正则}
X_train, X_valid, y_train, y_valid = train_test_split(train.drop('Attrition',axis=1), train['Attrition'],test_size=0.2, random_state=42)train_data = xgb.DMatrix(X_train, label=y_train)valid_data = xgb.DMatrix(X_valid, label=y_valid)test_data = xgb.DMatrix(test)model = xgb.train(param, train_data, evals=[(train_data, 'train'), (valid_data, 'valid')],num_boost_round = 10000, early_stopping_rounds=200, verbose_eval=25)predict = model.predict(test_data)test['Attrition']=predict# 转化为二分类输出test['Attrition']=test['Attrition'].map(lambda x:1 if x>=0.5 else 0)test[['Attrition']].to_csv('submit_lgb.csv')

LightGBM:
• 2017年经微软推出,XGBoost的升级版
• Kaggle竞赛使用最多的模型之一,必备机器学习神器
• Light => 在大规模数据集上运行效率更高
• GBM => Gradient Boosting Machine
Motivation:
• 常用的机器学习算法,例如神经网络等算法,都可以以mini-batch的方式训练,训练数据的大小不会受到内存限制
• GBDT在每一次迭代的时候,都需要遍历整个训练数据多次。如果把整个训练数据装进内存则会限制训练数据的大小;如果不装进内存,反复地读写训练数据又会消耗非常大的时间。对于工业级海量的数据,普通的GBDT算法是不能满足其需求的
• LightGBM的提出是为了解决GBDT在海量数据遇到的问题,让GBDT可以更好更快地用于工业场景
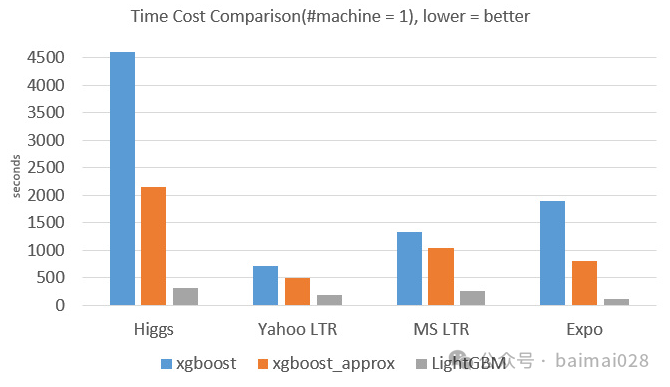
LightGBM与XGBoost:
• 模型精度:两个模型相当
• 训练速度:LightGBM训练速度更快 => 1/10
• 内存消耗:LightGBM占用内存更小 => 1/6
• 特征缺失值:两个模型都可以自动处理特征缺失值
• 分类特征:XGBoost不支持类别特征,需要对其进行OneHot编码,而LightGBM支持分类特征
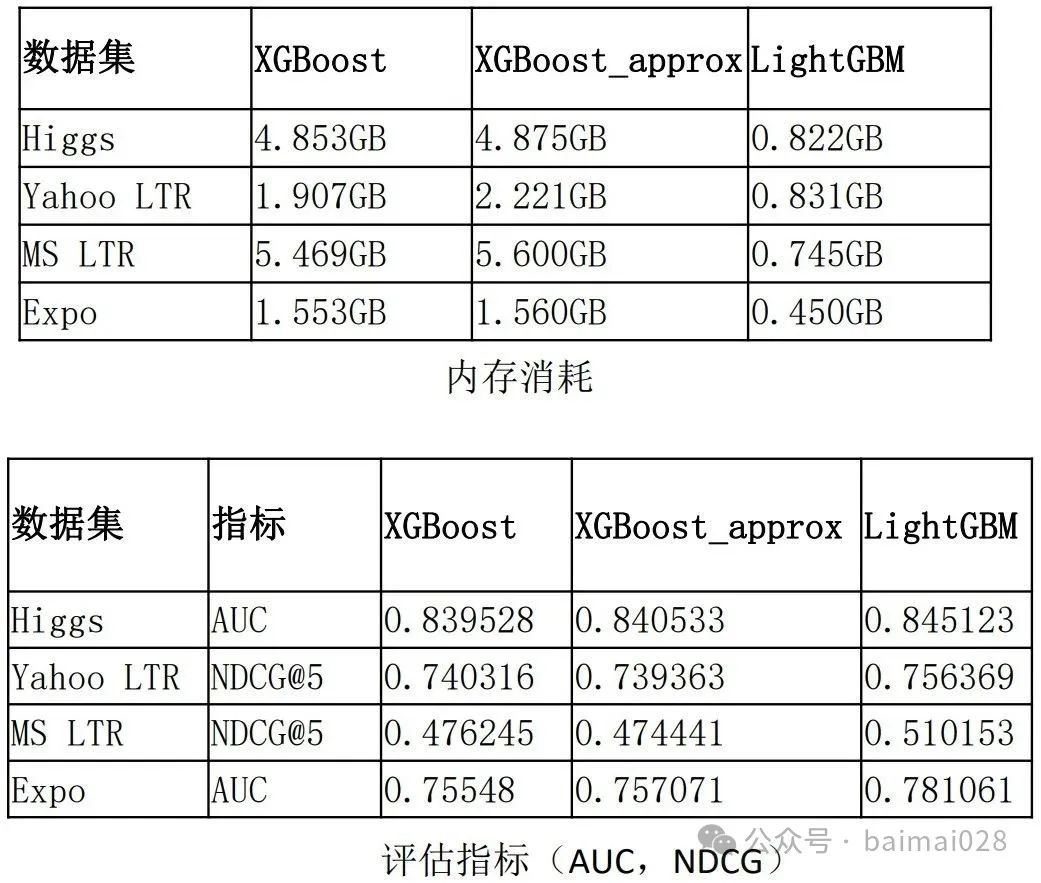
XGBoost模型的复杂度:
• 模型复杂度 = 树的棵数 X 每棵树的叶子数量 X 每片叶子生成复杂度
• 每片叶子生成复杂度 = 特征数量 X 候选分裂点数量 X 样本的数量
针对XGBoost的优化:
• Histogram算法,直方图算法 => 减少候选分裂点数量
• GOSS算法,基于梯度的单边采样算法 => 减少样本的数量
• EFB算法,互斥特征捆绑算法 => 减少特征的数量
• LightGBM = XGBoost + Histogram + GOSS + EFB
XGBoost的预排序(pre-sorted)算法:
• 将样本按照特征取值排序,然后从全部特征取值中找到最优的分裂点位
• 预排序算法的候选分裂点数量=样本特征不同取值个数减1

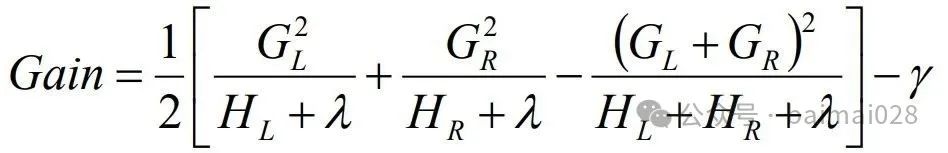
LightGBM的Histogram算法:
• 替代XGBoost的预排序算法
• 思想是先连续的浮点特征值离散化成k个整数,同时构造一个宽度为k的直方图,即将连续特征值离散化到k个bins上(比如k=255)
• 当遍历一次数据后,直方图累积了需要的统计量,然后根据直方图的离散值,遍历寻找最优的分割点
• XGBoost需要遍历所有离散化的值,LightGBM只要遍历k个直方图的值
• 候选分裂点数量 = k-1
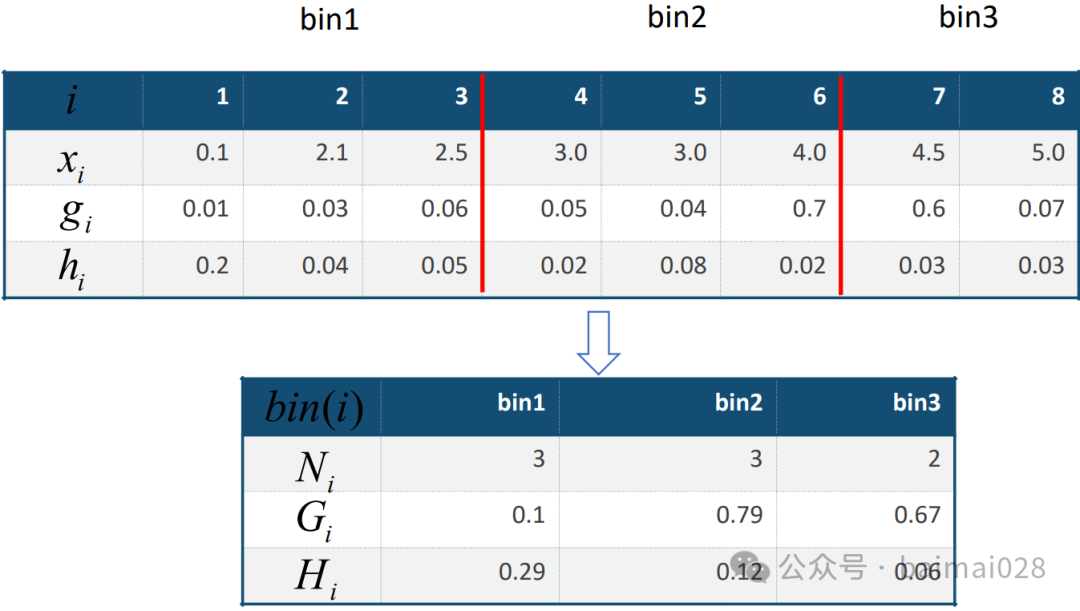
GOSS算法:
• Gradient-based One-Side Sampling,基于梯度的单边采样算法
• 思想是通过样本采样,减少目标函数增益Gain的计算复杂度
• 单边采样,只对梯度绝对值较小的样本按照一定比例进行采样,而保留了梯度绝对值较大的样本
• 因为目标函数增益主要来自于梯度绝对值较大的样本 => GOSS算法在性能和精度之间进行了很好的trade off
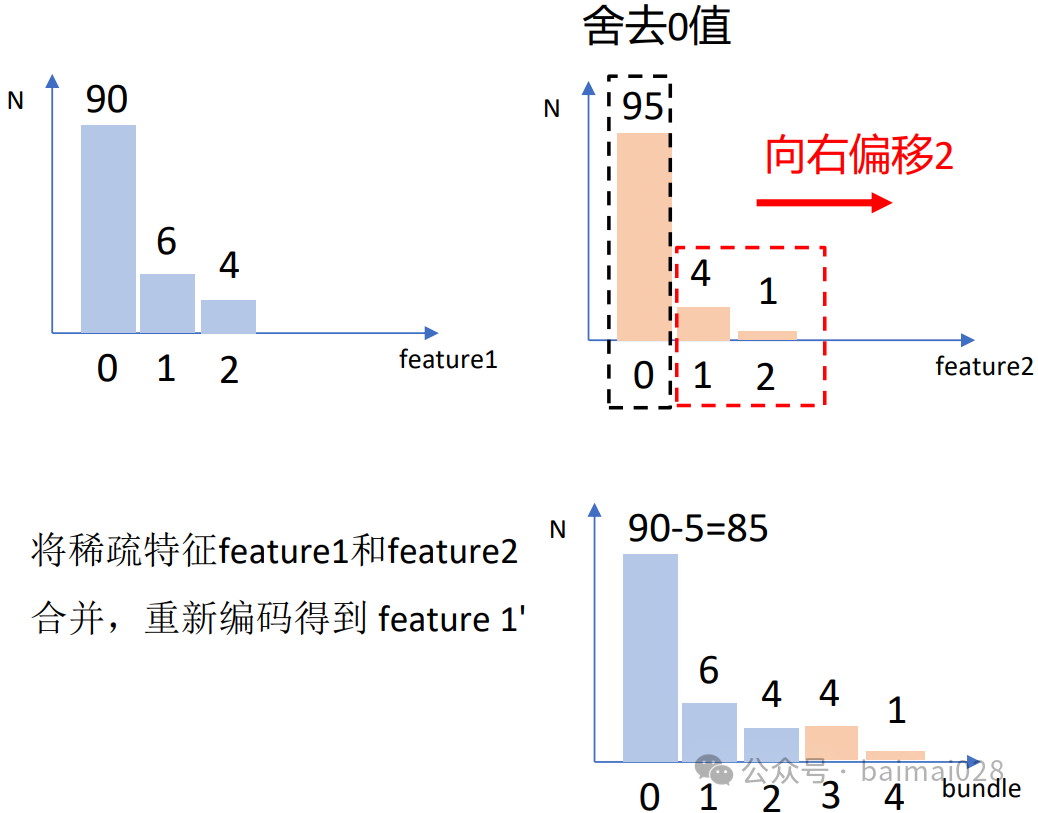
EFB算法:
• Exclusive Feature Bundling,互斥特征绑定算法
• 思想是特征中包含大量稀疏特征的时候,减少构建直方图的特征数量,从而降低计算复杂度
• 数据集中通常会有大量的稀疏特征(大部分为0,少量为非0)我们认为这些稀疏特征是互斥的,即不会同时取非零值
• EFB算法可以通过对某些特征的取值重新编码,将多个这样互斥的特征绑定为一个新的特征
• 类别特征可以转换成onehot编码,这些多个特征的onehot编码是互斥的,可以使用EFB将他们绑定为一个特征
• 在LightGBM中,可以直接将每个类别取值和一个bin关联,从而自动地处理它们,也就无需预处理成onehot编码
LightGBM工具:
import lightgbm as lgb• 官方文档:http://lightgbm.readthedocs.io/en/latest/PythonIntro.html
参数:
•boosting_type,训练方式,gbdt
• objective,目标函数,可以是binary,regression
• metric,评估指标,可以选择auc, mae,mse,binary_logloss,multi_logloss
• max_depth,树的最大深度,当模型过拟合时,可以降低max_depth
• min_data_in_leaf,叶子节点最小记录数,默认20
Bagging参数:bagging_fraction+bagging_freq(需要同时设置)
• bagging_fraction,每次迭代时用的数据比例,用于加快训练速度和减小过拟合
• bagging_freq:bagging的次数。默认为0,表示禁用bagging,非零值表示执行k次bagging,可以设置为3-5
• feature_fraction,设置在每次迭代中使用特征的比例,例如为0.8时,意味着在每次迭代中随机选择80%的参数来建树
• early_stopping_round,如果一次验证数据的一个度量在最近的round中没有提高,模型将停止训练
参数:
• lambda,正则化项,范围为0~1
• min_gain_to_split,描述分裂的最小 gain,控制树的有用的分裂
• max_cat_group,在 group 边界上找到分割点,当类别数量很多时,找分割点很容易过拟合时
• num_boost_round,迭代次数,通常 100+
• num_leaves,默认 31
• device,指定cpu 或者 gpu
• max_bin,表示 feature 将存入的 bin 的最大数量
• categorical_feature,如果 categorical_features = 0,1,2, 则列 0,1,2是 categorical 变量
• ignore_column,与 categorical_features 类似,只不过不是将特定的列视为categorical,而是完全忽略
param = {'boosting_type':'gbdt','objective' : 'binary', #任务类型'metric' : 'auc', #评估指标'learning_rate' : 0.01, #学习率'max_depth' : 15, #树的最大深度'feature_fraction':0.8, #设置在每次迭代中使用特征的比例'bagging_fraction': 0.9, #样本采样比例'bagging_freq': 8, #bagging的次数'lambda_l1': 0.6, #L1正则'lambda_l2': 0, #L2正则}
X_train, X_valid, y_train, y_valid = train_test_split(train.drop('Attrition',axis=1), train['Attrition'],test_size=0.2, random_state=42)trn_data = lgb.Dataset(X_train, label=y_train)val_data = lgb.Dataset(X_valid, label=y_valid)model = lgb.train(param,train_data,valid_sets=[train_data,valid_data],num_boost_round =10000 ,early_stopping_rounds=200,verbose_eval=25, categorical_feature=attr)predict=model.predict(test)test['Attrition']=predict# 转化为二分类输出test['Attrition']=test['Attrition'].map(lambda x:1 if x>=0.5 else 0)test[['Attrition']].to_csv('submit_lgb.csv')
LGBMClassifier经验参数clf = lgb.LGBMClassifier(num_leaves=2**5-1, reg_alpha=0.25, reg_lambda=0.25,objective='binary',max_depth=-1, learning_rate=0.005, min_child_samples=3,random_state=2021,n_estimators=2000, subsample=1, colsample_bytree=1,)num_leavel=2**5-1 #树的最大叶子数,对比XGBoost一般为2^(max_depth)reg_alpha,L1正则化系数reg_lambda,L2正则化系数max_depth,最大树的深度n_estimators,树的个数,相当于训练的轮数subsample,训练样本采样率(行采样)colsample_bytree,训练特征采样率(列采样)
XGBoost效果相对LightGBM可能会好一些
xgb = xgb.XGBClassifier(max_depth=6, learning_rate=0.05, n_estimators=2000,objective='binary:logistic', tree_method='gpu_hist',subsample=0.8, colsample_bytree=0.8,min_child_samples=3, eval_metric='auc', reg_lambda=0.5)
max_depth ,树的最大深度
learning_rate, 学习率
reg_lambda,L2正则化系数
n_estimators,树的个数,相当于训练的轮数
objective,目标函数, binary:logistic 用于二分类任务
tree_method, 使用功能的树的构建方法,hist代表使用直方图优化的近似贪婪算法
subsample,训练样本采样率(行采样)
colsample_bytree,训练特征采样率(列采样)
subsample, colsample_bytree是个值得调参的参数, 典型的取值为0.5-0.9(取0.7效果可能更好)

CatBoost算法:
• 俄罗斯科技公司Yandex开源的机器学习库(2017年)
• https://arxiv.org/pdf/1706.09516.pdf
• CatBoost = Catgorical + Boost
• 高效的处理分类特征(categorical features),首先对分类特征做统计,计算某个分类特征(category)出现的频率,然后加上超参数,生成新的数值型特征(numerical features)
• 同时使用组合类别特征,丰富了特征维度
• 采用的基模型是对称决策树,算法的参数少、支持分类变量,通过可以防止过拟合

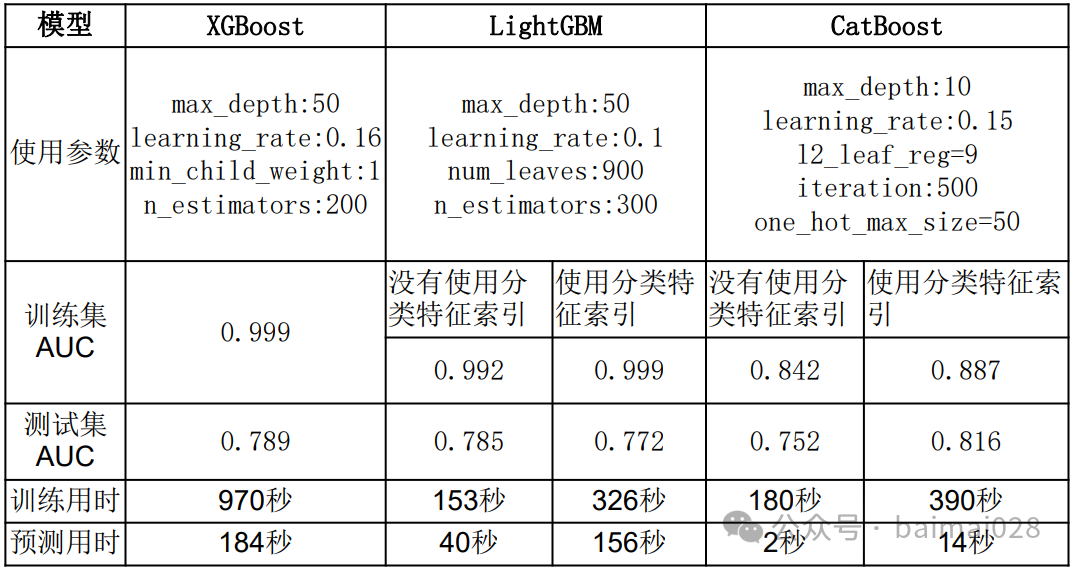
CatBoost,LightGBM,XGBoost对比:
• 2015 年航班延误数据,包含分类和数值变量
• https://www.kaggle.com/usdot/flight-delays/data
• 一共有约 500 条记录,使用10%的数据,即50条记录
• CatBoost 过拟合程度最小,在测试集上准确度最高0.816,同时预测用时最短,但这个表现仅仅在有分类特征,而且调节了one-hot最大量时才会出现
• 如果不利用 CatBoost 算法在这些特征上的优势,表现效果就会变成最差,AUC 0.752
• 使用CatBoost需要数据中包含分类变量,同时适当地调节这些变量时, 才会表现不错
• 处理特征为分类的神器
• 支持即用的分类特征,因此我们不需要对分类特征进行预处理(比如使用LabelEncoding 或 OneHotEncoding)
• CatBoost 设计了一种算法验证改进,避免了过拟合。因此处理分类数据比LightGBM 和XGBoost 强
• 准确性比 XGBoost 更高,同时训练时间更短
• 支持 GPU 训练
• 可以处理缺失的值
三种模型在flight-delays预测中的训练速度和准确度:
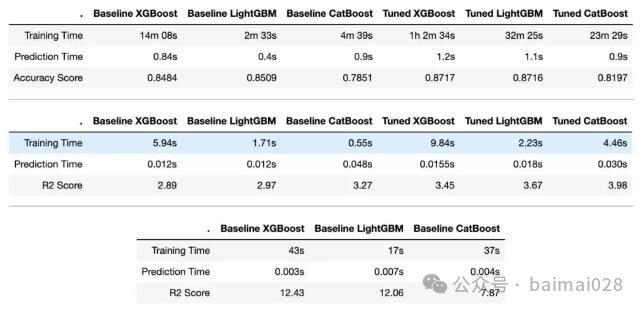
实验1,分类模型 MNIST识别(6万数据,784特征)
实验2,回归模型,预测纽约出租车票价(6万数据,7个特征)
实验3,回归模型,预测纽约出租车票价(200万数据,7个特征)
CatBoost工具:
• https://github.com/dmlc/xgboost
•https://catboost.ai/docs/concepts/python-reference_catboostclassifier.html
构造参数:
• learning_rate,学习率
• depth, 树的深度
• l2_leaf_reg,L2正则化系数
• n_estimators,树的最大数量,即迭代次数
• one_hot_max_size,one-hot编码最大规模,默认值根据数据和训练环境的不同而不同
• loss_function ,损失函数,包括Logloss,RMSE,MAE,CrossEntropy,回归任务默认RMSE,分类任务默认Logloss
• eval_metric,优化目标,包括RMSE,Logloss,MAE,CrossEntropy,Recall,Precision,F1,Accuracy,AUC,R2
fit函数参数:
• X,输入数据数据类型可以是:list; pandas.DataFrame; pandas.Series
• y=None
• cat_features=None,用于处理分类特征
• sample_weight=None,输入数据的样本权重
• logging_level=None,控制是否输出日志信息,或者其他信息
• plot=False,训练过程中,绘制,度量值,所用时间等
• eval_set=None,验证集合,数据类型list(X, y)tuples
• baseline=None
• use_best_model=None
• verbose=None
model = CatBoostClassifier(iterations=1000, #最大树数,即迭代次数depth = 6, #树的深度learning_rate = 0.03, #学习率custom_loss='AUC', #训练过程中,用户自定义的损失函数eval_metric='AUC', #过拟合检验(设置True)的评估指标,用于优化bagging_temperature=0.83, #贝叶斯bootstrap强度设置rsm = 0.78, #随机子空间od_type='Iter', #过拟合检查类型od_wait=150, #使用Iter时,表示达到指定次数后,停止训练metric_period = 400, #计算优化评估值的频率l2_leaf_reg = 5, #l2正则参数thread_count = 20, #并行线程数量random_seed = 967 #随机数种子)
attr=['Age','BusinessTravel','Department','Education','EducationField','Gender','JobRole','MaritalStatus','Over18','OverTime']
model = cb.CatBoostClassifier(iterations=1000,depth=7,learning_rate=0.01,loss_function='Logloss',eval_metric='AUC',logging_level='Verbose',metric_period=50)# 得到分类特征的列号categorical_features_indices = []for i in range(len(X_train.columns)):if X_train.columns.values[i] in attr:categorical_features_indices.append(i)print(categorical_features_indices)
[0, 1, 3, 5, 6, 9, 13, 15, 19, 20]
model.fit(X_train, y_train, eval_set=(X_valid, y_valid),cat_features=categorical_features_indices)predict = model.predict(test)test['Attrition']=predicttest[['Attrition']].to_csv('submit_cb.csv')
总结:
• LighGBM效率高,在Kaggle比赛中应用多
• CatBoost对于分类特征多的数据,可以高效的处理,过拟合程度小,效果好
• XGBoost, LightGBM, CatBoost参数较多,调参需要花大量时间
• Boosting集成学习包括AdaBoosting和Gradient Boosting
• Boosting只是集成学习中的一种(Bagging, Stacking)

实战:二手车价格预测学习赛
https://tianchi.aliyun.com/competition/entrance/231784/information
一、赛题数据
赛题以预测二手车的交易价格为任务,数据集报名后可见并可下载,该数据来自某交易平台的二手车交易记录,总数据量超过40w,包含31列变量信息,其中15列为匿名变量。为了保证比赛的公平性,将会从中抽取15万条作为训练集,5万条作为测试集A,5万条作为测试集B,同时会对name、model、brand和regionCode等信息进行脱敏。
字段表
| Field | Description |
|---|---|
|
SaleID |
交易ID,唯一编码 |
|
name |
汽车交易名称,已脱敏 |
|
regDate |
汽车注册日期,例如20160101,2016年01月01日 |
|
model |
车型编码,已脱敏 |
|
brand |
汽车品牌,已脱敏 |
|
bodyType |
车身类型:豪华轿车:0,微型车:1,厢型车:2,大巴车:3,敞篷车:4,双门汽车:5,商务车:6,搅拌车:7 |
|
fuelType |
燃油类型:汽油:0,柴油:1,液化石油气:2,天然气:3,混合动力:4,其他:5,电动:6 |
|
gearbox |
变速箱:手动:0,自动:1 |
|
power |
发动机功率:范围 [ 0, 600 ] |
|
kilometer |
汽车已行驶公里,单位万km |
|
notRepairedDamage |
汽车有尚未修复的损坏:是:0,否:1 |
|
regionCode |
地区编码,已脱敏 |
|
seller |
销售方:个体:0,非个体:1 |
|
offerType |
报价类型:提供:0,请求:1 |
|
creatDate |
汽车上线时间,即开始售卖时间 |
|
price |
二手车交易价格(预测目标) |
|
v系列特征 |
匿名特征,包含v0-14在内15个匿名特征 |
二、评测标准
评价标准为MAE(Mean Absolute Error)。
MAE越小,说明模型预测得越准确。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

三、结果提交
提交前请确保预测结果的格式与sample_submit.csv中的格式一致,以及提交文件后缀名为csv。
形式如下:
SaleID,price
150000,687
150001,1250
150002,2580
150003,1178XGBoost, LightGBM, CatBoostg融合代码:
#!/usr/bin/env python# coding: utf-8"""二手车价格预测 - 增强特征工程与CatBoost+LightGBM+XGBoost三模型集成"""import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as snsimport lightgbm as lgbimport xgboost as xgbfrom catboost import CatBoostRegressor, Poolfrom sklearn.metrics import mean_squared_error, mean_absolute_error, r2_scorefrom sklearn.model_selection import train_test_splitimport joblibimport datetimeimport osimport warningswarnings.filterwarnings('ignore')# 设置中文显示plt.rcParams['font.sans-serif'] = ['SimHei']plt.rcParams['axes.unicode_minus'] = False# 创建结果文件夹if not os.path.exists('model_results'):os.makedirs('model_results')if not os.path.exists('feature_data'):os.makedirs('feature_data')def load_data():"""加载原始数据"""print("正在加载数据...")# 加载训练集train_data = pd.read_csv('used_car_train_20200313.csv', sep=' ')# 加载测试集test_data = pd.read_csv('used_car_testB_20200421.csv', sep=' ')print(f"训练集形状: {train_data.shape}")print(f"测试集形状: {test_data.shape}")return train_data, test_datadef preprocess_data(train_data, test_data):"""数据预处理"""print("\n开始数据预处理...")# 合并训练集和测试集进行特征工程train_data['source'] = 'train'test_data['source'] = 'test'data = pd.concat([train_data, test_data], ignore_index=True)# 保存SaleIDtrain_ids = train_data['SaleID']test_ids = test_data['SaleID']# 从训练集获取y值y = train_data['price']return data, y, train_ids, test_idsdef create_time_features(data):"""创建时间特征"""print("创建时间特征...")# 保存原始日期值data['regDate_raw'] = data['regDate'].copy()data['creatDate_raw'] = data['creatDate'].copy()# 转换为datetime格式data['regDate'] = pd.to_datetime(data['regDate'], format='%Y%m%d', errors='coerce')data['creatDate'] = pd.to_datetime(data['creatDate'], format='%Y%m%d', errors='coerce')# 处理无效日期reference_date = pd.to_datetime('20160101', format='%Y%m%d')data.loc[data['regDate'].isnull(), 'regDate'] = reference_datedata.loc[data['creatDate'].isnull(), 'creatDate'] = reference_date# 车辆年龄(天数)data['vehicle_age_days'] = (data['creatDate'] - data['regDate']).dt.daysdata.loc[data['vehicle_age_days'] < 0, 'vehicle_age_days'] = 0# 车辆年龄(年和月)data['vehicle_age_years'] = data['vehicle_age_days'] / 365.25data['vehicle_age_months'] = data['vehicle_age_days'] / 30.44# 提取年月日和其他时间特征for prefix, date_col in [('reg', 'regDate'), ('creat', 'creatDate')]:data[f'{prefix}_year'] = data[date_col].dt.yeardata[f'{prefix}_month'] = data[date_col].dt.monthdata[f'{prefix}_day'] = data[date_col].dt.daydata[f'{prefix}_dayofweek'] = data[date_col].dt.dayofweekdata[f'{prefix}_is_weekend'] = (data[f'{prefix}_dayofweek'] >= 5).astype(int)data[f'{prefix}_quarter'] = data[date_col].dt.quarterdata[f'{prefix}_season'] = data[f'{prefix}_month'].apply(lambda x: (x%12 + 3)//3)# 使用强度特征data['km_per_year'] = data['kilometer'] / (data['vehicle_age_years'] + 0.1)data['km_per_month'] = data['kilometer'] / (data['vehicle_age_months'] + 0.1)# 分段特征data['age_segment'] = pd.cut(data['vehicle_age_years'],bins=[-0.01, 0.5, 1, 2, 3, 5, 7, 10, 15, 100],labels=['0-0.5年', '0.5-1年', '1-2年', '2-3年', '3-5年', '5-7年', '7-10年', '10-15年', '15年以上'])data['km_segment'] = pd.cut(data['kilometer'],bins=[-0.01, 1, 3, 5, 10, 20, 50, 100, 200, 1000],labels=['0-1万', '1-3万', '3-5万', '5-10万', '10-20万', '20-50万', '50-100万', '100-200万', '200万以上'])data['usage_intensity'] = pd.cut(data['km_per_year'],bins=[-0.01, 5000, 10000, 20000, 30000, 50000, 100000, 1000000],labels=['极低', '低', '中低', '中', '中高', '高', '极高'])return datadef create_car_features(data):"""创建车辆特征"""print("创建车辆特征...")# 缺失值处理与标记numerical_features = ['power', 'kilometer', 'v_0', 'v_1', 'v_2', 'v_3', 'v_4', 'v_5', 'v_6','v_7', 'v_8', 'v_9', 'v_10', 'v_11', 'v_12', 'v_13', 'v_14']for feature in numerical_features:data[f'{feature}_missing'] = data[feature].isnull().astype(int)data[feature] = data[feature].fillna(data[feature].median())# 品牌与车型组合data['brand_model'] = data['brand'].astype(str) + '_' + data['model'].astype(str)# 对数变换for col in ['power', 'kilometer']:data[f'log_{col}'] = np.log1p(data[col])# 异常值处理for col in ['power', 'kilometer']:Q1 = data[col].quantile(0.05)Q3 = data[col].quantile(0.95)IQR = Q3 - Q1data[f'{col}_outlier'] = ((data[col] < (Q1 - 1.5 * IQR)) | (data[col] > (Q3 + 1.5 * IQR))).astype(int)data[col] = data[col].clip(Q1 - 1.5 * IQR, Q3 + 1.5 * IQR)# 高级特征data['power_per_km'] = data['power'] / (data['kilometer'] + 1)data['power_age_ratio'] = data['power'] / (data['vehicle_age_years'] + 0.1)data['km_age_ratio'] = data['kilometer'] / (data['vehicle_age_years'] + 0.1)# 二次型特征data['power_squared'] = data['power'] ** 2data['age_squared'] = data['vehicle_age_years'] ** 2data['km_squared'] = (data['kilometer'] / 10000) ** 2# 三阶交互特征data['power_age_km'] = data['power'] * data['vehicle_age_years'] * data['kilometer']data['log_power_age_km'] = np.log1p(np.abs(data['power_age_km']))# 车辆状态综合指数data['vehicle_condition_index'] = ((data['power'] / data['power'].max()) * 0.3 +(1 - data['vehicle_age_years'] / data['vehicle_age_years'].max()) * 0.4 +(1 - data['kilometer'] / data['kilometer'].max()) * 0.3)return datadef create_statistical_features(data, train_idx):"""创建统计特征"""print("创建统计特征...")# 仅使用训练集数据创建统计特征train_data = data.iloc[train_idx].reset_index(drop=True)# 统计特征列表group_features = ['brand', 'model', 'bodyType', 'age_segment']for feature in group_features:# 基础统计特征stats = train_data.groupby(feature).agg({'price': ['mean', 'median', 'std', 'count'],'kilometer': ['mean', 'median'],'power': ['mean', 'median']}).round(2)# 展平多级索引stats.columns = [f'{feature}_{col[0]}_{col[1]}' for col in stats.columns]stats = stats.reset_index()# 合并到原始数据data = data.merge(stats, on=feature, how='left')# 品牌车型组合特征brand_model_stats = train_data.groupby('brand_model').agg(brand_model_price_mean=('price', 'mean'),brand_model_price_count=('price', 'count')).reset_index()data = data.merge(brand_model_stats, on='brand_model', how='left')# 相对价格特征for feature in group_features:price_mean_col = f'{feature}_price_mean'if price_mean_col in data.columns:data[f'{feature}_price_ratio'] = data[price_mean_col] / data[price_mean_col].mean()# 填充缺失值for col in data.columns:if '_mean' in col or '_median' in col or '_std' in col or '_ratio' in col:data[col] = data[col].fillna(data[col].median())return datadef encode_categorical_features(data):"""编码分类特征"""print("编码分类特征...")# 准备分类特征列表categorical_cols = ['model', 'brand', 'bodyType', 'fuelType', 'gearbox', 'notRepairedDamage','age_segment', 'km_segment', 'usage_intensity', 'brand_model']for col in categorical_cols:if col in data.columns:# 转换为字符串并填充缺失值data[col] = data[col].astype(str)data[col] = data[col].fillna('未知')# 频率编码freq_encoding = data.groupby(col).size() / len(data)data[f'{col}_freq'] = data[col].map(freq_encoding)# WOE编码(仅对训练集部分)if 'price' in data.columns and 'source' in data.columns:train_data = data[data['source'] == 'train'].copy()mean_price = train_data['price'].mean()woe_dict = {}for cat in train_data[col].unique():cat_mean = train_data.loc[train_data[col] == cat, 'price'].mean()if pd.notna(cat_mean) and cat_mean > 0 and mean_price > 0:woe = np.log(cat_mean / mean_price)woe_dict[cat] = woedata[f'{col}_woe'] = data[col].map(woe_dict)data[f'{col}_woe'] = data[f'{col}_woe'].fillna(0)# 转换为category类型data[col] = data[col].astype('category')return data, categorical_colsdef feature_selection(data):"""特征选择和最终数据准备"""print("特征选择和最终数据准备...")# 删除不再需要的列drop_cols = ['regDate', 'creatDate', 'price', 'SaleID', 'name', 'offerType', 'seller', 'source','regDate_raw', 'creatDate_raw']data = data.drop(drop_cols, axis=1, errors='ignore')return datadef train_catboost_model(X_train, X_val, y_train, y_val, categorical_cols):"""训练CatBoost模型"""print("\n开始训练CatBoost模型...")# 准备分类特征索引cat_features = [col for col in categorical_cols if col in X_train.columns]# 创建CatBoost数据集train_pool = Pool(X_train, y_train, cat_features=cat_features)val_pool = Pool(X_val, y_val, cat_features=cat_features)# 设置模型参数params = {'loss_function': 'RMSE','eval_metric': 'RMSE','learning_rate': 0.03,'depth': 6,'min_data_in_leaf': 50,'l2_leaf_reg': 3,'random_seed': 42,'iterations': 3000,'early_stopping_rounds': 100,'verbose': 100,'task_type': 'CPU' # 如果有GPU可以改为'GPU'}# 训练模型model = CatBoostRegressor(**params)model.fit(train_pool, eval_set=val_pool, use_best_model=True)# 保存模型model_path = 'feature_data/catboost_model.cbm'model.save_model(model_path)print(f"CatBoost模型已保存到 {model_path}")return modeldef train_lightgbm_model(X_train, X_val, y_train, y_val, categorical_cols):"""训练LightGBM模型"""print("\n开始训练LightGBM模型...")# 分类特征索引cat_indices = [X_train.columns.get_loc(col) for col in categorical_cols if col in X_train.columns]# 创建数据集train_data = lgb.Dataset(X_train,label=y_train,categorical_feature=cat_indices if cat_indices else None)val_data = lgb.Dataset(X_val,label=y_val,reference=train_data,categorical_feature=cat_indices if cat_indices else None)# 设置模型参数params = {'boosting_type': 'gbdt','objective': 'regression','metric': ['mae', 'rmse'],'num_leaves': 31,'learning_rate': 0.05,'feature_fraction': 0.9,'bagging_fraction': 0.8,'bagging_freq': 5,'verbose': 0,'n_jobs': -1}# 定义回调函数callbacks = [lgb.early_stopping(100, verbose=True),lgb.log_evaluation(100)]# 训练模型model = lgb.train(params,train_data,valid_sets=[train_data, val_data],num_boost_round=3000,callbacks=callbacks)# 保存模型model_path = 'feature_data/lightgbm_model.txt'model.save_model(model_path)print(f"LightGBM模型已保存到 {model_path}")return modeldef train_xgboost_model(X_train, X_val, y_train, y_val):"""训练XGBoost模型"""print("\n开始训练XGBoost模型...")# 创建DMatrix数据结构dtrain = xgb.DMatrix(X_train, label=y_train, enable_categorical=True)dval = xgb.DMatrix(X_val, label=y_val, enable_categorical=True)# 设置模型参数params = {'objective': 'reg:squarederror','eval_metric': ['mae', 'rmse'],'max_depth': 7,'eta': 0.05,'subsample': 0.8,'colsample_bytree': 0.9,'min_child_weight': 3,'alpha': 1,'gamma': 0.1}# 训练参数evals = [(dtrain, 'train'), (dval, 'val')]# 训练模型model = xgb.train(params,dtrain,num_boost_round=3000,evals=evals,early_stopping_rounds=100,verbose_eval=100)# 保存模型model_path = 'feature_data/xgboost_model.json'model.save_model(model_path)print(f"XGBoost模型已保存到 {model_path}")return modeldef ensemble_predict(model_cat, model_lgb, model_xgb, X_val, categorical_cols, y_val=None):"""三模型集成预测"""print("\n生成集成预测...")# CatBoost预测cat_features = [col for col in categorical_cols if col in X_val.columns]val_pool = Pool(X_val, cat_features=cat_features)y_pred_cat = model_cat.predict(val_pool)# LightGBM预测y_pred_lgb = model_lgb.predict(X_val, num_iteration=model_lgb.best_iteration)# XGBoost预测dval = xgb.DMatrix(X_val, enable_categorical=True)y_pred_xgb = model_xgb.predict(dval)# 加权集成预测 (可以根据各模型的验证集表现调整权重)weights = [0.4, 0.3, 0.3] # CatBoost, LightGBM, XGBoost的权重y_pred_ensemble = (weights[0] * y_pred_cat +weights[1] * y_pred_lgb +weights[2] * y_pred_xgb)# 如果有真实值,评估性能if y_val is not None:models = {'CatBoost': y_pred_cat,'LightGBM': y_pred_lgb,'XGBoost': y_pred_xgb,'集成模型': y_pred_ensemble}print("\n各模型评估结果:")for name, pred in models.items():mae = mean_absolute_error(y_val, pred)rmse = np.sqrt(mean_squared_error(y_val, pred))r2 = r2_score(y_val, pred)print(f"{name} - MAE: {mae:.2f}, RMSE: {rmse:.2f}, R2: {r2:.4f}")# 保存验证集预测结果for name, pred in models.items():joblib.dump(pred, f'feature_data/{name.lower().replace(" ", "_")}_val_predictions.joblib')# 绘制预测对比图plt.figure(figsize=(12, 8))plt.scatter(y_val, y_pred_ensemble, alpha=0.5)plt.plot([y_val.min(), y_val.max()], [y_val.min(), y_val.max()], 'r--', lw=2)plt.xlabel('实际价格')plt.ylabel('预测价格')plt.title('三模型集成预测价格 vs 实际价格')plt.tight_layout()plt.savefig('model_results/triple_ensemble_prediction_vs_actual.png')plt.close()return y_pred_cat, y_pred_lgb, y_pred_xgb, y_pred_ensembledef plot_feature_importance(model_cat, model_lgb, model_xgb, X_train, categorical_cols):"""绘制特征重要性图"""print("\n绘制特征重要性...")# CatBoost特征重要性cat_importance = pd.DataFrame({'feature': X_train.columns,'importance': model_cat.feature_importances_})cat_importance = cat_importance.sort_values('importance', ascending=False)# LightGBM特征重要性lgb_importance = pd.DataFrame({'feature': X_train.columns,'importance': model_lgb.feature_importance('gain')})lgb_importance = lgb_importance.sort_values('importance', ascending=False)# XGBoost特征重要性xgb_importance = model_xgb.get_score(importance_type='gain')xgb_importance = pd.DataFrame({'feature': list(xgb_importance.keys()),'importance': list(xgb_importance.values())})xgb_importance = xgb_importance.sort_values('importance', ascending=False)# 保存各模型的特征重要性cat_importance.to_csv('model_results/catboost_feature_importance.csv', index=False)lgb_importance.to_csv('model_results/lightgbm_feature_importance.csv', index=False)xgb_importance.to_csv('model_results/xgboost_feature_importance.csv', index=False)# 计算综合特征重要性all_features = pd.DataFrame({'feature': X_train.columns})# 合并三个模型的特征重要性importance_dfs = {'CatBoost': cat_importance,'LightGBM': lgb_importance,'XGBoost': xgb_importance}for name, df in importance_dfs.items():# 归一化重要性分数df['importance_normalized'] = df['importance'] / df['importance'].sum()all_features = all_features.merge(df[['feature', 'importance_normalized']],on='feature',how='left',suffixes=('', f'_{name.lower()}'))# 计算平均重要性importance_cols = [col for col in all_features.columns if 'importance_normalized' in col]all_features['importance_mean'] = all_features[importance_cols].mean(axis=1)all_features = all_features.sort_values('importance_mean', ascending=False)# 保存综合特征重要性all_features.to_csv('model_results/ensemble_feature_importance.csv', index=False)# 绘制Top 20特征重要性图plt.figure(figsize=(15, 10))sns.barplot(x='importance_mean', y='feature', data=all_features.head(20))plt.title('三模型集成 Top 20 特征重要性')plt.tight_layout()plt.savefig('model_results/triple_ensemble_feature_importance.png')plt.close()return all_featuresdef main():"""主函数"""# 加载数据train_data, test_data = load_data()# 预处理数据data, y, train_ids, test_ids = preprocess_data(train_data, test_data)# 创建时间特征data = create_time_features(data)# 创建车辆特征data = create_car_features(data)# 找回训练集和测试集的索引train_idx = data[data['source'] == 'train'].indextest_idx = data[data['source'] == 'test'].index# 创建统计特征data = create_statistical_features(data, train_idx)# 编码分类特征data, categorical_cols = encode_categorical_features(data)# 特征选择和最终数据准备data = feature_selection(data)# 分离训练集和测试集X_train_full = data.iloc[train_idx].reset_index(drop=True)X_test = data.iloc[test_idx].reset_index(drop=True)# 划分训练集和验证集X_train, X_val, y_train, y_val = train_test_split(X_train_full, y, test_size=0.2, random_state=42)# 保存处理后的数据os.makedirs('feature_data', exist_ok=True)X_train.to_csv('feature_data/triple_boost_X_train.csv', index=False)X_val.to_csv('feature_data/triple_boost_X_val.csv', index=False)joblib.dump(y_train, 'feature_data/triple_boost_y_train.joblib')joblib.dump(y_val, 'feature_data/triple_boost_y_val.joblib')X_test.to_csv('feature_data/triple_boost_test_data.csv', index=False)joblib.dump(test_ids, 'feature_data/triple_boost_sale_ids.joblib')joblib.dump(categorical_cols, 'feature_data/triple_boost_cat_features.joblib')print("\n预处理后的数据已保存")# 训练三个模型model_cat = train_catboost_model(X_train, X_val, y_train, y_val, categorical_cols)model_lgb = train_lightgbm_model(X_train, X_val, y_train, y_val, categorical_cols)model_xgb = train_xgboost_model(X_train, X_val, y_train, y_val)# 在验证集上进行集成预测_, _, _, _ = ensemble_predict(model_cat, model_lgb, model_xgb, X_val, categorical_cols, y_val)# 绘制特征重要性feature_imp = plot_feature_importance(model_cat, model_lgb, model_xgb, X_train, categorical_cols)# 在测试集上进行集成预测y_pred_cat, y_pred_lgb, y_pred_xgb, y_pred_ensemble = ensemble_predict(model_cat, model_lgb, model_xgb, X_test, categorical_cols)# 保存各个模型的预测结果predictions = {'catboost': y_pred_cat,'lightgbm': y_pred_lgb,'xgboost': y_pred_xgb,'ensemble': y_pred_ensemble}for name, pred in predictions.items():submit = pd.DataFrame({'SaleID': test_ids, 'price': pred})submit.to_csv(f'model_results/{name}_submit_result.csv', index=False)print("\n模型训练与预测完成!")print("各模型预测结果已保存至model_results目录:")print("- CatBoost预测结果:model_results/catboost_submit_result.csv")print("- LightGBM预测结果:model_results/lightgbm_submit_result.csv")print("- XGBoost预测结果:model_results/xgboost_submit_result.csv")print("- 集成模型预测结果:model_results/ensemble_submit_result.csv")print(f"\nTop 10 重要特征:\n{feature_imp[['feature', 'importance_mean']].head(10)}")if __name__ == "__main__":main()
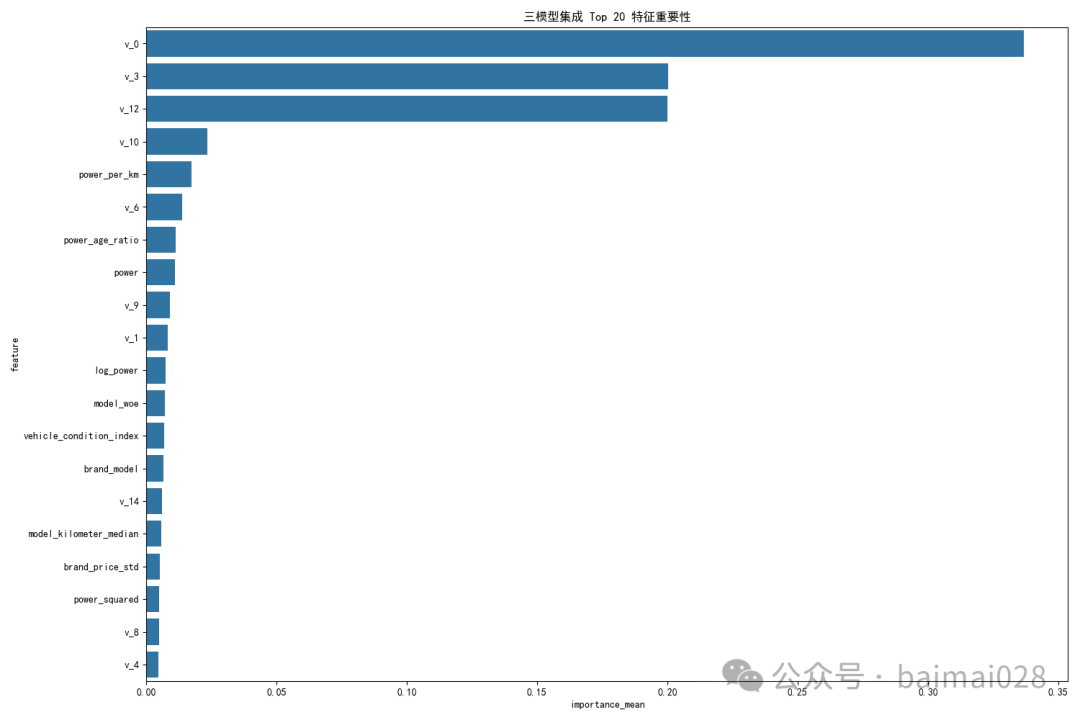
特征工程:
# 二手车价格预测 - 三模型集成特征工程总结本文档详细总结了二手车价格预测项目中使用的特征工程方法,这些方法为CatBoost、LightGBM和XGBoost三模型集成提供了高质量的特征输入。## 1. 时间特征工程时间特征是二手车价格预测的关键因素,我们从日期数据中提取了丰富的时间维度信息:### 1.1 基础时间特征- **日期格式转换**:将原始日期字符串转换为标准datetime格式- **缺失日期处理**:使用参考日期(20160101)填充无效日期- **时间分量提取**:```pythonfor prefix, date_col in [('reg', 'regDate'), ('creat', 'creatDate')]:data[f'{prefix}_year'] = data[date_col].dt.yeardata[f'{prefix}_month'] = data[date_col].dt.monthdata[f'{prefix}_day'] = data[date_col].dt.daydata[f'{prefix}_dayofweek'] = data[date_col].dt.dayofweekdata[f'{prefix}_quarter'] = data[date_col].dt.quarter```### 1.2 车龄特征- **多精度车龄计算**:```pythondata['vehicle_age_days'] = (data['creatDate'] - data['regDate']).dt.daysdata['vehicle_age_years'] = data['vehicle_age_days'] / 365.25data['vehicle_age_months'] = data['vehicle_age_days'] / 30.44```- **异常车龄修正**:注册日期晚于创建日期的情况归零处理- **车龄分段**:将连续的车龄特征划分为9个区间```pythondata['age_segment'] = pd.cut(data['vehicle_age_years'],bins=[-0.01, 0.5, 1, 2, 3, 5, 7, 10, 15, 100],labels=['0-0.5年', '0.5-1年', '1-2年', '2-3年', '3-5年', '5-7年', '7-10年', '10-15年', '15年以上'])```### 1.3 衍生时间特征- **周末标记**:标记是否为周末注册/创建```pythondata[f'{prefix}_is_weekend'] = (data[f'{prefix}_dayofweek'] >= 5).astype(int)```- **季节映射**:将月份映射为季节(1-春,2-夏,3-秋,4-冬)```pythondata[f'{prefix}_season'] = data[f'{prefix}_month'].apply(lambda x: (x%12 + 3)//3)```## 2. 车辆特征工程车辆自身属性是价格的重要影响因素,我们进行了全面的特征提取:### 2.1 缺失值处理- **缺失标记**:为每个数值型特征创建缺失标记```pythondata[f'{feature}_missing'] = data[feature].isnull().astype(int)```- **中位数填充**:使用中位数填充数值型特征的缺失值```pythondata[feature] = data[feature].fillna(data[feature].median())```### 2.2 数值特征变换- **对数变换**:对偏斜分布的特征进行对数变换```pythondata[f'log_{col}'] = np.log1p(data[col])```- **异常值处理**:使用IQR方法检测和截断异常值```pythonQ1 = data[col].quantile(0.05)Q3 = data[col].quantile(0.95)IQR = Q3 - Q1data[f'{col}_outlier'] = ((data[col] < (Q1 - 1.5 * IQR)) | (data[col] > (Q3 + 1.5 * IQR))).astype(int)data[col] = data[col].clip(Q1 - 1.5 * IQR, Q3 + 1.5 * IQR)```### 2.3 交叉特征- **品牌车型组合**:`brand_model = brand + '_' + model`- **功率公里比**:`power_per_km = power / (kilometer + 1)`- **功率车龄比**:`power_age_ratio = power / (vehicle_age_years + 0.1)`- **公里车龄比**:`km_age_ratio = kilometer / (vehicle_age_years + 0.1)`- **三阶交互特征**:`power_age_km = power * vehicle_age_years * kilometer`### 2.4 非线性特征- **二次型特征**:对关键特征进行平方变换```pythondata['power_squared'] = data['power'] ** 2data['age_squared'] = data['vehicle_age_years'] ** 2data['km_squared'] = (data['kilometer'] / 10000) ** 2```### 2.5 综合指标- **车辆状态综合指数**:结合功率、车龄和公里数的加权指标```pythondata['vehicle_condition_index'] = ((data['power'] / data['power'].max()) * 0.3 +(1 - data['vehicle_age_years'] / data['vehicle_age_years'].max()) * 0.4 +(1 - data['kilometer'] / data['kilometer'].max()) * 0.3)```### 2.6 分段特征- **公里数分段**:将公里数划分为9个区间```pythondata['km_segment'] = pd.cut(data['kilometer'],bins=[-0.01, 1, 3, 5, 10, 20, 50, 100, 200, 1000],labels=['0-1万', '1-3万', '3-5万', '5-10万', '10-20万', '20-50万', '50-100万', '100-200万', '200万以上'])```- **使用强度分段**:基于年均行驶里程的使用强度分类```pythondata['usage_intensity'] = pd.cut(data['km_per_year'],bins=[-0.01, 5000, 10000, 20000, 30000, 50000, 100000, 1000000],labels=['极低', '低', '中低', '中', '中高', '高', '极高'])```## 3. 统计特征工程统计特征能够捕捉不同类别的整体价格趋势,是重要的预测因子:### 3.1 单维度统计特征基于训练集数据,计算不同类别的价格统计信息:```pythonfor feature in group_features:stats = train_data.groupby(feature).agg({'price': ['mean', 'median', 'std', 'count'],'kilometer': ['mean', 'median'],'power': ['mean', 'median']}).round(2)# 展平多级索引stats.columns = [f'{feature}_{col[0]}_{col[1]}' for col in stats.columns]stats = stats.reset_index()# 合并到原始数据data = data.merge(stats, on=feature, how='left')```### 3.2 相对价格特征计算各类别的相对价格水平,反映市场定位:```pythonfor feature in group_features:price_mean_col = f'{feature}_price_mean'if price_mean_col in data.columns:data[f'{feature}_price_ratio'] = data[price_mean_col] / data[price_mean_col].mean()```### 3.3 组合统计特征计算多维度组合的统计特征:```pythonbrand_model_stats = train_data.groupby('brand_model').agg(brand_model_price_mean=('price', 'mean'),brand_model_price_count=('price', 'count')).reset_index()data = data.merge(brand_model_stats, on='brand_model', how='left')```## 4. 分类特征编码对分类特征进行编码,使其适合机器学习模型处理:### 4.1 频率编码计算每个类别的出现频率,反映类别的流行度:```pythonfreq_encoding = data.groupby(col).size() / len(data)data[f'{col}_freq'] = data[col].map(freq_encoding)```### 4.2 WOE编码计算每个类别与目标变量的关系强度:```pythontrain_data = data[data['source'] == 'train'].copy()mean_price = train_data['price'].mean()woe_dict = {}for cat in train_data[col].unique():cat_mean = train_data.loc[train_data[col] == cat, 'price'].mean()if pd.notna(cat_mean) and cat_mean > 0 and mean_price > 0:woe = np.log(cat_mean / mean_price)woe_dict[cat] = woedata[f'{col}_woe'] = data[col].map(woe_dict)data[f'{col}_woe'] = data[f'{col}_woe'].fillna(0)```## 5. 三模型集成特点我们的三模型集成方法具有以下特点:### 5.1 模型选择- **CatBoost**:原生支持分类特征,无需独热编码- **LightGBM**:高效处理大规模数据,速度快- **XGBoost**:强大的正则化能力,防止过拟合### 5.2 集成策略采用加权平均的集成策略,权重分配为:- CatBoost: 0.4- LightGBM: 0.3- XGBoost: 0.3```pythonweights = [0.4, 0.3, 0.3] # CatBoost, LightGBM, XGBoost的权重y_pred_ensemble = (weights[0] * y_pred_cat +weights[1] * y_pred_lgb +weights[2] * y_pred_xgb)```### 5.3 特征重要性分析综合三个模型的特征重要性,获得更可靠的特征评估:```pythonfor name, df in importance_dfs.items():# 归一化重要性分数df['importance_normalized'] = df['importance'] / df['importance'].sum()all_features = all_features.merge(df[['feature', 'importance_normalized']],on='feature',how='left',suffixes=('', f'_{name.lower()}'))# 计算平均重要性importance_cols = [col for col in all_features.columns if 'importance_normalized' in col]all_features['importance_mean'] = all_features[importance_cols].mean(axis=1)```## 6. 实施流程完整的特征工程和模型集成流程如下:1. **数据加载与预处理**:加载数据,合并训练集和测试集2. **时间特征创建**:处理日期,提取时间特征3. **车辆特征创建**:处理车辆属性,创建交叉特征和非线性特征4. **统计特征创建**:基于训练集计算各类别的统计特征5. **分类特征编码**:对分类特征进行频率编码和WOE编码6. **特征选择与准备**:删除冗余特征,准备最终数据集7. **模型训练**:分别训练CatBoost、LightGBM和XGBoost模型8. **集成预测**:使用加权平均方法融合三个模型的预测结果9. **特征重要性分析**:综合分析三个模型的特征重要性## 7. 未来改进方向虽然当前的特征工程已经较为全面,但仍有以下改进空间:1. **特征选择**:添加基于重要性的特征筛选步骤2. **高级非线性变换**:尝试更多的非线性变换,如立方根、指数等3. **聚类特征**:添加基于KMeans等聚类算法的特征4. **PCA降维特征**:对高维特征考虑添加PCA降维5. **目标编码的交叉验证**:使用K折交叉验证方式实现WOE编码,避免数据泄露6. **周期性特征处理**:对月份等周期性特征使用正弦/余弦变换7. **更多的异常检测方法**:结合多种异常检测方法,如Z-score、孤立森林等8. **自动特征工程**:尝试使用自动特征工程工具,如featuretools通过这一系列特征工程和模型集成方法,我们能够充分挖掘数据中的信息,显著提高二手车价格预测的准确性。
评价标准为MAE(Mean Absolute Error)。所以是分数越低越好,争取下次低于500。
如何学习AI大模型?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 23
23 0
0- 0



 已为社区贡献902条内容
已为社区贡献902条内容

所有评论(0)