混合专家模型(MoE):大模型效率革命的核心密码
最后我们回到开头的问题:MoE到底是什么?它不是什么高深莫测的黑科技,而是把人类社会的“专业化分工”思想,用到了神经网络设计中。从“全能医生”到“专科会诊”,从“稠密模型”到“混合专家”,MoE的出现告诉我们:AI的进步不一定靠“堆参数”,更靠“巧设计”。未来,随着负载均衡、推理优化等技术的突破,MoE大概率会成为大模型的主流架构,让AI在更高效、更精准的道路上越走越远。
如果你关注大模型领域,一定听过“GPT-4疑似采用MoE架构”“Mixtral 8x7B凭MoE碾压同参数稠密模型”这样的说法。当大家都在追逐模型参数规模时,混合专家模型(Mixture of Experts,简称MoE)却用“分而治之”的思路,掀起了一场效率革命。
作为AI初学者,不用被“专家”“门控”这些术语吓倒。今天这篇文章,我会用医院分诊、公司分工这样的生活化比喻,从核心思想、结构组成、工作流程到实际应用,带你彻底搞懂MoE到底是什么,以及它为什么能成为大模型的“效率密码”。
先来整体看下:
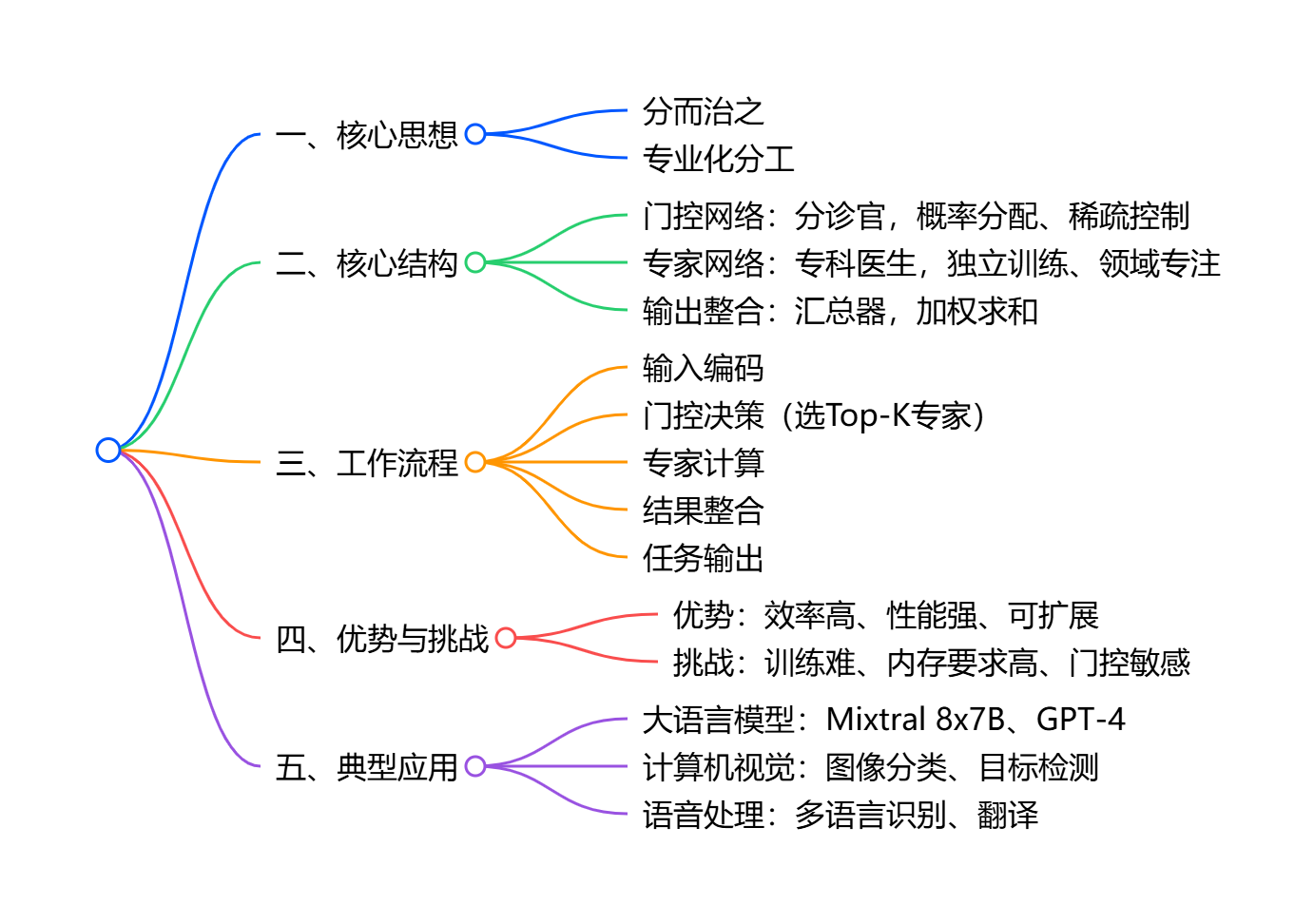
一、先搞懂核心逻辑:为什么需要“混合专家”?
在MoE出现之前,我们熟悉的大模型大多是“稠密模型”——就像一位“全能医生”,不管患者是感冒、心脏病还是皮肤病,都得亲自接诊。这种模式的问题很明显:
-
效率低下:处理简单问题时,动用全套复杂网络纯属浪费;遇到复杂问题,单一网络又可能“力不从心”。
-
成本高昂:参数规模扩大时,计算量和内存占用会同步飙升,训练千亿参数模型需要耗费上千万美元的算力。
-
专精不足:全能模型很难在所有细分领域都做到顶尖,就像全科医生在专科疾病上不如专科医生精准。
MoE的出现,就是为了解决这些痛点。它的核心灵感来自人类社会的“专业化分工”——就像医院会设置分诊台,把不同症状的患者分配给对应科室的专科医生;公司会划分不同部门,让市场、技术、运营各司其职。
简单来说,MoE把一个庞大的稠密模型,拆成多个小型“专家网络”,每个专家只专注处理某一类特定任务或数据;再配一个“门控网络”当“分诊官”,负责给输入数据“派活”;最后汇总专家的意见得到结果。这样一来,效率和精度就同时兼顾了。
二、三大核心组件:门控、专家、整合器各司其职
一个完整的MoE模型,就像一家高效运转的医院,由“分诊台(门控网络)”“专科医生(专家网络)”“会诊中心(输出整合模块)”三个核心部分组成。我们逐个拆解它们的作用:
1. 门控网络:输入数据的“智能分诊官”
门控网络是MoE的“大脑”,主要负责两件事:判断输入数据的类型,以及分配给最合适的专家。它就像医院的分诊护士,通过简单询问症状,就能把患者精准分到内科、外科或儿科。
具体来说,门控网络的工作逻辑是这样的:
-
接收输入:拿到经过编码的输入数据(比如文本转换后的向量)。
-
计算适配度:通过轻量级神经网络(比如简单的全连接层),计算每个专家对该输入的“适配概率”——就像分诊护士判断患者适合哪个科室的概率。
-
选择专家:为了保证效率,通常不会让所有专家都参与(否则就变回稠密模型了),而是选择概率最高的Top-K个专家(比如K=2或K=4)。这种“只激活部分专家”的机制,就是“稀疏MoE”的核心,也是效率提升的关键。
-
平衡负载:如果门控网络一直把活派给某几个“明星专家”,其他专家就会“闲置”,导致能力退化。所以门控网络会通过特殊的损失函数,确保所有专家都能得到合理的调用。
2. 专家网络:专注细分领域的“专科医生”
专家网络是MoE的“执行层”,每个专家都是一个独立的小型神经网络,专门处理某一类特定的数据。比如在大语言模型中,可能有这样的分工:
-
专家1:专门处理语法纠错、句式调整等语言规范问题;
-
专家2:专门处理逻辑推理、数学计算等理性任务;
-
专家3:专门处理情感分析、文案创作等感性任务。
这些专家的结构可以灵活设计,既可以是Transformer的前馈网络(FFN),也可以是卷积层、全连接层,具体取决于任务场景。关键优势在于:
-
参数独立:每个专家的参数单独训练,不用兼顾其他领域,能更快学到细分领域的核心特征;
-
按需调用:只有被门控网络选中时才工作,未被选中时完全“休息”,大幅节省计算资源。
3. 输出整合模块:汇总意见的“会诊中心”
当被选中的专家各自完成计算后,就需要一个“会诊中心”来汇总结果——这就是输出整合模块的作用。它会根据门控网络给出的“适配概率”,对专家的输出进行加权求和。
举个简单的例子:如果门控网络判断某条情感分析的输入,专家3(情感分析专家)的适配概率是0.8,专家1(语言规范专家)的适配概率是0.2,那么最终输出就是:0.8×专家3的结果 + 0.2×专家1的结果。这样既保证了核心任务的精度,又兼顾了语言表达的规范性。
三、一步一步看流程:MoE如何处理一个具体任务?
光说组件可能有点抽象,我们以“文本情感分析”(判断一句话是正面、负面还是中性)为例,完整走一遍MoE的工作流程,看看它是如何运转的:
步骤1:输入编码——把文本变成模型能懂的“语言”
首先,我们输入一句话:“这部电影的剧情超精彩,就是特效有点拉胯”。模型会通过词嵌入、位置编码等技术,把这句话转换成一个向量(数字组合),这是所有神经网络都能理解的“通用语言”。
步骤2:门控决策——给输入“派活”
门控网络接收这个向量后,开始计算每个专家的适配概率:
-
专家3(情感分析):适配概率0.7(核心任务是情感判断);
-
专家1(语言规范):适配概率0.2(需要判断语句是否通顺);
-
专家2(逻辑推理):适配概率0.1(涉及“剧情好但特效差”的转折逻辑)。
门控网络选择概率最高的Top-2专家:专家3和专家1,让它们参与处理。
步骤3:专家计算——专科医生“各司其职”
被选中的专家开始各自工作:
-
专家3(情感分析):分析“超精彩”是正面情绪,“有点拉胯”是轻微负面情绪,综合判断为“整体正面”,输出对应的向量;
-
专家1(语言规范):判断语句语法正确、表达流畅,输出“符合语言规范”的向量。
步骤4:结果整合——汇总出最终答案
输出整合模块根据门控网络的概率(0.7和0.2),对两个专家的输出进行加权求和,得到最终的特征向量。再把这个向量输入到分类层,输出结果:“正面情感,置信度0.85”。
整个过程中,专家2完全没有参与计算,节省了不必要的算力消耗;而参与的专家又都是各自领域的“高手”,保证了结果的精度。
四、优势与挑战:MoE不是“万能药”
MoE能成为大模型领域的“香饽饽”,自然有其不可替代的优势,但它也不是没有短板。了解这些 pros and cons,能帮我们更理性地看待这项技术。
核心优势:效率与性能的“双赢”
-
算力效率飙升:稀疏激活机制让计算量不再随参数规模同步增长。比如一个有100个专家的MoE,每次只调用2个,计算量仅为同参数稠密模型的2%。这意味着用同样的算力,能训练更大规模的模型;
-
模型性能更强:专业化分工让每个专家都能深耕细分领域,比全能模型更精准。比如Mixtral 8x7B(8个70亿参数专家)的性能,能媲美甚至超过700亿参数的稠密模型;
-
扩展性极佳:要提升模型能力,不用重构整个网络,只需增加新的专家即可。比如需要处理多语言任务,就新增几个“小语种专家”。
主要挑战:看似美好,实则有“坑”
-
训练难度高:最头疼的是“负载均衡”问题——门控网络可能会“偏心”,反复调用某几个专家,导致其他专家“饥饿”,训练不充分;另外,单个专家只处理部分数据,容易出现过拟合;
-
推理内存压力大:推理时需要加载所有专家的参数(即使只调用部分),对内存的要求比稠密模型更高。比如Mixtral 8x7B需要加载560亿参数,对显卡的显存要求不低;
-
门控设计敏感:门控网络的“分诊能力”直接决定了MoE的效果。如果门控分配不合理(比如把情感分析任务派给了逻辑推理专家),模型性能会大幅下降。
五、实际应用:那些采用MoE的明星大模型
如今,MoE已经从学术研究走向了工业界,成为众多顶尖大模型的核心架构。这些实际案例,能让我们更直观地感受到MoE的价值。
1. 大语言模型:MoE的“主战场”
-
Mixtral 8x7B:最出圈的MoE大模型之一,由Mistral AI推出。它包含8个70亿参数的专家,每次调用2个,性能媲美700亿参数的Llama 2,但推理速度快3倍。凭借“小参数规模+高性能”的优势,成为很多开发者的首选;
-
GPT-4:虽然OpenAI没有官方确认,但业界普遍推测GPT-4采用了MoE架构。有消息称它包含16个专家,每个专家有1110亿参数,通过稀疏激活实现了“万亿级参数的性能”,同时控制了推理成本;
-
PaLM-E:谷歌的多模态大模型,将文本和图像信息融合。它采用MoE架构,让不同的专家分别处理文本、图像以及跨模态融合任务,实现了“文生图”“图生文”的高效联动。
2. 计算机视觉:给图像“分专家”
在图像任务中,MoE也能发挥作用。比如在图像分类任务中,可以让不同的专家分别处理图像的纹理、形状、颜色等特征;在目标检测任务中,让专家1专门检测行人,专家2专门检测车辆,专家3专门检测交通标志。这种分工能大幅提升检测的准确率和速度。
3. 语音处理:多语言任务的“救星”
处理多语言语音识别时,MoE的优势更明显。可以为每种语言(或语系)设置专门的“语言专家”,门控网络根据输入语音的语言特征,分配给对应的专家。这样一来,模型在处理小语种时,也能有很高的识别准确率,避免了“一刀切”的弊端。
六、初学者学习建议:从“理解”到“实践”
如果你想深入学习MoE,不用一开始就啃复杂的论文。这里给初学者提3点建议,帮你快速入门:
-
先搞懂“稀疏激活”核心:MoE的效率本质来自“稀疏性”——只激活部分专家。先理解这个核心逻辑,再去研究门控网络的设计、负载均衡的实现等细节,会更轻松;
-
动手实现简易版MoE:用PyTorch或TensorFlow,搭建一个包含2-4个专家的简单MoE,处理MNIST手写数字分类或文本情感分析任务。比如用全连接层做专家,用单层神经网络做门控,亲身体验“分而治之”的效果;
-
精读经典论文:入门后可以读MoE的经典论文《Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer》,这篇论文详细介绍了MoE在Transformer中的应用,是理解工业级MoE的关键。
总结:MoE的本质是“高效协作”
最后我们回到开头的问题:MoE到底是什么?它不是什么高深莫测的黑科技,而是把人类社会的“专业化分工”思想,用到了神经网络设计中。
从“全能医生”到“专科会诊”,从“稠密模型”到“混合专家”,MoE的出现告诉我们:AI的进步不一定靠“堆参数”,更靠“巧设计”。未来,随着负载均衡、推理优化等技术的突破,MoE大概率会成为大模型的主流架构,让AI在更高效、更精准的道路上越走越远。
如果你还有关于MoE的疑问(比如门控网络的具体代码实现、负载均衡的损失函数设计),欢迎在评论区交流~ 觉得有帮助的话,别忘了点赞收藏,关注我一起学习AI技术!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 26
26 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)