DeepSeek 的恐怖时刻还未到来:V3.2 逼近 Gemini 3,但这只是“缺算力”版本
DeepSeek 的技术报告向来以坦诚著称,这次也不例外。他们在“局限性”部分直言:由于总训练 FLOPs(浮点运算次数)较少,V3.2 在世界知识的广度上仍落后于 Gemini 3.0 Pro 等顶级闭源模型。不盲目等待更大的基础模型,而是先用一年时间,将合成数据、自我验证和大规模 RL 的方法论打磨到极致,探明后训练时代的上限。V3.2证明了“自我进化式工程”在通用效率上的威力;Special

就在上周,OpenAI 前首席科学家、现任 SSI 掌门人 Ilya Sutskever 在播客中抛出了一枚震撼行业的“烟雾弹”:他认为过去五年主导 AI 发展的“Scaling Age”(规模化时代)已近黄昏。预训练数据的枯竭意味着,单纯依靠堆砌 GPU 将模型放大百倍,已不再能保证质的飞跃。在他看来,行业正被迫回归以纯粹研究为核心的时代,唯一的区别是我们现在手握巨大的算力。这一言论,似乎为盛传已久的“Scaling Law 撞墙论”盖上了官方印章。
然而,仅仅数日之后的 12 月 1 日,大洋彼岸的 DeepSeek 便用 V3.2 和 V3.2-Speciale 两款新模型,给出了一份截然不同的答卷。
拒绝“撞墙论”:DeepSeek 的反击宣言
模型发布后,DeepSeek 研究员 Zhibin Gou 在社交媒体上的发言,不仅是对新产品的介绍,更像是一份技术宣言:
“如果说 Gemini-3 证明了预训练规模仍有挖掘空间,那么 DeepSeek-V3.2-Speciale 则向世界展示了在大规模上下文语境下,强化学习(RL)惊人的扩展潜力。我们耗时一年将 DeepSeek-V3 推向极限,得出的核心信条是:与其被动等待更强的基础模型,不如通过优化方法论和数据,主动打破训练后的瓶颈。 ”
他更是直言不讳地补充道:“持续扩大模型规模、数据量、上下文和强化学习投入。别让那些‘遭遇瓶颈’的杂音阻挡你前进的步伐。”
在全行业都在焦虑 Scaling Law 是否失效的当下,DeepSeek 团队这番罕见的高调发声意味深长。他们用实打实的代码和模型证明:Scaling Law 并没有死,它只是从“预训练”的战场,转移到了“后训练”和“推理”的战场。
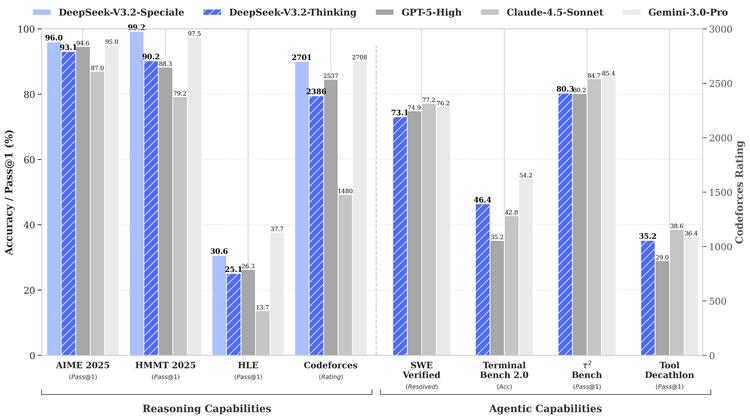
虽然行业内普遍承认后训练(Post-training)的重要性,但敢于将超过预训练成本 10% 的算力预算“豪赌”在强化学习上的企业,DeepSeek 仍是凤毛麟角。他们不仅是这条路线的信徒,更是将其工程化、规模化的先行者。
此次发布的双子星模型,正是这一激进路线的结晶:V3.2 旨在成为对标 GPT-5 的日常主力;而 Speciale 则剑指极限推理,对标 Gemini 3.0 Pro,并已将四枚国际竞赛金牌收入囊中。
V3.2:极致效率的通用主力
V3.2 是 9 月实验版 V3.2-Exp 的正式继承者,其核心使命是在“推理能力”与“输出成本”之间寻找完美的平衡点。
在硬核的推理类基准测试中,V3.2 已然跻身 GPT-5 的同温层:AIME 2025 数学竞赛得分 93.1%(GPT-5 为 94.6%),HMMT 2025 二月赛得分 92.5%(GPT-5 为 88.3%),LiveCodeBench 代码评测得分 83.3%(GPT-5 为 84.5%)。更关键的是,相比 Kimi-K2-Thinking 等竞品,V3.2 在保持性能的同时,通过严格的 Token 约束和长度惩罚机制,实现了更省、更快、更经济的输出。
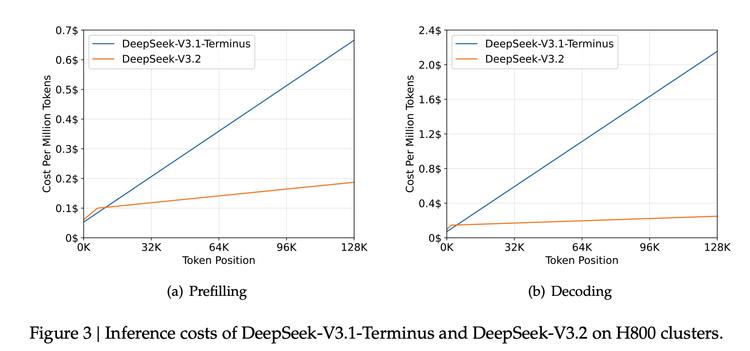
底层架构的革新:DeepSeek Sparse Attention (DSA) V3.2 的效率秘密源于架构层面的突破——引入 DeepSeek 稀疏注意力机制(DSA)。这项技术将计算复杂度从传统的 O(L²) 降维打击至 O(Lk)。经过两个月的实战验证,DeepSeek 确认了 DSA 的巨大价值:在标准 Benchmark 和 ChatbotArena 评分持平甚至略优于全量注意力模型的前提下,大幅释放了算力效率。这意味着 DeepSeek 赌对了方向:稀疏注意力是通往高效能的必经之路。
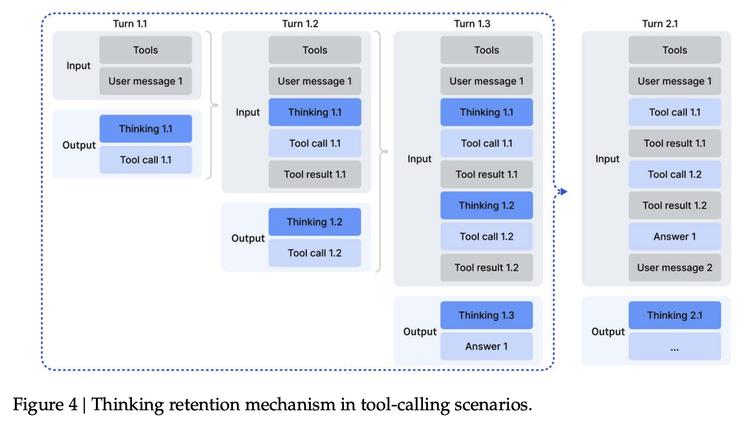
打破“思考”与“行动”的隔阂 V3.2 还达成了一项重要成就:它是首个将“深度思考”与“工具调用”无缝融合的模型。包括 OpenAI o 系列在内的过往推理模型,往往在进入思考模式后便无法操作外部工具。V3.2 打破了这一桎梏,无论是否处于思考模式,都能灵活调用工具,极大地扩展了其实用边界。
Agent 能力的“合成”进化 技术报告中最引人注目的篇章,在于其 Agent 能力的训练方法论。DeepSeek 构建了一套包含 1800+ 环境和 85000+ 复杂指令的大规模任务合成流水线。其核心哲学是**“难解答,易验证”**。
以旅行规划为例,搜索空间巨大,但验证方案是否合规却极易自动化。这种特性天然契合强化学习,模型无需人工标注,仅凭大量的自我尝试和明确的对错反馈即可进化。结果显示,仅依靠合成数据进行 RL 训练的模型,在 Tau2Bench 等基准测试中取得了显著提升,证明了这种泛化能力的真实性,而非单纯的“刷榜”技巧。
V3.2-Speciale:以“过程正义”换取极限逻辑
如果说 V3.2 是通过克制来追求效率,那么 Speciale 则是通过“放纵”来追求深度。作为“长思考增强版”,Speciale 被设计为放宽长度限制,鼓励模型进行更深层次的思维推演。
技术报告中的数据揭示了一个有趣的现象:在 AIME 2025 测试中,Speciale 的输出高达 23k tokens,远超 GPT-5 High 的 13k 和 Gemini 3.0 Pro 的 15k;在 Codeforces 上,其输出量甚至是 Gemini 的 3.5 倍。
然而,得益于 DeepSeek 激进的定价策略和 DSA 带来的效率红利,即便 Speciale “想得更多”,其使用成本依然对竞争对手构成降维打击:比 GPT-5 便宜约 25 倍,比 Claude Opus 4.5 便宜约 62 倍。
从数学证明到通用逻辑的泛化 Speciale 的核心价值在于验证了一个关键假设:对推理“过程”的监督,可以从数学领域泛化到更广泛的逻辑任务中。
继承自 DeepSeekMath-V2 的“生成器-验证器”双模型架构在这里大放异彩。生成器负责产出,验证器负责找茬,两者在动态博弈中同步提升。DeepSeek 成功将这套原本用于数学定理证明的“过程监督”机制,迁移到了代码生成和通用逻辑任务中。这意味着“自我验证”不再是数学极客的专属工具,而已成为一种通用的能力提升范式。
结语:当 DeepSeek 补齐最后一块拼图
DeepSeek 的技术报告向来以坦诚著称,这次也不例外。他们在“局限性”部分直言:由于总训练 FLOPs(浮点运算次数)较少,V3.2 在世界知识的广度上仍落后于 Gemini 3.0 Pro 等顶级闭源模型。
但这恰恰暴露了 DeepSeek 的战略定力:不盲目等待更大的基础模型,而是先用一年时间,将合成数据、自我验证和大规模 RL 的方法论打磨到极致,探明后训练时代的上限。
如今,方法论已验证成功:
- V3.2 证明了“自我进化式工程”在通用效率上的威力;
- Speciale 证明了过程奖励与自我验证在高阶逻辑推理中的可行性。
两条路径殊途同归:未来的 AI 进化不再依赖人力堆砌,而是依靠合成环境中的自我博弈。
DeepSeek 下一步的计划已在报告中明示:扩大预训练算力,补齐知识短板。
这不禁让人产生巨大的遐想: 回顾过去一年,从 Janus 的多模态统一,到 Math-V2 的自我验证,DeepSeek 在 V3 这个基座上已经迭代出了惊人的创新。那么,当一个参数规模更大、训练数据更足的 V4 或 R2 问世,并叠加这些已经验证成熟的方法论时,会发生怎样的化学反应?
或许,当算力缺口被补齐的那一刻,我们看到的将不再是一个传统的“语言模型”,而是一个具备长期记忆、能感知多模态环境、并在真实交互中持续自我进化的智能体。在英伟达高端算力受限的背景下,DeepSeek 如何解决算力来源虽是未知数,但一个“完全体”的 DeepSeek 下一代模型,无疑是目前 AI 领域最值得期待的变量。想要在职场中脱颖而出?点击→立即尝试 让 AI 成为你职业成功的加速器!🚀

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 14
14 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)