一文详解!大模型为什么需要KV缓存是何动机与原理?为什么Q不用缓存?看这一篇就够了!!
文章详细介绍了大模型中KV缓存机制的动机、原理及实现。KV缓存通过缓存自注意力计算中的Key和Value,避免了生成式模型推理过程中的重复计算,显著提高推理速度,尤其对长序列处理优势明显。文章通过图解和代码实现,对比了有无KV缓存时的推理过程差异,并探讨了在张量并行环境下的应用,是理解LLaMA等大模型加速技术的关键。
前言
我们都知道,现在各个大模型在整体的网络结构上基本上并没有太大差异,都是基于 Transformer 中的 Docoder 改进而来,所以基本也就是对其中的模块或使用顺序进行了替换或优化,因此为了后面能够更好的理解 LLaMA 2 模型的原理,掌柜依旧会先逐一介绍其中各个小的模块的原理及实现,然后再来整体看 LLaMA 2 模型。
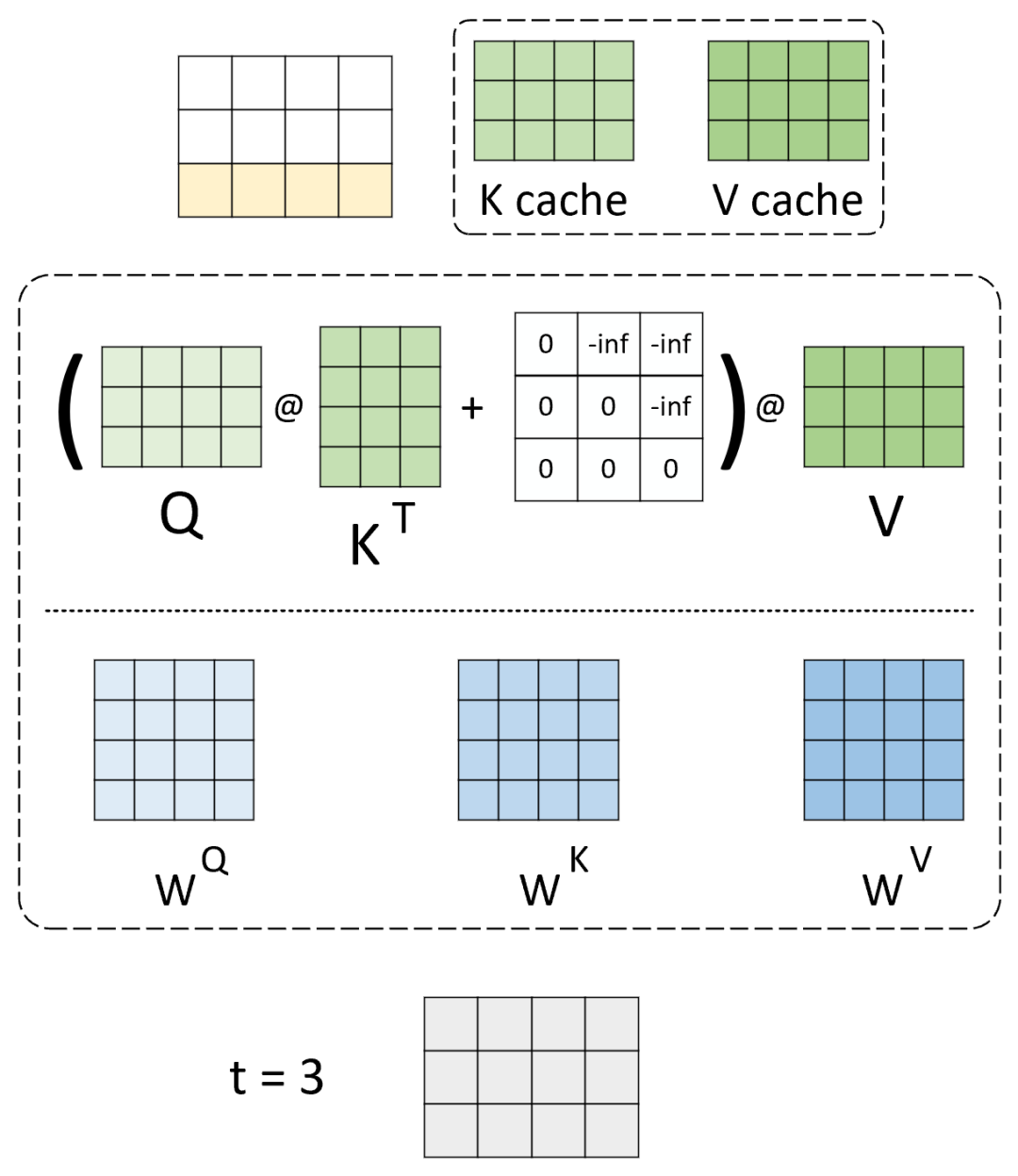
使用 KV 缓存自注意力计算过程
因此,在今天这篇文章中,掌柜想要和大家介绍的便是大模型当中都会使用到的 Key-Value Cache ,简称 KV Cache。
1 动机
由于在生成式模型(如 Transformer 解码器)的推理过程中,token 是逐时刻解码生成得到,每个时刻新生成 token 时都需要将先前所有已生成的 tokens 重新输入到模型中,所以这就会带来巨大的计算冗余和重复,使得解码过程越来越慢。
例如在解码生成第 时刻时,会将第 到 时刻的 token 都输入到模型中进行编码;而在生成第 时刻时,又会将第 到 时刻的 token 都输入到模型中进行编码,其中第 到 时刻就会涉及到重复计算的问题。
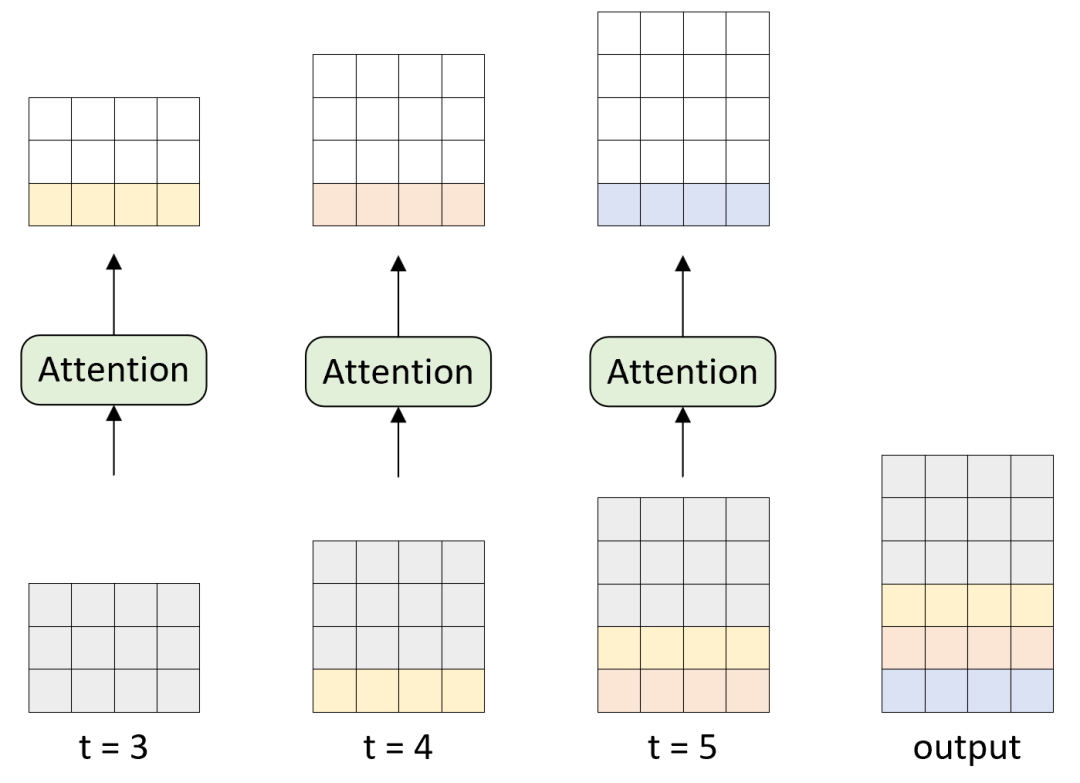
图 1. 推理解码过程图
如图1所示,模型输入 prompt 的长度为 3,在对 时刻解码时会将整个 prompt 作为输入然后解码得到一个长度为 3 的张量,并取最后一个时刻作为 时刻的生成结果;在对 时刻解码时,会将 时刻的输入与输出拼接起来作为输入生成 时刻的结果;后续以此类推。
可以看出整个过程中会涉及到大量重复和冗余的计算。
注意这里的两个关键词“重复”冗余“”,重复代表着需要去重,而冗余则是要去掉。
有人可能会问,那训练阶段为什么不会呢?
这因为在训练阶段是一次性将整个样本输入到模型中(通过注意力掩码 attention mask 来使得编码当前时刻注意力只能关注到过去的信息而不能看到未来的信息),且所有时刻的输出都将用于损失计算,所以不存在重复或无用计算的问题。
因此,为了避免这种重复和冗余的计算的工作,Key-Value 缓存应运而生。简单来说,它在每次的自注意力计算过程中,都会将此时计算得到的 Key 和 Value 进行缓存,后续在生成下一个时刻的 token 时,模型只需对当前时刻输入的一个 token 计算隐藏状态,再把缓存与该隐藏状态拼接即可得到完整的隐藏状态 Key 和 Value,这样就能显著加快推理速度,而这在长序列或交互式应用中优势非常明显。
2 不采用 KV 缓存推理过程
在介绍完 KV 缓存出现的动机以后,我们再来看 KV 缓存的原理到底是什么样的。
不过为了让大家更好的理解整个过程,掌柜先来带大家通过图示的方式来回顾一下没有 KV 缓存时的完整计算过程,以便稍后将两者进行对比,以便更容易理解。
2.1 计算原理图解
下面,我们依旧以图1中的情境为例进行说明。
首先,我们需要明白的是当模型训练完成以后,在推理过程中各个权重参数是固定不变的,因此对于同样的输入部分,其输出结果也是不变的,这一前提我们要知道。
假定现在有一个训练完成的模型将用于推理任务,为了便于介绍我们只考虑涉及到 KV 缓存的部分,即自注意力机制的计算过程,如图2所示。
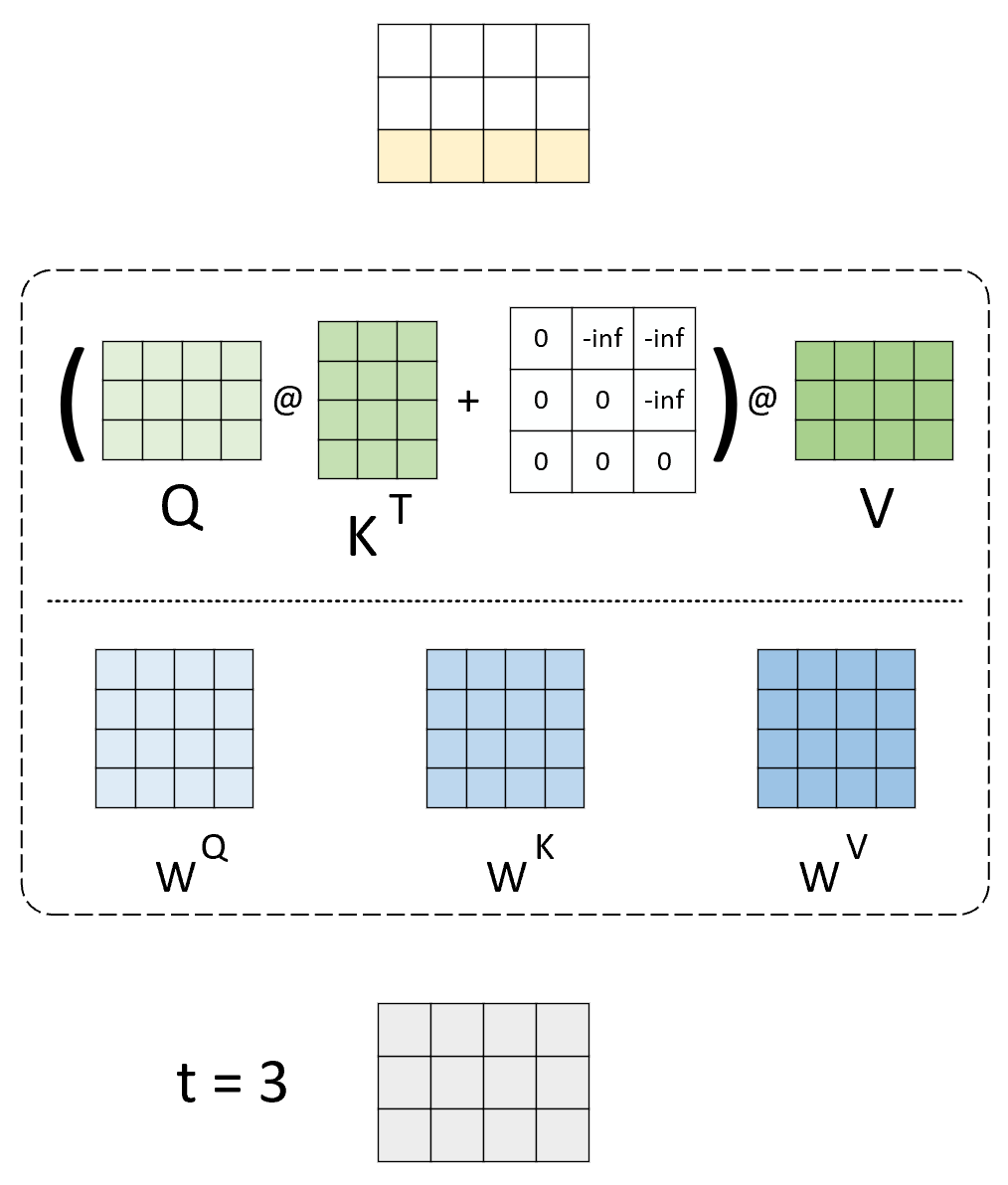
图 2. 不采用 KV 缓存自注意力计算过程,‘()’ 表示 Softmax 操作
在图2所示的示例中,原始 prompt 输入为一个长度为 3 的序列,输入到模型已经首先完成 3 个线性变换分别计算得到 、 和 ,进一步完成注意力权重的计算已经最终的输出,即最上方的结果。这里需要注意的是,因为这是在推理阶段,所以在对输入序列进行编码时需要进行 attention mask 操作,以保证当前时刻不能看到未来信息。在得到第 时刻的整个输出以后,模型将会取结果的最后一个时刻作为 时候的生成结果。
此时,我们可以得到第一个结论:在对第 个时刻解码时,生成内容中前 个时刻的结果是无用的。
进一步,开始依次进行后续时刻的解码生成,如图3所示。
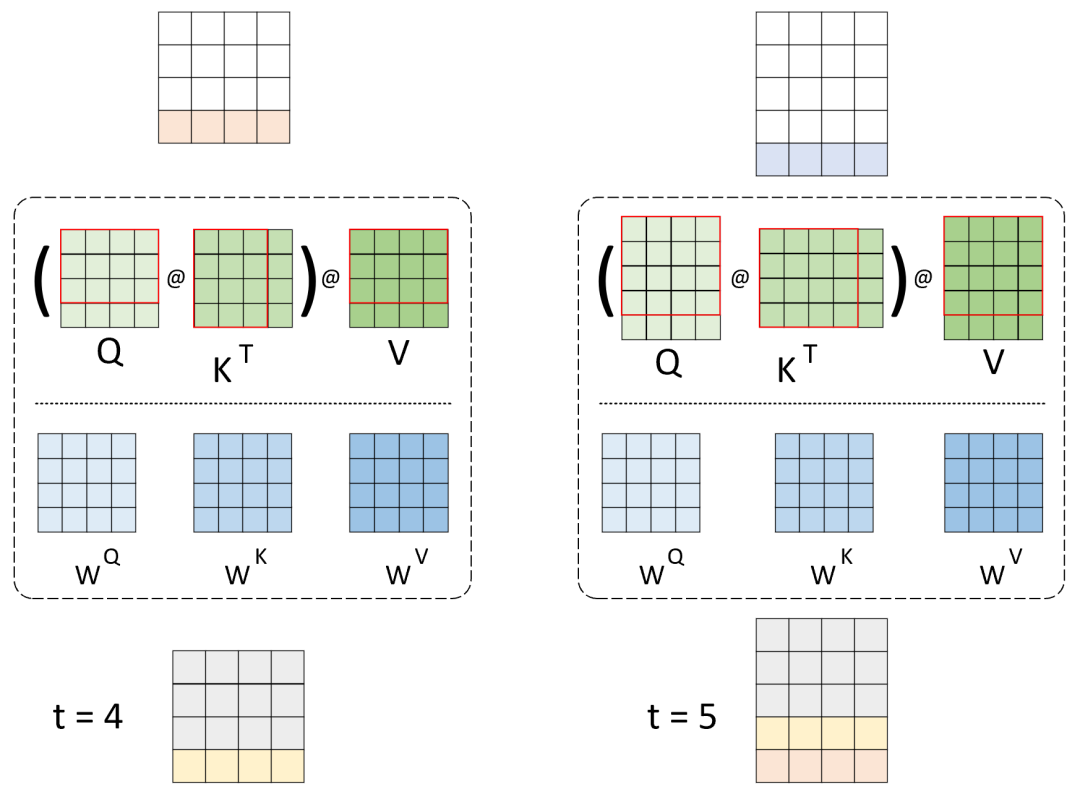
图 3. 不采用 KV 缓存自注意力计算过程,‘()’ 表示 Softmax 操作
在图4中,模型对第 时刻解码时,会将整个 prompt 以及到当前时刻为止已经生成的内容拼接起来作为输入来生成当前时刻的结果。同理,此时的输入首先将完成 3 个线性变换分别计算得到 、 和 ,然后进行后续计算。此时我们可以发现,在第 时刻时,其输入序列的前 3 个 token (图中灰色部分)在第 时刻中已经分别进行过了一次同 、 和 的线性变换,也就是说此时 、 和 这3个矩阵的前三行都是之前已经计算过的(图中红框中的内容),这里是在重复计算。
进一步,得到 、 和 后将完成自注意力计算过程并得到最后的输出。这里需要注意的是,因为此时已经是逐时刻进行解码,模型可以看到当前时刻之前的所有信息,所以不再需要进行 attention mask 操作。同时,我们已经可以知道,对于 的输出结果,依旧只会取最后一个时刻对应的结果作为 时刻生成的内容,其余时刻的结果无用。
当第 时,其生成过程完全与上述过程一致,大家可以自行默想。
此时此刻掌柜相信大家已经发现了其中的门道:
① 如果我们每次在进行解码生成时,都将当前时刻计算得到的 和 进行缓存,那么在下一时刻进行解码时就不需要再重复计算对应的结果,这就是解决前面提到的“重复计算”的问题;
② 因为只取每个时刻输出结果的最后一个时刻作为当前时刻的生成结果,所以在①的基础上,当前时刻的输入仅使用上一时刻的输出的最后一个时刻即可,不需要和先前的输入拼接,这就是解决前面提到的“冗余计算”的问题;
③ 基于对于②的理解,所以我们不需要对 进行缓存,因为后面根本用不到。
上面这两点就是 KV 缓存的核心思想。下面我们先来通过一个示例来模拟一下不采用 KV 缓存推理时的整个过程。
2.2 从零开始实现
首先,我们来快速实现多头注意力机制的计算过程,代码如下所示:
1 class Attention(nn.Module):2 def __init__(self, embed_dim=64, num_heads=8):3 super().__init__()4 self.num_heads = num_heads5 self.embed_dim = embed_dim6 self.head_dim = embed_dim // num_heads7 assert self.head_dim * num_heads == self.embed_dim8 self.wq = nn.Linear(self.embed_dim, self.embed_dim, bias=False)9 self.wk = nn.Linear(self.embed_dim, self.embed_dim, bias=False)10 self.wv = nn.Linear(self.embed_dim, self.embed_dim, bias=False)11 self.wo = nn.Linear(self.embed_dim, self.embed_dim, bias=False)1213 def forward(self, x: torch.Tensor, mask=None):14 bsz, seq_len, _ = x.shape15 xq, xk, xv = self.wq(x), self.wk(x), self.wv(x)16 # [ bsz, seq_len, embed_dim] @ [embed_dim, embed_dim] = [ bsz, seq_len, embed_dim]17 xq = xq.view(bsz, seq_len, self.num_heads, self.head_dim) # [bsz, seq_len, num_heads, head_dim]18 keys = xk.view(bsz, seq_len, self.num_heads, self.head_dim) # [bsz, seq_len, num_heads, head_dim]19 values = xv.view(bsz, seq_len, self.num_heads, self.head_dim) # [bsz, seq_len, num_heads, head_dim]20 print(f"keys(values) shape [bsz, seq_len, num_heads, head_dim]: {values.shape}")21 xq = xq.transpose(1, 2) # [bsz, num_heads, seq_len, head_dim]22 keys = keys.transpose(1, 2) # [bsz, num_heads, seq_len, head_dim]23 values = values.transpose(1, 2) # [bsz, num_heads, seq_len, head_dim]24 scores = torch.matmul(xq, keys.transpose(2, 3)) / math.sqrt(self.head_dim)25 if mask isnotNone: # [1, 1, seq_len, seq_len]26 scores = scores + mask27 scores = F.softmax(scores.float(), dim=-1).type_as(xq)28 output = torch.matmul(scores, values) # [bsz, num_heads, seq_len, head_dim]29 output = output.transpose(1, 2).contiguous().view(bsz, seq_len, -1)30 return self.wo(output)
上述代码就是多头注意力的完整实现过程,已经对相关变量的形状进行了清晰地标注,相信大家对这部分内容已经非常熟悉,在这里就不再赘述。
2.3 推理过程模拟
进一步,我们来完模拟整个解码过程,示例代码如下:
1 if __name__ == '__main__':2 start_pos = seq_len = 33 bsz = 34 embed_dim, num_heads = 4, 25 total_len = 106 input_embeddings = torch.randn([bsz, seq_len, embed_dim])7 attn = Attention(embed_dim=embed_dim, num_heads=num_heads, max_batch_size=10)8 for cur_pos in range(start_pos, total_len):9 print(f" =========== decoding at pos: {cur_pos} ============")10 print(f"input_embeddings shape [bsz, seq_len, embed_dim]: {input_embeddings.shape}")11 _, seqlen, _ = input_embeddings.shape12 mask = None13 if cur_pos == start_pos:14 mask = torch.full((1, 1, seqlen, seqlen), float("-inf"))15 mask = torch.triu(mask, diagonal=1)16 print(mask)17 print(f"mask shape [1, 1, seq_len, seq_len]: {mask.shape}]")18 output = attn(input_embeddings, mask) # [bsz, seq_len, embed_dim]19 print(f"attention output shape [bsz, seq_len, embed_dim]: {output.shape}")20 next_token_hidden = output[:, -1].unsqueeze(1) # [bsz, 1, embed_dim]21 print(f"next_token_hidden shape [bsz, 1, embed_dim] : {next_token_hidden.shape}")22 input_embeddings = torch.cat([input_embeddings, next_token_hidden], dim=1)
在上述代码中,第2行定义初始序列的长度,也就是 prompt 的长度, 其中 start_pos 表示从 时刻开始解码生成。第 3~5 行是定义模型的相关参数。第6行是随机生成一个输入序列经过 embedding 后的结果,将作为初始输入。第7行是实例化一个多头注意力模块,这里我们将其简单的看成是解码器。第8行是开始逐时刻进行解码。第11~17行是构建对 prompt 编码时所需要的 attention mask 输入。第18、20行是得到当前时刻的解码输出,然后取最后一个时刻作为结果,并将其扩维到 [bsz, 1, embed_dim]。第22行则是将当前时刻的输入和结果拼接起来,作为下一个时刻的输入,并再次解码生成。
理解上述代码的时候,建议对照上面的图示过程。以上完整示例代码可参见 Code/C06_SelfAttention/C01_attention_no_kv_cache.py 文件。
2.4 输出结果分析
在上述代码执行结束以后,将会得到类似如下结果:
1 =========== decoding at pos: 3 ============2 input_embeddings shape [bsz, seq_len, embed_dim]: torch.Size([3, 3, 4])3 tensor([[[[0., -inf, -inf],4 [0., 0., -inf],5 [0., 0., 0.]]]])6 mask shape [1, 1, seq_len, seq_len]: torch.Size([1, 1, 3, 3])]7 keys(values) shape [bsz, seq_len, num_heads, head_dim]: torch.Size([3, 3, 2, 2])8 attention output shape [bsz, seq_len, embed_dim]: torch.Size([3, 3, 4])9 next_token_hidden shape [bsz, 1, embed_dim] : torch.Size([3, 1, 4])1011 =========== decoding at pos: 4 ============12 input_embeddings shape [bsz, seq_len, embed_dim]: torch.Size([3, 4, 4])13 keys(values) shape [bsz, seq_len, num_heads, head_dim]: torch.Size([3, 4, 2, 2])14 attention output shape [bsz, seq_len, embed_dim]: torch.Size([3, 4, 4])15 next_token_hidden shape [bsz, 1, embed_dim] : torch.Size([3, 1, 4])1617 =========== decoding at pos: 5 ============18 input_embeddings shape [bsz, seq_len, embed_dim]: torch.Size([3, 5, 4])19 keys(values) shape [bsz, seq_len, num_heads, head_dim]: torch.Size([3, 5, 2, 2])20 attention output shape [bsz, seq_len, embed_dim]: torch.Size([3, 5, 4])21 next_token_hidden shape [bsz, 1, embed_dim] : torch.Size([3, 1, 4])2223 =========== decoding at pos: 6 ============24 input_embeddings shape [bsz, seq_len, embed_dim]: torch.Size([3, 6, 4])25 keys(values) shape [bsz, seq_len, num_heads, head_dim]: torch.Size([3, 6, 2, 2])26 attention output shape [bsz, seq_len, embed_dim]: torch.Size([3, 6, 4])27 next_token_hidden shape [bsz, 1, embed_dim] : torch.Size([3, 1, 4])2829 =========== decoding at pos: 7 ============30 input_embeddings shape [bsz, seq_len, embed_dim]: torch.Size([3, 7, 4])31 keys(values) shape [bsz, seq_len, num_heads, head_dim]: torch.Size([3, 7, 2, 2])32 attention output shape [bsz, seq_len, embed_dim]: torch.Size([3, 7, 4])33 next_token_hidden shape [bsz, 1, embed_dim] : torch.Size([3, 1, 4])3435 =========== decoding at pos: 8 ============36 input_embeddings shape [bsz, seq_len, embed_dim]: torch.Size([3, 8, 4])37 keys(values) shape [bsz, seq_len, num_heads, head_dim]: torch.Size([3, 8, 2, 2])38 attention output shape [bsz, seq_len, embed_dim]: torch.Size([3, 8, 4])39 next_token_hidden shape [bsz, 1, embed_dim] : torch.Size([3, 1, 4])4041 =========== decoding at pos: 9 ============42 input_embeddings shape [bsz, seq_len, embed_dim]: torch.Size([3, 9, 4])43 keys(values) shape [bsz, seq_len, num_heads, head_dim]: torch.Size([3, 9, 2, 2])44 attention output shape [bsz, seq_len, embed_dim]: torch.Size([3, 9, 4])45 next_token_hidden shape [bsz, 1, embed_dim] : torch.Size([3, 1, 4])
对于上述结果,大家可以自行进行分析,关键一点就是观察各个变量的输出形状。
看到这里,掌柜想要给大家抛出一个疑问,在真正的推理场景中不同用户同时向模型发起请求,那么同一个时间段内模型接收到的多个样本长度肯定是不一样的,那么此时将其作为一个 batch 输入到模型中进行解码生成应该如何处理呢?
换句话说,在一个 batch 中,prompt 的初始长度不同,如何根据 prompt 同时生成多个样本的输出内容?
最后
为什么要学AI大模型
当下,⼈⼯智能市场迎来了爆发期,并逐渐进⼊以⼈⼯通⽤智能(AGI)为主导的新时代。企业纷纷官宣“ AI+ ”战略,为新兴技术⼈才创造丰富的就业机会,⼈才缺⼝将达 400 万!
DeepSeek问世以来,生成式AI和大模型技术爆发式增长,让很多岗位重新成了炙手可热的新星,岗位薪资远超很多后端岗位,在程序员中稳居前列。

与此同时AI与各行各业深度融合,飞速发展,成为炙手可热的新风口,企业非常需要了解AI、懂AI、会用AI的员工,纷纷开出高薪招聘AI大模型相关岗位。
最近很多程序员朋友都已经学习或者准备学习 AI 大模型,后台也经常会有小伙伴咨询学习路线和学习资料,我特别拜托北京清华大学学士和美国加州理工学院博士学位的鲁为民老师给大家这里给大家准备了一份涵盖了AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频 全系列的学习资料,这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

AI大模型系统学习路线
在面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。

但知道是一回事,做又是另一回事,初学者最常遇到的问题主要是理论知识缺乏、资源和工具的限制、模型理解和调试的复杂性,在这基础上,找到高质量的学习资源,不浪费时间、不走弯路,又是重中之重。
AI大模型入门到实战的视频教程+项目包
看视频学习是一种高效、直观、灵活且富有吸引力的学习方式,可以更直观地展示过程,能有效提升学习兴趣和理解力,是现在获取知识的重要途径

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
海量AI大模型必读的经典书籍(PDF)
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。
600+AI大模型报告(实时更新)
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。
AI大模型面试真题+答案解析
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 11
11 0
0- 0



 已为社区贡献344条内容
已为社区贡献344条内容

所有评论(0)