【保姆级教程】我写了个 AI Agent,手机上就能自动验证漏洞扫描结果 (CentOS + Gemini + Telegram)
🧐 背景:为什么要做这个?
作为安全运营人员,最头疼的就是自动化扫描器(Nuclei/Httpx)时不时报出一堆结果。
-
痛点:有时候人在外面,手边没电脑,看到报警心痒痒,不知道是误报还是真“炸”了。
-
需求:我想把扫描结果转发给 Telegram 机器人,让它控制服务器去跑
curl验证,然后用 AI 帮我分析是真是假。
经过一番折腾(踩了不少坑),我终于在 CentOS VPS 上部署成功了。这篇文档记录了全过程,希望能帮到有同样需求的兄弟。
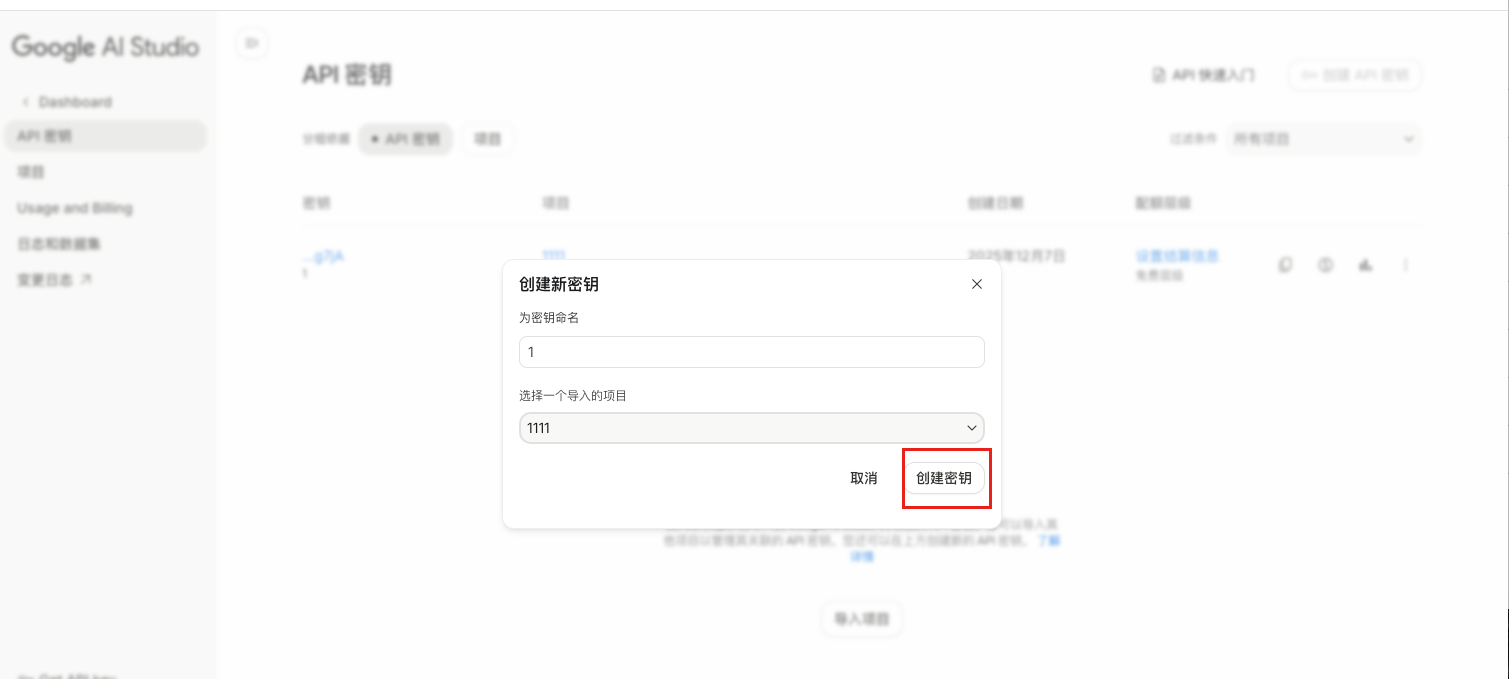
一、准备工作:获取 API
既然是 AI Agent,我们需要两个核心 Key:大脑(AI)和嘴巴(Telegram)。
1. Google Gemini API Key (大脑)
-
目前 Google 的 Gemini Flash 模型便宜且速度快,非常适合做这种分析。
-
申请地址:Google AI Studio
-
点击 "Get API Key" 即可。
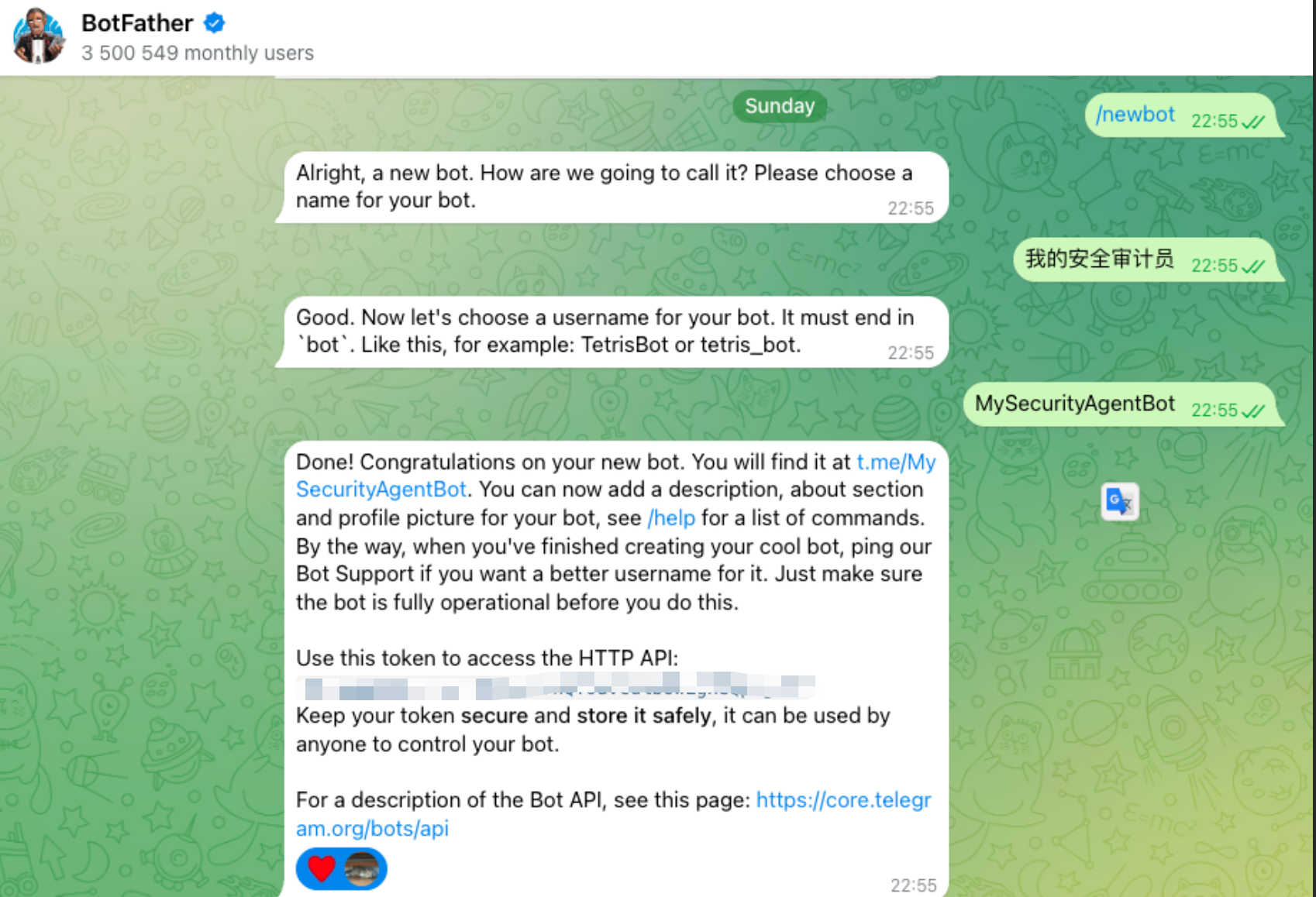
2. Telegram Bot Token (嘴巴)
-
打开 Telegram,搜索
@BotFather。 -
发送 /start ->
/newbot,按照提示给机器人起个名字。 -
你会得到一串 HTTP API Token,保存好它。
二、服务器环境部署 (CentOS 篇)
我的 VPS 是 CentOS 系统。这里重点说一下 CentOS 和 Ubuntu 在环境安装上的区别,也是我踩坑的地方。
1. 安装基础依赖
CentOS 的官方源比较“保守”,很多新软件(如 httpx, nodejs)默认源里没有,所以必须安装 EPEL 源。
# 安装 EPEL 源 (Extra Packages for Enterprise Linux)
# 相当于给系统加了一个“第三方扩展商店”
yum install epel-release -y
# 更新一下
yum update -y
2. Python 环境的区别
-
Ubuntu 用户:Python 被拆分很细,想用虚拟环境需单独装
sudo apt install python3-venv。 -
CentOS 用户(我):通常
python3包里已经自带了 venv 模块,直接用即可。
3. 安装安全工具
我们需要 httpx 或 curl 来让 Agent 调用。
# 安装 Go 语言环境 (因为 httpx 是 go 写的)
yum install go -y
# 安装 httpx
go install -v github.com/projectdiscovery/httpx/cmd/httpx@latest
# 软连接方便全局调用
ln -s /root/go/bin/httpx /usr/bin/httpx
#安装 Python3, pip, Node.js, npm 和基础工具(CentOS 使用 yum install 而不是 apt-get install)
yum install -y python3 python3-pip nodejs npm curl wget nano git unzip三、代码编写与部署
1. 创建项目与虚拟环境
这一步非常重要!为了不弄乱系统自带的 Python 环境,我们创建一个独立的空间。
# 创建目录
mkdir my_security_bot
cd my_security_bot
# 创建虚拟环境
python3 -m venv venv
# 激活虚拟环境 (注意:激活后你的命令行前缀会变)
source venv/bin/activate
# 安装依赖库
pip install google-generativeai pyTelegramBotAPI
2. 编写代码 (bot.py、.env)
我们需要解决两个核心问题:
-
AI 分析逻辑:怎么让 AI 像安全工程师一样思考?
-
消息过长报错:Telegram 单条消息限制 4096 字符,AI 分析长了发不出去怎么办?
ps:新建文件技巧:
在终端输入 nano bot.py,粘贴代码。
保存:按
Ctrl + O-> 回车。退出:按
Ctrl + X。
完整代码如下(含长消息自动分段修复):
我们通过在命令行输入:nano bot.py
(此时屏幕会变黑进入编辑器,直接复制粘贴下面的完整代码)
这里注意ai模型初始化的时候需要根据自己需要“问”一下 Google,你的账号到底能用哪些模型。
请在终端执行这条命令(curl "https://generativelanguage.googleapis.com/v1beta/models?key=你的apikey"),它会列出你当前 Key 能访问的所有模型列表,再在里面选取可用的模型填写在代码里面
import os
import subprocess
import telebot
import time # <--- 新增:引入 time 库,用于发送分段消息时的缓冲
from dotenv import load_dotenv
# 引入 Google 和 LangChain 库
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain.agents import tool, initialize_agent, AgentType
# 加载 .env 环境变量
load_dotenv()
# ================= 代理配置 =================
# os.environ["HTTP_PROXY"] = "http://127.0.0.1:7890"
# os.environ["HTTPS_PROXY"] = "http://127.0.0.1:7890"
GOOGLE_API_KEY = os.getenv("GOOGLE_API_KEY")
TELEGRAM_TOKEN = os.getenv("TELEGRAM_TOKEN")
if not GOOGLE_API_KEY or not TELEGRAM_TOKEN:
print("❌ 错误:未找到 Key 或 Token,请检查 .env 文件!")
exit(1)
# 初始化 Gemini Pro 模型
llm = ChatGoogleGenerativeAI(
model="gemini-2.5-flash",
google_api_key=GOOGLE_API_KEY,
temperature=0.1
)
# 定义工具
@tool
def execute_security_tool(command: str) -> str:
"""
执行安全命令。只允许: curl, ping, httpx, nmap, whois, dig。
输入例如: 'curl -I https://example.com'
"""
allowed_tools = ["curl", "ping", "httpx", "nmap", "whois", "dig"]
cmd_parts = command.strip().split()
if not cmd_parts:
return "❌ 命令为空"
if cmd_parts[0] not in allowed_tools:
return f"🚫 禁止执行未授权工具: {cmd_parts[0]}"
print(f"🤖 执行命令: {command}")
try:
result = subprocess.check_output(
command, shell=True, stderr=subprocess.STDOUT, timeout=45
).decode('utf-8', errors='ignore')
# 结果截断,防止 LLM 处理的数据量过大
if len(result) > 3000:
return result[:3000] + "\n...(内容过长截断)"
return result
except subprocess.TimeoutExpired:
return "⏰ 命令执行超时,目标可能无响应。"
except Exception as e:
return f"⚠️ 执行错误: {str(e)}"
# 初始化 Agent
tools = [execute_security_tool]
agent = initialize_agent(
tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True, handle_parsing_errors=True
)
# 启动 Telegram Bot
bot = telebot.TeleBot(TELEGRAM_TOKEN)
print("🚀 机器人正在启动...")
# ==================== 👇 新增的核心函数 👇 ====================
def send_safe_response(chat_id, text, reply_to_message_id=None):
"""
智能发送函数:
1. 处理超长消息(>4000字符自动切分)
2. 处理 Markdown 解析错误(自动降级为纯文本)
"""
max_length = 4000 # 留一些余量(官方限制4096)
# 按照长度切分消息
for i in range(0, len(text), max_length):
chunk = text[i:i+max_length]
try:
# 尝试以 Markdown 格式发送
if reply_to_message_id and i == 0:
# 第一段引用回复
bot.send_message(chat_id, chunk, parse_mode="Markdown", reply_to_message_id=reply_to_message_id)
else:
# 后续片段直接发送
bot.send_message(chat_id, chunk, parse_mode="Markdown")
except Exception as e:
print(f"⚠️ Markdown 发送失败 (可能是格式截断),尝试纯文本发送: {e}")
# 失败后,移除 parse_mode 再次尝试(此时一定能发出去)
if reply_to_message_id and i == 0:
bot.send_message(chat_id, chunk, reply_to_message_id=reply_to_message_id)
else:
bot.send_message(chat_id, chunk)
# 稍微暂停,防止触发 Telegram 频率限制
time.sleep(0.5)
# ==================== 👆 新增结束 👆 ====================
@bot.message_handler(func=lambda m: True)
def handle_message(message):
print(f"📩 收到指令: {message.text}")
bot.send_chat_action(message.chat.id, 'typing')
try:
prompt = (
"你是一名高级应用安全专家(AppSec Engineer),擅长漏洞验证与误报剔除。"
"用户会提供 Nuclei 或 Httpx 的扫描结果,你需要利用服务器上的工具(curl, nmap, httpx, whois, dig)进行人工复核(Triage)。"
"你的核心分析逻辑如下:"
"1. 【Httpx 结果分析 - Soft 404 识别】:"
" - 观察输入中是否有多个不同路径返回相同的 Content-Length 或 Hash(例如 [1494] [3acbfe...])。"
" - 如果存在,这极大概率是 Soft 404(误报)。"
" - **行动**:使用 curl 请求一个该域名下的随机不存在路径(如 /random_check_123),对比目标路径的响应头和包大小。如果一致,标记为【误报:Soft 404】。"
"2. 【Nuclei 结果分析 - 漏洞复现】:"
" - 对于 CVE 告警(如 CVE-2025-55182 WP用户枚举):使用 curl 访问相关接口(如 /wp-json/wp/v2/users),检查是否返回具体 JSON 数据。"
" - 对于信息泄露(如 .prettierrc.json, robots.txt, time.php):使用 curl 获取内容,判断是否包含敏感信息(如 API Key、内网 IP、系统路径),还是只是空文件或 HTML 报错。"
" - 对于端口服务(如 dameng-detect, snmp):如果是非常规端口,建议构造 nmap 命令检查端口开放情况。"
"3. 【执行规则】:"
" - 必须使用 `execute_security_tool` 执行命令,严禁通过想象回答。"
" - 执行 curl 时,建议加上 `-I` (只看头) 或 `-s` (静默) 参数,视情况加 `-k` (忽略证书)。"
" - 遇到 `wpcomstaging` 或 `test-api` 等测试环境域名,重点关注是否开启了 Debug 模式。"
"4. 【输出格式】:"
" - 对每个分析的目标,给出明确结论:【🔴 确认漏洞】、【🟡 疑似风险】、【🟢 误报/已修复】。"
" - 简要说明验证过程和证据。"
f"\n用户提供的扫描数据或指令: {message.text}"
)
response = agent.run(prompt)
# ==================== 👇 修改的部分 👇 ====================
# 原代码:bot.reply_to(message, response, parse_mode="Markdown")
# 修改为使用我们定义的安全发送函数:
send_safe_response(message.chat.id, response, reply_to_message_id=message.message_id)
# ==================== 👆 修改结束 👆 ====================
except Exception as e:
error_msg = f"机器人发生错误: {str(e)}"
print(error_msg)
# 报错信息通常比较短,可以直接发
bot.reply_to(message, error_msg)
if __name__ == "__main__":
bot.infinity_polling()再通过输入nano .env编写配置文件:
GOOGLE_API_KEY=AIzaS......
TELEGRAM_TOKEN=78.......四、运行与避坑
坑点:路径与环境变量
刚开始我直接用 python3 bot.py 运行,结果报错说找不到 telebot。
原因:因为刚才的依赖都装在 venv (虚拟环境) 里了,而系统默认的 python3 找不到它们。
正确运行姿势:
必须使用虚拟环境里的解释器路径:
# 方式一:先激活再运行
source venv/bin/activate
python bot.py
# 方式二(推荐):直接指定解释器路径,不用激活
/root/my_security_bot/venv/bin/python bot.py
进阶:使用 PM2 后台守护
为了防止 SSH 断开后机器人挂掉,建议使用 pm2。
# 安装 PM2 (需要先装 nodejs,CentOS 下需通过 EPEL 或 NVM 安装)
yum install nodejs npm -y
npm install pm2 -g
# 启动机器人
# 注意:interpreter 必须指向虚拟环境的 python!
pm2 start bot.py --name "security-bot" --interpreter ./venv/bin/python
五、效果展示与总结
现在,当我在外面收到扫描报告时,只需要把那行 URL 复制给机器人。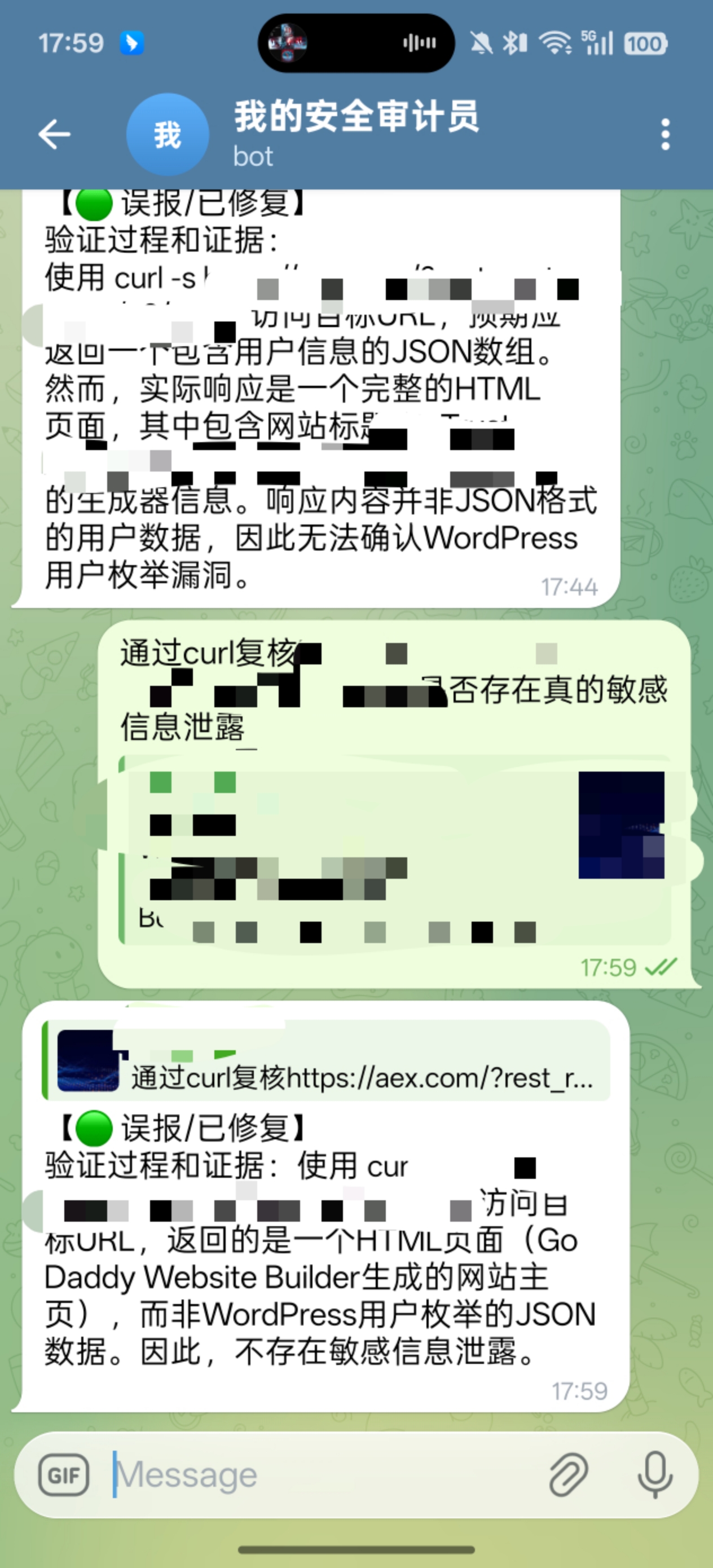
它会自动在服务器后台:
-
解析我的意图。
-
运行
curl -I或httpx。 -
通过 Gemini 1.5 Flash 快速分析响应包。
-
如果是 Markdown 格式错乱 或者 内容太长,它现在的自动分段代码也能完美处理,不会再报错退出了。
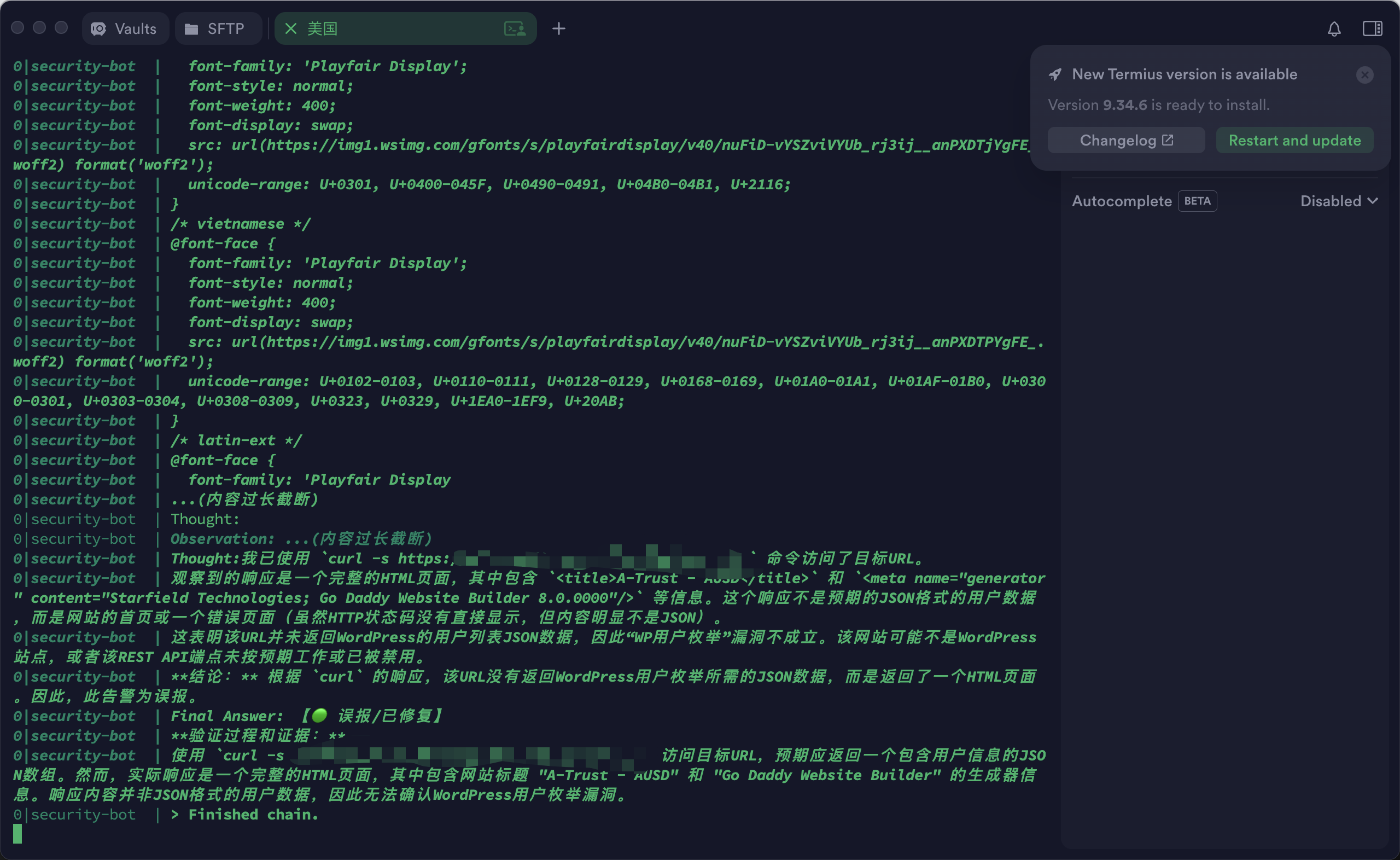
这就是 ChatOps 的魅力,希望能给各位安全佬一点启发!

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐



 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)