Temperature Scaling可大幅提高Test-Time Scaling瓶颈!
为了进一步提升性能,研究者提出了两种主要路径:一是通过强化学习(RL)训练模型生成更长、更复杂的推理轨迹,二是通过。在推理任务中,不同问题可能需要不同程度的探索:有些需要严格逻辑(偏好低温),有些需要创造性思维(偏好高温)。下,模型能解决的问题子集不同。这启发作者提出“温度缩放”的新思路:通过在不同温度下采样,整合模型的全部推理潜力。这就是“温度缩放”的核心思想——将样本均匀分配到不同温度,从而整
大型语言模型(LLMs)如GPT、Qwen等,在解决复杂推理问题(如数学、代码生成、逻辑推理)时表现出色。为了进一步提升性能,研究者提出了两种主要路径:一是通过强化学习(RL)训练模型生成更长、更复杂的推理轨迹,二是通过测试时扩展(Test-Time Scaling, TTS),在推理时生成多个候选答案并选择最佳结果。TTS的优势在于无需额外训练,计算效率高。

-
论文:On the Role of Temperature Sampling in Test-Time Scaling
-
链接:https://arxiv.org/pdf/2510.02611
然而,传统TTS方法主要依赖增加样本数量(K),即生成更多推理轨迹。本文发现,当K增大到一定程度后,性能提升停滞,部分“难题”始终无法解决。令人惊讶的是,不同采样温度(Temperature) 下,模型能解决的问题子集不同。这启发作者提出“温度缩放”的新思路:通过在不同温度下采样,整合模型的全部推理潜力。
实验表明,温度缩放在多个模型和任务上平均提升7.3个百分点,甚至让基础模型达到与RL训练模型相媲美的性能。这一发现不仅拓展了TTS的边界,也为LLM的高效推理提供了新方向。
研究动机:为什么需要温度采样?
在传统TTS中,模型在固定温度下生成K个样本,通过验证器选择最佳答案。早期研究认为,增加K能持续提升性能,但本文通过大规模实验发现:
-
当K从1增加到1024时,性能稳步提升;
-
但当K进一步增加到13312时,性能不再增长,部分问题始终无法解决。
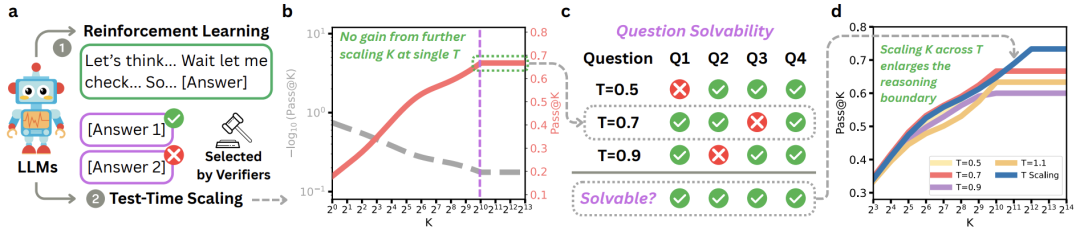
更关键的是,作者发现不同温度下模型能解决的问题不同。例如,一个在温度0.5下无法解决的问题,可能在温度0.7下被解决。这说明单一温度只能覆盖模型潜力的一部分。
因此,作者提出:为什么不把计算预算分配到多个温度上? 这就是“温度缩放”的核心思想——将样本均匀分配到不同温度,从而整合各温度下的可解问题集,扩大模型的推理边界。
温度采样的理论基础
温度采样是LLM生成文本时控制随机性的关键参数。其数学形式如下:
-
:模型输出的logits(未归一化的分数)
-
:温度参数,非负实数
-
:下一个生成的令牌
温度的作用:
-
当 :分布趋于确定性,选择最高logit的令牌(贪婪解码)
-
当 较小:分布更“尖锐”,生成更保守、确定性高
-
当 较大:分布更“平坦”,生成更多样、随机性强
在推理任务中,不同问题可能需要不同程度的探索:有些需要严格逻辑(偏好低温),有些需要创造性思维(偏好高温)。温度缩放正是利用这一点,让模型在不同“探索强度”下生成答案。
实验设计与设置
为了验证温度缩放的效果,作者设计了严谨的实验:
模型:
-
Qwen3系列(0.6B, 1.7B, 4B, 8B)
-
RL训练的Polaris-4B-Preview
数据集:
-
数学推理:AIME 2024/2025, MATH500
-
代码生成:LiveCodeBench v6
-
逻辑推理:Hi-ToM(高阶心理理论)
评估指标:
-
Pass@K:从K个样本中至少有一个正确的概率
-
Avg@N:N个样本的平均准确率,反映模型的基础能力
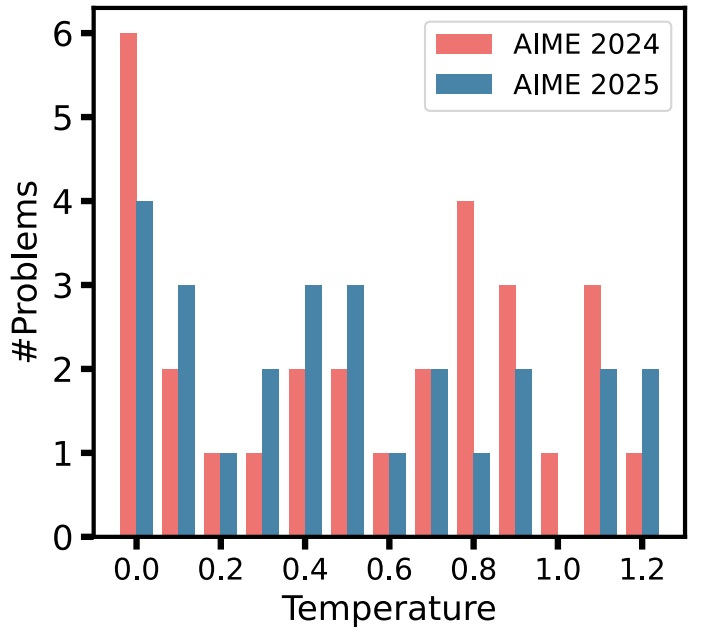
温度设置:
-
温度范围:0.0 ~ 1.2,步长0.1
-
每个温度生成1024个样本(T=0.0只生成1个)
验证方法:
-
对低正确率问题,使用GPT-5验证推理轨迹是否逻辑正确,避免“猜对答案”的误判。
核心发现与结果分析
1. 温度缩放 vs 单一温度缩放

如表所示,温度缩放在所有模型和任务上均带来显著提升:
-
平均提升7.3个百分点
-
在AIME 2025上,Qwen3-4B提升13.3点
-
即使在小模型(如0.6B)上也有明显增益
这说明没有单一温度能在所有问题上表现最佳,每个问题有其“偏好温度”。
2. 温度缩放 vs 样本数量缩放
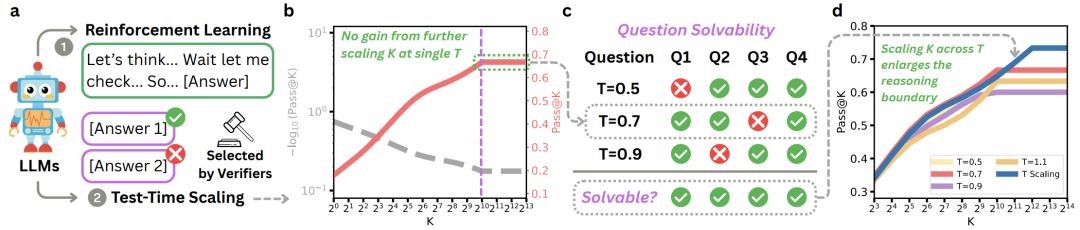

-
增加K在初期有效,但后期饱和
-
温度缩放能在相同计算预算下突破性能天花板
-
例如,在AIME 2025上,温度缩放带来6.67%的额外提升
3. 与强化学习模型的对比
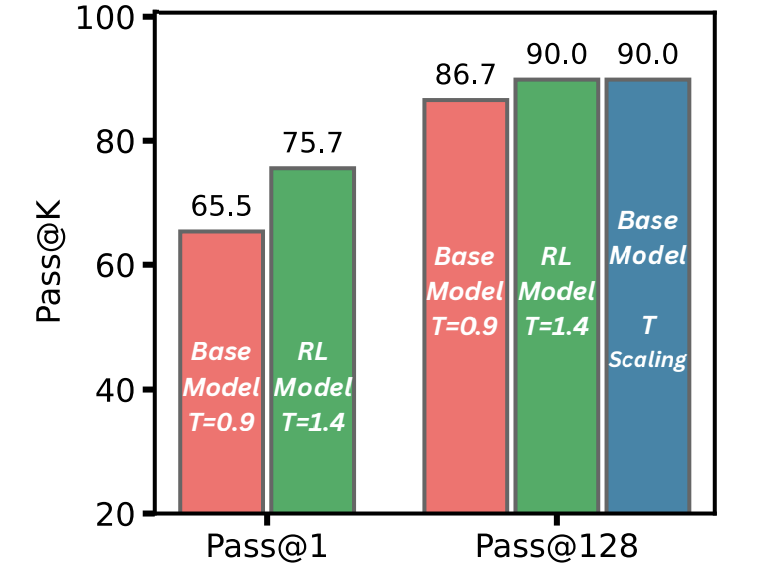
-
仅增加K,基础模型无法追上RL模型
-
但结合温度缩放后,基础模型在整体正确率上与RL模型相当
-
两者未解决的问题不同,说明温度缩放扩展了推理边界
深入分析:温度如何影响推理?
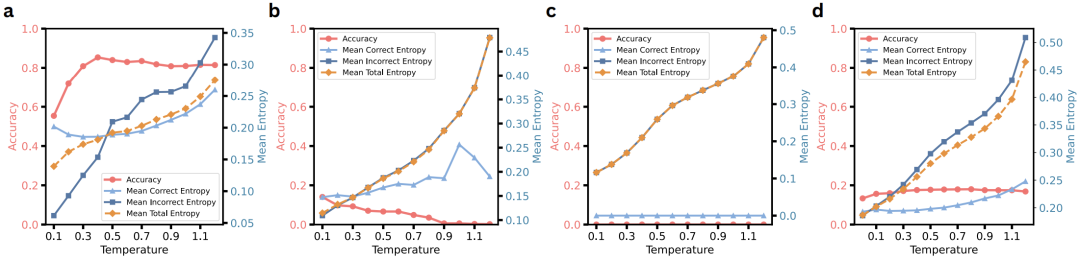
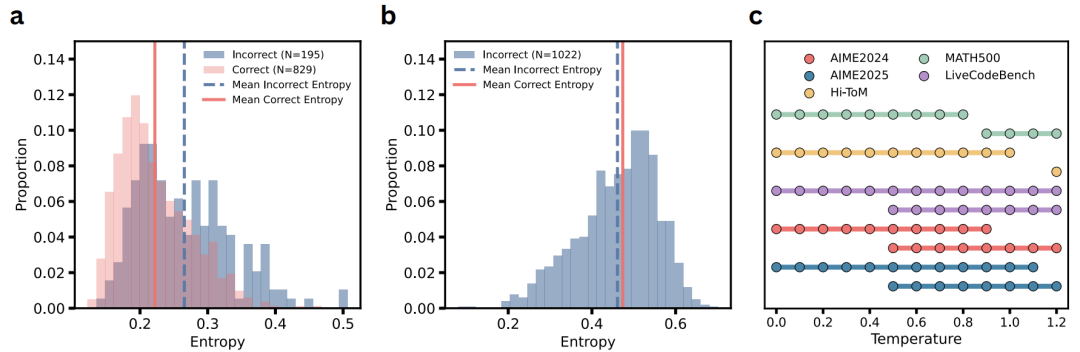
熵分析:模型是否“知道它知道”?
作者使用熵来衡量模型生成时的不确定性:
-
在简单问题上,正确轨迹的熵较低,模型“自信”
-
在难题上,正确轨迹的熵不一定低,模型不一定“知道它知道”
-
这说明熵不能作为通用筛选信号,尤其在难题上
案例研究:AIME 2025 Q24
-
在T=0.7时,模型通过严格数学推导得出正确答案
-
在T=0.9时,模型尝试近似方法,全部失败
-
说明不同温度激活不同的推理路径
温度缩放的优缺点
优点:
-
显著提升性能上界
-
无需额外训练,适用于任何基础模型
缺点:
-
计算开销大,需多温度采样
-
依赖验证器或投票机制筛选答案
高效温度缩放方法
为了降低计算成本,作者提出多温度投票算法:

算法流程:
-
每个温度维护一个候选答案池
-
每轮生成新样本,进行内部温度投票:若某温度的多数答案票数≥0.8,则认为该温度“自信”
-
若所有温度都自信,则进行跨温度投票:若某个答案在所有温度中得票一致,则判定为“简单问题”,早期退出
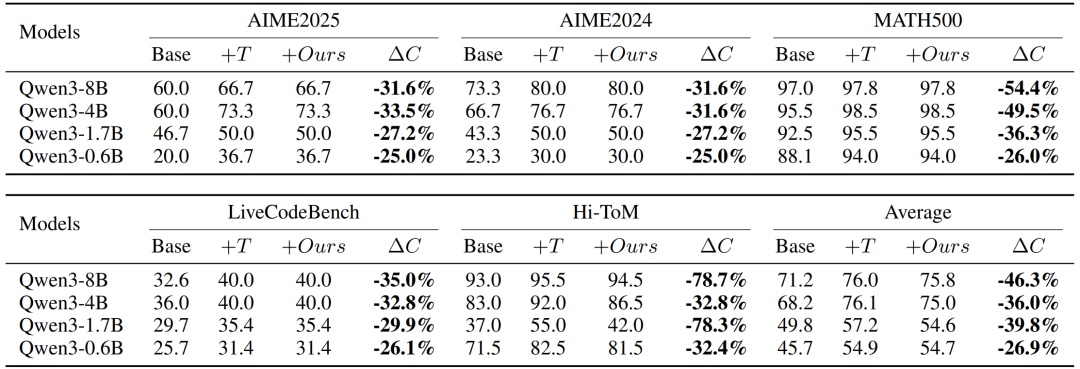
该方法在保持性能的同时,显著降低计算成本(最高减少78%),尤其在简单问题上效果显著。
讨论与未来方向
-
通用性:温度缩放在不同模型、任务中均有效,具备推广潜力
-
实际应用:可结合验证器实现动态采样,进一步提升效率
-
挑战:如何自动选择温度子集?如何与搜索算法结合?
-
未来方向:动态调整温度 within trace、多模态任务中的应用等
结论
本文系统性地提出了温度缩放作为测试时扩展的新维度,核心贡献包括:
-
新维度:温度缩放突破了传统TTS的瓶颈,扩展了模型的推理边界
-
深入分析:通过熵与案例研究,揭示了温度影响推理的机制
-
高效方法:提出多温度投票算法,显著降低计算开销
温度缩放不仅让基础模型媲美RL模型,也为LLM的高效推理提供了简单而强大的工具。未来,结合温度与其他TTS技术,有望进一步释放LLM的潜力。



火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 4
4 0
0- 0



 已为社区贡献257条内容
已为社区贡献257条内容

所有评论(0)