存储与 AI 的深度融合:一文读懂阿里云 OSS 向量 Bucket 架构原理
阿里云OSS向量Bucket创新性地将向量检索能力集成到对象存储中,解决了AIGC时代非结构化数据管理的痛点。其核心采用"统一接口、存算分离"架构:通过标准OSS API同时管理文件和向量数据,底层由对象存储引擎和向量检索引擎分工协作。数据写入采用异步设计,文件即时存储而向量后台索引;查询时先通过向量引擎快速检索,再获取文件元数据。这种设计既保持了OSS的高性能特性,又提供了专
在 AIGC 和大模型应用(如 RAG 检索增强生成)爆发的今天,开发者面临着一个新的挑战:如何高效管理海量的非结构化数据(文档、图片、视频)以及它们对应的数学表达——向量(Embeddings)。
传统的做法是“两条腿走路”:原始文件存放在对象存储(如 OSS),而向量数据则存放在专门的向量数据库(如 Milvus、Elasticsearch)中。这种架构虽然可行,但带来了复杂的维护成本、数据同步问题以及昂贵的资源开销。
阿里云推出的 OSS 向量 Bucket 打破了这一僵局。它通过将向量检索能力原生集成到对象存储中,让开发者可以用管理文件的思路来管理 AI 数据。
核心理念:统一接口,存算分离
OSS 向量 Bucket 的核心价值在于“化繁为简”。对于用户而言,它依然是一个熟悉的 OSS Bucket,使用标准的 OSS API/SDK 进行交互。但在其内部,阿里云巧妙地将存储引擎与检索引擎进行了融合与分层。
让我们通过第一张高层架构图来看看它的全貌:
图 1:OSS 向量 Bucket 整体高层架构
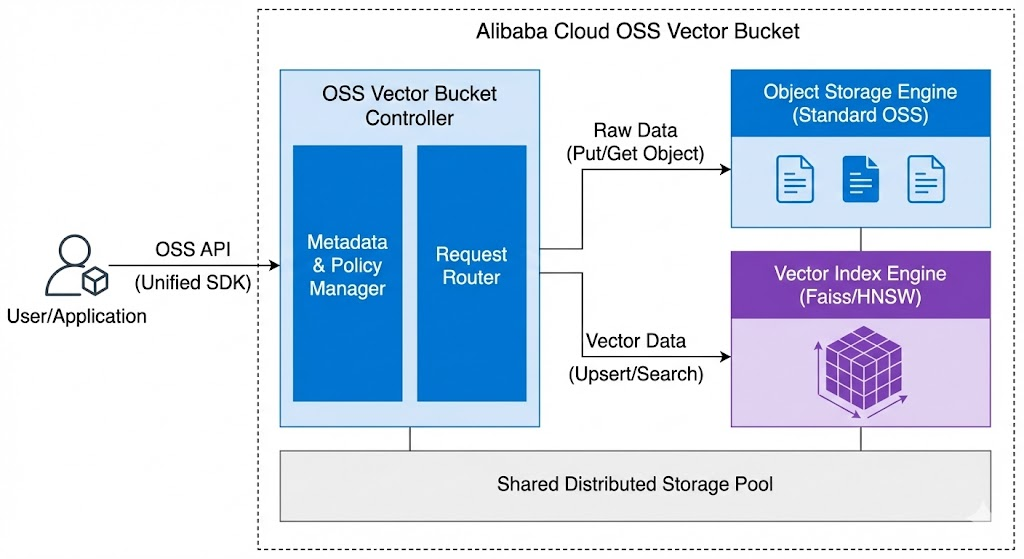
从图中我们可以清晰地看到几个关键组件:
-
统一入口 (User/Application & OSS API): 这是最外层,对开发者完全透明。无论你是上传普通文件还是带有向量的数据,亦或是发起向量检索,都统一通过标准的 OSS SDK 接口进入。你不需要维护两个客户端,也不需要学习两套 API。
-
OSS Vector Bucket Controller (核心中枢): 这是向量 Bucket 的大脑。它包含请求路由(Request Router)和元数据管理。它的核心职责是识别进入的请求类型(是存文件,还是查向量?),并将其分发到后端的不同引擎。
-
双引擎驱动 (Separated Engines): 这是架构设计的精髓。OSS 并没有试图用一个引擎解决所有问题,而是采用了“术业有专攻”的策略:
-
Object Storage Engine (标准 OSS):负责“存”。它稳定、廉价、持久地存储原始的非结构化文件数据。
-
Vector Index Engine (向量引擎):负责“算”。它集成了业界领先的向量检索算法(如 HNSW, Faiss 等),专门用于构建高性能的索引并执行毫秒级的相似度计算。
-
这两个引擎底层共享分布式存储池,确保了数据的一致性和可扩展性。
原理剖析:数据的流入与流出
了解了整体架构,我们再来看看数据是如何在这个系统中流转的。OSS 向量 Bucket 巧妙地设计了写入和查询路径,以平衡性能和功能。
1. 写入流程:异步解耦,高效入库
当我们向向量 Bucket 上传一个文件,并希望同时存入其向量信息时,系统是如何处理的?关键在于“异步”。
图 2:数据写入流程 (Ingestion Flow)
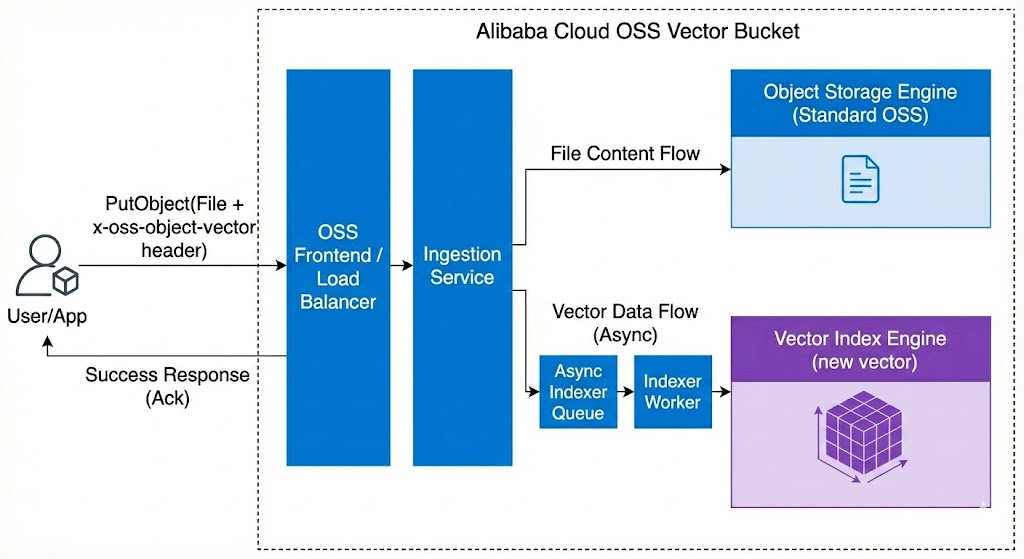
如图所示,流程如下:
-
携带向量的上传请求:用户发起标准的
PutObject请求。关键点在于,开发者通过一个特殊的 HTTP Header(如x-oss-object-vector)将向量数据“挂载”在文件上传请求上。 -
分流处理:Ingestion Service 接收到请求后,会迅速将数据一分为二:
-
文件内容流 (同步):原始文件被立即写入标准的 Object Storage Engine。这保证了 OSS 一贯的高吞吐写入性能,文件上传成功后客户端会立即收到 ACK 确认。
-
向量数据流 (异步):向量数据并没有同步写入索引,而是被放入了一个异步队列(Async Indexer Queue)。后台的 Indexer Worker 会从队列中获取数据,并将其构建到 Vector Index Engine 中。
-
设计亮点:这种异步设计极大地降低了上传延迟。用户不需要等待耗时的索引构建完成就能得到上传成功的响应,保证了业务的流畅性。
2. 查询流程:先查索引,再取元数据
当我们需要进行“以文搜图”或“语义知识库检索”时,查询流程则是一个经典的“两步走”策略。
图 3:查询检索流程 (Search Flow)
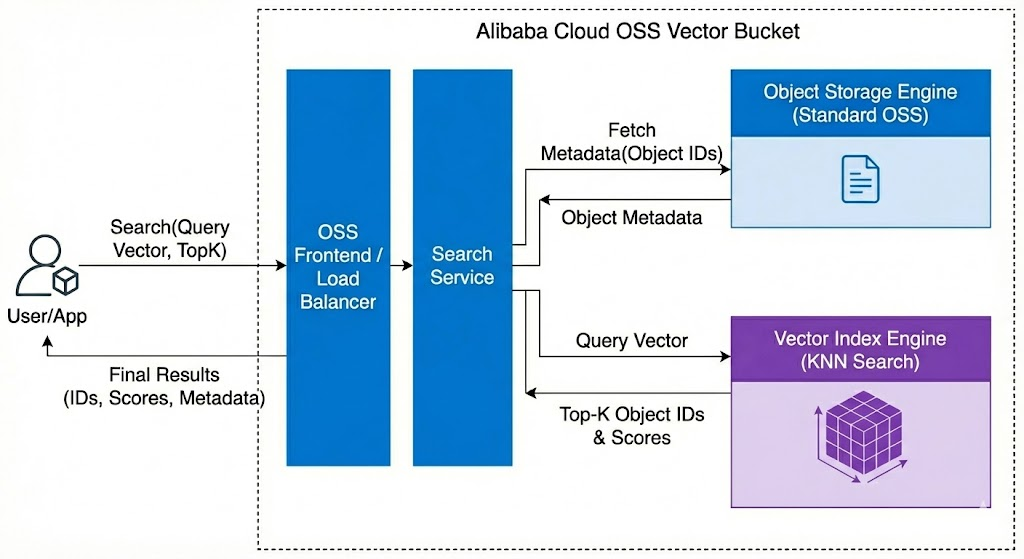
流程拆解:
-
发起检索:用户通过 SDK 发起
Search请求,携带查询向量和需要的 Top-K 数量。 -
第一步:向量引擎竞速:Search Service 将请求转发给 Vector Index Engine。引擎在海量向量空间中进行高效的 KNN(K-最近邻)搜索,快速计算出最相似的 Top-K 个结果。注意,这一步返回的主要是 Object ID 和 相似度得分。
-
第二步:元数据回捞:仅仅知道 ID 是不够的,用户需要知道具体是哪个文件。Search Service 拿着这组 Object ID,高效地向 Object Storage Engine 并发查询这些对象的元数据(如文件名、文件大小、自定义标签等)。
-
结果聚合:最后,Search Service 将相似度得分与文件元数据打包聚合,形成最终结果返回给用户。
设计亮点:这种“先索引后元数据”的方式,避免了在向量引擎中存储过多冗余信息,保持了索引的轻量和高效,同时也充分利用了 OSS 在元数据管理上的优势。
总结
阿里云 OSS 向量 Bucket 的架构设计,完美体现了云计算时代“Serverless”和“云原生”的趋势。
通过将复杂的向量数据库能力“下沉”到存储基础设施层,并采用统一接口、存算分离、异步写入的架构设计,它为开发者提供了一种成本极低(按量付费,无需维护实例)、扩展性极强且使用简单的 AI 数据基础设施。
对于正在构建 RAG、多模态搜索或智能推荐系统的开发者来说,理解了这一架构,就能更好地利用 OSS 向量 Bucket,释放数据的 AI 潜力。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 13
13 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)