数据总结token不够长的问题
大模型目前在数据分析方面还是限制比较多,所以主要依托的还是平台原有的能力,并且大模型的引入,还需要将原来的平台功能,与分析方法有机结合在一起,能够智能生成分析步骤,执行并获取的结果,然后才是利用大模型进行分析。
前提是不接受抽样,抽样会导致数据缺失,总结内容会有对不齐
方案一、数据切片
根据维度,或者列信息,进行切片,每次给大模型一个切片数据进行总结,然后将多次总结再次作为提示词交给大模型进行总结。
方案二、数据向量化+RAG(检索增强生成)
核心是将需要总结的数据进行向量化存储,大模型通过检索动态生成上下文,而不是全量一次性读取全量数据。
1、将 BI 报表/数据表按行或块编码为向量(如使用 text-embedding-ada-002);
2、但是如果数据量仍然超大,还是需要配合方案一来实现。
方案三、预计算 + 指标中心驱动(Pre-aggregation + Semantic Layer)
核心思想:
不是利用明细数据来调用大模型,而是利用BI数据平台的能力(指标定义+语义层),将过大的数据聚合到更高级别的指标,然后再将这些高度总结的数据推送到大模型。
案例:
阿里的Quickbi+通义千问的智能问数采用了此模式
Microsoft Fabric + Copilot 也强调“基于语义模型生成洞察”
但是,这里预计算,并不是单纯的聚合数据,因为聚合后数据仍然可能超过token上限。而是利用BI平台的能力,把能计算的值计算出来。然后将汇总值给到大模型。
举例:
假设你有一张 50 万行的汇总表:日-门店-品类-销售额
用户问:“请总结 2025 年 Q4 整体销售表现,并指出异常点。”
❌ 错误做法:
把 50 万行全导出成 JSON → 超过 1M tokens → 模型拒绝或截断。
✅ 正确做法(分层处理):
-
第一层:全局指标(1 行
-
{"period": "2025-Q4", "total_sales": 1.2亿, "yoy": "+8.3%", "mom": "-2.1%"} -
第二层:关键维度 Top/Bottom(各取 10 行)
- 销售额 Top 10 门店
- 同比下滑最严重的 10 个品类
- 日销波动最大的 7 天(标准差最大)
-
第三层:异常检测结果(由 BI 引擎预计算)
- 使用统计方法(如 Z-score、IQR)标记出 50 个异常点(如某天某店销量突降 90%)
- 只传这 50 条异常记录
-
合并输入给大模型:
- 总体趋势(1 行)
- 关键亮点/风险(Top/Bottom 各 10 行)
- 异常明细(50 行) → 总共约 70 行结构化数据,token 消耗 < 2000
-
大模型输出:
“Q4 整体同比增长 8.3%,但环比略有下滑……华东区 A 类门店表现突出,而饮料品类在 12 月第 2 周出现集中性下滑,可能与供应链中断有关…
技术方案说明:
大模型目前在数据分析方面还是限制比较多,所以主要依托的还是平台原有的能力,并且大模型的引入,还需要将原来的平台功能,与分析方法有机结合在一起,能够智能生成分析步骤,执行并获取的结果,然后才是利用大模型进行分析
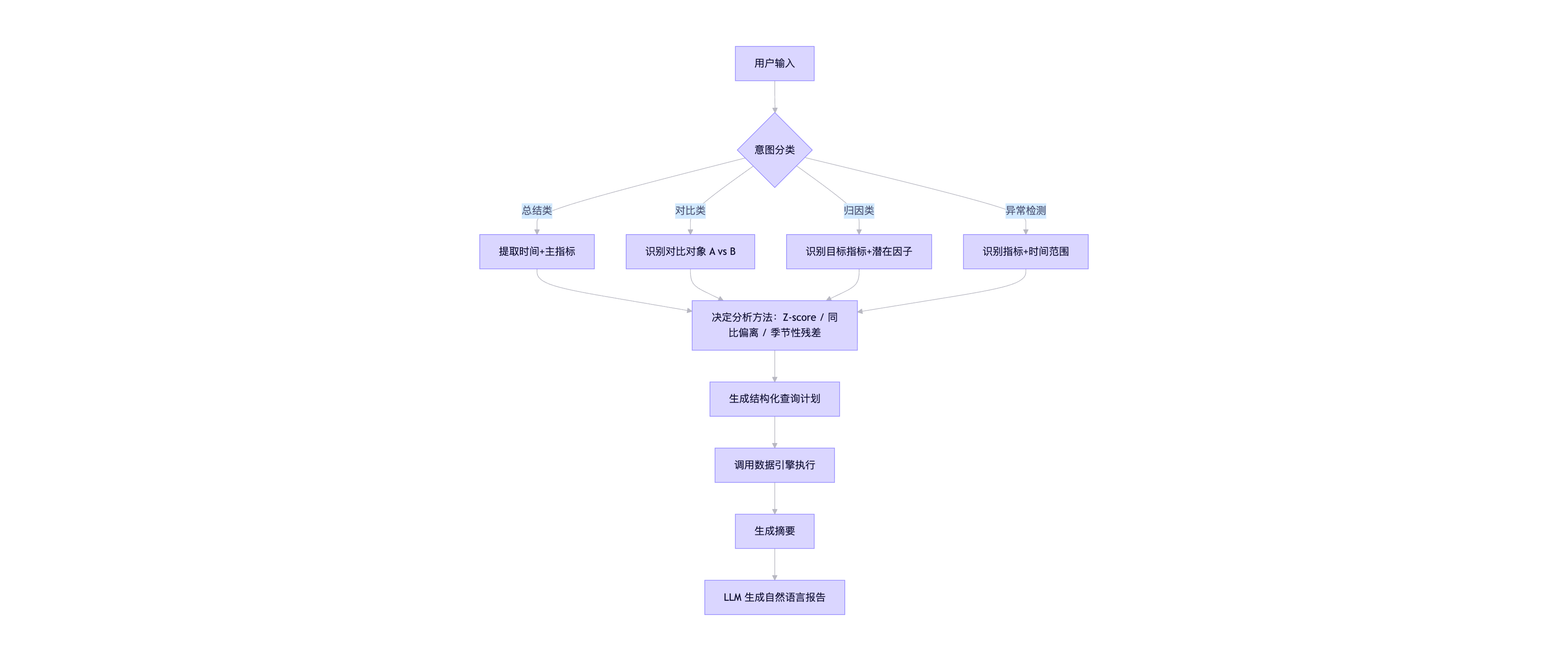
整体的流程:
| 能力 | 说明 | 示例 |
| 意图识别 | 判断是“总结”、“对比”、“归因”还是“预警” | “为什么下降?” → 归因 |
| 实体抽取 | 识别时间、维度、指标、过滤条件 | “华东区 Q4 利润率” → region=华东, period=Q4, metric=利润率 |
| 分析模式匹配 | 将问题映射到预设的分析范式 | “表现如何?” → 趋势 + 极值 + 异常 |
| 查询规划 | 决定需要哪些聚合、是否需多步计算 | 归因需先算贡献度,再排序 |
BI平台为实现该能力,需要具备的内嵌的分析知识:
| 模式 | 适用问题 | 计算逻辑 |
| 趋势分析 | “最近怎么样?” | 移动平均、环比、同比、斜率 |
| 排名分析 | “谁最好/最差?” | Top N / Bottom N + 占比 |
| 对比分析 | “A 和 B 有什么不同?” | 差异值、百分比变化、贡献度分解 |
| 归因分析 | “为什么下降?” | 指标拆解(如 GMV = UV × 转化率 × 客单价),Shapley 值,或维度贡献排序 |
| 异常检测 | “有没有异常?” | Z-score > 3、同比偏离 > 50%、残差分析 |
| 预测推演 | “接下来会怎样?” | 简单线性外推、季节性调整(可选) |
技术实现建议:
| 组件 | 推荐方案 |
| 语义层 | 自研元数据服务 / Looker / Power BI Semantic Model |
| NL2Query 引擎 | Vanna.ai(开源)、LangChain SQL Agent、或自研规则+微调小模型 |
| 分析方法论引擎 | 用 Python/Java 实现“分析模式调度器”,支持插件化扩展 |
| 执行引擎 | 直连数据仓库(ClickHouse/Doris/BigQuery),避免导出 |
| 缓存优化 | 对高频查询结果缓存(如“昨日销售”),提升响应速度 |
行业实践参考:
| 厂商 | 能力 | 说明 |
| ThoughtSpot Sage | 内置 20+ 分析模式,支持自动归因、异常检测 | 用户问“why down?” 自动触发根因分析 |
| Microsoft Copilot for Power BI | 基于 semantic model 动态生成 DAX 查询 | 支持“show me by region”等自由切换 |
| 阿里 Quick BI 智能问数 | 结合指标中心 + 分析模板 + 通义千问 | 支持中文复杂问法,自动选择图表和计算 |
| Tableau Ask Data | 基础 NL2Viz,但分析深度有限 | 更适合简单查询,复杂归因需增强 |

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)