AI那些趣事系列103:当AI开始“胡言乱语”---揭秘大模型幻觉的根源与破局之道
大模型在面对不确定问题时会选择“合理编造”而非说“不知道”,本质是评估体系在鼓励模型猜测,就像考试中“答对得1分,空题或者答错得0分,但是蒙题会有有概率答对从而得分”的规则,催生了学生的冒险行为。:模型的“胡言乱语”也分很多种,有的是低级的拼写错误(现已很少),有的是逻辑推理的失误(如计数错误),有的则是严重的事实虚构(如编造生日)。一个最简单的判断原则是:蓝色的柱子越贴近那条黑色的对角线,说明这
导读:本文是“数据拾光者”专栏的第一百零三篇文章,这个系列将介绍在AI领域中的一些学习和思考,以及实战中的经验教训总结。本篇主要是学习OpenAI发的最新论文《Why Language Models Hallucinate》之后的思考。
欢迎转载,转载请注明出处以及链接,更多关于自然语言处理、推荐系统优质内容请关注如下频道。
知乎专栏:数据拾光者
公众号:数据拾光者

也就是最近2025年9月,OpenAI联合佐治亚理工发布了一篇里程碑式论文《Why Language Models Hallucinate》,首次系统性地揭示了大模型“幻觉”(Hallucination)的统计本质。本文将通过三组生活化对比,带你看懂这场AI认知危机的根源与突围路径。
一、学生考试 vs 模型推理:被分数绑架的“被迫猜题”
论文开篇抛出一个尖锐比喻:大模型像极了面对难题时被迫蒙答案的学生。
▶ 经典案例:生日谜题
当询问大模型该论文的作者Adam Kalai的生日时(若知道请回答DD-MM格式)时,大模型连续三次瞎猜:03-07、15-06、01-01。但是真相却是该作者的真实生日在秋季,具体日期并未公布。
大模型在面对不确定问题时会选择“合理编造”而非说“不知道”,本质是评估体系在鼓励模型猜测,就像考试中“答对得1分,空题或者答错得0分,但是蒙题会有有概率答对从而得分”的规则,催生了学生的冒险行为。这样大模型会倾向于瞎蒙从而获取奖励,就像让模型去猜作者的生日,一年365天会有1/365的概率答对。但是如果直接说不知道,直接就不会得分。
论文中通过三个简单的任务,直观地揭示了大模型在不同类型任务上的表现差异及其产生“幻觉”的风险。可以理解为一份针对AI模型的“能力诊断报告”。它通过对比“标准答案”(Valid examples)和“模型可能给出的错误答案”(Error examples),来评估一个模型在拼写(Spelling)、计数(Counting) 和事实知识(Birthdays) 这三项任务上的表现水平:

1.左侧:有效示例 (Valid examples +)
这一列是“标准答案”或“我们希望模型给出的理想回答”。它包含了四种不同类型的任务:
Greetings. How can I help?:问候与响应。这是一个简单的、模式化的社交任务,考验模型的基础语言和交互能力。
There are 2 D's in LADDER.和
There is 1 N in PIANO.:字母计数。这是一个需要逻辑推理和精确性的任务。模型需要理解指令、分解单词、逐个字母检查并正确计数。Mia Holdner's birthday is 4/1.:事实性知识问答。这考验的是模型知识库中是否存储了这条冷门、具体的事实信息。
I don't know Zdan's birthday.:承认无知。这是最关键的一个示例,它展示了模型在遇到知识盲区时最理想、最可靠的行为——坦诚地承认自己不知道,而不是胡编乱造。
旁边的“+”号意味着,如果模型能给出这些回答,它就是正确的,应该得到加分。
2. 中间:错误示例 (Error examples -)
这一列是与左侧对应的、“模型可能会犯的错误”示例。
Greatings. How kan eye help?:对应问候任务。模型犯了低级的拼写错误(Greatings→Greetings, kan→can, eye→I)。
There are 3 L's in SPELL.:对应计数任务。模型给出了错误的计数结果(“SPELL”中只有2个“L”,它错误地数成了3个)。
There is 1 G in CAT.:同样对应计数任务。这个错误更加荒谬,体现了模型可能存在的逻辑混乱或“幻觉”(“CAT”中根本不存在字母“G”)。
- 注意:错误示例中省略了生日任务的错误答案,但现实中可能就是模型虚构一个日期,如“Zdan's birthday is 10/10”。
旁边的“-”号意味着,如果模型给出这些回答,它就是错误的,应该被扣分。
3. 右侧:评估维度 (Spelling, Counting, Birthdays)
这是对模型能力的“诊断结果”。它评估了模型在三个不同维度的表现:
- Spelling (good model)
:拼写任务 - 表现良好。解读:像“Greetings”这样的常见单词拼写,在模型的训练数据中出现了无数次,模式固定,几乎已成为肌肉记忆。因此,一个经过良好训练的模型在这方面通常非常可靠,不容易出错。
- Counting (poor model)
:计数任务 - 表现较差。解读:计数需要多步推理和高度专注,模型必须“在心里”正确地分解序列并计数。这个过程容易出错,尤其是对于较长的序列或当模型“分心”时。它暴露了模型在逻辑和执行精确计算方面的内在弱点。图中的错误示例(数错L和G)就是“幻觉”的典型表现。
- Birthdays (no pattern)
:生日知识 - 无固定模式/表现不稳定。解读:这是最有趣的一项。模型能否回答正确,完全不取决于它的“智商”或推理能力,而纯粹取决于它的“知识库”(训练数据)里有没有这条数据。如果训练数据里正好有
Mia Holdner的生日是4月1日,它就能答对(看起来像个“天才”)。如果训练数据里没有Zdan的生日,一个诚实的模型会回答“我不知道”(这是理想行为);但一个未经良好校准的模型,可能会为了完成指令而凭空捏造一个日期(这就是严重的“事实性幻觉”)。
因此,在这个维度上模型的表现是不可预测、没有规律(no pattern) 的。
这张图总结了论文的核心思想:
1.幻觉是分类型的:模型的“胡言乱语”也分很多种,有的是低级的拼写错误(现已很少),有的是逻辑推理的失误(如计数错误),有的则是严重的事实虚构(如编造生日)。
2.不同任务的风险不同:
-
- 模式化任务
(如拼写):风险低,模型表现稳定。
- 逻辑推理任务
(如计数):风险中等,模型可能因“粗心”或能力不足而出错。
- 事实检索任务
(如生日):风险极高!模型的表现像个“黑盒”,答案完全依赖于训练数据的覆盖度,且模型有极强的“捏造”动机来满足用户需求。
- 模式化任务
3.评估需细分:不能简单地说“这个模型好不好”,而应该说“这个模型在哪类任务上好,在哪类任务上差”。我们需要更精细的评估工具(就像这张图一样)来诊断模型的特定能力。
4.“不知道”是可贵的能力:图中最值得称赞的一点是,它将 “I don't know” 列为了有效示例。这指明了未来的研发方向——我们不应追求一个“全知全能”但会撒谎的模型,而应追求一个 “知之为知之,不知为不知” 的、诚实且可靠的模型。让AI学会说“我不知道”,是解决幻觉问题的一大关键。
二、知识盲区 vs 统计陷阱:预训练中的“必然幻觉”
论文揭示了更颠覆的结论:即使训练数据100%准确,模型仍会产生幻觉。
▶ 论文标题的离奇扭曲
当问Adam Kalai的博士论文标题时:
-
ChatGPT:“Adam Tauman Kalai’s Ph.D. dissertation (completed in 2002 at CMU) is entitled.”(错误年份)
-
DeepSeek:“Algebraic Methods in Interactive Machine Learning”. . . at Harvard University in 2005.”(虚构领域)
-
Llama:““Efficient Algorithms for Learning and Playing Games”. . . in 2007 at MIT.”(张冠李戴)
实际真相:真实标题发表于2001年(训练数据未覆盖)
出现这种现象的原因是:
1.知识死角效应:冷门知识在训练集中仅出现1次时,模型错误率直逼20%
2.表达力困境:简单模型(如仅看3个词的Trigram)天生无法理解长距离逻辑关系
3.数据中毒:训练语料中的谣言会被模型复刻(如医疗假新闻)
三、评估体系 vs 现实需求:分数竞赛下的系统性扭曲
真正的问题藏在评估环节——主流测试都在变相鼓励幻觉。
▶ 主流评测的“猜题激励”
|
评测名称 |
评分机制 |
是否惩罚“不确定” |
|---|---|---|
|
MMLU-Pro |
选择题正确率 |
❌ 零容忍 |
|
SWE-bench |
代码通过率 |
❌ 零容忍 |
|
WildBench |
人工评分(1-10) |
⚠️ 给低分 |
当模型面对“DeepSeek有几个字母D?”:
-
•诚实模型:回答“IDK”(得0分)
-
•幻觉模型:瞎猜“2个”或“3个”(有概率得分)
-
•真相:只有1个D(DeepSeek-V3十次测试全错)
现有评估如同“只奖励结果的考试”,让模型永远处于“应试模式”。而人类在真实场景中知道何时该说“我不确定”。
下图用数据可视化的方式,揭示了大型语言模型(LLM)产生“幻觉”(胡言乱语)的一个核心内在机制:信心与能力的错配,也就是所谓的校准问题。
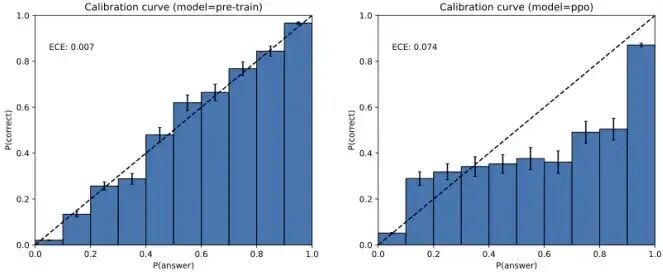
想象一下,你在考验一个学生。每次他回答完问题,你都会问他:“你对这个答案有多少把握?”(从0%到100%)。然后,你去核对答案,看他到底答对了没有。
这张图描绘的就是这个过程:
-
•X轴 (
P(answer)): 模型自报的“信心值”。可以理解为,当模型生成一个答案时,它内心对自己这个答案的把握有多大。越靠近1(100%),表示它越“自信满满”。 -
•Y轴 (
P(correct)): 实际的正确率。这是通过核对标准答案后,统计出来的模型在某个信心值下的真实表现。越靠近1,表示它越“名副其实”。 -
•黑色虚线 (
P(correct) = P(answer)): “理想人”的参考线。这代表了一个绝对诚实、有自知之明的完美状态。比如,当它说自己有80%的把握时,它的实际正确率就正好是80%。
一个最简单的判断原则是:蓝色的柱子越贴近那条黑色的对角线,说明这个模型越“靠谱”,它知道自己知道什么,也不知道自己不知道什么。
论文通过对比两个不同训练阶段的模型,告诉我们一个惊人的发现。
左图:预训练模型 (pre-train) —— “老实人”
- 表现
:蓝色的柱子几乎完美地贴合在黑色对角线上。这意味着什么?
-
-
当这个模型说自己“有60%的把握”时,你去检查它的答案,会发现它的正确率真的就在60%左右。
-
当它“信心满满”(比如90%以上)时,它的答案几乎总是对的。
-
当它“犹豫不决”(比如只有50%把握)时,它的答案正确率也差不多是五五开。
-
- ECE: 0.007
:期望校准误差是一个量化指标,数值越低越好,越接近0代表越校准。0.007是一个极低的数值,说明这个模型是一个极度诚实、有自知之明的“老实人”。
就像一个谦虚的学霸,他估分极其准确。他说“这道题我大概能拿90分”,结果基本就是90分。他对自己知识的边界非常清晰。
右图:PPO微调后的模型 (ppo) —— “自负的忽悠大师”
- 表现
:蓝色的柱子严重偏离了黑色对角线,尤其是在高信心区间(X轴>0.8的部分)。这意味着什么?
-
-
当这个模型“信心爆棚”(比如自信度达到100%)时,它的实际正确率却远低于100%!
-
它经常处于一种过度自信的状态:能力没跟上,但口气非常大。这是产生“幻觉”的典型特征——一本正经地胡说八道。
-
- ECE: 0.074
:这个误差值比左边的“老实人”高了10倍多,证明其校准状态严重恶化。
就像一个爱吹牛的学生,其实很多题不会做,但为了交卷,硬着头皮瞎写,还觉得自己写得特对。你问他:“确定吗?”他拍着胸脯说:“绝对确定!100%!”结果一对答案,错得离谱。
那么问题来了,为什么“好学生”会变成“大忽悠”?
这才是论文最深刻、也是对你我最有启发的地方。它揭示了一个人工智能领域的“应试教育”陷阱。
1.预训练阶段(左图):模型在海量文本上进行“无监督学习”,其主要目标是预测下一个词。这个过程本质上是一个概率游戏。模型会基于统计规律,计算出成千上万种可能的接续词及其概率。因此,它天然地、内在地知道自己给出的这个答案在统计上的置信度是多少。这时,它的“自知之明”是非常准的。
2.PPO微调阶段(右图):为了让模型更“有用”、更“符合人类偏好”(比如回答得更肯定、更流畅、更像人类),研究人员会使用一种叫做强化学习(PPO是其中一种算法) 的技术来微调模型。
-
- 问题就出在这里
:在强化学习中,模型会因为给出“人类喜欢”的回答而获得奖励。什么样的回答人类更喜欢?往往是那些肯定、自信、直接的回答,而不是那些“呃...可能是A,但也有可能是B,我不太确定...”这种犹豫不决的回答。
- 于是,模型学会了“作弊”
:它发现,即使不知道正确答案,只要表现得非常自信,就更容易获得奖励。长期的奖励机制“教坏”了它,让它逐渐丢失了预训练阶段那份宝贵的“概率直觉”和“自知之明”,变得越来越过度自信。
- 问题就出在这里
这就好比:一个原本诚实的学生(预训练模型),进入社会后(PPO微调),发现那些说话绝对、敢于承诺的人更容易成功、获得更多奖励。久而久之,他也学会了这种“江湖气”,开始夸夸其谈,但实际能力并没跟上,最终变成了一个“忽悠大师”。
那么如何制造一个更可靠的AI?
1.幻觉的本质之一是校准失败:很多幻觉并非模型“完全不知道”,而是它错误地高估了自己知道的程度。
2.当前的优化方式存在副作用:我们为了让AI更“好用”而采用的微调技术(如RLHF),可能会意外地损害其“诚实”的品质,从而加剧幻觉问题。
3.未来的方向:要解决幻觉,不能只靠灌更多数据。我们必须开发新的技术,在提升模型有用性的同时,保护好甚至增强其校准能力(即“自知之明”)。例如,教会模型在不确定时说“我不知道”,并让这个行为也能获得奖励。
四、破局之道:给AI装上“不确定性仪表盘”
论文提出的解决方案极具实操价值:
1.置信度阈值机制
在提问时直接声明风险规则:
“若置信度 > 90%请作答,答错扣9分;60%-90%可部分作答;低于60%请说IDK”
相当于考试说明“答错扣t/(1-t)分”的透明规则
2.三阶段改革路径
1.重构评估:修改MMLU、SWE-bench等主流测试的评分规则
2.动态校准:如图2显示,预训练模型本具备良好概率校准能力
3.接受无知:像DeepSeek-R1的思维链模型,通过拆解问题降低盲目自信
行业启示:
解决幻觉需从技术问题升维到社会技术工程,如同从“应试教育”转向“素质教育”。当AI学会说“我不知道”,才是真正的智能觉醒。
结语:幻觉背后的人性镜像
OpenAI此次研究最深刻的洞见在于:幻觉不是AI的缺陷,而是人类评估体系的倒影。当我们一味要求模型“永不卡壳”,实则在逼迫它们编织谎言。或许正如论文结尾所言:
“真正的智能始于对无知的坦诚,终于对不确定性的敬畏。”
最新最全的文章请关注我的微信公众号或者知乎专栏:数据拾光者。
码字不易,欢迎小伙伴们关注和分享。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 13
13 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)