大模型学习(三)从零打造HTTP并发推理服务
是Python 的异步编程模型。允许在单线程中并发处理多个 I/O 操作(比如等待网络、文件、数据库)。
核心技术原理
- vLLM支持Continuous batching of incoming requests高并发批推理机制,其SDK实现是在1个独立线程中运行推理并且对用户提供请求排队合批机制,能够满足在线服务的高吞吐并发服务能力
- vLLM提供asyncio封装,在主线程中基于uvicorn+fastapi封装后的asyncio http框架,可以实现对外HTTP接口服务,并将请求提交到vLLM的队列进入到vLLM的推理线程进行continuous batching批量推理,主线程异步等待推理结果,并将结果返回到HTTP客户端
- vLLM天然支持流式返回next token,基于fastapi可以按chunk流式返回流式推理成果,在客户端基于requests库流式接收chunk并复写控制台展示,实现了流式响应效果。
流程如下:
HTTP 客户端
│
▼
[ FastAPI + Uvicorn ] ←─ 主线程(异步事件循环)
│
▼ (提交请求到 vLLM)
[ vLLM 引擎 ] ←─ 后台有自己的推理线程池 + 调度器
│
▼
GPU 执行批量推理(Continuous Batching)
│
▼
结果返回给 FastAPI → 返回给客户端
asyncio:是Python 的异步编程模型。允许在单线程中并发处理多个 I/O 操作(比如等待网络、文件、数据库)。
FastAPI + Uvicorn:
- FastAPI:一个Python Web 框架,原生支持 asyncio。
- Uvicorn:一个 ASGI 服务器,用来运行 FastAPI 应用。
- 它们一起提供 异步 HTTP 服务,能同时处理成百上千个并发请求。
vLLM 提供了两种接口:
- LLM:同步接口(会阻塞线程)
- AsyncLLMEngine:异步接口,专为 asyncio 设计。
服务器端
首先定义一个https接口服务app:
# http接口服务
app=FastAPI()
这个app实例就是整个Web服务的“入口”,后续可以通过@app.post(…),@app.get(…)等装饰器来定义接口,例如:
from fastapi import FastAPI
app = FastAPI() # ← 创建 HTTP 服务应用
@app.post("/chat")
def chat_endpoint(query: str):
# 处理聊天请求
response = f"你问的是: {query}"
return {"answer": response}
接下来就是一些vLLM模型加载相关的代码:
# vLLM模型加载
def load_vllm():
global generation_config,tokenizer,stop_words_ids,engine
# 模型下载
# snapshot_download(model_dir, cache_dir="./Models")
# 模型基础配置
generation_config=GenerationConfig.from_pretrained(model_dir,trust_remote_code=True)
# 加载分词器
tokenizer=AutoTokenizer.from_pretrained(model_dir,trust_remote_code=True)
tokenizer.eos_token_id=generation_config.eos_token_id
# 推理终止词
stop_words_ids=[tokenizer.im_start_id,tokenizer.im_end_id,tokenizer.eos_token_id]
# vLLM基础配置
args=AsyncEngineArgs(model_dir)
args.worker_use_ray=False
args.engine_use_ray=False
args.tokenizer=model_dir
args.tensor_parallel_size=tensor_parallel_size
args.trust_remote_code=True
args.quantization=quantization
args.gpu_memory_utilization=gpu_memory_utilization
args.dtype=dtype
args.max_num_seqs=20 # batch最大20条样本
# 加载模型
os.environ['VLLM_USE_MODELSCOPE']='True'
engine=AsyncLLMEngine.from_engine_args(args)
return generation_config,tokenizer,stop_words_ids,engine
generation_config,tokenizer,stop_words_ids,engine=load_vllm()
tips:AsyncEngineArgs是创建异步引擎,实现异步。
接下来就是chat对话方法的实现:
- 定义了一个 HTTP POST 接口,路径为 /chat
@app.post("/chat")
async def chat(request: Request):
- 等待并读取客户端发送过来的JSON数据:
request=await request.json()
tips:先了解一下异步的一些概念:(1)“协程”(Coroutine)是一种可以暂停和恢复执行的函数,它是实现异步编程的核心机制。(2)协程用 async def定义,await 在协程内使用。(3)协程是"能暂停的函数",await是"暂停并等待的指令"。(4)当有10 个客户端同时发送 POST /chat 请求时,事件循环接收 10 个请求,为每个请求创建一个 chat 协程对象,10 个协程都已启动,并在各自的 await 处暂停等待。当数据陆续到达,协程陆续恢复,最终每个协程完成并返回。
- 获取请求的一些信息:
query=request.get('query',None)
history=request.get('history',[])
system=request.get('system','You are a helpful assistant.')
stream=request.get("stream",False)
user_stop_words=request.get("user_stop_words",[]) # list[str],用户自定义停止句,例如:['Observation: ', 'Action: ']定义了2个停止句,遇到任何一个都会停止
if query is None:
return Response(status_code=502,content='query is empty')
- 若用户传入了停止词,则转换成token List:
# 用户停止词
user_stop_tokens=[]
for words in user_stop_words:
user_stop_tokens.append(tokenizer.encode(words))
- 使用之前定义的方法构造Prompt:
# 构造prompt
prompt_text,prompt_tokens=_build_prompt(generation_config,tokenizer,query,history=history,system=system)
- 向异步引擎传入Prompt、配置等信息。
# vLLM请求配置
sampling_params=SamplingParams(stop_token_ids=stop_words_ids,
early_stopping=False,
top_p=generation_config.top_p,
top_k=-1 if generation_config.top_k == 0 else generation_config.top_k,
temperature=generation_config.temperature,
repetition_penalty=generation_config.repetition_penalty,
max_tokens=generation_config.max_new_tokens)
# vLLM异步推理(在独立线程中阻塞执行推理,主线程异步等待完成通知)
request_id=str(uuid.uuid4().hex) #生成一个全局唯一、无重复、不可预测的字符串 ID,用作当前请求的唯一标识符(Request ID)。
results_iter = engine.generate(
inputs=prompt_text,
sampling_params=sampling_params,
request_id=request_id
)
- 流式返回,即迭代transformer的每一步推理结果并反复返回:
if stream:
async def streaming_resp():
async for result in results_iter:
# 移除im_end,eos等系统停止词
token_ids=remove_stop_words(result.outputs[0].token_ids,stop_words_ids)
# 返回截止目前的tokens输出
text=tokenizer.decode(token_ids)
yield (json.dumps({'text':text})+'\0').encode('utf-8')
# 匹配用户停止词,终止推理
if match_user_stop_words(token_ids,user_stop_tokens):
await engine.abort(request_id) # 终止vllm后续推理
break
return StreamingResponse(streaming_resp())
其中,yield (json.dumps({'text':text})+'\0').encode('utf-8')将当前生成的文本封装成一个 JSON 字符串,末尾加上空字符 \0 作为分隔符,再转为字节流(bytes),通过生成器(generator)逐块返回给客户端。StreamingResponse(streaming_resp())将一个异步生成器(streaming_resp())包装成 HTTP 流式响应,让客户端可以“边生成、边接收”数据,而不是等全部结果生成完才一次性返回。
- 整体一次性返回:
# 整体一次性返回模式
async for result in results_iter:
# 移除im_end,eos等系统停止词
token_ids=remove_stop_words(result.outputs[0].token_ids,stop_words_ids)
# 返回截止目前的tokens输出
text=tokenizer.decode(token_ids)
# 匹配用户停止词,终止推理
if match_user_stop_words(token_ids,user_stop_tokens):
await engine.abort(request_id) # 终止vllm后续推理
break
ret={"text":text}
return JSONResponse(ret)
客户端
while True:
query=input('问题:')
# 调用api_server
response=requests.post('http://localhost:8000/chat',json={
'query':query,
'stream': True,
'history':history,
},stream=True)
full_text = "" # 用于累积完整响应
# 流式读取http response body, 按\0分割
for chunk in response.iter_lines(chunk_size=8192,decode_unicode=False,delimiter=b"\0"):
if chunk:
data=json.loads(chunk.decode('utf-8'))
# print("data:",data)
text=data["text"].rstrip('\r\n') # 确保末尾无换行
new_content = text[len(full_text):]
print(new_content, end='', flush=True)
print()
full_text = text
print()
# 对话历史
history.append((query,full_text)) # 使用累积的完整文本
history=history[-5:]
其中,for chunk in response.iter_lines(chunk_size=8192, decode_unicode=False, delimiter=b"\0"):实现流式读取 HTTP 响应,从而实现流式输出的效果。流式输出效果如下: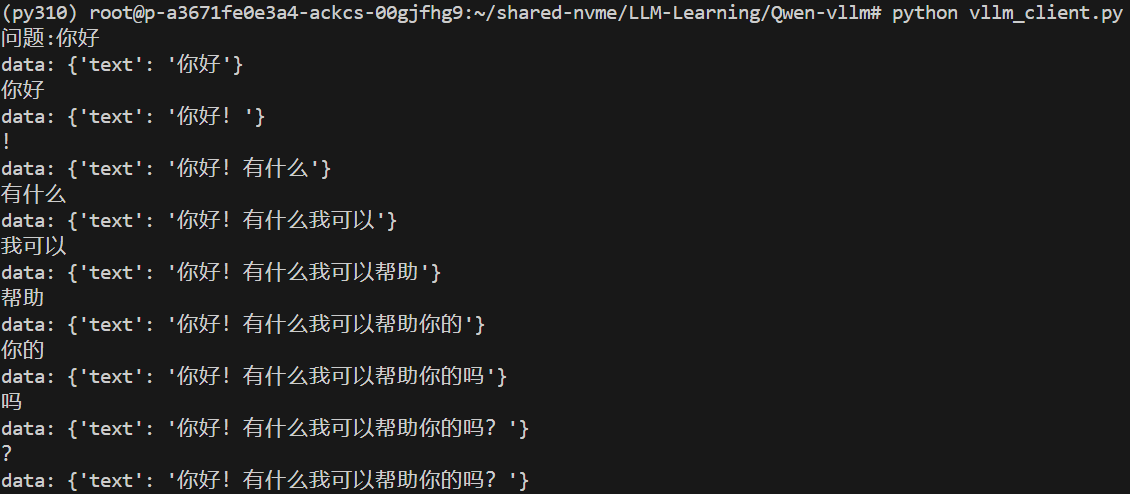

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 11
11 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)