大模型基础 | Transformer-KVCache
Transformer的KVcache
背景
我们之前内容提到,Transformer的Self-attention计算主要通过QKV三个矩阵进行计算,我们提升推理性能方面可使用KV两个矩阵进行缓存,而大家可能有个问题为什么Q不做缓存呢?下面会详细说明具体的原因。
Transformer Decoder计算
如下图所示,这里展示了Transformer Decoder所有模块的框架图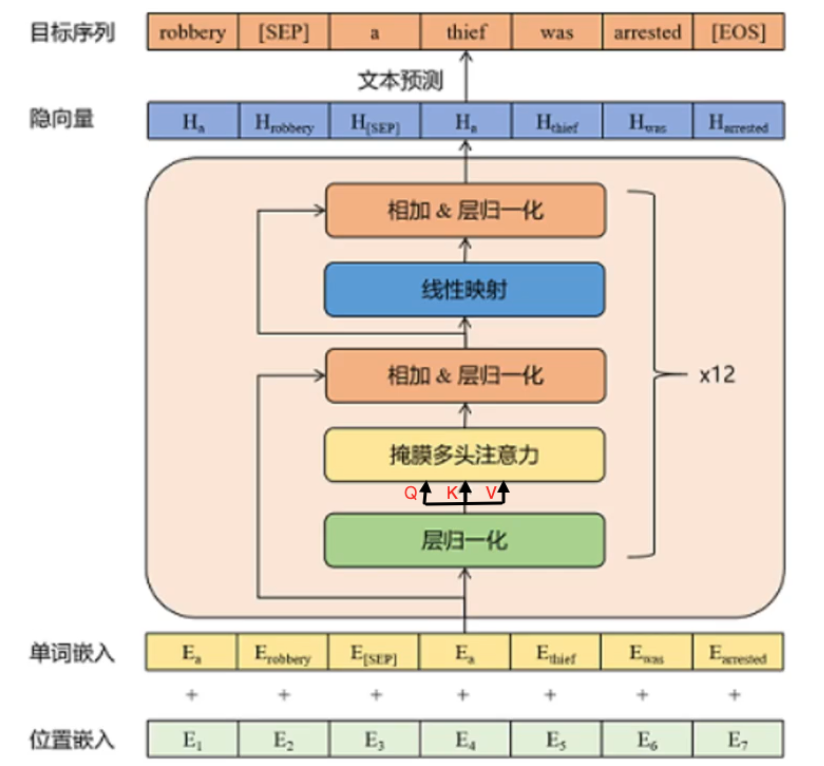
我们主要优化的组件就是Q、K、V三个内容
因为 Decoder-only Transformer 的任务是自回归(GPT模型)语言建模:
每一步只能根据已经生成的历史 token 来预测下一个 token,绝不能偷看未来信息。
为什么 Q 是当前 token,K/V 是历史信息?
在 Self-Attention 中,计算公式为:
Attention ( Q , K , V ) = softmax ( Q K ⊤ d k ) V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^\top}{\sqrt{d_k}} \right)V Attention(Q,K,V)=softmax(dkQK⊤)V
- Query(Q):表示当前正在处理的 token(即模型当前正在预测的位置)。
- Key(K) 和 Value(V):表示所有历史 token(包括当前 token 本身),因为它们提供了用于计算注意力的上下文信息。
推理步骤与公式
1. 计算当前 token 的 Q, K, V
q t + 1 = x t + 1 W Q ∈ R d k k t + 1 = x t + 1 W K ∈ R d k v t + 1 = x t + 1 W V ∈ R d v \begin{align*} q_{t+1} &= x_{t+1} W^Q \quad &\in \mathbb{R}^{d_k} \\ k_{t+1} &= x_{t+1} W^K \quad &\in \mathbb{R}^{d_k} \\ v_{t+1} &= x_{t+1} W^V \quad &\in \mathbb{R}^{d_v} \end{align*} qt+1kt+1vt+1=xt+1WQ=xt+1WK=xt+1WV∈Rdk∈Rdk∈Rdv
2. 构建完整的历史 Key 和 Value 矩阵
K new = concat ( K cache , k t + 1 ) ∈ R ( t + 1 ) × d k V new = concat ( V cache , v t + 1 ) ∈ R ( t + 1 ) × d v \begin{align*} K_{\text{new}} &= \text{concat}(K_{\text{cache}},\, k_{t+1}) \quad &\in \mathbb{R}^{(t+1) \times d_k} \\ V_{\text{new}} &= \text{concat}(V_{\text{cache}},\, v_{t+1}) \quad &\in \mathbb{R}^{(t+1) \times d_v} \end{align*} KnewVnew=concat(Kcache,kt+1)=concat(Vcache,vt+1)∈R(t+1)×dk∈R(t+1)×dv
说明:将当前 token 的 k t + 1 , v t + 1 k_{t+1}, v_{t+1} kt+1,vt+1 拼接到缓存中,形成包含所有已生成 token 的完整矩阵。
3. 计算 Attention 分数(点积)
Scores = q t + 1 ⋅ K new T ∈ R 1 × ( t + 1 ) \text{Scores} = q_{t+1} \cdot K_{\text{new}}^T \quad \in \mathbb{R}^{1 \times (t+1)} Scores=qt+1⋅KnewT∈R1×(t+1)
重点内容:为什么不是[q0, q1, …, qt+1] 进行相乘呢
[q0, q1, …, qt+1] 与 K^T 相乘,这其实是 训练阶段 的标准做法。而在自回归生成(推理)阶段,我们只关心这个即将被生成的token的上下文是什么,所以我们只计算 q_{t+1} 这一个向量。
推理阶段(比如ChatGPT生成回答)是自回归的,即一个一个地生成token。
第1步: 给定x0,模型计算 q0,并生成第一个token x1。
第2步: 输入 x0, x1,模型需要生成第二个token x2。
第t+1步: 输入为 [x0, x1, …, x_t],模型需要生成下一个token x_{t+1}。
因此K可以通过缓存机制记录历史信息,而Q是当前位置x的内容,其是实时传入的没办法缓存
4. 缩放(Scale)
Scores scaled = Scores d k \text{Scores}_{\text{scaled}} = \frac{\text{Scores}}{\sqrt{d_k}} Scoresscaled=dkScores
5. 应用因果掩码(Causal Mask)
Scores masked = Scores scaled + M \text{Scores}_{\text{masked}} = \text{Scores}_{\text{scaled}} + M Scoresmasked=Scoresscaled+M
其中 M ∈ R 1 × ( t + 1 ) M \in \mathbb{R}^{1 \times (t+1)} M∈R1×(t+1) 是掩码向量,满足:
- M j = 0 M_j = 0 Mj=0,当 j ≤ t + 1 j \leq t+1 j≤t+1(允许关注当前及之前 token)
- M j = − ∞ M_j = -\infty Mj=−∞,当 j > t + 1 j > t+1 j>t+1(实际实现中用极小值如
-1e9代替)
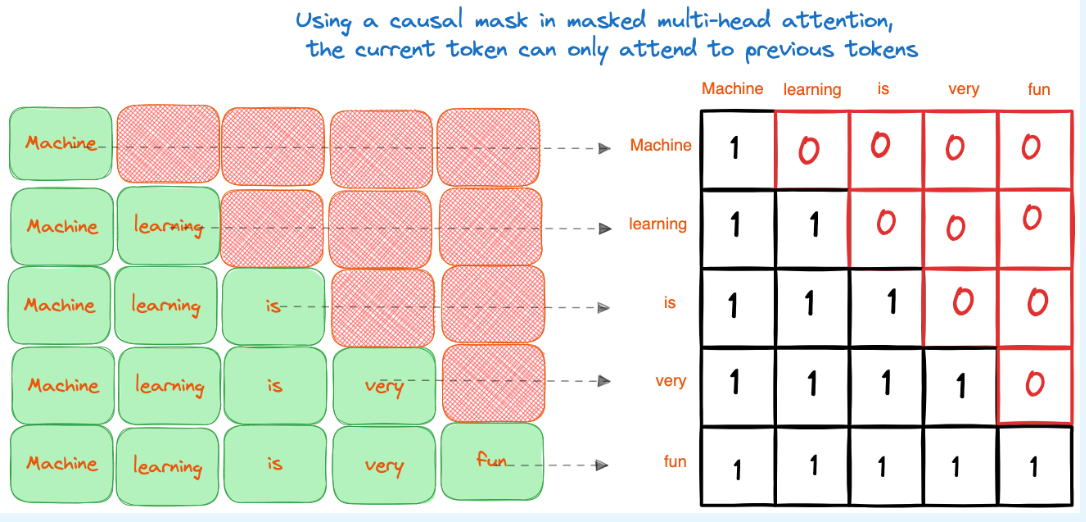
应用因果掩码操作如图所示
相当于只关注之前的token,未来的token不做计算做了掩码
6. Softmax 归一化(得到注意力权重)
Weights = softmax ( Scores masked ) ∈ R 1 × ( t + 1 ) \text{Weights} = \text{softmax}(\text{Scores}_{\text{masked}}) \quad \in \mathbb{R}^{1 \times (t+1)} Weights=softmax(Scoresmasked)∈R1×(t+1)
7.加权求和得到输出
o t + 1 = Weights ⋅ V new ∈ R d v o_{t+1} = \text{Weights} \cdot V_{\text{new}} \quad \in \mathbb{R}^{d_v} ot+1=Weights⋅Vnew∈Rdv
这里也需要计算V的历史,可以通过缓存机制记录历史信息。因此K、V会进行缓存,而Q是实时计算
8.缓存更新(为下一个 token 准备)
K cache ← K new V cache ← V new \begin{align*} K_{\text{cache}} &\leftarrow K_{\text{new}} \\ V_{\text{cache}} &\leftarrow V_{\text{new}} \end{align*} KcacheVcache←Knew←Vnew
以GPT为例,Attention 每个 Token 推理公式(自回归生成)
在自回归语言模型(如 GPT)中,文本是逐个 token 生成的。为了提升效率,Attention 计算会利用缓存(past_key, past_value)避免重复计算历史信息。
- 符号说明
| 符号 | 含义 |
|---|---|
| x t + 1 x_{t+1} xt+1 | 当前输入 token 的嵌入向量, x t + 1 ∈ R d model x_{t+1} \in \mathbb{R}^{d_{\text{model}}} xt+1∈Rdmodel |
| K cache K_{\text{cache}} Kcache | 已缓存的历史 Key 矩阵, K cache ∈ R t × d k K_{\text{cache}} \in \mathbb{R}^{t \times d_k} Kcache∈Rt×dk |
| V cache V_{\text{cache}} Vcache | 已缓存的历史 Value 矩阵, V cache ∈ R t × d v V_{\text{cache}} \in \mathbb{R}^{t \times d_v} Vcache∈Rt×dv |
| W Q , W K , W V W^Q, W^K, W^V WQ,WK,WV | 可学习的投影权重矩阵 |
| q t + 1 , k t + 1 , v t + 1 q_{t+1}, k_{t+1}, v_{t+1} qt+1,kt+1,vt+1 | 当前 token 的 Query, Key, Value |
| o t + 1 o_{t+1} ot+1 | 当前 token 的 Attention 输出 |
✅ 关键优势:通过缓存机制,每个 token 的推理时间复杂度为 O ( t ) O(t) O(t),而非 O ( t 2 ) O(t^2) O(t2),显著提升生成效率。
综上所述,Q 是当前 token,K/V 是历史信息,确保模型只能利用过去的信息进行预测,符合自回归语言建模的要求。transformers_gpt2
因此在Transformer的Decoder,会对KV历史信息进行缓存,而Q是根据当前输入实时计算的。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐


 14
14 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)