Breaking the Synthetic Barrier: Towards Stable and Generalizable Real-World Image Dehazing
本文提出了一种突破合成数据限制的图像去雾新方法。针对现有算法在真实场景中因领域差距导致的性能下降问题,创新性地设计了多级子空间分布适配器(MSDA)和双域同步优化(DDSO)策略。MSDA通过层级化子空间建模,在感知、结构和语义三个层面实现跨域特征对齐;DDSO则联合利用合成数据的监督信息和真实数据的分布特性进行同步优化。实验表明,该方法在多个数据集上显著提升性能,在RTTS数据集上的FADE指标

标题: 突破合成数据壁垒:迈向稳定且泛化的真实场景图像去雾
原文链接:https://dl.acm.org/doi/pdf/10.1145/3746027.3755780
发表:ACM MM-2025
摘要
现有基于学习的去雾方法在合成数据上表现优异,但由于领域差距,在真实场景中往往难以奏效,导致图像存在残留雾霾和细节丢失问题。为解决这一问题,本文提出一种多级子空间分布适配器(MSDA),通过层级化子空间建模逐步减小特征分布差距。同时,本文引入双域同步优化(DDSO)策略,在统一的训练框架中联合利用合成数据的监督信息和真实场景的适配学习。大量实验验证了所提方法的优越性,其在无参考图像质量指标上也表现出色。
CCS 概念
• 计算方法学 → 人工智能;计算机视觉;计算机视觉问题;图像重建;
关键词
图像去雾;领域适配;子空间建模;训练策略优化
1 引言
图像去雾旨在从雾霾退化的观测图像中重建视觉真实的图像。尽管现有方法在合成数据集[11, 29, 37]上表现良好,但由于领域差距,它们往往难以泛化到真实场景。合成数据假设训练样本和测试样本是独立同分布的,但真实世界数据存在显著的分布差异,导致模型性能下降。
为缓解这一问题,本文提出一种多级子空间分布适配器(MSDA),在深度特征空间中进行逐步适配——该空间中的分布偏移更为明显。与在像素级或浅层特征上操作的方法[28]不同,MSDA在多个编码器阶段对感知、结构和语义层面的特征进行跨域对齐。这种层级化策略保留了细粒度细节和高层语义,提升了模型对真实场景的泛化能力。如图1所示,在NH-HAZE数据集[1]上,MSDA有效减小了合成数据预测结果与真实标签之间的分布差异,生成了更稳定、一致的特征表示。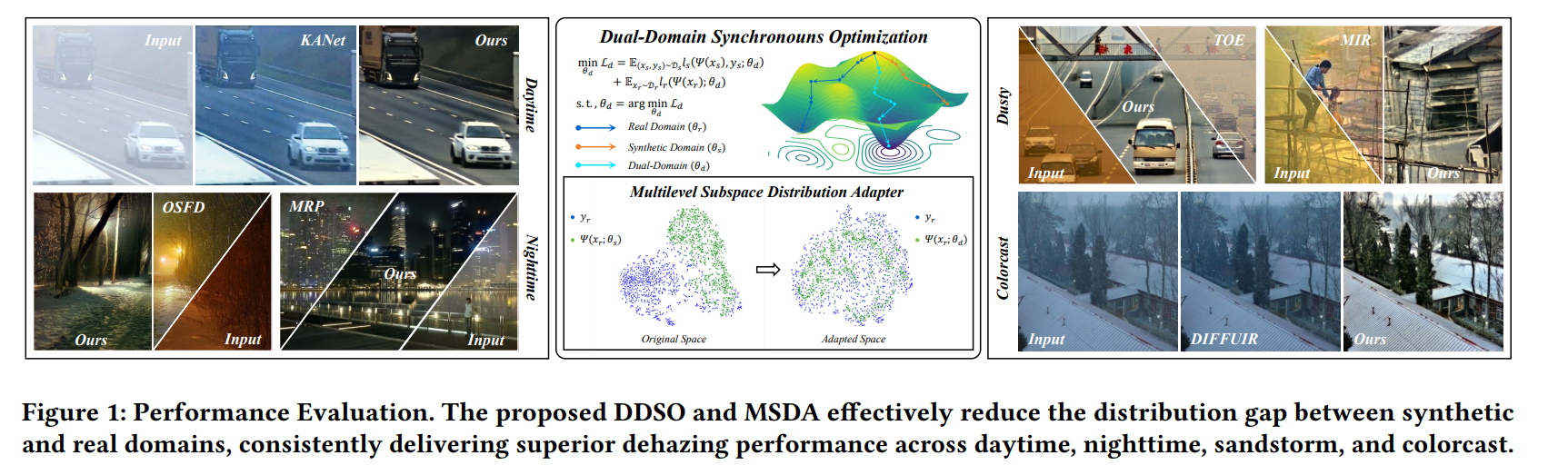
尽管MSDA在特征层面有效减小了领域差距,但仅基于合成数据训练仍会面临过拟合问题,限制模型泛化到真实场景的能力。为解决这一问题,本文提出双域同步优化(DDSO)策略,在训练过程中联合在合成域和真实域上优化模型。
DDSO利用合成数据的密集监督信息,同时适配真实数据的分布特性。通过联合利用带标签的合成数据和真实域特征,促使模型学习兼具语义意义和跨域鲁棒性的特征表示。如图1所示,单域训练的性能欠佳,而DDSO在多种复杂挑战场景(包括白天、夜间、沙尘暴和偏色场景)中均能稳定取得更优结果。
综上所述,本文的主要贡献如下:
- 为有效减小合成雾霾数据与真实雾霾数据之间的领域差异,提出多级子空间分布适配器(MSDA),对感知、结构和语义特征进行层级化对齐。
- 引入双域同步优化(DDSO)策略,联合在合成域和真实域上训练,结合监督学习的稳定性和真实域的自适应学习,提升模型在复杂多样场景下的泛化能力。
- 所提方法在不同合成数据集(THaze、RESIDE、Haze4K)和网络架构(MSBDN、Dehamer、DEA)上均能持续提升去雾性能,在RTTS数据集上的FADE指标提升37.24%、PM2.5指标提升29.61%、BIQME指标提升3.98%、熵值(Entropy)提升1.61%。
2 相关工作
2.1 领域适配
大多数去雾模型依赖合成数据,但合成图像与真实世界图像之间的领域差距往往限制了模型的泛化能力。为解决这一问题,领域适配已成为一种颇具前景的方案,无需依赖真实清晰图像标签。现有方法可分为三类:
- 第一类是特征对齐方法,采用对抗学习或最大均值差异等统计指标来对齐跨域深度特征[27]。
- 第二类是基于语义先验的方法,融入清晰图像的先验信息(如结构、纹理或颜色统计特征),引导感知真实的图像恢复[13, 32]。
- 第三类是伪监督策略,通过生成伪标签或施加一致性约束进行自监督适配,利用无标签真实图像[5, 8]。
尽管这些方法具有一定效果,但它们往往难以实现跨场景泛化,且对光照变化、雾霾浓度和颜色偏差高度敏感。这凸显了在真实场景中实现鲁棒且自适应性能仍面临挑战。
2.2 学习策略优化
除领域适配外,学习范式对提升去雾模型的鲁棒性和泛化能力也至关重要。近年来,多任务学习、自蒸馏和对比学习等策略在提高训练效率和特征表达能力方面展现出潜力:
- 多任务学习将去雾与深度估计或光照建模等相关任务联合优化[18, 29],引入有益的几何和物理先验。但该方法的性能对任务选择和损失平衡较为敏感,适配不当的辅助任务可能会阻碍主任务目标的实现。
- 自蒸馏采用师生框架,在无监督或弱监督设置下,学生模型从教师模型的中间输出中学习[20]。其效果严重依赖教师模型的质量,在训练初期教师模型可能会误导学生模型。
- 对比学习通过拉近正样本对、推远负样本对,学习领域不变且具有判别力的特征[30],但由于样本配对有限或欠佳,往往存在训练不稳定性问题。
这些局限性共同影响了现有学习范式的稳定性和可扩展性,尤其在复杂且未见过的真实场景中表现更为明显。
3 所提方法
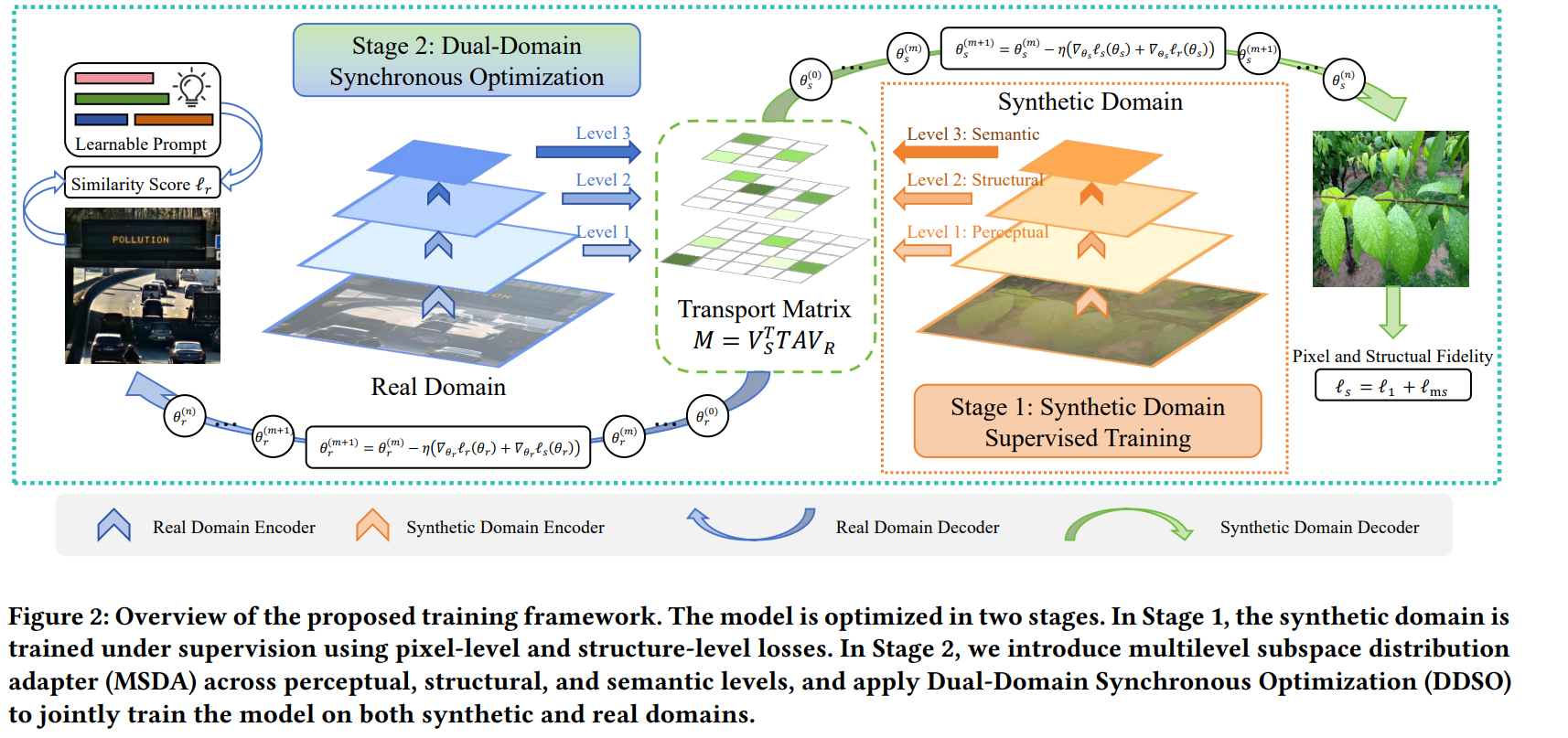
图2:所提训练框架概述。该模型分两个阶段进行优化:第一阶段,在合成域上利用像素级和结构级损失进行监督训练;第二阶段,在感知、结构和语义层面引入多级子空间分布适配器(MSDA),并采用双域同步优化(DDSO)策略在合成域和真实域上联合训练模型。
图2展示了所提方法的整体训练框架,该框架基于混合架构模型 Ψ \Psi Ψ构建,包含两个阶段。模型 Ψ \Psi Ψ集成了预训练的Res2Net编码器[14]和基于MSBDN的解码器[7],通过通道注意力模块[31]连接以增强特征融合。该设计有效结合了清晰度感知表示、多尺度细化、改进的信息流和语义一致性,为鲁棒且泛化的去雾任务构建了强大的骨干网络。
第一阶段,在合成域上进行全监督训练,学习稳定且与清晰图像对齐的特征表示。第二阶段,引入多级子空间分布适配器(MSDA),在感知、结构和语义层面逐步缩小合成域与真实域之间的分布差距。这一过程由传输矩阵引导,下一节将详细说明。
3.1 多级子空间分布适配器
如前所述,领域差异体现在不同的特征层面,从纹理到语义结构。为解决这一问题,我们采用共享编码器 E ( ⋅ ) E(\cdot) E(⋅)从合成输入 I s I_s Is和真实输入 I r I_r Ir中提取多个阶段的特征,涵盖 N N N个层级的表示。每个特征张量随后被转换为紧凑且具有判别力的矩阵形式,以便进行子空间建模,得到:
F ~ s = R ( E ( I s ) ) = { F ~ s ( l ) } l = 1 N (1) \tilde{F}_s=\mathcal{R}\left(E\left(I_s\right)\right)=\left\{\tilde{F}_s^{(l)}\right\}_{l=1}^{N} \tag{1} F~s=R(E(Is))={F~s(l)}l=1N(1)
其中, R ( ⋅ ) \mathcal{R}(\cdot) R(⋅)表示将4D特征张量展平为2D矩阵的重塑操作, R − 1 ( ⋅ ) \mathcal{R}^{-1}(\cdot) R−1(⋅)表示其逆操作。真实域的特征 F ~ r ( l ) \tilde{F}_r^{(l)} F~r(l)通过相同方式获得。
为提取能够捕捉特征分布主要变化的紧凑且具表达力的子空间,我们求解以下保方差优化问题:
V s ( l ) = arg max V ⊤ V = I Tr ( V ⊤ F ~ s ( l ) ⊤ F ~ s ( l ) V ) V_s^{(l)}=\arg\max_{V^{\top}V=I} \text{Tr}\left(V^{\top} \tilde{F}_s^{(l)\top} \tilde{F}_s^{(l)} V\right) Vs(l)=argV⊤V=ImaxTr(V⊤F~s(l)⊤F~s(l)V)
然后,通过选择最重要的方向及其相关方差来定义降维子空间:
S s ( l ) = span ( max d ( V s ( l ) , Σ s ( l ) ) ) = span ( V s ( l , d ) , Σ s ( l , d ) ) (3) S_s^{(l)}=\text{span}\left(\max_d\left(V_s^{(l)}, \Sigma_s^{(l)}\right)\right)=\text{span}\left(V_s^{(l,d)}, \Sigma_s^{(l,d)}\right) \tag{3} Ss(l)=span(dmax(Vs(l),Σs(l)))=span(Vs(l,d),Σs(l,d))(3)
其中, max d ( ⋅ ) \max_d(\cdot) maxd(⋅)表示选择占比最大方差的前 d d d个主成分。真实域的子空间 S r ( l ) S_r^{(l)} Sr(l)通过类似方式构建。
为考虑子空间之间的空间方向和分布扩散,我们估计一个转换矩阵 T ( l ) T^{(l)} T(l)(反映基向量方向的旋转或偏移)和一个矩阵 A ( l ) A^{(l)} A(l)(比较数据沿这些方向的变化程度):
T ( l ) = V s ( l , d ) ⊤ V r ( l , d ) , A ( l ) = Σ r ( l , d ) Σ s ( l , d ) (4) T^{(l)}=V_s^{(l,d)\top}V_r^{(l,d)},\ A^{(l)}=\frac{\sqrt{\Sigma_r^{(l,d)}}}{\sqrt{\Sigma_s^{(l,d)}}} \tag{4} T(l)=Vs(l,d)⊤Vr(l,d), A(l)=Σs(l,d)Σr(l,d)(4)
基于计算得到的转换矩阵,将合成域特征投影到真实域的适配子空间中:
F ~ s ( l ) ′ = F ~ s ( l ) M ( l ) (5) \tilde{F}_s^{(l)\prime}=\tilde{F}_s^{(l)} M^{(l)} \tag{5} F~s(l)′=F~s(l)M(l)(5)
其中,传输矩阵 M ( l ) M^{(l)} M(l)定义为:
M ( l ) = V s ( l , d ) T ( l ) A ( l ) V r ( l , d ) ⊤ (6) M^{(l)}=V_s^{(l,d)} T^{(l)} A^{(l)} V_r^{(l,d)\top} \tag{6} M(l)=Vs(l,d)T(l)A(l)Vr(l,d)⊤(6)
最后,将转换后的多级表示重新投影到原始张量形式,并通过解码器生成适配结果:
I s o u t = D ( ⋃ l = 1 N R − 1 ( F ~ s ( l ) ′ ) ) (7) I_s^{out}=\mathcal{D}\left(\bigcup_{l=1}^{N} \mathcal{R}^{-1}\left(\tilde{F}_s^{(l)\prime}\right)\right) \tag{7} Isout=D(l=1⋃NR−1(F~s(l)′))(7)
其中, D ( ⋅ ) \mathcal{D}(\cdot) D(⋅)表示解码器,用于从转换后的多级特征集中聚合并重建清晰图像。所提多级子空间分布适配器(MSDA)的详细工作流程如算法1所示。
输入:合成域输入 I s I_s Is、真实域输入 I r I_r Ir、特征层级数 N N N
输出:适配结果 I s o u t I_s^{out} Isout、真实域特征 { F ~ r ( l ) } l = 1 N \{\tilde{F}_r^{(l)}\}_{l=1}^{N} {F~r(l)}l=1N
1: % 提取并重塑多级特征
2: { F ~ s ( l ) } l = 1 N ← R ( E ( I s ) ) \{\tilde{F}_s^{(l)}\}_{l=1}^{N} \leftarrow \mathcal{R}(E(I_s)) {F~s(l)}l=1N←R(E(Is)), { F ~ r ( l ) } l = 1 N ← R ( E ( I r ) ) \{\tilde{F}_r^{(l)}\}_{l=1}^{N} \leftarrow \mathcal{R}(E(I_r)) {F~r(l)}l=1N←R(E(Ir))
3: for l = 1 l=1 l=1 to N N N do
4: % 计算完整子空间基向量
5: V s ( l ) ← arg max V ⊤ V = I Tr ( V ⊤ F ~ s ( l ) ⊤ F ~ s ( l ) V ) V_s^{(l)} \leftarrow \arg\max_{V^{\top}V=I} \text{Tr}\left(V^{\top} \tilde{F}_s^{(l)\top} \tilde{F}_s^{(l)} V\right) Vs(l)←argmaxV⊤V=ITr(V⊤F~s(l)⊤F~s(l)V)
6: V r ( l ) ← arg max V ⊤ V = I Tr ( V ⊤ F ~ r ( l ) ⊤ F ~ r ( l ) V ) V_r^{(l)} \leftarrow \arg\max_{V^{\top}V=I} \text{Tr}\left(V^{\top} \tilde{F}_r^{(l)\top} \tilde{F}_r^{(l)} V\right) Vr(l)←argmaxV⊤V=ITr(V⊤F~r(l)⊤F~r(l)V)
7: % 提取前d个子空间表示
8: ( V s ( l , d ) , Σ s ( l , d ) ) ← max d ( V s ( l ) , Σ s ( l ) ) (V_s^{(l,d)}, \Sigma_s^{(l,d)}) \leftarrow \max_d(V_s^{(l)}, \Sigma_s^{(l)}) (Vs(l,d),Σs(l,d))←maxd(Vs(l),Σs(l))
9: ( V r ( l , d ) , Σ r ( l , d ) ) ← max d ( V r ( l ) , Σ r ( l ) ) (V_r^{(l,d)}, \Sigma_r^{(l,d)}) \leftarrow \max_d(V_r^{(l)}, \Sigma_r^{(l)}) (Vr(l,d),Σr(l,d))←maxd(Vr(l),Σr(l))
10: % 计算转换矩阵
11: T ( l ) ← V s ( l , d ) ⊤ V r ( l , d ) T^{(l)} \leftarrow V_s^{(l,d)\top} V_r^{(l,d)} T(l)←Vs(l,d)⊤Vr(l,d)
12: A ( l ) ← Σ r ( l , d ) / Σ s ( l , d ) A^{(l)} \leftarrow \sqrt{\Sigma_r^{(l,d)}} / \sqrt{\Sigma_s^{(l,d)}} A(l)←Σr(l,d)/Σs(l,d)
13: M ( l ) ← V s ( l , d ) T ( l ) A ( l ) V r ( l , d ) ⊤ M^{(l)} \leftarrow V_s^{(l,d)} T^{(l)} A^{(l)} V_r^{(l,d)\top} M(l)←Vs(l,d)T(l)A(l)Vr(l,d)⊤
14: % 转换合成域特征
15: F ~ s ( l ) ′ ← F ~ s ( l ) M ( l ) \tilde{F}_s^{(l)\prime} \leftarrow \tilde{F}_s^{(l)} M^{(l)} F~s(l)′←F~s(l)M(l)
16: end for
17: % 重建输出
18: I s o u t ← D ( ⋃ l = 1 N R − 1 ( F ~ s ( l ) ′ ) ) I_s^{out} \leftarrow \mathcal{D}\left(\bigcup_{l=1}^{N} \mathcal{R}^{-1}(\tilde{F}_s^{(l)\prime})\right) Isout←D(⋃l=1NR−1(F~s(l)′))
19: return I s o u t I_s^{out} Isout, { F ~ r ( l ) } l = 1 N \{\tilde{F}_r^{(l)}\}_{l=1}^{N} {F~r(l)}l=1N



3.2 双域同步优化
为进一步提升模型的泛化能力,我们引入双域同步优化(DDSO)策略,在MSDA之后联合利用合成域和真实域的反馈监督网络。具体而言,由于MSDA集成到每个训练迭代中,解码器同时从合成域和真实域特征中重建去雾输出。真实域输出计算如下:
I r o u t = D ( ⋃ l = 1 N R − 1 ( F ~ r ( l ) ) ) (8) I_r^{out}=\mathcal{D}\left(\bigcup_{l=1}^{N} \mathcal{R}^{-1}\left(\tilde{F}_r^{(l)}\right)\right) \tag{8} Irout=D(l=1⋃NR−1(F~r(l)))(8)
然后,通过统一的训练框架优化网络,该框架结合了合成域的强监督信息和真实域的补充无监督反馈。以下详细说明两个域的损失函数设计。
对于合成输入 I s I_s Is,适配结果 I s o u t I_s^{out} Isout采用混合损失监督,平衡像素保真度 ℓ 1 \ell_1 ℓ1和多尺度结构一致性 ℓ m s \ell_{ms} ℓms:
ℓ s = λ 1 ∥ I s o u t − I c ∥ 1 + λ 2 ( 1 − ∏ k = 1 K SSIM k ( I s o u t , I c ) ) (9) \ell_s=\lambda_1\left\|I_s^{out}-I_c\right\|_1+\lambda_2\left(1-\prod_{k=1}^{K} \text{SSIM}_k\left(I_s^{out}, I_c\right)\right) \tag{9} ℓs=λ1
Isout−Ic
1+λ2(1−k=1∏KSSIMk(Isout,Ic))(9)
其中, I c I_c Ic是对应的清晰图像标签, SSIM k \text{SSIM}_k SSIMk衡量多尺度结构相似性。 λ 1 \lambda_1 λ1和 λ 2 \lambda_2 λ2控制像素精度与结构相似性之间的平衡。
对于真实域输入 I r I_r Ir,受Liang等人[23]的启发,在缺乏配对监督的情况下,我们采用基于CLIP的无监督损失 ℓ r \ell_r ℓr约束预测结果。具体而言,从Foggy500[3]数据集中采样雾霾图像作为负样本 I − I_- I−,从RESIDE-OTS子集[22]中采样相同数量的清晰图像作为正样本 I + I_+ I+,每个样本分别关联对应的可学习提示 T − T_- T−和 T + T_+ T+。通过CLIP的图像编码器 Φ image ( ⋅ ) \Phi_{\text{image}}(\cdot) Φimage(⋅)和文本编码器 Φ text ( ⋅ ) \Phi_{\text{text}}(\cdot) Φtext(⋅)对每个图像-提示对进行编码,并在CLIP的 latent 空间中采用对比交叉熵损失优化提示。一旦提示能够有效区分雾霾和清晰图像,便为真实域输出推导基于相似性的对比损失:
t r = e cos ( Φ image ( I r o u t ) , Φ text ( T − ) ) ∑ i ∈ { − , + } e cos ( Φ image ( I r o u t ) , Φ text ( T i ) ) (10) t_r=\frac{e^{\cos\left(\Phi_{\text{image}}\left(I_r^{out}\right), \Phi_{\text{text}}\left(T_-\right)\right)}}{\sum_{i\in\{-,+\}} e^{\cos\left(\Phi_{\text{image}}\left(I_r^{out}\right), \Phi_{\text{text}}\left(T_i\right)\right)}} \tag{10} tr=∑i∈{−,+}ecos(Φimage(Irout),Φtext(Ti))ecos(Φimage(Irout),Φtext(T−))(10)

如图2所示,与传统的单域优化不同,DDSO建立了双向梯度流,在整个训练过程中促进合成域和真实域之间的相互增强。这种设计使两个域在学习过程中能够交互并协同进化,而非独立优化。
从合成域的角度来看,参数更新同时受来自带标签合成数据的监督学习信号和通过共享网络传播的无监督反馈指导:
θ s ( m + 1 ) = θ s ( m ) − η ( ∇ θ s ℓ s ( θ s ) + ∇ θ s ℓ r ( θ s ) ) (11) \theta_s^{(m+1)}=\theta_s^{(m)}-\eta\left(\nabla_{\theta_s} \ell_s\left(\theta_s\right)+\nabla_{\theta_s} \ell_r\left(\theta_s\right)\right) \tag{11} θs(m+1)=θs(m)−η(∇θsℓs(θs)+∇θsℓr(θs))(11)
其中,监督损失 ℓ s \ell_s ℓs确保像素级和结构保真度,而 ℓ r \ell_r ℓr的指导使合成输出更自然,更接近真实场景的清晰度。
从真实域的角度来看,更新规则为:
θ r ( m + 1 ) = θ r ( m ) − η ( ∇ θ r ℓ r ( θ r ) + ∇ θ r ℓ s ( θ r ) ) (12) \theta_r^{(m+1)}=\theta_r^{(m)}-\eta\left(\nabla_{\theta_r} \ell_r\left(\theta_r\right)+\nabla_{\theta_r} \ell_s\left(\theta_r\right)\right) \tag{12} θr(m+1)=θr(m)−η(∇θrℓr(θr)+∇θrℓs(θr))(12)
其中,无监督目标 ℓ r \ell_r ℓr促进与真实世界分布的一致性,而 ℓ s \ell_s ℓs的辅助监督作为正则化项,减轻过增强现象并抑制不自然的纹理或伪影。

4 实验结果
4.1 实现细节
4.1.1 训练设置
我们基于PyTorch框架在NVIDIA RTX 2080 Ti GPU上实现模型。采用Adam优化器,设置 β 1 = 0.9 \beta_1=0.9 β1=0.9、 β 2 = 0.999 \beta_2=0.999 β2=0.999、 ε = 1 0 − 8 \varepsilon=10^{-8} ε=10−8。第一训练阶段的初始学习率设为 1 × 1 0 − 4 1\times10^{-4} 1×10−4,第二阶段设为 1 × 1 0 − 5 1\times10^{-5} 1×10−5;两个阶段的学习率均通过余弦退火调度逐步衰减至0。模型在RGB空间中训练,采用的数据增强技术包括随机256×256裁剪、90度旋转和水平翻转。
4.1.2 数据集描述与评价指标
训练阶段,我们采用THaze[12]数据集作为合成域,使用URHI[22]数据集中的4660张真实世界雾霾图像作为真实域,同时预留150张URHI图像用于评估。为全面验证所提方法的有效性,我们在多个代表性真实世界数据集上进行测试,包括RTTS[22]、URHI、Fattal[9]和夜间雾霾数据集NHRW[35]。这四个数据集的雾霾图像数量分别为4322张、150张、31张和150张。
为评估真实世界场景下的去雾性能,我们采用四个广泛认可的无参考图像质量评估指标:FADE[4]、PM2.5[16]、熵值(Entropy)和BIQME[17]。
4.1.3 对比方法
为全面评估模型在不同真实世界场景下的性能,我们将所提方法与针对不同场景设计的最先进方法进行对比:
- 针对白天去雾,评估对象包括近期的主流方法,如C2P[37]、D4+[33]、IPC[13]、DEA[2]和KANet[10]。
- 为评估复杂天气变化下的性能,进一步纳入通用型多天气恢复模型,如MIR[26]、TOE[15]、ROP+[24]、DiffUIR[36]和FSNet[6]。
- 此外,针对高度病态的夜间场景,我们与专门的夜间去雾技术进行基准测试,包括MRP[34]、MRPF[34]、OSFD[35]和GAPSF[21]。
4.2 常规场景下的评估
4.2.1 定量对比
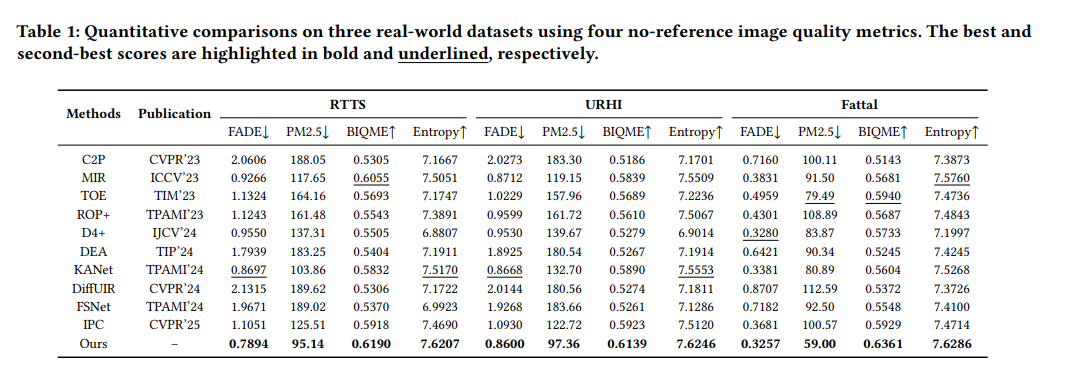
表1展示了所提方法与10种代表性去雾算法的全面对比,包括5种最先进的白天去雾模型和5种近期的多天气处理方法。所提方法在多个真实世界基准数据集上均持续优于所有对比算法,证明其在不同雾霾场景下具有更优的稳定性和泛化能力。
4.2.2 定性对比

如图3所示,在真实世界道路场景中,全监督方法(C2P、DEA)的性能有限,无法提供令人满意的去雾结果。无监督方法(D4+)和领域适配方法(IPC、KANet)在颜色恢复和细节保留方面也存在明显局限。相比之下,所提方法能更有效地去除雾霾,恢复远处的结构和交通标志。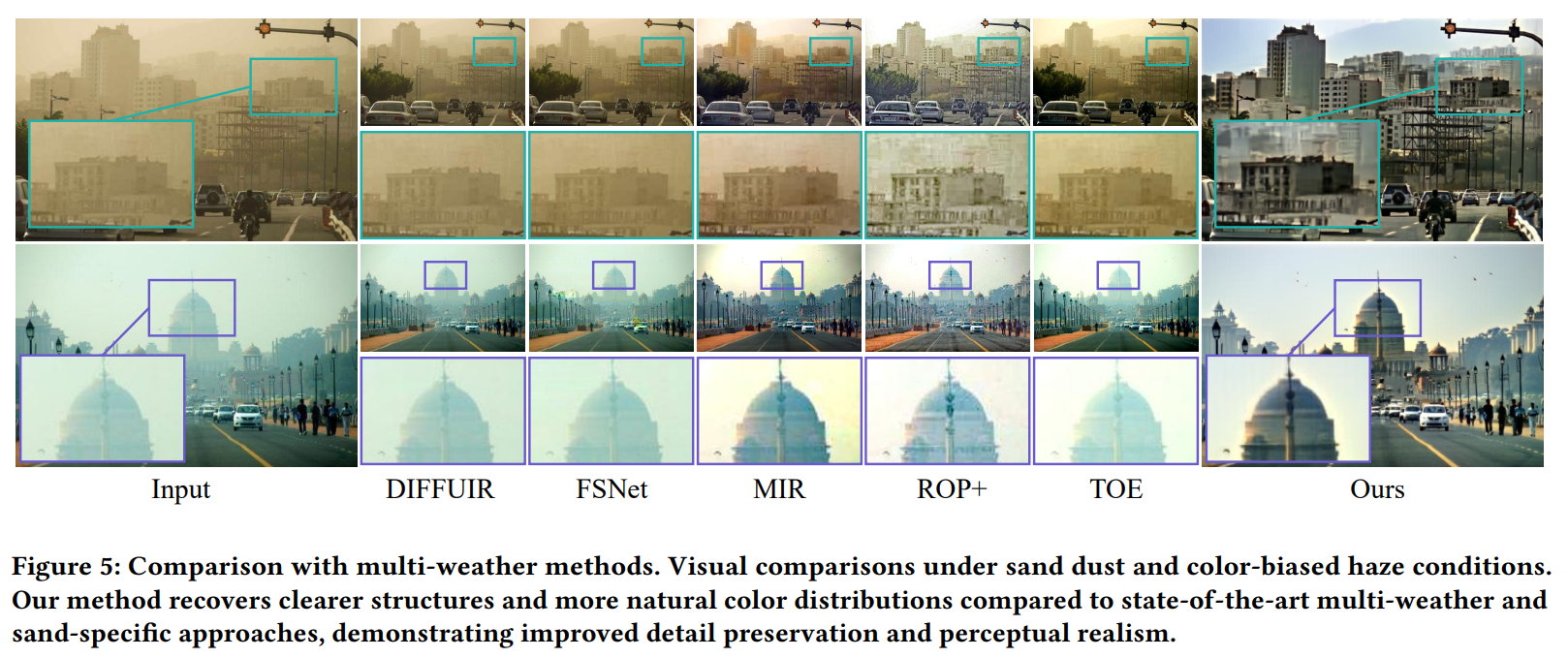
图5进一步表明,多天气方法(DiffUIR、FSNet)在沙尘暴和偏色雾霾等挑战场景下表现不佳,而MIR容易引入严重的颜色失真。即使是针对沙尘场景设计的方法(ROP+、TOE),在严重偏色情况下的鲁棒性也会下降。相比之下,所提方法在多样复杂的场景中均能稳定生成清晰自然的去雾结果,同时保留精细纹理和结构细节。
4.2.3 RTTS数据集上的任务驱动目标检测
为进一步评估所提方法在道路交通场景中的实际适用性,我们采用最新的YOLO11s模型在任务驱动的RTTS数据集上进行目标检测。如图4所示,在严重偏色的道路场景中,所提方法不仅能准确定位车辆目标,还能获得比其他多天气去雾方法显著更高的置信度分数。定量检测结果汇总于表2,所提方法在RTTS数据集中标注的五个交通相关目标类别上的检测精度均稳居前两名,并在平均精度(mAP)上取得最佳总体性能。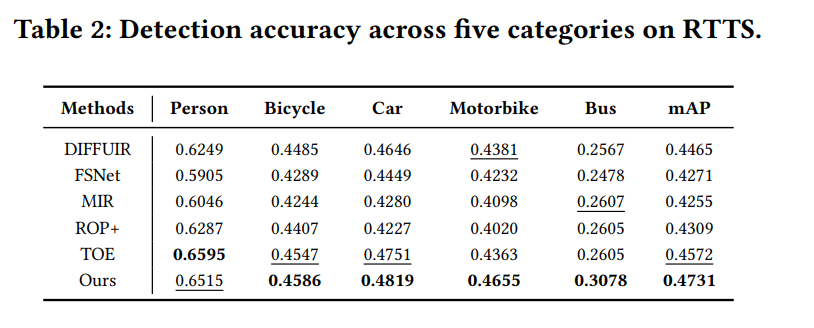
4.3 夜间场景下的评估

为评估模型的领域泛化能力,我们在具有挑战性的真实世界夜间雾霾场景下进行对比实验。图6(a)表明,在RTTS数据集的夜间场景中,常规方法(D4+、IPC、FSNet)难以处理强烈的光晕效应,而ROP+会引入严重的噪声放大。图6(b)进一步凸显了现有夜间专用去雾方法在更具挑战性的NHRW数据集上的局限性,这些方法常出现颜色失真和雾霾去除不彻底的问题。相比之下,所提方法能有效消除雾霾并抑制光晕,同时更好地保留结构细节,生成更自然的视觉结果。表3中的定量对比证实,所提方法在多个无参考图像质量指标上均持续取得更优性能。
(注:表1为基于四个无参考图像质量指标在三个真实世界数据集上的定量对比,表2为RTTS数据集上五个类别的检测精度对比,表3为NHRW数据集上的无参考分数对比;图3为白天专用方法的视觉对比,图4为RTTS数据集上目标检测的视觉对比,图5为多天气方法的视觉对比,图6为夜间场景去雾性能的定性对比)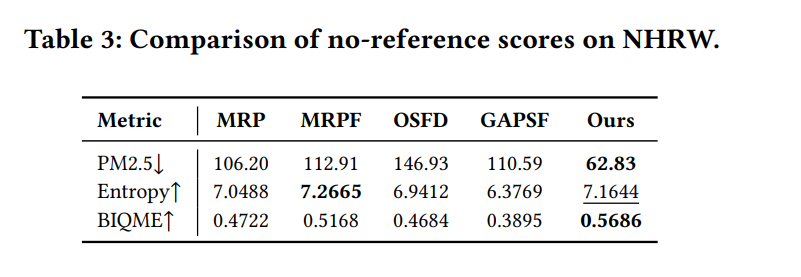
5 消融研究
5.1 算法特性分析
本文证明,所提MSDA和DDSO策略能显著提升模型对真实世界域的泛化能力,且不受合成数据分布或底层网络架构的影响。为验证这一点,我们分析了它们在不同合成数据集和骨干模型上的有效性。
5.1.1 跨多样合成域的迁移性
我们在三个合成域(RESIDE[22]、Haze4K[25]和THaze)上训练模型,并在真实世界基准数据集Fattal和NHRW上进行评估。如表4所示,与仅依赖合成数据的第一阶段训练相比,引入第二阶段适配后,四个广泛使用的无参考图像质量评估指标均得到显著提升。此外,图8中的视觉对比进一步表明,所提方法在所有合成域上均能持续提升感知质量,凸显其强大的跨域泛化能力。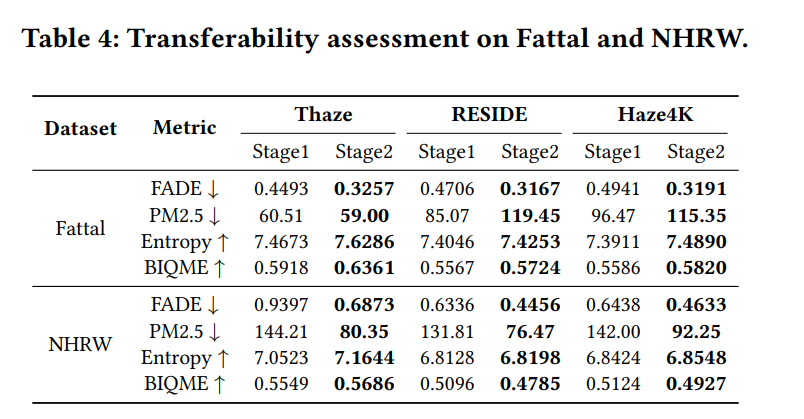

5.1.2 跨多样架构的适用性
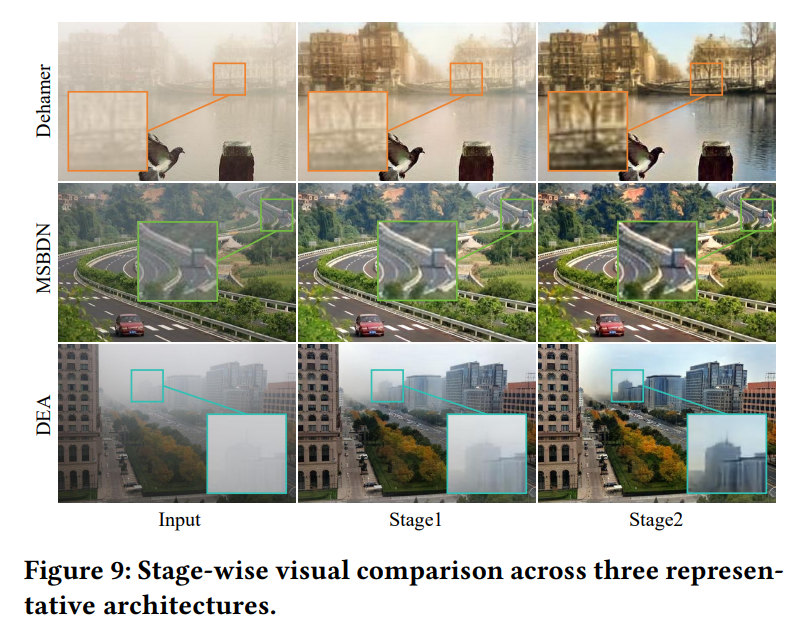
我们将所提MSDA和DDSO训练策略集成到三种代表性架构中:MSBDN、Dehamer[19]和DEA[2]。如表5所示,与在THaze上的第一阶段训练相比,所提方法在URHI和Fattal数据集的大多数指标上均取得显著提升。图9中的视觉结果进一步验证了其有效性,在不同骨干网络上均能提供更优的去雾质量和更具吸引力的结果。
此外,在权威的RTTS数据集上,图7显示所提方法在合成域和模型架构上均能实现持续提升。具体而言,FADE和PM2.5指标分别显著降低37.24%和29.61%,而熵值(Entropy)和BIQME指标分别提升1.61%和3.98%。
(注:表4为Fattal和NHRW数据集上的迁移性评估,表5为URHI和Fattal数据集上的适用性评估;图7为不同合成域和架构下各指标的雷达图,图8为多个合成雾霾域上的阶段式视觉对比,图9为三种代表性架构上的阶段式视觉对比)
5.2 MSDA的效果
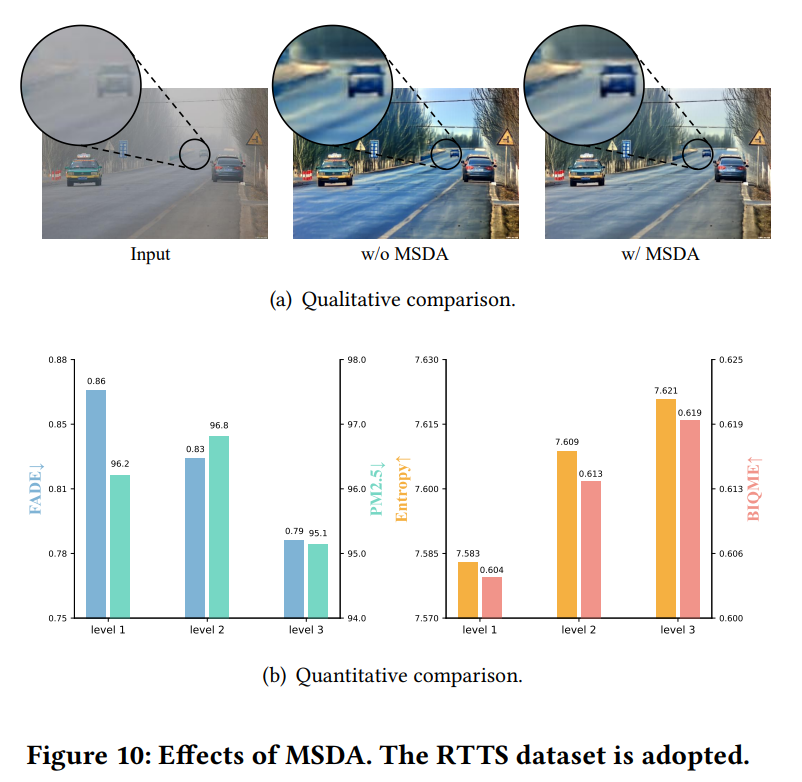
图10通过详细的定性和定量对比验证了所提MSDA的有效性。如图10(a)所示,缺少MSDA时,模型在具有挑战性的真实世界场景中会产生不稳定、不一致的去雾结果,常出现明显的颜色失真和结构完整性下降。而加入MSDA后,这些伪影被显著抑制,生成的重建图像更清晰、自然。
图10(b)展示了对不同网络层(从高层语义到低层感知表示)进行逐步适配的影响。当适配深度从1级增加到3级时,所有评估指标均呈现持续提升,证实更深层次的特征级适配能显著增强领域鲁棒性和整体视觉保真度。
(注:图10(a)为定性对比,图10(b)为定量对比,采用RTTS数据集)
5.3 DDSO的效果
图11从定性和定量角度对所提双域同步优化(DDSO)策略进行了全面对比分析。如图11(a)所示,不使用DDSO时(仅使用MSDA),模型容易过拟合合成数据的先验信息,导致雾霾去除不彻底、纹理丢失和颜色色调不自然。相比之下,融入DDSO的模型持续生成更清晰的输出,结构更锐利、颜色更准确,证明其对真实世界场景具有更好的泛化能力。
图11(b)通过四个广泛采用的无参考图像质量指标(FADE、PM2.5、熵值、BIQME)进一步量化了这种提升。与基线方法相比,DDSO持续实现更低的雾霾相关分数(FADE和PM2.5)和更高的感知质量分数(熵值和BIQME),表明其能更有效地去除雾霾并提升结构一致性。视觉和定量指标的双重提升证实,DDSO增强了整体去雾质量和对真实世界场景的泛化能力。
(注:图11(a)为定性对比,图11(b)为定量对比,采用URHI数据集)
6 结论
本文提出一种新颖的图像去雾框架,通过引入多级子空间分布适配器(MSDA)和双域同步优化(DDSO)策略,提升模型在真实世界场景中的泛化能力。MSDA通过层级化、多尺度的特征适配,有效减小合成域与真实域之间的分布差距;DDSO在两个域上联合优化模型,进一步提升训练稳定性和泛化能力。大量实验表明,所提方法在多样且具有挑战性的真实世界场景(包括白天、夜间、沙尘暴和偏色场景)中均能取得优异的去雾性能,同时展现出强大的跨域迁移性和广泛的实际适用性。
思考:
对于第一个模块,个人理解:对于合成域和真实域而言,编码器得到的特征很可能是不一样的,所以解码器面对不一样的特征导致,在合成域数据上去雾效果好,而真实域数据上效果差,那么就通过第一个模块得到的转换矩阵,使得解码器面对合成域和真实域的特征大致相似(把合成域特征转换成接近真实域特征),从而在真实图片中得到比较好的去雾效果。
对于第二个模块,个人理解:利用合成域的强监督得到比较明显(好)的去雾效果,利用真实域的弱监督,通过对比损失,让解码器得到的特征与清晰的文本特征更加接近,让解码器生成语义为清晰的图像。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 10
10 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)