超越相关性:迈向生物医学中的因果大语言模型代理
大语言模型(LLMs)在生物医学领域展现出潜力,但缺乏真正的因果理解,而是依赖于相关性。本文设想了因果LLM代理,这些代理能够整合多模态数据(文本、图像、基因组学等),并进行基于干预的推理以推断因果关系。实现这一目标需要克服关键挑战:设计安全且可控的代理框架;开发严格的因果评估基准;整合异构数据源;以及协同结合LLMs与结构化知识(KGs)和正式因果推理工具。这样的代理可以解锁变革性机会,包括通过
阿迪布·巴兹吉尔
密苏里大学哥伦比亚分校
哥伦比亚,密苏里州 65211,美国
阿米尔·哈比卜杜斯特·拉夫马贾尼
密苏里大学哥伦比亚分校
哥伦比亚,密苏里州 65211,美国
张玉文 *
密苏里大学哥伦比亚分校
哥伦比亚,密苏里州 65211,美国
摘要
大语言模型(LLMs)在生物医学领域展现出潜力,但缺乏真正的因果理解,而是依赖于相关性。本文设想了因果LLM代理,这些代理能够整合多模态数据(文本、图像、基因组学等),并进行基于干预的推理以推断因果关系。实现这一目标需要克服关键挑战:设计安全且可控的代理框架;开发严格的因果评估基准;整合异构数据源;以及协同结合LLMs与结构化知识(KGs)和正式因果推理工具。这样的代理可以解锁变革性机会,包括通过自动化假设生成和模拟加速药物发现,以及通过患者特定的因果模型实现个性化医疗。本研究议程旨在促进跨学科努力,将因果概念和基础模型结合起来,开发可靠的AI伙伴以推动生物医学进步。
1. 引言
大语言模型(LLMs)在医学领域的许多任务中展示了前所未有的灵活性,从回答临床问题到解读生物医学文献[10]。然而,这些模型主要学习数据中的相关性,而非真正的因果关系[8]。相关性并不等于因果关系——这是生物医学研究中尤其重要的一个信条[11],因为在生物医学研究中,了解为什么某事物起作用往往比知道哪些因素与结果相关更重要。独立的LLMs会臆造、依赖过时的数据,并缺乏因果理解,这限制了它们在医学中的应用[15]。尽管LLMs擅长处理文本并隐含地捕捉领域知识,甚至生成看似合理的因果论点[9],但区分原因和结果或进行稳健的反事实推理仍然是一个挑战。它们可能表现出“因果盲点”,难以直接从复杂的生物数据中推断因果关系[22]。同时,多模态基础模型正在出现,这些模型可以解释文本、图像、基因组和其他数据的组合,生成丰富的输出,如自由文本解释或图像注释[14]。多领域数据和LLM能力的融合为创建具有因果意识的LLM代理提供了新机会。这种代理可以整合多模态生物医学数据,并像科学家一样进行推理,设想干预并预测结果。近期的研究探索了在代理框架中使用LLMs进行假设生成[4]、与工具交互[17, 20]、结构化非结构化真实世界数据(RWD)如临床笔记[7]、自动化因果发现工作流[20]、将叙述性文本转换为可分析的图结构[13],甚至进行对话式用户互动[21]。然而,要实现真正的个性化和可靠性,必须超越LLMs本身的能力。整合结构化知识来源如知识图谱(KGs)提供了一条路径来使LLM推理更可靠并增强可解释性,尽管KGs本身可能是静态的[15]。此外,真正的因果理解需要纳入正式的因果发现和推理方法,如孟德尔随机化(MR)或处理观察数据中混杂因素的技术[7, 20, 22],这些方法可以应用于个体患者数据以获得个性化的见解[8, 21]。本文概述了一个关于因果LLM代理的愿景,讨论了需要克服的关键挑战,包括LLMs、KGs、因果方法和多模态数据的协同整合,并强调了
在几个生物医学领域中的潜在机会,例如自动因果知识发现和真实世界证据(RWE)生成,如图1所示。
2. 实现因果推理的挑战
2.1. 代理框架设计与控制
构建用于生物医学的代理LLM框架意味着允许模型自主执行任务,例如提出实验、检索文献、进行分析或提出临床建议,而不仅仅是被动地回答问题。设计这种自主性引发了严重的安全性和控制挑战。在生物医学背景下,代理的行为或建议可以直接影响实验或患者的护理,因此严格监督和保障措施是必不可少的。例如,如果一个因果LLM代理连接到实验室自动化系统、PubMed文献数据库、OpenGWAS GWAS数据存储库或临床决策支持工具,我们必须确保它不会执行有害的干预或错误地检索和处理信息。MRAgent框架展示了如何让LLMs控制涉及多个外部工具和数据源的复杂工作流,用于自动化因果发现任务,例如使用孟德尔随机化。人类参与循环控制机制,如MatAgent框架中所探讨的权限门控和高风险行动许可,以及符合伦理准则的对齐,都是至关重要的。此外,代理的目标应该受到约束——一个“对齐”的代理应该理解其权威的界限。设计一个可以审计和约束LLM代理行为的框架是一个开放的挑战。整合结构化知识,如KGs,可以提高透明度并为代理的决策提供更清晰的证据,从而增加信任。LLMs本身可以用来将叙述性的临床文本,如精神病案例公式,转换为适合分析的图表示,尽管这些转换的可靠性和有效性需要仔细评估。研究人员主张AI代理应像科学家一样接受审查,对其计划和推理进行严格的同行评审。在效率和规模上取得适当的平衡,同时确保安全性和信任所需的可靠控制和可追溯性,将是生物医学LLM代理的关键。
2.2. 基准测试、评估和可重复性
评估因果LLM代理的性能提出了独特的困难。传统指标不足以衡量因果推理的质量或决策的安全性。需要新的基准和评估策略来测试特定的因果能力。这包括评估生成正确因果论证文本的能力、推理反事实的能力,以及识别案例中的必要和充分原因[9]。在形式化的因果任务上的表现,如成对因果发现或完整图生成,需要使用已建立的基准(例如Tübingen对)和领域特定的图,包括对训练截止后创建的新数据集的泛化测试[9]。新兴的替代评估方法包括结构化输出评估,例如让LLMs从医学概念生成KGs[16]或从叙述性文本生成因果图[13],然后使用图相似性度量(例如节点语义相似性、Jaccard边相似性)与专家或真实值进行比较。在生物医学应用中的任务特定性能评估,如识别癌症基因[22]或评估药物警戒中的因果关系[18],通常揭示了领域特定模型的优势。对于代理系统,评估整个工作流执行情况并与人类专家在同一多步骤任务上的表现进行比较[20],可以提供全面的评估。综合临床评估框架,如CLEVER[10],使用专家评分评估LLMs在多个临床维度(理解、推理、决策支持、风险管理)上的表现,包括不同数据分布(ID、OOD、罕见疾病)下的表现,并与医生进行比较。多代理评估,使用集成或辩论框架批评假设[2, 3],提供了另一层验证。然而,标准化协议仍然缺乏,现实世界测试仍然有限[5]。由于LLM的随机性和更新,可重复性也是一个问题[6]。虽然CoT有助于审计
性 [16, 20],但确保可验证的输出仍具挑战性。应对LLM的失败模式,如幻觉、偏差和对提示的敏感性,需要系统化的压力测试和结合这些多样化方法的稳健、多方面的评估方法 [9]。
2.3 因果推理和多模态整合的困难
当前的LLMs,即使是非常强大的模型,也缺乏对形式化因果推理的真实掌握 [9]。虽然它们在基于知识的因果发现方面表现出色(例如,从变量名称推断 A→B\mathrm{A} \rightarrow \mathrm{B}A→B)并能从文本生成反事实论据,但在观察数据中区分因果关系与相关性、严格理解干预措施以及在没有外部指导的情况下应用形式化因果方法方面本质上存在困难 [8]。它们的文本知识并不意味着对形式化数学和因果逻辑的理解。一些策略旨在通过整合LLMs与更形式化的方法和多样数据类型来弥合这一差距。一个关键策略是通过代理框架整合因果工具和方法。LLM代理可以设计为调用实现特定因果算法的外部库或API。例如,“Causal Agent”框架展示了使用标准因果发现工具(如PC算法)和表格数据分析进行因果推理的应用 [8]。特定领域的例子包括MRAgent,它通过调用工具查询PubMed、从OpenGWAS获取GWAS数据并使用TwoSampleMR包执行MR分析来自动化孟德尔随机化工作流 [20]。同样,ICGI框架结合了LLM提示的知识检索与使用Debiased Machine Learning (DML) 在组学数据上进行因果特征选择,以识别潜在的癌症基因 [22]。另一个重要方向是LLMs和知识图谱(KGs)的协同整合。KGs为LLM推理提供依据,提高可解释性并减少幻觉 [15]。LLMs帮助从文本或数据中提取新关系以构建和更新KGs。这种双向互动创建了一个更强大和动态的知识系统,解决了KGs的静态性质和LLMs的无根据性质 [15]。此外,有效处理多模态数据对于生物医学应用至关重要。代理必须处理文本、图像、结构化数据和日志 [17]。LLMs帮助结构化临床EMR文本以实现可扩展的RWE生成 [7, 10]。先进的框架如MATMCD探索显式整合多种模态,例如将检索到的文本或日志与统计因果图结合使用,利用代理进行数据增强和约束生成以改进因果发现 [7]。如前所述,叙事到图的转换是一个有前景但尚未验证的用例 [13]。构建这些能力很大程度上依赖于大规模、多模态生物医学数据集的可用性,用于训练
机遇与应用
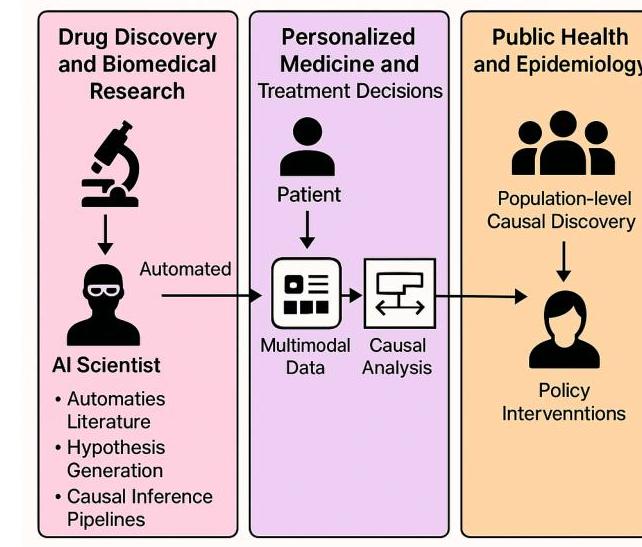
图2. 不同生物医学应用中因果LLM代理工作流的全自动周期。
更强大的基础模型 [12]。至关重要的是,领域特定的预训练和微调一致提高了模型在专门医学和因果任务上的表现,相较于通用模型 [10, 18]。
3. 机遇与应用
如图2所示,尽管面临重大挑战,未来的因果LLM代理为转化生物医学研究和医疗保健提供了令人兴奋的机会。通过结合基础模型的广泛知识和模式识别能力与原则性的因果推理,这些代理可以在多个领域解锁新颖的应用。
3.1 药物发现与生物医学研究
具备因果意识的LLM代理可以作为“AI科学家”,通过自动化知识合成、假设生成和分析来加速发现。关键应用之一是自动化的因果知识发现。像MRAgent这样的代理展示了自主扫描文献、识别给定疾病潜在的暴露-结果对、检查先前的因果分析(如孟德尔随机化)、检索相关遗传数据(OpenGWAS)、执行因果推理分析(使用TwoSampleMR等工具)并生成综合报告的能力。这大大加快了从现有知识和数据中发现潜在因果联系的过程 [20]。以此为基础,AI驱动的假设生成可以得到增强。代理可以从文献(可能通过RAG)、结构化数据库和实验数据中综合信息以提出可测试的因果假设。LLMs基于其庞大的训练数据生成因果论据的能力可以引导这一过程 [2, 4]。此外,因果代理可以帮助确定和验证靶标。通过将LLM驱动的因果推理与应用于组学数据的数据驱动因果发现方法(如DML-CGI)相结合,可以识别并优先考虑可能在癌症等疾病中起因果作用的基因或通路,并附带对其假定角色的解释 [22]。最后,自动化的实验分析,例如使用基于视觉的代理在无需任务特定训练的情况下检测显微镜图像中的药物-细胞相互作用,可以简化实验工作流。总体而言,这些能力有望缩短研究周期、基于因果可能性优先考虑实验,并发现新的治疗策略 [1]。
3.2 个性化医学与治疗决策
具备因果意识的LLM代理可以通过针对个人因果因素制定决策,超越人群平均水平,从而实现个性化医疗。核心能力之一是识别个人因果驱动因素。通过应用因果发现和推理技术,由LLM代理协调调用专用工具,对个体的纵向多模态数据(来自可穿戴设备、电子健康记录、基因组学等)进行分析,可以揭示诸如饮食、活动、睡眠与健康结果之间的患者特异性因果联系。TChatDiet使用N-of-1分析来估计个性化营养效果 [8, 21]。一旦确定了个人因果因素(例如,驱动某种癌症亚型的特定突变),代理可以定制干预措施,并建议针对该个体根本原因的靶向疗法或生活方式改变 [22]。至关重要的是,LLMs可以使用患者特异性因果模型解释推荐,提高透明度。这超越了简单地将患者匹配到指南,朝着动态将患者分层为因果子群的方向发展 [6]。LLMs在诊断辅助方面也显示出潜力。高级医疗LLMs如MedFound可以生成差异诊断并概述推理步骤,即使对于罕见疾病也显示出有效性 [10]。整合因果推理能力可以通过帮助区分原因与症状或共病来进一步提高诊断准确性。通过因果关系链接多模态数据可以进一步改善个性化护理。
3.3 公共卫生与流行病学
自动化因果发现技术,可能由MRAgent等LLM代理驱动,可以系统地扫描文献和人口水平数据(如GWAS)以假设和测试环境暴露、遗传因素与公共卫生结果之间的潜在因果联系 [20]。这些能力可以导致更加知情、数据驱动的公共卫生政策和干预措施,这些措施基于对因果机制的理解。
4. 讨论
因果LLM代理是实现科学和生物医学中可靠、有影响力的AI的关键一步。这需要超越当前LLM基于相关性的能力,转向真正理解和操作因果关系的系统。实现这一点需要一种协同方法,超越单独的LLM,将其优势与形式化因果方法、结构化知识和与外部工具的动态交互相结合。从讨论的挑战和机遇中出现了关键的研究方向。首先,协同整合显得至关重要。最佳路径是将LLMs与KGs结合以提供依据,并与形式化工具(如MR、DML)结合以进行推理。代理框架对于协调这些组件至关重要,使LLMs能够智能地调用外部工具、查询KGs并处理多样化的数据输入。其次,我们必须有效地利用LLMs的优势,同时缓解其弱点。LLMs在推断关系、生成论据和从临床叙述中提取因果结构方面表现出色。这些能力可以自动化知识合成并增强人类专业知识。然而,它们在从数据中进行形式化因果推理方面的困难、容易产生幻觉以及缺乏内在依据,需要与可验证的知识来源(KGs)和形式化因果方法相结合。稳健的评估和对齐技术对于确保安全性和可靠性至关重要。第三,进展高度依赖于数据生态系统。这包括访问大规模、多样化、多模态的生物医学数据集,以及关键的是,结构化和整合真实世界数据(RWD)的能力,特别是电子病历中大量的非结构化文本。领域特定的预训练和微调已被证明对于在专业医学和因果任务中实现高性能至关重要。第四,必须开发和标准化稳健的评估方法。这超出了典型的自然语言处理指标,包括对因果推理的具体评估、在不同数据分布和疾病稀有性上的表现评估、与专家基准相比的代理任务完成评估,以及通过结构化的人类评估框架评估临床实用性。最后,推动这项研究的应用是变革性的。关键机会包括从文献和数据中自动化因果发现、从电子病历中生成可靠的真实世界证据、通过N-of-1因果分析实现个性化医学,以及提供可解释的诊断和决策支持。
5. 结论
生物医学中因果LLM代理的发展需要从独立模型转变为复杂、集成的系统。这些代理,由专门工具赋能、由结构化知识支持并受正式因果原则指导,有可能成为研究人员和临床医生不可或缺的伙伴。实现这一愿景需要持续的跨学科合作,以应对集成、评估、验证和安全、道德部署的复杂挑战。
参考文献
[1] 阿迪布·巴兹吉尔 和 张玉文. 药物发现代理:一种自动化的药物-细胞相互作用视觉检测系统。在CVPR Workshop on Computer Vision For Drug Discovery (CVDD): 我们在哪里?超越是什么?2025年。4
[2] 阿迪布·巴兹吉尔,张玉文 等。ProteinHypothesis: 一种物理感知的多代理 RAG LLM 链用于蛋白质科学中的假设生成。在Towards Agentic AI for Science: Hypothesis Generation, Comprehension, Quantification, and Validation, 2025. 2, 4
[3] 阿迪布·巴兹吉尔,张玉文 等。MatAgent: 一种以人为中心的多代理 LLM 框架,用于加速材料科学研究周期。在AI for Accelerated Materials Design-ICLR 2025, 2025. 2
[4] 阿迪布·巴兹吉尔,张玉文 等。AgenticHypothesis: 使用 LLM 系统进行假设生成的综述。在Towards Agentic AI for Science: Hypothesis Generation, Comprehension, Quantification, and Validation, 2025. 1, 4
[5] 苏哈娜·贝迪,刘雨桐,露西·奥尔温格,德夫·达什,桑米·科耶霍,艾莉森·卡拉汉,杰森·A·弗里斯,迈克尔·沃诺,阿克沙伊·斯瓦米纳坦,丽莎·索莱曼尼·莱曼 等。大型语言模型在医疗保健应用中的测试与评估:系统评价。JAMA, 2024. 2
[6] 高尚华,方达,黄叶鹏,瓦伦蒂娜·金奇利亚,阿育什·努里,乔纳森·理查德·施瓦茨,雅沙·埃克塔菲耶,乔凡娜·康迪克 和 马林卡·齐特尼克。通过AI代理增强生物医学发现。Cell, 187(22):61256151, 2024. 2, 4
[7] 贾维尔·冈萨雷斯,克利夫·王,泽拉姆·格罗,贾斯·巴加,丽莎·陈,爱德华·奥拉夫金,阿迪提亚·诺里,罗斯汉蒂·维拉斯辛赫 等。TrialScope: 一个统一的因果框架,用于通过生物医学语言模型扩展真实世界证据生成。arXiv预印本 arXiv:2311.01301, 2023. 1, 3
[8] 韩凯荣,匡坤,赵梓宇,叶俊健,吴飞。基于大型语言模型的因果代理。arXiv预印本 arXiv:2408.06849, 2024. 1, 3, 4
[9] Emre Kiciman, Robert Ness, Amit Sharma, 和 Chenhao Tan. 因果推理和大型语言模型:为因果关系开启新的前沿。Transactions on Machine Learning Research, 2023. 1, 2, 3
[10] 刘晓红,刘浩,杨国兴,姜泽宇,崔曙光,张昭泽,王欢,陶立远,孙永昌,宋珠 等。一种通用的医疗语言模型用于疾病诊断辅助。Nature Medicine, 第1-11页, 2025. 1, 2, 3, 4
[11] Sebastian Lobentanzer, Pablo Rodriguez-Mier, Stefan Bauer, 和 Julio Saez-Rodriguez. 基础模型时代的分子因果关系。Molecular Systems Biology, 20(8): 848-858, 2024. 1
[12] Alejandro Lozano, Min Woo Sun, James Burgess, Jeffrey J Nirschl, Christopher Polzak, Zhang Yuhui, Chen Liangyu, Gu Jeffrey, Lopez Ivan, Josiah Aklilu 等。从开放科学文献中衍生出的大规模视觉-语言数据集,以推进生物医学通用AI。arXiv预印本 arXiv:2503.22727, 2025. 3
[13] Chris Ludlow. 探究大型语言模型识别心理案例研究中因果关系的能力:心理案例公式分析的方法学概念验证。LLMs 和精神病例,2025. 1, 2, 3
[14] Michael Moor, Oishi Banerjee, Zahra Shakeri Hossein Abad, Harlan M Krumholz, Jure Leskovec, Eric J Topol, 和 Pranav Rajpurkar. 用于通用医学人工智能的基础模型。Nature, 616(7956):259-265, 2023. 1
[15] Park Chaelim, Lee Hayoung, Lee Seonghee, 和 Jeong Okran. 增强基于XAI的临床决策支持系统的知识图谱和LLM协同联合模型。Mathematics, 13(6):949, 2025. 1, 3
[16] Gabriel R Rosenbaum, Lavender Yao Jiang, Ivaxi Sheth, Jaden Stryker, Anton Alyakin, Daniel Alexander Alber, Nicolas K Goff, Young Joon Fred Kwon, John Markert, Mustafa Nasir-Moin 等。MedG-KRP: 医疗图知识表示探测。arXiv预印本 arXiv:2412.10982, 2024. 2, 3
[17] Shen ChengAo, Chen Zhengzhang, Luo Dongsheng, Xu Dongkuan, Chen Haifeng, 和 Ni Jingchao. 探索使用工具增强的LLM代理进行精确因果发现的多模态整合。arXiv预印本 arXiv:2412.13667, 2024. 1, 3
[18] Wang Xingqiao, Xu Xiaowei, Liu Zhichao, 和 Tong Weida. 变压器类大语言模型在患者安全和药物警戒中的双向编码器表示:因果推理影响的全面评估。Experimental Biology and Medicine, 248(21): 1908-1917, 2023. 2, 3
[19] Anpeng Wu, Kun Kuang, Minqin Zhu, Yingrong Wang, Yujia Zheng, Kairong Han, Baohong Li, Guangyi Chen, Fei Wu, 和 Kun Zhang. 大语言模型的因果性。arXiv预印本 arXiv:2410.15319, 2024. 3
[20] Wei Xu, Gang Luo, Weiyu Meng, Xiaobing Zhai, Keli Zheng, Ji Wu, Yanrong Li, Abao Xing, Junrong Li, Zhifan Li 等。MRAgent: 一种基于LLM的自动化代理,通过孟德尔随机化在疾病中进行因果知识发现。Briefings in Bioinformatics, 26(2):bbaf140, 2025. 1, 2, 3, 4
[21] Yang Zhongqi, Elahe Khatibi, Nitish Nagesh, Mahyar Abbasian, Iman Azimi, Ramesh Jain, 和 Amir M Rahmani. ChatDiet: 通过LLM增强框架赋予个性化营养导向食品推荐聊天机器人力量。Smart Health, 32:100465, 2024. 1, 4
[22] 曾浩龙,尹朝一,柴春阳,王月竹,戴琪,孙慧燕。通过整合因果提示大语言模型与组学数据驱动因果推理识别癌症基因。Briefings in Bioinformatics, 26(2):624, 2025. 1, 2, 3, 4
参考论文:https://arxiv.org/pdf/2505.16982

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 24
24 0
0- 0



 已为社区贡献285条内容
已为社区贡献285条内容

所有评论(0)