Datawhale AI夏令营第三期:多模态RAG图文问答挑战赛Task2学习笔记
本文为我参加Datawhale AI夏令营第三期:科大讯飞AI大赛(多模态RAG方向)的学习笔记,该方向对应“iFLYTEK AI 开发者大赛”中“”赛题,Datawhale提供了和。
本文为我参加Datawhale AI夏令营第三期:科大讯飞AI大赛(多模态RAG方向)的学习笔记,该方向对应“iFLYTEK AI 开发者大赛”中“多模态RAG图文问答挑战赛”赛题,Datawhale提供了ModelScope版和GitHub版的Baseline代码仓库,在此感谢教程作者!
Baseline说明
ModelScope中的Baseline分两步完成比赛中图文问答的任务:
第一步运行fitz_pipeline_all.py,基于PyMuPDF(fitz)逐页提取PDF文本内容,得到结构化的JSON数据(all_pdf_page_chunks.json);
第二步运行rag_from_page_chunks.py,基于刚刚得到的JSON数据构建内存向量库,然后对test.json中每个question向量化。在内存向量库中执行相似度搜索,找出最相似的Top-K知识块(Baseline中K取5)。将用户的原始问题 + 上一步检索到的Top-K个知识块(包含文本和元数据)作为prompt输入大模型,从大模型返回结果中提取答案主体、文件名和页码,整理成比赛要求的格式,保存成rag_top1_pred.json文件。
我在Baseline上做的修改
首先运行Baseline前需要修改env.txt文件,在LOCAL_API_KEY=后加上自己申请的硅基流动API密钥,再将env.txt文件名修改为.env。如果在ModelScope Notebook上运行的话,此时文件会被隐藏。
此时已经可以正常按下⏩按钮,点击Restart确认,等待运行完成后提交rag_top1_pred.json文件。
查看了rag_top1_pred.json文件后,发现文件中answer、filename、page字段基本是空的。

为什么呢?这是因为rag_from_page_chunks.py文件中为了快速得到可提交的文件,只是随机提取了10个问题进行回答,修改TEST_SAMPLE_NUM参数为None后即可回答所有问题。
修改参数后重新运行,发现回答了四百多个问题后报错RateLimitError,这是因为硅基流动对用户 API 在指定时间内访问 SiliconCloud 平台服务频次有限制,Baseline用到的两个模型中Qwen/Qwen3-8B RPM为1,000,TPM为50,000;BAAI/bge-m3 RPM为2,000,TPM为500,000,超出限制后便报错,根据报错信息,这里超出的是Qwen/Qwen3-8B的TPM。
- RPM( requests per minute,一分钟最多发起的请求数)
- TPM( tokens per minute,一分钟最多允许的token数)
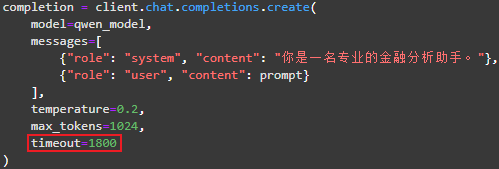
为解决此问题,我尝试修改代码,使用try-except语句,在报错后自动等待50秒并重试,但又出现了APITimeoutError错误。这个是因为网络或服务端处理超时,OpenAI Python库中默认timeout时间为600(10分钟),而此时响应超出了这个时间。最后我发现设置timeout参数,把超时时间放大,即可将以上两个问题一起解决。我取了1800(30分钟),最后代码成功跑完,不过所需时间也有所扩大,rag_from_page_chunks.py文件我一共运行了约2小时。
未来计划
在后面,我计划使用mineru_pipeline_all.py代替fitz_pipeline_all.py,从基于PyMuPDF(fitz)逐页提取PDF文本内容转化为基于MinerU进行版面分析,区分出标题、段落、表格和图片,同时把表格转换成Markdown格式,对于解析出来的图片,使用多模态大模型,来生成文字描述,把图片信息也文本化,方便后续的检索。这样就不只能提取文本,还能提取表格和图片了。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)