DIFY合同生成全流程开发实践(二、Agent开发)
一、背景说明
上一篇内容以采购合同为例说明了各种需要前期准备的文档和开发环境,本篇内容则聚焦于实际功能Dify的节点开发,同时除了采购合同外,还添加了销售合同生成类型,用户需要通过对话框选择合同类型后,根据提示一步步生成相应的合同。
二、变量设置
-
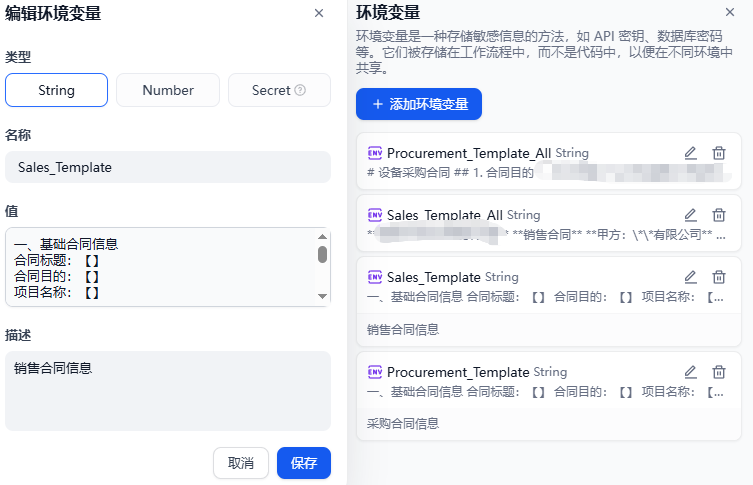
环境变量说明
分别是两套合同的合同模板md格式,以及对应的合同需要收集的合同信息模板。
-
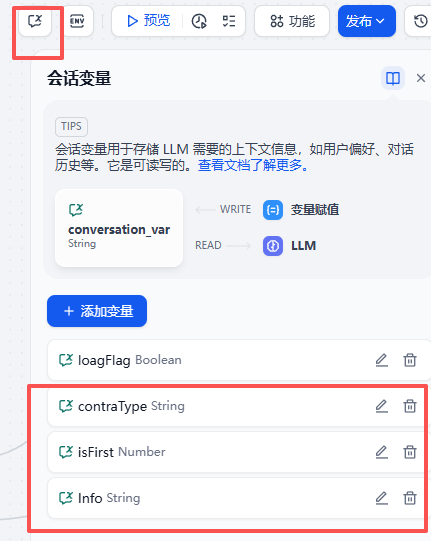
会话变量说明
工作流要存的合同类型、是否首次对话标识、和用户上传的新的合同信息。
三、节点设计
前期为了专注于合同生成,减少意外风险,所以可以在开始节点后加入判断节点,如果用户输入的内容不是合同类型,则提示用户输入要生成的合同类型,减少随意输入带来的各种问题。
-
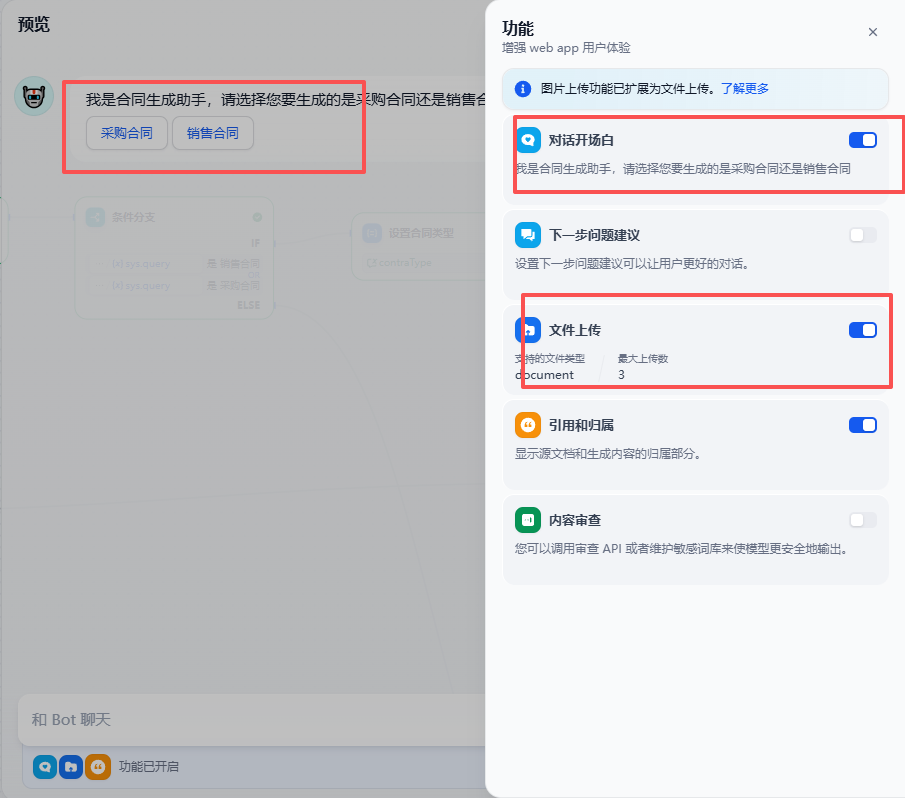
开启开场白与文件上传功能
-
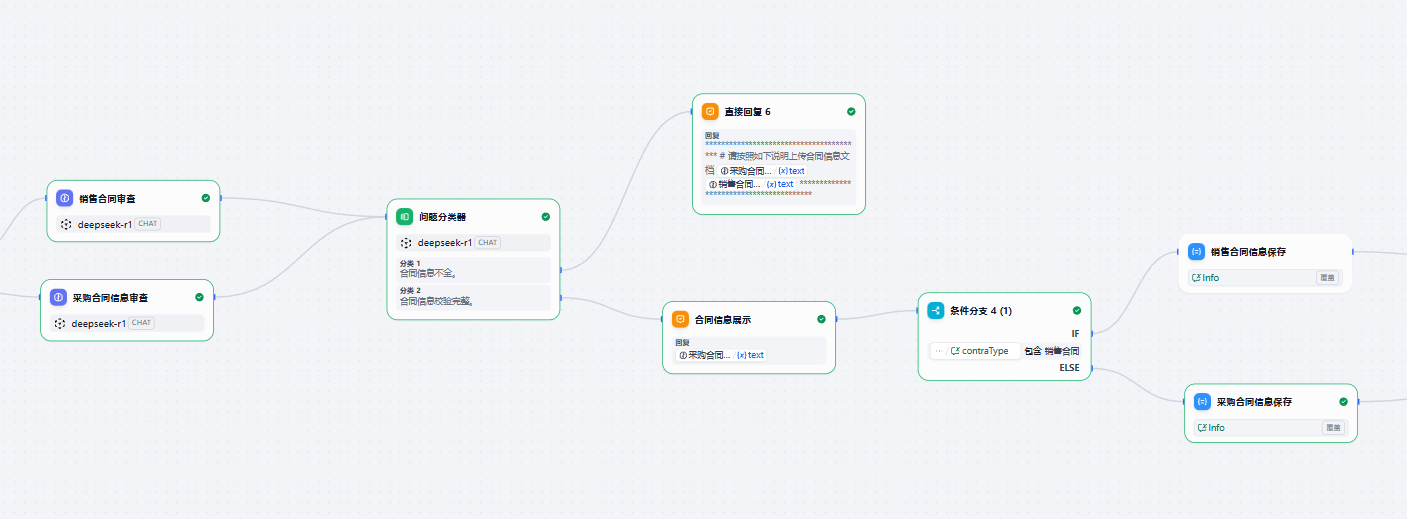
合同信息判断。
当用户选择合同类型后,提示用户上传合同信息,然后模型会根据上传的合同信息,对比环境变量合同信息填写模板,判断信息是否完整,如果完整则继续生成合同,如果不完整,给出提示。
-
模板处理
合同信息校验保存在会话变量之后,就可以让deepseek开始按照合同信息和参考模版生成合同了,但是通常情况下,一个合同的合同模板上万字是很正常的,再加上合同信息,相当于一次对话上下文,要上万字的Token,这样带来以下几个问题:
显存占用过高:
在超长文本处理场景下,DeepSeek 的显存需求可能显著攀升。处理万字级别文档时显存消耗可达48GB,这对普通显卡等硬件设备造成较大压力,易引发性能下降或处理失败问题。
生成质量波动(主要):
研究发现,当输入文本超过4000字时,模型生成结果可能出现逻辑断层或细节缺失现象。这种质量波动在要求高精度的应用场景(如代码生成或商业文书撰写)中尤为明显,可能影响内容的完整性和专业性。
计算资源消耗:
长文本处理会带来显著的计算开销,导致响应时间延长。
实现方式:
目前通过代码节点将合同文本按章节分割为长字符串数组,通过循环节点,将合同信息+每章节模板作为上下文传入模型,可以实现较好的生成结果,最后再将生成的每章内容拼接成完整合同。
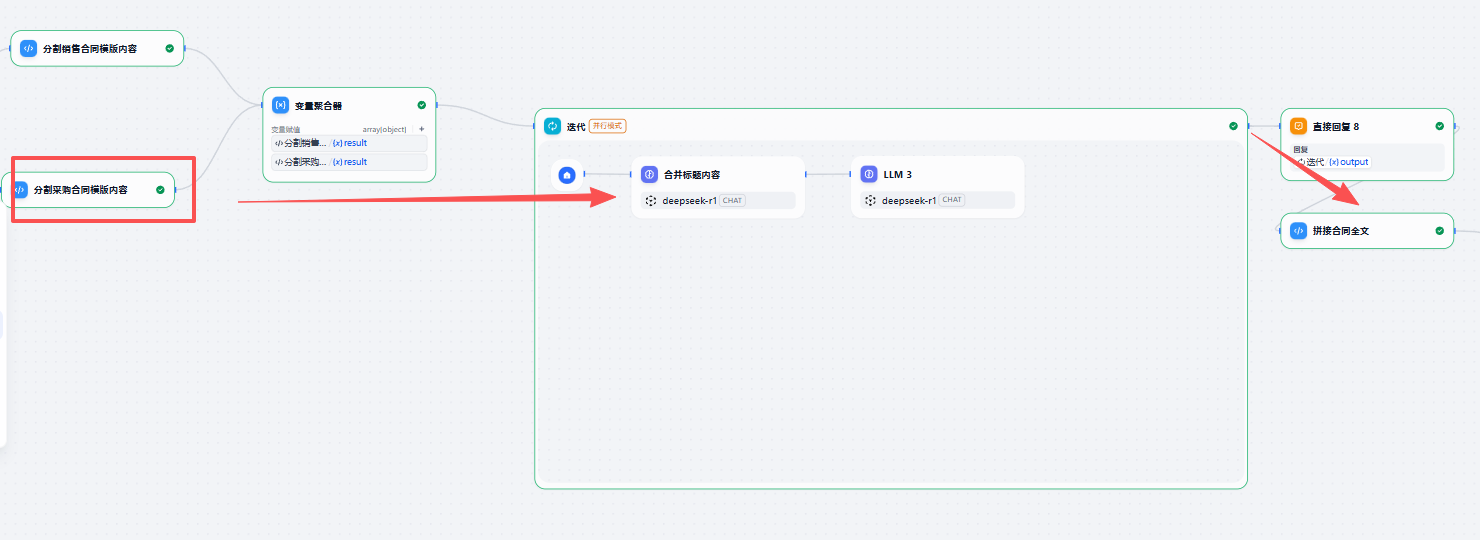
生成word文档
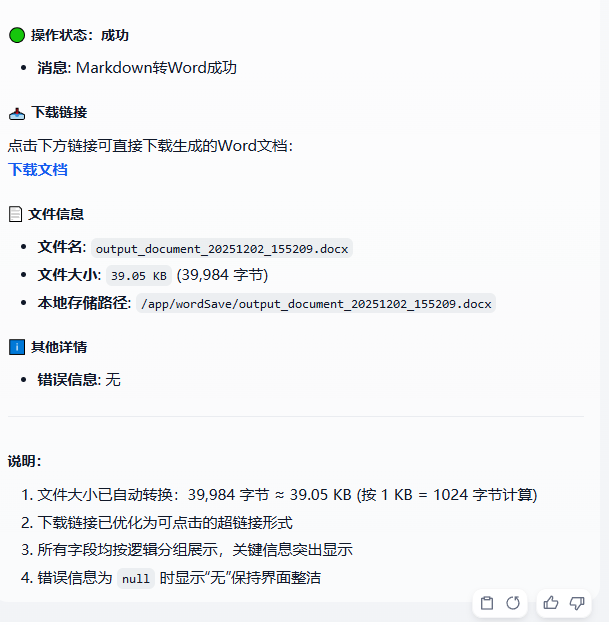
拼接的合同全文,通过http请求节点,调用python文档生成接口,生成word生成路径并返回,实现聊天框点击直接下载。
四、踩坑细节
1.生成的按章节合同文本拼接时,前置增加 \n\n
如果不加,拼接完整的合同md格式在转换word时,pandoc无法有效识别 ## 标题 样式为word标题。
2.请求接口时,完整合同文本超过万字,通常post请求受限,需要后端进行设置。
# 创建FastAPI应用实例
# 修改应用创建部分,移除请求体大小限制
app = FastAPI(
title="Markdown转Word服务",
version="2.1.0",
description="使用pypandoc的Markdown转Word文档服务",
# 移除请求体大小限制
body_size_limit=None
)3.全文的合同文本,是md格式的字符串形式,http请求时作为请求体,换行,空格等等格式会被收到影响,导致最终md转word出现问题,所以有效的解决方法是将合同全文进行base64编码,后端服务接收后再解码,保持原格式。
编码请求:
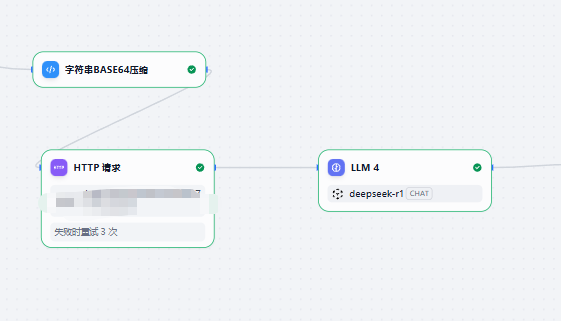
后端解码:
# 解码base64内容
try:
decoded_content = base64.b64decode(markdown_content).decode('utf-8')
except Exception as e:
raise ValueError(f"Base64解码失败: {str(e)}")

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐


 17
17 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)